
Нормализация БД – просто и доступно.
Вместо предисловия.
Поводом к написанию данной статьи послужил тот факт, что несмотря на то, что мы уже давно живем в 21 веке, тема нормализации отношений БД в публичных источниках до сих пор не раскрыта. Если обратиться к википедии, то становится ясно, что ничего не ясно. Не проясняет ситуацию ни яндекс, ни гугл. Данный вакуум понимания/не понимания был обнаружен случайно. Однажды, в процессе общения на ИС выяснилось, что посоветовать прочесть собеседнику, что-нить адекватное на эту тему не удалось. К тому же выяснилось, что различные источники трактуют нормальные формы по своему. В свое время, в 1998 году мне повезло познакомиться со школой «Третьякова Сергея Робертовича» и его концепцией третьей нормальной формы. С тех пор я искренне считал, что вопрос закрыт.
Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости.
Нормализация и проектирование
Проектирование баз данных, как правило, играет одну из ключевых ролей в большинстве проектов. Грамотно спроектированная база позволяет без особых проблем вносить изменения, изменять структуру системы.
Цели нормализации:
- Исключение некоторых типов избыточности. Избыточность данных приводит к непродуктивному расходованию свободного места на диске и затрудняет обслуживание баз данных.
- Устранение некоторых аномалий обновления. Например, если данные, хранящиеся в нескольких местах, потребуется изменить, в них придется внести одни и те же изменения во всех этих местах. Несогласованность информации в базе данных — это настоящий кошмар, который почти всегда приводит к возникновению ошибок. Если вы забудете хотя бы об одной таблице, которую нужно обновить, то все данные станут не достоверными.
- Устранение некоторых аномалий выборки. Например, если данные, хранящиеся в нескольких местах, потребуется выбрать, то выборка одних и тех же данных из разных источников может дать различные результаты.
- Упрощение процедуры применения необходимых ограничений целостности. Отношения, определенные с помощью первичных и внешних ключей позволяют организовать СУБД автоматический контроль согласованности данных, в том числе позволяют реализовать каскадное обновление связанных по внешнему ключу полей в соответствующих таблицах. Разработка проекта базы данных, который является достаточно «качественным» представлением реального мира, интуитивно понятен и может служить хорошей основой для последующего расширения;
Нормализация как таковая не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение физического объёма базы данных. Однако качественная модель, разработанная на основе принципов нормализации ведет к уменьшению физического объема базы данных и обеспечивает приемлемый уровень производительности.
Зачем нужны принципы нормализации?
- Целостная система принципов нормализации позволяет различным разработчикам получать на выходе идентичные схемы баз данных, при условии, что на вход они получили идентичные задания. То есть реализуется принцип единообразия.
- Появляется возможность автоматизировать процесс анализа результата проектирования для выявления рекомендаций, замечаний и грубых ошибок.
- В условиях неопределенности нормализация позволяет создавать системы с широкими потенциальными возможностями для последующего развития. В ходе эволюционных модернизаций любая система рискует оказаться в тупике, преодолеть, который можно только революционным путем. Приверженность принципам нормализация позволяет развивать систему без серьезных потрясений и накладных затрат на радикальные изменения структуры.
- Нормализованная структура базы данных поддерживает целостность данных на уровне структуры.
- Оптимальная структура базы данных обеспечивает максимальную производительность системы, сочетая простоту и функциональность.
- Принципы нормализации создают основу для общения между архитекторами системы и разработчиками, разработчиками и заказчиками приложений.
- Осознание принципов позволяет выявить скрытые проблемы в уже работающих системах и помогает принять взвешенные решения для устранения недостатков.
Существует несколько правил нормализации баз данных. Каждое правило называется «нормальной формой». Если выполняется первое правило, говорят, что база данных представлена в «первой нормальной форме». Если выполняются два первых правила, считается, что база данных представлена во «второй нормальной форме» Если выполняются три первых правила, считается, что база данных представлена в «третьей нормальной форме». Есть и другие уровни нормализации, однако для большинства приложений достаточно нормализовать базы данных до третьей нормальной формы.
Как таковые первая и вторая нормальные формы не являются целью оптимизации – это промежуточные этапы для приведения схемы базы данных к третьей нормальной форме. В то время как первая и вторая нормальные формы позволяют реализовать схему базы данных различным набором связанных таблиц. Строгая третья нормальная форма предполагает только один вариант решения задачи проектирования схемы базы данных. с заданной функциональностью. Таким образом, различные программисты одну и туже задачу решают одним и тем же способом, что в значительной мере облегчает коммуникации между разработчиками и архитекторами. К тому же, единообразие позволяет проверять качество проектирования схемы баз данных с помощью автоматизированных средств разработки.
В дальнейшем для решения задач производительности или обеспечения простоты может быть проведена денормализация схемы базы данных. Опытный разработчик баз данных такую денормализацию выполняет на лету в своей голове, однако для этого нужен достаточно большой опыт практического применения принципов нормализации в течении нескольких лет. К сожалению, принципы проектирования 1С не соответствуют принципам проектирования по третьей нормальной форме. Для приобретения навыков проектирования можно взять базу данных mySQL и реализовать на её базе несколько web-приложений.
Пример ошибок нормализации
Не будем далеко ходить. Для примера возьмем наш горячо любимый Инфостарт, с которым вечно, что-то не так. Давайте обратим внимание на показатели рейтинга. В один и то же момент времени они показывают разные значение: 179, 183. Как такое может быть? Отчет очень простой — данные об одном и том же атрибуте хранятся в трех различных местах. Можно себе представить, что твориться внутри, если снаружи основной ключевой показатель выглядит таким образом?
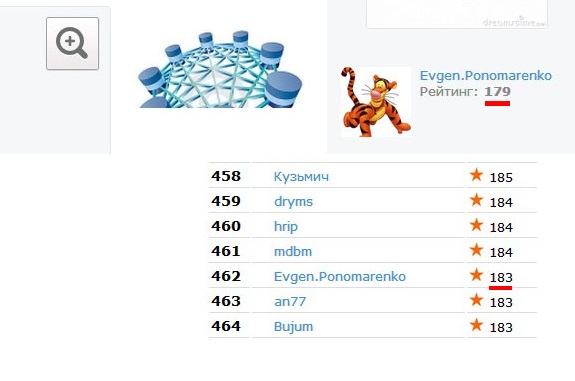
С одной стороны понятно стремление Доржи идти вперед. Но с другой — как можно заниматься редизайном без реинжениринга? Может быть сначала стоило провести рефакторинг базы данных, не трогая визуализации? Да, это затратно и с точки зрения пользователей — бессмысленно. Но может быть стоит хотя бы начать? Понятно, что все уже устали и тех. поддержка в том числе. Но без порядка — нет развития, проект все время будет упираться в «неожиданные» трудности. Но это моё личное мнение.
Продолжим…
Первая нормальная форма
Первая нормальная форма относится только к одной таблице.
Таблица находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты.
Первая и главная нормальная форма требует от таблицы (а точнее, от ее проектировщика) следования следующим правилам:
- Каждый столбец в строке должен быть атомарным, т.е. столбец может содержать одно и только одно значение для заданной строки.
