

Сразу предупрежу, что никаких трепанаций программ не делал. Только лишь наблюдал извне. В распоряжении имелись 1С версии 8.3.12.1469 и MS SQL 10.50.1600.1 с его профайлером, куда ж без него.
При старте 1С:Предприятие семь раз обращается к таблице v8users, а если запустить из конфигуратора в режиме отладки, то все 11. Все бы ничего, но мною для экспериментов было сгенерировано 300 тысяч пользователей. Так сказать для наглядности. Само количество не имеет никакого значения, просто взято "с потолка" (так сказать, за время на обеденного перерыва).
Назначение каждого запроса мне, конечно же, неизвестно, но то, что они не столь очевидны, думаю, оценят многие. Назначение одного точно не то, что не знаю, не имею представления. Он второй по списку. Синтаксис остальных можно поставить под сомнение. Например, поиск текущего пользователя операционной системы. Саму обработку не прилагаю, придется ставить ценник, а лишь немного процитирую:
Вооружимся профайлером и начнем.
Первый запрос выглядит так:
SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE EAuth IS NULL OR AdmRole IS NULL OR UsSprH IS NULL
Данный запрос никак не оптимизируется, тем более, что таблице не хватает нужных индексов. Есть только один, да и тот не очень-то и подходит:
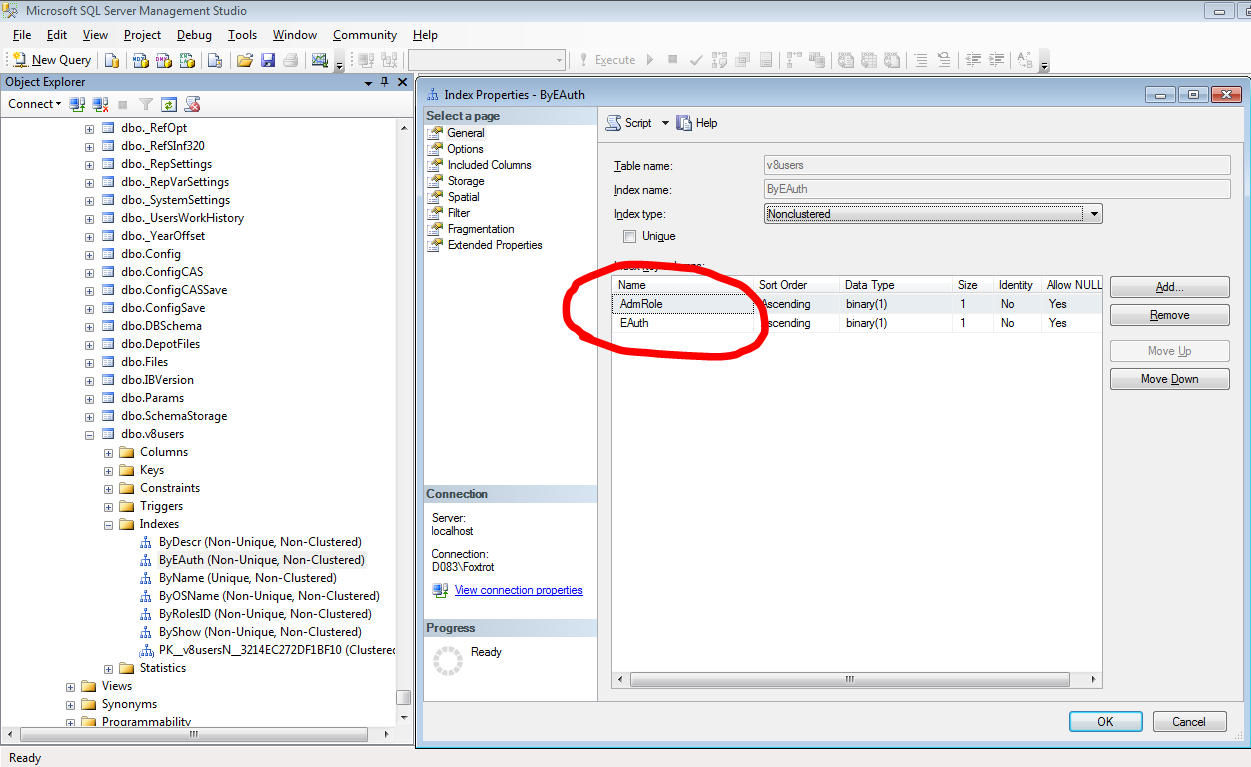
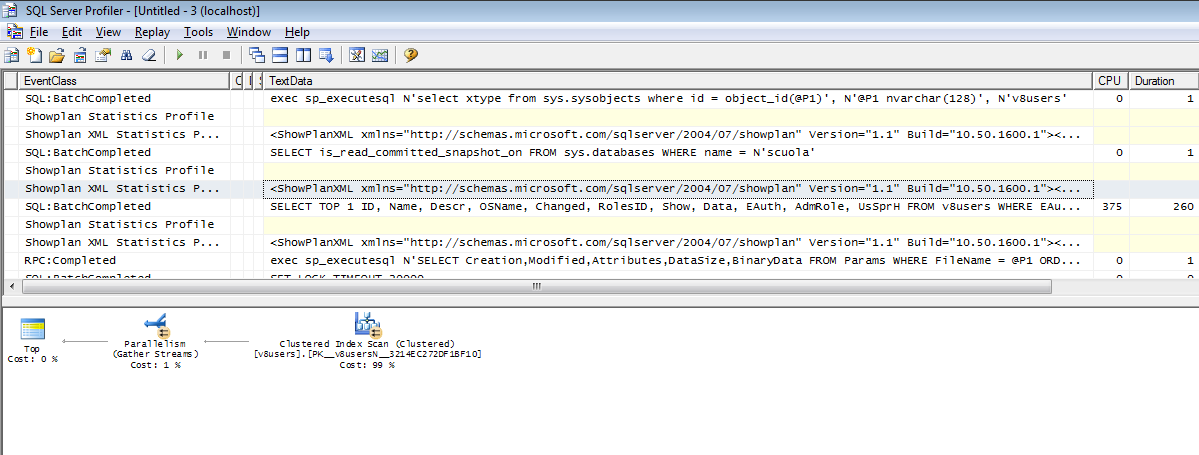
Второй запрос имеет вид:
SELECT MAX(Changed) FROM v8users
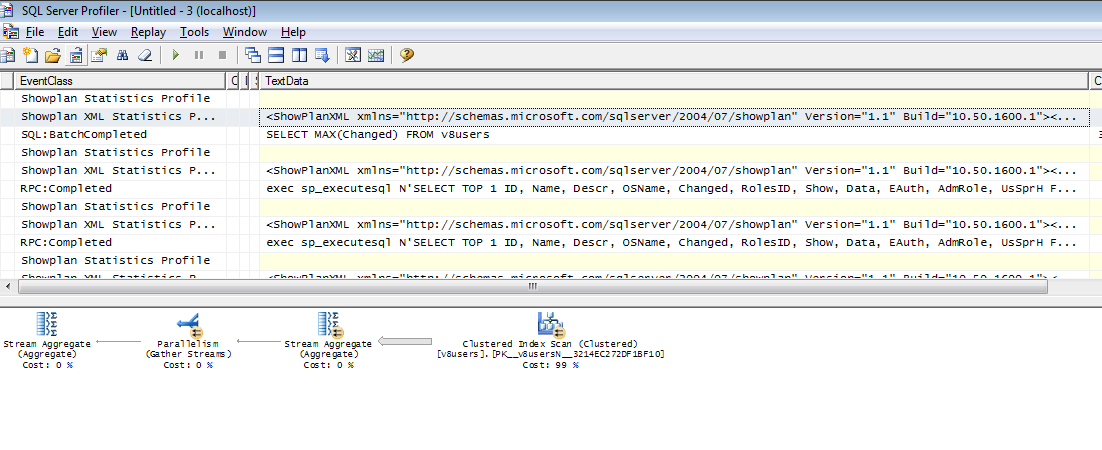 Данный запрос выполняется медленно потому, что нет индекса по полю Changed. Что мешало разработчикам создать его, остается для меня загадкой. Надо понимать, что данный запрос выполняется каждый раз при запуске 1С, и сколько времени можно было бы сэкономить пользователям, британским ученым пока неизвестно. Так же неизвестно для чего потребовался этот запрос. Да узнаем мы, когда последний раз изменяли параметры пользователя, а дальше что? Что делать с этой информацией? Буду признателен тому, кто приоткроет тайну.
