
Определения NoSQL и CRDT
Если дать расшифровку определениям, которые используются в заголовке, то:
- аббревиатуру NoSQL обычно переводят как «не только SQL», хотя есть сторонники прямого перевода, в котором, по сути, технология NoSQL противопоставляется классическим базам данных SQL
- А CRDT (Conflict-free Replicated Data Types) – это типы данных для бесконфликтной репликации. По сути, требования к объектам обмена для минимизации проблем
О чем будет статья?
- Мы поговорим про обмен данными, который традиционно предполагает наличие двух и более распределенных систем, которые, в идеале, друг про друга почти ничего не знают, но умеют между собой взаимодействовать
- Сразу оговорюсь, что к распределенным системам я отношу, в том числе, мобильные и веб-приложения, которые я рассматриваю не только как интерфейс пользователя, но и как полноценный инструмент для хранения и обработки данных
- Рассмотрим, что предлагают базы NoSQL в части хранения и репликации, какие там есть встроенные механизмы для построения распределенных систем
- А также у нас будет четыре наглядных примера, которые проиллюстрируют работу взаимодействия между базой NoSQL и 1С
Почему именно NoSQL?
Список преимуществ, которые дает использование NoSQL, упорядочить трудно – для меня все перечисленные здесь пункты важны:
- Это, конечно, высокая скорость работы приложений под большой нагрузкой
- Это – экстремальная надежность, практически неубиваемость данных
- Наличие встроенных на уровне ядра инструментов для построения распределенных систем
- В NoSQL есть интересный механизм – map-reduce индексы. В некоторых случаях использование этих индексов оказывается существенно эффективнее, чем традиционные SQL-запросы
- Ну и, наконец, открытый исходный код. Когда мы строим серьезную систему, хочется, чтобы платформа, на которой мы ее строим, нам сюрпризов не преподносила
Вокруг много технологий, и непонятно, на изучение какой стоит потратить время. Я расскажу о некоторых возможностях CouchDB и надеюсь, что эта математика вас заинтересует, и вы захотите потратить на нее еще немного времени.
Теорема CAP
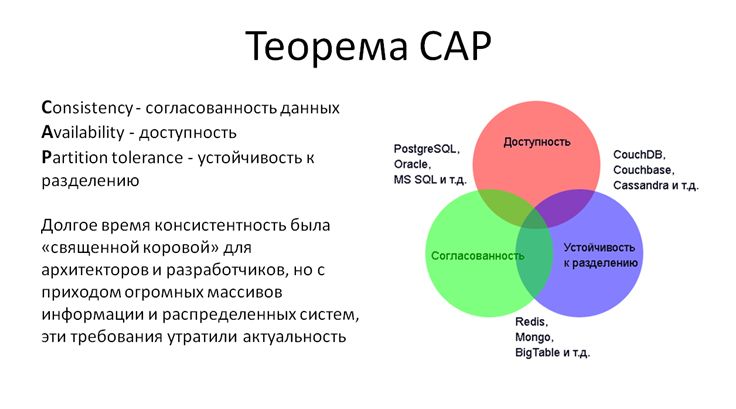
У теоремы CAP нет строгого доказательства, но она получила широкое признание среди специалистов по распределенным вычислениям. Суть теоремы сводится к тому, что обеспечить одновременно целостность данных, их высокую доступность и способность к разделению очень трудно. Каким-то одним из этих показателей приходится жертвовать. Проблема не новая, и в нашем распоряжении достаточно инструментов, которые отдают приоритет той или иной паре показателей:
- В традиционных SQL-базах все хорошо с доступностью и с согласованностью данных, но есть проблемы с разделением данных
- Есть базы, где во главу угла поставлена консистентность и устойчивость к разделению, но могут возникать проблемы с доступностью
- А CouchDB сосредоточена на высокой доступности и разделяемости данных, но не гарантирует их транзакционной целостности
В реляционных базах данных (таких, как PostgreSQL, Oracle и MS SQL) определенный уровень изоляции обеспечивается за счет блокировок или undo-логов. Но с приходом огромных массивов информации и распределенных систем стало ясно, что обеспечить для них транзакционность набора операций с одной стороны и получить высокую доступность и быстрое время отклика с другой — невозможно, соответственно требования к транзакционной целостности стали уже неактуальны. Известно мнение разработчиков всемирной сети банкоматов – процитирую: «если бы мы на самом деле дожидались окончания каждой транзакции, это занимало бы столько времени, что клиенты убегали бы прочь в ярости». Например, если вы и ваш партнер одновременно в двух банкоматах снимаете деньги с одного банковского счета и превышаете лимит – что происходит? Несмотря на это, вы оба получите деньги, а банк решит эту проблему позднее – будет сформирован технический овердрафт и в худшем случае, даже если деньги не удастся вернуть, это будет все равно в 10 раз дешевле, чем попытки обеспечить синхронную работу большой системы.
Что такое NoSQL?
