
После жалоб пользователей на замедление 1С:Предприятие администраторы высказали подозрение, что причиной тормозов является Журнал регистрации. Журналы – это несколько файлов формата lgd от одного до двух гигабайт. Чтобы развеять все сомнения, и вооружившись трехзвенкой 8.3.12.1469 x86, а также инструментами от производителя, решено было изучить вопрос вдоль и поперек или другими словами, узнать, «что там под капотом».
Чтобы 1С:Предприятие хранила журнал в данном формате, необходимо его указать явно в конфигураторе или файле настроек. Либо просто удалить все файлы из каталога журнала, если там файлы предыдущего формата. Разделение данных, как было в предыдущей версии, не поддерживается. Корневой каталог журналов указывается в параметрах запуска службы после ключа -d. Например, -d “d: empsrvinfo”
Итак, журнал представляет из себя не что иное, как базу данных sqlite, хотя 1С использует свое именование расширения и даже свой драйвер для доступа, который входит в поставку платформы. Разработчики 1С не стали использовать предлагаемый авторами sqlite драйвер, а просто скомпилировали свой, видимо для совместимости и/или простоты использования, благо исходники доступны на сайте sqlite. Но используется он своеобразно. К примеру, если пометить на удаление записи в журнале любым доступным вам способом, то это ничего не даст потому, что 1С просто игнорирует эту метку. То есть при просмотре отразятся все без исключения записи.
Разработчики sqlite утверждают, что размер файла базы данных может превышать сотню гигабайт и даже сотню терабайт. Так что, если бы 1С:Предприятие тормозила из-за журнала, то скорее всего это могло случиться только из-за кривого драйвера от 1С или неумения его правильно готовить использовать. Хотя конечно могут влиять и внешние факторы, как например, дефрагментация диска и тому подобное. К примеру, одно из последних нововведений разработчиков sqlite – метод VACUUM. И хотя он также упоминается в драйвере 1С, на деле этот метод никак не используется или я не смог спровоцировать его выполнение. Если вы решите сократить полностью журнал из Конфигуратора, то вместо того, чтобы заново создать файл или основную таблицу журнала, 1С:Предприятие начнет удалять все записи в таблице EventLog. И если у вас он большого размера, то придется запастись терпением. За то при этом все пользователи могут продолжать свою работу в обычном режиме, вот только вряд ли при этом что-то отразится в журнале об их работе. Многопоточность? Нет, не слышал.
В документации сказано, что при загрузке информационной базы все записи журнала не очищаются. Для чего так сделано? Ведь если конфигурация иная, то в базе останутся никому не нужные записи об объектах предыдущей конфигурации, которых просто может не быть в новой. Видимо пользователю предлагается самому найти этот файл и удалить.

Службы 1С:Предприятие автоматически создает файл 1Cv8.lgd при первом же обращении будь то конфигуратор или web-приложение. Что интересно база не формируется сразу же целиком, а только по необходимости. К примеру, если установить уровень «Регистрировать ошибки», запустить регламентное задание, то создадутся только две таблицы, пусть и пустые. То есть о выполнении регламентных заданий вы не узнаете, пока не начнется нормальное ведение журнала, а для этого нужно хотя бы раз открыть 1С:Предприятие (в любом режиме). Кстати регламентные задания в журнале отражаются как фоновые. Почему так? Зачем понадобилось два термина?
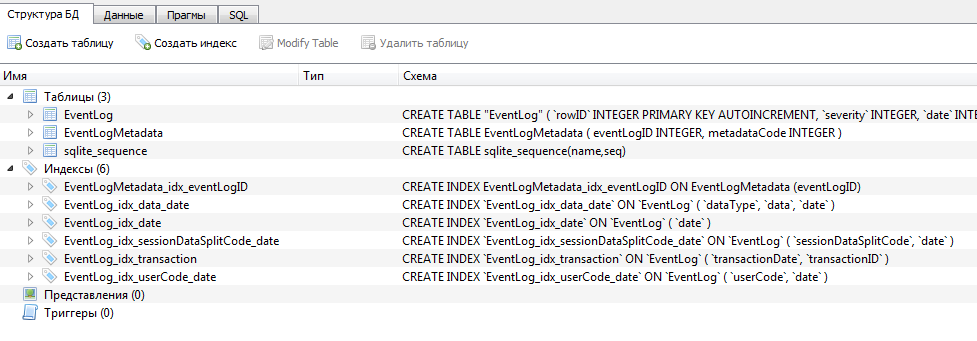
Скрипт создания таблицы EventLog
 И только при запуске 1С:Предприятие в режиме конфигуратора или обычного приложения создадутся все оставшиеся необходимые таблицы. Записи создаются по такому же алгоритму. К примеру, есть таблица MetadataCodes, в которой хранятся объекты конфигурации. Но все объекты разом не записываются, хотя это можно было бы сделать, к примеру, при обновлении конфигурации, а записываются только по требованию.
