
Перед прочтением желательно ознакомиться с предыдущими статьями: Как мы управляем версиями (GIT+1C), Как мы управляем версиями и тестированием 1C 8.3 (часть 2)
Разработка качественных продуктов для 1С:Предприятие 8 довольно большая проблема. Для начинающих программистов и специалистов средней руки вопрос не стоит так остро, они не отвечают за работу огромных, высоконагруженных, сложных и нестандартных механизмов, где иногда часы простоя стоят огромных денег. Естественно все это создается не одним человеком и не за один день, когда случается переход от простых задач к глобальным и цена ошибки велика, вот в этот момент возникают вопросы взаимозаменяемости специалистов, совместное владение кодом и даже просто владение, регистрация и учет изменений, сроки реализации функционала, тестирование, списки приемных тестов и т. п.
Что же мы имеем в 1С |
Чего же все-таки хочется |
Хранилище конфигурации:
|
|
УСТАНОВКА GIT
Git берем отсюда http://git-scm.com/download. С установкой не должно возникнуть проблем. Как пользоваться Git можно прочесть здесь.
Что такое контроль версий, и зачем он вам нужен? Система контроля версий (СКВ) — это система, регистрирующая изменения в одном или нескольких файлах с тем, чтобы в дальнейшем была возможность вернуться к определённым старым версиям этих файлов.
ВЫБИРАЕМ BITBUCKET.ORG ИЛИ GITHUB.COM
Регистрируемся в системе для бесплатного хостинга вашего кода. Выделить один из сервисов сложно, мы используем оба. Регистрация довольно простая, да и все вопросы настроек уже описаны сотни раз в интернете.
Что выбрать, и зачем это нужно? Сервисы позволяют провести код ревью, выполнить объединение, синхронизацию, оповестить трекер задач об изменениях по определенной задаче, выслать извещение участникам проекта и т. п. В каждом сервисе есть свои плюсы и минусы — выбор остаётся за вами.
НЕОБХОДИМЫЕ ВЕЩИ
Хранить в Git бинарные файлы можно, но практической пользы от этого мало, их нужно распаковать в текстовые файлы понятные простому обывателю. С конфигурацией сделать это просто с помощью команды "Выгрузить конфигурацию в файлы…". С внешними обработками и отчетами это сделать сложнее, на помощь приходит сообщество c инструментами V8Commit или precommit1C, последний умеет собирать внешние обработки и отчеты из файлов.