- Каждая строка в таблице обязана содержать одинаковое количество столбцов
- Каждый столбец в строке должен быть строго типизирован
- Каждая строка должна иметь независимый первичный ключ. Нельзя использовать в роли первичного ключа атрибуты внешнего мира, такие как табельный номер сотрудника, наименование города и т.д. Первичный ключ – это номер цифровой последовательности
Первичный ключ — один или несколько столбцов, уникально идентифицирующих строку в таблице. Значения в столбце, объявленном как первичный ключ, не может дублироваться в нескольких строках. Колонку первичного ключа обозначаем префиксом «PK»
Не стоит использовать для первичного ключа комбинацию столбцов, используйте только генератор последовательностей СУБД – и будет вам Счастье.
Вторая нормальная форма
Вторая нормальная форма относится только к двум таблицам.
- Таблицы должна соответствовать первой нормальной форме.
- Определите главную таблицу по правилам отношения «один ко многим»,
- В зависимой таблице добавьте внешний ключ.
Внешний ключ — один или более столбцов в таблице, значения которых соответствуют значениям некоторых столбцов в другой таблице (как правило, ее первичным ключам). Внешние ключи нужно стараться использовать везде и всегда, когда между двумя таблицами существует взаимосвязь. Технически, современные системы поддерживают автоматический контроль ссылочной целостности при использовании внешних ключей. Колонку внешнего ключа обозначаем префиксом «FK»
Третья нормальная форма
Третья нормальная форма относится ко всем таблицам задачи в комплексе. Анализируемые таблицы не должны содержать избыточную информацию в не ключевых полях. Все таблицы должны быть связаны между совой по принципу «один ко многим»
- Таблицы должны соответствовать второй нормальной форме.
- В зависимой таблице внешний ключ должен быть not null.
- Все поля стремятся быть not null
- Избавиться от избыточной информации, содержащейся в не ключевых столбцах. Другими словами не ключевая информация должна храниться только в одной таблице в одном поле
Если содержимое группы полей может относиться более чем к одной записи в таблице, подумайте о том, не поместить ли эти поля в отдельную таблицу.
Связь между таблицами «один к одному»
В связи «один к одному» строке таблицы А может сопоставляться только одна строка таблицы Б и наоборот. Связь «один к одному» создается, если для обоих связанных ключей определены ограничения первичного ключа и уникальности.
Этот тип связи обычно не используется, так как большую часть связанных таким образом данных можно хранить в одной таблице. Связь «один к одному» можно использовать для следующих целей:
- Изоляция части таблицы из соображений безопасности.
- Хранение кратковременных данных, которые можно легко удалить вместе со всей таблицей.
- Хранения данных, которые относятся только к части основной таблицы.
Само по себе использование связи один к одному есть нарушение требований к третьей нормальной форме и может применяться как средство осознанной денормализации для решения задач оптимизации технических проблем.
Связь между таблицами «один ко многим»
Связь «один ко многим» — единственно возможная в рамках требований третьей нормальной формы. В этом типе связей у строки таблицы А может быть несколько совпадающих строк таблицы Б, но каждой строке таблицы Б может соответствовать только одна строка из таблицы А. С логической точки зрения возможны два случая:
Случай первый:
Таблица А – это справочник; Таблица Б – это таблица фактов. Внешний неуникальный ключ из таблицы Б ссылается на первичный ключ таблицы А.
Случай второй:
Таблица А – это главная таблица; Таблица Б – это зависимая таблица. Внешний не уникальный ключ из таблицы Б ссылается на первичный ключ таблицы А.
Однако с физической точки зрения выглядит это одинаково: Несколько строк из таблицы Б ссылаются на одну строку таблицу А. К тому же внешний ключ таблицы Б не может быть null.
Это главное правило определяющее направление внешней связи.
Связь между таблицами «многие ко многим»
В связи «многие ко многим» строке таблицы А может сопоставляться несколько строк таблицы Б, и наоборот. Наличие такой связи в системе таблиц говорит об ошибках проектирования.
Такие связи устраняются либо путем определения третьей таблицы, которая называется таблицей соединения, первичный ключ которой состоит из внешних ключей А и Б, либо пересмотром всех отношений связанных таблиц.
Пример нормализации
| Для начала возьмем следующие данные: |
| ФИО | Табельный номер | Паспортные данные | Город проживания | Дети сотрудника |
| Иванов Е. Г. | 00001 | ВМ 045345 | Харьков | Иванова Татьяна 13.06.2009 Иванов Михаил 20/03/10 |
|
Петрова Елена Николаевна |
00002 | ТК 45645 | Харьков | Наталья Федоровна |
| Хлебникова Ольга Александровна | 00003 | 567897 | Москва |
Первая нормальная форма
|
Для первой нормальной формы таблица примет вид: Таблица: «Сотрудники» |
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | Город проживания | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | Харьков | 13.06.2009 | Иванова | Татьяна | |
| 2 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | Харьков | 20.03.2010 | Иванов | Михаил | |
| 3 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | Харьков | Наталья | Федоровна | ||
| 4 | Хлебникова | Ольга | Александровна | 00003 | 567897 | Москва |
- В качестве первичного ключа выбрано поле «Ид», источником для которого является штатный генератор последовательности СУБД.
- Колонка ФИО разбита на три атомарных колонки «Фамилия», «Имя», «Отчество». Это позволяет контролировать заполненность полей, убирать пробелы, задавать алгоритм буквицы, формировать сокращения с помощью простых штатных средств SQL.
- Табельный номер сотрудника не используется в качестве первичного ключа, так как он относится к атрибуту внешнего мира и может со временем измениться, что может привести к массивным каскадным обновлениям.
- Дата рождения ребенка определена типом колонки «дата», что ведет к однозначности интерпретации данных
Вторая нормальная форма
|
Для второй нормальной формы таблицы примут вид: |
Таблица «Сотрудники»
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | FK_Город проживания | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 13.06.2009 | Иванова | Татьяна | |
| 2 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 20.03.2010 | Иванов | Михаил | |
| 3 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | 101 | Наталья | Федоровна | ||
| 4 | Хлебникова | Ольга | Александровна | 00003 | 567897 | 102 |
Таблица «Города»
| PK_ИД | Город |
| 101 | Харьков |
| 102 | Москва |
| 103 | Житомир |
- В качестве первичного ключа выбрано поле «Ид», источником для которого является штатный генератор последовательности СУБД.
- В таблице «Сотрудники» появился внешний ключ «FK_Город проживания». В данном колонке могут быть использованы только значения из таблицы «Города»: 101,102,103. В данном примере используются только Ид Харькова и Москвы.
