
Часть 1. Как подключиться к команде разработки и начать использовать Git
Содержание
Часть 2. Реализация Git workflow в 1С-разработке по шагам (эта статья)
Содержание
Прежде чем начинать внедрять gitflow в своей команде, вам для начала предстоит решить, какую модель ветвления вы будете использовать? А из этой части гайда вы узнаете об основных операциях, выполняемых при разработке, которые присутствуют почти в каждой из них.
Начало работы над задачей
Работу по каждой задаче следует выполнять в отдельных ветках, называемых "фича". По соглашению в команде, имя фичи содержит, как правило, номер задачи из трекера. Например, у нас принят шаблон: feature9999. Фича начинается в основном стволе разработки (обычно это ветка develop) и сливается в него по окончании разработки.
Прежде чем начать работу над задачей, актуализируем состояние своего локального репозитория, ведь с тех пор, как мы делали это последний раз, могли появиться новые коммиты наших коллег. Для этого сделаем текущей ветку develop, перейдя на неё, и выполним получение изменений.
Переход на ветку develop и получение изменений
cmd
SourceTree
В списке веток выполняем двойной щелчок по ветке develop. Активная ветка выделяется полужирным начертанием и появляется колечко слева от имени.
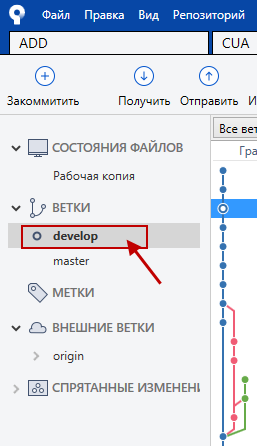
Для получения изменений в текущую ветку нажимаем кнопку "Получить" и в открывшемся окне нажимаем ОК (ничего в нём не меняем):
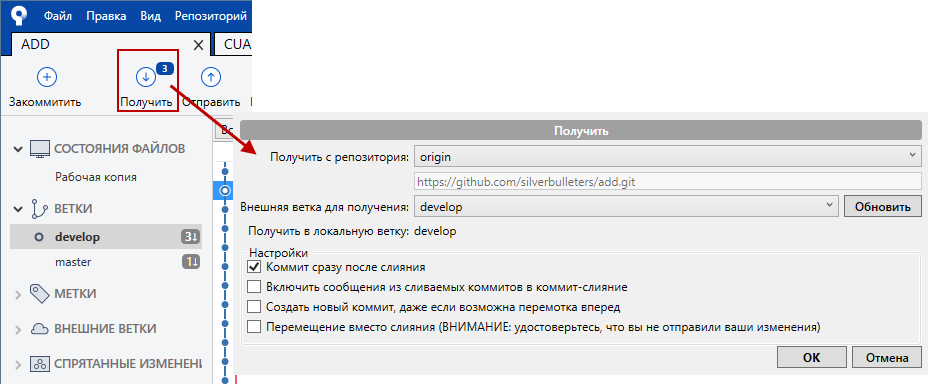
На этом рисунке также видно, что SourceTree любезно информирует о наличии новых трёх коммитов в текущей ветке (возле кнопки "Получить" и рядом с именем ветки). Кроме того, видно, что в неактивной ветке master также есть один не полученный коммит.
При необходимости взять в работу еще одну фичу, приостановив работу над предыдущей, следует проделать эту последовательность еще раз. Но перед этим сделайте коммит в первой фиче (хотя, Git и так вас предупредит, если обнаружит не зафиксированные изменения). Таким образом, у разработчика может быть несколько незакрытых фич, между которыми он переключается в процессе работы, переходя с одной ветки на другую (точно так же, как мы в начале делали активной ветку develop).
Более того, разработчик может в рамках своей фичи создавать собственные суб-ветки и целые деревья, если это необходимо, чтобы, например, реализовать параллельно несколько идей в решаемой задаче или решить ее несколькими способами и сравнить результат. Главное, чтобы в конечном итоге на слияние в develop был отправлен тот единственный рабочий вариант, который должен уйти в рабочую версию.
Процесс жизнедеятельности задачи
Фиксация изменений
По мере того, как продвигается работа над задачей, правилом хорошего тона является периодическая фиксация изменений, или коммит, в ветку фичи.
Напомню, что в процессе коммита изменённые файлы проходят через несколько состояний: сначала они индексируются (или собираются "в очередь" на фиксацию, add), затем производится коммит (commit) проиндексированных изменений в локальный репозиторий, и в конце выполняется отправка (push) изменений в удалённый репозиторий. Некоторые инструменты по работе с Git делают несколько или все эти операции одновременно, так что для разработчика процесс происходит быстро и не напряжно. Но в целом положение дел с вашими файлами именно такое.
cmd
SouceTree
О появлении новых изменений в SourceTree сигнализирует надпись "Незакоммиченные изменения" в продолжении текущей ветки, при этом в списке "Файлы не в индексе" появится перечень всех изменённых файлов. Нажмите "Индексировать всё" (или выделите нужные для фиксации файлы и нажмите "Индексировать выделенное").
