
Есть у нас регистр сведений с атрибутами документов. Строк в нем примерно 250 000 000. Да, миллионов. И иногда возникает естественное желание этим регистром воспользоваться. Например, так:
ВЫБРАТЬ
Документы.ИД КАК ИД,
Срез_1.Значение КАК Атрибут1,
Срез_2.Значение КАК Атрибут2,
Срез_3.Значение КАК Атрибут3
ПОМЕСТИТЬ
ДокументыСАтрибутами
ИЗ
Документы КАК Документы
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут1)) КАК Срез_1
ПО Документы.ИД = Срез_1.ИД
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут2)) КАК Срез_2
ПО Документы.ИД = Срез_2.ИД
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут3)) КАК Срез_3
ПО Документы.ИД = Срез_3.ИД
Опытный 1С-ник сразу видит, что три соединения с виртуальной таблицей противоречат стандартам разработки и хочет это оптимизировать. К тому же, нет условий на документы внутри срезов, что дает повод задуматься о производительности.
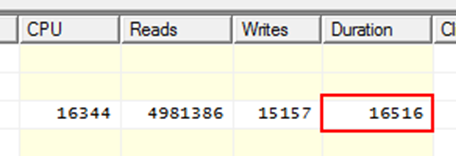
Программист идет в профайлер, смотрит время текущей версии запроса и видит это:
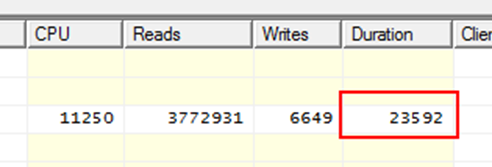
23 секунды, немного. Но и немало.
Пишет запрос, который выбирает атрибуты документов во временную таблицу. Добавляет условие по документам внутрь среза, потому что «так правильно» (https://its.1c.ru/db/metod8dev#content:2594:hdoc).
ВЫБРАТЬ
Срез.Атрибут КАК Атрибут,
Срез.ИД КАК ИД,
Срез.Значение КАК Значение
ПОМЕСТИТЬ
ВТЗначАтрибутов
ИЗ
РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут В (ВЫБРАТЬ ВТ1.Атрибут ИЗ ВТАтрибуты как ВТ1)
И (ИД)
В (
ВЫБРАТЬ
Документы.ИД
ИЗ
Документы
)
) КАК Срез
И соединяет полученную таблицу с документами
ВЫБРАТЬ
Документы.ИД КАК ИД,
Срез_1.Значение КАК Атрибут1,
Срез_2.Значение КАК Атрибут2,
Срез_3.Значение КАК Атрибут3
ПОМЕСТИТЬ
ДокументыСАтрибутами
ИЗ
Документы КАК Документы
ЛЕВОЕ СОЕДИНЕНИЕ ВТЗначАтрибутов КАК Срез_1
ПО Срез_1.Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут1)
И Документы.ИД = Срез_1.ИД
ЛЕВОЕ СОЕДИНЕНИЕ ВТЗначАтрибутов КАК Срез_2
ПО Срез_2.Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут2)
И Документы.ИД = Срез_2.ИД
ЛЕВОЕ СОЕДИНЕНИЕ ВТЗначАтрибутов КАК Срез_3
ПО Срез_3.Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут3)
И Документы.ИД = Срез_3.ИД
Здесь небольшое отступление, чтобы восполнить пробелы в структурах данных.
Таблица с атрибутами содержит 3 строки со значениями перечислений.
ВЫБРАТЬ
ЗНАЧЕНИЕ(Перечисление.Атрибуты.Атрибут1) КАК Атрибут
ПОМЕСТИТЬ ВТАтрибуты
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
ЗНАЧЕНИЕ(Перечисление.Атрибуты.Атрибут2)
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
ЗНАЧЕНИЕ(Перечисление.Атрибуты.Атрибут2)
ИНДЕКСИРОВАТЬ ПО
Атрибут
Таблица «Документы» довольно большая, там 300 000 строк. Колонок в ней немного, для данного примера это неважно.
ВЫБРАТЬ
Док.ИД КАК ИД
ПОМЕСТИТЬ
Документы
ИЗ
Документ.Какой_то_документ
ГДЕ
Какие-то условия
Довольный 1С-ник запускает новый запрос в надежде получить значительный прирост скорости и немигающим взглядом смотрит в монитор:
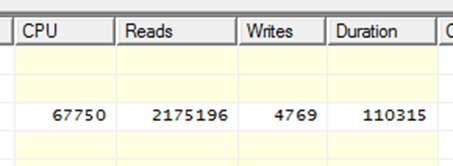
Хуже в 5 раз. Почему? Да потому что количество атрибутов разное. Атрибут 1 – 2000, Атрибут 2 – 120 000, Атрибут 3 – 120 000.
