
Сейчас, действительно, настал момент, когда надо задуматься о переходе на PostgreSQL. Компания «Инфософт», как интегратор, давно интересуется этой темой, причем, следит за связкой PostgreSQL именно с 1С.
Все давно слышат, что системе 20 лет, она удачно работает как на маленьких инсталляциях, так и на огромных базах данных. Но как она работает совместно с 1С – большой вопрос. До сих пор есть опасения, что система долго и сложно настраивается.
Все эти сложности из-за информационного вакуума. Знающих людей достаточно мало, даже в рамках страны, и тем более, в рамках партнерского сообщества 1С. Людей, которые конкретно могут подсказать настройки, – единицы.
Наша компания накопила определенный практический опыт по переходу на PostgreSQL. Мы работали и на небольших инсталляциях, и на крупных – оперирующих терабайтами данных и обслуживающих сотни пользователей одновременно. Поэтому уверены, что наши подсказки понадобятся многим.
Подготовка к переходу и первый опыт
Непосредственно перед переходом придется решить один вопрос: на какой операционной системе это делать. Большинство переходов, осуществленных компанией «Инфософт», было совершено на ОС Windows. И вот почему.
Несмотря на то, что PostgreSQL разрабатывался под Linux-системы переход сам по себе с наиболее популярной системы в 1С на MS SQL на PostgreSQL – это риск. Риск, связанный с тем, что база данных работает совсем по-другому, и в большинстве случаев ее особенности малоизвестны. Поэтому если одновременно поменять операционную систему и перейти на Linux, то риск увеличивается в степень. Придется обучить администраторов с нуля, сломать все их стереотипы. Они всю жизнь работали на Windows. Более того, мир 1С – это 99% Windows. Конечно, есть энтузиасты, и их достаточно много, которые удачно ставят систему на Linux, но если что-то менять, то лучше постепенно.
Поэтому пока компания «Инфософт» проводит инсталляции на Windows. И тесты производительности 1С не выявляют особых кардинальных отличий на одной и той же скорости и конфигурации. Разница в реальных, не синтетических, нагрузках составляет 1-2% и не является критичной.

Первый опыт «Инфософта» – перевод базы данных Microsoft на PostgreSQL в самой компании. Что это за базы данных? Это полностью переписанные ПП1.3 (? Время: 3.56) на неуправляемых формах с интегрированной телефонией, рабочим кол-центром и т.д. до типовой бухгалтерии 3.0 уже на управляемых формах. Нагрузка составляет примерно 150 пользователей в пике.
Главным результатом перехода на PostgreSQL стало то, что пользователи ничего не заметили. Это один из самых положительных результатов, которые можно достичь при переходе. Какие-то процедуры стали немного быстрее, но в основном все работает точно так же. PostgreSQL позволяет спокойно спать администраторам ночью, и при этом не имеет никаких дополнительных расходов на покупку программного обеспечения, как сегодня MS SQL.
Поэкспериментировав на локальных серверах, мы перевели наш облачный сервис на PostgreSQL. Раньше он также работал на MS SQL.

1С Fresh в фирме 1С тоже частично работает на PostgreSQL. Мы полностью перевели наш сервис. Тут нагрузки серьезнее – 200 с лишним баз данных. Согласитесь, большая разница: администрирование 1 базы данных на 1,5 терабайта и 200 баз на 1,5 терабайта. Отличаются требования к отказу устойчивости сервиса, к работе на 24/7/366 (? Время: 5:20). Кроме того, клиенты находятся по России, технологических окон практически нет, так что требования очень жесткие.
Что тут нас ждало? Очень приятный сюрприз: типовые конфигурации 1С хорошо справляются со своими действиями после перехода. Никаких значительных переписок кода нет.
Ничего не надо делать с массовыми типовыми конфигурациями, если они выпущены после 2026-го года. Фирма 1С сделала большие шаги с точки зрения платформы и с точки зрения переписывания кода в типовых конфигурациях, поэтому от очень тонких моментов мы были избавлены.
Выход на рынок
После того, как все свои системы компания «Инфософт» перевела, было решено выйти на широкий рынок. Самым большим проектом по переводу с MS SQL на PostgreSQL был проект с крупным федеральным обувным ритейлером, который хотел перевести на систему PostgreSQL базы розницы.
Сложность перехода в данном случае заключалась в том, что необходимо брать в расчет сразу несколько сотен точек по всей стране, и все это должно реплицироваться. Это 40 баз общим объемом 6 терабайт. Это тысяча пользователей в онлайне. Очень жесткие требования к отказу устойчивости на уровне транзакций, при этом требования ужесточаются еще и тем, что никакого общего хранилища данных быть не должно. Все должно быть максимально независимо.
Тут очень сильно порадовала репликация PostgreSQL, работающая из коробки, плюс каскадная репликация, просто супер вещь, которая решает очень много задач. Фактически это полный аналог Microsoft, только полностью бесплатный.

Еще одним интересным проектом был перевод базы бухгалтерского учета федерального оператора экспресс доставки на PostgreSQL. Этот проект запомнился тем, что клиента перевели на новую систему за одну ночь. Представьте, 150 бухгалтеров ушли вечером, закрыв 1С в MS SQL, а утром пришли и открыли его в PostgreSQL. Ничего не поменялось в худшую сторону, некоторые операции стали работать лучше, некоторые продолжили работать точно так же. Клиент был настолько доволен результатом, что принял решение перевести все свои базы 1С, как существующие, так и проектируемые, на PostgreSQL. Он даже он готов рискнуть перейти на Linux в 2026 году.
Технические стороны перехода
Какие особенности нужно учитывать, чтобы угодить клиенту при переходе на PostgreSQL? В принципе имеется 3 этапа. На первом надо настроить код 1С, на втором – подкорректировать настройки самого PostgreSQL, а на последнем – заняться подбором железа. Рассмотрим подробно каждый из них.