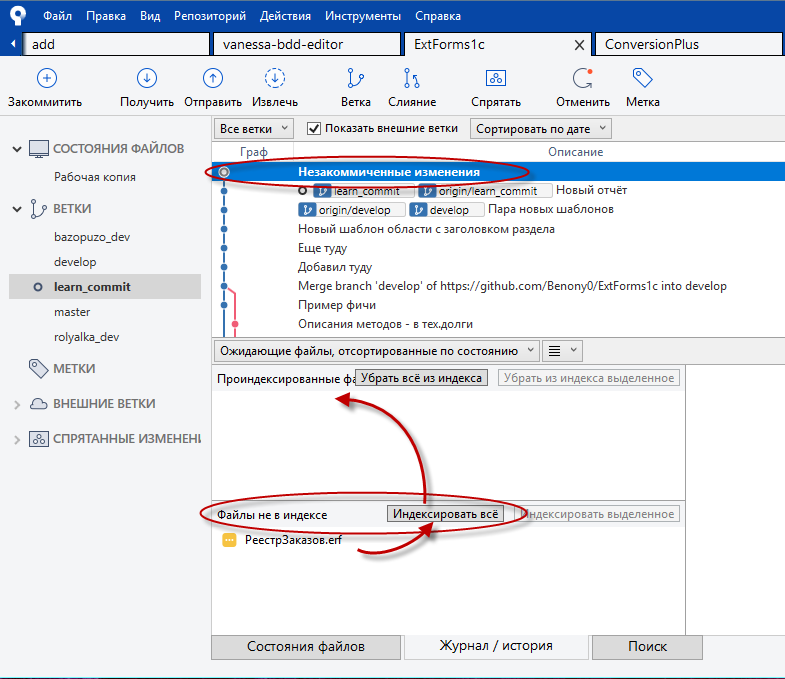
Проиндексированные файлы отправляем в коммит кнопкой "Закоммитить" в верхнем левом углу. Программа попросит внести комментарий к изменениям, после чего нажатие другой кнопки "Закоммитить", уже внизу справа, приведёт собственно к фиксации коммита.
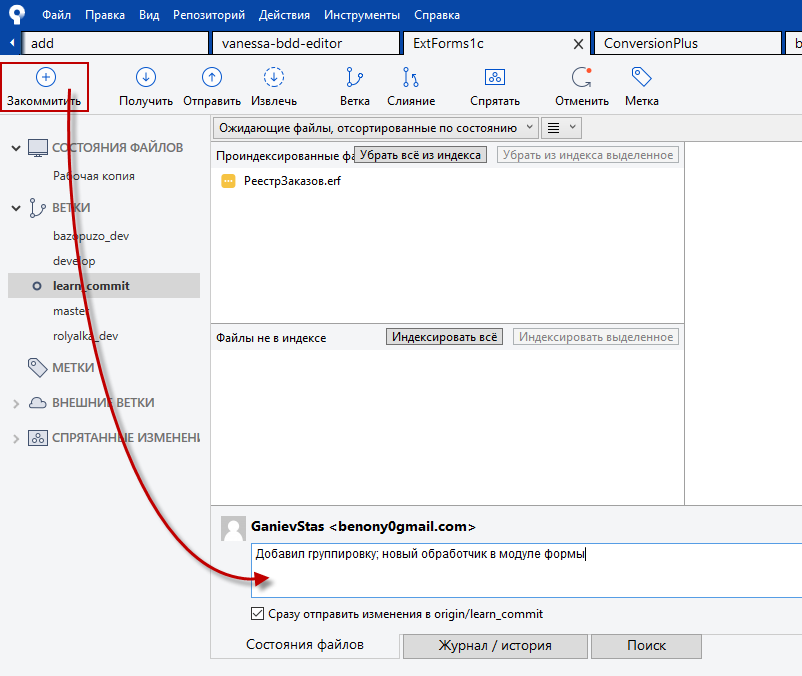
При этом, если установить флажок "Сразу отправлять изменения в origin", то коммит будет отправлен в удалённый репозиторий, и ваша фича синхронизируется с локальной версией.
Если же флажок снят, то коммит будет зафиксирован только в локальном репозитории. Это может быть удобно, если в процессе разработки вы предпочитаете часто коммититься, но не торопитесь делиться с коллегами не работающим кодом. В этом случае, возле имени ветки и около кнопки "Отправить" появится информация о количестве коммитов, готовых к отправке из локального репозитория в удалённый.
