Постановка задачи
Проблема: выполнение операции занимает значительное время под пользователями с ограничениями.
Задача: оптимизировать проблемный участок с минимальными переделками и доработками.
Исходные данные: ERP ~700 онлайн одновременно. Подсистема производство. Точка входа: кнопка «Диспетчирование (ББВ)» в подсистеме производство.

Пару слов про работу этой кнопки с технической стороны: По нажатию на эту кнопку на сервере запускается фоновое задание, результат которого ожидается на форме клиента. Фактически ЕРП не в исит (выполняется асинхронно), но пользователь ждет результатов выполнения, чтобы приступить к работе.
исит (выполняется асинхронно), но пользователь ждет результатов выполнения, чтобы приступить к работе.
Замечание: Мы же знаем, что время = деньги! А также что время ожидания еще коррелирует с точкой закипания пользователя 😉
Последовательность решения
Начальный этап.
Определяемся с точкой анализа и определяем порядок действий для выполнения замера.
Замечание: Согласитесь — плохой тон включать ТЖ на все и для всех.
I) Замер с таймером.

А) Замер с таймером на рабочей базе.
Предварительный анализ показал, что под пользователем с полными правами выполняется в диапазоне от 5-15 сек. Под пользователем с ограничениями выполняется от 50-70 сек.
Б) Замер с таймером на локальной копии.
Под полными правами 3-8 сек. Под пользователем с ограничениями 4-10 сек.
Выводы: проявляется под нагрузкой.
II) Включаем замер технологического журнала (ТЖ).
 Для замера используем отбор по сеансу, базе и пользователю, чтобы не анализировать кучу данных ненужных. Подготовка, пользователь открывает подсистему и ждет команды нажать кнопку. В ТЖ обязательно включить следующие условия (данные в зависимости от текущей ситуации):
Для замера используем отбор по сеансу, базе и пользователю, чтобы не анализировать кучу данных ненужных. Подготовка, пользователь открывает подсистему и ждет команды нажать кнопку. В ТЖ обязательно включить следующие условия (данные в зависимости от текущей ситуации):
<eq property="p:processName" value="ERP"/>
<eq property="usr" value="Пользователь"/>
<property name="sessionid" value="1234"/>
А) Замеры на рабочей показали следующую картину см. таблица 1. Под полными и правами пользователей с ограничениями.