Код 1С. На этом этапе больше всего проблем, но когда они решаются, получаем огромный эффект. Конкретный пример: возьмем номенклатуру 300 тысяч позиций и попытаемся сформировать ценники и этикетки на все позиции. У конкретного заказчика MS SQL справлялся с этой задачей за 15 минут. Полностью настроенный PostgreSQL на Windows на том же железе, к сожалению, пришлось ждать 6,5 часов. Он справился, но с большой задержкой. Еще один пример: номенклатура 10 тысяч характеристик. Открывая позицию номенклатуры, заказчик хочет видеть не только 10 тысяч характеристик, но еще и остатки по каждой характеристике, да еще и в разрезе складов. Опять же MS SQL справлялся за 30 минут, а PostgreSQL пришлось ждать 12 часов. Но все гениальное – просто. Более того, написано на ИТС фирмы 1С. Основной причиной такого поведения было левое соединение с виртуальной таблицей последних средств. Здесь главная рекомендация – выносите срез последних виртуальных таблиц в отдельную временную таблицу и затем уже делайте соединение, как требует бизнес-логика клиента. После этих изменений в коде (дольше их было искать, чем менять), скорости стали следующими: вместо 6,5 часов печать ценников производится за 13 секунд, вместо 12 часов открытие номенклатуры стало занимать 10 минут. Это совершенно приемлемые условия.
Еще одна рекомендация, правда, ее сложнее выполнить. Попробуйте избавиться от полного соединения. Тут уж если бизнес-логика позволит.
Никаких других рекомендаций нет.
Еще раз подчеркну, что все массовые конфигурации 1С прекрасно показывают себя на PostgreSQL. Не бойтесь переводить типовые инсталляции на PostgreSQL. Все отлично. Никаких задержек даже у такой тяжелой конфигурации как Комплексная 2.0 (там только запуск первого соединения к базе занимает около 1,5-2 минуты и минус 2 гигабайта на сервере 1С оперативки).
Перейдем ко второму этапу – настройки самого PostgreSQL. Как наточить нашу систему в связке с 1С?
Для 1С используются (? Время: 12:00). Одним из главных патчей, которые влияют именно на быстродействие, является online_analyze. Обратите внимание: на сайте 1С последняя релизная версия PostgreSQL вышла 1,5 года назад, новее нет. Она содержит критичную ошибку в конфигурации PostgreSQL. Этот патч (online_analyze) отключен. То есть мало того, что 1С и так любит временные таблицы, а PostgreSQL их недолюбливает, в конфигурации еще и патч отключен. Конкретно эта ошибка заставила нашу компанию отказаться от использования PostgreSQL на полгода. Мы поставили, попробовали, ужаснулись, но времени разбираться не было. А когда еще раз все перечитали, поменяли off на on, все поехало. Дальше остаются тонкости.

Еще несколько важных настроек.
1. Не отключайте autovacuum. Единственный оправданный случай, когда можно отключить «автовакуумное» время, — это загрузка DT (? Время:13:40) в базу. Тогда, действительно, он будет создавать лишние блокировки. Загрузка – монопольная операция, в базу больше никто не заходит. Вы отключаете autovacuum, все спокойно создается, а затем включаете обратно. Но чтобы autovacuum еще и плодотворно трудился и не сильно нагружал систему, количество worker-ов должно быть как минимум 4, а в идеале – 25% всех ядер, которые выделены серверу базы данных для работы с PostgreSQL.
2. Оnline_analyze.enaible обязательно on. Кто пробовал, и не устроило быстродействие, пересмотрите настройки в PostgreSQL. В самом конце, в самом неприметном месте, может быть такое «чудо».
3. synchronous_commit = off. Эту настройку могу порекомендовать, только если fsync включен. Тогда мы экономим время записи транзакции. Она записывает только валы, и дальше идем, не ждем записи базы.

4. В PostgreSQL имеется еще одно ограничение: здесь нет инструмента, похожего на профайлер. И чтобы собирать статистику, помимо технологического журнала 1С, рекомендую включать статистику logging_collector (оn).
5. Следующий параметр позволит ограничить запросы 10 секундами. Все, что быстрее 10 секунд, не надо собирать, иначе соберёте гигабайт, а все что выше – собирать. Параметр log_min_duration_statement варьируете, как хотите, собираете сначала пики, когда десятисекундные пики срезали, собираете трехсекундные и так далее.
6. Еще один параметр – update_process_title. Недавно появилась статья о результатах синтетического теста именно на Windows. Отключая параметр «обновление ID процесса», люди получили производительность в 2 раза выше. Но это только на очень серьезных нагрузках. В эксперименте тест начинал оправдывать себя только после 2 тысяч одновременных соединений. При этом на маленьких нагрузках это тоже не приводит ни к чему плохому. Все работало как раньше. Но на всякий случай включите, вдруг к вам зайдут 2 тысячи человек, а у вас система не выдержит.
Переходим к последнему этапу – подбор железа. Тут есть пара особенностей.
Во-первых, PostgreSQL не умеет работать многопоточно на много запросов. Один запрос – одно ядро. Поэтому количество ядер является достаточно критичным параметром при подборе железа сервера. Заставить PostgreSQL работать по-другому в нашей компании пока не знают как.
Второе ограничение. Мы живем в эпоху твердотельных накопителей. Нам повезло, они стали доступны и в то же время настолько надежны, что их можно использовать для баз данных. Единственное отличие: PostgreSQL в отличие от MS SQL всегда-всегда пишет в новое место, всегда создает рядом файл, неважно обновление это или нет. MS SQL создает файлик mdf, когда он пометил строчку на удаление, он пишет туда же. Это с одной стороны влияет на скорость, с другой – очень быстро наступит деградация ssd, если ваша операционная система и raid контроллеры не поддерживают команду TRIM. Иначе ssd (даже терабайтные) серверной версии «умрут» очень быстро, даже на 20 гигабайтной базе. На это обратите особое внимание. TRIM надо поддерживать. Обязательно.
Чтобы уменьшить требования к дисковой системе оборудования, можно воспользоваться несколькими трюками. Первый – директорию статистики перенести в диск оперативной памяти. Чем это хорошо? Это никогда не занимает много места – 256 мегабайт выделили, создали диск, перенесли. Даже если неожиданно каталог исчезнет, PostgreSQL не остановится. Просто будет появляться ошибка, что некуда записывать статистику. Тогда достаточно создать каталог заново, и статистика продолжит собираться. Несмотря на то, что директория не занимает много места, туда каждый процесс пишет очень много потоков, сильно нагружает диски. Очень рекомендую перенести директорию.