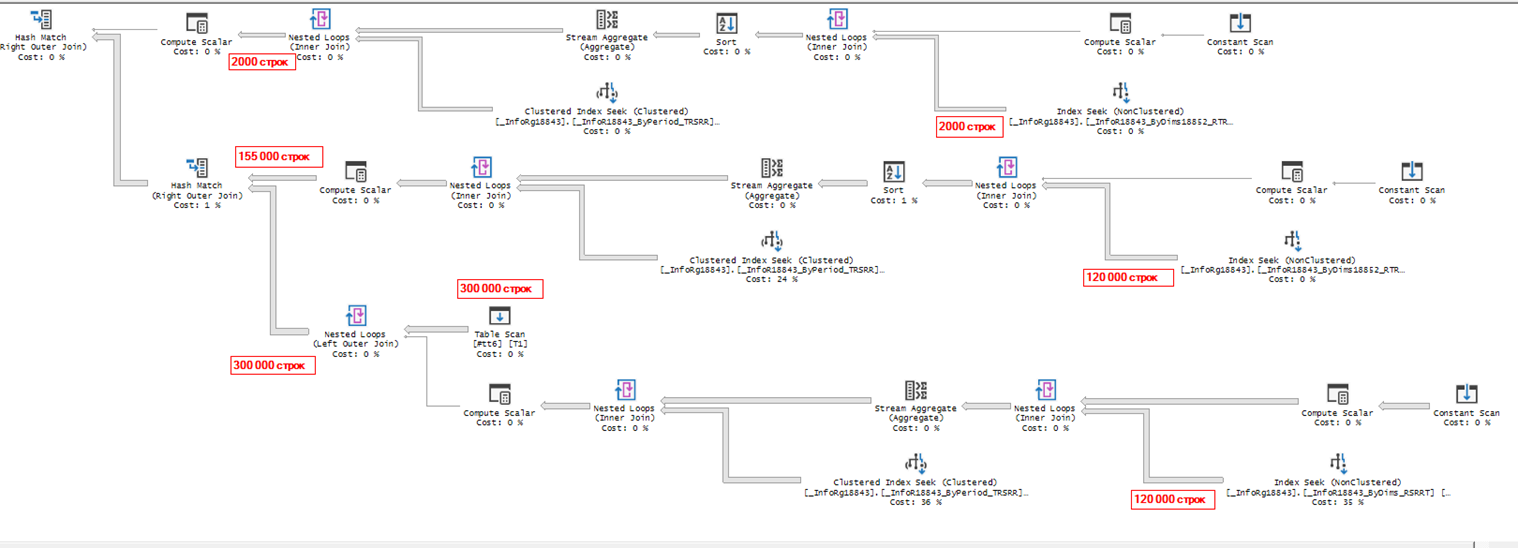
Посмотрим на планы запросов. Сначала на исходный, до оптимизации. Сервер считает, что лучше всего будет выполнить 3 поиска в регистре атрибутов по ИД документов (и, забегая вперед, скажу, что сервер прав).
