
Изначально я использовал связку grep (cygwin) + perl, команды были что-то из разряда:
grep '' -rh --include '*.log' | perl descr.pl
или
cat */*.log | perl descr.pl
Первый вариант предпочтителен т.к. мы не зависим от количества вложенных директорий.
Вот собственно скрипты которые выложены на kb
descr.pl
query.pl
tlock.pl
Надеюсь я не нарушил никакое авторское право :). Сразу бросается в глаза, что эти скрипты написаны по одному шаблону и во всех трех присутствует одна и та же ошибка (не будем об этом).
Данные скрипты маленькие, емкие, лаконичные если хотите, и весьма быстрые. Однако они не самодостаточные, т.е. они не агрегируют duration, не выводят количество, по сути эти скрипты некий промежуточный этап, потом результат можно дополнительно обрабатывать AWK или SED’ом, что не очень удобно и не всем доступно (с точки зрения доступности скилов).
Решил я написать перловый скрипт который агрегирует произвольные значения (duration, потребление памяти, да что захотите), хитро группирует колстек (выбрасывает из него все нечитаемые символы, цифры и всякие ",:;’ ), но в консоль выводится все красиво. Скрипт был написан, ознакомиться можно в репе, данный скрипт на вход принимает различные параметры (сортировка, группировка, топ). Вроде все ок, но потом я подумал, все же зачем людям ставить к себе cygwin, надо искать файлы перлом, сказано — сделано. Однако, такой скрипт работал на несколько порядков медленнее. Например если скрипт который читает из StdIn выполнялся 10 сек. то скрипт который читал файлы уже тратил около 15 минут. (обрабатываемый объем естественно одинаков)

Видимо это из-за того, что я регулярку натравливал на весь файл
Решил было распараллелить процесс чтение из файлов, но perl нормально не параллелится и это было мое последнее разочарование, после которого я потерял интерес к perl’у.
perl нормально не параллелится
Тут стоит внести ясность, перл конечно умеет работать "параллельно", но в режиме кооперативной многозадачности, для этого в перл есть т.н. корутины (coroutines) или модуль AnyEvent
Схематично это можно представить так:
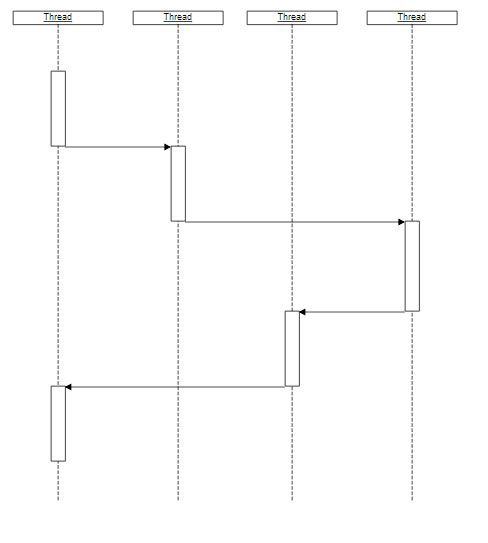
т.е. управление передается от корутины к корутине, но общее время выполнение будет такое же как если бы код выполнялся линейно.
К тому же, исторически все же перл создан под linux, в linux можно было бы создать отдельные процессы (fork) и радоваться, но в винде не создается отдельный процесс при выполнении fork(). Есть еще AnyEvent::Fork::Pool, но запустить пример из cpan мне так и не удалось. (особо не старался если честно)
В целом мое впечатление о перле — синтаксис удобный, но язык тяжелый для изучения
После этого я переключился на Golang, параллельность у Go это его сильная сторона. В Go есть свои корутины, в Go они называются горутины. Горутины из себя представляют треды которые работают как в кооперативной многозадачности, так и параллелятся по процессам. Как результат был написана консольная утилита (ссылка на репу в конце статьи).