Первый трюк – это, можно сказать, must have. А второй – требует внимательности и аккуратности. Речь идет о переносе каталога журнала транзакций в оперативную память. В нашей компании это есть. Но я вам рекомендую это делать только в том случае, если у вас есть постоянный автоматический мониторинг репликаций, лучше еще и репликация каскадная. Если вдруг что-то пойдет не так, база встанет. Обратите внимание, если рискнете, нужно протестировать пиковые нагрузки на свои системы, чтобы понять, какой объем вала будет занят в оперативной памяти, чтобы выделить место заранее с запасом. Иначе, неожиданно сервер может остановиться.
Разработчики PostgreSQL, наверное, будут против такого решения, но оно очень помогает снизить нагрузку на дисковую подсистему. И в принципе где-то имеет право на жизнь. Наша компания пользуется таким решением год, и пока все хорошо.
Фичи
У PostgreSQL есть несколько неприятных особенностей, некоторые из них можно «пережить», другие – достаточно сложно.
Первая: PostgreSQL не умеет делать дифференциальное резервное копирование. Только полный backup. Казалось бы, ну и что? А то, что теперь место на резервном сервере, если вы хотите хранить информацию месяц (стандартный режим хранения), должно быть почти в 20 раз больше чем при использовании MS SQL.
Вторая: технологическое окно каждый день должно быть достаточно большим, чтобы спокойно сливать резервные копии. Как это обойти? Опять же с помощью репликаций. Настраиваете реплику, сливаете копии с серверов реплик и все прекрасно. Production CD работает, сервер реплики может иметь на борту любое сетевое хранилище данных, а там сливаете и сливаете.
Еще один момент – гораздо более серьезный: PostgreSQL не имеет средств валидации файлов backup. Совсем. Вы сняли backup и никогда не узнаете, можно ли из него восстановиться. Казалось бы, ладно, восстанавливайся, проверяй, что база целая. Отлично. А если база в 15 терабайт и восстанавливается 3 дня? Я трое суток не буду знать, у меня на тот день база живая или нет? Здесь разработчики нам обещают, что в версии 9.6 либо 9.7 появится средство валидации, а также дифференциальные backup. Но пока их нет. На это надо обратить внимание. Резервная копия – спокойный сон для админов. Такого тут нет.
В связи со всеми описанными моментами мониторинг системы на PostgreSQL особенно важен. Потому что нет профайлера, нет валидации backup, нет еще пары фишек, которые MS SQL имеет.
Поэтому рекомендуем настраивать средства мониторинга. Можно писать свои, использовать известные, например, Zaibix. Надо мониторить параметры железа, параметры баз данных, дополнительно мониторить еще лог, и вытаскивать из него ошибки…
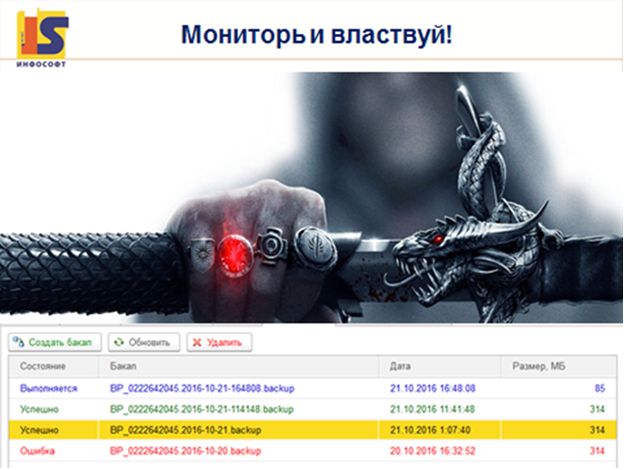
В компании «Инфософт» решили проблему валидации backup-ов следующим образом: на 1С мы написали специальный веб-сервис (его можно увидеть на картинке). Что он делает? Посмертно проверить файл backup невозможно, но в процессе создания backup утилита (? Время 22:38) пишет лог ошибок. Мы анализируем во время создания backup лог, выводим в отдельный файл лог ошибок, и если файл пустой, значит, backup создался удачно. Если хотя бы что-то помешало это сделать, файл будет содержать текст ошибки. Далее достаточно администраторам выдать само сообщение, что какой-то backup ошибочный. Они уже разберутся, проверят все логи и остальное.
В завершении хочется подчеркнуть, что PostgreSQL позволяет не только жить в парадигме «денег нет, но вы там держитесь», но еще и жить комфортно и безопасно. А все ограничения, которые есть, в принципе удачно решаются.
Отдельное спасибо команде Postgres Pro за то, что они очень быстро делают сборки для 1С. Фактически спустя месяц после появления релиза PostgreSQL на сайте уже есть сборка для Linux и Windows. Пожалуйста, тестируйте. Причем, сборка для Windows крайне удачна, setup делает за вас 90% настроек, остается буквально чуть-чуть «подшаманить» и все.
Пробуйте, дерзайте, у вас точно получится. У нас же получилось!
***************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 DEVELOPER. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Статья хороша (хоть и смахивает на рекламную), но содержит кучу ошибок….
Не очень укладывается в голове ограничение — один запрос — одно ядро… т.е. если у меня 32 ядра, то максимальное количество одновременных запросов 32? как это сочетается с несколькими тысячами одновременно работающих пользователей?
В статье вы пишите, что при переходе на postgre — быстродействие оставалось либо прежним, либо лучше..
не лукавите ли вы? на моей практике ровно наоборот.
Интересны причины перехода на postgre?
(2) ну, вообще-то это обычная вытесняющая многозадачность.
Запрос немного поработал на ядре, отдал ядро другому, сам спит.
Автор имел ввиду, что выполнение одного запроса не распараллеивается.
(3)
не лукавите ли вы? на моей практике ровно наоборот.