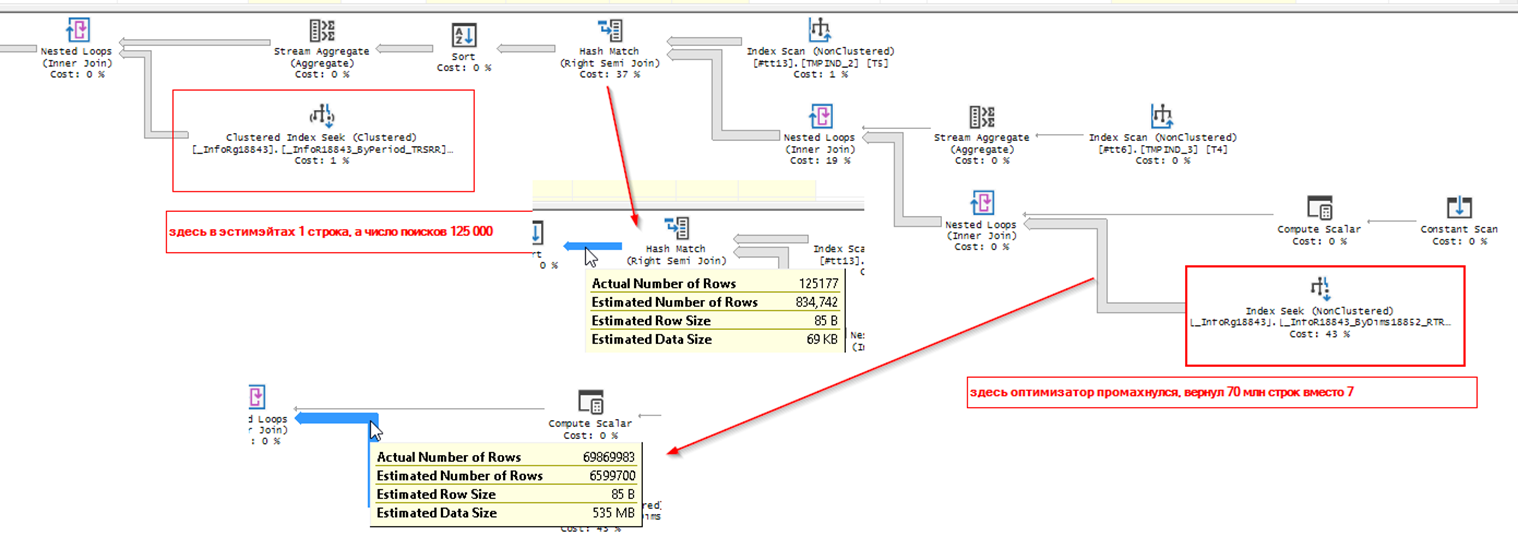
После оптимизации получился другой план, в котором сервер посчитал, что будет лучше сначала сформировать срез атрибутов по всем документам, и лишь после этого отобрать нужные документы. Причем, слегка промахнулся в оценке, выбрав в итоге 70 млн строк, вместо 7 млн. Одна из причин замедления — самый правый IndexSeek, выполнившийся 70 млн раз.
Путем недолгих размышлений условие на атрибут сначала было вынесено из среза наружу, но результата это не принесло, план остался тот же, только время снизилось за счет прогретого буфера. И лишь полный отказ от этого условия дал нужный эффект. Но этим самым мы вернулись к отправной точке, просто вынесли срез последних во временную таблицу.
Вот условие, о котором идет речь:
Атрибут В (ВЫБРАТЬ ВТ1.Атрибут ИЗ ВТАтрибуты как ВТ1)
А вот новые данные по запросу (на прогретом буфере).
План запроса вернулся к исходному состоянию (сравните с первым скриншотом, там 3 таких блока), что логично, т.к. запрос тоже вернулся к исходному.

Но это только срез последних. А ведь еще есть соединение с таблицей документов. На него тратится 5 секунд, и это нивелирует все усилия по оптимизации данного запроса.
Такой вот, безрезультатный результат.
P.S. Не то, чтобы я призываю к отказу от отборов в виртуальных таблицах, но иногда надо все же проверить, что получится в итоге оптимизации.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
В регистре сведений в каком порядке идут измерения?
Посмотрим за дискуссией
А существующие индексы нам знать не обязательно?
Без структуры регистра не пойдет
Измерения: ИД, строка (20); атрибут (перечисление). Кластерный индекс в формате 8.2, т.е. поле _period слева.
У документа есть атрибуты с разными датами?
1) Можно пример документа. Как определяются даты реквизитов и как контролируется их «правильная» последовательность?
2) Если отказаться от 1Совского среза последних, хотя бы для двух соедений, заменив их своим вариантом с дополнительным условием на дату документа/результата из первого среза, какие будут результаты?
А почему не индексируете поля временных таблиц, по которым в дальнейшем идет соединение?
Цитата: «Внимание! Не забудьте проиндексировать созданную временную таблицу. В качестве индексных полей следует указать все поля, которые используются в условии соединения.»
Мне почему-то режет взгляд первое измерение — строка — как то я не очень перевариваю их в регистрах…
у вас индексы весят как и данные?
почему то это мне напоминает статусы заказов..
А можно подробнее об архитектуре регистра и чем она обусловлена?
(5)
Выложите скрин структуры регистра сведений. Ничего не понятно.
Что за секретность ?
(5) Типичный регистр для таких целей.
Ну так делать отбор для среза в данном примере бессмысленно, что и показано. Оптимизировать тут нечего, словом совсем.
