






В данной статье попытаюсь показать способы доработок типовой конфигурации 1C для нескольких различных задач и на картинках продемонстрировать подход к разработке с использованием git. Основное применение и ценность данной статьи, в моем понимании, донести до программистов пользу от совместного использования git и 1С. Git в некоторых случаях значительно лучше разрешает конфликты, и совместное использование данных инструментов позволяет качественней и быстрей проводить обновления.
Стоит предупредить и о том, что любая автоматизация каких-либо процессов влечет за собой риск пропустить что-либо важное и для уменьшения такого риска будем писать тесты и автоматически их запускать, такая вот рекурсия.
В статье описывается логика создания тестов для различных случаев, так что кому не нужен git, может смело пропускать мимо ушей слова git, кто готов руками проверять результат обновления, тот может пропускать описание логики создания тестов.
Используемый инструментарий
Ожидаю, что знакомы с git, знакомы с понятием “прописать путь в переменную PATH” и уже пробовали выгружать/загружать конфигурацию на исходники.
Скриншоты будут представлены для инструмента Git Extensions, для “черепахи” и SourceTree. Возможно другая локализация, но думаю суть будет понятна.
Дополнительно:
- у меня есть выгруженные релизы ERP в git, которые я скачиваю с официального сайта users.v8.1c.ru через свой офицальный акаунт 1С.
- данную историю получил простой выгрузкой каждой версии 1с в файлы и коммитом в git от имени 1C 1c@1c.ru.
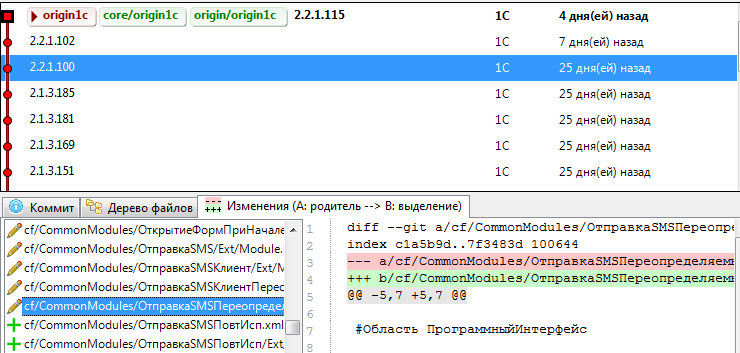
- все изменения будем проводить на версии 2.1.3.185 с последующим обновлением на 2.2.1.100
Для целей доработки создаем свой репозиторий и на базе коммита 2.1.3.185 создаем 2 новые ветки master и develop. Ветка master будет у нас для фиксации текущего релиза обновленного в рабочей базе или же для фиксации готового релиза и признака, что подготовили поставку для обновления. В ветку develop будем делать основные доработки с последующим выпуском релиза в master ветке. Для ветки develop можно настроить синхронизацию с хранилищем и все изменения в коде фиксировать стандартным способом в хранилище конфигурации.
Мы же будем использовать вариант без хранилища, пользуясь только стандартными средствами «Выгрузка конфигурации в файлы» и «Загрузка конфигурации в файлы».
Доработка документов из подсистемы Взаимодействия.
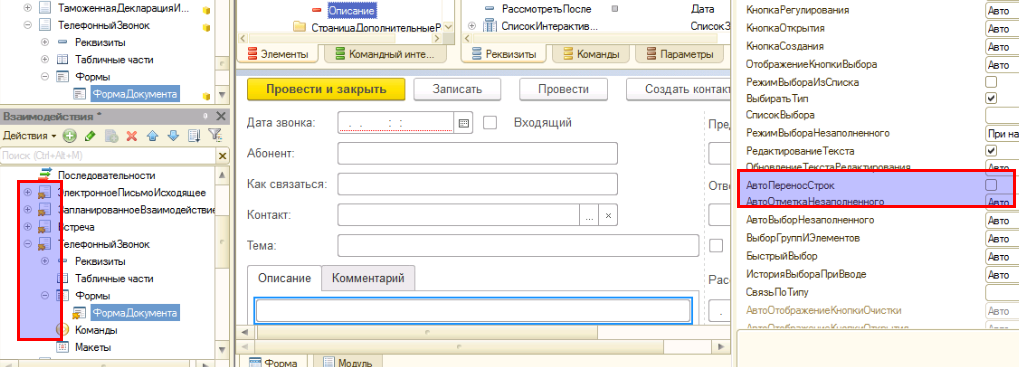
Имеем подсистему «Взаимодействия» и для ее документов вида «ЗаполанированноеВзаимодействие», «Встреча», «ТелефонныйЗвонок» в формах данных документов необходимо добавить авто-перенос строк, т.к. при заполнении описания встречи текст уезжает вправо и теряется контекст заполнения.
Вариантов решения задачи несколько:
-
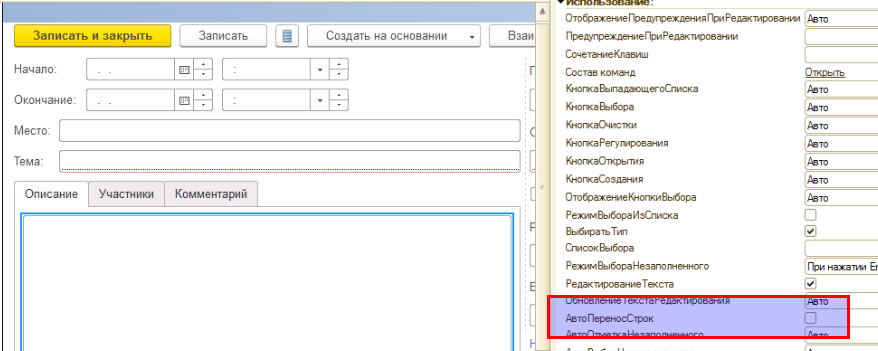
непосредственное изменение формы документа для реквизита «Описание» установить флаг «АвтоПеренос»
-
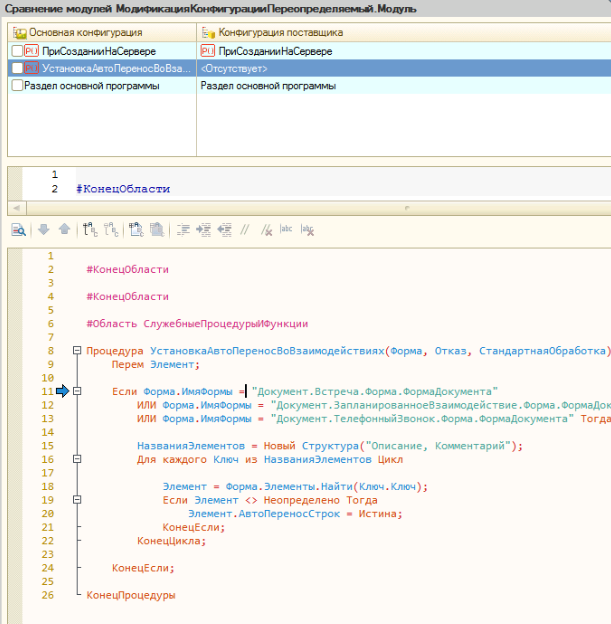
Программная модификация формы. Для этого необходимо в процедуру формы «ПриСозданииНаСервере» добавить вызов процедуры из модуля «СобытияФорм», которая неявно вызывает общий модуль «МодификацияКонфигурацииПереопределяемый» и там уже добавить процедуру «УстановкаАвтоПереносВоВзаимодействиях»
- Использование расширений конфигурации. Добавляем расширение называем его по главной подсистеме, для тех объектов, которые хотим изменить и префикс делаем crm_.
Простейшая доработка у нас сейчас превратилась в 3 различных варианта решения, но протестировать нам так и так придется одно поведение. Поэтому создадим простейший feature файл с проверкой необходимого значения реквизита для формы.
Мы не делали ограничение видимости или доступности элемента для определенных ролей, поэтому можем спокойно предположить, что данный тест будет проводиться под полными правами пользователя «Орлов (Администратор)» на типовой демо базе. Сам тест будет прост, открыть необходимую форму, найти реквизит формы и проверить, что свойство установлено в правильное значение.