Проблема компетенции. Если просто поставить постгрес и оставить его работать в режиме микроволновки, то конечно же, он будет работать медленнее чем стоковый MS SQL.
Тут как с телескопом — можно в окна подглядывать, а можно на звезды смотреть.
(4) сходу две:
1. На первом месте и зачастую единственном — стоимость
2. Импортозамещение (сейчас много клонов postgre под русской вывеской)
(3) согласен. по моим впечатлениям мссиквел работает на порядок(раз в 10) быстрее чем постгри. Причем я в свое время нанимал опытного админа для настройки постгри — ускорение было на большом запросе в консоли запросов процентов на 10%.
(4) Халява сэр.
Даже не знаю. У нас все на Postgree. Когда в организацию приехала 1С — даже не думали про MS. Все знают постгри — на нем и завели. 140 пользователей. Все нормально.
вот в этом случае я бы хорошо подумал бы на месте системного администратора
Вопрос: Почему нельзя использовать 1 лицензию для админа, ведь с SQL сервером конектится только 1 учетка?
Ответ: В Лицензии на клиентский доступ к Microsoft SQL Server указано: «Каждая Лицензия на клиентский доступ дает право доступа к Серверной Программе с одного конкретного компьютера, рабочей станции или иного цифрового электронного устройства». Таким образом, число лицензий на использование Microsoft SQL Server должно быть не меньше числа пользователей, одновременно работающих с «1С:Предприятием 8» в клиент-серверном варианте.
Попробовал посчитать ценник: получается используя модель лицензирования на 8-ядерном процессоре при цене на ядро выйдет сумма в 3717 * 8 * 60 = 1,7млн руб.
мде…
Статья для тех, кто все знает про Postgresql, только не знает, как его соединить с 1с. Т.е. целевая аудитория очень узкая.
Я вот не уверен что в итоге получится дешевле — #$@ля с бесплатной СУБД — найм админов, программистов, обучение их, страдания пользователей, простои, потерянные бэкапы, переписанные запросы типовых конфигураций или покупка MS SQL…
Для контор из Linux World это всё дело всё-таки ИМХО.
1С и с MS SQL то работает безобразно, но там хотя бы были десятки лет обучения и исправления — регулярно долбят в мозг несчастные программеры, которые пытаются разобраться почему «ваша программа висит». Но собственно в последнее время и их перестали слушать — огородившись «ЦКТП» с лозунгом
«все вы идиоты кроме ЦКТП»«всё фигня кроме пчел», а на практике оказывается «да и пчёлы тоже фигня».А уже как 1С с PSQL работает — тут стоит сказать что «очень хорошо что нет профайлера»…
Вообщем без КОРП техподдержки, договора с ребятами из PSQL Russia, договора с ЦКТП я бы на высоконагруженных проектах на PSQL не решился бы…
(14)
Полностью согласен. И уж если переходить на PGSQL, то ставить его точно не на виндовз сервер.
(15)
Это вообще отдельная тема…. хоть раз пообщаться с C++ разработчиком который писал и там и там, он вам расскажет как «унифицирован код»
и «одинаково работает» «кроссплатформенное».
Реально одинаково везде работает — Java. Но Сервер СУБД на Java — это примерно как 3D шутер на 1С.
А всё остальное должно работать там для чего оно разрабатывалось.
MsSQL — на Windows
PSQL — на Linux.
(14) покупка или не покупка MSSQL — это вполне чёткая осязаемая для руководства цифра. а вот остальное:
найм админов — в топку, есть же здоровенный штат в полтора тыжпрограммиста
обучение их — в топку, они ж гугл умеют
страдания пользователей — да они вечно ноют, лишь бы не работать
простои — мы теряем абстрактные миллионы, посчитать мы их не можем
потерянные бэкапы — пока не клюнет, там наверху всем пофиг
переписанные запросы типовых конфигураций — им же зарплату за это платят, пусть работают
мы сейчас тоже сидим и грустим: поставлена задача — сэкономить на лицензиях MSSQL.
… Но, конечно, не знаю, как там для венды. Труадмены вообще логируют все, что приодит на 5432.
Для хайлоад-сегмена нужны реплики, с которых уже и делаются бэкапы. про реплики вообще …
Сейчас в планах развития постгри инкрементальные бэкапы и валидация бэкапов. 1С, по-сути, ломается только в случае выхода из строя системных таблиц (config и прочее), поэтому особых трудностей с восстановлением данных можно избежать, если понимать, что и как хранится. В любом случае можно создавать бэкапы даже обычной выгрузкой таблиц в файлы (COPY FROM MyTable TO FilrName…[STDOUT | bzip — arcfile]), при этом есть возможность бэкапить что-то с таймстэмпом, большим, чем данные предыдущей выгрузки (если в таблице есть таймстэмп). Так решают проблемы инкрементального копирование некоторые крупные пользователи — в принципе универсальный подход. Можно и журнал для реплик писать, а потом его накатывать на бэкап — но это уже сложнее технически (хотя, если разобраться, не так и сложно).
Все зависит от того, на сколько конкретные специалисты готовы решать подобные проблемы, выискивая подход не только в документации, но и в собственном мозге.
А по поводу скорости, то хорошо настроенный постгри обычно быстрее хорошо настроенного ms sql (по крайней мере Лустин в свое время писал, что его DBA по потгрям достигал лучшей производительности, чем DBA MS SQL — и я ему тут верю, кстати, хотя, на мой взгляд, он и не всегда адекватен). У меня на обычной машинке (RYZEN 5 1600/16Gb/8.3.10.2299/PSQL 9.6.2 (PGPRO)/Ubuntu 17.04_64) скорость теста Гилева 36,78 (можете посмотреть в списке теста по имени starik2005 (#k8SjZc9Dxk#k8SjZc9Dxk>) bk — ru), при том файловая — 65-70. А это вполне сопоставимо достаточно мощномуXeon’чику на MS SQL и серверной винде). Более того, у многих Хеончиков скорость при аналогичной частоте (3,2GHz) меньше, но вряд ли райзен работает быстрее Хеонов…
(18)
Меньше только если сервер «забыли» настроить. E3-1230, после минимальной настройки, выдаёт 45-50 «попугаев» в клиент серверном режиме. Причём, этот тест выполнялся в виртуальной машине, которая на том серваке крутилась, а на «голом» железе должно быть ещё на 15-20% быстрее.