Архитектура утилиты получилась такая такая:
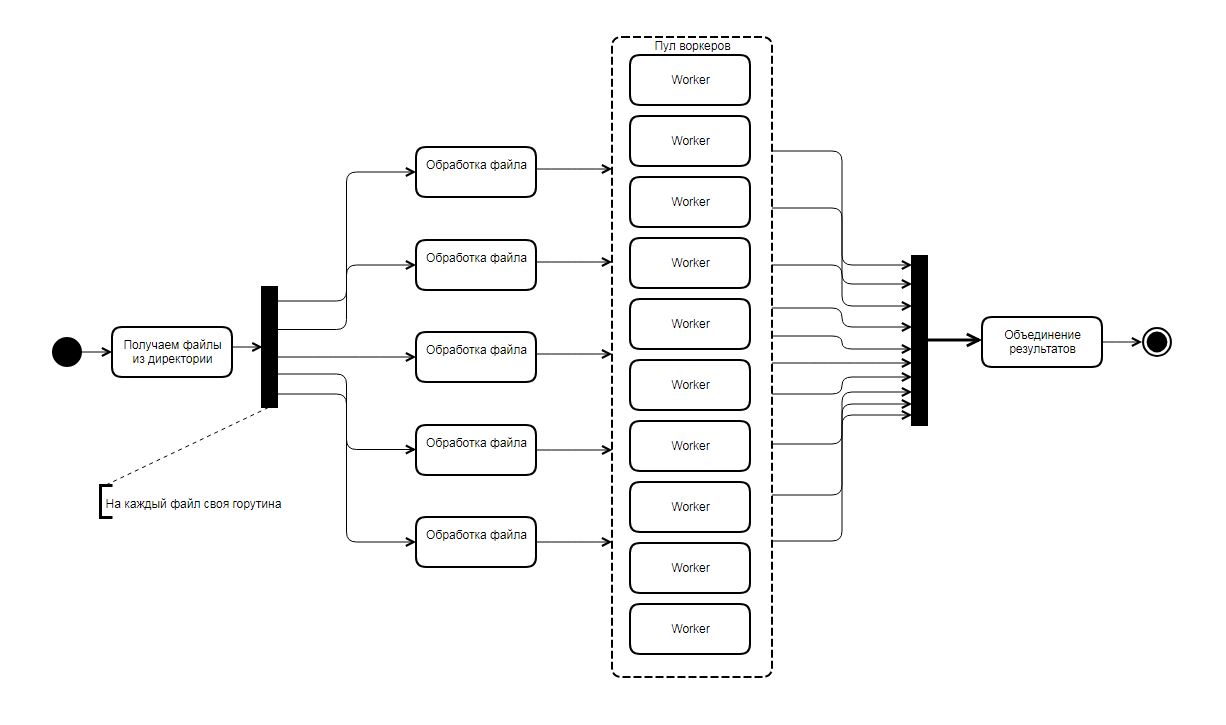
Каждый файл обрабатывает отдельная горутина, каждая такая горутина разбирает файл на такие части:
41:56.637012-1,SCALL,2,process=rphost,p:processName=ZKGU_KBR,OSThread=15448,t:clientID=20,t:applicationName=BackgroundJob,t:computerName=SP-SRV1,t:connectID=293645,SessionID=11,Usr=DefUser,ClientID=17,Interface=12af46e1-4f3e-4446-a753-519e54d55f48,IName=IObjectLocksStor,Method=2,CallID=33656,MName=clearObjectLocks
41:58.602000-0,CONN,1,process=rphost,OSThread=15448,ClientID=20,Txt=Incomming connection closed: long still
41:58.602001-10966996,CONN,0,process=rphost,OSThread=15448,t:clientID=20,t:clientID=20,t:computerName=SP-SRV1,t:applicationName=BackgroundJob,t:connectID=293645,Calls=11
42:01.551000-0,CONN,0,process=rphost,OSThread=5148,Txt='Ping direction statistics: address=[::1]:1541,pingTimeout=5000,pingPeriod=1000,period=10296,packetsSent=10,avgResponseTime=0,maxResponseTime=0,packetsTimedOut=0,packetsLost=1,packetsLostAndFound=1'
42:11.847000-0,CONN,0,process=rphost,OSThread=5148,Txt='Ping direction statistics: address=[::1]:1541,pingTimeout=5000,pingPeriod=1000,period=10296,packetsSent=10,avgResponseTime=0,maxResponseTime=0,packetsTimedOut=0,packetsLost=1,packetsLostAndFound=1'
42:17.588001-0,EXCP,0,process=rphost,OSThread=16304,Exception=0874860b-2b41-45e1-bc2b-6e186eb37771,Descr='srcLicenseBaseImpl.cpp(5203):
0874860b-2b41-45e1-bc2b-6e186eb37771: Ошибка программного лицензирования. Error=10004(0x00002714): Операция блокирования прервана вызовом WSACancelBlockingCall.
