


Или как мы создавали комфортные условия административному персоналу на отдельно взятом складе.
Часть первая, художественная.
Вступление
История решения проблемы, с которой ежедневно сталкивается разработчик 1С при решении прикладных задач, связанных с оперативным учетом на предприятии.
Для начала определимся с тем, что такое оперативный учет. Оперативный учет, проще говоря, это когда решения на основе предоставляемых системой данных принимаются здесь и сейчас. Где нет "пометить на удаление" и "отменить проведение". Где вся структура учета строится исключительно из потребностей бизнеса без учета ПБУ, НК и проч-проч-проч.
Такие решения не очень популярны на сегодняшних день на платформе 1С, но тем не менее, потихоньку набирают обороты и, надеюсь, будут только шириться.
Самый простой пример оперативного учета — это складская деятельность при достаточно высоком уровне автоматизации склада. Высоким уровнем автоматизации давайте договоримся считать способность системы принимать решения и отдавать задачи исполнителям в режиме on-line. Подобный подход продемонстрирован компанией Axelot в конфигурации 1С:WMS Логистика. Управление складом.
В рамках разработки таких систем узким местом является сбор и наглядное представление данных для принятия управленческих решений и при контроле за исполнением задач в силу высокой динамики изменения входных данных.
Стандартные отчеты плохо подходят наличием кнопки "Сформировать" и весьма скромными графическими возможностями.
Разнообразные варианты форм с автообновлением по обработчикам ожиданий весьма прилично нагружают систему при мало-мальски существенном объеме выводимой информации.
Хочется чего-то легкого, красивого и понятного…
Завязка
К предлагаемому варианту решения проблемы подтолкнула, как не странно, квалификация инженеров на проекте. В рамках крупного проекта ежедневно приходится сталкиваться не только с проблемным поведением 1С, блокировками на СУБД, кривым кодом и нелепыми бизнес-процессами. Есть еще основа всего этого — локальная сеть с кучей оконечного оборудования. Начиная от свитчей и заканчивая терминалами сбора данных. А если копнуть еще глубже — то и у энергоснабжающих организаций бывают проблемы. И все это заканчивается банальным: "1С не работает".
В современных реалиях существует огромное множество систем мониторинга оборудования. Но у нас ее не было. И с нее пришлось начать. На первом этапе — завели Zabbix, начали собирать статистику со всего до чего смогли дотянуться. Потом потребовалось собирать данные с удаленных филиалов. И снова Zabbix, но расположенный на другом сервере и нам доступный только read-only. А потом возникло желание видеть данные единовременно с обоих серверов мониторинга. И тут на помощь пришла совершенно потрясающая платформа для мониторинга и аналитики — Grafana.
Лирическое отступление первое
После настройки системы мониторинга и выводом информации о жизненно важном аппаратном слое системы, жить на проекте стало несколько легче. Шишки перестали падать с такой частотой и с таких высот.
Однако решение проблем административного персонала было в зачаточном состоянии. Управление многоэтажным складом посредством отчетов и полубумажной технологией делало несчастными администраторов.
Попытки построения системы мониторинга процессов на внешних обработках делало несчастными разработчиков и сервер с СУБД.
А чувство прекрасного продолжало настойчиво требовать легкости и понятности.
Кульминация
По результатам созерцания аккуратных метрик в Grafana логично была предпринята попытка вытащить туда данные напрямую из 1С. Благо, есть плагин, позволяющий дергать данные непосредственно с помощью JSON. При обновлении дашбордов с метриками раз в 10 секунд (ибо отказы железа по-прежнему хочется видеть оперативно), начала проседать база 1С. Попытки выливать данные в Zabbix и работать от него закончились порванным бубном и стесанной до кости сушеной заячьей лапкой.

Начали подбирать варианты. Взгляд адепта красно-желтой литературы, отринув мысли о MSSQL и Postgree, начал обращаться в направлении сторонних продуктов. И после череды проб и ошибок остановился на проекте Prometheus.