- В SQL мы сначала раскладываем наш объект по прямоугольным табличкам, а потом мучаемся с блокировками, чтобы обеспечить целостность при записи, и строим многоэтажные join-ы при чтении данных
- А в NoSQL вместо термина «запись» или «строка» используют понятие «документ»
- Структура этого документа, за исключением служебных полей, не регламентирована – можно добавлять новые реквизиты без предварительного декларативного описания
- Сами реквизиты NoSQL-документов могут быть как примитивных, так и сложных типов – это могут быть массивы и объекты, также содержащие свои вложенные реквизиты, массивы и объекты
Основные отличия традиционных баз SQL и базы NoSQL
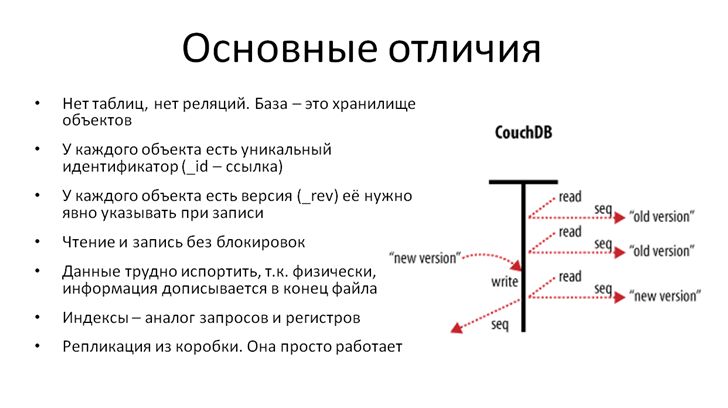
- В NoSQL нет таблиц и, соответственно, нет реляций между этими таблицами. Базу данных можно рассматривать просто как «свалку» объектов
- У каждого объекта есть уникальный идентификатор-ссылка. Это нам близко – в 1С у документов и справочников тоже есть ссылки
- Существенное отличие – это поле версии. Оно в NoSQL неотъемлемое, и это – не какой-то инструмент, спрятанный вовнутрь ядра. Это – реквизит, с которым мы явно работаем, когда хотим записать изменения. Версия в NoSQL – это важно
- Чтение и запись происходят без блокировок. Картинка справа это иллюстрирует. Понятно, что и для чтения, и для записи нужно время, но первым двум читателям отдается предыдущая версия объекта. А когда транзакция записи завершилась, очередной читатель получит уже свежие данные
- Данные в NoSQL трудно испортить, так как физически они просто дописываются в конец файла. За все системы NoSQL не скажу, но в CouchDB именно такая организация B-дерева. Поэтому при аварийном отключении питания, обрыве сетевых проводов последнюю транзакцию мы можем потерять, но все остальное хранится в том самом виде, в котором записалось
- Индексы кроме прямой функции указателя на запись в NoSQL еще могут содержать итоги. И в этом смысле они больше похожи на наши регистры накопления
- Ну и наконец, репликация из коробки. В CouchDB она просто работает
Демо-приложение № 1 «Миллион записей».

Я подготовил для доклада несколько живых примеров. Это – не навороченные приложения, а компактные обработки в один экран для демонстрации короткого списка возможностей.
Данный пример иллюстрирует работу со списком номенклатуры длиной в миллион записей. Перейдя по QR-коду, приведенному на слайде, можно самому протестировать работу этого приложения.
- Здесь задействован элемент управления «Динамический список» с бесконечной полосой прокрутки – Infinite Loader
- Использована фильтрация данных с помощью индексов NoSQL
- На серверной стороне использовано довольно скромное оборудование, например, для той виртуальной машины, на которой крутится CouchDB, сейчас отдано только два физических ядра и 8Gb ram, но она спокойно может обслуживать сотни параллельных запросов клиентов, что соответствует тысячам одновременных клиентов. Все это хорошо масштабируется – достигаются высокопроизводительные результаты
- В таблице честный миллион записей – код примера опубликован в github – желающие могут повторить и сделать замеры производительности на своих компьютерах
- Те записи, которые выводятся в список – это, физически, не какие-то сырые данные, а элементы справочника «Номенклатура». В качестве наименования использованы случайные слова русского и английского языков, длина наименования варьируется от одного до трех слов
- Поисковый индекс устроен таким образом, что мы ищем по первым символам любого из слов наименования. В этом индексе примерно 2 миллиона записей (так как наименование у нас в среднем состоит из двух слов, а записей – миллион)
- Кроме этого, работает поиск по коду, например, можно сразу перейти к самой последней записи в этом списке
Списки короче 10 тысяч записей я рекомендую загружать в ОЗУ при старте приложения. Это убивает сразу двух зайцев. Во-первых, отзывчивость интерфейса – мы эти данные можем быстро показать человеку, а во-вторых, мы по пустякам не беспокоим сервер, разгружаем его. По длинным спискам тут нужно принимать творческие решения – иногда их бывает дешевле и проще прочитать прямо с сервера. Но если списки не такие длинные, удобнее держать их на клиенте, особенно если эти данные нужны для автономного режима работы.