File=srcLicenseBaseImpl.cpp(5144)'
42:18.508012-0,EXCP,0,process=rphost,OSThread=10848,Exception=acea3e6e-3687-4792-8319-09c009274c9a,Descr='srcRHostImpl.cpp(5456):
acea3e6e-3687-4792-8319-09c009274c9a: Рабочий процесс не найден'
(раскрасил для наглядности)
Каждая такая часть поступает на обработку пулу воркеров, по дефолту пул состоит из 10 воркеров (воркер — отдельная горутина, которая работает в фоне и ожидает на вход каких-то данных для обработки), размер воркеров может меняться параметром, об этом далее.
Результат работы воркера это определенная структура, каждый воркер накапливает внутри себя map’ы результатов, по окончанию обработки файлов у нас получается 10 (по количеству горутин) map’ов, они в свою очередь объединяются в общую мапу отдельной горутиной.
map — структура данных в Go, в perl аналог — хэш, в 1С — соответствие
В результате на выходе мы получаем некий контекст (программист задает, что будет контекстом) и некие агрегируемые поля (агрегация всегда осуществляется по полю value, а вот откуда будет браться значения для value определяется программистом)
Вывод результата получается такой:
Для события EXCP
(rphost) EXCP, количество - 7 'srcVResourceInfoBaseImpl.cpp(1113): 580392e6-ba49-4280-ac67-fcd6f2180121: Ошибка работы сеанса Ошибка при выполнении запроса POST к ресурсу /e1cib/logForm: 60c686dc-798f-4d17-aadb-a90156a16eb8: Сеанс отсутствует или удален ID=1204924e-c4ad-43e0-a801-78dca981c70d (rphost) EXCP, количество - 7 'Сеанс отсутствует или удален ID=3c12c449-3c3a-48fb-a1c4-f01869814f97 (rphost) EXCP, количество - 2 'Сеанс отсутствует или удален ID=f8467c59-27ca-4ed9-8768-5f48b6f9ce92
для события CALL
(ИмяБазы) CALL, количество - 9, MemoryPeak - 8317991
ОбщийМодуль.Вызов : ОбщийМодуль.ДлительныеОперацииВызовСервера.Модуль.ОперацииВыполнены
(ИмяБазы) CALL, количество - 1, MemoryPeak - 950231
ОбщийМодуль.Вызов : ОбщийМодуль.СтандартныеПодсистемыВызовСервера.Модуль.СкрытьРабочийСтолПриНачалеРаботыСистемы
(ИмяБазы) CALL, количество - 1, MemoryPeak - 726808
ОбщийМодуль.Вызов : ОбщийМодуль.ИнтернетПоддержкаПользователейВызовСервера.Модуль.ПередНачаломРаботыСистемы
(ИмяБазы) CALL, количество - 1, MemoryPeak - 1454045
ОбщийМодуль.Вызов : ОбщийМодуль.МенеджерОборудованияВызовСервера.Модуль.НайтиРабочиеМестаПоИД
(ИмяБазы) CALL, количество - 1, MemoryPeak - 1210482
Форма.Вызов : Обработка.РезультатыОбновленияПрограммы.Форма.ИндикацияХодаОбновленияИБ.Модуль.ЗагрузитьОбновитьПараметрыРаботыПрограммыВФоне
в данном случай value выбрано MemoryPeak, можно выбрать duration, как напишите регулярку.