Б) Делаем замер на копии. Под полными и не полными.
Получаем фактически «квадрат» из таблиц, показывающих как ведет себя система под нагрузкой и без, при учете РЛС и без.
Для выполнения анализа воспользуемся конфигурацией «анализ технологического журнала» ссылки в конце статьи.
Замечание: Мы считаем, что анализ журнала должен быть простым и наглядным, а мериться длиной глубиной знаний в разборе текста на perl или regexp не стоит, можно заняться и более приятным делом, пока необходимый инструмент работает. К примеру, выпить чаю с печенькой)
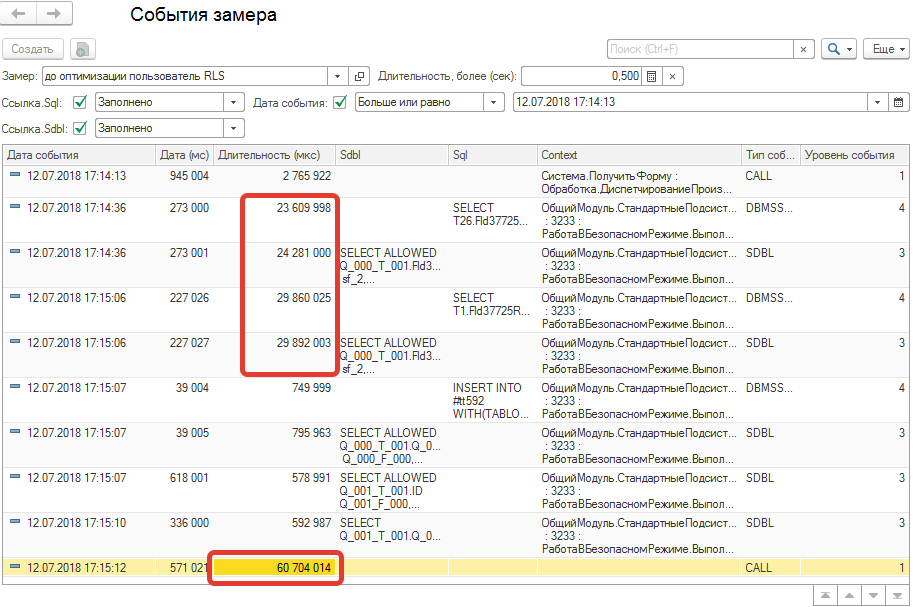
Табл. 1 Замеры пользователя с ограничениями RLS на нагруженной базе
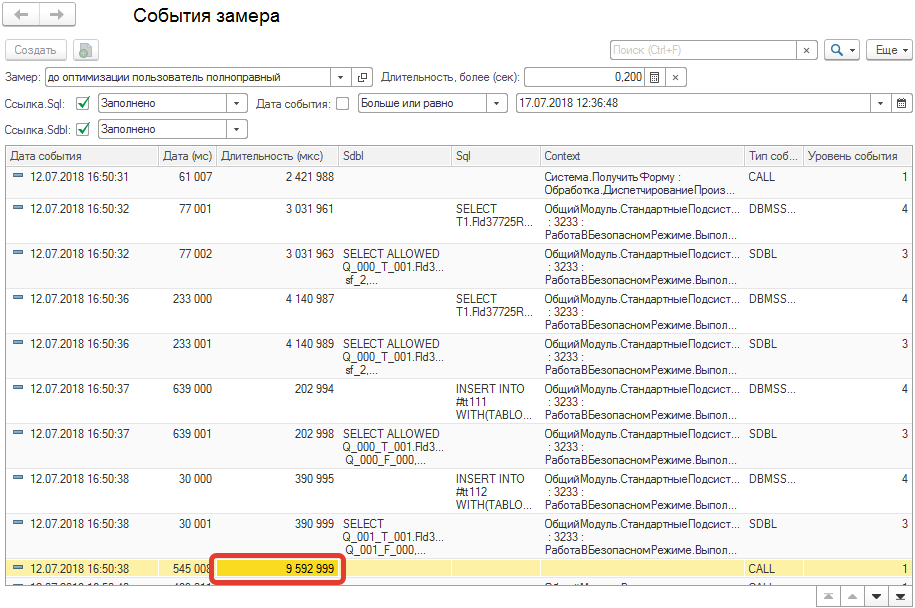
Табл. 2 Замеры пользователя администратора на нагруженной базе
III) Анализируем, выполняем поиск проблемных участков
Берем и открываем расшифровку Context для длительной операции согласно рисунку "Табл.1" и смотрим его расшифровку:
ОбщийМодуль.СтандартныеПодсистемыСервер.Модуль : 3233 : РаботаВБезопасномРежиме.ВыполнитьМетодКонфигурации(ВсеПараметры.ИмяМетода, ВсеПараметры.Параметры);
ОбщийМодуль.РаботаВБезопасномРежиме.Модуль : 513 : Выполнить ИмяМетода + "(" + ПараметрыСтрока + ")";
: 1 : Обработки.ДиспетчированиеПроизводства.ВыполнитьЗаданиеОбновитьДанные(Параметры[0],Параметры[1])
Обработка.ДиспетчированиеПроизводства.МодульМенеджера : 1260 : Результат = ПодготовитьДанныеДляДиспетчированияПроизводства(Параметры);
Обработка.ДиспетчированиеПроизводства.МодульМенеджера : 1270 : ПодготовитьТребуетсяСформироватьМЛ(Параметры, Результат);
Обработка.ДиспетчированиеПроизводства.МодульМенеджера : 1281 : ТребуетсяСформироватьМЛ = ОперативныйУчетПроизводства.ТребуетсяСформироватьМаршрутныеЛисты(
ОбщийМодуль.ОперативныйУчетПроизводства.Модуль : 1007 : ДанныеМаршрутныхЛистов = ОперативныйУчетПроизводстваВызовСервера.ДанныеДляФормированияМаршрутныхЛистов(Подразделение,, СписокЭтапов, УправлениеМаршрутнымиЛистами);
ОбщийМодуль.ОперативныйУчетПроизводстваВызовСервера.Модуль : 423 : ДанныеГрафика = Запрос.Выполнить().Выбрать();
Технически проблемная часть находится в модуле «ОперативныйУчетПроизводстваВызовСервера» -> функция «ДанныеДляФормированияМаршрутныхЛистов».