По результатам feature файлов у нас должно получиться 4 процедуры теста и по результату работы каждой процедуры теста мы запишем необходимую нам информацию в контекст: сначала ссылку на открытую форму, потом найденный элемент формы, и в последнем шаге мы уже сможем сделать проверку. Для генерации формы шагов смотрите вебинар Паутова Леонида.

В первом шаге мы просто открываем форму по определенному пути и указание правильного полного имени формы будет на совести написавшего feature файл. Полученную форму мы помещаем в структуру контекста и в следующем шаге, в найденной форме, находим необходимый элемент и также помещаем в контекст, чтобы следующий шаг смог его использовать.
Проверив правильность тестов, мы можем приступать к следующим доработкам.

Ссылки на файлы патчей будут чуть ниже, а на данном скриншоте можно посмотреть, как будет выглядеть данный патч для конфигурации:

Доработка форм
Будем оптимизировать получение информации о партнере при каждой активизации строки в форме списка справочника “Партнеры”. У формы “Справочник.Партнеры.Форма.ФормаСписка” и “ФормаСпискаБезПолнотекстовогоПоиска” при активизации строки в списке используется стандартный алгоритм подключения обработчика ожидания и дальнейшей обработки информации текущей строки и заполнения панели информации по текущей строке. Самый большой вопрос к процедуре

ЗаполнитьПанельИнформацииПоДаннымПартнера(ТекущиеДанные.Партнер);, т.к данная процедура вызывается на сервере, с передачей всего контекста формы, при этом заглянув в нее видим, что там необходим только один серверный вызов, для получения данных с сервера и параметром принимает только ссылку на партнера, т.е. данный код можно легко вынести в безконтекстную функцию и все манипуляции с элементами формы производить на клиенте.

Идея простая, реализация вроде как тоже, давайте напишем тест для проверки поведения. В данном случае у нас оптимизация существующего кода, без видимого изменения поведения и желательно сначала написать тест, а потом оптимизировать данный функционал. Дополнительным условием оптимизации будет мое желание отправить патч на деревню дедушке по адресу 1c@1c.ru с предложением принять данный патч, поэтому тесты будем писать для всех случаев использования данной процедуры, глобальный поиск поможет нам с вами определить где используется данная процедура.