Шаблон для вывода может переопределять программист.
Параметры которые принимает утилита:
- -SortByCount — признак того, что нужно сортировать результат по количеству
- -SortByValue — признак того, что нужно сортировать по значению
- -io — признак того, что данные будут поступать из потока stdin
- -Top — ограничение по количеству выводимого результата
- -Go — количество горутин в пуле (по умолчанию 10)
- -RootDir — директория где будет осуществляться поиск
И для профилирования:
- -cpuprof
- -memprof
Пример использования:
ParsLogs.exe -RootDir=C:Logs
В данном случае поиск логов будет производиться по каталогу "C:Logs"
Также можно применять в тандеме с grep’ом
grep » -rh —include ‘*.log’ | ParsLogs.exe -io
Пример сочетания параметров
ParsLogs.exe -RootDir=C:Logs -Top=10 -SortByCount
Будет выведено 10 результатов отсортированных по количеству
Немного сравнения с перлом:
Для примера был взят мой перловый скрипт с агрегацией и объем логов ТЖ 2.8г
grep » -rh —include ‘*.log’ | perl CallDurationsMem.pl скрипт выполнялся ~ 10 минут
grep » -rh —include ‘*.log’ | ParsLogs.exe -io примерно 3 минуты зависит от того сколько внутри регулярок применяется к блоку данных
ParsLogs.exe -RootDir=C:Logs примерно 2 минуты
Пробовал парсить 30Гб логов, ушло около 2ч.
Кто-то скажет, так перловый скрипт видимо написан не оптимально, я соглашусь, я в перле новичок, так же как и в Go, т.е. считаем, что оба эти приложения написаны не особо оптимально (кстати в Go написать менее оптимально вероятности куда больше, т.к. там нужно не забывать тот факт, что структуры и большинство типов передаются по значению)
Профилирование приложения показало, что основную нагрузку на приложение дает регулярка:
По этому скорость обработки логов напрямую зависит от того насколько оптимальна написана регулярка и сколько этих регулярок под капотом. Регулярок может быть несколько т.к. в приложении был применен pattern chain of responsibility, об это будет рассказано далее.
Если вы захотите присоединиться к разработке, ниже информация для вас:
Как уже писалось выше, в архитектуре решения был применен pattern chain of responsibility (кому интересно вот статья как накостылить этот паттерн на 1С). Основная структура в коде это Chain и интерфейс IChain который чаще всего будет претерпевать изменения. Структура Chain это есть один из звеньев в цепочки ответственности
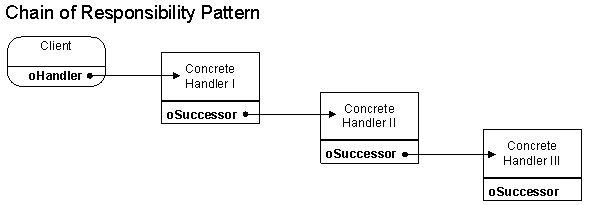
Цепочка строится в методе BuildChain() (метод в пакете Tools)
func BuildChain() *Chain {
Element1 := Chain{
regexp: regexp.MustCompile(`(?si)[,]CALL(?:.*?)p:processName=(?P<DB>[#k8SjZc9Dxk,]+)(?:.+?)Module=(?P<Module>[#k8SjZc9Dxk,]+)(?:.+?)Method=(?P<Method>[#k8SjZc9Dxk,]+)(?:.+?)MemoryPeak=(?P<Value>[d]+)`),
AgregateFileld: []string{"event", "DB", "Module", "Method"},
OutPattern: "(%DB%) CALL, количество - %count%, MemoryPeak - %Value%
%Module%.%Method%",
}
Element2 := Chain{
regexp: regexp.MustCompile(`(?si)[,]CALL(?:.*?)p:processName=(?P<DB>[#k8SjZc9Dxk,]+)(?:.+?)Context=(?P<Context>[#k8SjZc9Dxk,]+)(?:.+?)MemoryPeak=(?P<Value>[d]+)`),
