












Введение
Временами требуется проанализировать "сырые" логи технологического журнала, чтобы решить проблемы зависания, взаимоблокировок, медленных запросов и много чего еще.
Парсить непосредственно содержание сами логов на предмет нужных событий — утомительное занятие. Для того, чтобы этот процесс как-то автоматизировать, я решил написать максимально универсальный инструмент, который позволяет решить проблему поиска нужных событий в кластере из нескольких рабочих процессов, а то и серверов.
Описание
V8 Log Scanner — open-source проект на core java 1.8. Без лишней скромности, это продвинутый и весьма быстрый парсер, нацеленный на анализ логов такого объема, который какой-нибудь notepad++ даже побоится открыть (прим. в notepad++ зашито ограничение в файл размером 500 мб).
По сути V8 Log Scanner – легковесная кроссплатформенное консольная утилита, в которой разбор логов выполняется с помощью sql синтаксиса. Несмотря на свою «консольность», в утилите есть меню, поэтому вводить вручную, а тем более держать в голове команды, вообще нет никакой необходимости. Все действия в утилите осуществляются через ввод цифр с клавиатуры, т.е. чтобы выбрать первый пункт мы должны ввести 1 и нажать Enter
Не могу сказать, что являюсь адептом java, но тем не менее утилита активно использует многопоточность, собственный ByteChannel файловый ридер, java Stream API, регулярные выражения, а также паттерн Map-Reduce. Благодаря всему этому объем потребленной памяти во время парсинга зависит только лишь от размера выходной выборки. Так что, например, парсинг нескольких гигабайтов лога ради 2-3 событий является совсем не затратным по ресурсам компьютера. На следующей картинке наглядно видно, что парсинг 800 мб лога отнимает в среднем 200 мб памяти.
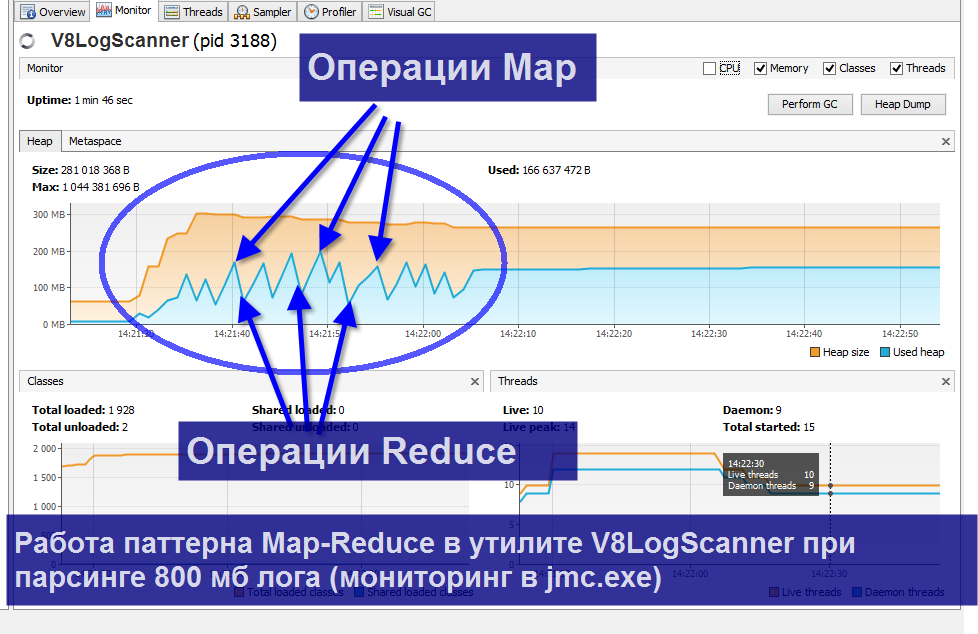
Здесь map-reduce – это фактически оператор СГРУППИРОВАТЬ ПО, только выполяемый ресурсами традиционного ЯП, а не СУБД.
Инструкция
По шагам это выглядит так:
1. В главном меню Вы выбираете один из 3 доступных алгоритмов парсинга.