Данный запрос выполняется медленно потому, что нет индекса по полю Changed. Что мешало разработчикам создать его, остается для меня загадкой. Надо понимать, что данный запрос выполняется каждый раз при запуске 1С, и сколько времени можно было бы сэкономить пользователям, британским ученым пока неизвестно. Так же неизвестно для чего потребовался этот запрос. Да узнаем мы, когда последний раз изменяли параметры пользователя, а дальше что? Что делать с этой информацией? Буду признателен тому, кто приоткроет тайну.
Последующие запросы на первый взгляд похожи друг на друга и различаются лишь параметрами. Радует, что все выражения оптимизируемы планировщиком, так как имеют все необходимые индексы.
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x00000000000000000000000000000000,0x952A5019EAE6A1F74023E7966E3EE1DE
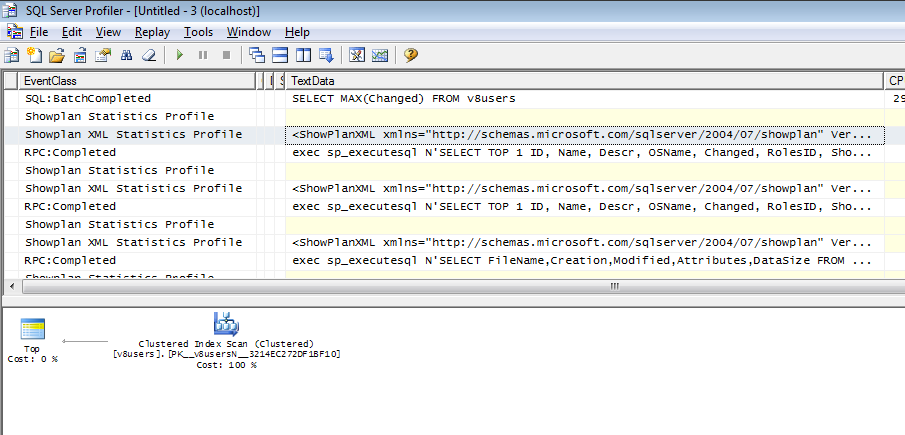
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE OSName = @P1 AND ID <> @P2
ORDER BY OSName',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'\localhostFoxtrot',0x952A5019EAE6A1F74023E7966E3EE1DE
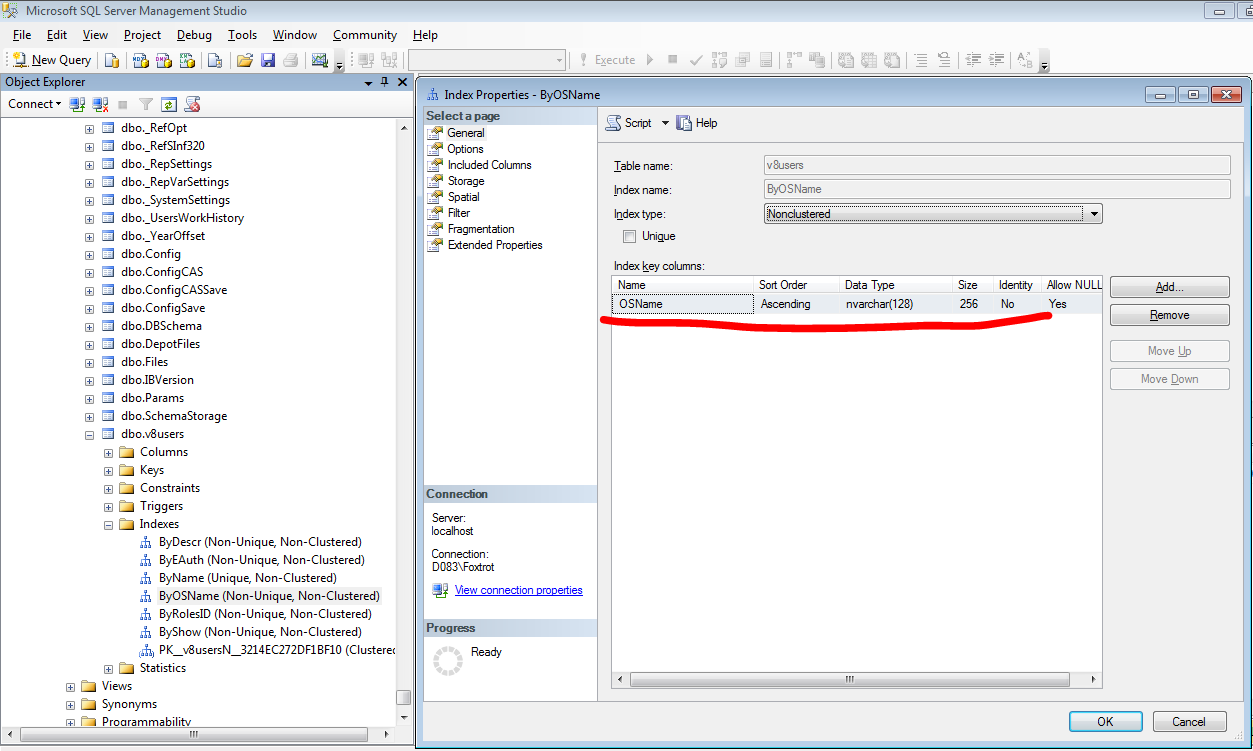
Видимо из-за размера поля OSName такой план запроса.