1й вариант — эталон, отбор по атрибуту, соединение по ИД, этого достаточно.
(8) Индекс в общем то не бесплатный. И индексация 70 млн строк может привести к еще более интересным проблемам. Одна из рекомендаций 1с: эксперт — по возможности отказаться от индексации временных таблиц.
(12) Понятно, спасибо. Но меня смущает слово «может». Пока не попробуем, не узнаем точно. Хотелось бы услышать мнение автора на этот счет.
(5) А что за измерение ИД (строка 20)? Это для связи с доками? Почему не ссылка на доки? И даже для гуида коротковата. Вы сами как-то идентифицируете уникальные доки?
(7)индексируются. Посмотрите на второй план, там справа есть 2 оператора IndexScan. Т.е. можно было и не индексировать. Эксперты правильно советуют не индексировать, т.к. временная таблица, как правило, меньшего размера и NestedLoops использует ее в качестве внутренней. Это всегда Scan.
(13) Индексируется. Но смысла в этом нет, т.к. в плане видно IndexScan.
Если не заморачиваться как в статье , то во-первых, нет необходимости три раза соединяться, можно 1 раз соединиться на таблицу и через выбор когда тогда значения устанавливать, использую группировку соответственно. Во-вторых, в каком порядке идут измерения «ИД» и «Атрибут», мне кажется атрибуты после ИД, почему в условии к виртуальной Условие на ИД не стоит первом и не оптимально было бы оставить только условие на ИД ? а на отбор с атрибутами не заморачиваться и сделать как написал выше.
Показать
Можно попробовать с временной таблицей, следуя рекомендациям ИТС, но так тоже должно быть более оптимально.
Секретности нет. Опубликовал статью и уехал в отпуск без компьютера. Не могу сделать скриншот со структурой регистра. Но состав полей я уже сообщил. Измерения: строка, ссылка на перечисление. Ресурс всего один — ссылка на справочник атрибутов. Выбрана такая структура, потому что нужна историчность атрибутов. Атрибута с типом Дата нет, поэтому альтернативный срез здесь неприменим.
А если не пихать всё в одну временную таблицу ВТЗначАтрибутов, а сделать 3 временные таблицы:
1. ВТЗначАтрибутов1 = СрезПоследних(&ПериодСреза, Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут1) И ИД В …)
2. ВТЗначАтрибутов2 = СрезПоследних(&ПериодСреза, Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут2) И ИД В …)
3. ВТЗначАтрибутов3 = СрезПоследних(&ПериодСреза, Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут3) И ИД В …)
проиндексировать все их по ИД, а потом все связки со срезами последних из исходного запроса заменить на связки с этими таблицами?
(18)
Спасибо, не понял сразу что атрибут — ресурс
(8) Совет по индексации временной таблицы даётся в расчете на то, что оптимизатор выберет MergeJoin. Это быстрее, чем NestedLoops, но вторая таблица также должна быть отсортирована.
(9) Строка в измерении это не такое большое зло, как может показаться. Документы приходят из разных внешних систем. Длина ИД от 6 до 10 знаков, в юникоде это до 20 байт. Для сравнения, ссылка занимает 16 байт. В итоге оверхед получается не слишком значительный. Размер индекса нетрудно посчитать, два поля из трёх — примерно 66% от кластерного. Подумываю сделать покрывающий вместо стандартного, чтобы из плана ушла операция KeyLookup.
(19) Интересная мысль, но может получиться так, то будет три раза использован второй план запроса и время из 110 секунд превратится в 330. Надо проверять.
(3) Индексы стандартные, кластерный по периоду и 2 некластерных по измерениям.
(21) Моя (и не только) практика показывает, что реальная польза от индексации временных таблиц — скорее исключение, чем правило. И ничего странного в этом нет, если подумать. Чаще всего временные таблицы не настолько велики, чтобы оптимизатор дал применению индексов зеленый свет. А на реально больших временных таблицах скорее всего хэш-таблицу строить будет.
(17) из этого примера на громадных базах конечно условие
ИД В (ВЫБРАТЬ Ф.ИД ИЗ Документы КАК Ф) должно оперировать с временной таблицей, а на очень больших базах я его еще и убираю из виртуальной таблицей в секцию ГДЕ.
Условия в виртуальной таблице все-равно в SQL «соскакиваю» в ту же секцию ГДЕ.
