
Обмен между конфигурациями с идентичными метаданными
Обмен между конфигурациями с различными метаданными
Обмен между конфигурациями с разными метаданными с использованием XDTO
Введение
Обмен будет работать между двумя конфигурациями на платформе 1С. Он будет иметь следующую логику: из одной базы данных будут выгружаться элементы справочников и документа. Будем называть такую базу Trade (имя только для того, чтобы в дальнейшем различать конфигурации). Далее выгруженные данные будут загружаться в базу данных Accounting. Из Accounting в Trade будет загружаться только документ. Реализация такого обмена будет выполнена за 3 итерации, на каждой будет получен работоспособный обмен данными. Конфигурации можно использовать в других решениях в качестве шаблона.
Обмен между конфигурациями с идентичными метаданными
На первой итерации создадим обмен с отбором между идентичными конфигурациями. В качестве транспорта данных будем использовать файлы.
Создадим новую конфигурацию с именем Trade. В ней создадим роль FullRights, в которой включим флажок Назначать права для новых объектов. Укажем эту роль в качестве основной роли в свойствах конфигурации.
Создадим справочники Companies, Counterparties, Products, в которых все оставим по умолчанию.
Создадим документ SupplierInvoice. Добавим реквизит Company с типом CatalogRef.Companies. Добавим реквизит Counterparty с типом CatalogRef.Counterparties. Добавим табличную часть Inventory с реквизитом Product, тип которого CatalogRef.Products и Quantity с типом Number.
Создадим план обмена с именем NoRull. Изменим длину кода на 40, длину наименования на 50 символов. В состав плана обмена включим справочники Counterparties, Products с включенной авторегистрацией. Для документа SupplierInvoice и справочника Companies отключим авторегистрацию.
Реализуем возможность регистрации данных с учетом отбора. Для этого у плана обмена добавим реквизит Company с типом CatalogRef.Companies. Для каждого узла обмена (узел обмена = элемент плана обмена) данные будут фильтроваться по указанной в узле организации. Создадим подписку на событие OnWrite (ПриЗаписи) для документа и обработчик подписки разместим в общем модуле с взведенным флагом Сервер (не будем учитывать Толстый клиент).
Сниппет обработчика подписки на событие при записи документа:
Функция ExchangeNodesByCompany модуля менеджера плана обмена возвращает массив узлов, организация которых совпадает с переданной в нее организацией. Далее для таких узлов регистрируется изменение документа по ссылке. Создадим аналогичную подписку для справочника Companies.
Для реализуемого варианта обмена создание узлов плана обмена – ручная операция, поэтому в режиме Предприятие в плане обмена зададим код и наименование для текущего узла, а также создадим еще один узел с заполненой организацией. После этого создадим пару организаций, 1 контрагента, пару товаров, несколько приходных накладных.
Проверить объекты, которые зарегистированы к выгрузке, можно с помощью любой консоли запросов. В конструкторе запросов нажимаем на кнопку Отображать таблицы изменений и выбираем данные из нужной таблицы.
Создадим общую форму ExchangeManagement, с помощью которой будем выполнять обмен данными. Добавим реквизит формы ExchangeCatalog с типом Строка и реквизит ExchangeNode с типом ExchangePlanRef.NoRull. Создадим элементы формы для созданных реквизитов. Также добавим команду, которая будет запускать выполнение обмена. Форму разместим на начальной странице приложения.
Подготовительные работы на этом закончены. Перейдем к реализации алгоритмов обмена.
Алгоритм обмена условно можно разделить на следующие пункты:
Импорт данных
- Чтение заголовков файла обмена
- Удаление зарегистрированных объектов для отправителя
- Чтение тела файла обмена
- Фиксация факта обработки данных
Экспорт данных
- Формирование заголовков файла обмена
- Формирование тела файла обмена
- Фиксация факта обработки данных
Данный функционал реализуется за несколько строк кода. В общем модуле создадим экспортную процедуру ExecuteExchange с входящими параметрами Directory и Node, в которые будем передавать значения реквизитов общей формы ExchangeManagement. Процедура ExecuteExchange в свою очередь будет вызывать процедуры ImportData и ExportData с аналогичными входящими параметрами.