Третья нормальная форма
|
Таблица «Сотрудники» имеет следующие недостатки |
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | FK_Город проживания | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 13.06.2009 | Иванова | Татьяна | |
|
2 |
Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 | 20.03.2010 | Иванов | Михаил | |
| 3 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | 101 | Наталья | Федоровна | ||
| 4 | Хлебникова | Ольга | Александровна | 00003 | 567897 | 102 | null | null | null | null |
- В строках 1,2 дублируются не ключевые поля
- В строке 4 данные о ребенке остаются не заполненными по причине того, что у данного сотрудника нет ни одного ребенка. Отсутствующая серия паспорта в строке 4 говорит о возможной неполноте данных, отсутствие данных о наличие ребенка носит объективный характер.
Таким образом таблицу сотрудники можно разбить на две таблицы «Сотрудники» и «ДетиСотрудников» итого получаем:
Таблица «Города»
| PK_ИД | Город |
| 101 | Харьков |
| 102 | Москва |
| 103 | Житомир |
Таблица «Сотрудники»
| PK_ИД | Фамилия | Имя | Отчество | Табельный номер | Серия паспорта | Номер паспорта | FK_Город проживания |
| 1 | Иванов | Егор | Григорьевич | 00001 | ВМ | 045345 | 101 |
| 2 | Петрова | Елена | Николаевна | 00002 | ТК | 45645 | 101 |
| 3 | Хлебникова | Ольга | Александровна | 00003 | null | 567897 | 102 |
Таблица «ДетиСотрудников»
| PK_ИД | FK_ИД Сотрудника | Дата рождения ребенка | Фамилия ребенка | Имя Ребенка | Отчество Ребенка |
|
1001 |
1 |
13.06.2009 | Иванова | Татьяна | null |
| 1002 | 1 | 20.03.2010 | Иванов | Михаил | null |
| 1003 | 2 | null | null | Наталья | Федоровна |
- Добавляем Внешний ключ «FK_ИД Сотрудника» типа «один ко многим».
- Для сотрудника с табельным номером 00003 строка в таблице «ДетиСотрудников» полностью отсутствует.
- Остальные не заполненные поля отражают лишь неполноту данных по ребенку сотрудника. Данное поле можно запретить вводить пустым, и тогда наши таблицы будут соответствовать строгой третьей нормальной форме. А можно «смягчить» данное требование. Оно нам было нужно только во время нормализации структуры базы данных. Ограничение на полному данных можно перенести из задач СУБД в задачи приложения.
Нормализация с точки зрения 1С
С точки зрения нормализации в 1С этот процесс выглядит довольно «прозрачно». Программисты интуитивно принимают следующие решения: Таблица «Города» реализуется как справочник «Города», Таблица «Сотрудники» реализуется как справочник «Сотрудники» с реквизитом «Город» типа СправочникСсылка.Города и табличной частью «ДетиСотрудника». В данном случае данный факт можно считать преимуществом 1С, так как процесс разработки скрывает от программиста излишнюю сложность. Если бы не одно большое НО. В табличной части, равно как и в регистре сведений отсутствует первичный ключ. Все бы ничего, но проблемы возникают во время интеграции с реляционными СУБД, в частности при обмене данными с web-сайтом на базе mySQL. Решается проблема с помощью искусственного первичного ключа в табличной части или регистре сведений.
Денормализация с точки зрения 1С
С моей точки зрения большим технологическим прорывом стало появление в 1С регистра накопления. Сама по себе строгая нормальная форма несет в себе порядок в процессе проектирования, но доведенная до абсурда способна тормознуть любой проект своими ограничениями. Во-первых, строгая третья нормальная форма хороша только для статических систем. Для динамических систем, которые меняются во времени, такие ограничения лишают программные комплексы необходимой гибкости. К примеру, в SAP нельзя внести контрагента, пока не заполнишь все обязательные поля, вплоть до телефона директора. Во-вторых, регистр накопления реализует OLAP технологии на уровне платформы, так как регистр накопления имеет измерения, ресурсы и временную ось. Структура регистра накопления позволяет значительно увеличить производительность за счет заранее посчитанных итогов, а штатные средства отчетов позволяют реализовывать принципы drill-down, drill-up в рамках единой среды.
В принципе, регистры накопления и регистры сведений – единственное отличие от третьей нормальной формы.
К сожалению, отсутствие ограничений на уровне платформы дает программисту слишком большую степень свободы и ведет накоплению ошибок проектирования. По этому, на мой взгляд, знать 1С программисту принципы нормализации обязательно. Более того, отсутствие привычки «задумываться о нормализации» во время проектирования приводит к тому, что разработчики умудряются использовать не по назначению справочники, документы и регистры.
Область применения принципов нормализации
В принципе, методика нормализации подходит для объектов справочники и документы. Принципы проектирования регистров выходят за рамки данной статьи. Одно могу сказать точно — наличие в конфигурации свыше 50 регистров накопления свидетельствует об отсутствии концептуальной целостности в частности и об отсутствии модели учета как таковой. К сожалению, а может быть к счастью здесь просто не паханое поле.
Первая нормальная форма, без первичного ключа хорошо подходит для обсуждения и фиксации требований с заказчиков. Обычно заказчик легко идет на обсуждение задач в формате первой нормальной формы, тем более, что экселевская обработка таких данных естественным образом справляется с сортировкой и автофильтрацией.
Третья нормальная форма хороша для общения между архитекторами, консультантами и программистами. По крайней мере, умение читать структуру базы данных и видеть её ограничения позволяет согласовать приемлемое решение с учетом текущего момента.
Чек лист последовательности проектирования базы данных
Для тех, кто ещё только делает первые шаги в проектировании баз данных будет полезна типовая последовательность выполнения работ:
- Определить таблицы объектов
- Определить атомарные поля
- Определить типы полей
- Определить первичные ключи
- Определить внешние ключи
- Определить индексы полей
- Определить уникальность полей
- Определить признаки полей null/not null
- Определить дополнительные ограничений полей
- Выполнить нормализацию до 3-й нормальной формы
- Выполнить денормализацию с учетом ограничений по производительности
Методология IDEF1Х и программный продукт ERWin
|
На основании своего опыта могу сказать, что в моем конкретном случае использование AllFusion Data Model Validator (ERwin Examiner) приведет к сокращению трудозатрат приблизительно на 1000 человеко-часов при перепроектировании и настройке баз данных моей фирмы. Билл Кларк, администратор БД компании FunMail |
В свое время компания Computer Associates в рамках серии продуктов ERwin реализовала стандарт IDEF1X.
IDEF1X является методом для разработки реляционных баз данных и использует условный синтаксис, специально разработанный для построения концептуальной схемы структуры данных предприятия, независимой от конечной реализации базы данных и аппаратной платформы.
Сущность предметной области в IDEF1X описывает собой совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых друг от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности. Таким образом, сущность в IDEF1X описывает конкретный набор экземпляров реального мира, в отличие от сущности в IDEF1, которая представляет собой абстрактный набор информационных отображений реального мира.
Поддержка нормализации в ERWin. ERWin не содержит полного алгоритма нормализации и не может проводить нормализацию автоматически, однако его возможности облегчают создание нормализованной модели данных. В первую очередь ERwin Examiner позволяет провести инспекцию структуры базы данных на предмет соответствия её общепринятым нормам проектирования в автоматическом режиме.