Что выбрать? Сейчас precommit1C активно развивается и дорабатывается, по моему, выбор очевиден. V8Commit развивается "закрыто" и пока не ясно под какой лицензией будет распространяться в дальнейшем, так же нужно обязательно в commit включать бинарные файлы (*.epf, *.erf).
КОГДА ОСИЛЕНЫ ПРЕДЫДУЩИЕ ПУНКТЫ
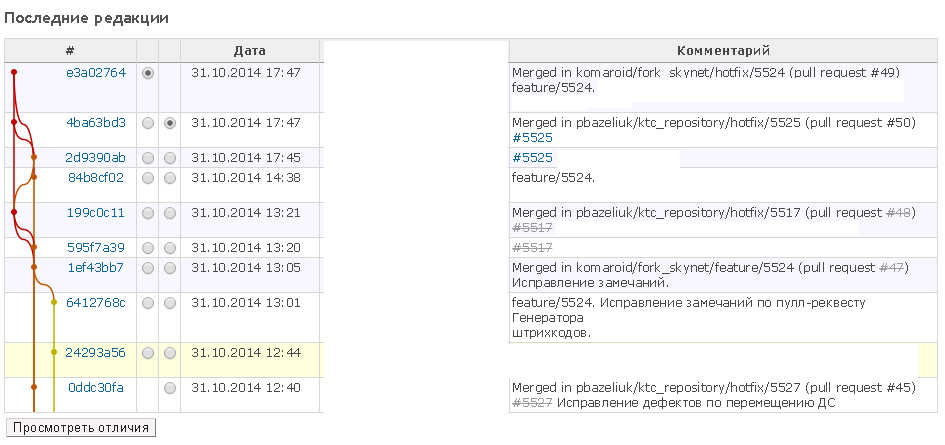
Примерный результат будет таков (в данном примере bitbucket.org):
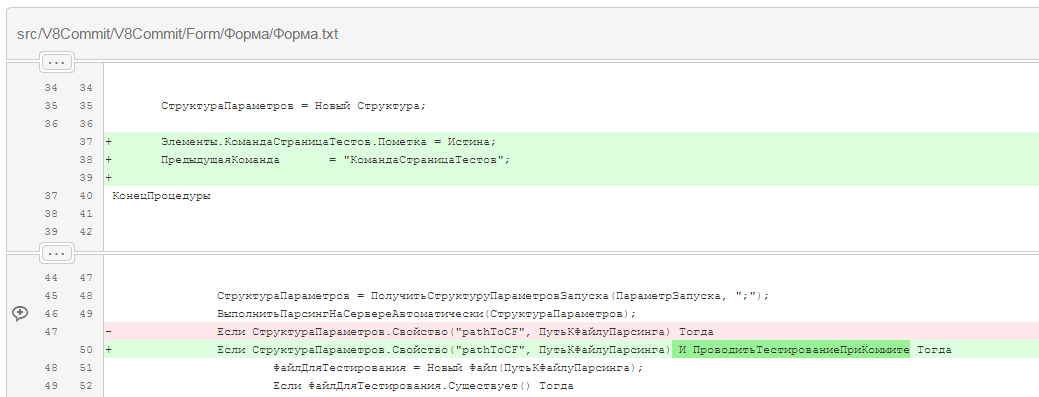
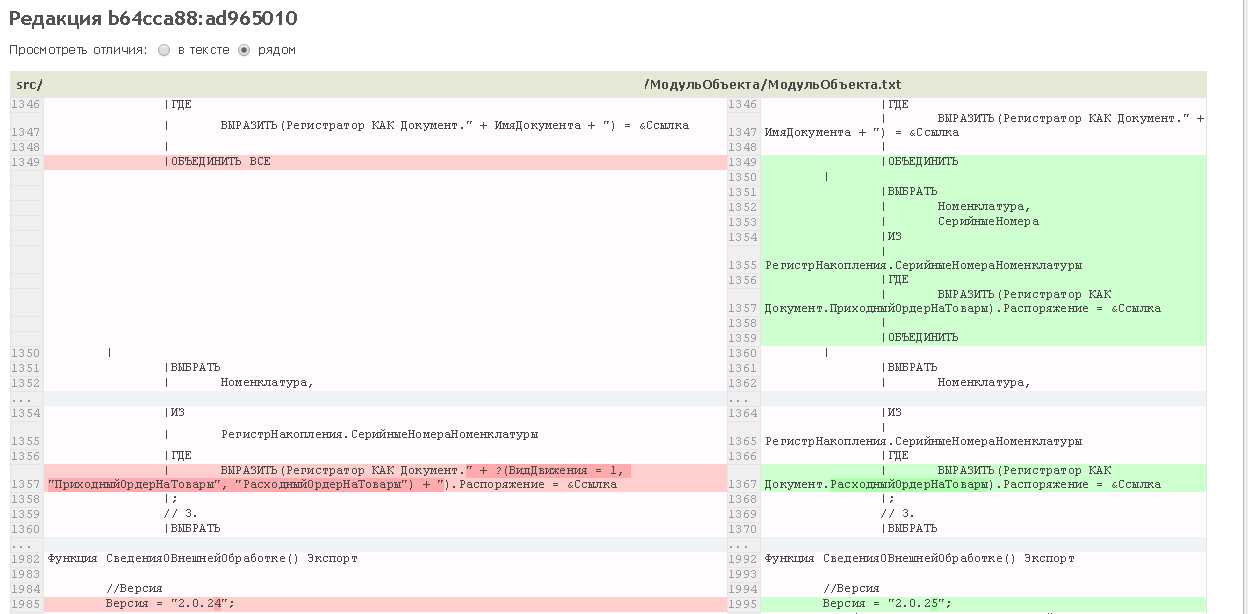
К каждой строчке можно оставить комментарий, этот текст придет участникам проекта на почту (можно перенастроить), если это pull-request, только тому кто запросил внести изменения. Красным цветом помечено, что удалено; зеленым цветом, что добавлено; ярко-зеленым, что добавлено новое в этой строке по сравнению с предыдущей версией.
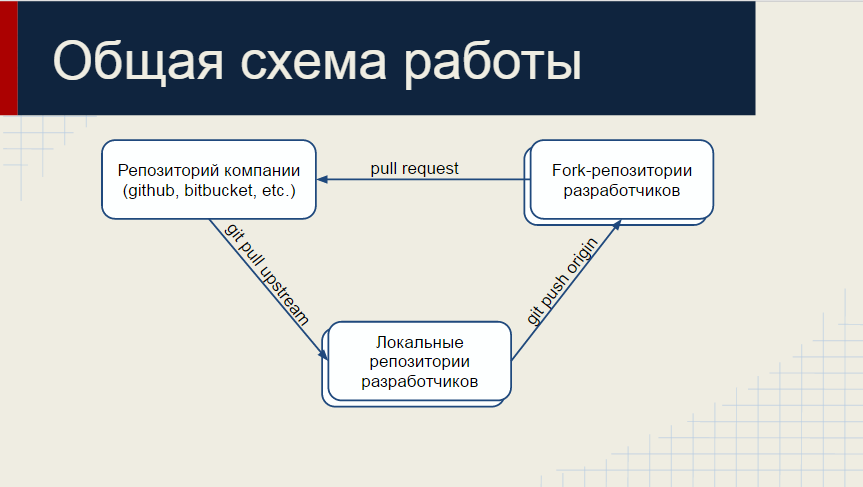
ТЕРМИНОЛОГИЯ GIT-FLOW
- fork — использование кодовой базы проекта для старта нового или доработки с последующий объединением;
- commit — принять и сохранить последние изменения в репозиторий (хранилище);
- pепозиторий — место, где хранятся и поддерживаются какие-либо данные;
- push — отправитьобновить новые или измененные объекты в удалённый репозиторий;
- pull — получитьобновить новые или измененные объекты из удалённого репозитория;
- push request — запрос на объединение fork c кодовой базой стартового проекта;
- alias — используется для сокращение команд;
- branch — направление разработки, независимое от других;
- master — в данной статье стабильнаярабочаяиспользуемая ветка;
- develop — в данной статье ветка которая разрабатывается и в будущем изменения будут перенесены в ветку master, после успешной демонстрации заказчикам;
- hotfix/number — ветка, которая предназначена для внесения правок напрямую в master, по сути это ветка быстрых исправлений критических ошибок, number — номер задачи трекера;
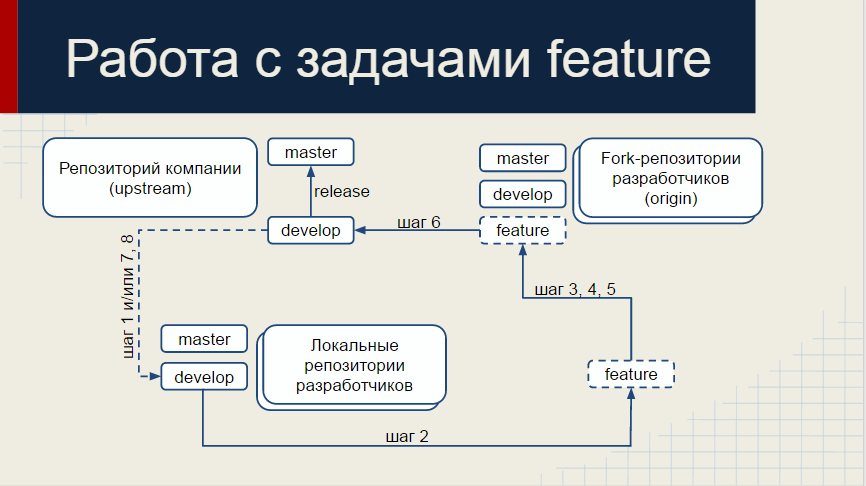
- feature/number — ветка, которая предназначена для реализации нового функционала, после того как задача предположительно готова — выполняется pull request в ветку develop. При удачном код ревью, выполняется объединение с веткой develop, иначе отсылается на доработку. number — номер задачи трекера;
- code review — проверка кода на оптимальность, соответствия техническому заданию и стандартам http://its.1c.ru/db/v8std.