Проблемной частью в нашем случае является выполнение запроса под RLS. Архитектурные изменения не рассматриваем (минимум изменений), думаем как оптимизировать.
Запрос и представление функции выглядит так.
Функция ДанныеДляФормированияМаршрутныхЛистов(Подразделение = Неопределено, СписокРаспоряжений = Неопределено, СписокЭтапов = Неопределено, УправлениеМаршрутнымиЛистами = Неопределено) Экспорт
Запрос = Новый Запрос(
"ВЫБРАТЬ РАЗРЕШЕННЫЕ
| ДанныеГрафикаПроизводства.Распоряжение,
| ДанныеГрафикаПроизводства.КодСтрокиПродукция КАК КодСтроки,
| ДанныеГрафикаПроизводства.КодСтрокиЭтапыГрафик КАК КодСтрокиЭтапыГрафик,
| ДанныеГрафикаПроизводства.Подразделение КАК Подразделение,
| ДанныеГрафикаПроизводства.Подразделение.ИнтервалПланирования КАК ИнтервалПланирования,
| ДанныеГрафикаПроизводства.Подразделение.УправлениеМаршрутнымиЛистами КАК УправлениеМаршрутнымиЛистами,
| ДанныеГрафикаПроизводства.Этап КАК Этап,
| ВЫБОР
| КОГДА ЗаказНаПроизводствоЭтапы.МаршрутнаяКарта <> ЗНАЧЕНИЕ(Справочник.МаршрутныеКарты.ПустаяСсылка)
| ТОГДА ЗаказНаПроизводствоЭтапы.МаршрутнаяКарта.МаксимальноеКоличествоЕдиницПартийИзделия
| ИНАЧЕ ДанныеГрафикаПроизводства.Этап.МаксимальноеКоличествоЕдиницПартийИзделия
| КОНЕЦ КАК МаксимальноеКоличествоЕдиницПартийИзделия,
| ЭтапыПроизводства.НачалоЭтапа КАК НачалоРаботыКлючевогоРабочегоЦентра,
| ЭтапыПроизводства.Период КАК ОкончаниеРаботыКлючевогоРабочегоЦентра,
| ЭтапыПроизводства.НачалоПредварительногоБуфера КАК Начало,
| ЭтапыПроизводства.ОкончаниеЗавершающегоБуфера КАК Окончание,
| ЗаказНаПроизводствоПродукция.Номенклатура КАК Номенклатура,
| ЗаказНаПроизводствоПродукция.Характеристика КАК Характеристика,
| ЗаказНаПроизводствоПродукция.Ссылка.ВидРабочегоЦентра.ПроизводствоПоСменам как ПроизводствоПоСменам,
| ЗаказНаПроизводствоПродукция.Ссылка.ВидРабочегоЦентра как ВидРабочегоЦентра,
| ДанныеГрафикаПроизводства.ЗапланированоОстаток КАК Запланировать
|ИЗ
| РегистрНакопления.ГрафикЭтаповПроизводства.Остатки(
| ,
| (Подразделение = &Подразделение
| ИЛИ &Подразделение = НЕОПРЕДЕЛЕНО
| ИЛИ &Подразделение = ЗНАЧЕНИЕ(Справочник.СтруктураПредприятия.ПустаяСсылка))
| И &УсловиеОтбораРаспоряжение) КАК ДанныеГрафикаПроизводства
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрНакопления.ЭтапыПроизводства КАК ЭтапыПроизводства
| ПО ДанныеГрафикаПроизводства.Распоряжение = ЭтапыПроизводства.Распоряжение
| И ДанныеГрафикаПроизводства.КодСтрокиПродукция = ЭтапыПроизводства.КодСтрокиПродукция
| И ДанныеГрафикаПроизводства.КодСтрокиЭтапыГрафик = ЭтапыПроизводства.КодСтрокиЭтапыГрафик