AllFusion Data Model Validator 7.1 (ранее: ERwin Examiner 4.1)
Обработка «СтруктураКонфигурацииIDEF1c.epf»
ERwin examiner позволяет провести анализ модели данных на основе экспертных данных заложенных в программу разработчиками. Не смотря на то, что средства ERwin не могут сказать как нужно делать, они могут сказать как делать не нужно. Использование средств валидации схем баз данных позволяет на собственном опыте решения практических задач впитать лучший опыт разработки.
Методология IDEF1X включает в себя графическое представление отношений между сущностями. Являясь проекцией стандарта IDEF1 на физический уровень баз данных, который позволяет вести как прямую разработку структуры базы данных в терминах конкретной СУБД так и обратный реинжениринг, методология IDEF1X позволяет переносить модели из одной СУБД в другую.
Для целей документирования структуры данных платформы 1С мной была разработана нотация IDEF1c. Простая и очевидная текстовая структура вот уже 5 лет помогает закрывать бреши в технологическом обеспечении платформы 1С. Данный инструмент не претендует на полноту — это скорее попытка начать диалог на эту тему заинтересованных разработчиков.
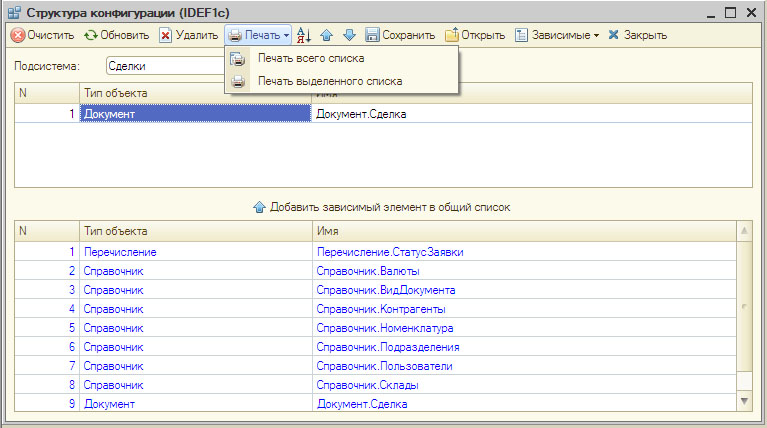
Операции:
- Подсистема — Выбор «подсистемы» для анализа объектов конфигурации. При смене подсистемы, объекты дописываются в конец списка.
- Очистить — Очистить список объектов для последующего добавления объектов конфигурации.
- Обновить — Добавить в конец списка объекты указанной подсистемы.
- Добавить зависимый элемент в общий список — Переместить из нижнего списка зависимых объектов в список объектов конфигурации для дальнейшей печати.
- Удалить — Удалить текущий объект из списка.
- Печать всего списка — Печать всего списка объектов конфигурации.
- Печать выделенного списка — Печать только выбранных элементов из списка объектов
- Сохранить — Сохранить список объектов конфигурации в xml-файле, для последующего использования
- Открыть — Загрузить спискок объектов конфигурации из xml-файла.
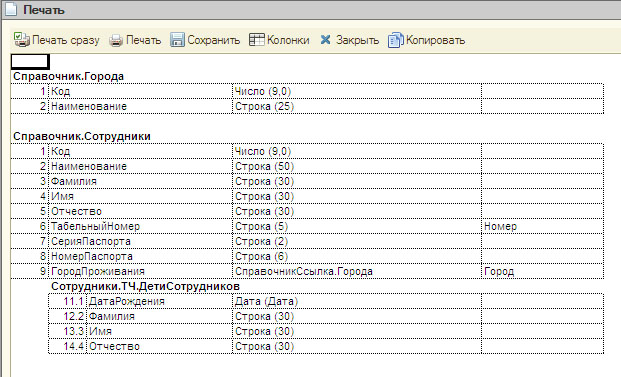
Данная обработка работает в обычной и управляемых формах, версия платформы 8.2.13.219 и выше. Может использоваться как внешняя обработка, что делает её удобным инструментом для исследовальских работ чужих конфигураций.
Related Posts
 Оценка и планирование проекта
Оценка и планирование проекта Мысли о видах информационных систем…
Мысли о видах информационных систем… Конфигурация "Выдача пропусков и учет рабочего времени"
Конфигурация "Выдача пропусков и учет рабочего времени" Управление ИТ-проектами. Модуль 3: продвинутый курс по гибкому управлению проектами. Agile. Первый поток. Вебинары проходят с 11 сентября по 27 ноября 2026 г.
Управление ИТ-проектами. Модуль 3: продвинутый курс по гибкому управлению проектами. Agile. Первый поток. Вебинары проходят с 11 сентября по 27 ноября 2026 г. Загрузка/Выгрузка Excel для справочника "Графики работы сотрудников"
Загрузка/Выгрузка Excel для справочника "Графики работы сотрудников" Онлайн-курсы по управлению ИТ-проектами от Марии Темчиной
Онлайн-курсы по управлению ИТ-проектами от Марии Темчиной
Про инфостарт ты загнул, звездочки и рейтинг никак не связаны друг с другом. Звездочки показывают количество твоих голосов отданных за публикации. А рейтинг рассчитывается сложным образом в зависимости от вида публикации. Это совершенно разные показатели. И прежде чем публиковать такую «туфту» для начала бы надо было проконсультироваться с Доржи или разобраться самому.
(1) Раньше были несоответствия с рейтингами, подтверждаю. Сейчас пофиксили вроде бы.
(1) fishca,
Может и перегнул… но на то были причины
1) Мои обращения в тех. поддержу
Тикет #5263 Очень странно обновляется статья после редактирования
Тикет #5262 Ошибка рейтинга
Остались без реакции.
Я и не собирался публиковать этот обзац… но реально ДОСТАЛО! Давно не публиковался…но столько ГЛЮКОВ уже реально вывело из себя…
Скажем так, повод был выбран специально, чтобы обратить внимание Дорджи на ситуацию.
2)
Я не исключаю сложность, но в данном случае, я просто наблюдаю глючность… время от времени эти показатели, показывают одно и то же значение… потом разбегаются… потом снова показывают одно и то же. Замечено, что полный пересчет происходит после добавления новой статьи. Тогда показатели начинают совпадать. Не знаю… это мои личные наблюдения.
Мне в общем-то все равно, какой у меня рейтинг +/- 10 единиц не имеют значения. Мне важен сам принцип надежной разработки приложений.
3) Вот скажите, вы можете описать каким образом расчитываются эти показатели?
И привести алгоритм по которому можно оценить достоверность ваших доводов?
(2) Diversus,
Не… не пофиксили ))) После публикации данной статьи рейтинги из обоих источников синхронизировались… похоже на то, что рейтинги пересчитывают после публикации новой статьи. Это моя личная версия. Со временем показатели снова начнут «разбегаться» пока не будет опубликована новая статья.
(4) еще раз повторюсь это разные показатели
звездочки — это сколько раз ты проголосовал за публикации
рейтинг — это сколько раз за тебя проголосовали
разница на лице, не вижу предмета для обсуждения.