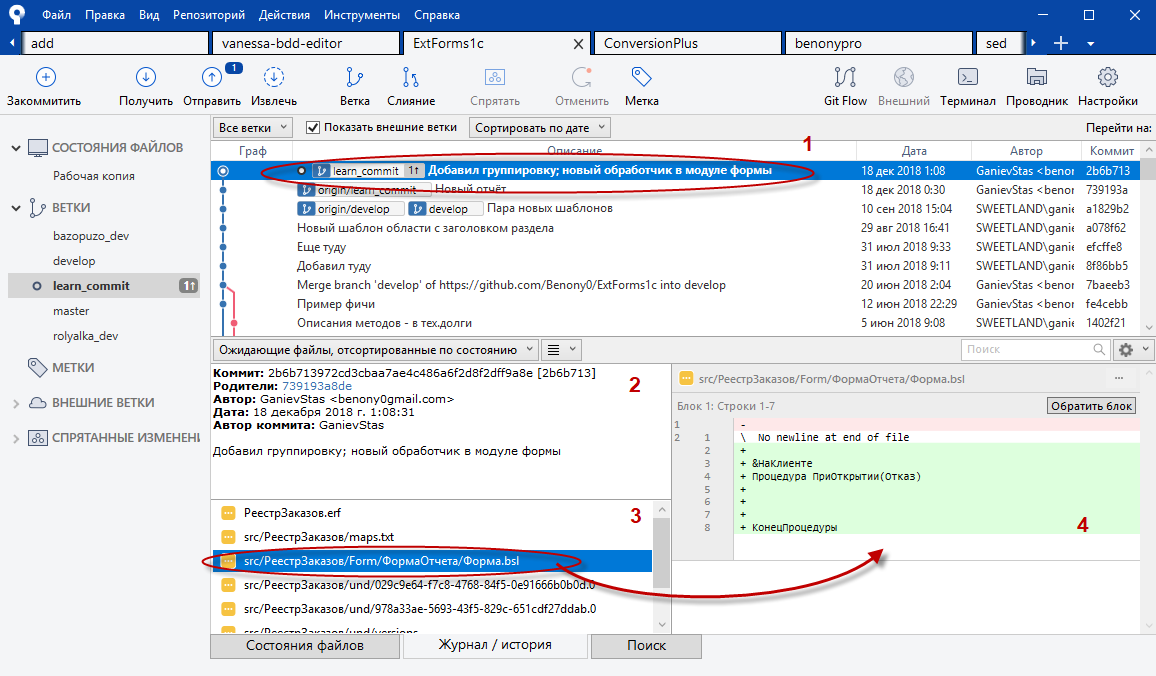
Что мы получили в результате коммита:
- Ветка фичи продвинулась на одну позицию, обрела комментарий об изменениях в данной точке, и теперь выделена жирным шрифтом, что показывает ее текущее положение;
- Подробное описание коммита в развёрнутом виде;
- Перечень файлов, подвергшиеся изменению. Да, их тут чуть больше, чем мы индексировали, т.к. сработал precommit1c, но об этом чуть позже;
- Построчное описание изменений текущего (выделенного) файла.
Теперь, чтобы отправить наши локальные изменения в удалённый репозиторий, нажмём кнопку "Отправить", и в открывшемся окне (ничего в нём не меняя) еще раз нажимаем "Отправить".
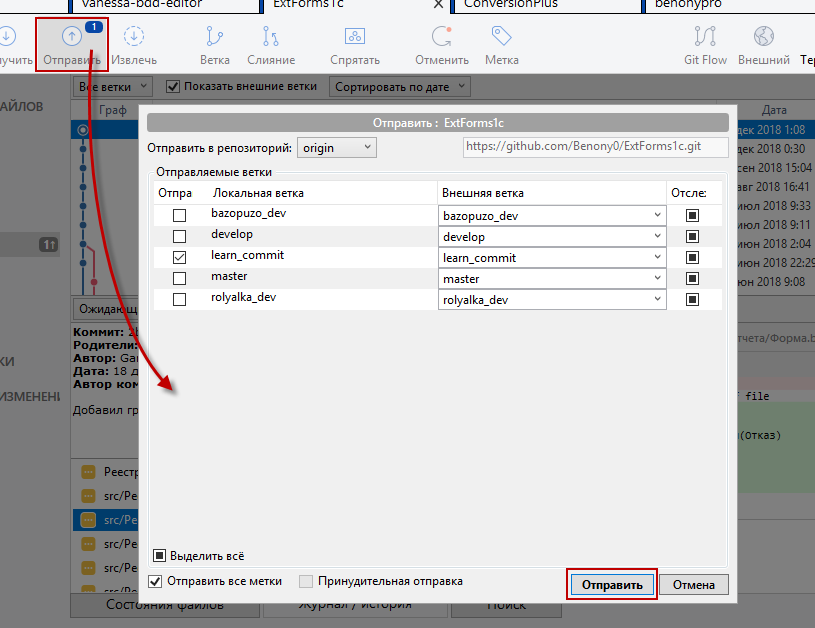
В этом простом примере заодно было показано, как работает Precommit1c: в момент коммита он автоматически раскладывает внешнюю обработку на исходные файлы и бережно раскладывает их в папке src с учётом иерархии. И то же самое он будет делать и с расширениями конфигурации, если вы ведёте разработку с их использованием.
Тут я хотел продемонстрировать еще одно преимущество работы с Git: ваш рабочий каталог — это сам git-репозиторий. Не нужно куда-то отдельно копировать обработку, чтобы потом что-то делать для фиксации версии. Достаточно сохранить ее прямо в репозитории, а всю грязную работу Git и Precommit1c выполнят за вас. Главное — правильно указать в начале текущую рабочую ветку.
Отмена изменений и других последствий невнимательности
В процессе работы много чего приходится отменять, отказывать и еще как-то заметать следы своих косяков, еще до того, как ваши труды полетят в продакшен, то есть пока вы возитесь в своём локальном репозитории.