Сниппет процедуры ImportData:
Функция GenerateFileName на основнии кодов узлов обмена формирует имя файла обмена с данными для импорта (пример — D:обменот 01 для 02.xml). Ситуация с отсутствующим файлом возможна при первоначальной синхронизции данных. Если же файл существует, то читаем его заголовки, которые имеют следующий вид:
<v8msg:Header>
<v8msg:ExchangePlan>NoRull</v8msg:ExchangePlan>
<v8msg:To>01</v8msg:To>
<v8msg:From>02</v8msg:From>
<v8msg:MessageNo>13</v8msg:MessageNo>
<v8msg:ReceivedNo>33</v8msg:ReceivedNo>
</v8msg:Header>
В заголовке содержится информация об имени плана обмена, кодах узлов и номерах сообщений. Наверное, каждый встречал ошибку при обмене, которая сообщает о том, что номер сообщения меньше или равен принятому. Поэтому для упрощения разрабатываемого алгоритма в метод BeginRead (НачатьЧтение) вторым параметром передадим, что ожидаются данные только с номером сообщения больше принятого. Если заголовки были успешно прочитаны, то это означает, что узел-отправитель успешно принял данные и теперь для него можно удалить все зарегистрированные для выгрузки данные, но номер сообщения которых меньше или равен номеру полученного сообщения (это базовые основы работы планов обмена платформы 1С, подробное описание их работы выходит за рамки данной статьи).
После этого читаем тело сообщения пока это возможно с помощью CanReadXML (ВозможностьЧтенияXML). Так как на данном этапе алгоритм предполагает обмен между конфигурациями с идентичными метаданными, то десериализация и сериализация прикладных объектов возможна с помощью ReadXML (ПрочитатьXML) и WriteXML (ЗаписатьXML) соответственно (методы обходят метаданные сериализуемого объекта и записывают/читают документ xml в точно таком же порядке). Для того, чтобы записываемый объект при обмене не регистрировался для выгрузки, в свойстве DataExchange (ОбменДанными) укажем узел плана обмена, от которого этот объект получен.
После того, как тело сообщения будет прочитано, вызовем метод EndRead (ЗакончитьЧтение), который увеличит номер принятого сообщения в узле обмена.
Сниппет процедуры ExportData:
При выгрузке данных аналогично получим имя файла, в который будут записываться данные. Далее с помощью метода CreateMessageWriter (СоздатьЗаписьСообщения) создадим объект RecordOfMessage, с помощью которого можно будет записать сериализованные данные. Метод BeginWrite (НачатьЗапись) объекта RecordOfMessage, формирует заголовки сообщения и объявляет начало тела сообщения. Далее метод SelectChanges (ВыбратьИзменения) вернет коллекцию ссылок на данные, которые подлежат выгрузке в узел-получатель (RecordOfMessage.Recipient). Далее обходим коллекцию, получаем выгружаемый объект и сериализуем его с помощью WriteXML (ЗаписатьXML). Для корректного завершения процесса выгрузки вызовем метод EndWrite (ЗакончитьЗапись), который сформирует окончание тела сообщения и увеличит номер отправленного сообщения в узле обмена.
Запустим режим Предприятие, укажем каталог обмена, узел-получатель (для которого ранее заполняли организацию) и выполним обмен. Если все сделано правильно, то в каталоге обмена должен появиться документ xml (сообщение обмена), в котором будут данные из базы Trade.
Теперь создадим новую конфигурацию и загрузим в нее ранее созданную конфигурацию Trade. Имя конфигурации зададим как Accounting (только для того, чтобы различать конфигурации). Удалим подписки на события, в плане обмена удалим реквизит Company, отключим авторегистрацию для справочников и включим для документа. Это позволит регистрировать изменения только для документа.
В режиме Предприятие для текущего узла зададим код и наименования точно такие же, как в базе Trade для узла с заполненой организацией. Добавим еще один узел обмена с кодом и наименованием такими же как и в базе Trade для узла с незаполненой организацией.