(5) fishca,
о звездочках речь уже не идет… (это была моя опечатка… ну глюканул яяяя)
речь идет о том, что один тот же рейтинг в различных источниках показывает разные значения…
хех… вообще речь в статье шла о сооооовсем другом ))) о системном подходе, системах моделирования аналогичным ErWin стандарте проектирования IDEF1х и обработке СтруктураКонфигурацииIDEF1c.epf, которая позволяет печать структуру конфигурации.
Статья великолепная. Хотя и отличается от классики (Дейт, например).
Но мне показался спорным один момент:
«Первичный ключ не должен относиться к внешнему миру».
Если для табельного номера это абсолютно верно, то например для ИНН, мне кажется, уже неверно. Или, скажем, для отпечатка пальца 🙂 Такие уникальные характеристики из внешнего мира могут и, наверное, должны использоваться как первичный ключ. Это дополнительная гарантия верности данных, ускорение их обработки и уменьшение накладных расходов на хранение.
(7) marsohod, использовать ли естественный (Natural) или искусственный (суррогатный, Surrogate) первичный ключ — тут мнения расходятся. 1С выбрали искусственный первичный ключ (UUID) для объектных таблиц (справочники, документы), и естественный составной для регистров, таб.частей(?). (Преимущество UUID перед автоинкрементным очевидно для каждого, кто обменами данных занимался.) Из вашего же примера — ИНН может быть одинаковым для нескольких (подразделений) организаций — у них КПП разное, ИНН и КПП могут менятся со временем в связи с изменением законодательства или ещё чего. Так что искусственный ПК более универсален.
(7) marsohod,
Очень меткий комментарий! Сразу видно, что человек в теме.
О да! Если говорить о классиках, то стоит упомянуть Кодда, Дейта, Брукса.
Если работы Теслы позволили совершить так называемый второй этап промышленной революции,
то эти люди заложили фундамент для третей.
Поверьте, если бы мое виденье не отличалось в данном случае от представлений Дейта,
я бы не тратил свое личное время. Дейт был математиком и способ подачи материала соответствует.
Я бы сказал, что мое виденье более популярное и расширяет его работы в сторону «упрощения».
Меня познакомили с этой практикой ещё 20 лет назад. Она основана на принципах Дейта,
но уже включает в себя опыт практиков. Просто для оптимизации структуры выбраны более простые
и надежные целевые функции.
«Первичный ключ не должен относиться к внешнему миру».
В самую точку! До 98 года я даже об этом не задумывался ))) Зато сталкивался с проблемой, что рано или поздно
при изменении ТЗ программу нужно переписывать заново. Скажем так, на тот момент времени я гордился, что мои программы выдерживали в среднем до 5-ти серьезных смены ТЗ. И в основном это касалось не верно выбранного первичного ключа.
К сожалению, зачастую нам приходится автоматизировать «неопределенности» которые могут казаться на первый взгляд полностью «детерминированными». Но Мир и наши Представления о нем могут меняться…
Так, что для создания информационных систем которые могут эволюционировать без серьезных потрясений, стоит всегда использовать внутренний идентификатор. Причем, если система изначально построена на таких ключах, производительность только выигрывает. Плохо, когда часть ключей «естественные» а часть «суррогатные».
По поводу объема хранимых данных — тут не стоит заморачиваться… сейчас технический прогресс успевает за потребностями.А вот если искажать структуру данных для решения чисто технологических задач, то мы рискуем создать программу-однодневку.
А в остальном, огромное спасибо за коммент, он позволил глубже раскрыть тему! )
(8) zqzq,
100-пудово ))) UUID — это большой шаг вперед, но если бы 1С внедрило его в табличные части и регистры сведений не было бы повода писать такие статьи.
(10) Глубоко внутри, может, у них и есть свои UUIDы. Хоть на уровне СУБД. Ведь и «УникальныйИдентификатор» далеко не сразу вытащили хотя бы в частичную доступность. Авось, однажды и мы до них из встроенного языка да из запросов дотянемся…
Статья хорошая, умная, только ненужная 95% одинэсников. Ибо есть программисты, архитекторы, разработчики, а есть 1С-ники… Которые не то что нормализацией заниматься не будут, а даже про индексы впервые слышат и хардкодят любую конкретику в исходниках и даже в свойствах сущностей. Увы.
(11) Yashazz,
Полностью согласен… Статья для архитекторов. Кодеры, скорее всего, столкнуться с траблами во время интеграции с другими системами. НО Я не мог её не опубликовать, я не мог идти дальше… было ощущение внутренней пустоты. Есть принцип концептуальной целостности, он предполагал именно такую последовательность изложений статей. У меня в черновиках лежат еще 6… теперь можно с чистой совестью продолжить. Честно говоря мне очень радует, что на ИС есть люди которые не только 1С-ят )))
(0) Класс. Мало стоящего на инфостарте стало публиковаться последнее время… Еще бы перечислить минусы нормализации…
(13) awk,
Мне трудно говорить о минусах нормализации…
это скорее процесс эволюции перехода от хаоса к нормализации, от нормализации к денормализации.
Я бы говорил о плюсах денормализации, как осознанных шагов после нормализации.
И все же, если говорить об ограничениях, то:
1.Нормальные формы больше подходят к статике, чем к динамике.
2.Нормальные формы имеют большее количество таблиц, что создает иллюзию сложности.
3.Чрезмерное увлечение ограничениями NOT NULL ухудшает юзабельность приложения.
4.Принцип «одна сущность — одна основная таблица» ограничивает универсальность решения.
Ну, а в остальном… главное — это обойтись без фанатизма.
Нормальные формы — это всего лишь еще одна полезная модель.
Автору спасибо за статью.
Когда читал про нормализацию в книге Пола Нильсена «Microsoft SQL Server 2005. Библия пользователя» то все было понятно, но как только закончилась глава — так и забылось. Считаю из-за отсутствия практики, а в 1С грамотный программист на автомате будет правильно разрабатывать схему. Но это не значит, имхо, что программист 1С не обязан помнить об этом. Особенно когда основной стала клиент-серверная версия программ 1С.
(15) Famza,
Если говорить о Микрософте, то популярно нормальные формы они объясняют здесь:
Но человек устроен так, что познание происходит через практику…
Я то же с трудом вспоминал, когда-то давным давно усвоенные принципы.
Но это как на велосипеде: нужно один раз научиться ездить — тогда не забудешь )))
(10) в том-то и дело, что, например, для независимого непериодического регистра сведений UUID — что для собаки пятая нога. Статья по теме не из мира 1С
Насколько мне известно, нормализация используется только в стенах образовательных учреждений… В промышленных БД сплошь и рядом денормализация. У фирмы 1С даже есть рекомендация по самодостаточности регистров.
