







Исходные данные:
Конфигурация: Розница 2.2
Платформа 1С: 8.3.7.1970
Ориентировочное число узлов в конце проекта: 200
Ресурсы оборудования в центре: без существенных ограничений
Оборудование на точке: обсуждаемый вопрос.
Срок проекта: год.
Архитектура:
Сперва определились со схемой РИБ. Было принято решение ориентироваться на схему «звезда», пока это будет возможно; при достижении технологических ограничений — снежинка.
В торговых точках используется клиент-серверный вариант работы, с выделенным сервером, под управлением ОС Windows.
Сервер 1С будет использован в варианте «Сервер 1С МИНИ» https://1c.ru/news/info.jsp?id=17577
Сервер СУБД — MS SQL Express 2008 R2.
SQL Express 2008 R2 — последняя на текущий момент времени версия данной линейки SQL Server.
Ограничния:
- 2 ГБ ОЗУ
- 1 физический процессор
- 10 ГБ максимальный объём базы
Из всего вышеперечисленного напрягает в осном ограничение на максимальный объём БД.
Но это всего лишь означает, что нужно гработно организовать процедуру её очистки от устаревших данных на местах.
Под сервер 1С и MS SQL выделяется отдельный физичский сервер. На него будет ложиться основная нагрузка по обменам и проведению длительных операций.
Конечные клиентские компьютеры не заменяются, потому как будут работать с тонким клиентом и нагрузка на них будет минимальной.
Сервер в магазине — просто мощьный ПК. Но обязательным условием является наличие диска SSD — на котором расположены базы MS SQL.
Также сервер будет обсепечивать возможность проведения регламентных операций в ночное время и доступ к базе магазина без отрыва от работы.
Основные настройки
Со времен УТ 10.3, на которой у меня состоялся первый проект внедрения РИБ на 60 узлов, конечно, «утекло много воды».
1С не стояли на месте. Розница 2.2 теперь учитывает необходимость выборочной выгрузки данных.
В базу магазина будет выгружаться только та информация, которая имеет к нему отношение:
- Все справочники (кроме специализированных)
- Документы по данному магазину
Регистрация данных происходит по правилам регистрации, всё что можно кэшируется. Существенных замедлений именно на регистрации не наблюдается.
Другой вопрос, что так или иначе добавление узла в базу означает добавление ещё одной записи в таблицу регистрации на каждый общий элемент при его записи.
В настройке самой выгрузки ничего специфичного нет. Есть некоторые нюансы при настройке сценариев синхронизации:
1) Нужно разделить на отдельные сценарии синхронизации на выгрузку и загрузку
Смысл в том, что выгрузка проходит долго и с блокировками, а загрузка достаточно беспроблемно. При этом часто бывает что данные нам нужно оперативно получать из розничных точек, отдавая при этом только несколько раз в день.
2) Выделить проблемные магазины и убрать их из общего сценария синхронизации. На них могут быть большие выгрузки — тормозиться при этом будет весь обмен, включая другие узлы. После решения проблем они доабвляются обратно
3) Создать несколько сценариев отправки и получения данных. Но тут главное поймать правильный баланс их количества.
Некоторые вещи в 1С не меняются. Тот самый метод «ВыбратьИзменения» может выполняться только последовательно (ещё с версии 8.1).
Следовательно, параллельность в выгрузке РИБ ограничена. На практике получается запускать параллельно 2-3 сценария.
Что касается сценариве получения — тут возможна куда большая параллельность, если нужна, конечно.
Что пришлось доработать
Конечно, грустно и печально, но пришлось основательно влазить в БСП. Самый главный косяк в штатной логике 1С РИБ — это обновления. После обновления появляется примерно такое окошко:

Это всё происходит в монопольном режиме. Кроме всего прочего, система ещё будет пытаться сделать обмен после обновления в монопольном режиме. К чему это все приводит — нетрудно догадаться.
Весь этот период времени магазин не может работать, на кассе стоят покупатели, компания теряет деньги.
Ещё одной проблемой обмена становятся регистры сведений. Выгрузка в XML каждой записи регистра сведений создаёт отдельный узел XML со служебными элементами и т.п.. Кроме того, функция «ВыбратьИзменений()» для регистра сведений в котором 100 записей получит результирующую таблицу в 100 строк, в то же время, есдли это справочник у которого 100 строк в табличной части выберется только одна запись. А это время монопольной блокировки. Так что если в РС много записей, которые регулярно регистрируются к обмену в другие магазины, то это, конечно, правильнее представить в виде справочника с табличной частью, который в крайнем случае при записи может формировать строки этого же регистра. В любом случае, регистры сведений в обменах — это зло.
Ещё одна важная деталь — из обмена польностью исключены дисконтные карты, а физлица — только сотрудники конкретного магазина. Зачем? Дисконтных карт скопилось уже близко к 3 млн. Для работы с ними используется внешняя online система. Если продолжать передавать дисконтные карты на все магазины — это в разы увеличит обмены, кроме того, может привести к превышению базой объёма в 10 ГБ.
Часть механизмов реализована online обращением в центральную базу: остатки в других магазинах, возврат по чеку из другого магазина, проверка валидности подарочного сертификата.
Тиражирование
Конечно, тиражирование ведётся ускоренными темпами.
Создание начального узла РИБ штатным образом сделало бы невозможным тиражирование в принципе.
Поэтому новый узел создаётся следующим образом:
1) Существует отдельная база с фейковым магазином
2) Эта база обменивается в РИБ всеми общими данными но не получает специализированных (документов)
3) Когда хотим создать новую базу — просто копируем эту
4) Потом устанавливаем настройки — магазин, префикс и т.п.
5) База для магазина готова.
На сервер разворачивается уже готовый пакет ПО, поэтому много врмени это не занимает. Потом на сервер заливается вновь созданная база, и он готов для отправки в магазин.