Я, «слава Дарвину», базы перенес с PostgreSQL (развернутый до меня) на MS SQL 2016. Расчет себестоимости в УПП стал делаться 10 минут, на том же сервере, на PostgreSQL 50 минут «лопатило». Создание архивной копии базы — 3 минуты, вместо 40 минут. Расчет документа «Зарплата» стал 30 секунд работать, ранее 5 минут.
Так и не понял зачем до меня ребята на постгри базы развернули, а оптимизации никакой не делали. Я разбираться не стал, ибо никогда с постгри надеюсь больше не встречусь, плюс на фирме лицензия на MS SQL.
Уж извините, что в разрез статьи…
(19) тут не так давно чел на хеоне с 1.1 ггц на мсскуле и прочее получил 1.67 балла, после переноса логов в озу и прочей свистопляске получил 4.7. У меня на калькуляторе быстрее.
Вообще, низкая производительность 1с с постгри и мастдаевским скулом — это проблема компетенций дба. А это уже от нежелания развиваться. Не так давно почили память закопирайтеного формата mp3, который так вот взял и помер внезапно. Иак что однажды может настать день, когда Вам пригодяться компетенции в linux и postgres — не стоит думать, что ничего не меняется в этом мире.
(18)
У всех в том списке TCP sql примерно половина от файлового варианта.
За оптимальность работы с СУБД четыре других показателя отвечают, они в таблице, а не в столбиках. Столбик мерит проц.
Вопрос к автору.
Не могли бы вы прогнать старенький тест Гилева на своем окружении и сюда запостить.
И напишите поподробнее, где логи, где данные. Как именно организовано хранение. Сколько памяти и ну все хардверные дела относящиеся к делу.
Очень интересный опыт.
(12)
Ответ: В Лицензии на клиентский доступ..
Попробовал посчитать ценник: получается используя модель лицензирования «на ядро» на 8-ядерном процессоре при цене 3,717$ на ядро выйдет сумма в 3717 * 8 * 60 = 1,7млн руб.
Все равно не понял. К ядру MS SQL подключается пользователь с 1C Сервера. Остальные пользователи соединяются к 1С Серверу.
Почему лицензий должно быть больше одной? Баз может быть много — сессий много — но логин — то нужен всего один, с одного устройства.
Ну когда в кластере 1С два сервера, то понятно — две лицензии и то, если сервисы на разных компах.
Че-та наверно здесь гораздо меньше денег.
«А если бы он вез патроны?» (из старого советского фильма)
Внимательно посмотрел на дату создания темы и даты комментариев.
Подумал, что кто-то поднял из небытия старую тему, годов так 2009-2011.
Но нет — год 2017, наши дни, а характер ответов не меняется, все та же гордость за свои личные неудачи с PostgrеSQL. «Нам же надо работать, а не разбираться не пойми в чем».
PostgreSQL уже довольно долгое время умеет многопоточный backup и restore,
параметр —jobs=n для pg_backup и pg_restore может весьма ощутимо сократить время этих операций на многоядерных серверах.
Параллелизация выполнения запросов также активно развивается. В 9.6.2 неплохо работает параллельно последовательное чтение
Например, sel ect count(*) fr om test; (для таблицы в примере из статьи по ссылке), выполняется до 8 раз быстрее на 8 потоках(при наличии 8 физических ядер, конечно).
А в будущих версиях (PostgreSQL 10 beta) «Обеспечено распараллеливание с задействованием нескольких ядер CPU таких операций, как сканирование индексов и битовых карт, выполнение запросов со слиянием таблиц (JOIN)», Это одно из многих добавлений/улучшений.
Побороть «нежелание» PostgrеSQL разбираться с «большими и тяжелыми» запросами можно, пригласив не только опытного админа, но и специалиста по оптимизации этих запросов в 1С.
А статья хорошая. Хотя бы тем, что описан действительно удачный опыт людей, желающих серьезно разбираться в этом вопросе и решать задачи.
(18) хотелось бы взглянуть на postgresql.conf
(8)
Впечатления на чем основаны? 10 раз это радикальная разница.
Статистика есть какая-то?
(16)
И везде она работает, и очень все хорошо. А на С++ писать плохо, как одна бабушка сказала.
(25)
Это справедливо только когда конфигурация полностью своя, что встречается достаточно редко, а работать, чаще всего, приходится с типовыми, для которых подобная оптимизация означает, либо существенное удорожание процесса обновления, либо полный отказ от обновлений.
«Я не могу просто ходить с флагом «Postgres – наше всё». Нужно руками доказывать, что это работает» – Алексей Лустин
Хорошее интервью. Социальная цель — борьба со страхами и предубеждениями.
(27)
Могу предположить, что на опыте эксплуатации не настроенных MS SQL и PostgreeSQL, на, скорее всего, не настроенном виндовз сервере.
(30) «Сильно переписанная типовая»(далее следует название конфигурации) с проблемами быстродействия нередкий гость в темах, как на Инфостарте, так и на других форумах, тем не менее.
По поводу типовых согласен.
(26)
Все по pgtune + 5000 на статистику.
(20) И правильно! Если за СУБД платит акционер, а Вам лишь бы ничего не делать, то да, MSQL лучше по всем показателям!
(34)
А список «всех» показателей где?
1. Цена — однозначно выигрывает PG.
2. Скорость — работают примерно одинаково на хорошо настроенной архитектуре.
3. Отказоустойчивость. Linux-системы в этом плане куда лучше, чем системы от мелкомягких. Не говоря уже о Unix-системах, в которых ПО работает годами. На мэйнфреймах ошибки допускались один раз в 20 лет. Кстати, тут нужно обратить внимание на такую фразу:
Нас это вполне может ждать в будущем, если не развивать свои решения.