Лирическое отступление второе
Prometheus — это, грубо говоря, TSDB (Time series database) — база данных формата NoSQL, организованная для хранения временных рядов, т.е. метрик. Плюс весьма неплохой ассортимент внешних плагинов для сбора данных. Плюс автоочистка истории. Плюс весьма скромные системные требования. Важное различие сборщиков метрик — это разделение на т.н. "pull" сборщиков — которые сами куда-то стучатся и требуют выдать им метрики и "push" сборщики, которые сидят и ждут, что к ним постучатся и принесут данные на блюдечке. Prometheus — pull сборщик, но при использовании плагина Pushgateway становится способен работать и в режиме push. В этом режиме отправка данных инициируется клиентом плагину, которого, в свою очередь, опрашивает Prometheus. И все это добро, как у нас принято, абсолютно free!
В терминах платформы Prometheus, сбор данных называется "scrape" — "соскоб". Т.е. берется срез данных на момент времени, ему присваивается timestamp (время взятия соскоба) и данные убираются в собственное хранилище Prometheus. Одно из выгодных отличий Prometheus является необязательность присвоения timestamp’а при отправке пакета с данным. При отсутствии метки времени присвоение происходит автоматически при помещении данных в базу Prometheus.
Чувству прекрасного для экстаза не хватало только понятности.
Развязка
Понятность пришла после конструирования подсистемы, обеспечивающей формирование метрик простыми кодом на родном языке.

Источником данных по-прежнему является 1С, однако хранение данных осуществляется в сторонней базе, а сбор данных происходит "соскобами", исключающими запросы с большой глубиной периода. "Соскобы" осуществляются двумя способами:
1) При построении данных статистики, необходимой для принятия решений (а мы помним — оперативный учет, да) происходит непосредственный push при самом выполнении регламентов или операций, что не требует повторного обращения к регистрам, да и вообще ничего больше не требует, поскольку сформированные метрики больше не касаются 1С.
2) Для съема метрик по фактически занесенным данным в результате жизнедеятельности пользователей, используется pull метод, когда регламентным заданием снимается срез данных (условно — остатки, не обороты) и заботливо подготовленные метрики ожидают запроса от Prometheus.
Обоими способами снятые метрики отправляются на хранение в Prometheus, откуда их читает Grafana с нужной периодичностью и с нужными временными границами.
Часть вторая, техническая, теоретическая.
Предлагаемый механизм связки с Prometheus является абсолютно бесплатным, никаких ограничений на модификацию кода нет и быть не может.
Решение собрано отдельной конфигурацией для удобства слияния с рабочей базой. Существование как отдельной конфигурации не имеет практического смысла, поскольку предназначено для извлечения метрик из непосредственно рабочих данных. Однако, конфигурация может быть развернута отдельно для препарирования и изучения — в таком режиме она полностью работоспособна.
Основным элементом конфигурации является справочник "Метрики", в котором содержатся алгоритмы сбора метрик.
Процесс описания метрики заключается в написании произвольного кода на языке 1С. Выполняется на сервере. Входные параметры отсутствуют.
В результате выполнения алгоритма получения метрики, должна быть сформирована переменная с именем "ТаблицаЗначений" и одноименного типа. В таблице значений в обязательном порядке должна присутствовать колонка "ЗначениеМетрики", в которое записывается числовой показатель метрики. Дополнительные колонки таблицы значений расцениваются как ярлыки (в терминологии Phrometheus), где имя ярлыка = имя колонки, а значение = строковому значению в ячейке. Эти поля удобно использовать для фильтрации данных при выводе в Grafanа.
Вариант PULL:
Регламентное задание конфигурации через равные промежутки времени запускает на выполнение все алгоритмы из справочника "Метрики" с типом pull не помеченные на удаление. Результат выполнения раскладывается в регистр сведений в текстовом формате, понятном Prometheus. При обращении платформы Prometheus к HTTP-публикации базы 1С, происходит чтение данных из регистра, агрегация в единый пакет и выдача ответом на REST запрос.
Вариант PUSH:
По событию системы вызывается элемент справочника "Метрики" и выполняется его обработчик. По окончанию обработки метрики отправляются в Pushgateway.
ИЛИ
Подготовленная любым удобным способом таблица значений с данными передается входным параметром в экспортную процедуру, которая форматирует данные и отправляет их в Pushgateway.
Настройки конфигурации:
— Константа "URL Pushgateway": адрес сбора метрик службой Pushgateway
— Константа "Число повторных запросов метрики": количество раз, которое метрика будет отдана Prometheus при повторных обращениях. Каждое обновление метрики обнуляет счетчик. Используется для исключения провалов графиков в случае длительного формировании метрики и/или частого опроса Prometheus’ом.