| И ДанныеГрафикаПроизводства.Этап = ЭтапыПроизводства.Этап
| И ДанныеГрафикаПроизводства.Подразделение = ЭтапыПроизводства.Подразделение
| И (ЭтапыПроизводства.Регистратор ССЫЛКА Документ.ЗаказНаПроизводство)
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.ЗаказНаПроизводство.Продукция КАК ЗаказНаПроизводствоПродукция
| ПО (ЗаказНаПроизводствоПродукция.Ссылка = ДанныеГрафикаПроизводства.Распоряжение)
| И (ЗаказНаПроизводствоПродукция.КодСтроки = ДанныеГрафикаПроизводства.КодСтрокиПродукция)
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.ЗаказНаПроизводство.ЭтапыГрафик КАК ЗаказНаПроизводствоЭтапыГрафик
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.ЗаказНаПроизводство.Этапы КАК ЗаказНаПроизводствоЭтапы
| ПО (ЗаказНаПроизводствоЭтапы.Ссылка = ЗаказНаПроизводствоЭтапыГрафик.Ссылка)
| И (ЗаказНаПроизводствоЭтапы.КлючСвязи = ЗаказНаПроизводствоЭтапыГрафик.КлючСвязиЭтапы)
| И (НЕ ЗаказНаПроизводствоЭтапы.ПроизводствоНаСтороне)
| ПО (ЗаказНаПроизводствоЭтапыГрафик.Ссылка = ДанныеГрафикаПроизводства.Распоряжение)
| И (ЗаказНаПроизводствоЭтапыГрафик.КодСтроки = ДанныеГрафикаПроизводства.КодСтрокиЭтапыГрафик)
|ГДЕ
| (&НеИспользоватьУправлениеМаршрутнымиЛистами
| ИЛИ ДанныеГрафикаПроизводства.Подразделение.УправлениеМаршрутнымиЛистами = &УправлениеМаршрутнымиЛистами)
| И ВЫБОР
| КОГДА &ПланироватьПроизводстваПоСменам = ИСТИНА
| ТОГДА ВЫБОР
| КОГДА &ФормироватьМаршрутныеЛистыПоСмене = """"
| ТОГДА НЕ ДанныеГрафикаПроизводства.Распоряжение.ВидРабочегоЦентра.ПроизводствоПоСменам
| ИНАЧЕ ДанныеГрафикаПроизводства.Распоряжение.ппк_ВидРабочегоЦентра.ПроизводствоПоСменам
| И ЗаказНаПроизводствоЭтапыГрафик.ДоступностьВидаРабочихЦентров.ПредставлениеСмены = &ФормироватьМаршрутныеЛистыПоСмене
| И ЗаказНаПроизводствоЭтапыГрафик.ДоступностьВидаРабочихЦентров.ВидРабочегоЦентра.Подразделение = ДанныеГрафикаПроизводства.Распоряжение.ВидРабочегоЦентра.Подразделение
| КОНЕЦ
| ИНАЧЕ ИСТИНА
| КОНЕЦ
|
|УПОРЯДОЧИТЬ ПО
| Начало,
| ДанныеГрафикаПроизводства.Распоряжение,
| КодСтрокиЭтапыГрафик,
| ЗаказНаПроизводствоПродукция.Спецификация,
| ЗаказНаПроизводствоЭтапы.НомерЭтапа");
// подготовка к выполнению, устанавливаем параметры
// ...
ДанныеГрафика = Запрос.Выполнить().Выбрать();
// далее обрабатываем
// ...
КонецФункции
IV) Вырабатываем решение.
Если рассмотреть в сравнении два первых рисунка, то видно, что в привилегированном режиме выполнение запроса минимально (это фактически минимально достижимое время без глобальных исправлений). Поэтому, если вынести весь запрос или его часть в этот особый режим, то время выполнения достигнет приемлемых величин.