Перед тем как включить нового разработчика в команду, ему нужно дать право на чтение необходимого репозитория компании на bitbucketgithub и сделать fork с которым ему придется работать в разрезе спринтапродуктового цикла разработки. Обязательно задать e-mail в настройках git, который должен совпадать с e-mail на bitbucketgithub для однозначной идентификации при выполнении pull request и для получении обратной связи от черного мастера код ревью.
Если разработка идет по верному пути, нижний слайд понадобится всего 1 раз.



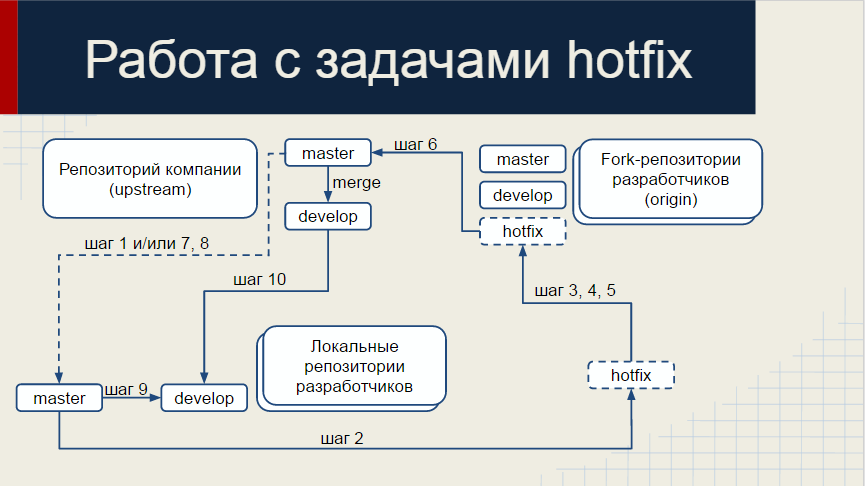
Позитивные стороны
- Подход серьёзно уменьшает количество ошибок и недоделок;
- Только качественные продукты попадут в работающую систему;
- Такая разработка сводит с ума "быдло-кодеров";
- Основные процедуры по обновлению можно планировать;
- Всегда можно заглянуть в fork разработчика и вместе навалится на противную задачу;
- Не нужно никого ждать, что кто-то захватил объект в хранилище, каждый работает со своей конфигурацией;
- Всегда быть в курсе изменений используя интеграцию bitbucketgithub с slackhipchat (статья про slack).
Негативные стороны
- Сложность внедрения. Без сторонней помощи тяжеловато, как выход вливаться в тусовку или посещать тематические мероприятия;
- Как минимум должен быть выстроен правильный процесс разработки (мы используем agile, чуток о нашем процессе);
- Придется потратится на SSD для каждого разработчика, "Выгрузить конфигурацию в файлы…" не столь быстро работает как бы хотелось;
- Конфликты объединения бывают, придется планировать разработку и разделение на task’s, например, формамодуль объектамодуль менеджерамодуль команды и т. п. (У нас задач много, последний конфликт был около 2-х месяцев назад)
Вначале упомянул Redmine, так вот, если при commit добавлять "#номер задачи" (из трекера) и настроить интеграцию с bitbucketgithub — можно будет прямо из задачи (на трекере) видеть изменения, какие были сделаны для ее решения. Вот несколько скриншотов. К сожалению, все описать детальней нет времени и сил, но начало положено. Надеюсь после статьи в наших рядах появится больше новых людей с новыми идеями.
Related Posts
 Оценка и планирование проекта
Оценка и планирование проекта Мысли о видах информационных систем…
Мысли о видах информационных систем… Конфигурация "Выдача пропусков и учет рабочего времени"
Конфигурация "Выдача пропусков и учет рабочего времени" Управление ИТ-проектами. Модуль 3: продвинутый курс по гибкому управлению проектами. Agile. Первый поток. Вебинары проходят с 11 сентября по 27 ноября 2026 г.