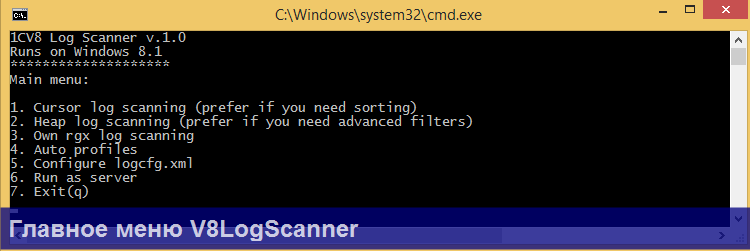
1) Cursor log scanning – когда требуется сортировка событий по их свойствам и ограничение конечной выборки с помощью оператора ПЕРВЫЕ N для экономного расхода памяти
2) Heap log scannning – когда хотите получить абсолютно все события по заданным фильтрам, а не только ПЕРВЫЕ N
3) Own rgx log scanning – когда хотите ввести собственное регулярное выражение. При этом не нужно заботится о "захвате" отдельных блоков событий регулярным выражением. Утилита это делает сама при помощи следующего выражения:
.+?(?=\d{2}:\d{2}\.\d{6})
2. Далее заполняете доступные операторы запроса с помощью нового меню. Справа от каждого пункта меню показываются текущие настройки для данного фильтра. При этом автоматически сканирутся все каталоги, исходя из настроек в logcfg.xml.
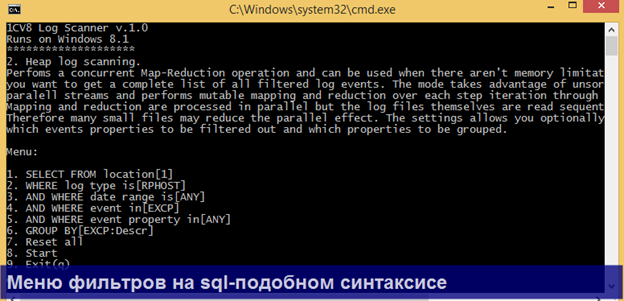
Не забудьте заполнить меню:
1. Select from location [0]
В нем нужно указать папку, из которой нужно брать логи. Также в меню есть возможность автоматически подтянуть каталоги из файла logcfg.xml.
3. Затем нажимаете Start и получаете на выходе результат в виде выборки.
Если фильтры для парсинга не ведены в предыдущем меню, а каталог логов исчисляется гигабайтами, то будьте готовы к значительному расходу памяти (максимум до 1/4 памяти компьютера), т.к. туда будет помещена вся конечная выборка. Если памяти не хватит для парсинга, утилита упадет без ошибок.
Отсюда совет — задавайте хотя бы минимальные фильтры по виду события (and WHERE Event in […] ).
Каждая строка выборки это пара ключ (key) – значение (event), где ключ – поле группировки (из оператора GROUP BY), а значение – массив событий логов. По выборке Вы можете двигаться по ключам либо вперед, либо назад.
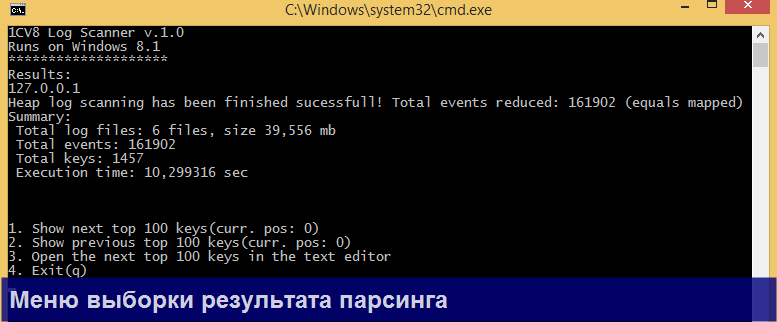
Отмечу, что для каждого ключа можно вывести полный список событий, если ввести на клавиатуре цифрой соответствующий индекс ключа.