Индексы в NoSQL

Мы привыкли, что индексы – это просто перечисление полей в инструкции ALTER TABLE или галочка «Индексировать» в конфигураторе 1С. И еще привыкли, что индексы магически ускоряют выполнение запросов. Но мало кто задумывается о физическом устройстве индексов и о накладных расходах на создание индексов при записи основных объектов.
- Индексы, которые создаются автоматически, в CouchDB тоже есть – это поисковые индексы (появились в CouchDB2.0)
- Но основные индексы map/reduce – это код JavaScript. И этот код похож на то, что мы пишем в процедуре проведения документов
- При запросах к данным NoSQL мы явно указываем индекс, из которого хотим прочитать данные, и явно указываем диапазон ключа, по которому эти данные должны быть ограничены
- Таким образом, мы используем те подходы, которые были популярны у программистов 40 лет назад (в до-SQL-ную эпоху). Оказывается, что когда данных становится очень много, эти подходы не так уж и плохи
Запас масштабируемости
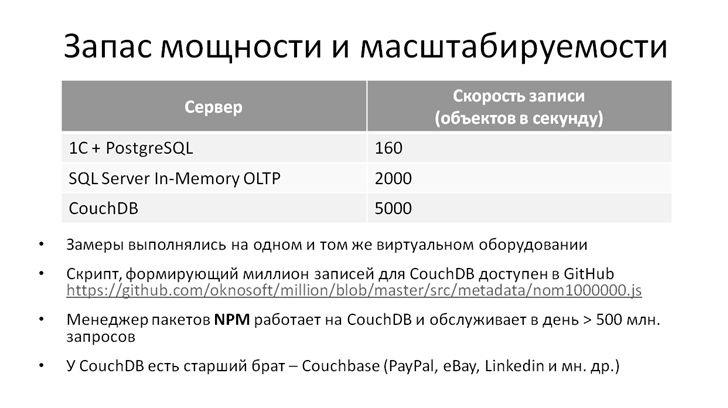
В прошлом году на конференции Инфостарт Денис Кирьяк рассказывал про свои эксперименты с Microsoft SQL Server In-Memory OLTP. В его докладе возможность записать 2000 объектов в секунду выдавалась как большое достижение. Чтобы добиться таких результатов, Денису пришлось создать хитрую виртуальную среду и написать скрипт, имитирующий высокую нагрузку на MS SQL. А в случае с CouchDB я на бытовом компьютере (а точнее, на виртуальной машине внутри бытового компьютера) не напрягаясь, получил скорость записи 5 тысяч объектов в секунду. Причем сделал это не на стерильном скрипте, а на реальной задаче при подготовке данных для предыдущего примера про миллион записей. Обратите внимание, что там используется не просто запись, а еще и заполнение реквизитов случайными значениями. Код на github доступен, можете открыть, посмотреть, как это сделано – прорешать, провести измерения на своем оборудовании.
Еще про масштабируемость:
- Согласно общеизвестной статистике пакетный менеджер npm от nodejs обрабатывает в день полмиллиарда запросов. Причем делает это уже много лет, и ни одного сбоя еще не зарегистрировано
- Такие известные сервисы, как PayPal, eBay и Linkedin используют базу Couchbase. У истоков баз Couchbase и CouchDB стоит один и тот же человек. Это разные базы, но протокол репликации у них поддержан одинаковый, и при необходимости они могут работать в тандеме
Поэтому когда мы примеряем, сгодится ли для нашей задачи с двумя сотнями пользователей CouchDB в качестве движка – скорее всего, сгодится
Распределенная система взаимодействующих баз CouchDB и 1С
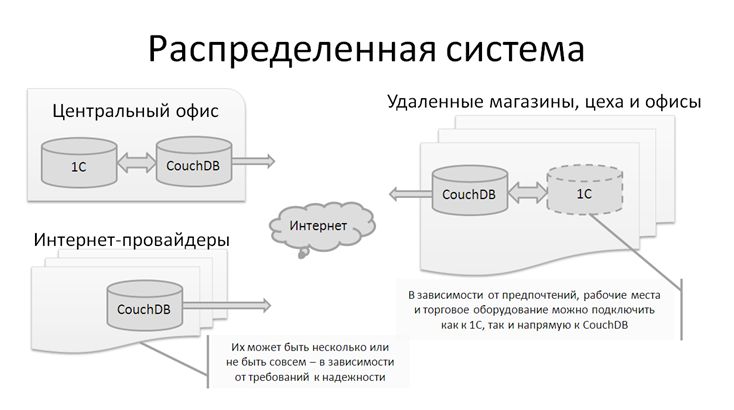
Данный слайд отвечает на вопрос «а причем здесь 1С»? Дело в том, что есть библиотека интеграции Metadata.js, которая делает подключение CouchDB к 1С таким же простым, как включение утюга в розетку
Использование совокупности этих методик позволяет нам строить распределенные системы, автономные рабочие места почти без кодирования. Трудности с репликацией объектов при взаимодействии по плохим каналам связи возьмет на себя математика CouchDB. В результате наша система получится:
- Очень надежная – любую часть можно в любой момент выключить
- Очень быстрая – попутно будет реализовано сжатие данных с минимизацией трафика. Таким образом, ограничение будет зависеть только от пропускной способности сети.