Управление ИТ-проектами. Модуль 3: продвинутый курс по гибкому управлению проектами. Agile. Первый поток. Вебинары проходят с 11 сентября по 27 ноября 2026 г. Загрузка/Выгрузка Excel для справочника "Графики работы сотрудников"
Загрузка/Выгрузка Excel для справочника "Графики работы сотрудников" Онлайн-курсы по управлению ИТ-проектами от Марии Темчиной
Онлайн-курсы по управлению ИТ-проектами от Марии Темчиной
А у себя хостить можно?
(1) Armando, да конечно, например или . На самом деле вариантов очень много
Я использую scm manager с соотвествущим плагином
(2) Ок понял.
Разбор на тексты корректно работает?
А то когда я последний раз коммитил в xUnit что-то сломалось в репо из-за этого. Артур не помню как потом починил.
А вообще я все тоже поглядываю в эту сторону.
Только от хранилища уходить пока не хочу.
Можно же настроить, чтоб хранилище по ночам разбиралось и коммиты делались от имени того кто поместил в хранилище?
А вы хранилище совсем не используете? Как макеты и формы тогда сравниваете?
Опечатка в терминологии push request. Надо pull
(4) Armando, xUnit работает сейчас без проблем, главное не забывать обновлять precommit1C. Да, есть люди что разбирают хранилище, настроить можно с помощью Jenkins. Мы ушли от хранилища очень давно, какой там прогресс мне точно не известно.
Хранилище не используем совсем. Управляемые формы это xml’ки, с макетами СКД еще можно разобраться. Ревью других макетов заложено в тесты, проверка хеша макета по ТЗ (по наперед заданным данным) с тем хешем, что выдает база.
В прикреплении пример формы справочника — ВидыЗапасов
off: (4) Armando, на конференции, я так понял не был. Подсказка работаешь с собранным cf и при этом подглядываешь какие объекты automerge прошли, а в каких конфликты обнаружились.
А почему именно GIT а не SVN? Собственное SVN-хранилище разворачивается легко, есть и в интернете. По простоте использования, как мне кажется, SVN выигрывает.
(8) Pasha1st, SVN централизованная система, git же распределенная. Хотел бы посмотреть как выстроить работу с фрилансерами на базе SVN.
Как при такой схеме выглядит типовой сценарий разработчика?
Когда выполнена какая-то работа. Что делает разработчик? Вручную делает выгрузку конфигурации в файлы в определенный каталог. Потом пул реквест. Так? В репо при этом попадут только измененные файлы?
Как выглядят действия других разработчиков при этом, чтоб свою конфигурацию проапдейтить с учетом коммита первого?
Когда разработчик делает форк, в его локальный репо копируются файлы. Он потом просто делает загрузить конфигурацию из файлов? Или еще что-то надо?
У вас эти действия автоматизированы?
(10) Armando,
Git определит файлы, которые нужно закомитить.
Если задачи никак не связаны между собой, обновлять не нужно. Обновление нужно сделать, когда приступаешь к новой задаче . Если задачи взаимосвязаны, достаточно обновить ветку (master или develop в зависимости от типа задачи разработчика) и сделать merge в ветку задачи (featurehotfix), далее загрузить файлы в конфигурацию (если есть конфликты разрешить их).
Достаточно загрузить файлы в конфигурацию и обновить конфигурацию базы данных.
Автоматизированы пока операции в Git (хороший пример (3)), некоторые операции автоматизированы с помощью Jenkins, полной автоматизации достигнуть не удастся, пока не будет исправлена ошибка в платформе 1С (Код ошибки 30010599)
(11) понял спасибо.
Сейчас попробовал нашу конфигу выгрузить в файлы. Обычные формы в виде бинарников выгружает(
Но мы через 4 месяца на бух 3.0 клиента переводим.
Да, и ошибка «При загрузке конфигурации из XML из командной строки неверно загружаются роли.» ставит крест на автоматизации некоторых операций(
У нас например при каждом коммите в хранилище, автоматом стартует стандартная проверка конфигурации (проверка целостности, некорректных ссылок и пр.). Это отдельная база, которая обновляется из хранилища.
И ночью из хранилища готовится файл поставки (это тоже отдельная база), которым обновляется рабочая база.
Вы это вручную делаете? Или у вас другой процесс?
(12) Armando,
Да есть такое, их нужно дополнительно разбирать. ( занимается вроде разбором обычных конфигураций).
И ночью из хранилища готовится файл поставки (это тоже отдельная база), которым обновляется рабочая база.
Вы это вручную делаете? Или у вас другой процесс?
Ну это уже CI к данной статье отношения не имеет. Работаем над похожим процессом с помощью Jenkins, только у нас планируемая реализация pull request -> code review -> build -> test -> принятие в репозиторий. 1 раз в неделю develop -> master -> build -> test -> отправка изменений в боевую базу.
У вас загрузка из файлов корректно работает?
Сейчас выгрузил конфиг в файлы, загрузил в новую базу. Сохранил cf. Сравниваю с базой откуда вначале файлы выгрузил.
Показывает туеву хучу изменений. Роли, макеты, предопределенные данные, формы…
Вы с этим не сталкивались?
Конечно, за реализацию респект и огромный, только возникает вопрос: «А оно действительно нужно?» Я просмотрел на тезисы «Чего действительно ..» и у меня возникает мысль, что Вы не совсем представляете картину происходящего. Поверьте, Вы создали классный продукт, почет Вам и уважуха, только, Ваш скромный слуга, имеет опыт работы на 2 крупных производственных предприятиях г. Нижний Новгород и, ИМХО, Ваша система контроля не совсем будет востребована. Учитывая уровень зп, текучку кадров, уровень персонала (да чего греха таить, и свой тоже!), такое не осилит ни один 1с-отдел. Да дело даже не в сложности — дело во времени! Реальная тех.поддержка — это постоянная занятость, никто не будет выделять время, освобождать от текучки, чтобы ..