Отказ от индексирования изменений
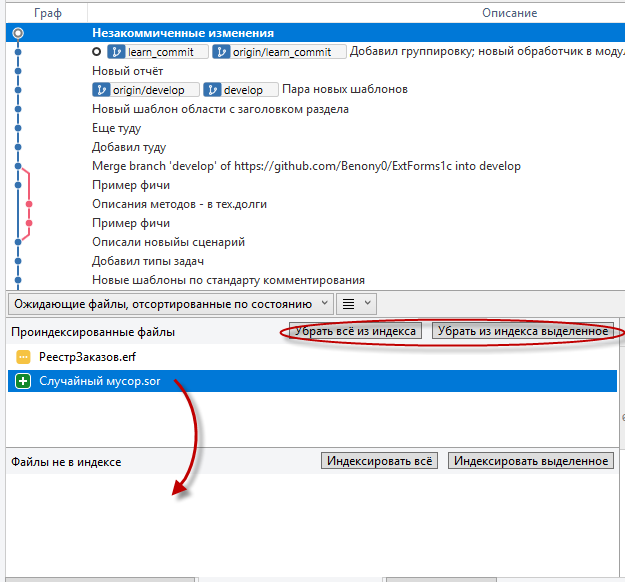
Лично моя — самая частая ошибка 🙂 Сначала индексируешь всё (удобно ведь одной кнопкой), а потом вспоминаешь, что не всё-то и надо было. Или вдруг вспоминаешь, что нужно было часть текущих изменений зафиксировать отдельным коммитом. Убираем файл из области индексирования:
cmd
SourceTree
Для удаления файла из индекса предусмотрены две кнопки "Убрать всё из индекса" и "Убрать из индекса выделенное"
Игнорирование файлов, файл .gitignore
Файл .gitignore (именно так, с точкой и без расширения) и механизм игнорирования позволяют отключить от версионирования часть файлов из вашего репозитория. Это очень удобно, когда, например:
- В локальном репозитории есть файл с локальными настройками или сведениями о состоянии проекта, но его смысл теряется при переходе к удалённому репозиторию. Такие файлы полезны только при работе на локальной машине, но их не надо коммитить. Пример такого файла — файл VERSION, необходимый при работе с gitsync;
- В локальном репозитории вы храните дополнительные рабочие файлы проекта, которые нужны только вам, но их не нужно версионировать и делать достоянием всей команды. У меня в репозитории с правилами обмена таковыми являются файлы с описанием структуры конфигураций. Они лежат в одном месте со всем, что связано с обменами, но при этом не мешают другим разработчикам.
Файл .gitignore располагается в корневом директории репозитория, а по своей структуре — это текстовый файл, в каждой строке которого содержится имя файла, маска файла или путь к каталогу, содержимое которого следует игнорировать системе Git. В дальнейшем, при изменении таких файлов они никак не будут влиять на состояние репозитория (не появится незакоммиченных изменений).
Если вы работаете с Git из консоли, то этот файл следует создать и настроить вручную.
SourceTree
Если файл еще не коммитился (новые файлы помечаются вопросительным знаком), то в его контекстном меню доступен пункт "Игнорировать…". При этом есть возможность выбрать вариант игнорирования.
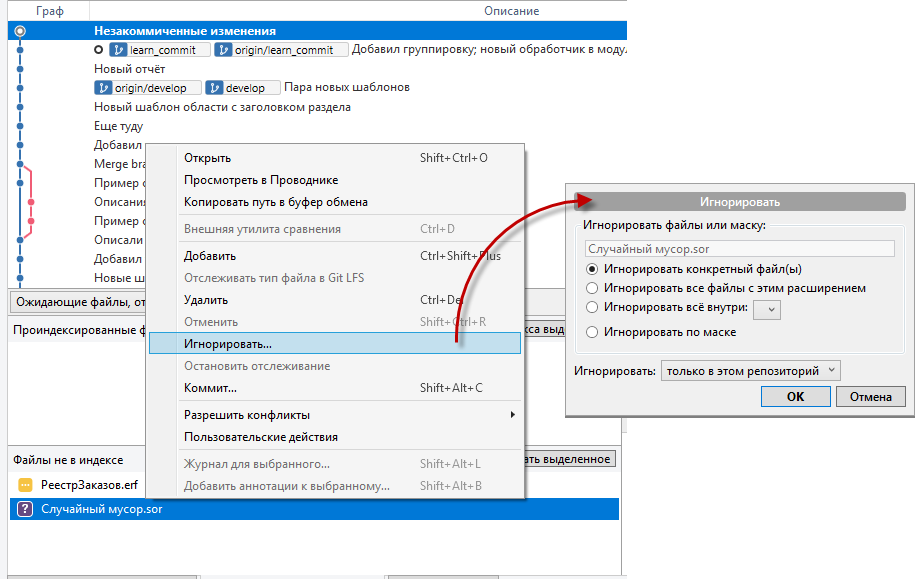
Следует отметить, что сам файл .gitignore тоже коммитится и версионируется. Это может сбить с толку новичка, когда, например, после получения изменений из develop система вдруг перестаёт видеть часть файлов разработчика. Или при создании новой фичи не действует игнорирование, которое только что настраивал, но настройка осталась в другой фиче, которая еще не слита в develop.
Поэтому рекомендую при любых изменениях .gitignore сразу же сливать его в основной ствол разработки. А еще лучше — договоритесь с коллегами, что именно будете игнорировать, и настройте файл заранее.
Отмена изменений в индексе
Если изменяется файл, который уже версионируется в проекте, то есть возможность отменить текущие изменения и вернуться к его исходному состоянию (к состоянию предыдущего коммита).
cmd
SourceTree
Изменённый файл отмечается значком с тремя точками, для таких файлов в контекстном меню доступна команда "Отменить"
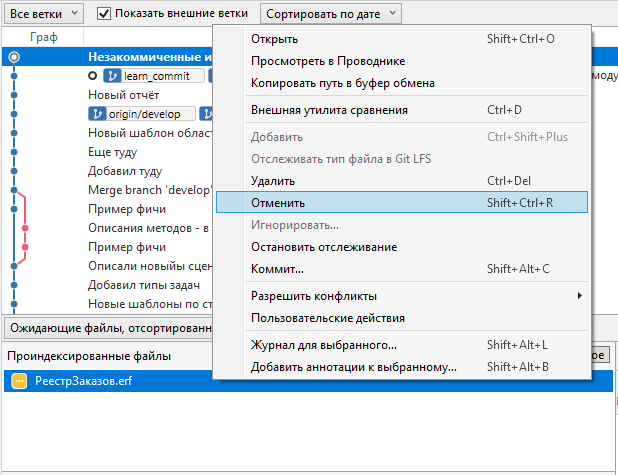
Кроме того, ряд операций с изменениями (помещение в индекс, удаление из индекса, обращение коммита) можно производить не только над файлом в целом, но и на отдельных блоках изменений и даже с отдельными строками кода. Для этого в окне изменений справа от списка файлов предусмотрены соотвествующие кнопки над каждых блоком. Если выделить отдельные строки кода, то кнопка над блоком примет вид в соответствии с вашими действиями.