4. Стоимость владения. Вот тут может установиться паритет, когда для MS дешевле поддержка, а для PG дешевле приобретение. Но это только если текущий специалист не разбирается в PG на достаточном для обеспечения работоспособности уровне. С учетом весьма обширной документации по PG можно ожидать, что скоро компетенции админов PG дорастут до некомпетенции админов MS, после чего произойдет качественный скачек используемой эффективности первого. Сейчас народу маловато, кто в PG хорошо понимает.
5. Что-то еще?
(33) Не верю. По PGTUNE не дает такой производительности
(36)
На какой машине не дает конкретно?
(37) AMD FX 8350 1600/16Gb/8.3.10.2299/PSQL 9.6.2 (PGPRO)/Ubuntu 17.04_64
(25) вы не пробовали переписать половину запросов в типовой ЗуП 2.5 например? когда на численности сотрудников под 1000, расчет зп, использующий срез последних с левым соединеним, разбытым на 5-10 модулей. выполняется вместо минут около часа?
И при каждом обновлении их контролировать?
(38)
Ну как бы не стоит сравнивать FX 8350 c Ryzen 5 1600. У меня на FX 8320 гилевский тест давал максимум 28-29, что говорит о том, что на 8350 будет максимум 30.
(39)
Все зависит от настроек. Если что-то на PG работает медленно, то тут три пути: увеличение производительности железа, тюнинг настроек и модификация кода.
(39) 1С вопросы оптимизации, кстати, решает.
Было —
Стало —
Проявлялось именно при расчете зарплаты.
Сейчас полностью типовая ЗиК БУ 1.0 на последней платформе считает весьма резво.
(40) Все равно не верю, да он дает 28 попугаев, но это не заслуга pgtune
(3)
Нет не лукавлю
Напишите ваше сообщение
(2)
Текстовка не всегда точно передаёт сказанное
Postgre может использовать только 1 ядро на 1 запрос (до версии 9,6), т.е. нельзя использовать для выполнения одного запроса 2 и более ядер. Смысл именно в этом
Напишите ваше сообщение
(1)
(16)
MsSQL — на Windows
PSQL — на Linux.
В общем да, но поскольку мир 1С состоит из Windows на 99%, то рассказывал именно про то что и на Windows тоже работает и достаточно успешно
(25)
+
—
Эти два утверждения противоречят друг другу. Можно разбираться в вопросе производительности постргреса… а можно решать задачи бизнеса
(18) ИМХО,
, видать в качестве DBA MS SQL он сам перст.
Больше похоже на фейл.
(35)
2. Скорость — работают примерно одинаково на хорошо настроенной архитектуре.
На одинаковом железе?
Хорошо настроенной, насколько хорошо?
Что именно примерно одинаково?
А если настраивать внутри СУБД, все будет по-прежнему одинаково или есть отличия по быстродействию и отказоустойчивости?
(46)
MS SQL есть и под Linux
Евгений, да, есть
Только стоимость MS SQL от того что он на Linux никто не отменял
Главный двигатель перехода на PG — это стоимость
(51)
Вот вот. И не надо говорить что оно шустрее.
Оно дешевле и работает приемлемо.
(52)
При правильной настройке и изменении кода 1С (при необходимости) оно как минимум не медленнее, а иногда и шустрее
Есть буквально 2-3 сценария где MS SQL прям намного шустрее, но 1С это сейчас исправляет
Последний пример — в последней версии БСП исправлены тормоза RLS при использовании PostgreSQL. Это было никак не решить на уровне БД, только изменением кода
(53)
При правильной настройке и изменении кода 1С (при необходимости) оно как минимум не медленнее, а иногда и шустрее
При правильной настройке чего? СУБД?
а иногда, как часто?
(53) Антон, меня просто смущает факт утверждение шустрости самого движка СУБД в сравнении с СУБД MS SQL.
Последний пример — в последней версии БСП исправлены тормоза RLS при использовании PostgreSQL. Это было никак не решить на уровне БД, только изменением кода
Вот вот.
Стало быть, не всё так вкусно и мягко, как и сказано Вами в статье.
Т.е. нужно каждому долбобею на лоб наклейку: «Помни про левые соединения виртуальных таблиц… и погладь кота!»
(43)
Во что конкретно Вы не верите? В 36-38 на Ryzen 5 1600? Ну у Вас же тест Гилева есть — там список произведенных измерений прилагается.
pgtune просто позволяет указать правильные настройки для максимального использования памяти железа при работе с высокой нагрузкой. В «базовом комплекте» постгри размеры буферов указаны таким образом, чтобы эту память почти не использовать. Статистика — это периодичность сбора статистики по измененным записям, чем больше поставите — тем реже постгри будет запускать анализ статистики для таблицы. По умолчанию стоит 100, а 1С рекомендует ставить 5к, что позволяет снизить нагрузку на сервер при таком количестве вставок, как 1С любит…
(55)
Ну не надо свои комплексы так пиарить — люди могут Вас неправильно понять )))
Постгрес работает достаточно хорошо с рядом продуктов 1С, с рядом других продуктов — недостаточно хорошо, но это решаемо. Например, в свое время в одной компании была база бухгалтерии с допиленным модулем под сельскохозяйственное предприятие (2-я бухня). Так проведение документов на файловой базе работало в районе 10 минут, на MS SQL — в районе получаса, а на постгри (который был поставлен на серверную винду рядом с MS вообще без настроек) — около 20 минут. Это было еще в далеком 2010-м году, когда 1С с постгресом работала весьма условно. Но вот для этого конкретного варианта оказалось так, что постгрес работал в полтора раза быстрее скула, который работал в три раза медленнее файловой. А был пример, когда действительно ЗУП 2.5 работала веьма медленно с посгресом из коробки, при этом достаточно шустро молотила в MS SQL и фаловой, при этом даже простое изменение настроек позволяло постгресу выйти на достаточный уровень производительности.
(54)
Типовые конфигурации работают на ура
А любую переписанную нужно анализировать
А Вас не смущает что при установке MS QSL по умолчанию, при серьёзном объёме базы и количестве пользователей — на сервере быстро закончится место, скорее всего будут блокировки на уровне СУБД и т.д….