«комментирование построчно кода с оповещением человека, который пытается поместить изменения.»
🙂 Эта строка улыбнула! Нет, я в хорошем смысле, только это так наивно звучит!
//
Много можно рассказать и подискутировать о трудовых буднях, об ответственности, об остановке конвейера на 2 часа и штраф в 10 млн. руб. и т.п., дело то не в этом. Как я понял, Вы изначально закладываетесь на работоспособность самой платформы, а она, увы, с ошибками! Может быть уже тут мина?
Я все к чему веду: да, разработка звучит круто, но только в лаборатории, реальность поглотит и оставит её пылиться в столах (что еще хорошо, может потеряться и никто ничего не вспомнит)!
//
p.s.
Желаю успешного развития! 🙂
(13)
Я не про CI. Я про то что базу для этого надо предварительно загрузить из файлов. А загрузка работает некорректно. И долго(
(15) DoctorRoza, то что 90% одинесников работают по хардкору без тестов, проверок, баг-трекера, и прочих нужных вещей, не говорит о том, что остальным 10% этого не надо. Я например страдаю от того, что в типовом хранилище нет резветвленной разработки, нет пул реквестов и нет комментирования отдельных его строк, нет связи с баг-трекером. Форма 1С конечно предложила свою технологию разветвленной разработки, но лучше об этом не говорить.
Трудно сказать. Но если никто не понимает зачем они это делают, то тогда и смысла в этом нет. Только хуже станет.
Но если все эти операции бдут максимально автоматизированы, то внедрение пройдет гладко. И использовать это не напряжно будет.
Я например себе это как представляю: разработчик запустил скрипт, который автоматом сделал форк, создал базу, загрузил в нее файлы, все там обновил, и открыл конфигуратор разработчику.
Когда все сделано разработчик запускает другой скрипт, который выгрузит файлы куда надо, и отправит пул реквест. Разработчику только описание внести надо.
(15) DoctorRoza, мы наверное из разных вселенных. Уровень программистов у нас выше среднего, текучки кадров из отдела разработки 1С за 5 лет равна 0. Тех. поддержка у нас отдельный отдел, программисты тех. поддержкой не занимаются.
На pull request бывает в среднем 3-5 замечаний и естественно отправка на доработку. Прием готовой задачи занимает от 10 до 20 минут.
Я все к чему веду: да, разработка звучит круто, но только в лаборатории, реальность поглотит и оставит её пылиться в столах
Все зависит от руководителя внедрять или не внедрять. По нашему опыту эффективность и скорость разработки увеличилась, количество ошибок уменьшилось в разы. От ошибок никто не застрахован, но пока удается с ними бороться.
Кстати, можно же скрестить использование хранилища с git`ом.
Например, у каждого разработчика скриптом вместе с форком и базой создается хранилище. Он работает по привычному для себя сценарию: захватывает объекты, помещает в хранилище, пишет при этом коммент. А когда делает пул реквест, то комменты из его хранилища служат описанием пул реквеста.
pbazeliuk, pumbaE по вашему опыту возможна такая схема? Со стороны 1С я пока не вижу особых проблем.
(16) Armando, ошибка проявилась. У нас она не проявляется при разработке, потому что пока используется *.cf из build-сервера (так быстрее сравниваетсяобъединяется).
(20)
Не понимать. Поясни что это значит. Я наверное еще далек от этого.
(16) Armando, выгрузка работает стабильно, но вот загрузка нет. У нас сейчас по сути в репозитории храниться разобранная конфигурация, но изменения берутся с build-сервера.
(21) Armando, есть центральная база для разработки в которую заливаются все изменения с помощью сравнения cf, от туда уже идет разбор конфигурации и pull request. По сути мы были в шаге от внедрения сборки из файлов, но пока оставим так как есть.
Но для внешних обработок и отчетов это работает с помощью precommit1C.
(21) Armando, build-сервер место где собирается конфигурация для дальнейшей прогонки тестов или доставки конфигурации в боевую базу.
(21) Armando, вот build est-сервер
(23) вот это ваще меняет дело. У меня щас что-то в голове перевернулось. То есть разработчик сначала в своей базе наделал делов. После этого надо сохранить cf, смержить его с какой-то другой базой, и только оттуда уже делать пул реквест? То есть из гита вы ничего не собираете? Он у вас только для реквестов, и быстрого доступа к версиям? Как у вас разветвленная разработка тогда ведется? Тоже все сводится к тому, что надо вручную совокуплять cf?
(25) спасибо поковыряюсь. Про Jenkins слышал от pumbaE но так и не пощупал его.
(26) Armando, дело в том что 90% разработок благодаря (информация устарела, но для понимания подхода сойдет) у нас внешние обработкивнешние отчеты, с ними работа проще и быстрее. Так же храним бинарники рядом, но можно собрать назад из файлов.
Написал, что были в шаге от перехода на чистые файлы конфигурации, но тут такая засада выяснилась и теперь пришло понимание почему у нас ошибки не проявлялись, как только 1С исправит ошибку загрузки все будет согласно статье.
(28) все ясно. У нас немного другой подход. Мы почти не используем внешние отчеты/обработки. У нас все в базе.
Подожду когда выгрузка/загрузка не будет приводить к изменениям. Тогда можно будет вернуться к вопросу. Спасибо что все разъяснил.
pbazeliuk, какой git-клиент Вы использовали — суровую консоль или TortoiseGit? У нас внедрение контроля версий (не для 1С) даже не началось без графического клиента (сначала был TortoiseSvn — потом некоторые для себя использовали TortoiseHg). А с консолью — очень сильно сопротивлялись.