Основным критерием применения данного подхода является следующее: качественный и количественный состав данных до изменения и после должен быть одинаков. Приведем некоторые варианты решений:
- Накладываем фильтр простыми отборами соответствующими RLS. В качестве примера возьмем реализацию АРМ "Отгрузки" типовой конфигурации. На пользователя наложен RLS по складам на справочник Склады, т.е. он может выбрать только те склады к которым у него есть доступ. Поэтому накладывать ограничения на запросы позволяющие получить таблицу распоряжений не имеет смысла и можно получать результат в привилегированном режиме.
- Накладываем фильтр набором разрешенных данных. Если в запросе с разрешенными можно выделить некоторую изначальную выборку данных, в рамках которой в дальнейшем определяется итоговый результат, то эти данные выберем сначала (используя разрешенные), а на последующий пакет запросов искусственно накладываем фильтр из этого набора (используем внутреннее соединение с временной таблицей, оператор "В"). Т.е. иногда можно разбить запрос с разрешенными на две части — под ограничениями и без (в привилегированном режиме).
В данном случае было предложено использовать разбиение запроса и реализовать следующим образом:
1. добавить мини запрос, в котором выбрать разрешенные распоряжения по таблице с остатками (фильтр из данных)
2. оставшийся типовой запрос выполнить в привилегированном режиме, но с дополнительной фильтрацией по данным временной таблицы из первого запроса.
На что еще необходимо обратить внимание (Вы это скорее всего прекрасно знаете):
а). Выносить во временные таблицы стоит только фильтрованные данные. Плохим примером было бы вынести вместо таблицы остатков, таблицу документов, а потом ее отфильтровать.
б). Стараться всегда, где можно использовать фильтры и отборы.
в). Обратить внимание на использование вложенных запросов, переделать на временные таблицы. Не забываем для временных таблиц указывать индексы полей, участвующих в соединениях или отборах, даже если в ней три записи.
г). Условия в виртуальных таблицах.
д). "Или" переделывать на объединения (вопрос к знатокам, приходилось ли разбивать на десятки объединений условия по ИЛИ)?
Код запроса и представление функции с изменениями:
Функция ДанныеДляФормированияМаршрутныхЛистов(Подразделение = Неопределено, СписокРаспоряжений = Неопределено, СписокЭтапов = Неопределено, УправлениеМаршрутнымиЛистами = Неопределено, ФормироватьМаршрутныеЛистыПоСмене = "") Экспорт // Кондрин А.В. Задача ES-2115, 2026-10-19 ++
// Первая часть
// получаем список распоряжений
Запрос = Новый Запрос("ВЫБРАТЬ РАЗРЕШЕННЫЕ
| ДанныеГрафикаПроизводства.Распоряжение КАК Распоряжение
|ПОМЕСТИТЬ ВТ_ДанныеГрафикаПроизводства
|ИЗ
| РегистрНакопления.ГрафикЭтаповПроизводства.Остатки(
| ,
| (Подразделение = &Подразделение
| ИЛИ &Подразделение = НЕОПРЕДЕЛЕНО
| ИЛИ &Подразделение = ЗНАЧЕНИЕ(Справочник.СтруктураПредприятия.ПустаяСсылка))
| И &УсловиеОтбораРаспоряжение) КАК ДанныеГрафикаПроизводства
|ГДЕ
| (&НеИспользоватьУправлениеМаршрутнымиЛистами
| ИЛИ ДанныеГрафикаПроизводства.Подразделение.УправлениеМаршрутнымиЛистами = &УправлениеМаршрутнымиЛистами)
|
|ИНДЕКСИРОВАТЬ ПО
| ДанныеГрафикаПроизводства.Распоряжение");
МВТ = Новый МенеджерВременныхТаблиц;
Запрос.МенеджерВременныхТаблиц = МВТ;
// подготовка к выполнению, устанавливаем параметры
// ...