И только при запуске 1С:Предприятие в режиме конфигуратора или обычного приложения создадутся все оставшиеся необходимые таблицы. Записи создаются по такому же алгоритму. К примеру, есть таблица MetadataCodes, в которой хранятся объекты конфигурации. Но все объекты разом не записываются, хотя это можно было бы сделать, к примеру, при обновлении конфигурации, а записываются только по требованию.
Структура базы нормализована по полной программе. Размер записи основной таблицы равен примерно 140 байт, что совсем немного для такого рода сценария использования как ведение логов.
Но есть вопросы. К примеру, для чего нужно было создавать отдельные таблицы используемых портов? Сколько килобайт планировали сэкономить авторы? Видимо это все ради того, чтобы потом быстро показать/использовать в форме отбора. Другого объяснения не нашел. Но опять же для чего надо было создавать поле Name, когда его значение можно было хранить в поле Code. Если у кого есть идеи, поделитесь.
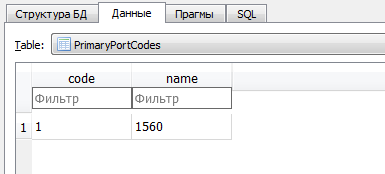
Следующий момент больше похож на ошибку разработчиков. Столкнулся с ней, когда попытался соединить эти таблицы. Дело в том, что ключ metadataCodes в основной таблице EventLog имеет тип TEXT, хотя должен был быть INTEGER. Выкрутился преобразованием «на лету»: SELECT 0+ metadataCodes FROM … Драйвер ODBC позволил такое проделать. Хотя можно просто изменить структуру таблицы, работоспособность журнала от этого никак не пострадает.
И эта песня тянется уже не один год.
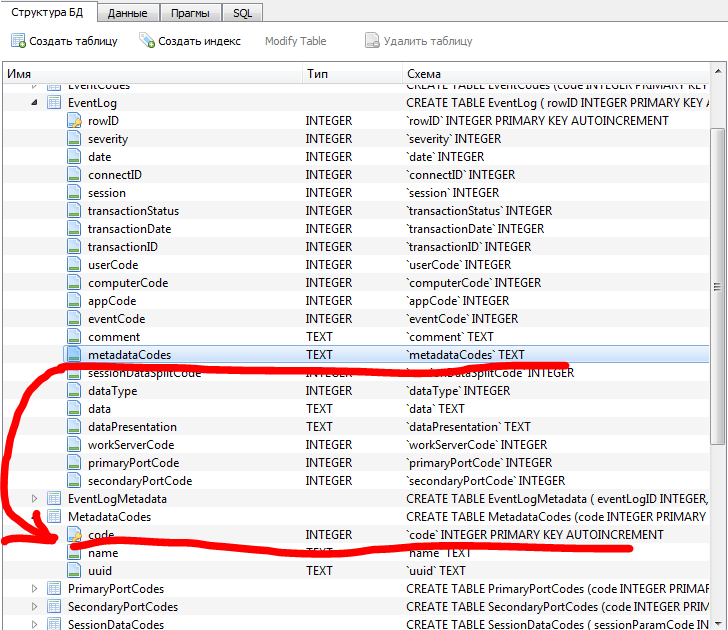
Скрипт для исправления типа поля MetadataCodes (TEXT =664; INTEGER) таблицы EventLog
 При любом несложном нарушении структуры базы она будет восстановлена. К примеру, мной были удалены некоторые индексы, и при следующем моем обращении к журналу из главного меню конфигуратора Администрирование – Журнал регистрации все индексы были благополучно восстановлены после небольшой паузы.
При любом несложном нарушении структуры базы она будет восстановлена. К примеру, мной были удалены некоторые индексы, и при следующем моем обращении к журналу из главного меню конфигуратора Администрирование – Журнал регистрации все индексы были благополучно восстановлены после небольшой паузы.
Итак, вернемся к файлу журнала, с которого все и началось. Размер его чуть превышал 1 гигабайт, что по меркам авторов sqlite это копейки. Нельзя не отметить всеобщий сарказм администраторов в отношении к 1С, многие относят ее к разряду «для киосков с оборотом 3 рубля». Это, конечно же, отдельная история. Хотя предыдущая статья лишь подтверждает этот момент, особенно аргументы в обсуждении.