(19) Armando, у каждого свое хранилище, каждое хранилище синхронизируется с git, для pull request берем cf из хранилища и объединяем с develop веткой, одновременно делаем merge в git и смотрим в два окошка конфигуратор и черепаху где есть конфликты и где нет конфликтов и можно спокойно объединять — у меня так.
p.s. учти, тесты нужны для понимания — а правильно ли ты все смержил и не помешал ли совершенно левый код(в теории и не должен, но всяко бывает) на правильность работы программы.
(30) zlolik, почему это консоль суровая, сделал необходимые alias’ы и уже проще. Ох, уже программисты пошли, графический клиент подавай)
Использовали вначале TortoiseGit, но когда квалификация выросла полностью перешли в консоль.
(31) pumbaE, спасибо за информацию. Что-то мне эти пляски пока не нравятся. Кроме меня никто этим заниматься не будет, а мне тоже не очень хочется. Для начала буду пробовать автоматный разбор хранилища и коммиты в гит. Для быстрого доступа к версиям удобно будет. Может по ходу еще что-нибудь рожу. Ну и ждать, когда типовая загрузка из файлов корректно работать будет.
(33) Armando, маленький вопросик — как часто сохраняешь cf файл, с недоделанным функционалом, который еще нельзя выпускать в релиз, но при этом надо срочно подправить некую ошибку и для этого приходиться отменять изменения, а потом через неделю возвращаешься к этому cf и мучительно пытаешься вспомнить, а что-же там было такого?
(34) pumbaE, у нас ни разу такого не было, чтоб пришлось что-то откатить, а потом обратно возвращать. Такое может случиться только при длительной разработке. А длительные разработки у нас в отдельных базах ведутся, которые не привязаны к основному хранилищу.
(35) Armando, ок, а как потом объединяете отдельную базу с основным хранилищем, как определяете, что этот объект необходимо взять из хранилища, этот из базы, а этот реально конфликтует и в хранилище и в базе его изменяли… ?
(36) pumbaE, у нас технология близка к той, что предлагает 1С. Разработчик должен свою базу обновить до состояния основного хранилища. В этот момент конфликты и разруливаются. Было и по два раза делали, когда первая итерация затянулась. После этого из базы разработчика сохраняется cf и объединяется с основным хранилищем. На этом этапе конфликтов уже не бывает.
(37) Armando,
так вот кому нужен git 🙂 и его merge.
У меня конфигурация в виде файлов весит почти 3 гб, стандартное хранилище умирает на таких объёмах (а это, между прочим, почти типовая УП 2.0). Исследую альтернативные подходы, в том числе хорошо зарекомендовавший себя на других проектах git. В ходе исследования обнаружил, что в некоторых случаях 1С выгружает одни и те же объекты «нестабильно»:
В xml файлах форм при разных выгрузках можно встретить в одном и том же месте, например, следующие два варианта тега ExtendedTooltip:
<ExtendedTooltip name=»КоличествоРасширеннаяПодсказка» id=»31″/>
<ExtendedTooltip name=»КоличествоExtendedTooltip» id=»31″/>
подобных проблем с внезапной локализацией-делокализацией я встретил массу.
Файлы html справки иногда также выгружаются со спонтанными изменениями. То порядок атрибутов в тегах отличается, то в заголовке версия MSHTML не та.
Всё это ведёт к куче ложных изменений при коммите в git, что не есть хорошо.
Также следует отметить, что повторно собрав из файлов конфигурацию, стоящую на поддержке с возможностью изменения, можно столкнуться с ложными отличиями при сравнении с конфигурацией поставщика. Например, у меня вываливаются в различия почти все картинки, некоторые шаблоны. Причём визуально я различий не вижу. Видимо что-то теряется при выгрузке-загрузке.
Как Вы оценивайте сроки по переходу на данную технология для команды из 10-15 человек? Нужно их обучить, консультировать первое время.
Как Вы оценивайте период освоения нового сотрудника с данной технологией? К Вам, наверное , приходят люди со стороны, как быстро они втягиваются?
(39) mcarrowd,
встречал такое только при обновлении платформы, на последней версии уже давно такого не было.
тоже пару раз видел, но вот посмотрел только что свои выгрузки, за последний месяц ни разу не менялись теги в html по истории.
У них еще опечатки бывают в наименованиях тегов.
Есть проблема с mxl отчетами, для себя написал простой скрипт, который смотрит на изменения в mxl по сравнению с предыдущим и если там в одном единственном теге идет изменение uuid, тогда эти изменения отменяю.
(38) pumbaE, да толку от него при текущем раскладе не так много(
Я то думал, что можно полностью отказаться от объединения cf с какой-то еще базой (билд-сервер).
(40) vladsol, самое сложное донести разработчикам зачем это нужно. Обучить нужно базовым вещам это не сложно, для 10-15 разработчиков 1 день за глаза (80% практики) и иметь для базовых вещей презентации. Так же все зависит от процесса разработки, который используется (waterflow, agile, kanban).
1 день достаточно для этого, но у нас есть еще правилашаблоныпроцессы с ними до недели и в процессе работы есть фичи к которым доступ будет получен через 3, 6, 12 месяцев (на самом деле все зависит от скила разработчика и его обучаемости).
Это точно. Мы пришли к простому способу — показываем как делаются два-три коммита, а потом — визуальный дифф. От такой демонстрации проникался каждый.