(17) zqzq,
Согласен, что в 95% случаях — это пятая нога, но вот здесь бы она мне пригодилась
Универсальный обмен между похожими конфигурациями
Ее отсутствие привело к тому, что я на тестирование механизма обмена регистров сведений потратил столько же
времени, как на тестирование всех других объектов 1С вместе взятых. Имхо — композитный ключ очень капризная штука )))
В свое время я участвовал в разработке генератора кода PL/SQL под ORACLE. Принцип был следующий: Сначала схема БД разрабатывалась
в ERwine, потом генерировался ею код DDL SQL. А наш генератор формировал код PL/SQL из DDL SQL,
что позволило сократить время разработки на треть. Дополнительно генерировались DDL SQL для исторических,
теневых таблиц вместе с кодом PL/SQL. Это стало возможно благодаря отказу композитных ключей. В дальнейшем я не раз сталкивался с побочными проблемами их использования, в том числе с проблемами производительности и синхронизации данных.
Так, что я их не использую принципиально, НОоооо ключ уникальности по копмозитному ключу — это святое дело.
В один 1С все в точности наоборот — в регистре сведений данные могут схлопнуться и бесследно исчезнуть в неизвестном направлении.
Я согласен, статья на об 1С… но кто сказал, что мы не можем творить историю?
(18) puzakov,
Это базовый курс
Это для продвинутых
Не верьте ))) у меня 80% рекомендаций 1С вызывают сомнения, а учебные курсы от 1С вызывают фатальный когнитивный диссонанс.
Хотя… регистры 1С действительно самодостаточны… а регистры накопления — это технологический прорыв ))))
Просто нужно слушать свой разум ))))
Третья нормальная форма? Как же, помню: курсовая, третий курс. То же мне откровение.
(21) Азбука Морзе,
))) Небось лабы препод проверял или все таки пользовались ERwin Examiner? 😉
В принципе статья получилась многоцелевая. К ней идет обработка, которая помогает документировать структуры 1С. Простая вещь, но очень полезная…
Написано всё правильно 🙂
Знать Правила нормализации это самое важное для любого программиста !
мелкие замечания:
1) «не должны содержать избыточную информацию…» — это в 1ом правиле, а не в 3ем
2) «Первичный ключ..» — это 2ое правильно, а не 1ое
3) «В зависимой таблице добавьте внешний ключ..» — это 3ее правило, а не 2ое
4) «..по принципу «один ко многим»» — это больше относится к 4ому правилу: запрещается связь многие ко многим
5) UUID в 1с не первичный ключ т.к. не может обеспечивать полную функциональную зависимость, в т.ч. нельзя использовать в запросах и др.
Код справочника тоже не первичный ключ т.к. может повторяться почему-то в 1С 8.2.
В регистрах составной ключ тоже не подходит т.к. нарушает второе правильно нормализации о том что запрещается иметь незаполненные значения в составном первичном ключе.
В 1С нет первичного ключа совсем нигде 🙁
(23) ManyakRus,
Ваша наблюдательность делает Вам честь )))
я скорее всего имел ввиду, что это справедливо и для 1-й и для 3-й форм, причем для всех связанных таблиц одновременно.
3) «В зависимой таблице добавьте внешний ключ..» — это 3ее правило, а не 2ое
4) «..по принципу «один ко многим»» — это больше относится к 4ому правилу: запрещается связь многие ко многим
В классике так и есть ))) я намеренно поменял местами операции, так как они отражают последовательность практических действий. В принципе, в целях нормализации смысл имеет только третья нормальная форма, сами по себе промежуточные 1-я и 2-я пользы приносят мало. А учитывая, что 3-я форма включает в себя 2-ю и 1-ю, суть от перестановки не меняется.
(23) ManyakRus,
Немного не понял…
предлагаю обратиться к
Если wiki©:«GUID» называют некоторые реализации стандарта, имеющего название Universally Unique Identifier (UUID).
Тогда ССЫЛКИ в 1С могут играть/играют роль первичных ключей и могут использоваться/используются в запросах…
(24)
..»суть от перестановки не меняется»
Как раз суть и меняется. Без правильной нумерации невозможно будет кратко сказать что именно неправильно типа «нарушение первого правила нормализации» а придётся долго объяснять что это такое тем кто не знает и не хочет ничего знать.
(26) ManyakRus,
))) та как скажите…
Статья не для тех кто не хочет знать, а для тех кто набил шишки )))
Насильно учить — зря тратить время.
Подсознательные фильтры восприятия делают свое дело.
Если не дошло — значит субъект еще не созрел 😉
Время все расставит все по своим местам. Может лет через 5 вспомнит ваши или мои слова…
и подумает!!! Таки да!!!
Или еще лучше — решит, что это он сам все придумал ))))))
Не знаю, как в «педии», а в ВУЗ-ах на профильных специальностях ещё в первой половине 90-х за нормализацию «ответку держали» 🙂
(28) wolfsoft,
На самом деле качество «ответки» очень зависит от преподавательского состава конкретного вуза.
К тому же не каждый выпускник профильного факультета работает программистом, и не каждый программист
имеет профильную специальность.
А по поводу «педии» — я с вами согласен на все 100%
Это так… чисто для «навигации», не более того.
В принципе, когда с sql/delphi переходил на 1с, то меня тоже мучил этот вопрос. Сейчас делаю так: если в 1с надо контролировать уникальность ключа на уровне платформы, то я использую регистры сведений (непериодический, независимый), где измерения (обязательно notnull) — части ключа (на сколько помню, PK может быть составным), а реквизиты— данные. И тогда при попытке записи одинакового набора измерений система выдаст ошибку. Ничего более подходящего я не нашел 🙂
(30) idhas,
Как вариант… Правда, если форма получает сообщение об ошибке от платформы, её не по-детски клинит )))
Я обычно проверяю в событии формы ПередЗаписью. Так помягче получается: и сообщение можно внятное выдать и курсор в поле перекинуть легче.
Отличная статья. Сейчас осознал что еще с института НФ въелись в сознание как татуировка в кожу (преподам отдельное спасибо). Но как любую татуху нужно подновлять, так что автору респект.
Вот только не нужно забывать, что есть программисты 1С, которые кроме 1С больше нигде не программировали… Для них здесь будет не все понятно.
(32) wunderland,
В 10-ку!!! Я надеюсь, что узким 1С специалистам будет хороший повод задуматься на тему расширения своего кругозора )))
Я отношусь к тем, кто «денормализацию выполняет на лету в своей голове» (цитата из статьи).
Наверно поэтому заметил несоответствие в данной статье.
В описании третьей нормальной формы автор пишет:
В описании связи один к одному:
Эти два утверждения противоречат:
(из описания связи один к одному). Я считаю, что никакого нарушения требований к третьей нормальной форме здесь нет.
Несколько абсурдный (с точки зрения реальных потребностей), но тем не менее вполне адекватный пример:
Допустим, нам для каких-то целей надо хранить информацию о документе заключения действующего в настоящий момент брака (дата, город, номер, наличие и параметры брачного договора, …). Поскольку многоженство у нас запрещено, то супруг(а) может быть только в единственном числе, либо не быть вообще. Следовательно, такой документ либо есть, либо его нет.
Если хранить информацию о документе в основной таблице — то это будет нарушением
(для тех, у кого документа заключения брака нет — все поля описания будут null).
