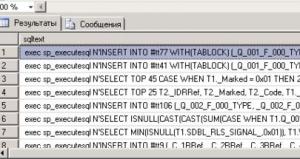



Для выявления тяжелых запросов часто используют данные трассировки. Подробнее можно узнать в статье: //infostart.ru/public/303656/ как собрать данные трассировки. Что ж, данные собрали, в таблицу загрузили. Выполняем запрос с группировкой по полю Duration для выявления наидлительнейших запросов:
Однако вот, что мы получаем:

В первых строках видно, что запросы одинаковые, но они не сгруппировались из-за разных имен временных таблиц #ttЧисло и параметров; замену параметров не рассматриваем, так как замена аналогична. Чтобы все же сгруппировать строки, необходимо заменить различающиеся подстроки одинаковыми. Сначала я сам взялся за обдумывание и попытки замены этих самых «#tt… », и не просто замены, а быстрой замены, но вскоре понял, что не все так просто, заменить-то можно, но быстро это никак не сделать — сканирование таблицы в любом случае. Эксперты 1С рекомендуют использовать функцию fn_GetSQLHash, приводящую строку к некоему хеш-виду, нам из нее необходима лишь часть, остальное удалим, поэтому я привожу только некоторый код из этой функции, который заменяет подстроку «#tt… »:
В этом варианте мне сразу не понравилось использование циклов для каждой строки. Я, конечно, рассматривал цикл, но только в самом последнем безнадежном случае. Теперь, когда сам сделать что-то устраивающее не смог, а официальное решение не совсем оптимальное, задал этот же вопрос на форуме: http://www.sql.ru/forum/1265293/kak-zamenit-tekst-mezhdu-dvumya-raznymi-simvolami
Предложенные ответы не решали полностью задачу, к тому же являлись неоптимальными. Однако один из ответов привел меня к решению, хотя и не универсальному — это использование CLR-библиотеки. По ответу, в интернете таких библиотек предостаточно, но мне хватило и той, что предложили: http://www.sql.ru/forum/1144247-a/faq-regex-parsim-zamenyaem-razbivaem-krutim-vertim
Итак, первым делом, проверяем, включена ли опция упрощенных пулов (lightweight pooling). Если включена, тогда надо разбираться, почему, нужна ли. Если обязательна, тогда на этом все закончено, придется использовать официальную функцию и забыть про регулярные выражения в MS SQL (некоторыми конструкциями регулярных выражений в like пренебрегаю, там все слишком ограничено не относится к нашей задаче). Подробнее: https://docs.microsoft.com/en-us/sql/relational-databases/clr-integration/clr-integration-enabling
Когда опция упрощенных пулов отключена, можно приступать к подключению CLR:
Затем в контексте определенной базы, в которой необходимо работать с регулярными выражениями, выполняем скрипт install.sql
Еще нюанс: при выполнении подобных изменений в настройках предполагается, что у пользователя SQL-сервера есть достаточно прав, а именно sysadmin и serveradmin.
Теперь результаты.
Вариант типовой.
use PerformanceAnalises
UPDATE [trace060720262] SET [TextData] = dbo.fn_GetSQLHash(SUBSTRING([TextData], 1, 4000));
(строк обработано: 2481423) время: 00:37:39
План выполнения:

Вариант с регулярным выражением
(строк обработано: 2481423) время: 00:21:04
План выполнения:

Если у Вас подобный план запроса, значит, быстрее уже некуда.
Выводы:
-
Замена подстроки в строке в любом случае является неоптимальной операцией, т. к. выполняется сканирование таблицы — оператор Table Scan, даже при наличии индекса. Поэтому лучше всего, чтобы был только один Table Scan.
-
В MS SQL нет регулярных выражений — это минус. Но можно подключить CLR-библиотеку, реализующую возможность использования регулярных выражений.
-
Производительность использования регулярных выражений существенно выше.
-
Не всегда есть возможность подключения CLR-библиотек. Необходимы права sysadmin и serveradmin. Не поддерживается при использовании упрощенных пулов (lightweight pooling).
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Малацца!
Сделал регулярное выражение универсальнее, оптимизировав тем самым замену:
И вариант с заменой параметров, лишних «exec…»:
автор молодец. но эта задача в выигрыше 10 секунд. не так интересна.
тк 1с разбивает запросы на части сохраняя промежуточные значения в временные таблицы.
и задача объединить эти запросы для выявления часто повторяющихся запросов значительно более ресурсоёмкая.
+(3)
но если номализованным текстам запросов сопоставить хэш — то задача объединения тестов сильно упростится.