- А главное, что немаловажно, система получится очень простая – внешне интерфейсы, с которыми предстоит иметь дело программисту 1С, очень просты, с ними любой желающий разберется.
Демо-приложение № 2 «Безбумажка»

Следующие два примера иллюстрируют работу распределенных систем. Приложение «Безбумажка» и «Регистратор штрихкодов» умеют работать при отсутствии связи с сервером. Сначала приложение «Безбумажка». На первый взгляд, ничего особенного. Сканируем штрихкод, получаем соответствующее ему задание на производство, регистрируем факт готовности. Особенности есть:
- Про автономный режим я уже сказал. Если взорвать сервер при помощи динамита, у нас конвейер в цеху не остановится. Вся необходимая информация для сегодняшнего суточного задания в мобильном клиенте у нас есть – мы продолжим отдавать команды конвейеру, и он будет выпускать изделия.
- В штатном режиме, когда сеть исправна и сервер доступен, информация по событиям диспетчеризации будет поступать в 1С в реальном времени.
- Это приложение работает, в том числе, на бытовых телевизорах – мои клиенты любят в цеху вывешивать такие большие экраны. И компьютер рядом ставить не нужно. Достаточно браузера, встроенного в современный телевизор.
- Можно реализовать сложные алгоритмы регистрации и сложные рабочие места. Эскиз, который мы здесь наблюдаем, это не простой вид-массив – каждый элемент понимает, какой кусок спецификации под ним лежит, и, соответственно, на основании этих данных мы можем сформировать рекламацию или корректировочное задание на производство.
- Кроме сканера, к веб-странице подключен станок по отрубанию фурнитуры. Когда человек кликает по ссылке, веб-приложение отправляет в станок команду, упор отъезжает на нужный размер и отрубает лишний кусок металла.
Демо-приложение № 3 «Регистратор штрихкодов»

Еще одно приложение – «Регистратор штрихкодов». Позволяет регистрировать штрихкоды в привязке к исполнителю и этапу производства. Главная задача этого слайда – продемонстрировать оффлайн режим с последующей синхронизацией.
Это приложение можно рассматривать как терминал сбора данных: когда связь отсутствует, мы можем автономно регистрировать события – например, те, которые поступают со сканера. А при возобновлении связи эти события отправляются в 1С.
Важно: здесь мы обмениваемся не какими-то сырыми данными, а передаем на сторону 1С полноценный документ «События планирования». У него есть табличная часть «Исполнители», которая заполняется в зависимости от настроек текущего пользователя. У него кроме обычных реквизитов есть дополнительные реквизиты и сведения, внесенные в 1С из соответствующей подсистемы БСП (мы в metadata.js также поддерживаем дополнительные реквизиты и сведения). В данном случае, в эти дополнительные реквизиты попадет информация по этапу производства (также из настроек пользователя).
Репликация в CouchDB

CouchDB изначально создавалась для работы в распределенных системах и умеет отвечать на вопрос: «Что изменилось в нашей базе данных, начиная с момента времени X». Для того, чтобы сформулировать ответ на этот вопрос, данные организованы определенным образом.
- Во-первых, это – версии объектов
- Во-вторых, это – уникальные метки для каждого события записи, поскольку все эти события у нас упорядочены во времени
- Ну и для того, чтобы обеспечить монотонность состояний, пришлось отказаться от операции удаления и изменения объекта
- Если нам нужно удалить объект, мы записываем новую версию, в которой взведена пометка на удаление
- Если нам нужно изменить объект, мы записываем новую версию с новыми значениями полей
- Список изменений можно отфильтровать на стороне сервера для задач частичной репликации. Данные можно передавать с фильтром по контрагенту, по подразделению и т.д. – любые алгоритмы, любые фильтры поддерживаются
- Есть излучатель событий. Клиенты, подключенные к обмену, получают от сервера сообщения о том, что некие объекты изменились, их данные нужно перечитать и на своей клиентской стороне как-то обработать
Разрешение конфликтов версий. CRDT (Conflict-free Replicated Data Types)

- Бесконфликтность репликации правильнее всего обеспечивать методологически – с помощью однонаправленного потока данных.
- Но в том случае, если разрулить проблему на уровне бизнес-процессов не получается и конфликты неизбежны, CouchDB помогает разрешать эти конфликты достаточно изящным способом, обеспечивая монотонность состояния.