Документов порядка 300к, атрибутов 250 000к — в среднем порядок набора атрибутов на документ 1к
А сколько документов участвует в типичном запросе? Все? или есть все таки какие то типичные ограничения?
Показать
Ну а чтобы развернуть атрибуты в строку варианты можно как предложили (17) проверку в полях + группировка или поместить всё в ВТ и крутить как душе удобно добавив индексы.
Я уже весь попкорн доел… сколько интересного!
Кому то структура регистра не нравится, кому-то строковое измерение…кто-то агрегацию использует, кто-то пытается переписать срез, кто-то рекомендует ИНДЕКСАЦИЮ ВТ! LOL
Да нету тут ничего совсем! Оптимизировать НЕ-ЧЕ-ГО!
Берём документы, делаем срез как было показано в первом примере, и никакой временной таблицы не надо — она лишняя.
Для тех кто в танке и им все равно нужна структура этого периодического регистра:
Изменения (по порядку): ИД, Атрибут
Ресурсы: Значение
Это типичный регистр для хранения доп. значений объектов!
предлагаю оставить этот регистр в покое и использовать для истории (в смысле смотреть когда какой атрибут менялся), ввести второй — с текущими значениями атрибутов, т.е. 3 измерения ИД, Атрибут, Значение. понятное дело надо будет писать код обеспечивающий запись туда данных
(27) Документов примерно 150 миллионов. Это за полгода. В примере рассмотрен типичный запрос с интервалом в три дня. Обычно на один документ приходится 2-4 атрибута, иногда ни одного.
(30) За вас это уже сделала фирма 1С в платформе 8.3. Посмотрите на ИТС про итоги в регистрах сведений. Минусы этого подхода очевидны — рост времени транзакции на запись и рост размера таблицы. В моем случае прибавится примерно 80% от основной таблицы.
(32)
вы там так сильно заморачиваетесь и экономите место на харде? по-моему это последнее нам чем думают 🙂 рост времени транзакции пользователю будет абсолютно не заметен, а если вы возьмёте этот подход и не станете использовать возможности платформы — тем более.
могу еще подкинуть идею сделать Ключи Атрибутов, сгруппировав записи регистра. т.е. в регистре будет одна запись вместо трёх и соответственно с тремя ресурсами. но тут надо посмотреть на статистику использования ваших атрибутов. в любом случае скорее вы не будете реализовать этот подход из-за большой трудоёмкости данного подхода.
(28) А это вообще что? Срез последних из этого левого соединения не получится. И условие на NULL странное.
Размер таблицы 200 ГБ:) вся база — 1.2 ТБ. На боевом сервере рэйд из SSD на 1.5 ТБ. Мы реально заморачиваемся и экономим место, т.к. диски недешевые. Про составное поле думал, но пока нет четкого представления, как перестроить бизнес-логику.
Смысла индексировать таблицу из трех строк, конечно, нет никакого, ибо Лог2(3)=1,7 — выигрыш нулевой. По поводу срезов, то я бы от них отказался. Но тут зависит от того, сколько обычно вариантов атрибутов у документа. Как я понимаю, атрибуты документов могут меняться со временем. Если таких ситуаций -> 0, то смысла в срезе нет, а если их масса, то в идеале вообще производить выборку атрибутов как-то отдельно и потом уже соединять. Главное — минимизировать чтение из таблиц и избежать дополнительных упорядочиваний, добиться использования индексов без скана.
Я стараюсь такие большие таблицы выносить в отдельные базы и подключать их к 1С через внешние источники данных. Так гораздо больше возможностей по оптимизации (партицирование, сложные индексы и т.д.). Такой подход себя оправдывает не во всех случаях, конечно.
(37) Невозможно хранить ссылки:( Также нельзя инсертить и джойнить с таблицами внутри базы.
все же не понятно почему вредит именно «условие срезе последних»
(34) Это именно срез последних и есть и именно за счёт вот этого странного условия на null
Проверьте.
Интересно увидеть план запроса на ваших данных. Генерировать у себя пока не стал.
(40) Остроумная конструкция. Первый раз такую встречаю.
(41) Когда мне такой вариант получения среза показали я просто был в восторге от гениальной простоты (и до сих пор поражаюсь). А самое главное что можно делать срез по каким угодно критериям и измерениям/реквизитам и вообще не по регистрам, а по чём угодно!
(42) Все способы ручного получения «последних» — универсальны.
Что касается этого, было бы интересно сравнить производительность с классическим двух-этапным вариантом и вариантом с коррелирующим подзапросом.