По результатам нам необходимо проверить всего 6 сценариев, что работает все нормально после рефакторинга.
Способов тестирования у нас множество, но обычно для таких случаев применяются 2 варианта:
- Мы получаем необходимую форму, позиционируем текущую строку на необходимом элементе, вызываем процедуру подписанную на “ПриАктивизацииСтроки” и проверяем, что не произошло ошибок и реквизиты формы заполнились корректно.
- Тестируем полное поведение, т.е. запускаем в режиме тестирования, запускаем тестового клиента и последовательно проходим по шагам открытие формы списка, позиционирование на необходимой строке, пауза на несколько секунд и проверка, что значения элементов формы заполнены правильно.
Анализ исходного кода показал, что “ОбработатьАктивизациюСтрокиСписка” не является экспортной и на первый взгляд, остается только один способ протестировать правильность работы при процедуры “ПриАктивизацииСтроки”, но т.к. у нас простейший тест, то мы можем воспользоваться и без открытия тестового клиента, только воспользовавшись программным открытием необходимых форм. Подробно опишу создание теста только для одного случая, остальные тесты можно будет увидеть в файле патча для данного изменения (для удобства патчей будет 2, один для тестов, другой для непосредственной модификации файлов конфигурации, для дальнейшей отправки).
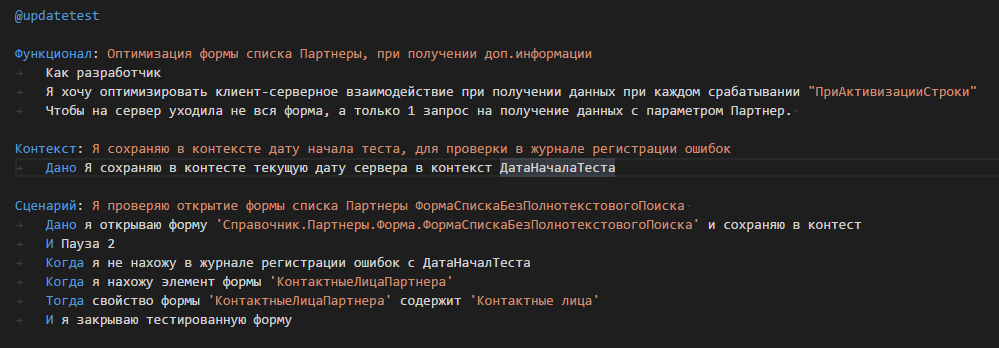

Алгоритм работы простой, сначала перед каждым тестом в контекст устанавливаем текущую дату сервера, процедура. Далее открываем форму с определенным в feature файле именем и сохраняем в структуре Контекст, в дальнейшем мы проверяем наличие на форме элемента “КонтактныеЛицаПартнера”, данный элемент выбран специально, т.к. он присутствует как в форме справочника Контрагенты “ФормаВыбораИспользуютсяТолькоПартнеры”, так и в формах справочника Партнеры.

Реализация методов, тривиальна: Пауза используем из библиотек, процедура СвойствоФормыСодержит, содержит проверку вхождения специальным методом “Ванесса.ПроверитьВхождение(“.
Для тестирования формы из справочника Контрагенты, нам необходимо будет дополнительно переключить константу “ИспользоватьПартнеровИКонтрагентов” на Ложь и по окончанию теста вернуть обратно в Истину, таким образом мы покроем тестами изменения кода на 100%.

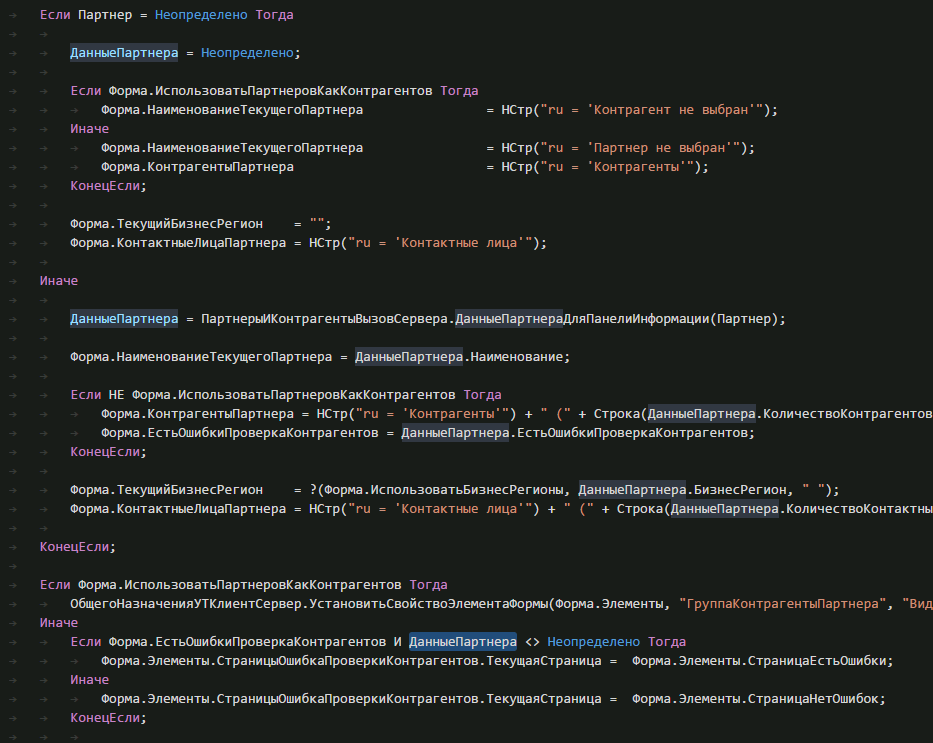
Приступим непосредственно к оптимизации клиент-серверных вызовов. Для этого переместим процедуру ЗаполнитьПанельИнформацииПоДаннымПартнера из модуля ПартнерыИКонтрагенты в модуль ПартнерыИКонтрагентыКлиент и в данной процедуре перенесем вызов ДанныеПартнераДляПанелиИнформации(Партнер) — это как раз и есть только 1 необходимый вызов сервера, в модуль ПартнерыИКонтрагентыВызовСервера. И в формах списка достаточно будет уже делать вызов не через сервер, а сразу в модуле формы.

Дополнительно нам необходимо будет подправить в функции “ДанныеПартнеровДляПанелиИнформации” запись в один из ключей структуры не ТаблицыЗначений, а массива из структур. После исправления кода, выгрузки файлов конфигурации и добавления в git измененных файлов получаем примерно такой patch типовой конфигурации.