Преимущества тонкого клиента
Два существенных преимущества Розницы 2.2 (Тонкого клиента) которые «согрели душу»:
1) Нет необходимости менять весь компьютерный парк в торговых точках. 90% операций выполяется на сервере, а сервер туда привозится «относительно мощный компьютер»
2) Техника имеет свойство отказываться работать, особенно часто это происходит с вновь установленным или уже изношенным оборудованием.
В этом случае действия теперь предельно просты — магазин переключается на работу в центральной базе.
Этот процесс занимает не более 5-10 минут, таким образом торговля не прерывается даже при существенных проблемах с оборудованием.
Поддержка и обновления
Наконец, дошли до самого интересного пункта — как же всё это поддерживать и обновлять?
Для нас обновления тоже долгое время были дилеммой:
1) Обновлять руками магазинов (не очень правильно, могут не получить изменения, будут звонки и проблемы) — так было ранее
2) Обновлять силами технической поддержки (нет столько ресурсов)
3) Написать *.cmd или 1С скрипт для обновления или взять готовый. Как показывает практика, такое решение всегда половинчатое (нестабильное ), а функциональности в нём получится заложить немного.
Какие у нас были задачи:
1) Обновление должно проходить в нескольких режимах и управляться централизованно
2) При обновлении возможно интерактивное взаимодействие с пользователем (сообщения, подтверждение, прогресс бар).
3) Обязательно должны приходить отчеты о состоянии и ошибках обновления
4) Должно быть резервное копирование
5) Система обновления должна уметь без проблем обновлять саму себя.
6) Система должна быть расширяема без особых проблем.
Конечно, задачи вышли далеко за перечень решаемых простыми методами. Поскольку без автоматизации с таким количеством конечных точек не обойтись, а ничего более-менее готового со схожим функционалом мы не нашли, пришлось заняться разработкой ПО, которое со временем приобрело название MU (MagicUpdater).
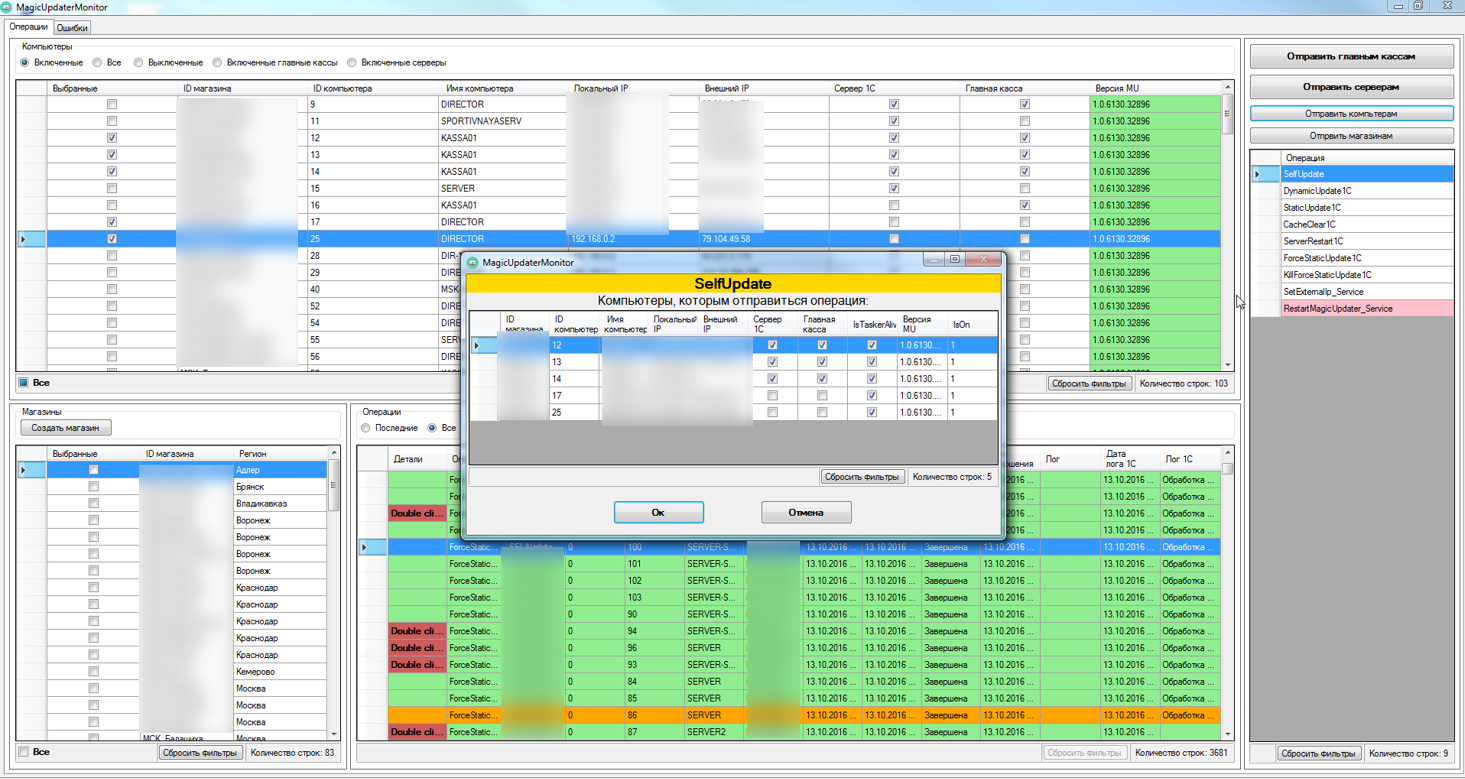
Основные функции:
1) Динамическое обновление базы (команда или по расписанию)
2) Статическое обнволение базы (команда или по расписанию)
3) автоматическое агентов на конечных компьютерах при их модификации
4) Проверка состояния агентов
5) Отчеты об обновлениях
6) резервное копирование
7) Административные действия с сервером 1C и MS SQL
8) Закрытие всех клиентских приложений 1С на компьютерах сети
9) Статическое обновление с акцептом на главной кассе
10) Отображение описания модификаций после обновления
11) Настройка порядка действий
12) Выполнение всех этих действий по расписанию
Примерная схем взаимодейтсвия:

Где MU Агент — это служба, устанавливается и настраивается в магазине. Собственно, она с центра получает команда на выполнение определенных дланных.