Принимая во внимание все вышеперечисленные проблемы, сомнения все же оставались. Мною было решено просто проверить, как влияет рост размера журнала на производительность. Была создана обработка, которая в цикле выполняла одну лишь команду:
ЗаписьЖурналаРегистрации(«TEST», УровеньЖурналаРегистрации.Ошибка);
20 циклов/замеров по миллиону записей. Размер файла вырос с пары-тройки десятков килобайт до почти трех гигабайт. Обратите внимание, что скорость никоим образом не изменилась, более того даже не деградировала от того, что файл сильно распух. Все же авторы sqlite правы, говоря, что это копейки.
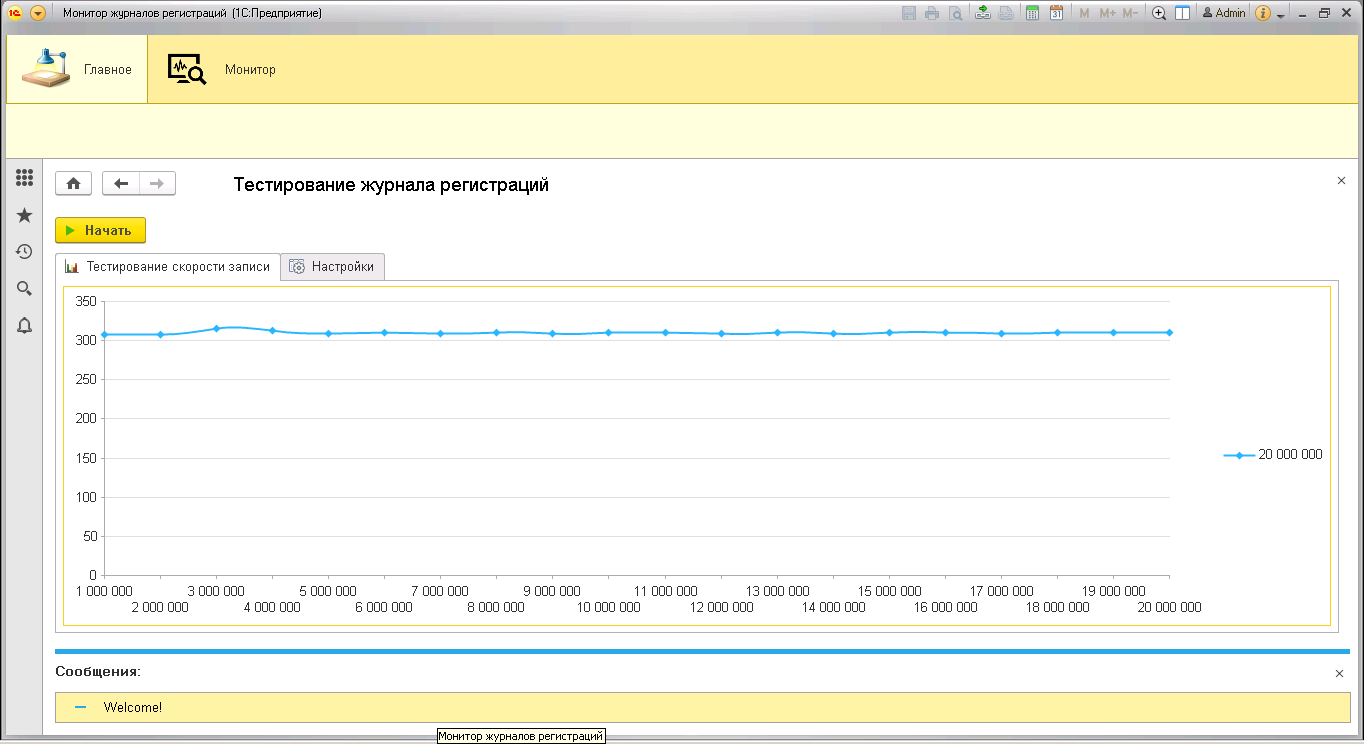
Так же для контроля скорости записи на диск использовалась программа Process Monitor (Procmon) из набора утилит Sysinternals Марка Руссиновича и Брюса Когсвела, которая лишь подтвердила полученные данные.