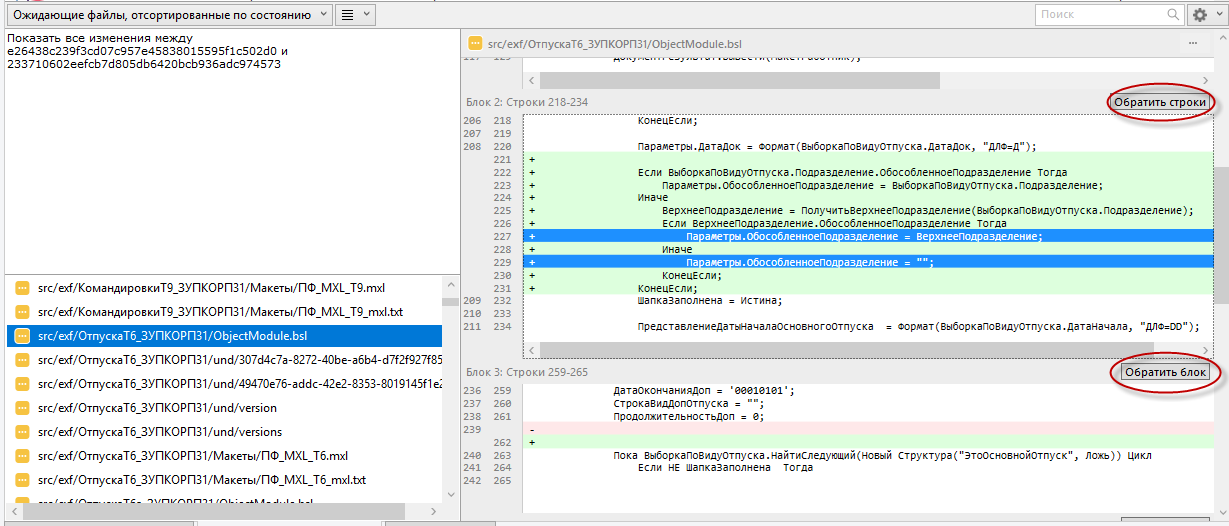
Внимание! Не все операции с выделенными строками возможны. Зачастую система требует, чтобы выделенные строки составляли непрерывный диапазон. А в операции с не подряд идущими строками (как на картинке) может быть отказано.
P.S. Отменяется выделение строки одинарным щелчком по ней же.
Просмотр изменений
Сравнение разных версий файлов и просмотр изменений — одна из ключевых задач, ради которых используется Git. Консольная команда git log использует большое число дополнительных параметров, благодаря которым можно получить практически любой отчёт по истории изменений.
cmd
SourceTree
Изменения для текущего (выделенного в списке) коммита можно видеть непосредственно в главном окне, в соответствующих областях. "Гуляя" по коммитам, можно увидеть перечень изменённых файлов и изменение строк кода для каждого из них.
Для просмотра всех изменений одного файла, достаточно найти его в списке коммита и в контекстном меню выбрать первый пункт "Журнал для выбранного":
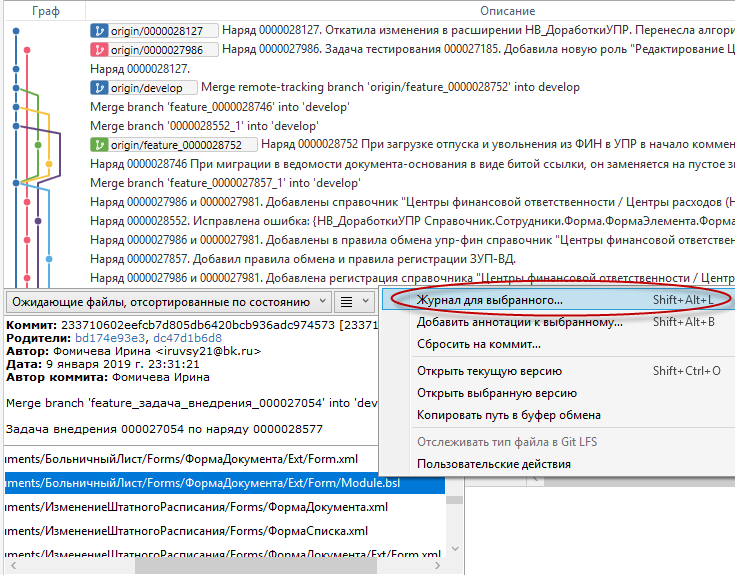
Откроется окно журнала для выбранного файла, с перечнем всех коммитов, в рамках которых был изменён этот файл:
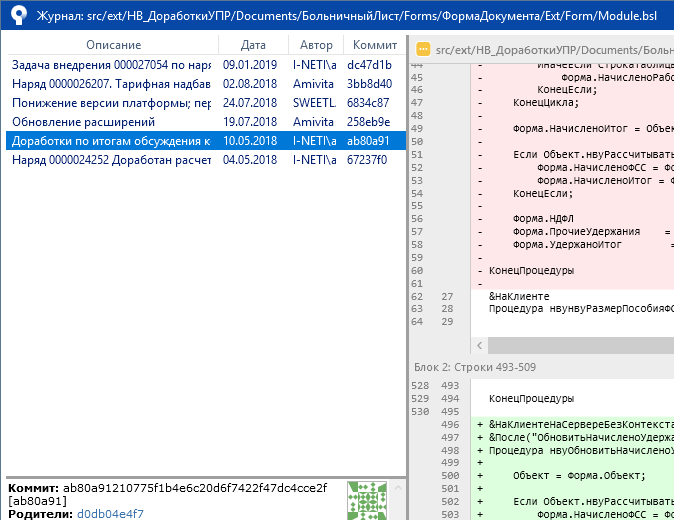
И тут встаёт ожидаемый вопрос: а если в текущем коммите нет файла, историю которого я хочу посмотреть? Или я вообще уже забыл, в каком коммите он последний раз изменялся? В этом случае просто воспользуйтесь командой git blame.