Примеры
Продемонстрирую несколько конкретных сценариев парсинга, в которых может пригодиться утилита.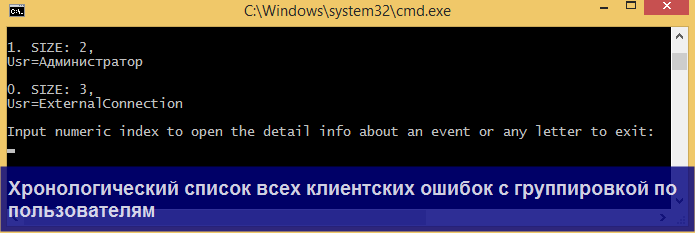
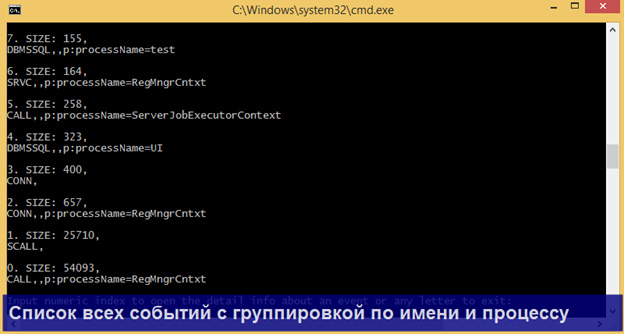
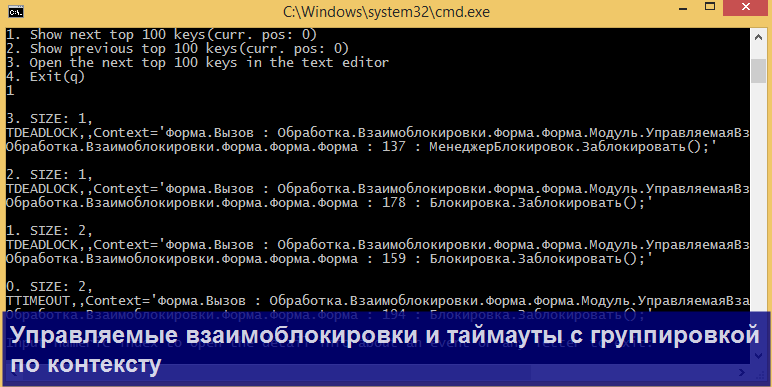
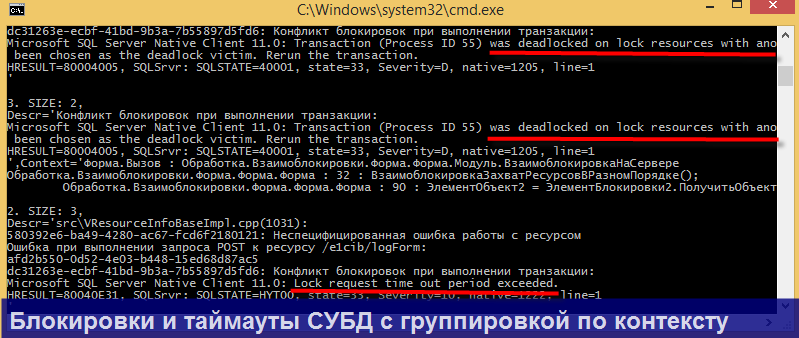
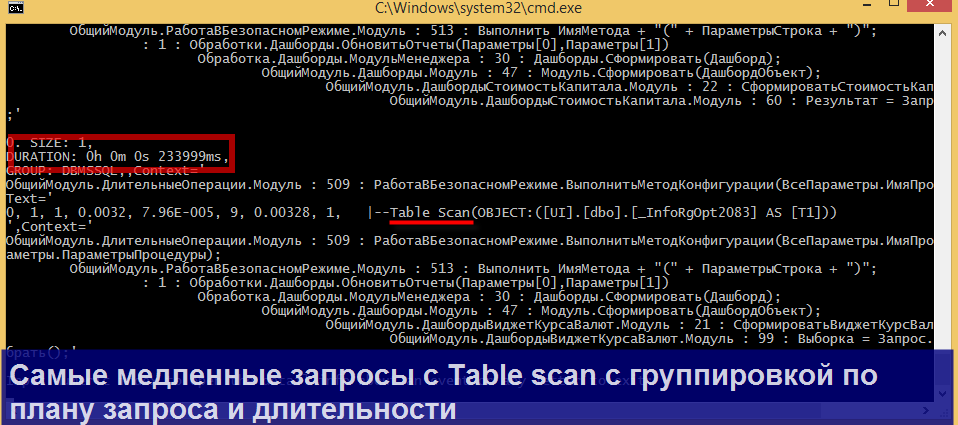
Для всех перечисленных сценариев уже прописаны настройки, доступные через меню Main => Auto profiles, так что Вам не придется их настраивать вручную!