(36) Я ведь и попытался сделать выборку атрибутов отдельно. Сами видите к чему это привело.
(40) Картинку видите в моем посте? Строки, где есть NULL, будут результатом вашего среза для моего регистра. Как-то не похоже на срез последних. Ошибки нет у вас? Если взять Макс(атрибуты_последний.период) и условие НЕ NULL, то становится больше похоже на правду.
(45) Очень сложно разбирать рукописную табличку. Ваш вариант можелировал запросом во вложении.
(40) ну ну.
Логически результат будет верный.
Если в рс счёт идёт на миллионы строк, но такой подход быстро превращается в тыкву, ибо СУБД быстро отхлебнет
Что-то не нашел ни решений, ни выводов… ни полных планов запроса (можно же сохранять по человечески, а не картинками).
Ни структуры регистра… ИД надеюсь у вас первым стоит? Иначе быть беде…
Интересно, какое время занимает скан индекса по измерениям?
Не нашел теста такого варианта (не обязательно тестить 3 среза сразу):
Из практики — он должен быть самым производительным.
Плохо или хорошо условие в срезе — зависит от многих факторов: от самих условий, от типа соединения среза с внешней таблицей…
Встречаю часто, что 1С любит в условия запросов (при условии в параметрах) добавлять EXISTS (SEL ECT 1 FR OM ….) — вот вам гарантированные NLoopsы и миллиарды/биллионы чтений.
Не нужно морочиться однозначными выводами и рекомендациями (никому не советовал бы их делать), потому что существуют разные типы и версии субд с кучей вариантов настроек, tf, влияющих на оптимизацию и компиляцию планов.
Да, есть советы и примеры, когда что-то явно тупит, но лучше иметь свой опыт. На чужом далеко не уедешь (
Да, срез может сильно удивлять и доставлять проблемы (особенно с периодичностью по регистратору, или на PG), как вы ни пытаетесь лечь под индексы.
(17) если убрать условие в параметрах, то план может быть проще, короче, быстрее. Оно ни к чему. Мсскл все равно строит план так, что нужная выборка будет получена «сразу», несмотря на многократную вложенность запросов.
(35)
КРУТО!
(49) Вернусь из отпуска — попробую.
(46) Проверил, действительно работает, как срез последних. Это я забыл, как строится left join:)
(50) Ничего крутого. Backup — 50 минут, Restore — 40. Опыта конечно добавляет. Начинаешь думать о последствиях изменения любого флажка в реквизитах регистров. Становится единственным возможным способом включить индексирование на колонке — создать новый индекс в SSMS.
(52) Очень хочется план и результаты измерений для такого варианта увидеть.
Был бы ОЧЕНЬ признателен. Да и другим тоже будет интересно и полезно думаю
(54) Выложу в понедельник
(56) ТЫ типичный 1с-ник?
Откройте для себя планы запросов, уровни оптимизации запросов, логические и физические операторы, построение планов выполнения (читай — «порядка физических манипуляций с данными») и прочие области психиатрии.
Но если вдруг вы со всем этим знакомы, то откуда такие выпады?
Представьте три уровня вложенных запросов с условием только на внешнем уровне:
Выбрать Поле Из (Выбрать Поле Из (Выбрать Поле Из Таблица)) Где Условие
Вопрос: будет ли СУБД сканировать (получать по вашему) всю таблицу на вложенных уровнях?
Ответ: конечно же нет.
СУБД пошлет и 1с, и программиста в… и применит это условие на нижнем уровне.
Вот такие разрывы шаблонов…
Так и в моем примере… Наложение условий соединения будет выполненно в первую очередь, т.е. «на нижнем уровне».
(35) слишком большая таблица, задумайтесь над тем чтобы её начать пилить. возможно некоторые атрибуты можно перенести в табличные части документа. как например был единый огромный регистр Значения свойств объектов, который был «размазан» по табличным частям объектов
(58) Ее используют 2 вида документов, поэтому нет смысла делить. Вместо одной на 250 млн строк получим две, на 100 и 150 млн.
(59) да, но типы таблиц то разные. там РС, а получите более простую. попробуйте перенести и выполнить замеры на тесте.
(57)
Только если СУБД достаточно интеллектуальна. Мы же, свою очередь, должны помочь ей это сделать, чтобы СУБД выбрала оптимальный план.
Но судя по вашему запросу, вы лишь затрудняете это.