Запрос.Выполнить();
// Вторая часть
Запрос.Текст =
"ВЫБРАТЬ
| ДанныеГрафикаПроизводства.Распоряжение,
| ДанныеГрафикаПроизводства.КодСтрокиПродукция КАК КодСтроки,
| ДанныеГрафикаПроизводства.КодСтрокиЭтапыГрафик КАК КодСтрокиЭтапыГрафик,
| ДанныеГрафикаПроизводства.Подразделение КАК Подразделение,
| ДанныеГрафикаПроизводства.Подразделение.ИнтервалПланирования КАК ИнтервалПланирования,
| ДанныеГрафикаПроизводства.Подразделение.УправлениеМаршрутнымиЛистами КАК УправлениеМаршрутнымиЛистами,
| ДанныеГрафикаПроизводства.Этап КАК Этап,
| ВЫБОР
| КОГДА ЗаказНаПроизводствоЭтапы.МаршрутнаяКарта <> ЗНАЧЕНИЕ(Справочник.МаршрутныеКарты.ПустаяСсылка)
| ТОГДА ЗаказНаПроизводствоЭтапы.МаршрутнаяКарта.МаксимальноеКоличествоЕдиницПартийИзделия
| ИНАЧЕ ДанныеГрафикаПроизводства.Этап.МаксимальноеКоличествоЕдиницПартийИзделия
| КОНЕЦ КАК МаксимальноеКоличествоЕдиницПартийИзделия,
| ЭтапыПроизводства.НачалоЭтапа КАК НачалоРаботыКлючевогоРабочегоЦентра,
| ЭтапыПроизводства.Период КАК ОкончаниеРаботыКлючевогоРабочегоЦентра,
| ЭтапыПроизводства.НачалоПредварительногоБуфера КАК Начало,
| ЭтапыПроизводства.ОкончаниеЗавершающегоБуфера КАК Окончание,
| ЗаказНаПроизводствоПродукция.Номенклатура КАК Номенклатура,
| ЗаказНаПроизводствоПродукция.Характеристика КАК Характеристика,
| ЗаказНаПроизводствоПродукция.Ссылка.ВидРабочегоЦентра.ПроизводствоПоСменам как ПроизводствоПоСменам,
| ЗаказНаПроизводствоПродукция.Ссылка.ВидРабочегоЦентра как ВидРабочегоЦентра,
| ДанныеГрафикаПроизводства.ЗапланированоОстаток КАК Запланировать
|ИЗ
| РегистрНакопления.ГрафикЭтаповПроизводства.Остатки(
| ,
| (Подразделение = &Подразделение
| ИЛИ &Подразделение = НЕОПРЕДЕЛЕНО
| ИЛИ &Подразделение = ЗНАЧЕНИЕ(Справочник.СтруктураПредприятия.ПустаяСсылка))
| И &УсловиеОтбораРаспоряжение) КАК ДанныеГрафикаПроизводства
// ++ добавляем условие
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ ВТ_ДанныеГрафикаПроизводства КАК ВТ_ДанныеГрафикаПроизводства
| ПО (ВТ_ДанныеГрафикаПроизводства.Распоряжение = ДанныеГрафикаПроизводства.Распоряжение)
// --
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрНакопления.ЭтапыПроизводства КАК ЭтапыПроизводства
| ПО ДанныеГрафикаПроизводства.Распоряжение = ЭтапыПроизводства.Распоряжение
| И ДанныеГрафикаПроизводства.КодСтрокиПродукция = ЭтапыПроизводства.КодСтрокиПродукция
| И ДанныеГрафикаПроизводства.КодСтрокиЭтапыГрафик = ЭтапыПроизводства.КодСтрокиЭтапыГрафик
| И ДанныеГрафикаПроизводства.Этап = ЭтапыПроизводства.Этап
| И ДанныеГрафикаПроизводства.Подразделение = ЭтапыПроизводства.Подразделение