- По умолчанию, при разрешении конфликтов просто выигрывает та версия, изменения в которую вносились позже.
- При этом прикладной программист в Conflict Resolver-е может реализовать любые алгоритмы, сказать, что победил первый, второй, третий и последний, или синтезировать свой собственный объект на основании прибежавших из разных мест данных. Например, для записи можно склеить строки табличных частей из разных версий. Однако при написании Conflict Resolver-ов следует придерживаться правил строгой событийной целостности (они здесь на слайде перечислены). Иначе можно сделать такой Conflict Resolver, который всегда будет создавать новые версии, и система будет генерировать незатухающие колебания.
Преимущество NoSQL – агрегаты по датам и строкам

В начале статьи я обещал привести пример, когда индексы NoSQL оказываются интереснее привычных запросов. Таким примером являются задачи диспетчеризации. Для их решения нужны итоги по датам. Обычно для получения итогов по состояниям изделий и датам событий используют объединения (в некоторых случаях для этого могут сгодиться агрегатные функции min-max). Но что тут важно понимать? Событий диспетчеризации, как правило, на один-два порядка больше, чем других хозяйственных операций. И если мы считаем оправданным использование регистров накопления для расчета остатков товаров на складах и остатков во взаиморасчетах, использование аналогичной математики тем более оправданно для решения задач диспетчеризации.
А используя индексы NoSQL, мы можем рассчитать статусы, рассчитать итоговые даты, сложить это все в значение индекса, а при построении отчетов просто показать пользователям готовые данные.
Демо-приложение №4. Отчеты для анонимных клиентов

Примером такого отчета, содержащего итоговые данные по диспетчеризации, является отчет для анонимного клиента. Казалось бы, это обычный бланк заказа, на котором нанесен QR-код. Однако, сфотографировав этот QR-код и перейдя по ссылке, можно увидеть актуальную информацию по событиям оплаты, отгрузки и изготовлению изделия этого заказа – все живые данные о диспетчеризации здесь присутствуют. Причем, эти данные не вычисляются кодом при построении отчета, а извлекаются из индекса map/reduce. При этом регистрация на сайте и специальный личный кабинет не требуются, достаточно только бланка с QR-кодом, который можно сфотографировать и перейти по ссылке. Конечно, найдутся маркетологи, которые скажут, что человеку не нужно давать простого способа увидеть интересующие его данные, что людей на сайте надо удерживать и показывать им разные рекламные пошлости, но я своим клиентам информацию предоставляю наиболее простым и быстрым способом.
Заключение

Итак, для построения распределенных систем с большой нагрузкой, если требуется экстремальная надежность и быстродействие на ограниченном железе, рекомендую использовать наш тандем и зарабатывать на внедрениях.
Конечно, любую задачу можно решить почти любыми инструментами. Можно написать редактор видеоклипов на 1С или написать складскую систему, например, на Autocad. Но я хочу напомнить про подход unix way, рекомендующий строить сложные системы из простых блоков, которые сосредоточены на решении конкретных задач и решают эти задачи самым оптимальным способом.
Задачи транспорта и репликации данных, база CouchDB решает очень эффективно, а библиотека metadata.js делает подключение CouchDB к 1С максимально простым.
***************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 DEVELOPER. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Дочитал до производительности и понял, что автор как-то сильно занижает скорость работы. Для 1С и СУБД соглашусь, но тут сама 1С сильно усложняет INSERT, а вот про NoSQL — как-то бедновато получается с производительностью.
Сам тестил в свое время тот же MySQL — в 300 потоков на AMD FX 8320 удалось записать 1кк (тот самый миллион записей) за 80 секунд (т.е. 12500 записей в секунду, по 1-й записи, а не пачкой). Это при отключенном кешированиии на обычный HDD (Seagate, 7200, 3000Gb, 64Mb кеша). Если кеширование включить, то те же данные в 5 потоков записываются за 25 примерно секунд (дальше потоки роли не играют, т.к. физически упираются в прочее железо, т.е. дальнейшее увеличение количества потоков уменьшает производительность). Все тестилось на PHP с либой .
Тестирование REDIS внутренним бенчмарком показывало скорость на уровне 100к запросов в секунду, включение режима именованных потоков (ключ —pipe) увеличивало производительность в 5-8 раз (до 500к-800к запросов GET/SET в секунду). На новом Ryzen 1600 3200MHz скорость была еще выше — до 2кк SET/GET в секунду (два миллиона записей в одну чертову секунду!)
Так вот, на райзене текстовый конвейер через sed в поток redis-cli 110 миллионов недействительных паспортов из CSV-файла базы ФМС грузит за 4 минуты, в Postgres с fsync=off через COPY в таблицу без индексов грузит 15 минут (но потом достаточно медленно выбирает), а в MS SQL — за 20 минут (но уже с индексами и на более мощном железе, конечно). Т.е. не все так печально, как Вы пишите. Просто 1С не умеет так работать и не дает возможности на это повлиять.