MU Сервер — Сервер, который принимает все запросы к системе.
MU монитор — то, что видят рядовые сотрудники технической поддержки — используется для просмотра логов и постановки заданий на обновление, либо прочих.
Получилось весьма неплохо, на мой взгляд. Теперь обновления проходят практически в автоматическом режиме.
Вот так, к примеру, выглядит сообщение об ошибке после обновления:

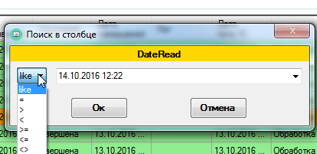
А вот таким образом мы осуществляем отправку команд на клиентские компьютеры
Приложения, конечно, не 1С-ные, но с достаточно приличным набором интерфейсных возможностей. Вот так, к примеру, выглядит отбор по дате:
Таким образом, у проекта появились неплохие шансы быть завершенным успешно. По крайней мере, на середине пути «полёт нормальный».
Если придём ещё к каким-либо решениям, которые могут показаться интересными, напишу отдельно.
P.S. и самое главное: Правильное планирование дальнейшей поддержки — один из ключевых факторов дальнейшего успеха подобных проектов. 🙂
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Подобный костылинг — следствие изначального выбора архитектуры, не подходящей под условия задачи.
(1) asved.ru, Расскажите нам какую архитектуру нужно выбрать что бы не было такого «костылинга»?
А то у меня сеть из 150+ узлов. То же вот костылингом занимаюсь.
К сожалению есть одно узкое место в механизме установки скидок, это «сегмент номенклатуры». Пришлось переделать правила регистрации ну и и тд. Что бы между магазинами не ходили сегменты.
Что бы данные выгружались именно в нужный узел, а не во все нужно брать напильник.
у меня на пустой базе(только НСИ и 2 работающих магазина) создались только первые 2 магазина штатными средствами и создавались около 1.5 часов каждый. На третьем уже всё… перестал работать штатный механизм.
На ИС нашёл публикацию по встраиванию механизмов исполнения произвольного кода в саму конфигурацию. Пишем скрипт, устанавливаем в каких узлах нужно его выполнить и делаем обмен. Этим же механизмом выполняется обновление узлов. Но я пока не пробовал обновлять на типовые обновления. Обновления были только на наши доработки.
Судя по старой базе которая была до Розницы и самой розницы базы раздувают «ЧекиККМ» и регистр «Продажи». Хотя может у меня просто не очень много карт(менее 100 тыс).
Смотря для какой цели нужно получать данные по несколько раз в день в точках… у нас для целей логистики и тд. Сделали базу в которую продажи приходят из магазинов по web сервисам. Если где то продали то максимум через 10 минут эти данные уже в базе.
Но в целом Розница очень некачественный продукт. Который просто не рассчитан на работу как фронт. И очень много ошибок. Начиная от не понятной арифметики фирмы 1С когда 7% от 1000 руб это 68 руб(хотя может это я так не правильно что то настроил, но как не крутил настроить точнее не получилось) или например при настройке вытеснения скидок. Есть сегмент на который распространяется скидка. Скидки по типу получателей(разные карты). Первые 8 товаров считает правильно, потом начинает считать что попало….
Я вот уже думаю что нужно в магазине на кассе вешать табличку: » Уважаемые покупатели просим извинить за предоставленные неудобства, но мы пользуемся программой 1С: Розница»
200 точек — это совсем немного.
Сопровождали систему, тоже розница (только 1-ой редакции) — свыше 2600 узлов (звезда).
— веб-сервис — пакеты — в каждом пакете — таблица значений с нужными объектами, записями, например, пакет из 1000 записей регистра
— проблемы регистров не было — см. выше
— возможность обмена при несовпадении версий центра и «дочек», обновление конфы дочек — отдельный пакет.
— адм-ние — команды на обновление, отслеживание где, чего и сколько обменялось — отдельная обработка в Центре, без доп. ПО.
— само собой отдельный план обмена на все это + свой механизм формирования пакетов.
(4) «- возможность обмена при несовпадении версий центра и «дочек»»
Каким образом сделали?
Какие альтернативы РИБ рассматривались до начала проекта ? Неужели их нет ?
В своё время решал проблему реализацией собственной подсистемы регистрации изменений, где не было регистрации общих элементов на каждый узел и блокировок при чтении изменений. Управление регистрацией изменений и их отправкой осуществлялось при помощи версий. Таким образом запись изменений не блокировалась чтением и даже удаление уже ненужных регистраций так же проходило без проблем. Распространение изменений управлялось подсистемой маршрутизации сообщений, которая копировала сообщения если это было необходимо, например, если это были общие элементы. Всё это, в конечном итоге, очень напоминало SQL Server Change Tracking, который появился в 2008 версии. Сейчас я использую этот механизм.
Более того, движения документов ходили в одном сообщении с документами, а одно сообщение всегда загружалось в транзакции. Таким образом мы реализовывали паттерн . Насколько я понимаю РИБ эту проблему не решает и движения могут периодически «долетать» позже самого документа или наоборот. Кстати как вы решаете эту проблему ?
Про независимые РС — убираем галку «основной отбор» у «неадресных»и «неиспользуемых в блокировках» измерений, тогда ценой снижения времени записи (незначительного, в некоторых случаях, когда записывается только наборами, вообще с ускорением записи) значительно ускоряется регистрация, выгрузка и загрузка.
Про тиражирование — когда-то давно работал в компании с 70 узлами РИБ, где новые узлы делались копированием. И один раз в разных узлах создался документ с одинаковым УИДом. очень долго искали причину «пропадания» данных. Это было во времена 8.1, сейчас может быть всё лучше.