| Да, да, я немного лукавил, когда говорил, что при использовании графической GUI-оболочки вы можете полностью отказаться от командной строки :)). Ни одна GUI не способна охватить весь спектр возможностей Git. И время от времени вы будете прибегать к помощи терминала. Он даже штатно вызывается из SourceTree в меню "Действия — Открыть в терминале…". |
Еще один приём, который удобно применять при код-ревью — это просмотр изменений между двумя релизными коммитами. Если выделить первый коммит и, зажав клавишу Ctrl, выделить второй, то будут отображены все изменения, произведённые между этими двумя фиксациями:
О других методах отладки в Git можно почитать здесь.
Слияние готовой фичи в develop
Когда работа над задачей завершена, готовый код объединяется с общей веткой разработки develop. Этот процесс называют слиянием, или merge в терминах Git.
Смержить изменения можно тремя способами: а) Выполнить merge локально, и результат слияния отправить в origin; б) Выполнить запрос на слияние (pull-request) в общий репозиторий разработки; в) Выполнить pull-request из своего fork в авторский репозиторий. О последнем варианте есть отличная статья Антона Иванова, рекомендую к прочтению. В ней же описаны и основные приёмы работы с запросами на слияние.
Сразу стоит остановиться на моменте, который сбивает с толку многих новичков: "Из какой ветки в какую принимается код, когда я выполняю merge?". Ответ прост: значение имеет то, на какой ветке feature1 вы сейчас находитесь. А при выполнении команды, скажем, git merge feature2, вы принимаете к себе новый код. То есть, feature2 вливается в feature1.
Вариант 1. Локальный merge
cmd
SourceTree
Двойным щелчком на названии ветки делаем активной ту, в которую будем сливать код. В панели инструментов главного окна нажимаем кнопку "Слияние":
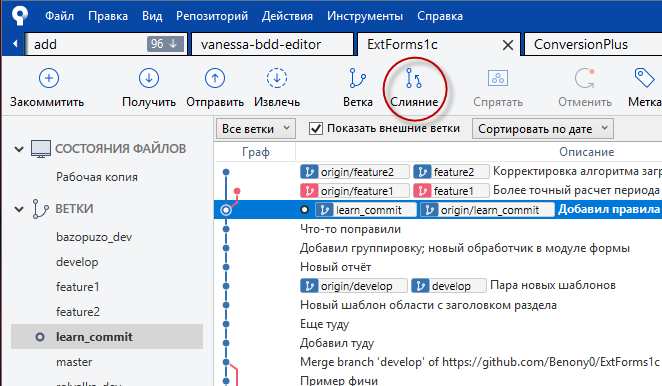
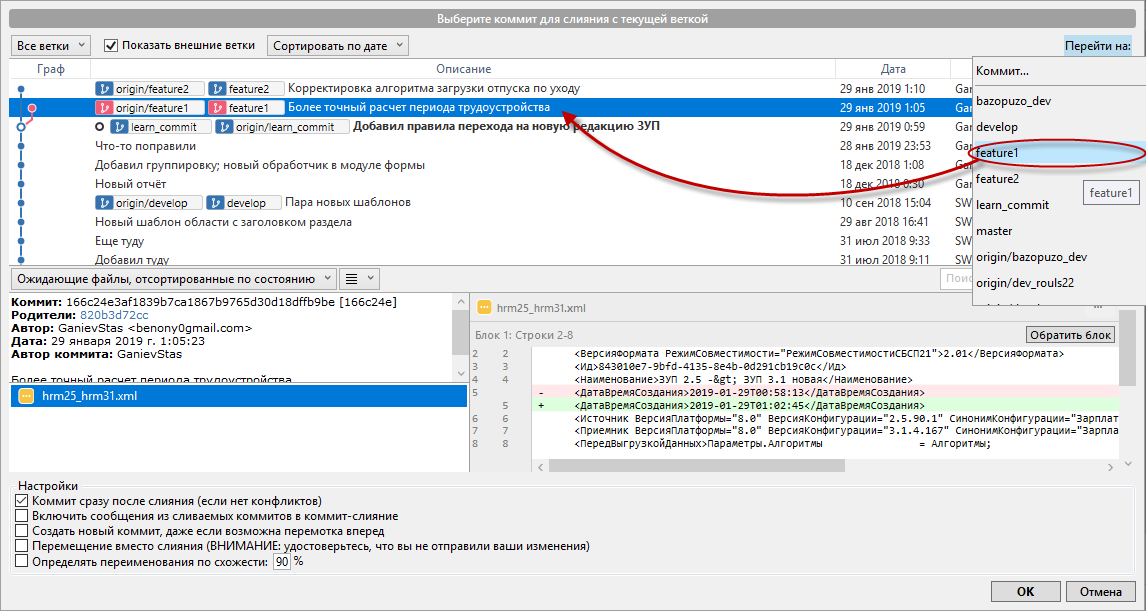
Откроется дополнительное окно для выбора коммита, из которого следует взять код для слияния. Выделяем нужный и щёлкаем "ОК". (Чтобы спозиционироваться на последнем коммите заранее известной ветки, бывает удобно воспользоваться кнопкой "Перейти на" в верхнем правом углу).