Как видим, изменения коснулись в основном 2х строк, саму процедуру, которая находится в формах на сервере ЗаполнитьПанельИнформацииПоДаннымПартнера мы не трогали, но если хотим отправить в 1С данный патч, желательно добится чистоты кода и удалить. Для внутреннего использования можно оставить, на обновление конфигурации это вряд-ли повлияет.
Доработка ролей.
В случае использования типового профиля «Менеджер по продажам» или же «Менеджер по закупкам», доступна роль “ДобавлениеИзменениеДоговоровКонтрагентов” при этом, для команды “ДоговорСКлиентомСоздатьНовый” справочника “ДоговорыКонтрагентов”, возможно, забыли добавить для этой роли право просмотра, в результате только под полными правами возможен вызов данной команды. Давайте исправим эту недоработку и напишем тест для возможности проверки данного функционала. Доработка тривиальна, поставить всего один флаг для роли, но вот легкость сопровождения/обновления вызывает вопросы.
Патч будет выглядеть просто, а вот с тестом чуть посложнее. Нам необходимо проверить доступность кнопки команды ввод на основании для пользователя не с полными правами, поэтому будем использовать менеджер тестирования и запускать тонкий клиент под другим пользователем и ограниченными правами. При этом сам тест мы можем записать от полных прав, получить готовый feature файл и потом поменять только несколько строк для возможности запуска под определенным пользователем.
Попробую вкратце описать необходимые шаги:
- Запускаем TestClient под именем пользователя Закупки (КоролевСВ)
- Открываем подсистему “Закупки” выбираем “Поставщики” и на первом же попавшемся нажимаем кнопку “Создать на основании” и выбираем “Договор”.
- Закрываем без сохранения.
Этих шагов достаточно, чтоб проверить правильность исправления роли и происходит упрощение ввода информации пользователем, т.к. ему нет необходимости открывать “Договоры поставщиков”, создавать новый договор и выбирать вручную поставщика.
Но не забываем, что у нас 2 таких исправленных команды, поэтому протестируем второй сценарий, это ввод на основании “Соглашение с поставщиком”.
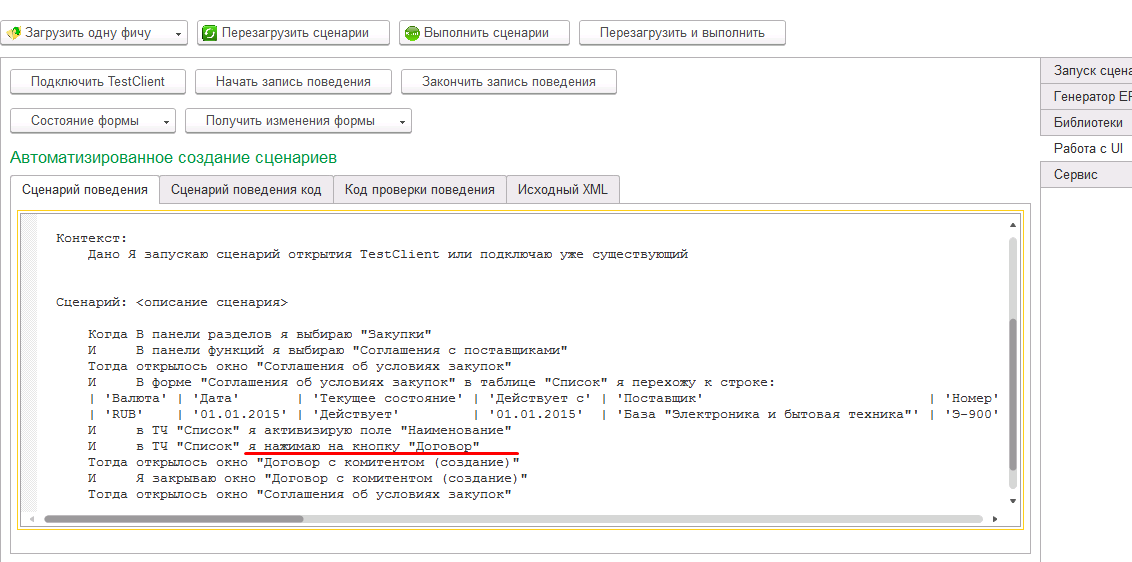