(1) asved.ru, А в чём собственно костылинг????
(3) TODD22,
У нас сервер… фоновые задания… кроме того нужно убить клиентов 1С которые подвисают если их скинуть… кроме того прогресс бар отобразить если днём обновляется… да много чего ещё, 1С у нас не прокатило
(4) ig1082, А тут ещё мой вариант называли «Костылями». Но у вас уже похоже не РИБ был?…
(10) Фоновые задания и в файловом варианте мешают обновлению. Обновление не проходит. И база остаётся заблокированной. Я сделал все фоновые и тд задания после 14.00. А задание для обновления с утра до 14.00.
Да и из фоновых у меня там только обновление индекса ППД и тд. то есть пара сервисных заданий висит. Обмены у нас утренние запускаются пользователем. А после 14.00 уже автообмены запускаются.
Хотя можно доработать и запускать утренний обмен при входе пользователя….
У меня ещё процесс отладки/наладки/доработки этого всего идёт.
Много ещё недоработок….
(6) zhichkin,
Как раз таки на РИБ настаивали… конфигурация должна быть единой, функционал единым. Убрать зоопарк, ввести общие правила.
Воочию не столкнулись… может не та интенсивность. Контроля остатков практически нигде нет
Я ещё тут смотрел в сторону 2is. Вроде как конфигурация позволяет очень сильно расширить функционал стандартных обменов. Но пока что то не дошли руки….
подпишусь
(13)
По опыту работы с подобной архитектурой (РИБ > 200 узлов, розница), основными проблемами были следующие:
1. Блокировки при «ПрочитатьИзменения».
2. Всплески объёмов при закачке новых подарочных сертификатов и подобных вещей.
3. Разсинхронизация движений документов с самими документами (не криминально, просто надо знать, что такое может неожиданно быть).
4. Обновления конфигураций, которые периодически останавливали работу магазина из-за ошибок обновления.
5. Тяжёлый код, в том числе разрешения коллизий, который тормозит проведение документов при регистрации в обмен.
6. Если обмены вставали на сутки, то возникал риск, что прокачка обменов не догонит рост объёмов изменений.
7. Наличие в магазинах кода и подсистем, которые им совершенно не нужны, а обновления всё равно делать надо.
Как-то так. Ничего не забыл ?
Больше всего проблем было с блокировками и скачками объёмов. На втором месте ошибки обновлений или сам факт необходимости обновлений.
Как решать:
1. Обновление в отдельной системе, как у вас, это +100 — нельзя логику обменов мешать с логикой технического сопровождения — это большой архитектурный косяк на мой взгляд.
2. Версионирование изменений решает проблему блокировок (по сути организация работы с очередями). По другому никак и это, по моему скромному мнению, ещё один архитектурный факап планов обмена.
3. Нужно упрощать код в транзакциях проведения документов. Мне кажется не стоит смешивать бизнес-логику и логику обмена данными.
Это, наверное, основное.
(16) «6. Если обмены вставали на сутки, то возникал риск, что прокачка обменов не догонит рост объёмов изменений. »
А какие объёмы данных? Сколько документов в сутки?
«1. Обновление в отдельной системе, как у вас, это +100 — нельзя логику обменов мешать с логикой технического сопровождения — это большой архитектурный косяк на мой взгляд.»
Обмены и техническое сопровождение можно разнести по времени или по подсистемам например обслуживание можно сделать на той же 1С и вынести все функции например в web сервисы что бы не было зависимости от пакетов обмена….
Отдельная система это хорошо, но требует отдельных людей на разработку и поддержку. Не у всех есть такой ресурс.
«3.Нужно упрощать код в транзакциях проведения документов.»
А можете подробней написать? Как пример что можно упростить и как это скажется на скорости обменов?
Чувствую после какого то количества магазинов этот вопрос будет для меня очень актуальным….
(16) «3. Разсинхронизация движений документов с самими документами (не криминально, просто надо знать, что такое может неожиданно быть). »
То есть документ есть, а движений нет? Или движения есть, а документа нет? Что имеется ввиду под рассинхронизацией?
(11)
Да, это было не РИБ.
То есть допускался «рассинхрон» версий центра и дочек. При таком количестве точек это допустимо и даже необходимо.
Почему? У вас есть изменение, которое хотите внести в боевую базу. 100% уверенности в его работоспособности нет (все мы люди).
Поэтому обновление дочек идет волнами — 1-ая волна — 10 точек, 2-ая — 100-200 точек, затем если все ОК — вся 2600 точек.
Пакеты использовались как наиболее быстрый способ обмена + не нужно оптимизировать структуру хранения регистров и т.п.
РИБ — это самый страшный из обменов. В один прекрасный момент (например после восстановления центральной базы) можно остаться без обмена на пару дней. Основной минус РИБ — это завязка на конфигурацию. Два раза подряд без обмена обновил центр и обмен встал.
В идеале надо:
1. Отдельную систему по распространению конфигурации
2. Жесткий формат файла обмена
3. Четкое описание миграции данных
Хорошо работает jenkins(систему по распространению конфигурации) + XDTO(формат файла обмена) + MSMQ(транспорт)
(19) ig1082,
в одной из дочек какая-то фича не появилась и они потеряли всех клиентов…. такое проходили и как раз этого и пытаемся избежать.
(20) awk,
по-моему это очень очень за уши…
в РИБ по сути и используется…. «вшитый в платформу» XDTO
MSMQ лучше FTP пожалуй… хотя инфраструктура сообщений и так в РИБ поддерживается.. .
(17) TODD22,
А какие объёмы данных? Сколько документов в сутки?
Центральная база данных = 6 Тб.
База данных среднего магазина = 6 Тб / 200 = 30 Гб (приблизительно).