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x00000000000000000000000000000000,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE OSName = @P1 AND ID <> @P2
ORDER BY OSName',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'\ localhost Foxtrot',0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name = @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'Admin',0x952A5019EAE6A1F74023E7966E3EE1DE
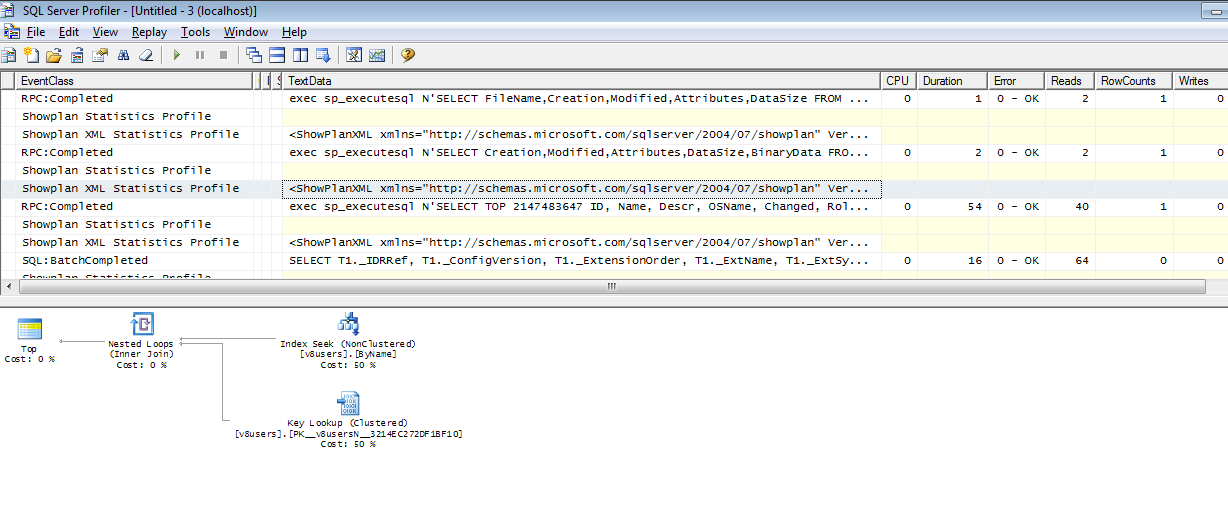
Поле Name меньшего размера, чем предыдущее – и план проще. Если кого-то заинтересовало мистическое число 2147483647, то есть статья в Википедии.
Последующие запросы дополнительно выполняются при запуске 1С:Предприятия из конфигуратора в режиме отладки. Все они лишь вариации предыдущих запросов, так что вопросов, думаю, быть не должно. О назначение каждого можно без труда догадаться, хотя конечно есть и вопросы.
Например, 0x952A5019EAE6A1F74023E7966E3EE1DE – это уникальный идентификатор пустой записи. Так вот не совсем понятно, для чего в каждом запросе писать:
ID <> 0x952A5019EAE6A1F74023E7966E3EE1DE
Ведь это только тормозит выполнение запроса. Тем более, что результат первой части запроса почти во всех случаях уникален.