NextElement: &Element1,
AgregateFileld: []string{"DB", "Context"},
OutPattern: "(%DB%) CALL, количество - %count%, MemoryPeak - %Value%
%Context%",
}
Element3 := Chain{
regexp: regexp.MustCompile(`(?si)[,]EXCP,(?:.*?)process=(?P<Process>[#k8SjZc9Dxk,]+)(?:.*?)Descr=(?P<Context>[#k8SjZc9Dxk,]+)`),
NextElement: &Element2,
AgregateFileld: []string{"Process", "Context"},
OutPattern: "(%Process%) EXCP, количество - %count%
%Context%",
}
return &Element3
}
Метод должен возвращать всегда ссылку на последнее звено в цепочке. Используется это так, выполняется метод "звена" Execute, если он вернул nil и есть следующий элемент в цепочке,тогда вызывается Execute следующего элемента. В Execute выполняется регулярка + кой какие пляски, чтобы можно было удобно работать с именованными группами захвата.
- regexp — шаблон регулярного выражения. Группы захвата обязательно должны быть именованными, в Go это делается так (?P<Имя> …..)
- NextElement — ссылка на предыдущее звено цепочки
- AgregateFileld — имена групп захвата по которым будет производиться агрегация
- OutPattern — шаблон по которому будет выводиться результат. В примере выше маркер %count% нигде не задается, это количество подходящих элементов в группе (при агрегации), давайте считать этот маркер "системным". Группа захвата содержащие значение которое будет суммироваться должна называться Value (имя групп регистрозависимое). Например, если мы захотим агрегировать значения duration, тогда регулярка будет такой `(?si)[d]+:[d]+.[d]+[-](?P<Value>[d]+)[,]CALL(?:.*?)p:processName=(?P<DB>[#k8SjZc9Dxk,]+)(?:.+?)……..`
Проект располагается на github, буду рад, если кто-то присоединится к проекту.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Вероятно следующим шагом будет использование мощностей CUDA и обработка блоков журнала ядрами GPU.
(1) Кстати, отличная тема, только там что-то все ссылки битые
(2) Тем ценнее будет, если напишешь собственную реализацию. Ссылку поправил.
(2) Вот еще интересно было бы протестировать с
(3) ресурс твой?
(5) Нет. Просто там явно шел «перепост» с другого сайта.
Гошан прекрасен.
Особенно кайфую от профайлера.
Тоже была мысль парсить на нем логи, но я хотел обойтись без регулярок.
(7) вполне вероятно, что такой вариант будет более быстрый, но явно менее поддерживаемый, так что нужно найти золотую середину
(1) по CUDA-grep вообще нет внятной документации, какой-нибудь how-to сделали б
(8) Я бы не был так уверен насчет «явно» )
Простые процедуры сканирования идентификаторов, чисел и прочих лексем не должны быть в общем случае сложнее для понимания/поддержки чем регулярки.
Еще кстати повсеместное использование map тоже может быть не оптимально. В определенных случаях линейный поиск будет теоретически быстрее, просто потому что map вынужден просматривать всю строку для вычисления хэша (хотя я на самом деле не знаю какая реализация map в Go, может и норм).
Не могу не заступиться за perl))
По поводу паралельности — он отлично паралелится на Windows (я про fork), а если еще между ними pipe прокинуть так процессы и общаться могут.