Здесь хорошо поможет
— для сотрудника, у которого такой документ есть, в таблице описания документов будет одна (!) запись соответствия записи в таблице сотрудников (связь 1:1). А для сотрудника, у которого нет документа о заключения брака — такой записи в таблице описания документа не будет.
Таких примеров можно привести достаточно много: информация об удалении аппендицита (остальные не интересуют); дачный участок в кооперативе «АБВГД»; информация о выходе на пенсию (дата, последнее место работы, сумма, причина, …); личный рекорд в покорении горных вершин до поступления на работу; …
Просьба к автору прокомментировать данный пост.
(34) FractonKireyev,
Честно, говоря в целом — вы абсолютно правы. Однако я не могу понять, каким образом вам удалось вырвать из контекста мои фразы и скомпилировать такой логичный вывод. По поводу вашего примера, хочу сказать, что он действительно не очень подходящий, хотя и интересный. Во-первых в течении некоторого времени сотрудник мог иметь несколько браков. Во-вторых, в реальной жизни действительно могут быть двоеженцы нарушающие законы, а отразить факт предметной области, при такой реализации схемы БД, у вас вряд ли получится. На самом деле, я больше говорил о тенденциях, чем о жестких правилах. Ибо тогда статья разрослась бы до невиданных размеров.
Однако, если абстрагироваться от примера — вы, еще раз хочу подчеркнуть, вы абсолютно правы. Мало того, такая схема решения очень часто встречается, когда нужно раскрыть некоторые подробности по контрагенту. Мне кажется, у вас в голове находится непротиворечивая модель, которая позволяет вам принимать рациональные решения. Она может немного в деталях отличаться от моей, но в целом, такая же. Я мог неудачно выразиться, либо моя модель наложилась на вашу не очень удачным способом. Но в любом случае, цель моей статьи была достигнута. Во первых, мне удалось выговориться, во вторых, найти единомышлеников, в третьих обозначить тему для классических 1с-ков.
Мне его трудно комментировать. Порой истину передать словами нет возможности, но на истину можно намекнуть. Мне кажется, что наши модели очень похожи, и мне не особо хочется углубляться в детали, чтобы разобраться в отличиях. Однако, если вам оооочень хочется, я могу вам составить компанию. Но тогда мне нужны более детальное описание корректного примера с вашим вариантом решения.
Ибо я не могу поставить себя на ваше место и пытаться анализировать самого себя. Поймите меня правильно.
Вообще странно, что не описана нормализация в рамках регистров накопления. Ведь по сути именно в них «типичный» 1С-ник и решает задачи нормализации. Ведь в зависимости от построения РН, он в рамках непосредственно СУБД может быть и 2, и 3 нормальной форме.
(36) qwinter,
))) Если, говорить о регистрах накопления, то я бы сказал, что это тема касается денормализации в классическом её понимании. Регистры накопления в большей степени соответствуют технологии OLAP, а там действуют свои принципы. В данном случае, я решил вынести обсуждение этой темы за рамки этой статьи. Кроме этого, структура регистров накопления должна отражать учетную модель предприятия. А модель предприятия как объект управления в 1С отсутствует как понятие, как в прочем и в подавляющем числе современных ERP-систем. Так, что перед тем, как пытаться раскрыть эту тему, стоит опубликовать еще как минимум три статьи.
А в целом, ваш вопрос вполне логичный. Я долго ждал: «Кто же его задаст?»
на УФ не запускается !!
получить форму на сервере…
(38) veretennikoff,
а подробнее можете описать ситуацию… чего пишет?
(39) ну я вам указал уже на ошибку «функция ПолучитьФорму() у вас написана на сервере»
ФормаУФ, строка 112
(40) veretennikoff,
Упс… режим запуска следует выбрать «толстый клиент», я понимаю, что это не фонтан, но пока так.
(40) veretennikoff,
Обработку поправил — теперь работает и в режиме «тонкого клиента» управляемой формы.
Интересно, а для целей разработки и автоматизации конфигурацию 1С:Система Разработки Прикладных Решений не пробовали использовать? Просто когда-то в ней проектировал, интересно ваше мнение.
(43) necropunk,
Если вы имеете в виду «Система проектирования прикладных решений» СППР,
то на мой взгляд — это правильное направление движения, но не актуальное.
К тому же 1С:СППР получился громоздким, как с точки зрения конфигурации, так и методики.
Мне больше нравится 3D подход — см. Эрика Эванса «Предметно-ориентированное проектирование (DDD)».
(англ. Domain-driven design)
1С:СППР предполагает конструирование с помощью кирпичиков согласно заранее согласованного проекта.
3D подход предполагает использование готовых унифицированных независимых блоков(шаблонов)
В своих разработках я уже более 5 лет использую «виртуальную машину», которая решает следующие задачи:
Позволяет формировать формы ввода/вывода на лету. Осуществляет мониторинг ВСЕХ действий пользователей и программистов.
Осуществляет взаимодействие между постановщиком/разработчиком/пользователем/администратором проекта в одном флаконе с привязкой к конкретным объектам конфигурации, с возможностью создавать на основе «заявки пользователя» контрольные примеры и FAQ.
«Виртуальная машина» позволяет вести документацию в автоматическом режиме. Согласованное техническое задание ложится в базу и полностью определяет поведение системы. Таким образом реализуется подход «что заказал — то и получил».
К слову сказать 3-е поколение виртуальной машины предполагало 80 тыс кода,а 4-е поколение по прогнозам должно уложиться в 20 тыс.
То есть, наблюдается упрощение внутренней структуры без потери функциональности.
На фоне выше сказаного, 1С:СППР воспринимается мной как доисторическим монстром.
(44) 1С:СППР — без автогенерации конфигурации — мартышкин труд.
(45) awk,
Что ты имеешь ввиду?
(46) думаю, имеется в виду, что при окончании проектировании на уровне метаданных — система должна сама собирать эти метаданные в цельную конфигурацию, с чем я, в общем-то согласен.
(47) necropunk,
Если в этом контексте, то я тоже спорить не буду. Правда возникают вопросы чисто практического значения:
1) В этом случае проект конфигурации на СППР должен проектировать с нуля, либо полностью определять отдельную подсистему либо СППР должна поддерживать функцию реверсинжениринга. В противном случае не получится собрать работоспособную конфигурацию и придется снова вышивать ручками.
2) Я имел в виду другое, в случае с виртуальной машиной, проект является исполняемой структурой. Для актуализации изменений достаточно выйти/войти в прикладной объект.
Реверсинженеринг она поддерживает (ну, там допилить правда немного приходится), а вот собирать она уже не умеет. Ну, не умела, по крайней мере.
Виртуальная машина — хорошо, конечно. У нас примерно так же организовано, но не опишешь в двух словах. Попытался, но понял что пустое все и стер 🙂
В общем, да, СППР — попытка хорошая, но до ума не доведенная, а лучшие решения — собственноручно выстраданные :)))
(49) necropunk,
та…да.
(46) Я работал с этой системой и заметил у нее два ключевых недостатка:
1. Это отсутствие возможности вести несколько проектов.