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name >= @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'',0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x9615C386AE786E744E60B9E4F7DD290A,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x9615C386AE786E744E60B9E4F7DD290A,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name >= @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'',0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x9615C386AE786E744E60B9E4F7DD290A,0x952A5019EAE6A1F74023E7966E3EE1DE
Все эти запросы 1С выполняет при запуске, и как решение проблемы медленного запуска можно запускать программу только один раз после каждого обновления конфигурации. Но как оказалось этого недостаточно. Дело в том, что еще есть регламентные задания. Так вот при каждом выполнении каждого регламентного задания выполняется дважды еще один запрос:
SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(NOLOCK)
WHERE EAuth IS NULL OR AdmRole IS NULL OR UsSprH IS NULL
Хорошая новость в том, что SQL-сервер при повторном выполнении использует результаты первого, то есть выполняет мгновенно.
При внешнем подключении выполняются все три запроса.
Чтобы управлять таким количеством пользователей был создан справочник «Пользователи» с реквизитом УИД, который синхронизировался с таким же полем таблицы v8users.

Ниже код синхронизации. Текст приведен не полностью, без вызываемых функций, но думаю, что их названия не вызовут затруднений в понимании назначений.
В качестве эпилога
При большом количестве пользователей не рекомендую лишний раз пользоваться методом ПолучитьПользователей() объекта ПользователиИнформационнойБазы потому, что он возвращает массив. Так что придется обождать пока не получите его целиком. Здесь впору кричать «массив, Карл!» Почему так было сделано, остается еще одной загадкой. Почему нельзя было сделать выборку, например как у справочников или документов:
Выборка = Документы.РасходнаяНакладная.Выбрать(ДатаНач, ДатаКон);
Время ожидания сразу же бы сократилось в разы. Метод ПолучитьПользователей() на стороне сервера выглядит следующим образом:
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name >= @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'',0x952A5019EAE6A1F74023E7966E3EE1DE
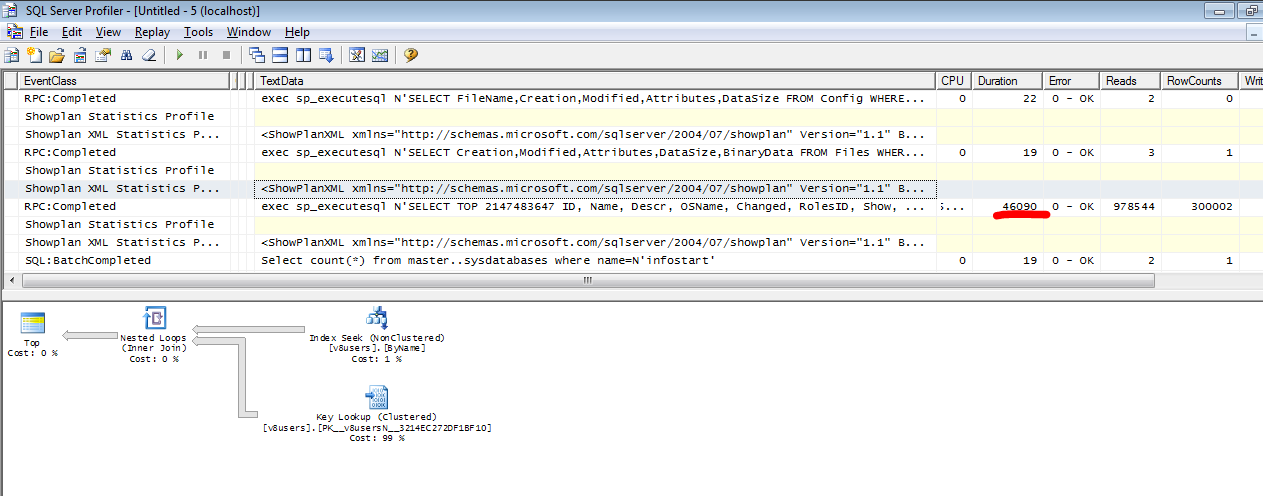
И план так себе, за то на выходе имеем массив. В моем случае из 300 тысяч элементов.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Чем больше пользователей, тем ниже производительность 1С. Это должно быть понятно без экспериментов.