P.S. Критика, пожелания, дополнения — горячо приветствуются!
UPD 24.02.19: Присоединяйтесь! Разработка обрела свой адрес
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
круто, спасибо
Спасибо за конфигурацию
а каким образом происходит обращение? как это реализовывается в Prometheus?
(2) Предполагается, что «тяжелые» запросы пишут в регистр по факту выполнения, а Prometheus, который опрашивает систему раз в -дцать секунд вместо выполнения «тяжелого» запроса считывает метрику из регистра, предварительно туда записанную.
В дальнейшем предполагается обеспечить возможность считывания одной и той же метрики несколько раз до ее устаревания. Это необходимо, когда частота регламентного опроса Прометеем превышает частоту формирования «тяжелой» метрики.
(3) хотелось уточнить чем забирать данные из http-сервиса? как и чем это настраивается? это выполняет отдельное приложение?
(4) Данные забирает непосредственно сам Прометей.
У него есть понятие «Цель» — это те http-сервисы, которые он опрашивает с определенной периодичностью и забирает соскобы себе в базу.
В приложенном файле — настройка Прометея на 3 цели: сам себя — показатели статистики, PushGateway — для получения с него метрик из короткоживущих процессов (отправляемые в PushGateway методом PUSH) и база WMS, которая и является основным поставщиком данных.
(4) тут описание в т.ч. первичная настройка целей и частоты их опроса.
(6)
в prometheus.yml добавить:
Показать
вроде разобрался
(7) У Вас публикация выполнена на той же системе где стоит Прометей?
И есть подозрение, что кириллицу в части учетки Прометей не воспримет — не проверял, не знаю.
(8) Да, для теста там же
Нормально воспринимает
(9) Спасибо, буду знать!
Какой у вас рецепт для отображения http status code? поделитесь если есть
(11) Посмотрите код http метода get. Там есть формирование кода ответа.
(11) Дополню — часть кодов дает сам web-сервер, часть — 1С. Например, если публикация не сделана на web-сервере, получите 404 средствами web-сервера. А вот если публикация есть, но rest не соответствует шаблону — получите status-код силами 1С.
То что нужно, а то хотелось уже писать шаблон для ответа
(14) Под «силами 1С» подразумевал описанную программистом реакцию системы на http-запрос.
Пример из конфы в аттаче статьи:
Показать
Если сообществу интересно — на следующей неделе смогу опубликовать доступ к треккеру по ошибкам и фичам подсистемы. Можно попробовать совместную разработку, еcли есть желающие. EDT, Git и вся фигня.
— склад под управлением какой WMS?
Спасибо, полезно
Рассматривали ли вы в качестве TSDB InfluxDB?
(16)
да, а то даже нет возможности поставить ее на поддержку, пришлось свою сборку делать конфигурации поставщика
(17) Есть самописки, есть Axelot
(16)
Да, думаю идея отличная, думаю найдется куча людей которые внесут свой вклад в разработку. Особенно с учётом,
В идеале сделать готовую сборку, в виде Docker контейнера , с Prometeus, Grafana, сервером 1С и тестовыми данными, чтобы так — Docker RUN и экстаз..
Привет, а что не так с Заббиксом?
У меня с ним проблем не возникло, и Графана успешно начитывает данные с Забикса.
(16)Выливай на гитхуб уже =)
порадовало
А стек ELK рассматривали? Если да, то чем не устроил?
(19) Простота интеграции Прометея сыграла свою злую роль.