Ни строчки кода не понадобилось писать, только записали поведение, дополнили ролями и бизнес-функцией этого теста и получили:
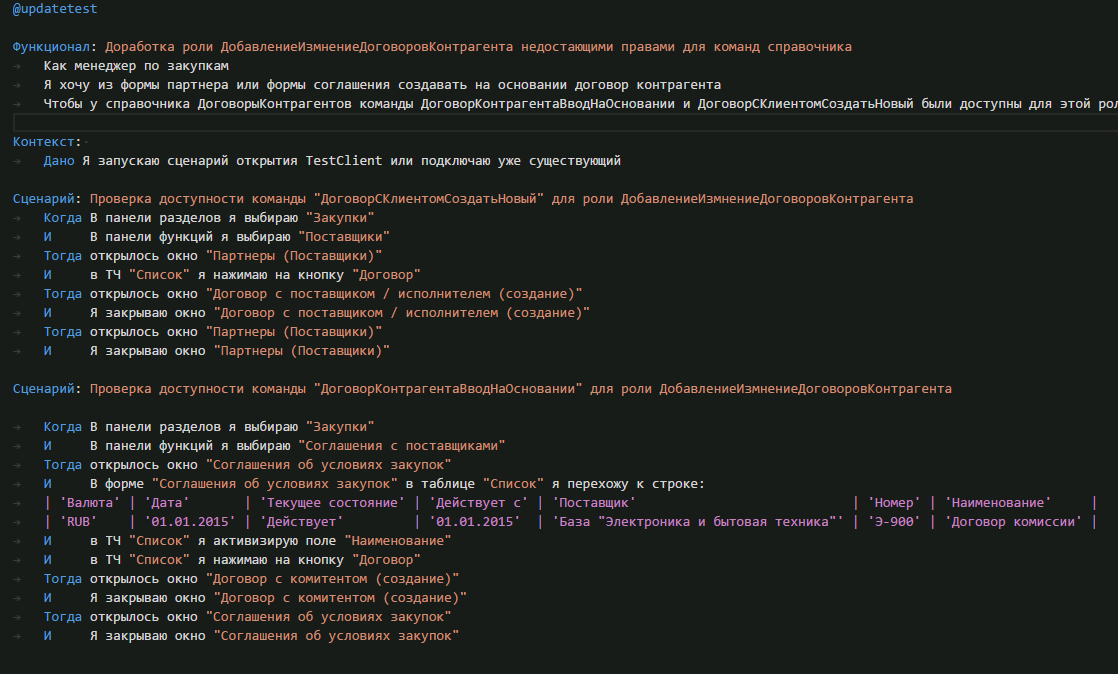
Запускаем от имени администратора, проверяем работоспособность данного feature файла и потом меняем только одну строку в разделе Контекст и используем существующий библиотечный шаг, по запуску тестового клиента, под другим пользователем “Закупки (КоролевСВ)” и теперь стало

Проверяем работу feature файла и видим, что с измененной ролью пользователю теперь доступно создание договора контрагента из необходимых нам разделов.

Обычно при доработке типовых ролей, добавляю в еще один шаблон с понятным наименованием и в комментариях пишу те изменения которые я сделал в данной роли. В данном примере я в git помещу только изменение роли, без изменения шаблона.