Вы пришли к выводу, что не стоит работать в 1с?
Или не стоит обращаться к методам 1с?
Поясните пожалуйста ваши выводы.
ребята из фейсбука, телеграм и прочими с тобой не согласятся
(2)У них как бы и не 1С…
Транзакции с большим количеством записей (строк/движений) можно сравнивать в Фейсбуке разве что с загрузкой группы файлов.
можно краткое сообщение а ля Выводы
Вывод1:
Вывод2:
Рекомендации:
—
—
а то лень вникать в эту плащанину — обилие скринов и выкладок, конеш, круто, но наиболее ценны результаты эксперимента,
которые, надеюсь, спрятаны в этом мессиве.
(0) даже если 1С теоретически выдержит запуск 300 тысяч пользователей как вы написали, запускать их на один сервер — безумство из-за цены ошибки, которая в этом случае получает коэффициент 300000
т.е. съедает код ошибочно 1 пользователя и избыточно одно ядро, так при вашем подходе вы положите любой сервер умножив ядра на коэф.-т
нарушается принцип изоляции ресурсов у процессов, которые между собой не пересекаются ни по данным ни по связям
кроме того вы забываете, что у каждого сервера свой предел, с таким же успехом можно исследовать ноутбук, сколько тыщ юзеров выдержит при том что предназначен он для одного пользователя, улавливаете или нет?
берете наш тест , запускаете второй тест и получаете цифру гарантированно работающих пользователей
и не сильно важно что они делают
причем тест не покажет даже тысяч, но делать можно в пределах заявленной цифры большинство реальных задач
если ваше решение горизонтально масштабируемо, то новые пользователи должны не в одни и те же таблицы попадать
и тут важнее генерация сразу финального объема данных, которых будет в продуктиве и ни когда не будет превышен
пишите покрывающие тесты и радуетесь
пользователи в базе не сами по себе, залогинились и чай пьют, а прежде всего являются инициаторами параллельного ввода или чтения данных, поэтому важнее способность системы не топить диски данными, как только они перестают откликаться в разумных пределах, т.е. стресстест достиг порога возможностей системы
(6)ваш тест учитывает кластеризацию?
(7) даже сама формулировка говорит многое о вашем восприятии.
Сможете дать определение что такое кластер? кластеризация?
Вы либо
не понимаете что спрашиваете так как масштабируемое решение это не одна база данных и все последующее и вытикающее из этого в том числе что тот же кластер 1С (который кстати на одном сервере называется вырожденным) ни какого отношения к масштабируемости не имеет и мало влияет на горизонтальную масштабируемость
либо
заменили цель и средство ее достижения
если сервер 1С окажется слишком слабым по количеству ядер (будь то один рабочий сервер или несколько в кластере), то наш тест в явном виде не скажет что ядер не хватает, но количество пользователей уменьшит так как работа фоновиков 1С чувствительна к этому, т.е. формальный ответ при несбалансированности железа тест G1C это укажет, даже если серверов будет несколько.
значит ответ — нет
и не собираюсь гуглить и копипастить ответы на твои вопросы, проще разбанить твою учетку в гугле
есть что спросить по самой статье? или высказать замечания?
речь в ней ведь не про твой тест. если очень прям хочется прорекламировать его, то давай тогда отдельную статью напишу. или ты только заглавие прочитал?
речь ведь про нехватку индексов и запросы 1С при старте непонятного содержания
Вам не понятно. Разработчикам понятно. Ценность статьи тоже под вопросом.
Есть не оптимизированный код 1С, запроса,… под 300тыс.
Можно оптимизировать. Только смысл этим заниматься, если и так работает, а вероятность появления в базе 300тыс. пользователей ну очень маленькая.
Оптимизация — это дополнительные ресурсы разработчика.
Соответственно — либо вылизанный продукт под 300тыс. пользователей, но скажем за 1млн $, либо не очень — за 1000$.
За 1млн$ купят мало. А за 1000$ — много. И тем кто купит за 1000$ с вероятностью 99,9999% — не нужно 300тыс. пользователей.
(10)твоя позиция понятна, но я ее не разделяю
А зачем это изучать? Слону понятно,что база 1с даже на 1000 пользователей оедко используется.
(12) что за чушь?
1000 пользователей — это записи таблицы. Речь в статье именно про это. Везде и повсеместно такое.