Обмен в центральной базе запускали каждые 10 — 15 минут. Это делалось для того, чтобы сообщения обмена были как можно меньше и соответственно транзакции выгрузки короче. Одно сообщение обмена «весило» в среднем где-то 30 Мб в xml. Естественно, что для транспортировки оно сжималось архиватором.
«3.Нужно упрощать код в транзакциях проведения документов.»
А можете подробней написать? Как пример что можно упростить и как это скажется на скорости обменов?
Я имел ввиду, что когда используется ручная регистрация изменений в плане обмена, то обычно это делают в подписке на события документа или даже в самом модуле объекта документа. Таким образом происходит смешение бизнес-логики документа и логики обмена данными. Кроме того, что это само по себе плохо как архитектурное решение, это удлиняет транзакцию проведения документа и создаёт дополнительные риски возникновения ожидания на блокировках и, как следствие, ошибок таймаута ожидания. В качестве решения подобных проблем я бы рекомендовал использовать везде, где можно, только автоматическую регистрацию изменений, а там, где это по каким-то причинам невозможно, делать максимально простую и быструю регистрацию наподобие отложенного проведения. Далее уже отдельным регламентным заданием разбираться что и куда делать по задачам обмена.
Я не люблю универсальных советов. Считайте, что это общий ответ. Любое решение принимается в каком-то конкретном контексте …
То есть документ есть, а движений нет? Или движения есть, а документа нет? Что имеется ввиду под рассинхронизацией?
Да, всё верно. Бывают оба варианта. Для того, чтобы так случилось, необходимо, чтобы документ и его движения попали в разные транзакции загрузки при импорте сообщений обмена. Как это получилось в нашем случае, если честно, то я уже не помню. Возможно, что как-то криво регистрировали изменения вручную и они попадали в разные сообщения обмена.
Подпишусь
(23)
У меня объёмы намного меньше… 🙂 Это меня радует 🙂
Имею на обслуживании розничную сеть, в одном из узлов которой 50 розничных точек в РИБ Розницы. Поклялся никогда больше так не делать. Смотрите в строну промышленных решений (не сочтите за рекламу, тот же Астор). Там в виде кассовой программы используется атоловский Frontol, который синхронизируется с центром с помощью их модуля SIS. Видел в работе, работает на порядок быстрее. С фоновым обменом и обновлением.
От типовой розницы, после того как ее адаптировать к таким объемам, мало что остается. Зачем себя так мучить? У вас сколько элементов в справочнике номенклатуры? Представьте, что в результате смены сегментов или других реквизитов (которые может и не выгружаются в розницу), у вас из основной базы в розницу уйдет весь справочник номенклатуры, а потом он разойдется по магазинам. А менеджеры запросто могут так отправить на изменение 100 тысяч элементов за день. Представьте размеры файлов XML и время загрузки этих сообщений. А ведь для розницы то могли и ничего не поменяться, и весь это объем гонялся в пустую…
(26)
Есть знакомые у которых сеть из 70 магазинов на Асторе. Что то радости большой не испытывают.
(26)
Представить можно много чего…. Наверное нужно правильно настраивать фильтры обменов.
Если менеджеры могут так сделать то это надо просто доработать… что им мешает в Асторе отправить 100 тысяч элементов за день?
Подписка
подписка
подписка
(27) TODD22, Я вам говорю о том, что Розница может конечно работать и с таких объемами, но для этого нужно ее превратить в другую конфигурацию. Есть проблемы со скоростью записи, лишними объектами и движениями, блокировками при выгрузки сообщений обмена. Если на кассах стоит специализированная кассовая программа, то в ней размер файла обмена значительно меньше и уходит только то, что нужно в кассовой программе. Например, изменение сегмента не влияет на выгрузку.
Мое мнение конечно субъективное. Просто я увидел как работает из коробки Асторовская система и знаю как из коробки работает Розница. Что бы Розница работала хотя бы так же, ее пилить и пилить.
А на что кстати жалуются ваши знакомые? Действительно интересно услышать стороннее мнение..
(22) Система (jenkins) смысл которой заключается в установки новой версии продукта притянута за уши?
Я говорил о неизменности формата обмена, а не о XDTO как таковом.Смысл в формате если 2-3 дня надо (гиперболизирую конечно), что бы его поняли все узлы?
Подписка
Подписка +
(31)
Это как так? Если у меня на сегмент завязаны скидки покупателям. Изменили сегмент и увеличили количество номенклатуры на которую распространяется скидка и она не выгружается? Покупатель не получил скидку….? Или что подразумевается под «не влияет на выгрузку»?
Так нет такой программы которая бы подходила всем и на 100% и ничего в ней допиливать не надо было… Если есть то дайте знать… Я себе обязательно поставлю. Когда я рассматривал программы для Розницы пришёл к выводу что проблем везде хватает.
Жалуются на обмены, на ошибки и ещё всякие недочёты… Кстати зашёл на сайт Астора, там эта компания в которой я интересовался у коллег в списке внедрений висит.
(35) TODD22, а что, FRONTOL не поддерживает нужный функционал?
Гилеву и Бурмистрову на заметку разработать курс «Разрабатываем highloaded РИБ на 1С»
(36) а фронтол можно самому дорабатывать?
В одной из логистических контор плюнули, в конечном счете на РИБ, потому что он перестал справляться от слова «совсем» и написали систему которая стала гонять SQL таблички выкидывая их в bcp. Сжатый бинарник мгновенно пулялся на центральный сервер, разворачивался в табличку промежуточной базы ну а затем insert, update, delete минуя «родную» платформу. Тоже самое в обратку. Конечно тут ни о каком использовании типового механизма речи не идет в принципе, да. Таблицы миллионники гонялись вообще без какого-либо особого влияния на скорость работы.
Похоже, что реализация РИБ средствами SQL Server это вполне себе актуальная тема ?
Если так, то просьба дать знать: планирую написать подробную статью об этом.