Результирующий патч получился совсем маленький, но при этому у нас в git хранится история изменения данной роли и есть тестовый сценарий, который мы можем запустить после обновления и получить сразу итоговый отчет с ответом на вопрос “все ли мы обновили, ничего не упустили?”.
Обновление
Итак доработки сделаны, изменения зафиксированы, теперь можно и запускать процесс обновления конфигурации на новый релиз. Обновление делать будем совместно с git -ом.
Упрощенный алгоритм обновления можно расписать на такие шаги:
- объединили с веткой 1С
- разрешили конфликты
- собрали итоговый cf файл
- посмотрели лог изменений по файлам и создали merge.xml в котором указали те метаданные, которые у нас изменились.
- запускаем конфигуратор и там стандартное обновление конфигурации, ждем долго, долго и потом соглашаемся на изменения с приоритетом основной конфигурации, сохраняем конфигурацию но не обновляем конфигурацию базы данных.
- запускаем сравнение конфигурации с файлом cf и подсовываем ему merge.xml который мы сделали автоматом, на основании лога git.
Делаем в git объединение с релизной веткой от 1с в моем случае это будет выглядеть так
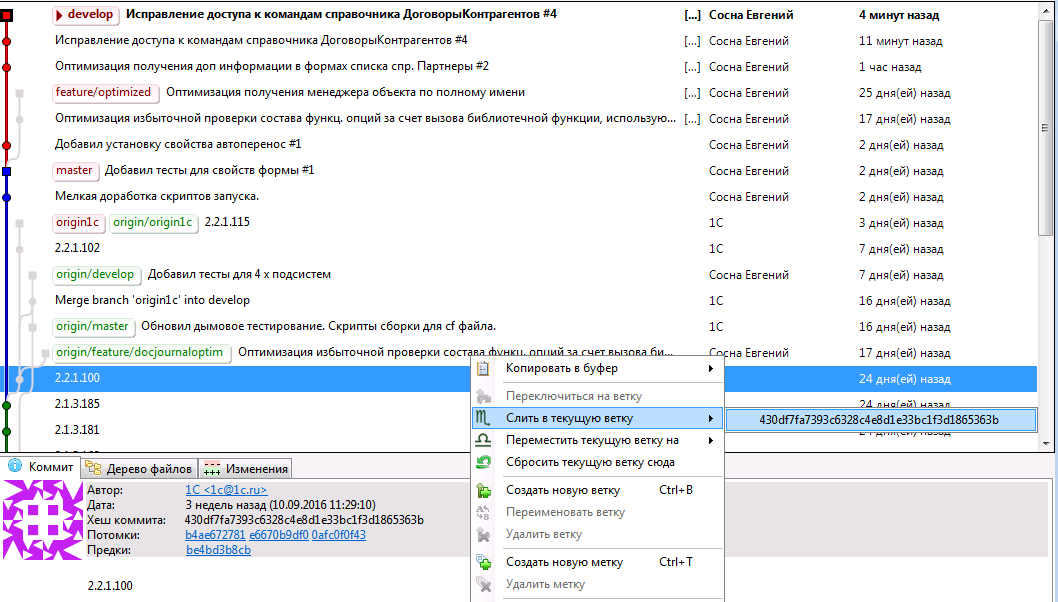
находясь в ветке develop находим оригинальный коммит необходимого нам обновления и выбираем пункт меню “Слить в текущую ветку” или же, если вы любите консоль так, как люблю ее я, то выполняем команду