Лично до меня автор так и не смог донести ключевую мысль всей статьи — это как же решается конфликт разных версий при обновлении одного и того же документа? Резюме автора свелось к тому, что программисту это нужно будет решать самостоятельно! Ну и что же ему для этого даст CouchDB? Возможность читать все версии для принятия решения? Но этого мало! Вот бизнес-процесс параллельного многоэтапного согласования. Положительная или отрицательная резолюция согласующего лица может изменить направление движения процесса согласования на тот или иной маршрут. Изменить общее состояние согласования на одно или другое значение. Узел не определяет приоритет (на изменение маршрута влияет только статус согласующего лица). В одном узле маршрут и состояние изменилось в одну сторону, в другом в другую. А потом, ещё до синхронизации, снова поменялся на какую-либо ветвь. И как это всё синхронизировать, какой маршрут и состояние будет в итоге? Всё ложится на плечи программиста — пиши алгоритм, который будет копаться в версиях и восстанавливай правильное состояние? А что делать с сопутствующими данными — другими, связанными, документами и состояниями, которые были изменены в процессе движения по карте маршрута? При небольшом желании для достижения той же ситуации ниаккой CouchDB не нужен — сойдут и регистры сведений 1С — где разные версии согласования просто будут зарегистрированы отдельными записями, с отделеным ключём, — и опять таки, программисту нужно писать код — который всех их будет сводить в одно общее, итоговое состояние.
(1)
Я упомянул в тексте, что цифра относится не к сырой записи, а к реальной задаче, в которой создаются элементы справочника Номенклатура, наименования этих Номенклатур заполняются случайными словами русского и английского языков и эти элементы отправляются в CouchDB.
Здесь справочник Номенклатура от metadata.js — его не надо путать с одноименным справочником типовых 1С.
Говорить о количестве запросов в секунду бессмысленно в отрыве от размера тела этих запросов.
Если документ имеет вложение в виде медиафайла размером в гигабайт, вряд ли получится записать 1000 таких документов в секунду.
(3)
Так и об одном в секунду тут говорить бессмысленно.
Но я о другом — если хотите показать масштаб разницы, то он действительно есть, но не 150/2000/5000.
По поводу версий, кстати, то не во всех NoSQL они есть (если говорить о ключе объекта и версии). Например, в REDIS есть несколько вариантов хранения данных; простой — ключ/значение, мультисет — ключ, несколько значений; хеш-таблица — ключ->ключ->значение; стек/очередь (LPUSH/LPOP|RPUSH/RPOP). Ну и возможность обмена, реализующая целостность (когда в результате система возвращает старый объект, меняя его на новый), Верисионирование здесь возможно в хеш-таблице, где версией будет второй ключ, но это лишь один из вариантов применения.
(1) «Просто 1С не умеет так работать и не дает возможности на это повлиять.» — и это проблема
(2)
Вынужден повторить лозунг Окнософта: «Если вы знаете способ решения вашей задачи без metadata.js — не надо тратить время на изучение наших технологий.»
(4)
Никакая это не проблема. Просто, не надо пытаться решить все задачи на одной платформе.
1С хороша для настольных учетных систем. В этом качестве её и надо использовать.
Для высоконадёжных, высоконагруженных и автономных систем есть другие инструменты.
(2)
Я так понимаю, что речь идет о «транзакционной целостности». Сейчас тоже, если не установить исключительные блокировки изменяемых данных, 1С при чтении исторических значений будет видеть некое одно состояние. Вот Вы начали транзакцию, прочитали, изменили, записали изменения. В это время 20 секунд ждет вторая транзакция, которая уже прочитала данные до изменения и ждет на записи пересекающихся элементов. Что вторая транзакция запишет? Что нужно сделать программисту 1С, чтобы вторая транзакция записала данные с учетом изменений, произведенных первой транзакций? При этом пользователь, который в форме задачи нажимает ролевую кнопку точки процесса, вообще ничего может не знать о том, что кто-то уже повел процесс по другой ветке. Т.е. без дополнительного кода и на 1С Вы ничего не сделаете.
С точки зрения того же REDIS, то в нем есть аналог транзакций — это множественное изменение (начало изменений, окончание изменений). Если устанавливать флаг блокировки элемента процесса через обмен (пишем истину и смотрим, что там было), то можно реализовать логику блокировки, аналогичную объектной блокировке. Если прочитали истину, пытаясь заблокировать объект, то это значит, то объект уже заблокирован. А с учетом того, что данные в REDIS можно хранить определенное время, после которого они удалятся, то это позволит не парится на тему зависших процессов (как это бывает в 1С, когда при падении клиента или сервера в системе остаются висеть блокировки, которые без рестарта сервисов 1С никак не снять).
(8)Я просто хотел увидеть весомое преимущество NoSQL подхода — я его не увидел 🙁
Интересно, что 1с, имея собственную, хоть и хромую на обе ноги, модель данных, могла бы, при желании, работать на любой nosql базе, эмулируя необходимый sql функционал на уровне своего сервера.