Выполним обмен данными, указав каталог обмена и выбрав узел обмена, для которого будем выгружать данные (от которого получаем). Если все сделано правильно, то в базу Accounting загрузятся данные из Trade, а в каталоге обмена появится еще один документ xml. В нем будут только заголовки (Headers), в которых будет информация о номере успешно принятого сообщения. Если в Accounting записать документ SupplierInvoice и выполнить обмен, то благодоря тому, что при импорте данных чтение сообщения происходит в попытке/исключение, мы не увидим ошибки о том, что номер сообщения меньше или равен предыдущему, а в сообщении для Trade появится тело сообщения.
Вот так за минут 20 можно создать простейшую систему обмена данными между решениями на платформе 1С. При желании практически весть код методов импорта и экспорта данных можно найти в СП. Но реализованный алгоритм имеет один большой недостаток, который рассмотрим далее.
Обмен между конфигурациями с различными метаданными
На второй итерации реализуем алгоритм обмена данными между конфигурациями с разными метаданными. В качестве транспорта данных будем использовать файлы.
Откроем конфигурацию Trade в режиме Конфигуратор и в документе поменяем порядок реквизитов Company и Counterparty. Затем в режиме Предприятие зарегистрируем документ к выгрузке (достаточно перезаписать документ) и попробуем выполнить обмен. На этапе загрузки файла с данными в Accounting получим ошибку преобразования xml. Вернем порядок реквизитов в Trade, а в Accounting у документа удалим реквизит Company и справочник Companies поскольку в нем нет практического смысла, ведь в Accounting всегда только одна организация. Теперь если из Trade выгрузить документ или элемент справочника Companies, то при попытке загрузки такого файла в Accounting получим уже знакомую ошибку разбора xml. Таким образом мы нашли главный недостаток разработанного ранее алгоритма обмена – метаданные объектов, которые участвуют в обмене, должны быть полностью идентичны (в том числе и порядок реквизитов).
Для решения данной задачи будем использовать постобработку xml. После выгрузки из Trade в документе xml нужно удалить все, что связано с организацией и перед загрузкой в Trade в документе xml добавить организацию для документа. Используем два способа редактирования xml – преобразование документа по шаблону (XSLT) и объектную модель (DOM).
На общей форме управления обменом добавим возможность выбора типа обработки данных xml – DOM или XSLT.
Теперь выгрузим из Trade элемент справочника Companies и документ SupplierInvoice, а потом проанализируем получившийся документ xml. В документе xml нужно удалить два узла — DocumentObject.SupplierInvoice/Company и CatalogObject.Companies. Для начала используем XSLT. В качестве редактора таблицы XSL я использую онлайн инструмент. В итоге должна получиться следующая таблица XSL:
XSLT для удаления тегов, связанных с Company
Сначала указываем, что будем использовать xsl преобразование и указываем имя пространства имен для того, чтобы преобразователь понимал что именно является инструкциями преобразования. Далее указываем, что на выходе ждем xml с определенной кодировкой и отформатированный отступами. Затем определяем "пространство", которое хотим преобразовать — в данном случае весь документ. (каждый узел со всеми его атрибутами). И дальше копируем каждый узел. После этого также определяем "пространство" как реквизит Company документа SupplierInvoice и элемент справочника Companies, но в качестве операторов преобразования ничего не ипользуем, то есть просто удаляем такие узлы.
Сохраним полученную таблицу XSL как макет плана обмена в конфигурации Trade. После метода, который экспоритрует данные, добавим вызов метода, который преобразует сформированный документ xml.
Сниппет функции TransformByXSLT
Используем объект платформы XSLTransform (ПреобразованиеXSL), которому передадим XSL таблицу (переменная Instructions). Далее вызовем метод TransformFromFile (ПреобразоватьИзФайла) и в качестве параметра передадим путь к документу xml, который нужно преобразовать. На выходе получим преобразованный xml документ, который нужно записать под именем FileName.
Реализуем такой же функционал с помощью объектной модели документа xml.