По поводу долго чтения файла. У перла при открытии файла можно указать «слои» которые нужно использовать. Рекомеедуется, если используешь функцию open, обязательно использовать слой io так как он буферезирует данные и читает норм.
Мои замеры таковы, что один процесс вычитывает файл, размером 2.5 гб, на локальной машине, примерно за минуту +- секунд 10, сюда также входит разбивка данных на события и определение его длительности, названия и т д, но без разбора самого события , а именно свойств и их значений.
(11) не знаю, я не наблюдал порождения нового процесса при fork’e, а если сделать sey pid после fork то выводил какой-то минусовой пид. Хотя не буду вступать в полемику, я допускаю, что мой скрипт на перл можно было бы сделать более производительным.
(11) если знаком с перлом, присоединяйся к разработке, в статье есть ссылка на репозиторий где тот скрипт лежит
(0) какое практическое применение?
(14) Ускорение работы регулярок. Я баловался писал парсер на питоне, там 95% затрат времени — работа с регулярками.
(15) а что за задачи , которые связаны с регулярными выражениями?
(16) анализ тех журнала
(15) в каких ситуациях требуется анализировать тех. журнал? тем более парсить его?
(17) Основная задача — расследование проблем с производительностью.
Еще есть задача — мониторинг
(19) спасибо
(17) Например:
1) у всех пользователей полезли ошибки — максимальное время ожидание транзакции — никак виновника, кроме как по ТЖ не найдете, потому что это Управляемые блокировки и они нигде более не фигурируют.
2) Просто тормозит база. На часик запись полного ТЖ, и смотрим какой запрос суммарно дольше всего выполнялся. Это может быть как и многомиллионный спам микрозапросов, которые например ЦУП пропустит(+ цуп именно эти вещи ну очень медленно вычисляет, да еще не всегда у него удается, на обучении при анализе ТЖ из 5ти попыток успешно прочиталось 1 раз только), из коробки там замер, дай бог памяти 1сек и более, так и какой нибудь чудовищный запрос. Или кто то накосячил в фоновом задании и оно бесконечно выполняется. Или 90% нагрузки создает ДС. Как правило после решения топ 3 строчек база порхать начинает.
3) Можно попытаться найти причиину утечек памяти, но тж не дает точной проблемы из-за особенностей записи этих событий, но направление дать может.
4) Мониторинг это не через час позвонили и сообщили о проблеме
1) а в течение 5 минут вам пришло уведомление, что число таймаутов за сутки стало больше порога.
2) Какой то ключевой запрос неделю назад выполнялся в среднем 5 секунд, а сегодня стал выполняться в среднем 10 секунд, хорошо бы понять причину
3) Число аварийных завершений процессов вместо допустимых ну скажем 3х в сутки, за час стало 5, надо разобраться
Ну это основное
Нашел статью Intel, где сравнивается производительность Perl и Hyperscan:
Вот еще статья на хабре:
Кстати, странно, что в интернете так мало информации об этой библиотеке.
Есть еще библиотека Яндекса, PIRE. Тоже было бы интересно поэкспериментировать:
(21) И для всего этого прекрасно подходит ELK стек. Сборщик логов там тоже на Go доступен.
(22) Hyperscan это ж сишная библиотека, а вот от яндекса можно попробовать
(10)Даёшь конечный автомат, специально заточенный под тех логи!
Яндекс библиотека PIRE как раз и переводит регулярки в конечный автомат 🙂
(23)
Условия в которых работать приходилось мне.
Вот тебе удаленный рабочий стол.
Вот тебе канал только для него.
Вот тебе ярлык на папку conf и на папку logs ну и права на них.
Вот тебе консоль.
Мы ничего ставить не будем — развлекайся.
Опыт у меня небольшой в этом, но пока удавалось.
Пункты 1 и 2 на практике применял, 3 и 4 в теории представляю как, но пока это никому не надо было.