Это я к тому что любую БД надо уметь настраивать и не пренебрегать этими знаниями.
(58)
Так ведь и я к тому же, что у каждой СУБД своя специфика и свои настройки.
в (57) — проведение документов на файловой базе работало в районе 10 минут, на MS SQL — в районе получаса, а на постгри (который был поставлен на серверную винду рядом с MS вообще без настроек) — около 20 минут.
Говорит о том, что с MS SQL что-то не так. Возможно, что около 1С it-ландшафт построен неправильно.
Если я всех пользователей загоню в терминал на сервер приложений, он же сервер СУБД, почты и домена… То и у меня настанет разруха.
Думаете так не бывает? Бывает.
(59)
Всяко бывает. Просто не следует свои навыки незнания иных СУБД, кроме MS SQL (который типа работает и из коробки удовлетворительно, что может говорить и о незнании MS SQL) выносить на свет.
(58)
>>А Вас не смущает что при установке MS QSL по умолчанию
Почему меня это должно смущать?
Я же не запускаю в продакт СУБД c default-ными настройками.
(60) Извините, в чем, собственно, не знание выражается?
(61)
А вот это обнадеживает.
(60) Разве где-то было утверждение «из коробки», «по-умолчанию»?!
(63)
Ну хотя бы в том, что оное пишется слитно. Вот, одним незнанием меньше ))) Но тут есть и те, кто даже слово «Вас/Вам/Ваш/Вы» пишет с маленькой буквы и доказывает, что именно так и есть правильно.
А по поводу незнания о постгресе, то оно выражается в совокупности Ваших предыдущих сообщений, которые намекают на то, что и разбираться с этим Вам никакого желания нет.
(64)
Было утверждение о том, что постгри у Вас работал существенно медленнее, чем MS SQL. Сейчас я понимаю, что MS SQL вы из коробки не юзаете (Вы сами об этом говорите в 61), но постгри Вы пробовали из коробки (о чем говорит пост 49 и многие посты до него).
(66) Нет, это не так. Постгри тоже настраиваем, тк есть PostGIS.
Для постгри плюс еще и в том, что код открыт и её можно сертифицировать для определенных нужд.
(66) меня просто смущает факт утверждение шустрости самого движка СУБД в сравнении с СУБД MS SQL
(65)
А оно и есть правильно, если применяется при обращении к группе лиц, так-что всё зависит от места применения и смысловой нагрузки. Вот например:
(58)
А любую переписанную нужно анализировать
Яркий пример попытки ввести в заблуждение. Не все типовые, и не совсем на «ура». И, как я уже отмечал выше, именно со своими разработками больше «руки развязаны» в плане оптимизации решения под PGSQL.
Хорошо настроенный постгри работает почти так же производительно как и мс эскуэл, плюс бесплатен, плюс код открыт. Но, применять его надо «по месту» — например, необходима обязательная сертификация программно-аппаратного комплекса, в штате есть хороший пг-дба, нет возможности купить мс эскуэл… Но вот так безапелляционно заявлять, а потом ещё и упорно доказывать, что постгри быстрее-лучше-сильнее — не хорошо. Тут присутствуют, надеюсь, профессионалы, а не сектанты.
(68)
Как это не забавно, но в отрыве от данных — оно так и есть, движок пг и был, и остаётся быстрее. А вот дальше начинается самое весёлое — заставить его быстро работать с имеющимися данными. Причём не просто данными, а данными, чтение и запись которых, в нашем случае, обрабатывает платформа 1С:Предприятие максимально универсальными алгоритмами.
(68)
Ну для разных задач шустрость разная. Есть разные показатели в разных задачах, при этом в одних выигрывает один, в других — второй. Но я ссылался в частности на Лустина, который утверждал, что его DBA (администратор баз данных) смог добиться лучшей производительности в PG SQL при всех танцах с бубном вокруг архитектуры среды.
(69)
Да, при обращении к группе лиц — правильно, но есть те, кто считает, что и при обращении к единственному лицу тоже можно писать это слово с маленькой буквы — но это так, лирическое отступление.
(69)
Полностью согласен, ибо он не лучше и не хуже. Он — особенный. Но при этом позиция, в которой доказывается, что MS SQL однозначно лучше — тоже не выдерживает критики, ибо все зависит от способностей организации, выбравшей свободное решение, справляться с проблемами, в этом случае возникающими. Но если нет бэкапов — то и на старуху проруха бывает…
Меньше функций — больше скорость.
Больше функций — меньше скорость.
И да, DBF 7.7 был быстрее, чем SQL 7.7, в однопользовательском режиме, когда функций требуется меньше.
Что там у Postgre с функциональностью?
(72)
Смотря чего делать. Он, например, так умеет:
VALUES (1)
UNI ON ALL
SEL ECT n+1 FR OM t WH ERE n < 1000
)
SEL ECT substring(to_char(n, ‘000000’) from 2 for 4)
FR OM t
Кто-нить может сказать, что будет в результате?
(71)
Ну, тут уже сложнее, или низкая грамотность, или желание подчеркнуть неуважительное обращение.
(73)
Вся «соль» в том, что не важно КАК умеет пг, важно КАКИЕ возможности пг использует платформа 1С.
А то я помню то время, когда он и транзакции ещё не умел, но для решения ряда определённых задач подходил идеально.
(74)
Вся соль в возможностях, а что там 1С умеет из этого — вопрос только для 1С-ников. а по поводу транзакций, то он их в том или ином виде всегда умел, просто 1С их готовить не умела — ограничивалась блокировкой таблицы целиком. С появлением управляемых блокировок, 1С стала куда ближе к постгресу, чем это кажется некоторым людям.
(75)
Тут, как бы, обсуждение пг в контексте работы совместно с 1С.
(75)
Нет. Когда добавили поддержку транзакций в пг — это было целое событие, вот только год не помню, но точно гораздо раньше появления 1С:Предприятие 8.0…
(76)
…Может пруф какой дадите?
(71) Леша Лустин вроде как не позиционировал себя и команду как евангелистов постгри.
Вроде как читал лекцию или видео какое-то было, так ведь в основе же паблик концепция «постгри на стероидах», которая появилась самостоятельно от Леши.