(10)
Вся проблема в том, что не все можно сэмулировать в NoSQL для SQL. Вообще, ORM реализуется на NoSQL куда лучше/проще/нагляднее, чем на SQL. В SQL — это идентификатор объекта, занимающий колонку, а в NoSQL — это ключ, по которому можно взять объект. Но если у объекта, например, есть табличная часть (или несколько), то уже на каждую строку каждой таблицы для каждого объекта придется сгенерировать ключ. Помимо прочего усложняется поиск по значению конкретной колонки, т.е. если нам нужно выбрать все документы и их движения за период. Также NoSQL в большинстве своем не умеет толком агрегировать данные, т.е. получить сумму всех документов определенного типа за период будет нетривиальной задачей, ибо у нас тут нет колонок — храниться ключ и объект, в котором уже хранятся каким-то образом колонки. Обычно алгоритм для решения подобной задачи в NoSQL сводится к тому, что читаются все документы (в ключе можно зашифровать, например, тип и дату, тогда поиск упростится), которые мы можем получить (для получения объекта необходимо предъявить ключ, а где мы его возьмем?), а потом проверить дату, после чего просуммировать суммы. Т.е. такая задача для NoSQL решается совсем не просто. А вот доступ к конкретному значению ключа в NoSQL просто безумно быстр.
Если рассмотреть, например, инфраструктуру современных HiLoad-сервисов (например, Stack Overflow), то там есть и Redis, и MS SQL, и другие технологии, которые применяются для разных задач. Для кеширования юзается NoSQL, для хранения данных — обычный SQL.
С точки зрения 1С, NoSQL может применяться очень обширно. Например, на нем достаточно несложно запилить кешер для многопоточных процедур, оперирующих общими данными (или даже для однопоточного проведения документов, когда в кешере сохраняются данные об остатках товаров/задолженности/партии/…. — зачем каждый раз лезти в SQL, если можно получить почти мгновенно данные из NoSQL, передав в отдельный поток данные для формирования значений регистров накопления, т.е. массив движений/наборы записей с установленным отбором по регистратору). Вот для этого NoSQL интересен, а для сборки отчетности с кучей временных таблиц, соединений и прочего — он просто не предназначен для этого.
Кстати, тут интересные штуки народ пилит: . В принципе, с формами на метадата уже можно будет жить без 1С. Типа, «спасибо, большой желтый брат, но ты нам больше не нужен» )))
(11) Спасибо за подробный ответ. Я просто хотел сказать, что если 1с так старательно , то зачем им sql в базе данных? Очень похоже, что от лукавого — сами не могут, а другим предлагают. Что касается неудобства NoSQL для структурированных запросов, то они достаточно успешно там
(12)
до этого ооочень далеко. у метадаты немалый такой порог входа сейчас — с ходу простому одинэснику не разобраться.
(13)
Кстати, да. Я так понял, что они просто запилили для обращения к данным механизмы SQL. Думаю, что это сделано для того, чтобы те, кто привык к SQL, могли попробовать новые механизмы практически не меняя подход и рассматривая данные, как таблицы. Но если попробовать реализовать какой-нибудь серьезный отчет на 1С к данным (ну, например, собрать ДДС), организованным в NoSQL, то без изменения подхода можно получить ту же производительность (если не меньшую). Правильным решением будет смена парадигмы, а не попытка все засунуть в формат аля-SQL.
Я не совсем понял — база данных целиком на CouchDB или параллельно c SQL Server ?
Если целиком — что прям все запросы (и методы связанные с БД) 1С транслируются в запросы CouchDB ?
Или это параллельный функционал хранения данных
(16) База целиком на couchdb, для сложных выборок данных используются map/reduce индексы в тандеме c alasql (SQL запросы к массивам данных в RAM)
(17)
Спасибо.
Но вот в если есть код
что в данном случае произойдет ?
Запрос будет автоматически транслирован в запрос к couchdb ?
(11)
Суммирование происходит так же как и в SQL. Для этого есть вторичные индексы.
Если нужен механизм типа регистра накопления с расчитанными остатками и оборотами — это делается поверх того механизма который предоставляет NoSQL(насчет всех БД не уверен), так же как и в случае с SQL.
Но основная фишка NoSQL, как я думаю, в распределенности. Опять же есть она не у всех NoSQL.
В Couchbase, например если нужно добавить производительности, достаточно просто добавить ноду и произойдет ребалансировка.
Объект, может хранится как JSON. За счет этого достигается древовидная структура объекта, с любым количеством таблиц внутри. Ключ остается один. Для всего объекта.
(15)
Есть альтернативный вариант — map/reduce.
(15)
Производительность упирается(на уровне логики БД) как обычно в индексы и в статистику. Ну и еще в распределенность(или отсутствие таковой).