Сниппет функции DomDocumentByFileName
Прежде всего получим DOM документ по имени файла (переменная Path)
Сниппет процедуры TransformXMLByDOMAfterExport
Далее будем использовать XPath (язык запросов к xml). Необходимо найти узел CatalogObject.Companies, который находятся на любом уровне дерева, именно поэтому используем // в поиске. Если такой узел найден, то удаляем его как дочерний узел родительского узла. Аналогично поступим с узлами DocumentObject.SupplierInvoice/Company, которых может быть несколько в документе и именно поэтому удалять такие узлы будем в цикле. Затем обработанный DOM документ необходимо сохранить под именем исходного документа xml.
Обработанный любым из двух способов, документ xml будет успешно загружен в Accounting. Если Вы впервые сталкивваетесь с XSLT и XPath, то рекомендую этот ресурс для изучения.
Остается добавить организацию в документ xml перед загрузкой в Trade. Поскольку в Accounting данные всегда по одной организации, то ИД организации для подстановки в документы можно брать как ИД организации, которая указана в узле отправителе. Для этого разработаем новую таблицу XSL.
XSLT для добавления тега Company в документ
Идея преобразования документа xml в следующем — определяем область, в которой будем что-либо менять — v8msg:Body/DocumentObject.SupplierInvoice/Posted (так как у узла Body есть префикс, то определим в заголовке документа пространство имен как xmlns:v8msg="http://v8.1c.ru/messages). Далее перебираем все узлы в этой области и к узлу Posted добавляем его текущее значение, а также узел Company со значением $CompanyId ($CompanyId заменим через СтрЗаменить на Гуид организации узла обмена). Полученную таблицу используем по аналогии с экспортом данных и преобразованный документ xml сохраним.
Реализуем такой же функционал, но с помощью объектной модели документа xml.
Сниппет функции TransformXMLByDOMBeforeImport
Выбираем все узлы DocumentObject.SupplierInvoice/Counterparty, которые находятся на любом уровне дерева. Обходим коллекцию таких узлов и добавляем новый узел DocumentObject.SupplierInvoice/Company для узла DocumentObject.SupplierInvoice, но перед DocumentObject.SupplierInvoice/Counterparty. Сохраняем обработанный DOM документ.
После этого будет работоспособный двухсторонний обмен. Данный способ сложен в разработке (количество объектов, которые участвуют в обмене, может быть большим) и его довольно тяжело поддерживать.
Обмен между конфигурациями с разными метаданными с использованием XDTO
На третьей итерации переработаем созданный ранее алгоритм. Откажемся от пост обработки документов xml, а в качестве транспорта данных будем использовать http. Инциатором обмена будет всегда выступать один из его участников, то есть можно сказать, что будет Клиент (инициатор) и Сервер (обработчик запросов клиента). Поэтому в качестве Клиента будет выступать Accounting (зададим новое имя конфигурации Client), в роли Сервера будет Trade (новое имя конфигурации Server). При инициации обмена клиентом подготавливается сообщение обмена и вызывается метод веб сервиса сервера, который отвечает за импорт данных. Сообщение обмена обрабатывается сервером и клиент получает результат обработки. Если он успешен, то вызывается метод веб сервиса сервера, который отвечает за экспорт данных. На сервере подготавливается сообщение обмена и отправляется в качестве ответа клиенту. В свою очередь клиент обрабатывает полученное сообщение.
Тело сообщения (узел Body в документе xml) можно использовать как "контейнер" для передачи любой сериализуемой информации. В качестве "шаблона", по которому будем формировать тело, используем XDTO пакет.
В конфигурации Server создадим XDTO пакет с именем пространств имен http://norull.com (имя может быть любым, главное чтобы оно было уникально в рамках проекта). Структура пакета следующая: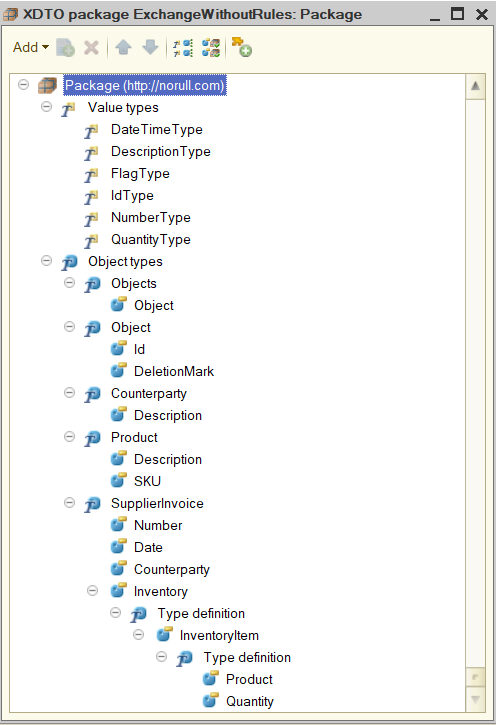
- Типы значений — все возможные типы значений, которые будут встречаться в рамках разрабатываемого пакета. Базовые типы всех значений из пространства имен http://www.w3.org/2001/XMLSchema (необязательно).