(61)
спорное утверждение
(60) Это невозможно по архитектурным причинам. Документы тоже в регистре сведений:) В двух регистрах, если точнее. Почему? Так увидел архитектор(не я). Они затем агрегируются, чтобы записать не миллион проводок в хозрасчетный, а десять.
Зря Вы статью цитировали. Там речь идет о виртуальной таблице срез последних с _отсутствующей_ датой среза. В платформе 8.3 такой запрос может обращаться к таблице итогов, использование параметров внутри полностью оправданно. У вас же дата среза используется.
Правда заключается в том, что виртуальные таблицы не все одинаково полезные. Например, таблица остатков полезна безусловно, а срез последних с датой или обороты с детализацией до регистратора — бесполезные, лучше обращаться к регистру напрямую.
Без доступа к базе конечно сложно говорить, но как вариант можно посмотреть фрагментацию индексов и статистику. Возможно их нужно перестроить и обновить, по дефолту SQL обновляет статистику не по всей таблице, а по ее части, что в некоторых случаях может иметь негативный эффект. Обычно указание отборов (не сложных) в параметрах виртуальной таблицы все же приводит к увеличению скорости запроса.
Готов на спор повозиться с вашим регистром и улучшить время запроса с 23 до 10 секунд ))
(62) Значит стандарты, методики и рекомендации 1с вам не знакомы.
Тогда, специально для вас:
Не стоит надеяться на ai субд.
(67)Можно сгенерировать аналогичный объем строк и попробовать ускорить. Вся информация есть в топике и комментариях. Или могу продублировать сводно.
(68) только не говорите такое Морозову, Богачеву… Они на экзамене или тренинге как раз пример такой приводят, что не все золото, что стандарт 1с. И разжевывают причину этого…
Не бросайтесь злыми словами, а потрудитесь сравнить планы запросов и сами запросы в СУБД… Там все предельно просто и понятно. Причины на лицо.
ПС: «достаточно интеллектуальна» — смешно… Вы окончательно меня убедили, что не владеете механизмами MSSQL или хотя бы PGSQL.
(64) предполагается, что итоги (срез) не включены (это слишком просто, чтобы вообще обсуждать). Речь конкретно про проблемы соединения с обычным срезом.
(67) 10 сек — это тоже не решение. Вне зависимости от объема таблицы поиск по индексу и отсутствие миллиардных циклов — это всегда доли секунды. Много миллиардные таблицы тоже возвращают данные за 0.0ххх сек.
Здесь или что-то вроде 0,5 или долгая дичь…
(70) А вы не убедили меня, настаивая на том, что оптимизатор — «бог», он все сделает как надо.
У меня есть платформа 8.2, sql2014, регистр с ценами на 70кк записей. Проведу тесты с очисткой статистики и кеша, а также поковыряюсь в настройках субд. Но я все же найду контрпример, чтобы заткнуть сего умника.
Пока нет возможности протестировать на сервере SQL. Шаблон для генерации данных в прикреплении.
(73) ой все…
Я не говорил, что запросы работают всегда одинаково. Естественно планы компилируются по разному в зависимости от условий, на процесс можно влиять.
Всегда можно сделать плохо. Это не нужно доказывать. Дурное дело не хитрое.
А вот хорошо сделать не всегда получается.
В 99.999% случаев (если специально не мешать) СУБД скомпилирует хороший быстрый план.
Короче, спите дальше в своем неведении. Хотите показать себя грамотным человеком — покажите положительный, а не отрицательный результат.
(72) Десять секунд — это время, полученное простым расчетом: вместо трех соединений использовать одно в три раза быстрее. И я тоже думаю, это не предел. Идея простая: использовать обращение к самой таблице регистра без среза.
(69) Поймите, когда я сгенерирую аналогичный объем и поспорю сам с собой, то выиграю спор самостоятельно. Я ожидал с Вашей стороны нормальное предложение спора.
(77) Не понимаю смысла этого спора. Если у вас есть желание заняться оптимизацией, то все в ваших руках. Если получится сократить время до 10 секунд — ваше кунг-фу сильнее:)
(78) я занимаюсь оптимизацией либо за деньги либо за азарт. Вам ваш запрос безразличен или у Вас есть интерес его ускорить ?
(75) Ясно, «слился». Мой «агр» был лишь на
Он не может быть производительнее по определению, а лишь идентичен, либо проигрывает. Вот и всё.