После этого давали сделать сотруднику тренировочный коммит и давали рекомендации — сделал что-то законченное сроком не более одного рабочего дня — закоммить и комментарий внятный сделай. Не успеваешь сделать за день или два — коммить то, что есть, описывай в вольном стиле «пробовал вот так, тормозит».
Позднее, когда сами разработчики начнут лазить в историю — они сами захотят какие-то теги в коммитах, ссылки на issue из багтрекинга. Тогда более сложные правила для коммитов можно ввести.
А уж когда пообвыкнутся работать с интегратором (а еще лучше когда сами по очереди его функции повыполняют), тогда и правилашаблоныпроцессы прекрасно держатся в голове.
(43) «самое сложное донести разработчикам зачем это нужно»
Самое сложное донести разработчикам платформы 1С зачем это нужно и чтобы они доработали стандартное Хоронилище в 1С 🙂
(43)
Не секрет что это за фичи?
(45) ZLENKO.PRO, давайте не будем холиварить, они все равно не услышат, бывает иногда трудно научить с хранилищем работать «программистов 1с» со стажем и с короной на голове.
p.s. а если и услышат, все равно будут скорей для эклипса это делать.
(46) Armando, как пример, у нас есть стандарт модульного подключения функционала к документам, механизм сложный и не привычный. Добавляется 1 вызов при старте документа в котором рисуется и подключается новый функционал. В нашем случае это учет серийных номеров, управление логистикой, управление затратами, бонусная система ну и другие.
(48) ясно. Я сначала подумал, что речь про инструментарий разработчика. Типа снегопат через 3 месяца дадим, через 6 скрипты к нему)))
(49) Armando, у нас TurboConf, к снегопату пока приглядываемся 🙂
Тут главное четко определять, что такое объект, над которым работают. Распределенная работа подразумевает, что можно спуститься вплоть до функций и строк. Как если бы в 1С можно было захватывать только одну строку :).
А работу интегратора всё-равно никто не отменял. Один поменял один объект, второй поменял другой объект — а вместе они не работают. Вот вам и конфликт. А если есть git или hg, да еще и сборка из исходников работает — то вот оно полное счастье, откатывайся на любой момент.
(51) Sardukar,
оставайтесь в мире, когда код дискетками переносили. Какой контроль и командная разработка может быть, если у вас нет взаимозаменяемости, если разработчик не может экспериментировать, не может недоделанный функционал отложить и потом через время вернуться к этому коду? Еще давайте про общие модули вспомним и правку их несколькими разработчиками или у вас ОбщегоНазначенияВаси, ОбщегоНазначенияПетя?
(51) Sardukar, «У хранилища от 1С есть конечно пока слабые стороны, в частности трекинга не хватает, но будем надеяться — поборят.»
Надеяться не будем. Не поборят 🙁
(47) pumbaE, «будут скорей для эклипса это делать.»
Странный «ход» со стороны 1С с Эклипсом… впрочем я уже ничему не удивляюсь после Такси.
(2) (3) Посоветуйте подходящий сервер под Windows. Чтоб с кирилицей проблем не было ну и прочее. Тот же Stash, например, пробовали?
(56) Armando,
(57) pumbaE, спасибо, все получилось. Только в веб-морде кириллицу не отображает почему-то. Не знаешь как лечить?
В SourceTree кириллицу нормально видно. И время на час вперед в вебе.
(58) Armando, все працює
(59) pumbaE, там где ты показал у меня тож все нормально оказывается.
А что у тебя по ссылке? см картинку
(60) Armando, форк.
(61) pumbaE, а в поле Message видно кириллицу или как у меня на скрине вопросы?
(62) Armando, в стандартном интерфейсе gitweb кирилцу не видно.
(63) pumbaE, ок понял спасбио
(62) Armando, а если на linux поднято, то все красиво видно.
(65) pumbaE, ну линукса тут нет нигде) Для меня это не критично. Вряд ли я туда смотреть буду. Но если вдруг тебе подвернется решение проблемы, то свистни, пожалуйста)
Может быть я пока не осознал всех преимуществ, или масштаб проблем, решаемых мной не разросся до требуемого уровня, но для меня использование такого инструмента остается сомнительным по нескольким причинам:
1. Необходимо время/люди для поддержания инструмента в рабочем состоянии.
2. Сомнительна возможность использования в «закрытых» предприятиях
3. Возможность «отката» к одной из ранних версий — не понятно насколько это просто.
Может видео бы какое-нибудь?
(67) утюгчеловек, когда нужен код-ревью — тогда дополнительно к Git (локально установленного у каждого), используется описанное в статье веб-решение, и только тогда действительно потребуется какое-то количество время/люди для поддержания инструмента.
А вот просто использование Git или Mercurial (особенно в Tortoise варианте) очень хорошо идёт даже для программистов-одиночек. Самая первая функция, которую им показывают — просмотр изменений (сделанных какое-то время назад, и конечно уже забытых) — всем очень нравится 🙂
Мы даже иногда передавали пачки изменений (mercurial bundle) друг другу без обращения в центральный репозиторий, что было особенно удобно, когда он был недоступен.
Эх как все это хочется попробовать но не скем и негде
Не дорос еще
Разработка и сопровождение персонально исполняю
Работа без команды
Как это все может пригодится одицэшнику-одиночке?
Спсб
(69) CheBurator, почему не может пригодиться одинцэшнику-одиночке?
Долгоиграющие доработки выделяй в отдельную «фичу» и тогда у тебя не будет в конфе мусора, который вроде как и сделан, но еще люди точно не подтвердили, что так и будет, а могут вообще на 2 месяца отложить и потом забыть. (Сейчас поди, добавил заготовки в метаданные, а потом лень удалять и т.д.).