Вся эта говша выполняется независимо от режима запуска? (толстый, тонкий, веб)
(14) да и конфигуратор впридачу, только там вроде как всего три запроса
Спасибо, полезно
Эта статья напоминает анекдот про мужиков и японскую бензопилу.
Стальную трубу она не распилила.
Обнаружился неоптимальный запрос к таблице, в которой всегда мало строк?
Сделаем строк много и скажем, что запрос медленный!
(6) Т.е. кейс, в котором в v8users несколько десятков тысяч пользователей, а сеансов в ИБ порядка пары сотен, Вы не рассматриваете? А зря. Это типичный случай для 1C:Fresh.
(7) Да он даже с гипертрейдингом не работает. Не говоря уже о многоядерности, NUMA, нескольких рабочих процессах и тем более кластеризации сервера приложения. Потому что прикладной код выполняется однопоточно, а наша звизда считает, что скорость выполнения одного потока (в синтетическом тесте) — подходящий критерий для оценки допустимой многопоточной нагрузки (продуктивным кодом).
к сожалению, каждый видит то, что хочет…
в статье не сказано про одновременную работу большого числа пользователей
я лишь хотел привлечь внимание на то, что в какой-то момент система начнет тормозить из-за, скажем, большого числа уже уволенных сотрудников
и тестировать в попугаях то, что не касается сути вопроса, это либо сознательный уход от вопроса либо профанация. тем более, что тесты писались совсем под другую старую систему
(19) многопоточно, и тон сбавь
(18) типичный случай для 1С:Фреш тотальная эскалация блокировок, другое дело что вам это не интересно, цель что то псевдоумное ляпнуть налицо
(22) Конечно не интересно, поскольку на практике этого не бывает: платформа выше разделителя не эскалирует, а соответствующий флаг на SQL ставится в плейбуке его установки.
Итак, кто из нас ляпнул псевдоумное?
(23) запрещающие флаги не работают 100%, при нехватке ресурсов блокировка все равно укрупняется
плюс проблема фрэша не в том что кто то один заблокировал 10 000 строк одним запросом, а в том что словить эскалацию блокировки можно 100 пользователями заблокировав безобидно по 100 строк — тут общее количество блокировок суммарно имеет тоже значение
иди еще практикуйся
все это верно, но никак не относится ни к одному из поднятых в статье вопросам
(24) увлечение пиаром плохо влияет на профессиональные навыки.
Внимательно и вдумчиво читаем про флаг 1211, в частности, описание возможных последствий при наложении большого количества блокировок. В дальнейшем просьба воздержаться от попыток подмены документации вендора своими фантазиями.
В 1С не оптимизирована работа с сотнями тысяч пользователей! Шок, видео!
Почему разработчики платформы такое допустили? Видимо, потому что реалисты.
(18) Несколько десятков тысяч даже для 1C:Fresh — вряд ли типичный случай. И предположу, что при использовании разделителей ситуация все-таки иная.
лучше б ответил кто на поставленные вопросы, а то обсуждение ушло в совсем другую сторону
(26) вам не нужна правда, вам нужна правота и подтягивание фактов под нее
во-первых многие до сих пор работают на старых версиях MS SQL Server и в разных версиях флаги либо вообще не присутствуют либо работают с другим алгоритмом либо вообще с другими субд
во-вторых про этот флаг мы написали еще черт знает сколько лет назад
там же написано для одаренных что не все так просто — когда в блокировках миллионы строк, сервер начинает захлебываться в любом случае, эскалация не эскалация, все равно — проблем в ДНК тех кто кладет непересекаемые данные в одну таблицу
если разные организации работают с разными данными, то консолидация в одной таблице это жирный минус по масштабируемости в любом случае, это только в теории скулю запретили и типа все ок, а на практике попробуйте и узнаете что это не работает, и что укрупнение на всю таблицу сработает
Но особо радует что вы сами не читали указанную вами ссылку — там черным по белому написано
т.е. сама неработоспособность Вам не интересна.
Идите дальше вдумчиво читайте и прекращайте приписывать людям свои фантазии.