(79) Я помощи не просил. Ни за деньги, ни за азарт. Оптимизировать, отказавшись от среза я и сам могу. У меня уже есть процедура, которая по расписанию удаляет старые версии атрибутов. Ее лишь нужно подключить к продакшн-базе.
(81) да, попробуйте обращаться напрямую к регистру АтрибутыДокументов, группировать по полям Атрибут, ИД, максимум по полю Дата, условие Где Дата =< &ПериодСреза. Это должно работать быстрее чем срез последних три раза. Мне интересно, что получится. Напишите.
(76) А у меня идея другая: добиться использования Merge, вместо медленного HashMatch. Без tf, гайдов и других «секретных» приемов (а-ля, ща покручу скуль)))).
Не туда смотрите. Какая разница? В СУБД в итоге вы сделаете один и тот же запрос, тот же плохой план, вид сбоку. Они только в 1с будут внешне отличаться.
(83) я указал в (82), какой запрос нужно сделать. Надеюсь, автор попробует.
(84) Обязательно попробую, сразу после отпуска, в понедельник.
(83)Чтобы получить Merge сначала надо сделать Sort, а это недешевая операция.
(81)
тады проще ваще удалить дату
(86) все верно, но все относительно… Например, относительно хешджоина…)
Пробуйте и расскажите нам.
(40) План запроса пока не могу приложить, но время работы через left join и проверку на null в 10 раз хуже стандартного среза. Логических чтений в 15 раз больше
(89) Перечитал статью и комментарии.
Атрибут 1 – 2000, Атрибут 2 – 120 000, Атрибут 3 – 120 000
Документов 300 000
Судя по всему получается, что атрибутов других ещё ОЧЕНЬ много так что в первую очередь нужно отсеить их.
Так что нужно развернуть очередность джойнов чтобы документ подсоединялся в конце.
Нужен план и первого варианта и второго в котором с документом соединение третье, а не первое
Оптимельность зависит от количество документов, атрибутов и количество «вариантов» значения одного атрибута.
Вы забили на тему? Или не отошли ещё от отпуска?)))
Я погряз в других задачах, которые тоже надо выполнять. Думаю, на выходных займусь этой проблемой.
А почему нельзя написать примерно так:
Показать
И не нужно огород городить с 3мя соединениями к одному регистру
Огород с тремя соединениями работает быстрее за счет технологии, называемой PREDICATE PUSHDOWN. Проверено на практике, я пробовал выполнить запрос, аналогичный вашему. Когда MSSQL джойнит виртуальную таблицу, то оптимизатор применяет фильтры, наложенные на главную таблицу. Смотрим на запрос ниже. Оптимизатор применит условие Doc.Ref IN() не только к таблице _Document123 , но и к таблице движений регистра накопления _AccumRg567.
SELECT
Doc.Ref,
RegVT.Amount
FROM
_Document123 AS Doc
LEFT JOIN (SELECT
Reg.Recorder,
Reg.Amount AS Amount
FROM
_AccumRg567 AS Reg
GROUP BY
Reg.Recorder) AS RegVT
ON RegVT.Recorder = Doc.Ref
WHERE
Doc.Ref IN ( здесь какое-то условие отбора, например по количеству документов, помещающихся на одну страницу динамического списка).
Почему оптимизатор так сделает? Потому что незачем читать лишние данные, которые все равно окажутся не востребованы в джойне, т.к. это LEFT JOIN.
Кстати, Postgres так не умеет. Недавно столкнулся с проблемой тормозов в РЛС при пролистывании журнала. В фактическом плане запроса стало понятно, что Postgres читает 200 000 строк из таблицы регистра, а MSSQL на таком же запросе — всего 100. Время соответственно 10 сек на отображение 35 строк на PG и 1 сек на MSSQL. Вы все еще за экономию на лицензиях?
(94) это запредел для многих местных «гуру».»». ага. 🙂 Однако цена вопроса тоже становится слишком велика. Просто цена.MSSQL Standard (16 cores max)… Мильоны, Карл !!!
(94)жалобу на сборку постгрес от 1с на хотлайн 1с отправляли?
(96) Да. Но дело не в 1С, а в оптимизаторе Postgres.
(95) Standard — до 24 ядер
(
лицензия на 2 ядра — 187000 руб
(
на 24 ядра — 4.5 млн руб.прошу прощения, 2,25 млн.
Да, недешево.
(99) я,я, натюрлих. заграница тоже не дремлет. выбор становится всё сложнее…
зы по 14-му — 16. Ну не суть, конечно.