| И (ЭтапыПроизводства.Регистратор ССЫЛКА Документ.ЗаказНаПроизводство)
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.ЗаказНаПроизводство.Продукция КАК ЗаказНаПроизводствоПродукция
| ПО (ЗаказНаПроизводствоПродукция.Ссылка = ДанныеГрафикаПроизводства.Распоряжение)
| И (ЗаказНаПроизводствоПродукция.КодСтроки = ДанныеГрафикаПроизводства.КодСтрокиПродукция)
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.ЗаказНаПроизводство.ЭтапыГрафик КАК ЗаказНаПроизводствоЭтапыГрафик
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.ЗаказНаПроизводство.Этапы КАК ЗаказНаПроизводствоЭтапы
| ПО (ЗаказНаПроизводствоЭтапы.Ссылка = ЗаказНаПроизводствоЭтапыГрафик.Ссылка)
| И (ЗаказНаПроизводствоЭтапы.КлючСвязи = ЗаказНаПроизводствоЭтапыГрафик.КлючСвязиЭтапы)
| И (НЕ ЗаказНаПроизводствоЭтапы.ПроизводствоНаСтороне)
| ПО (ЗаказНаПроизводствоЭтапыГрафик.Ссылка = ДанныеГрафикаПроизводства.Распоряжение)
| И (ЗаказНаПроизводствоЭтапыГрафик.КодСтроки = ДанныеГрафикаПроизводства.КодСтрокиЭтапыГрафик)
|ГДЕ
| (&НеИспользоватьУправлениеМаршрутнымиЛистами
| ИЛИ ДанныеГрафикаПроизводства.Подразделение.УправлениеМаршрутнымиЛистами = &УправлениеМаршрутнымиЛистами)
| И ВЫБОР
| КОГДА &ПланироватьПроизводстваПоСменам = ИСТИНА
| ТОГДА ВЫБОР
| КОГДА &ФормироватьМаршрутныеЛистыПоСмене = """"
| ТОГДА НЕ ДанныеГрафикаПроизводства.Распоряжение.ВидРабочегоЦентра.ПроизводствоПоСменам
| ИНАЧЕ ДанныеГрафикаПроизводства.Распоряжение.ппк_ВидРабочегоЦентра.ПроизводствоПоСменам
| И ЗаказНаПроизводствоЭтапыГрафик.ДоступностьВидаРабочихЦентров.ПредставлениеСмены = &ФормироватьМаршрутныеЛистыПоСмене
| И ЗаказНаПроизводствоЭтапыГрафик.ДоступностьВидаРабочихЦентров.ВидРабочегоЦентра.Подразделение = ДанныеГрафикаПроизводства.Распоряжение.ВидРабочегоЦентра.Подразделение
| КОНЕЦ
| ИНАЧЕ ИСТИНА
| КОНЕЦ
|
|УПОРЯДОЧИТЬ ПО
| Начало,
| ДанныеГрафикаПроизводства.Распоряжение,
| КодСтрокиЭтапыГрафик,
| ЗаказНаПроизводствоПродукция.Спецификация,
| ЗаказНаПроизводствоЭтапы.НомерЭтапа";
// подготовка к выполнению, устанавливаем параметры
// ...
УстановитьПривилегированныйРежим(Истина);
ДанныеГрафика = Запрос.Выполнить().Выбрать();
// далее обрабатываем
// ...
КонецФункции
Замеры после оптимизации показали следующие результаты:
— Время для полноправного пользователя стало в районе 3-10 сек ,
— Пользователь с ограничениями стал работать в интервале 10-15 сек.
На рисунке ниже приведена таблица с замерами, выполненными после оптимизации (все замеры проводились при одинаковых настройках).