- Тип Objects — "родительский контейнер", в который будут помещаться все сериализованные объекты.
- Object — список XDTO с типом Object
- Тип Object — базовый тип для всех остальных сущностей (Counterparty, Product, SupplierInvoice)
- Id — тип IdType
- DeletinoMark — тип FlagType
- Тип Counterparty — базовый тип Object
- Description — тип DescriptionType
- Тип Product — базовый тип Object
- Description — тип DescriptionType
- SKU — тип DescriptionType
- Тип SupplierInvoice — базовый тип Object
- Number — тип NumberType
- Date — тип DateTimeType
- Counterparty — тип IdType
- Inventory — "родительский контейнер", в который будем помещать строки табличной части документа
- InventoryItem — список XDTO
- Product — тип IdType
- Quantity — тип QuantityType
- InventoryItem — список XDTO
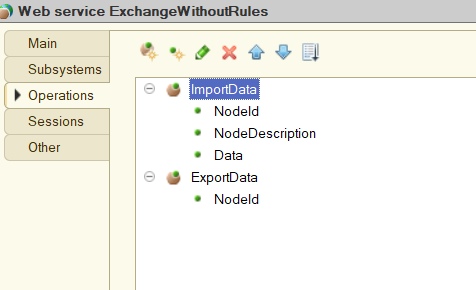
Создадим веб сервис с именем пространств имен http://norull.com и созданным ранее XDTO пакетом. Имя файла публикации зададим как server.ws. Вэб сервис будет обслуживать две операции — импорт и экспорт данных. Обе операции не могут возвращать пустое значение и будут выполняться в транзацкии (соответствующие флажки в свойствах операции). Операция импорта будет иметь 3 входящих параметра — идентификатор узла инициаотора обмена (NodeId, тип IdType), наименование узла отправителя (NodeDescription, тип DescriptionType) и данные для загрузки (Data, тип String). Операция экспорта будет иметь 1 входящий параметр — идентификатор узла инициатора обмена.
Из модуля веб сервиса вызовем функцию общего модуля, в которую передадим в качестве параметров — параметры метода вэб-сервиса.
Сниппет процедуры импорта данных в Trade
Функция FindCreateExchangeNodes модуля менеджера плана обмена проверяет наличие узла обмена с переданным ИД. Если такого нет, то создает его, а также инициализирует текущий узел обмена и устанавливает флаг NeedFullExchange в true. Таким образом в текущем варианте обмена нет необходимости вручную создавать узлы планов обмена. Далее если это новый обмен, то вызывается процедура ObjectsRegistrationForFullExchange, которая по определенной логике регистриует объекты для выгрузки. Затем из параметра Data получаем документ XML (сообщение обмена) и пробуем прочитать заголовки сообщения. Если их прочитать удалось, то удаляем зарегистрированные изменения для узла-отправителя. Далее читаем тело сообщения с помощью метода глобального контекста XDTOFactory.ReadXML (ФабрикаXDTO). Согласно созданному ранее XDTO пакету, все объекты XDTO будут находиться в "контейнере" Objects.Object, который может быть как списоком XDTO (если объектов больше 1) так и объектом XDTO (если объект в списке 1). Поэтому поместим все объекты XDTO в массив, с которым будем работать в дальнейшем. Так как в данном примере известно, что от клиента может прийти только документ, то при переборе массива объектов XDTO по имени объекта определяем тип текущего объекта и если это документ, то вызываем метод FindCreateSupplierInvoice (сниппет метода далее). После перебора всех элементов массива заканчиваем чтение сообщения обмена и возвращаем ответ инициатору обмена.