(18)
Ничего не произойдёт. Metadata.js ничего про код 1С не знает. Она для тех, кто хочет программировать на javascript, используя аналоги 1С-ных объектов.
В метадате есть документы, регистры и справочники. Они во многом похожи на 1С-ные, но во многом и отличаются.
(8) По-моему, Вы немного не о том ответили, о чём писалось в комментарии, на который Вы отвечали. Там человек говорил о том, что для многих (осмелюсь заявить — большинства) задач в 1С вот эта многопоточная несогласованность — она не просто не нужна, а вредна.
А Вы пишете, что её можно решить — и в 1С, и другими средствами. Да, можно, но какое преимущество даёт тот же коуч, например? Я вот тоже так и не понял — какое. Пока что мне кажется. что никакого. Боль и страдания блокировок — это не боль и страдания 1С, это сущность решаемых задач. Карту бизнес-процесса действительно нельзя запускать параллельно в нескольких узлах. Документ действительно нельзя записывать сразу двумя пользователями. Последний ящик пива со склада действительно нельзя списать одновременно двум покупателям. И никакая уличная магия с последующей конкуренцией версий тут не поможет — когда спишут то, чего нет. Блокировки здесь — это не наказание, а средство решения прикладной задачи. Можете её на 1С решать или на САПе или через блокнот и батники — Вам всё равно её нужно будет решить так, чтобы в любой момент времени данные были актуальны. А когда Вы начнёте реализовывать блокировки на коучах — рано или поздно создадите свой 1С с преферансом и поэтессами. С 1 записью в секунду и 1С справляется, тут коучи не нужны.
И об этом как раз и говорят те взрослые пользователи Коуча, которых в пример привёл автор — Пейпэлы, Линкедины и т.п. У них совершенно другие задачи. Если есть миллион пользователей, каждый из них имеет свою область данных (свой профиль-баланс), с которыми может работать только он, когда запись в область данных ведётся только одним пользователем, а другие пользователи чужие профили могут только читать — тогда да, скорость выходит на первое место, потому что актуальность данных подразумевается самой задачей.
И, соответственно, наоборот, если в 1С Вы решаете задачи, где область данных защищена правами (кнопку в бизнес-процессе может нажать только один пользователь, каждому складу сопоставлен менеджер с правами), тогда да, имеет смысл глянуть на варианты.
(23)
Возможно, ибо автора, который писал то, на что отвечал я, тут пока нет и прояснить свой тезис он сейчас не может (может и сможет попозже). Но вот в том сообщении некоторые слова:
На мой взгляд, отсюда непросто вывести то, о чем говорите Вы (про «для многих хрен забить на эту согласованность — единственный подход») )))
(24)
Так и не нашёл, где я такое говорил. Я как раз говорил, что забить хрен на согласованность в 1С нельзя, даже если придётся забить хрен на скорость.
С этим я полностью согласен. Я тоже так и не понял, где тут преимущество Коуча для 1С. В статье много отсылок на какой-то скрипт (насколько я понял, автор его продаёт), много каких-то с любовью описанных приложений, решающих какие-то узкоспециализированные задачи, для которых дан функционал, но почти ничего не сказано о реализации.
Более того, автор в самом начале сам говорит о том, что Коуч ставит целостность данных на второе место после скорости и распределённости. Вот тут как раз и нет пояснения, как Коуч может решить большинство задач в 1С. Да и не ставил автор, по-моему, такой цели. Статья описывает решение конкретных узких задач с помощью нового инструмента. А многие почему-то восприняли его как — залить свою старую БД керосином и бежать подключать Коуча))
Если не стоит проблема «списать того чего нет», тогда и блокировка не нужна. Тот же пример с банком — если он примирился с неактуальностью данных и риском двойного списания, тогда он выбирает коуч и иже с ним. Если у бизнеса актуальность стоит на первом месте — тогда никакой коуч имхо не спасет. Все зависит от задач.
(25)
Вы говорили о том, что для большинства задач в 1С многопоточная согласованность не нужна (даже вредна). Не? Я же говорю о том, что основная задача 1С — изменить данные в базе в соответствии с данными, полученными от пользователя. Если это просто регистрация факта финансовой деятельности, в котором есть 100% информации, то не нужна. На мой же взгляд, куда большее количество задач изменения информации так или иначе но используют исторические данные (при продаже товаров уже определяется, есть ли КЗ, какова себестоимость партий, после чего КЗ и себестоимость списываются или добавляется ДЗ, которая будет закрываться уже документом оплаты, а если товары/услуги агентские/комитентские, то все еще сильнее усложняется).
Фактически NoSQL (но не в том виде, как пишет автор статьи) из-за очень высокой скорости можно использовать для синхронизации многопользовательской или многопоточной работы с данными. В 1С в действительности не так много задач, которые бы в пределе не требовали бы той самой многопользовательской согласованности. Просто не на каждом предприятии это нужно, хотя перепроведение документов встречается повсеместно и производится весьма небыстро.