<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\
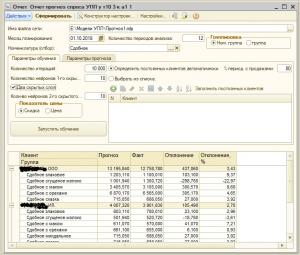









Воронцов есть такой ученый, вы как-то связаны?)
Хороший материал.
Осталось определиться, что считать «регулярными клиентами».
что значит «берут постоянно»..?
есть клиенты которые берут раз в два-три месяца. есть которые каждый месяц. объемы (в деньгах/тоннах/кубах) — могут и примерно одинаковые. а могут и нет.
.
даст ли что-то если проиграть несколько «сценариев», когда периодж может быт разный — поиграть сетью с «месяцем». поиграть сетью с кварталом..?
(1) Погуглил. Неа, просто однофамилец.
(2) В моем случае «постоянные клиенты» — это те, которые что то покупают каждый месяц за интервал статистики и даже присутствуют во внутренних фин. отчетах предприятия как предпределенные строки (типа Дебиторская задолженность «АО Тандер» … и т.д.). Но это ничего не значит. Можно добавлять свои варианты или вообще все засунуть в «Прочие клиенты». Но разбивка по клиентам все же имеет смысл так как для каждого создается сеть в которой рассчитывается модель его потребительского поведения. И общий спрос — как сумма моделей потребления. Такая была идея. С другой стороны всех покупателей подряд рассматривать как постоянных тоже не вариант при таких входных данных, так как могут быть вообще единоразовые покупки. Поэтому критерий, по которому можно отнести покупателей к постоянным — какой то процент периодов когда были покупки к общему числу периодов. Например 80%.
даст ли что-то если проиграть несколько «сценариев», когда периодж может быт разный — поиграть сетью с «месяцем». поиграть сетью с кварталом..?
Тут важно от чего зависят продажи. В моем случае период — это не элемент ряда, а фактор сезонности. Например в декабре перед новым Годом большой спрос (подарки). И если «зарыть» декабрь в 4-й квартал, а планировать все так же на месяц то этот фактор размоется я думаю.
Ну и что? Насколько прогноз сбывается?
(5) коварно в самом конце материала расположилось заключение с ответом на вопрос
1. Пробовали на этих данных более простые модели? Среднее, наивная (брать такой же месяц годом ранее), аппроксимация, Холта-Винтерса? С использованием сезонности от 1С.
2. Пробовали на этих данных что нить из ML? Фейсбучного пророка , линейную регрессию, бустинг, арима?
3. Кросс-валидация хотя бы на полгода?
4. Игрались с группировками и периодами? Группы без учета клиентов, или прогноз до недель/дней, а затем свертка до месяца
(7) 1. Сравнивали с обычным планированием на 1С (типовым) с учетом сезонности c усреднением за аналогичные периоды — результат точнее. По поводу Холта-Винтерса — там же надо каким то образом подбирать параметры. Честно говоря не знаю как это осуществить.
2. У меня задача другая нежели просто прогнозирование временных рядов. Статистические методы типа регрессии(почему обязательно линейной кстати?) тут можно применить только если не применять другие параметры — т.е. не указывать другую скидку например. Тут применение всех этих «статистических» а не «структурных» методов можно использовать как дополнение чтобы учесть влияние тренда, который у меня не учитывается, да.
3. Пока только 2 месяца, 1 и 1 месяц в 3х базах
4.Группы без учета клиентов — можно не указывать клиентов тогда будут все «Прочие клиенты» — разброс больше процентов на 20. До дней не делал.
(8) 1. У Холта-Винтерса параметры перебором подбираются. Для каждого набора запускается кросс-валидация и лучший результат — вот она модель. Я уже не помню по времени, но один ряд на 30 точек так минут 10 подбирался у меня, вроде б.
Вот, кстати, парадокс. Делаем очень крутую штуку, с мощным мат. аппаратом, почти ИИ. А средняя все равно дает результат лучше…
2. Линейная, потому что результат это линейная формула от входных коэффициентов. Чем там больше влияющих на результат признаков — тем лучше. Как раз прогнозирование временного ряда от задачи регрессии и отличается тем, что для прогнозирования есть только дата+целевое значение, а для регрессии куча признаков+целевое значение. Задача прогнозирование может быть сведена к задаче регрессии, наоборот — нет. Где то видел, что бустинг рвет все спец. библиотеки по прогнозированию, ариму и простую линейную регрессию.
И вот как раз в задаче регрессии появляется возможность добавлять доп. признаки — цена, скидка, это праздник, была мотивация персонала, желтый/обычный ценник или размер полки в случае пищевки, плановые остатки на складе, курс доллара, санкции итп
Именно в качестве прогнозирования у меня сложилась такая картина:
сперва юзаем простейшие методы, типа средней и наивной.
Если точности мало или хотим доп. признаки, или сезонность хитрая — фейсбучный пророк, если нужны графики и понимание или бустинг, если нужен результат, линейную регрессию только для оценки влияния признака на цель можно погонять.
А уже на это сверху можно навешивать полноценное планирование продаж и операций с прогнозом приростов от акций, расчетом загрузки производства, бюджетами и прочими ништяками.
(9) нет средняя как раз хуже. Может я неправильно выразился.
— вы имеете ввиду регрессию с фиктивными переменными? Но там же сдвиг или наклон только. От этого же форма зависимости не поменяется. А есть какой то материал с формулами с примером применения? Ну или вкратце — как добавить параметр?
(10) Нашел вот такое. Как в пророке добавлять свои сезонности, праздники и регрессоры (скидка и цена это как раз регрессор)
Пример прогнозирования на пайтоне с помощью линейной регрессии
Пример/сравнение прогнозирования по ARIMA, Facebook Prophet, XGBoost
Пример, где доп. признаков больше и они важнее, чем даты. Там 5 различных моделей
(11) хорошие ссылки. Спасибо!
(11) В статьях правда только куски кода с вызовом функций, это не очень помогает понять механику но видно это работает. Но к вопросу почему «нейросети а не стат. методы ?» Думаю могу ответить так: если сравнивать аппроксимацию разными методами больших различий не будет, но это если определена задача и определены влияющие переменные. Т.е. априори мы знаем о задаче эту информацию. Если же есть только гипотезы о влияющих факторах то применение сетей как раз проще — они сами «загасят» ненужные входы и настроят апроксимацию как надо. Т.е. больше универсальность и простота применения.
(13) Если хочется исходников, то и там по ссылкам. Там вроде даже где то научные работы есть, что в основе лежат.
Вы там потом под 1С запилить не забудьте)
(4)Дмитрий, наша компания занимается розничными продажами. Имеем 40 розничных точек. Работаем в 1С комплексная автоматизация. Хотим добавить в 1С внешние обработки по прогнозу спроса на основе нейросетей. Можете проконсультировать возможность такого внедрения в нашем случае и примерную стоимость?
(16) Ответил в личку
полезность любой прогнозной модели стремится к нулю.
Голоса в голове подсказываю что можно было обойтись линейной моделью. Почему нет сравнения с более простой моделью?
Это публикуется как продукт или как proof-of-concept? Т.е. есть ли возможность скачать обработку не за стартмани?
(18) Только за стартмани. Это заготовка для доработки напильником. В том смысле что работать в обозначенных конфигурациях она будет, но так как бизнесы разные то входы и параметры модели тоже разные соответственно источники данных возможно потребуется добавить свои.
Почему количество итераций 10000?
(20) С запасом. Это подбирается экспериментально.
(21)
Долго обрабатывает, в фон вытащу.