Дополнительная информация по этому вопросу в моей небольшой статье:
(0)
Эксплуатация сервиса дисконтных карт на couchdb обойдётся минимум в 10 раз дешевле, работать будет в 10 раз быстрее, а если сделать распределенную систему, то еще и в 10 раз надёжнее. Итого, 10#k8SjZc9Dxk3 в 1000 раз эффективнее.
(41)
По сравнению с чем?
По сравнению с чем?
Надёжнее по сравнению с чем? Зачем делать распределёнку? 3 млн карточек это что очень много?
Так же нужен будет специалист по couchdb, нужен тот кто это разработает и будет обслуживать….
Есть бесплатные специалисты которые разработают сервис в 10 раз дешевл, в 10 раз быстрее и в 10 раз надёжнее?
(42) TODD22,
для надёжности, чтобы работало при поломке оборудования у интернет-провайдеров.
Да, таких людей много.
(42) TODD22,
По сравнению с тем, что озвучил автор статьи в частном разговоре. Могу предположить, что это — средняя по рынку цена
(26) Циник,
Не всё так плохо… функционал сам по себе работает практически типовой
(31) Циник,
да нормално она работает. Чтобы там работало 300 пользователей в распределенке конечно надо пилить… как и любую конфу в которой работает 300-400 юзеров. Я видел фронтол… сильное чувство что пилить его намного больше. Из коробки там функционала меньше
(32) awk,
Однозначно. Мы не устанавливаем новую версию продукта. Мы «меняем репликацию». Главный смысл тут скорее в резервном копировании, взаимодействии с пользователем и т.п.
А не в том чтобы выполнить развертывание под различные варианты дейвайсов с различными версиями Linux-а c различным набором установленных пакетов…
(39) o.nikolaev,
ну и наверное зря. Есть же парни из 2is которые с РИБ «творят чудеса» на крайний случай. Ну и если уже не справится то нужно конечно не в SQL а в NoSQL это пулять… насколько я понял по итогам конференции
(41) unpete, Согласен полностью… вот ДК просится на Couchdb… спасибо большое за наводку наверное так и будем делать
(49)
А ДК это что?
(44) «По сравнению с тем, что озвучил автор статьи в частном разговоре.»
А тогда понятно… а то как то не понятно было по сравнению с чем дешевле и лучше…. Хотя понятней не стало по сравнению с чем 🙂
«Да, таких людей много.»
Можете привести пример? или ссылку где искать людей которые смогут бесплатно разработать базу?
(50) TODD22, ДК = Дисконтные Карты
(52)
А почему именно на couchdb?
У меня в сети бонусные карты.
Дисконтные карты у вас так же как и в Рознице реализованы? В результате нужно получить сумму покупок и набор товаров которые приобретал покупатель за период?
Или у вас что то больше вкладывается в понятие дисконтных карт?
(53) TODD22, Ну да, там куда сложнее… да и карточек уже 3 млн, а в день на тысяч 5 становится больше… плюс меняются, вообщем в РИБ это нельзя впихивать
(54) В РИБ понятно. Почему именно couchdb? Я просто с документоориентированными не работал. Но из описания они заточены под хранение документов.
А ДК это же не документы.
В чём профит couchdb перед тем же postgresql например?
(55) TODD22, Ну как минимум тем что оно раз так в 10-15 быстрее… И репликация — это его основа…
А нам как раз и нужно туда json запихнуть в одном месте, потом везде считать.
(56) Всё равно не понимаю… вроде и про couchdb почитал.
Данные же в «табличном» виде должны хранится что бы получить например сумму всех покупок по карте или список всех товаров по карте?
Или я ошибаюсь?
Мне кажется что документоориентированная БД не сможет полноценно заменить реляционную в том что касается работы с табличными данными.
Вообще интересная это couchdb.
(8) Fragster,
не лучше, недавно создали 4 подчиненные базы, в каждой из них создали группы доступа копированием базовой, так вот в 2 базах при последующем обмене с ЦБ они в итоге совпали с одним работающим магазином
(47) Всегда считал конфигурацию продуктом своей деятельности. А обновление ее поставкой новой версии продукта. Видать я заблуждался… 🙂
(57) TODD22, Если нужна агрегация то наверное да… но нам нужно хранить плоскую таблицу — карточек. В которую добавим сумму накопленных бонусов скорее всего
(59) awk, Нет, всё правильно. Обновление ЦБ — это релиз продукта. Его в принципе можно реализовать с использованием jenkins, когда немного процессы работы перестроим наверное к этому придём. Ну а обновление узлов… это лишь технический процесс репликации, которая в 1С реализована несколько «специфичным» образом
(60)
А в чём проблема с картами у вас? 3 млн это не такое уж и большое количество как мне кажется.
И если в нём проблема то можно сделать несколько баз с разными диапазонами карт.
И какую задачу вы хотите решить репликацией?
(62) TODD22, Проблема в том что ежедневно добавляется ещё тысяч 10… и модифицируется ещё столько же.
Ограничение SQL Express 10 ГБ база, ограничение обмена — 15 минут.
Приходит такой клиент, даёт кассиру карточку, а кассир — «ой, погодите, это в другой базе — сейчас вторую базу открою» :)))))))))
(63)
Ограничение SQL Express 10 ГБ база, ограничение обмена — 15 минут.
Да это как бы не проблема… есть же например Postgres.
У вас пользователь что руками бонусы в базе ищет?
Сделали по диапазонам. И обращаетесь к разным разным базам по диапазонам через web сервисы. У меня по крайней мере так. Горизонтальное масштабирование или как его там правильно.
(64) TODD22,
Спасибо :)))). В принципе скоро говорят 1С будет нормально с Postgres работать… но пока только говорят.
Мисье знает толк в извращениях :))))
Держать в магазине Web сервер, несколько баз и разделять на диапазоны это конечно жесть.
(65)
Спасибо :)))). В принципе скоро говорят 1С будет нормально с Postgres работать… но пока только говорят.
… Что-то про Постгрес, который вот-вот нормально заработает с 1с, я слышал в 2008 году.