git merge --no-ff --no-commit 430dfгде —no-ff это признак, что всегда делать результирующий коммит и 430df это sha1 от коммита, который делали от имени 1С при обновлении конфигурации поставщика, —no-commit означает, что не коммитить сразу, если не было конфликтов, возможно мы по результатам все-таки захотим отредактировать изменения или сообщение коммита.
По результатам merge видим, что у нас есть конфликты в сравнении пытаемся их разрешить с помощью kdiff3. Также видим, что все остальные объекты, метаданных, которые изменяли git разрешил сам.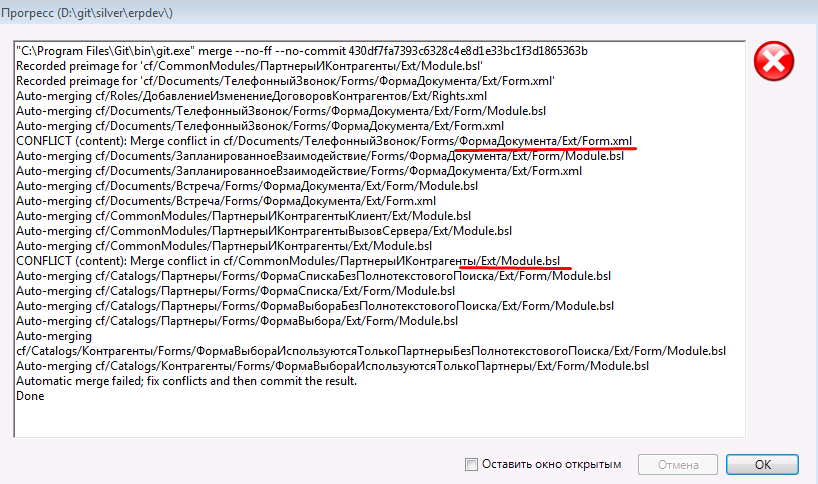
Для файла формы Телефонный звонок, kdiff3 автоматически сам разрешил конфликты и нам остается только нажать Ok, сохранить и закрыть kdiff3
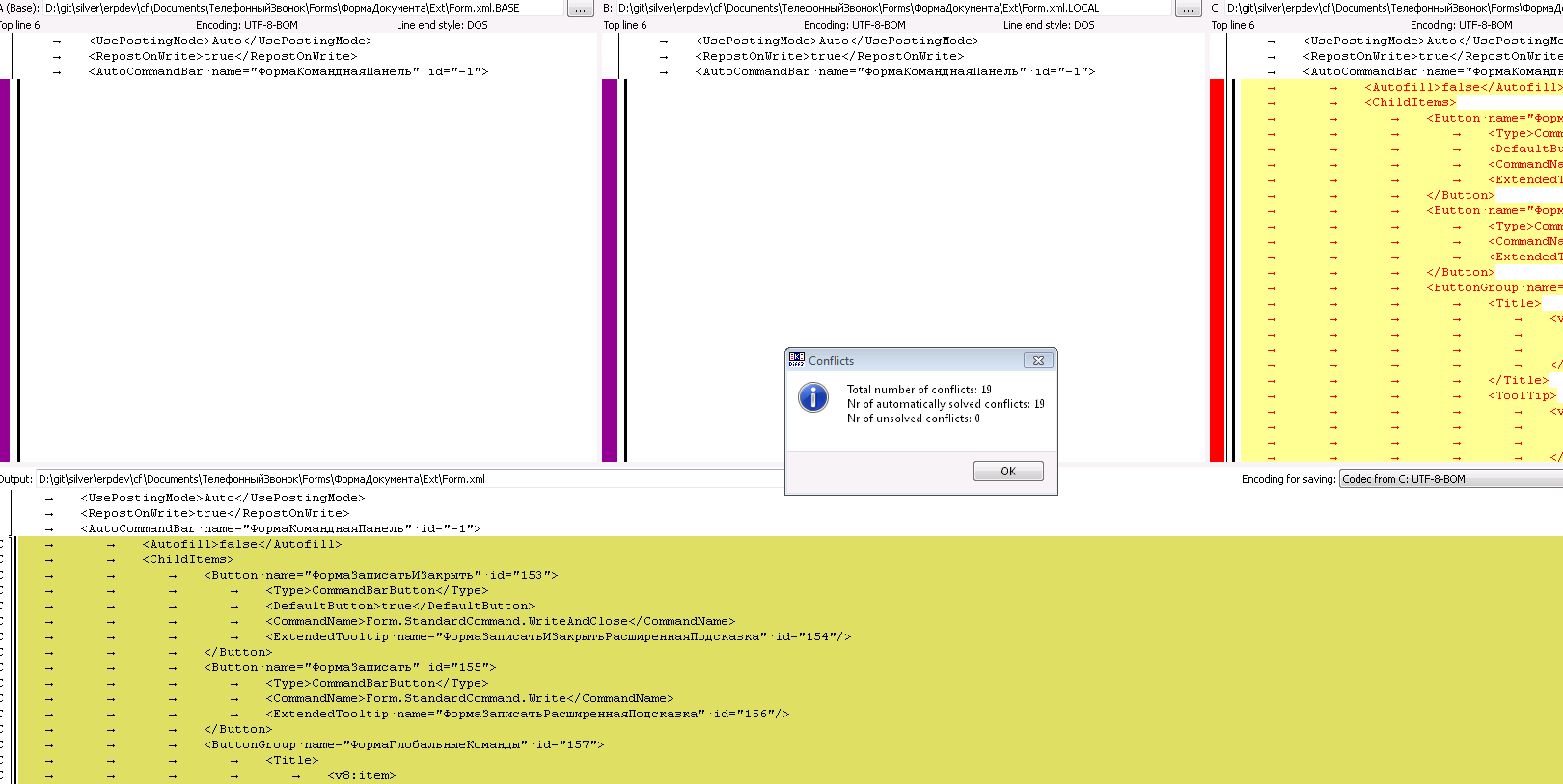
Для общего модуля “ПартнерыИКонтрагенты” чуть сложнее, т.к. тут изменилась процедура которую мы переместили в другой модуль, но как раз в этой процедуре и произошли изменения. Т.к. мы еще находимся в контексте изменений, то можем смело сказать, что нам надо разрешить конфликт с приоритетом файла B (тот, что посредине) и все также убрать данную процедуру из модуля и при этом измененную строку перенести в модуль ПартнерыИКонтрагентыКлиент. Но, если бы мы не были в контексте или же изменения были так давно, что мы даже забыли, а что же в этом модуле делали, то мы всегда можем с вами посмотреть историю изменения именного этого модуля и по сообщениям коммита вспомнить, что-же мы делали, такого. (Привет любителям пустого комментария в хранилище 1с).