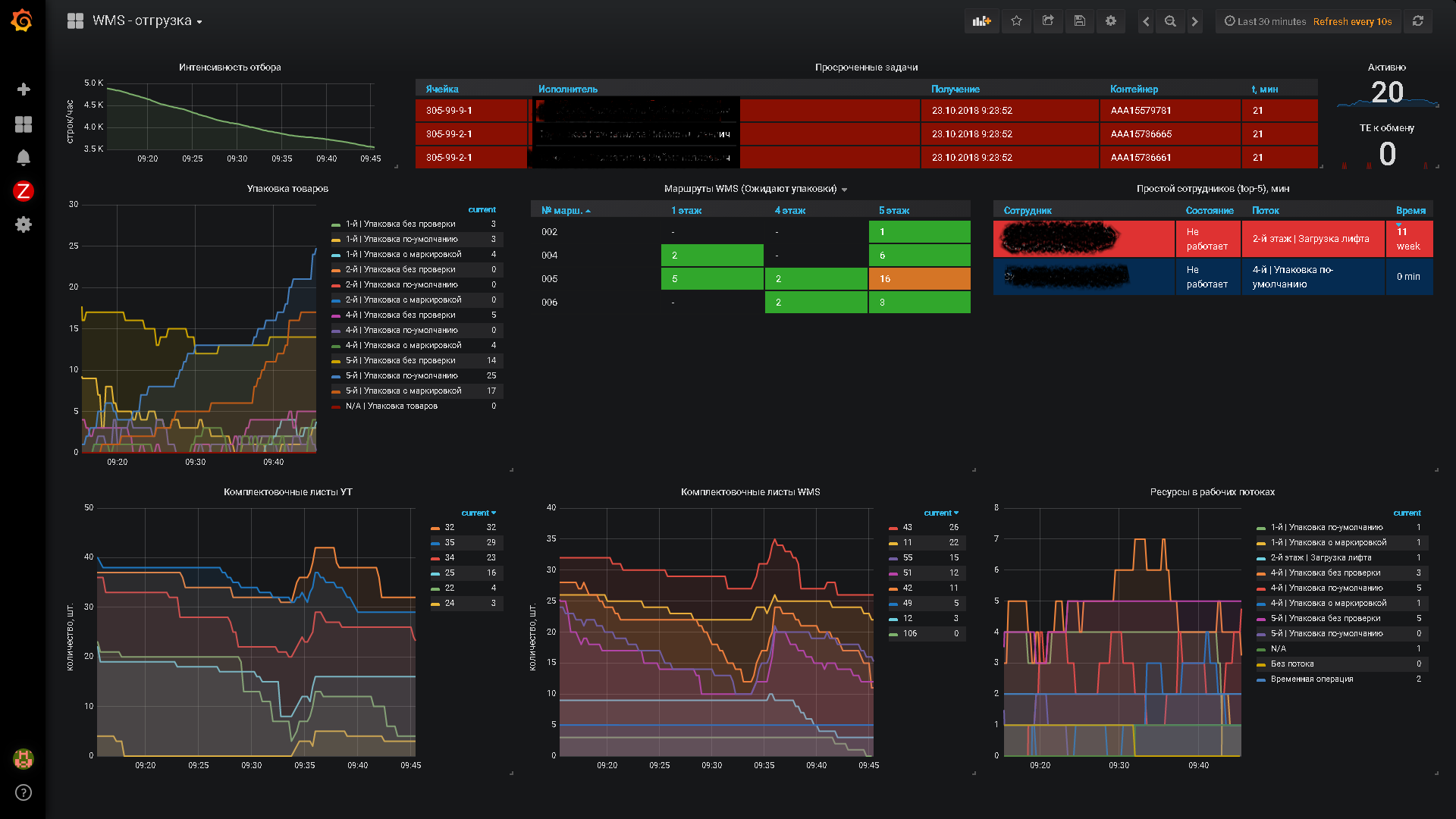
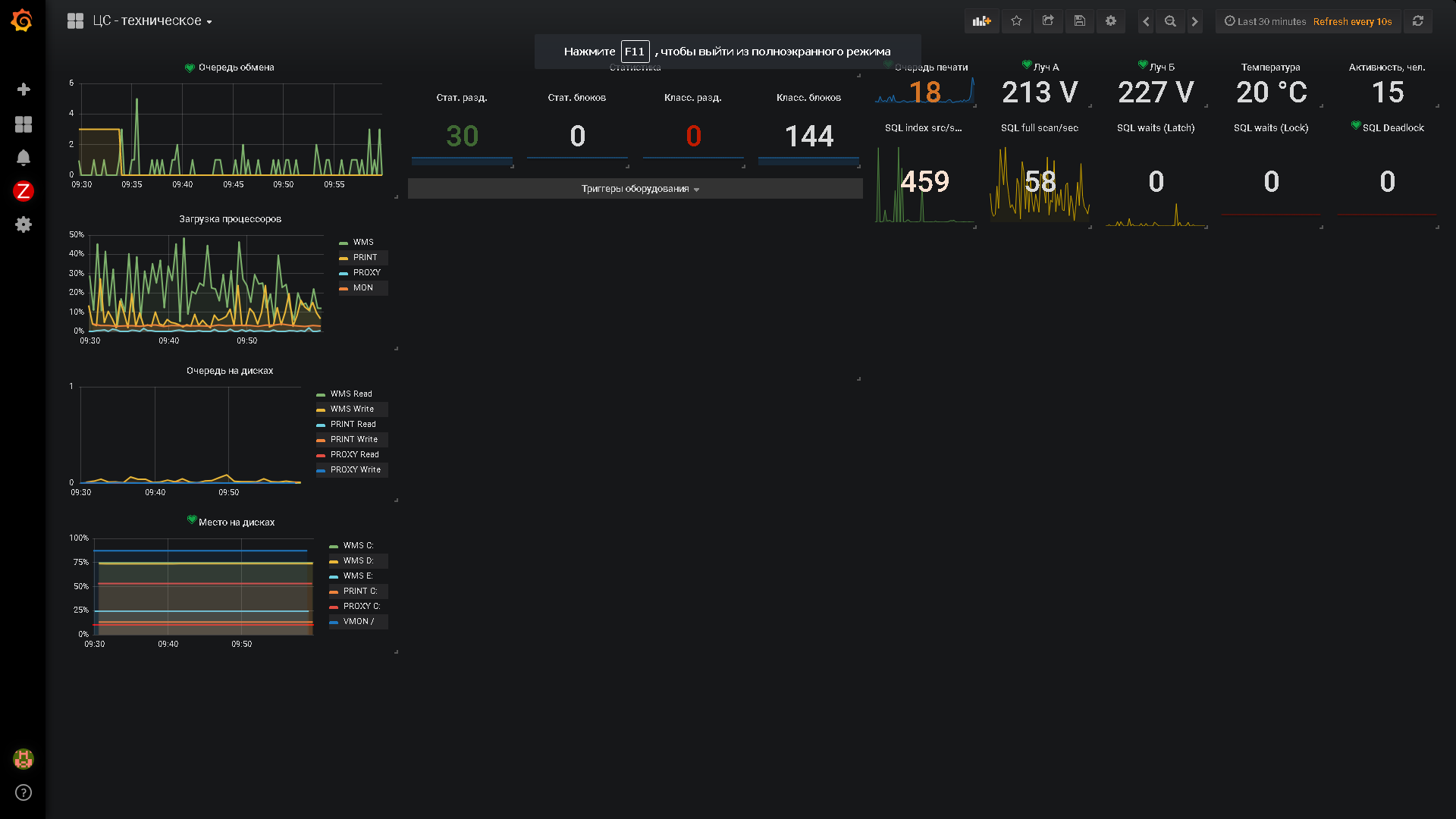
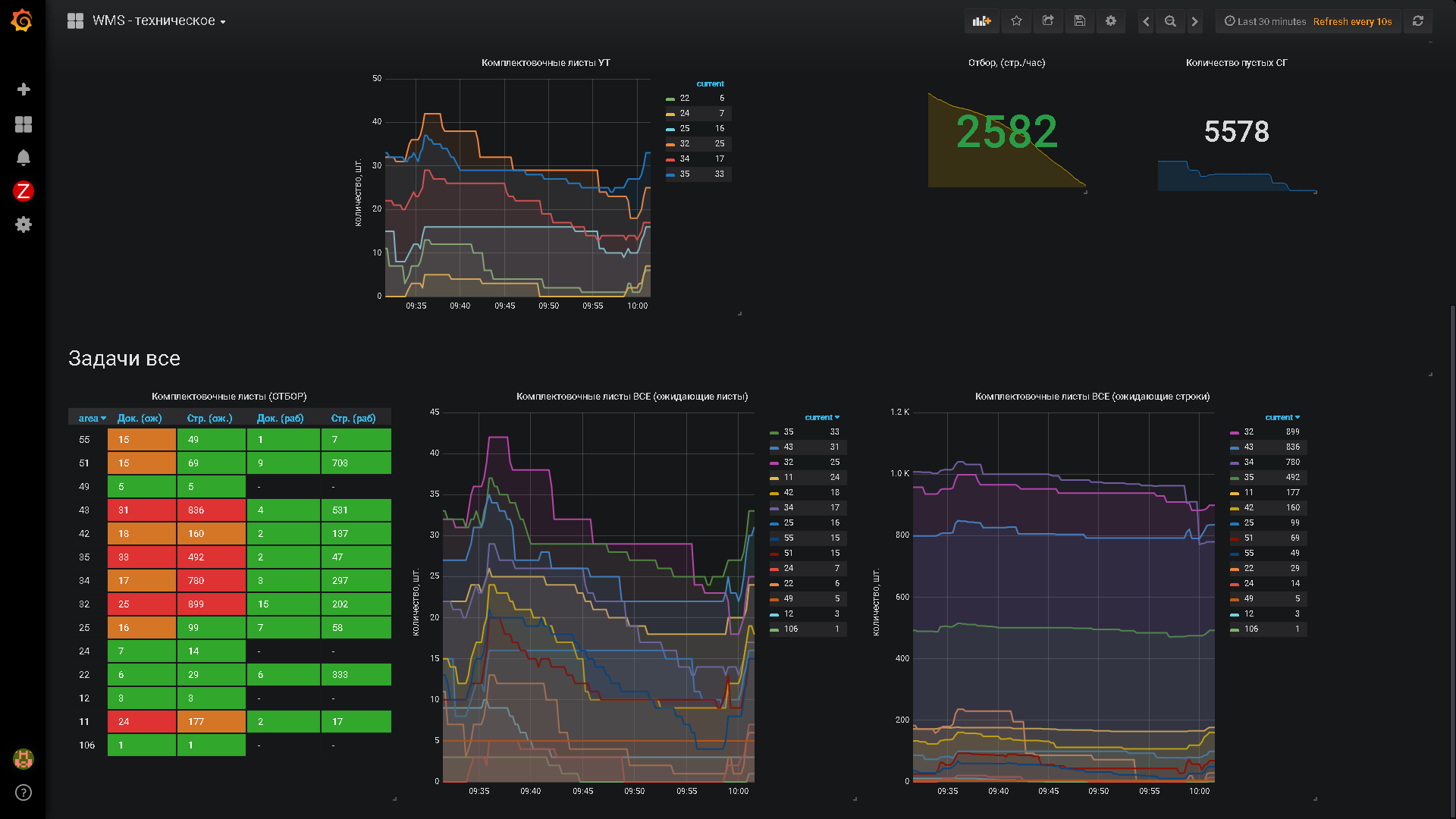
(24) На пикчах видно, что наша Графана выводит данные с 3-х систем — двух Заббиксов и одного Прометея.
Решали не проблему связки Заббикс-Графана — там проблем нет за исключением Алертов, а проблему «Куда деть данные оперативного учета из 1С»
(26) Интересный регистр. Не могли бы Вы пояснить назначение? Не могу понять потребность его скоблить.
(27) Elastiksearch вижу скорее как хранилище текстовых логов, а не упорядоченных временных серий. Как раз сейчас думаем на счет слива ТЖ в него для анализа проблем.
(20) (22)
Договорились! Отпишусь в теме.
(25) Леш, у меня свой локальный Git, поскольку я несколько параноидален.
(29) Данные оперативного учета я так понимаю нужны для
.
На мой взгляд Графана не совсем верное решение для таких целей, она для — цитата с офиц. сайта
, т.е. это все-таки тул для системного мониторинга.
В данном случае лучше подойдет PowerBI, который умеет не только представлять данные, но и крутить их в разные стороны.
(34)
Смотря что мы понимаем под оперативным учетом. Оперативный учет != отчеты о продажах за месяц. Оперативный учет на складе — это оценка изменения загруженности зон на горизонтах 30мин-1час, достаточности сотрудников по факту и распределение их по направлениям деятельности. И да, алерты по проблемным узлам тоже.
Это не аналитика. Это желание оперативно реагировать на возникающие проблемы по заранее выставленным контрольным точкам.
Рассматривали вариант, когда prometheus сервер находится вне локальной сети для получения метрик pull способом?
(36) Нам не приходилось, но в целом не вижу сложности. Если сможете обеспечить REST — должно работать.