Дополнительные возможности
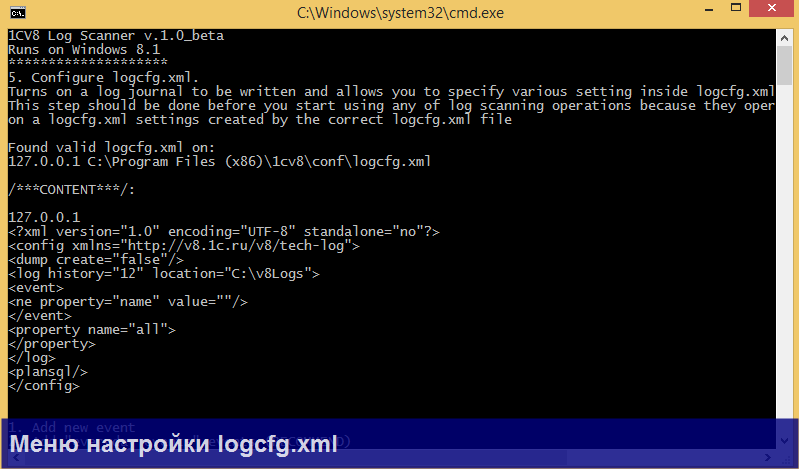
Во-первых, в V8 Log Scanner встроен конструктор файла настройки ТЖ logcfg.xml, доступный через меню Main => configure logcfg.xml. Конструктор позволяет задать настройки и автоматически сформировать файл в нужном каталоге установки платформы.
Во-вторых, V8 Log Scanner может работать в клиент-серверном режиме в меню Main => Run as server. Например, вы можете поместить утилиту в режиме запуска сервер в планировщик заданий или установить как сервис windows (для этого поставляются отдельные bat-ники) непосредственно на сервере приложений, на котором собираются логи и работать с утилитой удаленно через локальную сеть.
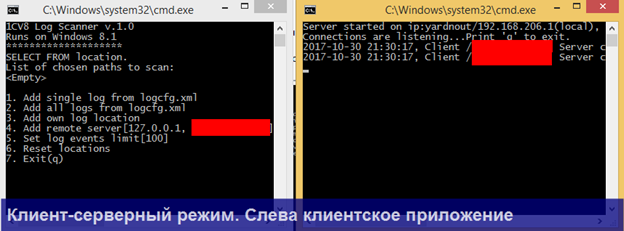
После запуска скрипта install_service.bat нельзя перемещать каталог с утилитой, иначе служба Windows не будет стартовать.
Заключение
Как уже говорилось, утилита находится в статусе бета-версии, поэтому не все функции могут работать как ожидается. Буду признателен за обратую связь и pull-request-ы на github-e. Исходники и билды доступны в репозитории на github https://github.com/ripreal/V8LogScanner
p.s. всем известные КИП или сервисы Гилева позволяют решают похожие задачи без необходимости копаться в логах. Маленькая и скромная утилита V8 Log Scanner не является их конкурентом. Но она может быть весьма полезна, если упомянутые сервисы не настроены для конкретной базы или нужно найти в логах, разбросанных по всем серверам, какие-то специфичные события (events) из журнала.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Интересная вещь Log Scanner!
Инструкцию бы получше…
Я попробовал вывести все пользовательские события, в окне промелькнули вложенные каталоги , появилась строчка
in: 1, out: 1, c: echlog
phost_138417110717.log
и на этом все
хорошая штука, интересно как к ней отнесутся на экзамене 1С:Эксперт
(2)
phost_138417110717.log
Эта строчка говорит о том, что идет процесс парсинга и утилита только-что распарсила лог по адресу c: echlog
phost_138417110717.log. При этом в процессах windows приложение java.exe должна грузить проц и диск (если не грузит, то что-то идет не так).
То что никаких новых сообщений не показывается долгое время — это нормально. Скорее всего утилита натолкнулась на особо толстый файл минимум в сотни мегабайт. На моем компьютере разбор 500мб лога занимает около 20 секунд. Нужно ждать. К сожалению, сейчас не готов индикатор, который детально показывал бы парсинг одного файла.