Вывод
Размер файла журнала регистраций никак не влияет на скорость записи. Конечно, надо учитывать еще много других факторов. Но текущая задача была лишь проверить как сама 1С:Предприятие работает с файлами sqlite большого размера.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
вроде и делаете все правильно, но не ваше это, не ваше
во-первых ЗаписьЖурналаРегистрации( не единственный кто пишет
во-вторых тестировать надо многопоточно
не просто так в последних версиях платформы разработчики вернули возможность интерактивно выбирать старый формат…
Согласен с Вячеславом. Тема не раскрыта полностью. Для более менее полноценного теста необходимо создать не менее 1000 фоновых заданий, причем не только писать в журнал параллельно, но и читать. Еще при этом желательно создать стороннюю нагрузку на дисковую подсистему где лежит журнал, чтобы эмитировать работу с контекстными данными, индексацию полнотекстового поиска, работу с TEMPDB и т.д. Кроме того на скорость выборки влияет сложность отборов. У нас, по непонятной причине, на ЖР на базе SQLITE отбор за день где в качестве отбора задавалась ссылка на любой объект базы приводил к полному зависанию фонового процесса навсегда. Проблема ушла только после перехода на старый формат. Отбор стал медленнее, не спорю, но зато результат выдает в конечном итоге.
Пока я вижу одно решение: самой фирме 1С ввести новый формат ЖР на базе NoSQL. Добавить еще один ключ к запуску агента сервера 1С, который позволит выбрать размещение одного лишь ЖР, а не всей папки srvinfo, т.к. в текущем варианте невозможно её перенести на RAM диск. Если контекстными данными мы еще можем пожертвовать в случае сбоя, то записями в ЖР нет.
сократить полностью журнал можно не только из конфигуратора, и записи она(sql lite) позволяет удалять при других соединениях с базой.
проблема ожиданий отклика рабочих процессов связана с рагентом, он монопольно держит файл(handle), рпхосты сбрасывают ему свою очередь на запись, отсюда и просадка в производительности. это к тому что «решено было изучить вопрос вдоль и поперек.»
предлагаю автору сделать тест с заранее подготовленным жр на 10-15 гб, и запустить туда запись на 400 сеансов, в 8 рпхостах, и да как уже выше говорилось читать еще в это время. это к тому что «Размер файла журнала регистраций никак не влияет на скорость записи»
Поднятие кластера не может поделить журнал регистрации на части для онлайн записи к примеру по 200 и 200 с какой-нибудь консолидацией всего где-нибудь в стороне без конкуренции с 400 сеансами?
посоветуйте, какие мне диски купить для ваших хотелок
вы что, генератор случайных фраз включаете? )))
(5) Причём тут диски?
Уже давно известно (тем кто занимается администрированием больше чем дале-далее), в чём узкие места ЖР в обоих его ипостасях. И вы своим тестированием не проверили и не выявили ничего полезного.
(2)
Можно поставить периодичность ЖР час и скидывать с RAM-диска файлы прошлых часов на другой диск.
ЖР на другом диске можно просматривать обработкой из инструментов разработчика.
Как вам такая схема?
RAM-диск в этом случае не нужен очень большой.
нет свободных дисков, отсюда и сарказм 🙂
а если по делу, то штатная гляделка логов никак не годится для файлов большого размера. поэтому пришлось рисовать свою конфигурацию для этого. не самое оптимальное решение в плане ресурсоемкости конечно же, но за то для пользователей все максимально понятно и просто
а старый формат видима вернули все же для «киосков»
жаль, что по теме мало что сказано
вы все время уходите на какие-то философские темы типа а что если добавить процессов, монопоточность и так далее
куча терминов… но все вокруг да около
но самое смешное то, что я все это уже продел. правда не такие количествах, 1000 заданий плодить не стал, мне 50 хватило
если обратили внимание на картинки во вложении, то это второй график
всем спасибо
Убежден, что идея писать первичные логи в SQLite была не от большого ума. Ни гранулярность хранения нормально не настроить, ни ротацию. Всего-то и нужно было — дать больше возможностей кастомизации, чтобы писалось только то что надо, а не «все или ничего». И половина проблем ушла бы сразу. А для агрегаций и быстрого поиска кому надо — можно что-то сверху прикрутить, как весь мир и поступает.
Слава богу, вернули штатную возможность переключаться на текстовый лог и не нужно больше извращаться.
У журнала в SQLite есть только один сомнительный плюс — индексы. Все остальное — явные минусы.
так там и индексов не хватает lol
но лично мне задумка нравится. негоже в 21 века хранить данные в текстовиках
может корпоративы повлияли, тенденция так сказать
но плюсы очевидны
другой вопрос, что готовить тож надо уметь. и вот тут есть вопросы к разработчикам сие чуда
(11) Вернее не только индексы. В общем, оптимизация на выборку данных (страничная организация данных и все такое). Фишка в том, что для первичного лога это вовсе не главное.