Сниппет метода FindCreateSupplierInvoice
Рассмотрим сниппет, который преобразует данные XDTO объекта в прикладной объект конфигурации (документ). Сначала пробуем получить ссылку на документ по ИД. Если ссылка существует, то получим объект от этой ссылки, в противном случае создадим новый документ и присвоим ему ссылку, которая пришла по обмену. Далее заполним атрибуты шапки и табличную часть документа, установим свойство Загрузка в истину и запишем документ с учетом пометки удаления. На этом алгоритм импорта данных готов.
Реализуем алгоритм экспорта данных. Из модуля веб сервиса вызовем функцию общего модуля, в которую передадим в качестве параметра — параметр метода веб сервиса.
Сниппет метода экспорта данных из Trade
Данный метод подготавливает список XDTO Objects.Object согласно зарегистрированным изменениям для узла обмена, ссылку на который находим по переданному коду узла. Затем с помощью XDTOFactory.WriteXML (ФабрикаXDTO.ЗаписатьXML) сериализуем подготовленный список и записываем его как тело сообщения. После завершаем запись сообщения обмена и упаковываем сообщение в строку Base64 формата. Отправляем ответ в формате json инициатору.
Реализуем алгоритм вызова веб сервиса со стороны клиента. Для этого в общей форме ExchangeManagement добавим команду, которая будет вызывать метод ExecuteExchange общего модуля, и реквизит формы, в котором будем указывать адрес опубликованной на веб сервере базы сервера.
Сниппет метода ExecuteExchange
Сначала получаем WSPorxy веб сервиса. Далее процедуры экспорта и импорта данных практически такие же как и в Trade, с той разницей, что при экспорте данных вызывается метод веб сервиса ImportData (то есть клиент данные экспортирует, а сервер их импортирует), а при импорте данных вызывается метод веб сервиса ExportData (сервер данные экспоритрует, а клиент импортирует), а также фабрика xdto используется от объекта WSPorxy.
Заключение
Каждый из рассмотренных трех вариантов реализации синхронизации данных хорош для конктертной задачи. Но на практике, как правило, используется 3 вариант (обмен с мобильным устройством или сайтом). Приведенный алгоритм реализации вполне работоспособный, но есть ряд фич, которые могут быть добавлены:
- Обработка сбоев
- Асинхронный обмен
- Кэширование
- Коды доступа приложений (мобильные устройства)
- Перенос данных регистров
- Удаление объектов
- Отложенное проведение документов
- Коллизии при обмене
- Передача и сжатие больших объемов данных
Если материал вызовет достаточный интерес в комьюнити, то сделаю продолжение по вышеозвученным фичам.
В архивах данной публикации можно найти конфигурации всех трех вариантов обмена со всеми формами и методами, код которых не был добавлен в данный материал по причине его объемности.
Третий вариант обмена доступен на github.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Проблема кодирования на английском в том, что правила языка сложнее соблюсти. ExchangePlans.NoRull например следовало бы назвать ExchangePlans.NoRules. Но код на английском действительно приятнее читается (субъективно).
По XSLT в приложении к 1С информации почти нет, а та что есть даёт мало разъяснений или отсылок к документации. Что и почему делается — непонятно. Кстати здесь тоже )) Поэтому продолжение было бы интересно почитать. Только с большим количеством разъяснений что и зачем сделано.
По XDTO тоже хороший пример. Постоянно наблюдаю как для веб-сервисов делают объекты исключительно со строковыми свойствами и укладывают в них невалидируемый JSON зачем-то )) Вместо того чтобы наоборот валидируемый XDTO-объект, если прямо очень нужно, во что-то упаковывать. Лучше уж тогда http-сервис делать. Вроде бы как и JSON можно автоматически валидировать, но не видел примеров для 1С. Было бы классно увидеть больше примеров с разъяснениями.
С другой стороны у Вас входящий пакет данных Data — это строка. То есть данные не валидируются автоматически на входе самим веб-сервисом. Почему бы не передавать непосредственно объект, а не строку, чтобы сохранить возможность автоматической валидации? Ведь всё равно для передачи по транспортному уровню данные сжимаются.