Как ты мне показывал, у тебя есть задачки, которые и по полгода могут длиться и потом таки не завершиться, неужели потихоньку добавляешь в конфигурацию, добавляешь заглушки, а потом удаляешь или оставляешь?
Легче проводить code-review иногда можешь сам глянуть на изменения и ужаснуться «неужели это я делал, ай».
Легче становиться понимать, а это уже работает в базе(было ли обновление в базе) или нет? (Пусть в системе задач и стоит пометка, что сделано и обновлено, но вот все равно бывает смотришь и думаешь, а какая-же версия сейчас в базе используется).
Более организовано начинаешь подходить к обновлениям, посмотрел список изменений из твоей разработки по отношению к базе (не просто измененные объекты, а еще и историю, например, за неделю с комментариями) и уже проще и легче сказать пользователям и окончательно в системе задач перевести статус с «реализовано» в «работает».
p.s.: обращайся, ты же вроде был на ?
Читаю, думаю
(66) Armando, посмотри на
(72) pumbaE, спасибо посмотрю
(53) pumbaE, я так понимаю это решение не работает для .cf 8.2 ? или что-то можно сделать ? меня интересует одновременная разработка общего модуля пети и васи с мержами текста
(75) eugeу iezheludkov, у меня 8.2 стоит для разработки.
(76) pumbaE, а как вы распаковываете .cf и снова его собираете ? из исходников ? чем ?
попробую правильно задать вопрос:
возможно существует пошаговая инструкция как все это работает (сам процесс)? имеется ли возможность merge на конфигурацию .cf 8.2 и как и как это настроить и реализовать на практике ?
Пс: посмотрел ролик по экспериментировал: получается что с гит может работать лишь файловая версия 1С, иначе как понять что .cf пора выгружать в пакетном режиме, как отловить событие что конфа изменилась или в прекоммите всегда её выгружать-распаковывать независимо от изменений ? а при мерже её снова компилить и обратно заливать в пакетном режиме ?
Добавьте пож. в README на git
—-
1. При использовании SourceTree в настройках надо указывать встроенного Git клиента (Windows 8.1)
2. Перед всеми манипуляциями Необходимо войти в БД 1С и исправить режим запуска на обычное приложение
—-
без этого система не срабатывает!
Интересно бы посмотреть статистику среди дев компаний 1С, сколько из них делают ревю кода, и на какой процент коммитов?
Понимаю, это функция разбора .wav файла на слова, но не делать же ревю на печать документа «Счет на оплату».
Насколько сильно качество упадет без ревю такого механизма? 1С не настолько сложный.
А без ревю и смысл гита отпадает.
Единственный плюс для меня — это бранчи и интеграция с редмайном.
Было бы круто, если б разработчики 1С что-то подобное сделали в хранилище (возможно как-то расширения задействовать можно?) и какой-то веб хук для slack, jira или в том же духе.
И, даже не представляю, как ревю может спасти от критической ошибки, что упадет софт.
ИМХО: Тестирование-наше все. А грузить в тест свежую конфу из хранилище, самое оно.
(79) ineshyk, просмотр кода нужен, если:
Git в первую очередь нужен чтобы ответить, что еще осталось сделать по спринту, что изменилось с кодом после реализации задачи, какие фичи попадут в релиз.
Тестами все невозможно покрыть. Тесты дополняют ревью, обычно перед просмотром кода происходит тестирование.
А по поводу «1С не настолько сложный» — с этим могу согласится только в случае разработки печатных форм, модулей проведения и прочего. Вся сложность начинает появляется, когда необходимо обновлять кодовую базу без обновления конфигурации, изменение вида форм с минимальным изменением конфигурации или нужно создать документ программно (особенность УТ11, что-то не заполнишь и документ с большой вероятностью сделает не верные движения. Вот и приходится создавать целые проверочные модули (паттерн Proxy)).
Добрый день.
Подскажите, можно ли как-то на Bitbucket настроить, чтобы показывало разницу между коммитами, но с учетом Процедур/Функций.
Если на Bitbucket нельзя тогда есть ли какие-то программы для этого?
(81) вопрос закрываю программа KDiff3 подошла.
(11) было бы неплохо вынести этот коммент в шапку, есть разработчики, которые не очень понимают «как оно без хранилища» (например я). А тут как раз по делу написано
(76) получаю ошибку при сборке файла внешней обработки:
C:Userslarin_aa>oscript C:OneScript-1.0.15libpackage-loader.os —compile C:
РаботаsrcЗ Н ИЗНИ RFC-163146 Работа отчета БДДС10 ах_ОтчетБДДС1 C:Usersla
rin_aaDesktopУдалить —recursive
{Модуль C:OneScript-1.0.15libpackage-loader.os / Ошибка в строке: 34 / Неизве
стный символ: ДобавитьКласс}
C:Userslarin_aa>oscript C:OneScript-1.0.15libpackage-loader.os
{Модуль C:OneScript-1.0.15libpackage-loader.os / Ошибка в строке: 34 / Неизве
стный символ: ДобавитьКласс}
подскажите, пожалуйста, что делаю не так?
(84) вам лучше задать этот вопрос разработчику OneScript. У себя использую стандартный из 1С:Предприятия разбор обработокотчетов и конфигурации (версия платформы 8.3.8).
(85) спасибо, Пётр, не знал, что для внешних уже тоже работает разбор в xml
Бросилось в глаза: нижний слайд понадобиться
Стоит перед выпуском в печать загонять в проверку, извините уж за въедливость.
(87) исправил и еще несколько других.