(26) Ага, это стандартная ситуация когда обращаются к эксперту для решения проблемы. Именно из-за этого не сертификации требуют умение анализировать логи через awk/sed итд.
Но имхо лучше в такой ситуации повысить компетенцию клиентов и внедрить нормальную систему анализа логов (можно и не только 1Совских).
(27)
Но имхо лучше в такой ситуации повысить компетенцию клиентов и внедрить нормальную систему анализа логов (можно и не только 1Совских).
Вопрос в деньгах. Времена тяжелые все таки, если после исправления ошибок все устраивает, то убедить в том что надо что то еще невозможно, ну банально нет денег ни на инфраструктуру ни на работы. Ну по крайней мере у средних клиентов, с которыми мне приходилось работать.
(28) Ну а крупных клиентов уже я не потяну, ибо практики в некоторых вопросах нет, а там платят за результат.
Но и то что есть меня пока устраивает.
(23) инструменты входящие в ELK быстро (считай из коробки) устанавливаются на linux, на винде нужно поплясать с этим, к тому же нет какого-то коробочного решения (если есть, поделись, я не слышал о таком) для парса лога ТЖ. Нужно изучать правила фильтрации logstash, нужно изучать DSL эластиксеча, не сказал бы, что это просто. Да если твоя работа с этим связана и тебе приходится постоянно парсить логи или ты можешь себе позволить инвестировать время на изучения этого стека технологий, но я бы не назвал это простым решением.
(30) Сам стек ставится в докере одинаково просто на windows и linux.
Beats (сборщик) нативный. Logstash изучать не надо, т.к. хватит ingest node. В остальном самым сложным является нормальные регулярки для рабора написать, но в вашей разработке задача ровно та же.
(31) дай образ докера под винду
(32) Нативный контейнер для Windows Server 2016 хотите? Такого нет официально. Да и имхо не нужно совершенно.
Остальные контейнеры тут:
Наконец то!. Это по моему первая статья здесь в которой есть golang.
(33) дело было я пробовал, потыкался, и забросил, я не могу сказать, что там все просто и понятно. Помню застрял на том, что в logstash не мог передать данные из stdin (а ранее мучался с кибаной, что бы на IIS поднять ее). Если есть опыт, пиши статью, как это делать, всем комьюнити спасибо скажем )
А когда сам вендор напишет нормальную утилиту для анализа ТЖ? у которой юзабилити была хоть сколько-нибудь приемлемая.
…Что? ЦУП и ЦКК говорите?
(36) вендор нормального подробного описания формата ТЖ не может предоставить, а ты говоришь утилиту.
(36)
…Что? ЦУП и ЦКК говорите?
Угу.
Атрибут Context может быть в записи, а может и не быть.
Мы так до сих пор и не поняли почему так случается (С)
Вообще символ перевода строки — это новая запись.
Но там где есть Context и тексты запроса это не работает. По этому достаем грепы и символом начала строки будет /d/d:/d/d/./d/d/d/d etc, а все остальные символы перевода строки заменяем <newline>
А да еще никто не догадался, что служебное имя временной таблицы никому не надо, по этому еще раз режем tt.+ на tt
И да, атрибуты в самом событии тоже просто так разбить нельзя, это не запятая+пробел.
Запятая + пробел — она может быть в текстах.
И да не Запятая + Пробел + .* + = Это тоже может быть в текстах
И для того что бы по человечески нарезать на столбцы надо 5 регулярок + около 10 СТРЗаменить.
Иначе никак.
А еще мы в каждый новый релиз платформы добавим пару атрибутов новых в ТЖ.
Но в описание релиза не поместим.
А Скажем Вам — ищите в руководстве администратора. Его издание было пол года назад — Вы просто неудачник, мы вот например знаем что это и зачем.
Вы так же можете воспользоватся ЦУП. Что он не работает и валится, а Вы за это отдали 100К? А если не валится то 5 минут парсит пару часов? Вы просто неудачник.
(38) прослезился