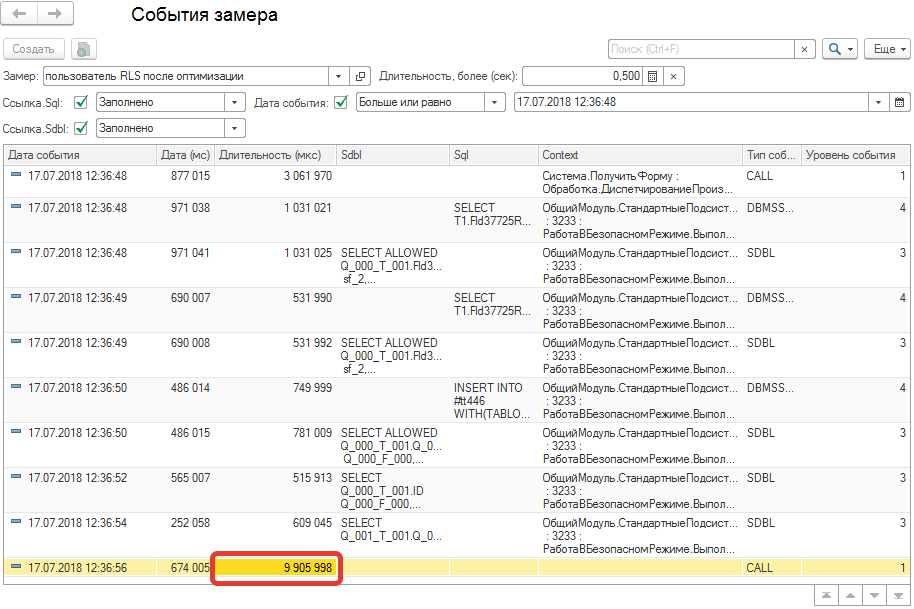
Табл. 3 Замеры пользователя с ограничениями RLS после оптимизации
Послесловие …
Проект для анализа технологического журнала расположен на GitHub по адресу: https://github.com/Polyplastic/1c-parsing-tech-log
Скажу сразу — другие готовые инструменты для решения подобных проблем нам не подошли в связи с поставленными перед нами целями и задачами.
Замечание: Для тех, кто не хочет ставить EDT и компилировать, но хочет посмотреть – есть возможность скачать с infostart ссылка внизу.
В общем включайтесь в разработку на EDT и Open Source, и да прибудет с нами сила.
(Об особенностях процесса разработки на EDT я рассказывал тут: Взгляд на практику разработки в EDT из зазеркалья )


 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями) Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
За конфигурацию по разбору логов ТЖ спасибо!
(1)
1. Спасибо всем нам) Буду рад если пригодится в работе. По вопросам и замечаниям, если будут пишите в секцию issue на GitHub проекта.
2. В ближайшем будущем мы планируем добавить еще некоторое количество полезного функционала.
3. Сейчас данная конфигурация у нас успешно работает в облаке для мониторинга проблемных ситуаций.
ИЛИ будет отрабатывать медленно, если отбор накладывается на разные поля. Пример:
Контрагент = &Контрагент ИЛИ Номенклатура = &Номенклатура.
Конструкция Контрагент = &Контрагент1 ИЛИ Контрагент = &Контрагент2 будет работать быстро.
Вложенные запросы сами по себе не страшны, плохо СОЕДИНЕНИЕ с вложенным запросом.
Соединение с виртуальной таблицей на уровне СУБД превращается в двойное соединение со вложенным запросом.
Индексирование не всегда полезно, даже если этому учат при экзамене по платформе. Тут дело в том, что на создание индекса тоже расходуется время. Тут надо экспериментальным путем подбирать. Иногда запрос тупил в два раза больше при накладывании индекса на временную таблицу.
А в целом да — РЛС убирать, и отборы, отборы и еще раз отборы!
(3) На счет индексирования. Недавно столкнулись с плавающим багом.
Относительно простой запрос по выборке выполнялся практически всегда быстро, но очень редко чертовски медленно — разница оказывалась порядка 100 раз. Смотрели сервер, потом планы запросов и выяснили, что их два: один хороший и оптимальный, а второй дурной со сканом. Так вот проблема была в том, что скуль иногда ошибался. Проблема решилась индексированием маленькой (в большинстве 40-50 записей) временной таблицы.
Поэтому в большинстве случаев настройки решение зависит от конкретной ситуации и окружения для рассматриваемой системы.
Проект на git-hub не содержит значимых файлов сорсов (одни md). Или я что-то не понимаю.
А вот статья получилась очень познавательная, более менее хорошо написанная! Побольше бы таких статей! Так держать!
(5)это проект EDT и все необходимые файлы на месте.
Чтобы запустить вам нужен EDT и 1С.
Далее в хелпе нужно найти статью как подключиться к git и развернуть проект.
(6)Это всё понятно. Я извиняюсь, всё нашёл — просто криво в начале посмотрел
(3)
абсолютно согласен с комментарием
Спасибо