2. Это отсутствие генерации конфигураций на основе проделанного описания. То есть сначала один вбивает все в СППР, а потом другой тратя то же время вбивает в конфигуратор. То есть все то же самое первый мог сделать в любой другой системе.
(51) awk,
Спасибо за информацию! Честно говоря, особо надежд по поводу СППР не питал, но…
Как же ж так??? (риторически пожимая плечами…) это ж самое вкусное!
Ну и на кой… она такая сдалась? (еще больше округляя глаза)
Нет… теперь точно на досуге поковыряю СППР, что-то ж в ней полезное должно быть?!
(52) У нее есть только одно полезное качество — это первый шаг. Если будет последним то…
Не согласен со следующими моментами:
, при желании можно почитать ответы гугла, на тему «Принципы построения реляционных баз данных», «основы реляционных баз данных» и тд, «там можно вводить разные слова» (с)кто из толпы.
Значит у вас ошибки в проектировании. Если вы пытаетесь обменяться движениями регистра накопления(или любого другого) с вебсайтом. У регистров единственная цель: ускорить и упростить формирование отчетов. Разумеется использование регистров увеличивает время записи документов. И тут чем быстрее тем лучше, поэтому в топку все лишние сущности, так же они не нужны при получении остатковоборотов, отсутствие идентификатора здесь плюс а не минус. При использовании не по назначению, получаем вышеообозначенные траблы.
(54) webester,
Хороший ресурс… качественный, в теории. Но вся проблема заключается в том,
что именно поиск корректных практических примеров реализации третьей нормальной формы оказался безрезультатным.
В данном конкретном случае в вашем источнике налицо вопиющие нарушения принципов 3НФ:
1) в результате нормализации были появиться как минимум пять таблиц, а не две:
Контрагенты
Сотрудники
Города
Должности
ВидыКонтрагентов
2) За связь по полю «Наим.» просто бил бы кривым ручкам.
3) А где первичные и вторичные ключи?
Вообще-то за такие примеры нужно лишать лицензии.
К теоретической части вопросов нет, очень хорошо проработана.
Вывод: Примеры писал либо аспирант, либо преподаватель-теоретик.
Это хорошо видно по его любимой фразе: «Переводя на человеческий язык:» и следующими за ней рекомендациями.
А вообще спасибо за пост — он еще раз подтверждает актуальность темы с одной стороны и тезис «век живи — век учись!» с другой стороны. На самом деле учебники содержат море ошибочных посылов — нужно быть всегда на чеку.
Про регистры сведений: я подозреваю, что при их создании в 1с немного свалили в кучу необходимость уникальности записей по измерениям (просто уникальный ключ) и первичный ключ (который для производительного решения должен быть минимальным, но чтобы его хватало). Так и вышло, что решили все сделать первичным ключом.
Добавлю, что в реальных системах много ненормализованных данных — и это почти всегда погоня за производительностью. База в 3х нормальных формах предполагает, что при запросе данных из нее — все они будут в реальном времени получены и скомпонованы, а эта операция может быть неимоверно долгой, поэтому расчет некоторых промежуточных итогов переносят на другой момент времени (на запись). Система быстрее выбирает данные, но медленнее пишет.
На уровне БД: все дополнительные индексы, кроме первичного — есть создание отдельной таблицы для быстрого поиска и поэтому потеря НФ (дублирование данных).
Любые кэширования данных есть потеря НФ (дублирование данных).
На уровне 1с:
Кроме «странных» ключей регистров сведений и таблиц итогов регистра накопления — есть еще вынос тяжелых данных в отдельные справочники или РС (например, присоединенные файлы в варианте, когда связь один-к-одному) — тоже потеря НФ (сущность расползлась на 2 таблицы).
Еще у меня припоминается реквизит СуммаДокумента — который рассчитывается на основании табличной части. (тоже по сути хранение заранее посчитанных итогов).
За обработку спасибо и «плюс»! Как раз понадобилась для нестандартной задачи,
напугатьпоказать людям, что номенклатура и её настройка для производства это не «два пальца…». А то руководство считает, что оно «разбирается» в ИТ и даже когда-то сисадминило/программировало, поэтому номенклатура в ERP это несложно…непонятно , для кого написана статья . Нормализация входит в курс основы работы с бд
уже лет 20. этот курс читается для всех ит специальностей.
а программистам «от сохи» нормализация вряд ли не нужна.
(56) mixsture,
Это некорректное сравнение — сумма это одна из основных сущностей документа и может не равнятся (если принята другая бизнес логика) посчитанным итогам ТЧ документа.
И является правильным применением «денормализации»
(59) caponid, соглашусь, что сумма документа может не равнятся итогам по ТЧ. Но она все равно вычисляется на основе итогов по ТЧ и другим реквизитам, а значит хранить ее отдельно — это «задваивание информации» => транзитивная зависимость (реквизит зависит от другого реквизита, а должен зависеть только от ключа) => потеря 3 НФ. Разве не так?
(59) caponid,
1ая НФ запрещает не только дублирование информации, но и детерминированные значения, когда одно вычисляется из другого,
поэтому СуммаДокумента нарушает 1НФ
Удивительно наблюдать как статья уже живет своей жизнью, обрастая своими идеями, которые и в голову не приходили. Одно это уже стоило того, чтобы дать ей жизнь.
(57) Puk2,
А еще с её помощью удобно общаться с подчиненными, и также печатать обои на стену, когда схемы объектов уже заняли всю рабочую поверхность стола. (К стати такие обои оказывают потрясающее впечатление как на начальство, так и на пользователей)
(56) mixsture,(59) caponid, (61) ManyakRus,
Зачет! Спасибо всем за диалог.
На самом деле если бы 1С поддерживала конструкцию «CRЕATE VIEW», то нормальность 1С бы значительно повысилась. Не смотря на шаги в верном направлении я бы на месте 1С уже давно встроил «тексты запросов» как объект конфигурации.
(58) МихаилМ, ну например для меня 🙂 или для половины всех существующих 1Сников, тк в основном все мы не имеем ИТ образования. И лично меня тема правильной разработки и проектирования интересует довольно сильно 🙂
(62) За статью спасибо, интересно для начала, но явно недостаточно. Для таких как я, без образования, но с желанием, она указывает верный путь дальнейшего обучения. Вроде бы как раз после первого прочтения этой статьи я полез в книги и видеокурсы, зарегистрировался на sql-ex и стал потихоньку догонять вумных программистов. После второго прочтения — сегодня, в целом стало ещё понятнее.
(63) slazzy,
Всему свое время )) Тем более, что утро вечера мудренее… При том, что обучение процесс последовательный, а целостно-концептуальное озарение/осознание ближе к параллельным процессам.
Рад, что нашему полку — прибыло 😉
(23)
UUID не является первичным ключом только лишь с точки зрения СУБД, однако с точки зрения метаданных 1С это первичный ключ. Правда называется он Ссылка (поле _idrref). А Ссылка на уровне СУБД и есть UUID, который в пользовательском представлении оборачивается Представлением (поле _description) ссылки (ранее только Кодом/Наименованием и т.д., с недавнего времени представление можно определять в модуле менеджера).