Да, у меня файлы по 300 — 900 МБ. И вправду грузит процессор, сразу не заметил, т.к. процесс java в фоновых, где-то внизу списка
Ну хорошо, эта штука поработала и закрыла за собой окно, не оставив никаких следов. Это баг бетаверсии?
(6)
Это может быть OutOfMemoryError, т.е. не хватило оперативной памяти, выделенной виртуальной машине java, если конечная выборка превышает объем памяти, разрешенный для виртуальной машины java.
Это вполне вероятно, если выбрали автопрофиль «Find all users events».
В чем особенности этого автопрофиля:
1. Он выводит ВСЕ события в логах, и пытается их сгруппировать по свойству Usr.
2. Он по умолчанию работает по алгоритму Heap log scanning (то есть без ограничения объема конечной выборки)
Это можно исправить. Измените алгоритм на Cursor log scanning. Данный алгоритм будет из каждой порции в 10 000 найденных событий в файле выбирать TOP 100 событий. То есть из лога в 5 000 000 событий, он выберет отсортированный поток (сортировка будет по значению указанному в настройке ORDER BY) в 500 событий . ЧТобы изменить алгоритм Выполните следующие действия из Main menu:
4. (Auto profiles), 1( Find all users events), 9 (Exit (q) ), 1 (Cursor log scanning). Все настройки автопрофиля сохраняться. Далее вы можете указать Log location и начинать парсинг.
В любой случае, хотелось бы посмотреть на логи ошибок. Включите их (Main menu -> Run as server -> Allow logging) и воспроизведите сценарий ошибки снова. После падения в папке с утилитой должен появится файл error_logs.txt
По предложенному алгоритму оно ничего не сканирует, т.к. не дает возможности указать каталог с логами вручную.
1CV8 Log Scanner v.1.0_beta
Runs on Windows 10
********************
Results:
127.0.0.1
Summary:
Total scanned log files: 0 files, size 0,000 mb
Total in events: 0
Total out events: 0
Final amount of events: 0 reduced to limit: 0
Total keys: 0
Execution time: 0,030752 sec
1. Show next top 100 keys(curr. pos: 0)
2. Show previous top 100 keys(curr. pos: 0)
3. Open the next top 100 keys in the text editor
4. Exit(q)
Чтобы началось сканирование я выбираю пункты 1, 1, 3 (здесь указываем путь к логу). В остальных комбинациях меню с пунктом 3 не появляется.
Оно опять свалилось и лога после себя не оставило. Это не бета-версия, а что-то вроде пред-альфы 🙂
(9) Можно узнать какой объем папки с логами, какая разрядность java и сколько памяти на компьютере?
windows 10 x64, java 8 x64 (JDK) , RAM 16GB, папка с логами 7ГБ, есть файлы по 700 МБ, диск SSD
Это похоже на OutOfMemoryError, связанное с техническими особенностями алгоритмов утилиты. В общем, Вы выбрали очень тяжелый сценарий парсинга!. С меню 1 — 1- 3. не используются никакие фильтры.Как выйти из этой ситуации? Это более активно использовать фильтры(предложения WHERE и GROUP BY в менбю утилиты).
Далее техническое объяснение:
В одном 700 мб логе у вас может быть около 4 000 000 событий. =>
это количество сокращается в результате работы алгоритма Cursor log scanning максимум до 40 000 событий => во всех файлах значит может быть около 400 000 (если все файлы по 700 мб) событий в конечной выборке.
По грубым расчетам для хранения 400 тыс событий утилите потребуется 2 гб памяти. Виртуальная машина java по умолчанию ограничивает объем потребяемой памяти до 1/ 4 памяти компьютера. У вас доступно максимум 4 гб для работы утилиты.
Теперь, если события в одном файле очень разные, то алгоритм Cursor log scanning не сможет сократить объем конечной выборки (на вход блок в 10 000, а на выход блок все те же 10 000), т.к. ключи события не сливаются по предложению GROUP BY в одно. Соответственно в конечной выборке у вас может быть до 40 млн событий, а это потребует максимум 200 гб памяти.
В целом, я попробовал у себя на компьютере распарсить 3.5. гб логов с 8 гб памяти по Вашему сценарию. Т.к. события были в целом однотипными, то на вход у меня было 2,3 млн событий, а на выход — 242 тыс. событий. Это отняло 900 мб памяти. УТилита сработала нормально.Затем я увеличил количество логов до 8 гб и утилита упала.