Вот еще например про правильный подход написано
А почему так сделано Вы не сказали. Тоже ведь частая проблема в том, что разработчики всю логику в модуле самого веб-сервиса реализуют.
В общем объяснения примененных приемов надо больше, чтобы не выглядело как «я достаю из шляпы кролика» )) Подпишусь на случай если будет продолжение ))
(1)
у нас на проекте передается объект, но минус в том, что если передать кривой XML, клиент получит 500 ошибку с невнятным сообщением о несоответствии формата пакета. Для строки можно при парсинге выдать сообщение в красивом виде, если есть желание заморочиться, но мы переложили ответственность на клиента — не прислал данные в нормальном виде, сам виноват, читай документацию к формату обмена
Интересно, до какой активности изменения обмениваемых данных планы обмена не создают проблем с блокировками?
(1)
Согласен, но лучше попробовать и ошибиться, чем не пробовать.
По XSLT придется писать самостоятльный материал и может даже не один. На ИС есть несколько статей на эту тему. Помню, что в одной из них хорошо расказанно про пространства имен например. Но, по факту, на практике, я чаще сталкиваюсь с XPath, нежели с XSL.
Любой ОбъектXDTO имеет метод Проверить(). Поэтому проверку валидности можно выполнять на клиенте. А если передавать сам объект, то его не получится сжать.
Про XDTO и его создание можно тоже писать отдельный материал. Там очень много чего можно сделать и документации от 1С особо нет по этому вопросу.
Так делаю потому что в каком-то из релизов отсутствовал синтакс-контроль модулей веб сервисов. Ну и так правильно делать с точки зрения архитектуры приложения (в мире Swift это можно назвать MVC, а здесь не знаю емкого определения. Может быть — стандарты 1С).
А в целом, спасибо за развернутый комментарий ))
(3)Блокировки при обмене — проблема известная. Есть несколько решений. Одно из них от Филиппова Евгения, можете найти на ютубе.
(1)
А как решать проблему согласованного изменения формата, когда у баз разное технологическое окно?
А почему текст на русском, коли такая тяга к английскому?
Описание статьи многообещающее, но разбирать код 1С на английском, крайне неудобно.
(6) Версия формата обмена может решить эту проблему
(7) Пару лет назад я тоже подумать и не мог, что придется писать код 1С на английском, но все меняется и на данный момент код на русском писать запрещено (в рамках моей работы).
(8)
Дублировать веб-сервисы под каждую правку xdto-пакетов? Проходили) заходит только когда формат меняется очень-очень редко.
В активно допиливающихся обменах (каждый релиз) хранить версии в метаданных такое себе решение.
JSON толерантней в этом отношении, особенно когда участников несколько и нужно поддерживать обратную совместимость.
(10) Зачем же дублировать веб сервисы. У веб сервиса добавляете входящий параметр — версия формата обмена. И по нему уже ориентируетесь какой пакет xdto использовать. И обратная совместимость вам гарантированна.
пересилил себя и прочел английский код
уверен, что если бы код был русский было бы 100500 комментов в стиле «УЖЕ БЫЛО!!!!»
а так в статье очень много нового и интересного, но не про обмен, а про англоязычный синтаксис 🙂
«Обмен без правил» — это от лукавого) По сути вы все равно анализируете структуры источника, приемника и определяете, по каким правилам вы будете формировать файл выгрузки и как его потом обрабатывать в приемнике, а XSLT — это и есть аналог правил обмена. Никогда, конечно, не доводилось работать с XSLT, поэтому трудно оценить, будет ли легче написать обмен между конфигурациями, особенно когда типы объектов источника и приемника не совпадают. Для обмена со сторонними системами всегда было достаточно нормальной XSD и использования XDTO
(6)
Под валидацией входящего XDTO объекта имел ввиду проверку на соответствие WSDL / XSD схеме. Либо автоматически веб-сервисом, либо методом Проверить() объекта XDTO.
Это проверка на то, соответствуют ли свойства объекта заданным типам, не передается ли массив объектов там где разрешен только один объект, соблюден ли порядок полей. В общем все те преимущества, что даёт типизация.