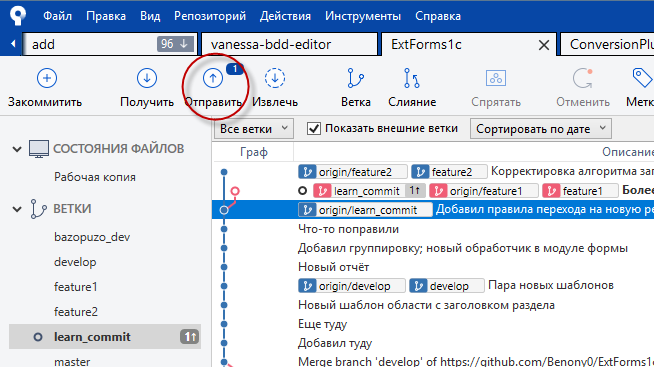
Если не было конфликтов слияния, то код принимается в родительскую ветку и выполняется локальный коммит. Теперь остаётся только отправить новую версию файла в удалённый репозиторий с помощью кнопки "Отправить".
Вариант 2. Создание запроса на слияние
Pull request, или запрос на слияние, отличается от простого слияния тем, что изменения никогда не принимаются сразу. При каждом таком запросе сливаемые ветки переходят в особое состояние, когда ожидают решения архитектора/тимлида о принятии новой версии. Работа эта (и создание запроса, и ответ на него) выполняется на сайте git-сервиса. Для всех сервисов процесс очень похож, приведу пример для GitHub.
На странице проекта нажимаем кнопку "New pull request"
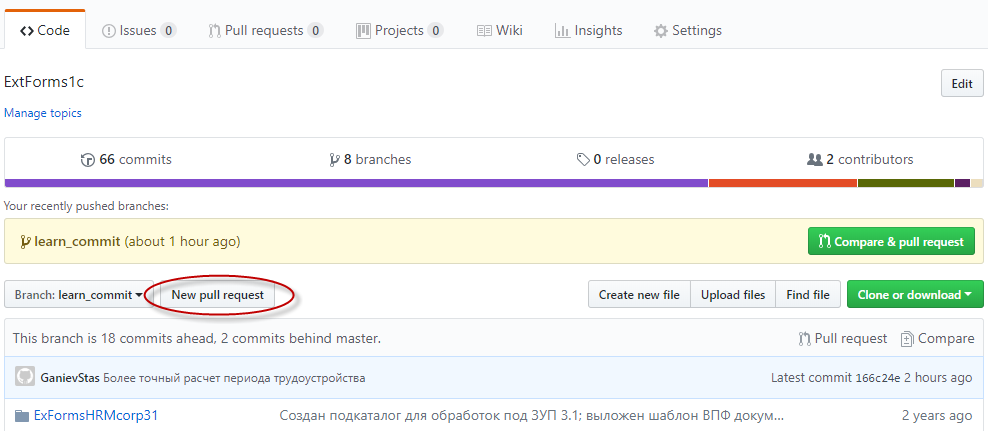
Далее, выбираем исходную и целевую ветки слияния. При этом название запроса автоматически будет подставлено из комментария коммита. При необходимости можно указать подробный комментарий к запросу. Нажимаем кнопку "Create pull request", и запрос готов.
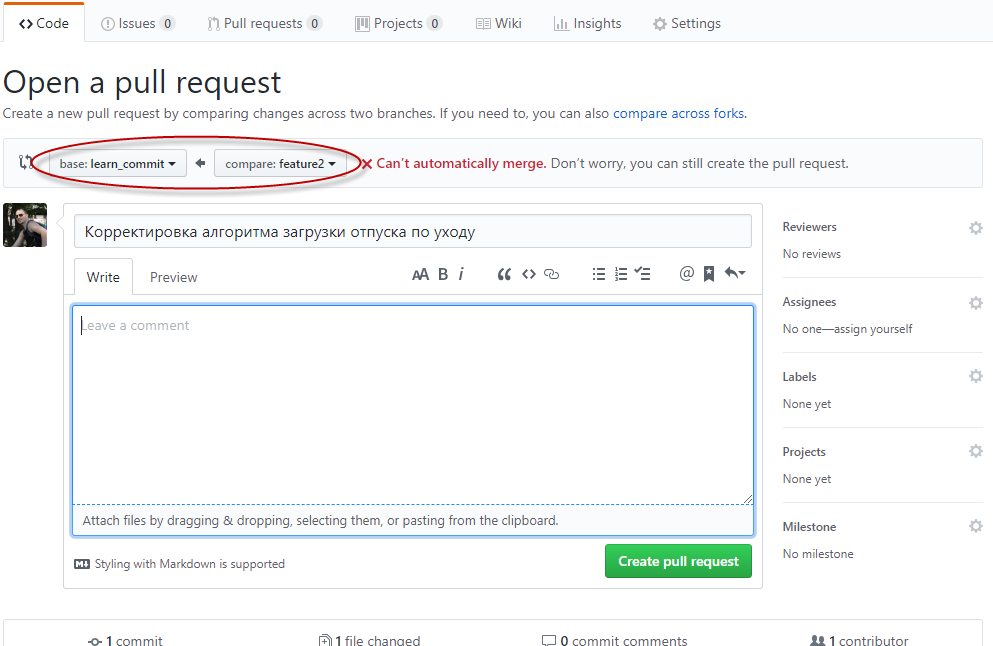
После проверки нового кода, владелец проекта нажмёт кнопку "Merge pull request", после чего изменения будут приняты в родительскую ветку.