если ресурс не умеет отвечать в формате prometheus тогда в тагретах пишет что
а по сути хочется только мониторить живучесть сервиса…
альтернатива писать прослойку — которая будет ретранслировать состояние сервиса? или есть еще варианты?
(38) Живучесть сервиса — Zabbix
(39) спасибо
(38) Есть вот такое расширение .
Вот здесь список официальных и неофициальных расширений (exporters) .
Очень познавательная статья. Спасибо Но
Попытки выливать данные в Zabbix и работать от него закончились порванным бубном и стесанной до кости сушеной заячьей лапкой.
Могли бы Вы написать подробнее — почему данный подход не получился. Это же «классический» подход по сбору метрик, и уже был описан на инфостарте.
И, хотелось бы больше слайдов и текста по проведения настроек связки продуктов друг с другом и самих метрик.
(42) Обратите внимание, какие метрики передаются в Прометея. Там накапливаются не данные о состоянии оборудования. Содержимое Прометея — это условные деньги в кассе, задолженности контрагентов, остатки на складе. Т.е. непосредственно данные бизнеса. Т.е. условные отчеты из условного 1С.
(43)Я просто не понимаю разницы в хранении (или нюанса передачи на хранение) данных о количестве соединений с серверов, количестве замятий бумаги на принтере, длинне очереди диска, или количества товаров на складе, количества занятых рабочих на складе, длинне очереди текущих заказов на сборку.
(44) Нюанс заключается исключительно в инструментарии, который для этого есть. Собственно, в Заббиксе достаточно достаточно сложный инструментарий, заточенный под сбор данных по железкам. С набором устоявшихся стандартных механизмов по отрасли.
Прометей позволяет сделать сильно проще использование системы со стороны наполнения ее данными. При этом, система прозрачна для программистов и позволяет организовать передачу данных привычным кодом на привычном языке.
Уточнюсь — обобрать данные в 1С запросом, затолкать в Заббикс, получить там несколько разрезов будет выглядить так:
— Содаем кучу хостов по ожидаемым разрезам запроса
— Формируем, скажем, JSON силами 1С
— Кладем его куда-нибудь
— Пишем скрипт парсинга полученного файла
— Наталкиваем в Заббикс
— Сталкиваемся с проблемой вывода, скажем, в таблицу в Графане
Прометей + приложенная конфигурация — сводится к написанию запроса. Остальное происходит силами самого Прометея. При этом, со стороны Графаны поддерживаются запросы, которые позволят не определять заранее разрезы вывода.
(44) имеется ввиду что периодически получаемые данные лучше где-то хранить и оттуда считывать Grafan-ой, нежели постоянно дергать 1С-ку и передавать в нее параметры, т.е. динамически получать
(46) Очень точно сказано.
Дополню:Это позволяет при складском учете работать «на переднем крае» данных. Т.е. держать в кеше СУБД их и, практически, не обращаться к диску.
Строить запросы, тем более глубокие — тяжело с точки зрения нагрузки на СУБД.
(47) Можете еще раз пояснить — почему ZABBIX не может работать в таком же варианте?
Точно также запрашивать 1С через веб сервисы и сохранять у себя данные. Он ведь все это умеет, разве нет?
(48) Пробуйте. Я не вижу в этом целесообразности потому что::
а) Сложности с механизмами подключения к 1С самого Заббикса.
б) Нагрузка на базу при вытаскивании данных периодами.
(49)
насчет пункта а) не соглашусь.
насчет б) да, такое может быть
(49) Пожалуй еще раз перечитать надо.
В итоге все выглядит красиво, но по-моему для многих осталась нераскрытой тема почему не стал использоваться тот же ZABBIX.
(51) Попробуйте получить Заббиксом из 1С данные, скажем, для построения графика динамики отгрузки клиентов с разбивкой по часам за сутки. Я правда не знаю как это сделать без насилия над собой и окружающими.
(52) Собственно в том и вопрос.
Мы просим Вас описать трудности, которые возникнут, если использовать Zabbix, и которые будут отсутствовать, если использовать Прометея.
Спасибо.
(53) Я не знаю типовых методов получения данных из 1С Заббиксом. В голове крутятся агенты Заббикса, дергающие скрипты, делающие выгрузки в текстовички из 1С но я это не прорабатывал, что бы выкладывать сюда. Отмел сразу на уровне идеи.