ЧтениеJSON ведь проверяет только правильно ли скобки, запятые и кавычки расставлены. А проверка на соответствие типам и «схеме» лежит на программисте. Но при этом вроде бы какие-то черновики-наброски для подобной валидации есть и для JSON. Но с примерами использования для 1С не встречался. Обычно либо в коде проверяются правильно ли данные переданы, либо вообще забивают на проверку и эксепшены уже в процессе обращения к полям вываливаются ))
Вот здесь информация о схеме для JSON, но похоже что еще в черновом варианте:
:
(13)
Еще один сигнал автору, что нужно в следующих публикациях подробнее раскрыть тему XSLT, а мы большое спасибо скажем и звёздочку поставим ))
(13), (16)
Основная идея этой публикации — не модификация xml с помощью xslt. Эта тема довольно обширна и к 1С не имеет прямого отношения. То есть эта технология используется везде и поэтому легко гуглится тот или иной вопрос.
Другое дело, что если не было опыта работы с ней, то это все может показаться сложным.
(15) Хороший пример, я регулярно так и делаю. Даже и не подумал, что это может быть не очевидно ))
(17) ну я и не говорил, что именно XSLT — это основная тема) В принципе обмен через web-сервис с использованием XDTO — это уже давно не ново. Собственно, в том числе и к этому шли 1Сники, разрабатывая универсальный формат обмена данными. Более того, если посмотреть БСП, то в ее составе найдете соответствующие web-сервисы:
а как переводится NoRull?
(19) Хорошая ссылка
(1) Какая проблема с валидируемым JSON?
Или я что-то не понял?
(14) А зачем смешивать WSDL/XSD и JSON ? Это же 2 разных технологии — либо делаешь SOAP на XML и используешь XDTO, либо REST на гибком JSON и можно его формировать/проверять через свой модуль, а настройки полей и объектов хранить в справочнике, не вижу проблемы — передал структуру данных в функцию подготовки к отправке — она тебе выдала или готовый JSON или набор ошибок.
При получении так же — преобразовал текст json в структуру, прогнал через функцию по правилам, выдал «ОК» или ошибки.
Версии форматов удобно хранить, вместо копирования XDTO-пакетов
Сейчас столкнулся что в пакете все пустые строковые поля стали объектами XDTO, то ли при переходе на 13-ю платформу, то ли что…
Теперь нельзя полагаться на проверку поля на пустую строку после преобразования xml в объект — строковые поля не становятся строковыми, замечательно
В то время как весь мир переходит на GraphQL, 1Сники городят обмены на файликах и ковыряют SOAP из 2005 года…
(20) гугл выдает что Rull это «рулет» на норвежском
(23)
Копировать XDTO при работе с SOAP нет необходимости. Всё есть в WSDL геренерируемом на одной стороне — стороне поставщика интерфейса.
При получении так же — преобразовал текст json в структуру, прогнал через функцию по правилам, выдал «ОК» или ошибки.
Вот как раз в этом случае хранить правила проверки придётся как на стороне клиента, так и на стороне сервера. И чтобы узнать эти правила на этапе поддежки/доработки нужно будет читать код. Либо читать специально составленную документацию, которую обычно никто не составляет.
Речь не шла о смешении XSD и JSON. Речь шла о том, что нет общепринятого аналога WSDL для JSON, поэтому в случае обмена каждый изобретает свои «велосипеды» для проверок на стороне клиента и сервера. А бывает вообще без проверок и документации обходятся, потому что причина отказа от документации и проверок та же что и причина выбора JSON вместо XDTO — скорость реализации и отказ от строгих универсальных правил. Это удобно когда два программиста отвечающие за клиент и за сервер рядом сидят или в чате могут перекидываться сообщениями. Но когда система усложняется, то желателен более строгий подход.
Хотя вот если поискать можно найти попытки прикрутить WSDL для REST ))
(12)
а я не стал себя пересиливать, зачем оно мне надо… на русском код читаю бегло, почти «по диагонали», а тут надо вчитываться в каждое слово… смысла нет время тратить…
смысл есть только для тех, кто для заграницы пишет…