Вместо заключения. О чём договариваемся в команде
- Выбор модели ветвления;
- Правила именования фич;
- Частота выполнения коммитов в процессе работы;
- На какой версии платформы работает вся команда? Важный момент, поскольку от релиза к релизу платформа может немного менять формат выгрузки конфигурации в файлы, да и в самих файлах содержится информация о версии платформы, которой они были созданы. При нарушении этой договорённости, коммиты отдельных сотрудников будут вызывать такое количество изменений, что польза самого использования Git сойдёт на "нет". Пропишите это в Readme к своему репозиторию (как, собственно, и все остальные правила вашей команды);
- Именование коммитов. Хорошая статья на эту тему — здесь;
- Состав файла .gitignore.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
По сравнению и применимости моделей ветвления (точнее воркфлоу) хотел бы поделиться ссылками на лучшие публикации, которые встречал по этой теме. Они правда на английском. C сайта Atlassian, где вообще очень много хороших методических материалов:
Модель с одной веткой и общее сравнение моделей:
Модель фича-бранчей:
Гитфлоу:
Форки и пул-реквесты:
P.S.: Из прошлой публикации пропала информация о том, что будет отдельная статья про применение Visual Studio Code при разработке на 1С. Надеялся, что выйдет. Больше нет в планах её публиковать?
Большое спасибо за статью! Давно ожидали продолжения 1-й части!
(1) Может и будет)) Просто не хочется обещать, вдруг опять что-то пойдёт не так…
При активном использовании CI/CD можно избежать использование веток develop, release и hotfix совсем.
Это то, что рекомендуется в вариантах github flow и gitlab flow.
(4) пожалуйста дайте ссылку на рекомендацию или поясните как тогда работать с хотфиксами и планированием релизов?
Думаю над организацией релизного управления и у меня пока классическое понимание: планирование релиза, сборка, тестирование, выпуск в продукт, исправление ошибок хотфиксами. При этом хотфиксы не идут в ветку develop, а при очередном релизе затираются нормальным решением.
(5) суть DevOps а в том, что у тебя был бы в мастере код всегда готовый к релизу. Любой комит может быть релизом. Фактическим релизом становится тот, на который ты повесишь тег.
Достигается это за счет предварительной проверки любого бранча до вливания его в мастер при мердж реквесте.
Для гитхаб флоу это так, в гитлаб флоу рекомендуется еще и деливери делать отдельными ветками типа с мастера можно отмерджить в ветеупрепрод где стейдж окружение и тесты уже не покомитные продукта, а скопом все окружение как копия прода, а с препрода можно отмерджить в прод.
> git commit -m «my comment» -a
использование параметра -a в команде commit делает бессмысленной вышеуказанную команду «git add FileName», потому как добавляет автоматом все изменения в индекс, а вы судя по всему хотели в индексе видеть только FileName
Интересно увидеть 3 часть 🙂
(0) Как работаете с ветками? Под каждую ветку заводите отдельную базу? Используете инкрементальные выгрузку и загрузку из/в конфигуратор? Как осуществляете переход между ветками, в которых созданы новые объекты?
—
(8)
Согласен.
(0)
Самое интересное начинается при деплое. Собрать cf из Гита(если соберётся) и …
(11)
Работаю с EDT, там конфигурация из исходников вроде нормально собирается. Т.е. работа происходит изначально с исходниками, из которых при каждом тестовом запуске собирается конфигурация.
Подскажите, пожалуйста, может кто сталкивался с проблемой различия кодировок в именах файлов и их содержимым?
Использую стандартную функцию Конфигурация->Выгрузить конфигурацию в файлы.
При изменении настроек кодировок в SourseTree корректно работает что-то одно.
Поведение программы видно на скриншотах.
(9)Под разные конфигурации следует создавать отдельные репозитории. Ветки репозитория — это истории жизни разных версий одного проекта, но никак не разные проекты.
Переход между ветками — обычным образом. Какие у вас с этим сложности?
(14) Ветки создаются под каждую задачу. Но если в рамках задачи создается новый объект конфигурации, то как быть тут? В одной ветке объект есть, в других нет.
(15)Тут следует поступать так же, как и в хранилище: добавляем объект и сразу вливаем его в основной ствол, предварительно сделав минимальные необходимые настройки. Ветку фичи при этом не закрываем и продолжаем в ней работать.
Другой вариант (без помещения в основной ствол): те, кому нужен новый объект, мержится от вашей фичи напрямую к себе. Потом уже не важно, кто первый смержить объект в дев, это уже легко разруливается гитом.
(16) В итоге нужно обновлять все свои ветки, чтобы данный объект был в них, либо заводить под базу с новым объектом отдельную базу. Так?
(17)