Добавил ссылку на разработку. Разработка ведется в формате EDT. Присоединяйтесь!
Добрый день.
Спасибо за публикацию. Очень интересно.
Подскажите для тех кто живет еще в прошлом веке и не использует EDT,
где можно взять архив с примером данной разработки?
— там релизные сборки.
Насчет критики zabbix не согласен.
Да, он больше заточен под работу с сетевым и серверным оборудованием, что несет в себе лишний оверхед в настройках.
НО
Никто не запрещает вам сделать правило обнаружение и создать одну метрику по шаблону в куче необходимых разрезов.
Так же никто не запрещает публиковать JSON из тех же регистров мониторинга и забирать его zabbix web agentoм. Zabbix sender такой же пушер, для синхронной отправки событий. Важно не отвергать забикс, если есть некий централизованный мониторинг и хорошая служба эксплуатации, которая не забывает на алерты и действует по регламенту)
В целом конечно верное и правильное решение использование прометеуса вместо забикса для мониторинга сервера приложений. Респект.
(58) Я уже писал выше и повторюсь — этот механизм не для наблюдения за сервером приложений 1С. За сервером наблюдает Zabbix, как и за остальным железом в сети, поскольку это проще.
Для этого есть, например:
Прометей предназначен для наблюдения за состоянием именно данных внутри базы данных. Т.е. за бизнес-процессами непосредственно.
(58) В продолжении — сделать в 1С JSON никто не мешает, но давайте представим, что нам нужно что бы собрать данные для отображения, скажем, статистики заказов к отгрузку:
1) В 1С — Создать регламент, который будет опрашивать данные и формировать JSON
2) В 1С — Куда-то положить сформированный JSON,
3) ЛИБО в 1С ЛИБО в Zabbix Agent настроить отправку. Не забыв о том, что 1С может несколько серверов приложений.
4) Самый ад: открыть Заббикс и настроить калькулируемые метрики (для каждого из разрезов аналитики), а так же при условвии, что новые данные (скажем, новый контрагент) заводятся в 1С, каждый раз при появлении нового элемента в разрезах аналитики — идти и донастраивать Заббикс.
Вот это вот всё и делает невозможным использования Заббикса для обработки данных. Слишком высокая трудоемкость обслуживания.
(58) И из практики: Вы каждого 1С-программиста сможете научить работать с Заббиксом? Оно Вам надо? А метрики в Прометея у нас кидает каждый программист )))))
>идти и донастраивать Заббикс.
Нет, этого не нужно, если использовать правила обнаружения, по которым метрики создаются из шаблона с нужным ключом для разреза.
>И из практики: Вы каждого 1С-программиста сможете научить работать с Заббиксом? Оно Вам надо? А метрики в Прометея у нас кидает каждый программист )))))
Ни в коем случае ни говорю, что нужно использовать заббикс. Ваше решение и использование прометеоуса как инструмента верное и наиболее гибкое. Хочу лишь донести, что ваши мысли об ограничениях забикса не свосем корректны.
(62)
Насколько часто Вы планируете их запускать?
(62)
Судя по Вашему отзыву, я, к сожалению, не смог донести корректно свои мысли касательно Заббикса.
Это шикарная система, с богатейшим функционалом и потрясающими возможностями (За исключением танцев с бубном вокруг Housekeeper’а и усекновения базы при больших нагрузках).
Однако для частоменяющегося и заранее неопределенного набора аналитических разрезов она слабо подходит вследствие своей жесткой структуры.
P.S. Вы очень интересный собеседник, с удовольствием бы продолжил общение в личке.
(63)
А это зависит от необходимости и «тяжелости» процедуры (скрипта) обнаружения.
(63)
Да, часто мы хайлоад сами себе на ровном месте делаем собирая очень часто ненужны метрики.
(63)
Я только за. Мало людей, которые серьезно относятся к мониторингу.
Спасибо большое за конфигурацию! вопрос вот в чем! Есть мануал по настройке связей, путей и т.д. между 1с и Prometeuse. Спасибо!
Пишите в личку — решим. Мануал how to не делал. Вкратце:
1) опубликовать http- сервис из 1С
2) настроить его как цель в prometheus.yml
Главный нюанс с которым я столкнулся — это то, что отступы пробелами в prometheus.yml имеют значение.