Также я попробую в будущих релизах обработать исключение OutOfMemoryError, чтобы давать более осмысленное сообщению пользователю об ошибках.
Хорошо, делаю более осмысленный выбор. Нажимаю 4 — 2 (excp rphost) — 8. Получаю ноль.
Summary:
Total log files: 0 files, size 0,000 mb
Total events: 0
Total keys: 0
Execution time: 0,073580 sec
А почему ноль? А потому что нет выбора своего пути к логам! Или я чего-то не понимаю. Придется изучать перл….
Просто не указали свой путь к логам. После 4 — 2 должно появится меню:
Menu:
1. SEL ECT FR OM location[0]
2. WHERE log type is[RPHOST]
3. AND WHERE date range is[ANY]
4. AND WHERE event in[EXCP]
5. AND WHERE event property in[ANY]
6. GROUP BY[EXCP:Descr]
7. Reset all
8. Start
9. Back(q)
Обратите внимание на пункт 1:
1. SEL ECT FR OM location[0]
В нем указываете откуда брать логи. Если перейти по нему откроется новое меню:
List of chosen paths to scan:
<Empty>
1. Add single log fr om logcfg.xml
2. Add all logs fr om logcfg.xml
3. Add own log location
4. Add remote server[127.0.0.1]
5. Reset locations
6. Back(q)
Чтобы добавить собственную директорию с логами, выбираете 3 и вводите местоположение вручную. Далее это меню возвращает сюда:
Menu:
1. SELECT FR OM location[2]
2. WH ERE log type is[RPHOST]
3. AND WH ERE date range is[ANY]
4. AND WH ERE event in[EXCP]
5. AND WH ERE event property in[ANY]
6. GROUP BY[EXCP:Descr]
7. Reset all
8. Start
9. Back(q)
В этом менб вы нажимате 8 и начинается работа утилиты.
Такое огромное количество различных парсеров… Все как-то парсят, показывают, заново парсят… Крутится чаще всего еле-еле… Не все конечно, но…
В когда-то, имея начальный опыт в понимании ТЖ и методов его парсинга (ЦУП оставил ужасные воспоминания в оперативности обработки), я не выдержал и накропал на коленке за пару вечеров на 1с парс в отдельную базу с усечением мусорных данных (а-ля космический инсерт — строка на миллионы и сотни миллионов символов, одно мало интересное событие — и сразу +гиг и т.п.) В итоге база для хранения непрерывных логов на удивление оказалась компактна и из гигабайтов в день хранит мегабайты.
Просматривается и анализируется в СКД, в любых
позахвариантах. Отчеты за день-два выстреливают пулей. И что не маловажно — есть история за длительный период.К чему это я? А х да… Не ужели каждый себе еще не понаписывал чего-то подобного? Эй, 1с-ники! Для чего нам 1с? Чтобы писать на яве? )))))))))
PS: а вообще круто. Зорачка.
(15)
Как ни крути, ну как минимум на сервер придется поставить Java.
Новый механизм реструктуризации мы планируем включить в версию 8.3.11 в статусе бета. Он реализован только на сервере, причём на сервере должна быть установлена Java 8.
Кажется работа с 250 кб утилитой, когда на всех серверах будет стоять java, все еще имеет свои преимущества, вроде максимальной оперативности получаемых результатов.
Реализовали подобное без написания кода: Elastic+filebeat+Grafana, получили плюсом визуализацию в режиме реального времени
(14) Ну вот, теперь более-менее понятно. Попробую.
(15)
Было бы здорово, если бы поделились своим продуктом.
(17) ну ведь для filebeat-то что-то написали? Где? Покажьте! 🙂
(17) тоже хотелось бы посмотреть
зачем тут оглядывания? Это ж замедляет производительность регулярки
(2) соглашусь, инструкция поверхностная
(5) как быстро программа разбирает гигабайт логов?
(24)
(23) Сильно зависит от количества событий в логах. выбранных фильтров, и скорости жесткого диска. У меня получалось в районе 30 секунд на ноутбуке без ssd, если требовалось вытащить пару событий.
(22)
Нужно, чтобы получить все события ТЖ, включая первое и последнее. Лучше что удалось придумать.
(26) не нужна для этой задачи регулярка, вот напиши свой алгоритм и с регуляркой и проверь на большом объеме