(9)
но вы говорите что проблем с жр нет, вас бы в передачу «где логика»
куча терминов… но все вокруг да около
это вам так кажется
вы нарушили все условия тестирования
плюс условия и задачи теста четко не сформулированы
даже не очень понимаете, какую проблему доказываете
отсюда другие ошибки, вы сразу решили что проблема в sqlite и полезли препарировать, хотя сначала надо было выяснить, а нет ли проблемы на стороне сервера 1С (как он работает с sqlite)
и главное тест не покрывающий полностью, из такого теста ни каких выводов нельзя сделать
у вас с логикой явно проблемы
«мы проделали тест и проблем не увидели»
это не означает что проблемы нет, это означает что тест мог условий воспроизведения проблемы не создать
подобные вам рассуждают в стиле:
В каждом электронном компоненте есть невосполняемый запас дыма. Если этот дым выходит, то деталь перестаёт работать.
Вот Вам домашнее задание — найдите ошибку в рассуждениях.
ты снова передергиваешь, сам того видимо не замечая
все же гляделка это не сам журнал, так что проблем тут не вижу
тем более, что ею я не пользуюсь от слова совсем
очередное задание? я почему-то не удивлен. однако замечу, что ты все же не в корпоративном чате, подчиненных здесь нет, опять таки от слова совсем
ну не понравилась статья, тест, аватар, да мало ли чего еще… так бывает. ничего страшного в этом нет
нда, еще раз убеждаюсь, можно объяснить всё, но не всем
По теме у меня возникает вопрос — какого тогда счастья когда я запускаю выборку в журнале за пару месяцев по полю данные пользователи не могут работать? И да до 200 Гб у меня журнал разрастается за пол года, приходится его копировать (требования руководства) и создавать по-новому. Конечно в журнал пишется каждый чих, но я не могу переубедить руководство что так делать не нужно. Согласен sqlite — идея хорошая, но почему бы не сделать журнал переодическим — мне непонятно. Пусть бы писался в отдельные файлы за какой-то определённый период (сам уже выбираешь за какой), так-то лучше, а просмотрщик собирающий данные из разных файлов я думаю создать небольшая проблема…
Журнал в 50 Гб, попытка установить отбор при просмотре приводит к фризу всех сеансов (полторы сотни) на неопределённое время с лечением перезапуском службы. Пишутся-то данные без проблем, но смысла в этом становится не сильно много.
Пришлось уйти на старый формат.
(16)штатная с одним файлом справится не может, с чего ВНЕЗАПНО она управится с несколькими, пусть даже меньшего размера
(17)на деле есть гляделок и прочего для управления журналом. так сказать на любой кошелек. но пользоваться штатным инструментом для просмотра я перестал и вам всем советую отказаться от него
(18) В том-то и проблема. Логи временами очень важны когда идет «Разбор полетов». в 1С этим не сильно озаботились. Ну есть журнал и есть, а в том что ним пользоваться ни разу невозможно — ваша личная проблема. Насчет кучи гляделок. А стандартную нормальной сделать — не судьба?
(17) Вот-вот… Это мой любимый момент, особенно когда нужно срочны и ты по своей глупости ткнул в отбор, а работаю 50 человек. Они не очень довольны перезапуском службы.
Лучше бы фирма 1С для старого формата сделала инструмент штатного портирования на субд, причем даже не сильно принципиально какую, а можно и в несколько, в NoSQL, в кубы
очевидно же что это инструмент отложенного анализа, значит не обязательно читать оттуда, куда первоначально пишется, можно и из реплик
пока выглядит это все как «озаботились только записью, но не последующим чтением, да и с записью сделали кое как».
(21) Да если бы просто сделали возможность тонкой настройки логируемых событий и оптимальные дефолты — уже бы на старом формате у мелко-средних компаний отпало большинство вопросов.
(20)
(17)
я вот так решил эти проблемы
журнал регистрации в новом формате дорос до 131 гигабайт. В 1с в результате просматривался лишь небольшой отрезок времени, меньше месяца, остальных записей как будто не замечая. Попытка очистить журнал привела к глобальному фризу с восстановлением только после ручного удаления жураналов и перезапуска сервера. Вернулись на старый формат с разбивкой по месяцам — их удалять хотя бы можно в процессе работы (за предыдущие периоды). Конфигурация типовая.
(24) был случай: при конвертации журнала с разбивкой по месяцам грохнулся скази диск, то есть был один файловый решили поделить на месяцы… и вот те раз
диск был на гарантии, но кому от этого легче )
но то была 8.2, хотя вряд ли там в этом плане что-то серьезно поменялось (