Надеюсь, полпути в этом направлении пройдено…
(65)
Держать в магазине Web сервер, несколько баз и разделять на диапазоны это конечно жесть.
А зачем мне бонусный сервер в магазине? Он у меня в офисе.
К нему через web сервис обращаются магазины для получения бонусных баллов.
Какое тут извращение? Всё просто и очевидно. Разделение на диапазоны вполне логичное и простое решение по увеличению производительности.
Зачем в каждом магазине ставить ДС? Работал с таким решением… и сидеть потом мучится с обменами между дисконтными серверами?
Сервер один на все магазины.
А зачем вам 1С в таком случае? Это может быть база сделана без прокладки в виде 1С. А без 1С задача ДС на Pg вполне решаема. И не надо ждать пока там 1С чего то сделает.
Можете сделать на том же ms sql express разделить базы на диапазоны если упёрлись в ограничения бесплатной версии сделали ещё одну базу с другим диапазоном.
(67) TODD22,
Вопросов больше не имею. Вопрос был как раз про offline решение.
Ну и конечно используя специализированную СУБД его не нужно разбивать на разные базы
(68)Смысл делать оффлайн решение? При наличии интернета и web сервисов? Плюс проблемы синхронизации между разными магазинами.
Вот мы например пивом торгуем у нас магазины зачастую в соседних домах. За 15 минут покупатель успеет посетить 3 магазина и во всех списать бонусы. Или если обмен встанет между магазинами.
(64) TODD22,
Да это как бы не проблема… есть же например Postgres. [/IS-QUOTE]
(0) задам неозвученный вопрос. Момент выбора СУБД аккуратно пропущен. Почему не Postgres? Удобство администрирования MS SQL? Может быть есть какие-то на него интеграции? Хватает ли 1 ГБ оперативки sql-серверу?
Вот написано, что гигабайт всего один, а не два.
(70) bforce, у 2008 R2 2ГБ и он по факту 2 юзает.
Postgress:
— Нужно обучение персонала администрированию
— Неизвестно где и что свалится
— Работает существенно медленнее MS SQL (тут может и не postgress виноват но тем не менее)
— Стабильнее 1С работает с MS SQL. а 200 серверов тут нужна стабильность
(56)
в PgSQL не пробоввали
(0) расскажите, как вы создаёте тестовый контур, базы для разрабов? сколько тестовых баз в него входит на каждом уровне распределёнки? руками разворачиваете или скриптами? как поддерживаете свежесть данных в тестовых базах?
(72) starik-2005, Не, зачем… есть специализированные средства
(73) baton_pk,
Базы для разрабов копируются со специального «тестового магазина».
Распределенка одного уровня, я же писал. Пока сможем поддерживать звезду будет звезда.
Девелоперских баз — 6
Тестовых — 2
Руками. Девелоперские базы обновляются не чаще раза в 3-4 месяца.
А тестовые — как правило конкретный магазин, его скриптом не заберёшь
На усмотрение консультантов
(75) А сколько всего человек над проектом работает?
Разработчиков 1С, консультантов, тех поддержка?
(63)
1. Сетевой трафик.
Каждый день +10 000 карт скидок. Одна карта это, предполагаю, где-то 100 байт чистых данных. Пусть даже 200. Если учесть накладные расходы в виде XML, например, то это, возможно в 5 раз больше — пусть 1 Кб. Итого имеем около 10 Мб трафика для новых карт на 1 магазин. Ещё столько же по обновлённым картам. 20 Мб трафика на 1 магазин. С учётом сжатия наверное где-то 2 Мб. Это только трафик и это немного — почти ничего.
2. Обработка данных.
20 Мб XML загрузить в базу магазина … ну минуты должно хватать на мой взгляд. По идее в 15 минут должны укладываться даже с выгрузкой/загрузкой и передачей по сети. Какой целевой показатель устанавливаете Вы ?
3. Рост базы данных.
(200 байт х 10 000 карт) чистых данных в день = 2 Мб в день = 60 Мб в месяц = 720 Мб в год … ну как-то вроде бы нормально … 10 Гб должно хватать.
Чего я не так считаю ? Поделитесь, пожалуйста, фактическими показателями =)
Долго рассказывать не буду. Но имеем розницу 2.2 РИБ на 350 узлов. Приходится греть голову жестко.
(78)
Так может расскажите какие трудности, что дорабатывали… какие подходы применяли?
Здесь люди вроде опытом заходят поделится, а не померится у кого РИБ длиннее….
Вовсе нет никакого желания меряться.
На момент начала нашего внедрения очень беспокоил вопрос количества узлов, которые выдержит РИБ. И вообще интересовал опыт успешного фунциклирования РИБ больше 100 узлов.
В интернете удалось найти только инфу о 120 узлах.
Столкнулись с большим количеством проблем, большинство которых уже описано в комментариях.
Основные:
1) обновление узлов,
2) проблема нестабильной работы с фискальниками,
3) блокировки,
4) обмен данными,
5) создание начальных узлов,
6) работать надо с ЕГАИС следовательно карежить конфигурации надо аккуратно, чтобы была возможность накатить обновления выпускаемые 1с
7) и т.д.
(77) zhichkin,
1) Ну одна карта это не 100 байт конечно :). Но трафик это меньшая из проблем.Обмен должен быть не более 15 минут. Карты будут очень долго выгружаться
даже если 1 минута, что конечно не так… то 1 * 200 = 200 минут… только на загрузку, а всего 4 процессса:
— выгрузка сообщения
— загрузка сообщения
— выгрузка ответа
— загрузка ответа…
Параллельность возможна… но «ВыбратьИзменения» нам параллельность ограничичвает. Вообщем много ещё Вы не понимаете…
Ну вы прочитайте про организацию SQL, внутреннюю структуру хранения 1С, юникод.. и т.п. и считайте уже нормально. Кроме того 3 млн уже есть 🙂
(78) oev, Обмен через какое время? Клиент-сервер? Звезда?