(27) в нынешней концепции имхо фреш не спроектирован под реальные десятки тысяч пользователей, хотя изначально на первых презентациях выглядело именно так что, что десять тысяч пользователей якобы можно посадить
но на практике это глупость конкретная
система должна быть масштабируемая горизонтально, т.е. добавил сервер и сажай еще пользователей,
а хранение в одной таблице немереного количества данных как разносить, по идее данные должны по разным дискам раскладываться разных серверов и при этом еще отказоустойчивость не потеряться, а как это реализовывать когда данные в одной таблице
«фейсбук» на 1С не реализовать из-за вот этого непонимания горизонтальной машстабируемости
имхо главную ошибку в 1С допустили когда поставили не правильно приоритеты — типа так легко и просто администрировать, ведь все в одном месте в одной таблице…
(30) еще раз
не путайте оперативную память с дисковой
в статье речь про количество записей в таблице, которые мешают нормальной работе
и не обязательно, что куча пользователей одновременно работают. это вообще к теме не относится
(30) хотя вот тут Грибанов говорит что они заново изобрели велосипед, и вместо вебсокетов и шардинга в сервере 1С они запилили Hazelcast с java, т.е. сами же отказались от сервера 1С как кэширующего сервера
с одной стороны это прогресс в понимании масштабируемости, с другой стороны ни одно дело до конца нормально довести не могут имхо, в результате ни платформа не горизонтально масштабируема, и еще непонятна судьба сервера системы взаимодействия
(31) количество записей таблицы индивидуально для каждого сервера с учетом его производительности
кому то 10 миллионов строк будет тяжело обработать, а кто то и 100 миллионов не заметит,
да и не важно это, потому что 1С тут тоже совершает ошибку — не контролирует максимально допустимый размер данных в одной таблице на одном диске, а это очень важно в горизонтально масштабируемых решениях
платформа изолирует программиста 1С с одной стороны от физического понимания процессов, а с другой стороны понимание протекания физических процессов крайне важно для крупных систем, так как код пишется от имеющегося железа и его возможностей и ограничений, а не наоборот
(32) Ваше требование горизонтальной масштабируемости от 1С похоже на требование «хорошей жизни» от правительства. Каждый первый горячо поддержит, только непонятно как этого достичь.
Финансовые приложения не очень хорошо поддаются горизонтальному масштабированию. Парой волшебных галок в метаданных его не реализуешь. Еventual consistency мало где допустима. С шардингом вариантов чуток больше, но тем не менее… Так или иначе это тонкие настройки под инфраструктуру конкретного клиента. Не говоря уже о многократно возрастающей сложности распределенных решений со всеми вытекающими последствиями для «доступно и всерьез».
Да, есть простые и понятные сервисы, которые относительно легко и универсально распределяются. «Система взаимодействий» — один из таких.
Но не платформа 1С как таковая и типовые решения на ней. В такого рода сложных продуктах всегда дешевле расти вертикально, пока это возможно за вменяемые деньги.
«Горизонтальное масштабирование» — это не волшебное лекарство от всех болезней. Там где его невозможно применить просто и прозрачно, оно приносит кучу своих проблем и доп-затрат и его бывает трудно назвать меньшим злом.
А фреш — это «облако для бедных». Он изначально не про масштабируемость, а про снижение затрат поставщика на сопровождение мелких баз. Вполне понятная история и ничего плохого я в ней не вижу.
(34) в IBM DB2 были распределенные данные и все необходимое еще до времен когда 1С начала дружить с данной субд
можно было просто начать использовать готовый механизм
это «про невозможность»
впрочем и в скуле можно сделать вручную (не в 1С) распределенную транзакцию, которая одновременно работает с несколькими таблицами в разных базах данных на разных серверах
только на скуле нет индексов знающих про распределение данных по нескольким физическим таблицам, но такую систему можно и вручную сделать
коллеги из софтпоинта вообще на объектах метаданных 1С целиком отдельные вещи запилили
не надо говорить что горизонтальная масштибируемость это блажь
просто для небольших компаний дешевле сервер помощнее купить, который «простит» ошибки и непонимание, а вот с ростом масштабов и тем более при хостинге сотен организаций провайдером понимание горизонтальной масштабируемости является залогом оптимизации затрат и расходов, делая бизнес рентабельным
Автор вроде неглупый, но для чего эта статья один аллах знает.
Извиняюсь за прямоту.
хех, аллахом меня еще никто не называл
статья о том, что кто предупрежден, тот вооружен