(77) вроде в версии Postgres 8.3 вроде как в 2012 году
+(77) это вроде как
ранее использовалась SAVEPOINT
(77)
Забавно, постгри существовал задолго до того как опубликовали 8.3 и был вполне себе популярной СУБД —
А поддержка транзакций, появилась начиная с 7-ой версии —
Как ни странно, сейчас найти упоминания об этом уже не просто, а тогда это была «бомба» — бесплатная оупен-соурс СУБД с функционалом не уступающим дорогим коммерческим продуктам.
(81) ИМХО, устраивать холивар какая СУБД лучше в чистом виде имеет смысл поднимать,например, на sql.ru.
То, что ребята популяризируют Postgres применительно к 1С, так честь им и хвала.
Эти сравнения производительности 1С под тем, или иным движком зачастую притянуты за уши под цели.
У кого-то чисто ради интереса, у кого-то коммерции для, у кого-то просто другого выбора нет.
Каждом своё.
(82)
Не имеет смысла ни на одном из ресурсов. Хороша та, которую лучше знаешь и точка.
Историю постгри можно и не знать, не все застали зарождение оупен-соурс движения, но популяризация должна быть взвешенной и объективной. Желательно с примерами настроек и скриптов… иначе можно получить обратный эффект, вплоть до абсолютного неприятия продукта сообществом.
(81)
Да, указывается, что транзакции в PG появились в середине 2000-го года. Но интересна и такая информация:
Т.е. в 2000-м году САП уже могла работать с 6700-ми юзерами на в общем-то медленной по современным дыннм машинке, а 1С даже с 1к юзеров на достаточно серьезном железе конца второго десятилетия XXI-века с жуткими тормозами работает. Вот где мы отстаем аж на 20 лет! )))
Смотрю бенчмарки от SAP, так там народ на 1к-ядерных SPARC’ах аж до 150к юзеров нагружают. Виндами там, конечно, и не пахнет, однако, не то что 1С-ами….
— и до 266к юзеров.
(84)
Не совсем. На тот момент 7.7 упиралась в производительность мс эскуэл да блокировки. Можно было и тогда сгенерить тест показывающий возможность работы до 4к юзеров с 1С, но, только на прямых запросах и от 1С там бы остался лишь интерфейс… да и 8 процессоров П3-550 — это далеко не «слабая» машина. По тем временам это было очень дорогое «топовое» железо. А учитывая разницу в стоимости САП и той же 1С:Производство услуги бухгалтерия, или как там она называлась — закупку подобного сервера под САП было гораздо проще обосновать, чем под 1С.
(85)
Ну, немного времени плюс САП-овские бюджеты на железо, то 1С и не такое покажет. Особенно на специально под такое количество пользователей заточенных решениях. Но, конечно, типовые тут уже не «взлетят».
(87)
Как пишут в газетах, работа в направлении «сверхбольших систем» уже идет.
200 с лишним баз данных … на 1,5 терабайта
Это не облачный сервис, а хостинг баз, не нужно его сравнивать с 1С:Фреш. Фреш работает по совсем иным принципам, и там, где у вас двести баз на полтора терабайта, во фреше будет одна гигов на двести.
Multitenancy потому что. Учите матчасть.
По существу же статьи:
1) Получив проектное решение положить wal в рамдиск, любой DBA сделает все, чтобы вас выгнали с проекта ссаными тряпками.
2) Windows принципиально иначе работает с файловым кэшем. Поэтому, ставя PG на Windows, необходимо понимать разницу в costs и рассказывать про нее PG. Иначе у вас все будет работать нормально ровно до тех пор, пока сохраняется избыточность по памяти.
имхо очень хорошая СУБД для бесплатной, но при эксплуатации бубен обязателен, запросы лагают и утекают в память, транзакции блокируются, неожиданная перезагрузка компа (сервера) может напрочь угробить службу — что еще пожелать, чтобы незадумываясь перейти на MSSQL 🙂 …
(88) не поверите, но я с Филипповым об этом на курсах подготовки к Эксперту разговаривал, указывая на то, что стандартный тест 1С с запуском кучей клиентов — это полная ерунда. Вот, смотрю, не зря я эту тему поднимал:
Но нужно понимать, что в SAP было среднее время открытия формы с данными до 1-й секунды. В статьях как раз скорость создание элемента справочника или документа не указана.
(91)
MS от этого тоже не застрахован. Тому пример — Skype, Пока все работало на Postgres — обрывы связи были нечастыми, а как все переехало на инфраструктуру MS, то падения проявляют себя постоянно. Вот буквально недавно Skype опять не работал существенное время.И если уж сама MS не может обеспечить бесперебойную работу Skyoe, что что говорить о других клиентах. Один товарищ рассказывал, что в ответ на обращение в MS о тормозах в базе 1С, пришло такое: «у вас в базе слишком много запросов». Вот прямо так, не в бровь, а в глаз )))
Почему PostgreSQL на windows запускают?
1С то на Windows лучше живет.
Хотя и полностью на Линукс живут базу.
Статья больше рекламная чем пользы.
(92) Даже по серверу никакой конкретики — «один, вполне обычный сервер». Видимо, основной задачей была проверка того, что система не загнется при таком количестве одновременно выполняющихся заданий.
Был опыт работы с Постгрес. В итоге никто из автоматизаторов не смог предложить услуги по улучшению быстродействия СУБД и работы 1с в целом. При этом пользователей было до 200 всего.
Перевели клиента на винду + скуль = все проблемы ушли.
(96)
Такое не только с постгри бывает. В компании где я сейчас работаю, горе «автоматизаторы» из партнёра номер 1 не смогли всё тоже самое, только с мс эскуэл.
(47) Задачи бизнеса своей компании автор публикации решает.
(59)
Думаете так не бывает? Бывает.
Я бы сказал так и надо, при современном железе. По шаред мемори 1с — ms sql работает резче.
почта с доменом на 100-200 — ерунда, если производительно организован диск.
Терминальный сервер можно выбросить в виртуальную машину на другие ядра.
Какая разруха? Нормально все