(82)
Прошу прощения, что был неправильно понял. К сожалению, под рукой нет 1С:Розницы. Суть моего комментария заключалась в том, чтобы кратко описать методику подсчёта объёмов данных и получить от Вас более точные цифры, если это не секрет конечно же =)
Кстати, выгрузку можно делать 1 раз. Загружать конечно же придётся 200 раз, но в каждом отдельно взятом магазине, то есть в сумме загрузка будет равна, например, 200 минут, но выполняясь параллельно в каждом магазине можно считать что это 1 минута. Условно конечно же, но моя мысль я думаю понятна.
Я в курсе, что РИБ регистрирует изменения на 200 узлов и, следовательно, одной выгрузкой не ограничишься =) Однако я ничего не говорил о том, что в своих расчётах я опирался только на средства типового РИБ =) Можно сделать, например, отдельный от РИБ план обмена только для ДК и выгружать их только 1 раз, затем копировать файл 200 раз или забирать его из магазинов, что будет ещё эффективнее. И это только одно из решений, которое приходит на вскидку.
Интересно было бы всё-таки услышать от Вас конкретные цифры из Вашей практики. Заранее спасибо =)
(89) zhichkin,
можно. Но тогда без гарантированной доставки, тогда это уже не РИБ .
если уже извращаться и отказываться от гаранитированной доставки, то планы обмена смысл теряют… тогда CouchDB.
Я не сохранил историю когда было всё плохо. Помню что файлы по 50 МБ у нас были (это сжатый XML). Обновления были АД-ом
Но в деталях расчет не вёл. Сейчас осталась проблема обмена ДК, её решаем через стороннюю систему.
(40) zhichkin, Не, имел «сексуальный опыт» с Change Tracking и репликацией MS SQL. Лучше уж РИБ
(108)
Интересно, что не получилось с Change Tracking и чем РИБ лучше ?
Что Вы думаете о решении СофтПоинт repltech.ru ? Не рассматривали такое ?
(113)
DDL же Change Tracking не переносит. Ну это на первый взгляд. На самом деле думаю проблем куда больше
— Думаю что оно стоит от 1 млн (это на 1 узел), ХЗ как потом его обслуживать — сторонняя закрытая приклада + в магазинах есть вероятность перехода на Postgre + обновление ИБ оно не решает. Короче лучше уж в коучдб всё выгружать.
(114)
Решает. Есть менеджер обновлений. Чем-то похож на Ваш MagicUpdater.
Есть возможность «докручивать» логику фильтрации на 1С из прикладного решения.
Мы заказывали бесплатную демонстрацию. За 2 часа нам ответили на все вопросы и показали всё «вживую» на удалённом сервере. Наш DBA был в восторге.
Приобретать пока что не стали. Почему — не знаю. Не мой вопрос =)
(115)
вот это больше всего и напугало когда прочитал что это и как это. Была надежда что как то научились обновлять без завершения сессий и человеческого участия, а тут нет…
Даже до первой версии updater-а ему очень далеко…
Это вообще полностью бессмысленное занятие. Правила регистрации замечательная, быстрая, удобная работающая штука… к ней претензий нет.
это правильно, у нас репликация SQL и отслеживание изменений работает на другом прикладном решении (не 1С). Мягко говоря недалеко она ушла от РИБ и в чистом виде. Колонку в таблицу боимся добавить :).
Имеет смысл это решение смотреть если хочется чтобы репликация была по скорости как двухфазная фиксация… и узлов много а денег ещё больше…
(23)
А можете подробней написать? Как пример что можно упростить и как это скажется на скорости обменов?
Я имел ввиду, что когда используется ручная регистрация изменений в плане обмена, то обычно это делают в подписке на события документа или даже в самом модуле объекта документа. Таким образом происходит смешение бизнес-логики документа и логики обмена данными. Кроме того, что это само по себе плохо как архитектурное решение, это удлиняет транзакцию проведения документа и создаёт дополнительные риски возникновения ожидания на блокировках и, как следствие, ошибок таймаута ожидания. В качестве решения подобных проблем я бы рекомендовал использовать везде, где можно, только автоматическую регистрацию изменений, а там, где это по каким-то причинам невозможно, делать максимально простую и быструю регистрацию наподобие отложенного проведения. Далее уже отдельным регламентным заданием разбираться что и куда делать по задачам обмена.
Я не люблю универсальных советов. Считайте, что это общий ответ. Любое решение принимается в каком-то конкретном контексте …
«Ручная» регистрация (ПланыОбменов.ЗарегистрироватьИзменения…) это зло, но лечение простое, добавить нужные узлы в <Объект>.ОбменДанными.Получатели, тогда непосредственно сама регистрация будет сделана платформой, как если бы объект регистрировался автоматически.
(126) Сергей, ты что, прочитал все комменты? :)))
(127) а ты что, не читаешь
обновлениячто люди пишут? 🙂(127) Олег, конечно, коменты эт самое сладкое ;)) Не осилил монументальные сообщения вида «подпи* «, но по диагонали читается быстро, опять таки вспомнил про couchdb.
(128) (129) Не думал я что этот срач кто-то читает, даже стыдно стало :))))
(130) кстати, у вас пакеты с данными наверняка в сжатом виде ходят, какую степень сжатия используете?
(131) 9-ка… она везде по-умолчанию у 1С в БСП, даже без возможности настройки…
(132) мы у себя сильно уменьшили нагрузку на сервера приложений заменив на 3. Сжимает на копейки меньше, а разница в потреблении процессора существенная.
(133) Логично. Но по процессору сейчас сервер пока простаивает, да и по загрузке оборудования вцелом. По сравнению со злополучными блокировками во время «ВыбратьИзменения» всё остальное мелочи.
(26)
астор — ацкая штука — в итоге отказались. У них логика обменов — просто ад. При обмене еще и документы допроводятся, что тормозит процесс обмена между центром и магазином — просто катастрофически