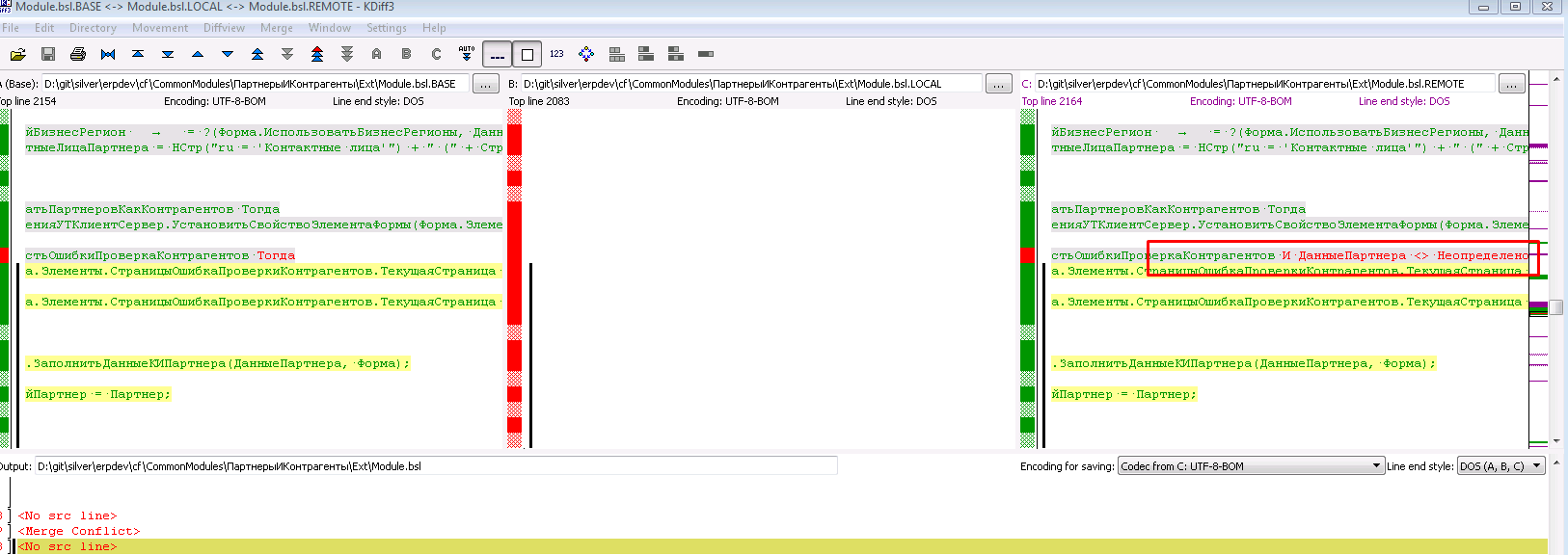
Т.е. для просмотра истории по файлу, открываем еще один просмотрщик git репозитория, находим в дереве наш файл и там выбираем пункт меню “История файла” или же “Авторство изменений”
В результате получаем историю с комментариями изменений именного этого файла и можем посмотреть, кто, что и когда делал. При необходимости можем быстро восстановить контекст изменения и понять, что же нам по результатам надо сделать с данным конфликтом:
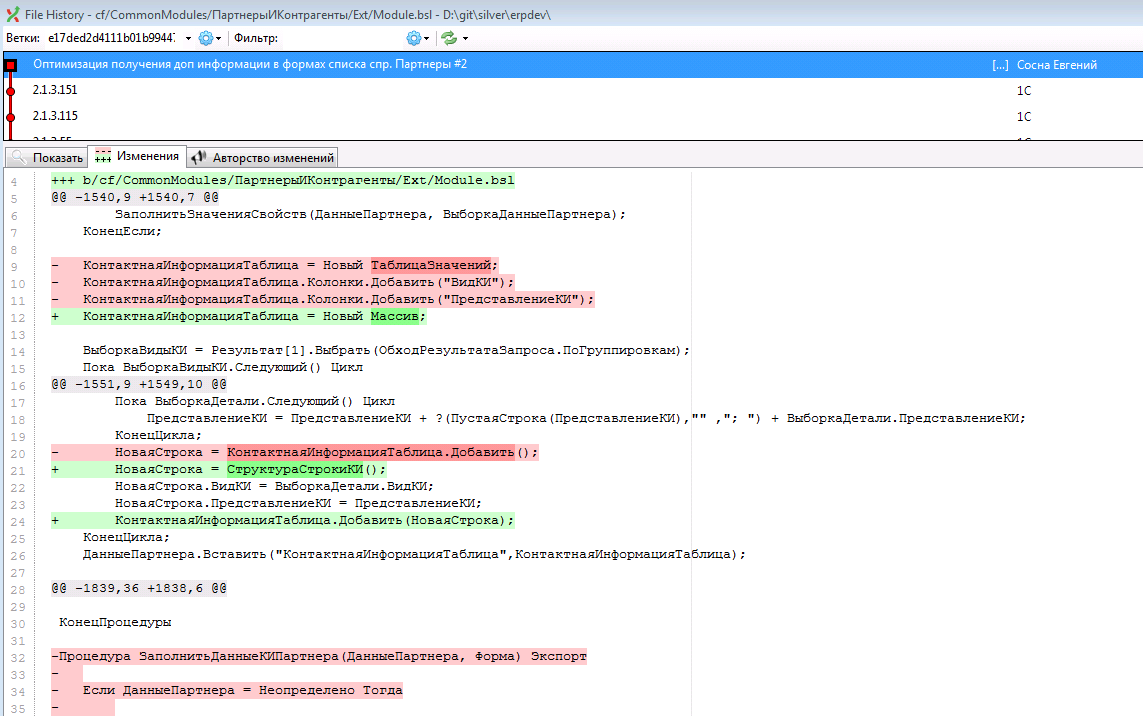
Возвращаемся в окошко kdiff3, копируем измененную строку и в vscode меняем необходимый нам модуль на правильное поведение.
Если бы я проводил code-review для этого изменения, то попросил бы в самом начале сразу инициализировать переменную “Форма.ЕстьОшибкиПроверкаКонтрагентов = Ложь” и не проверять дополнительно на ДанныеПартнера <> Неопределено, но не я провожу code-review и оставим типовой код как есть, для простоты последующего сопровождения.
Как видим на этом скриншоте у нас остался только 1 файл модуля ПартнерыИКонтрагентыКлиент не проиндексирован, т.к. мы его вручную исправляли.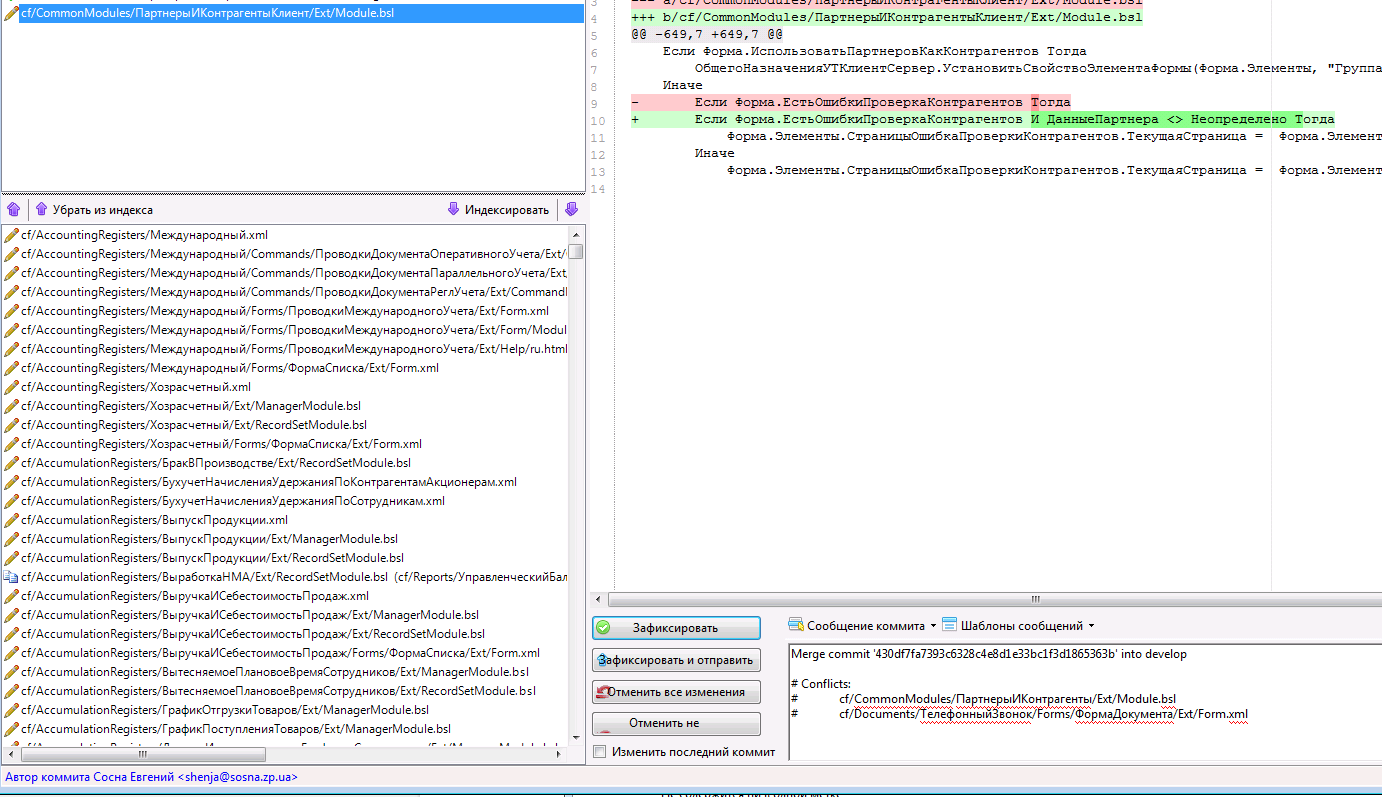
При запуске обновления с версией 2.2.1.100 фильтром “Показывать дважды измененные” можно увидеть количественный шум от списка изменений которые нам предлагаются разрешить.
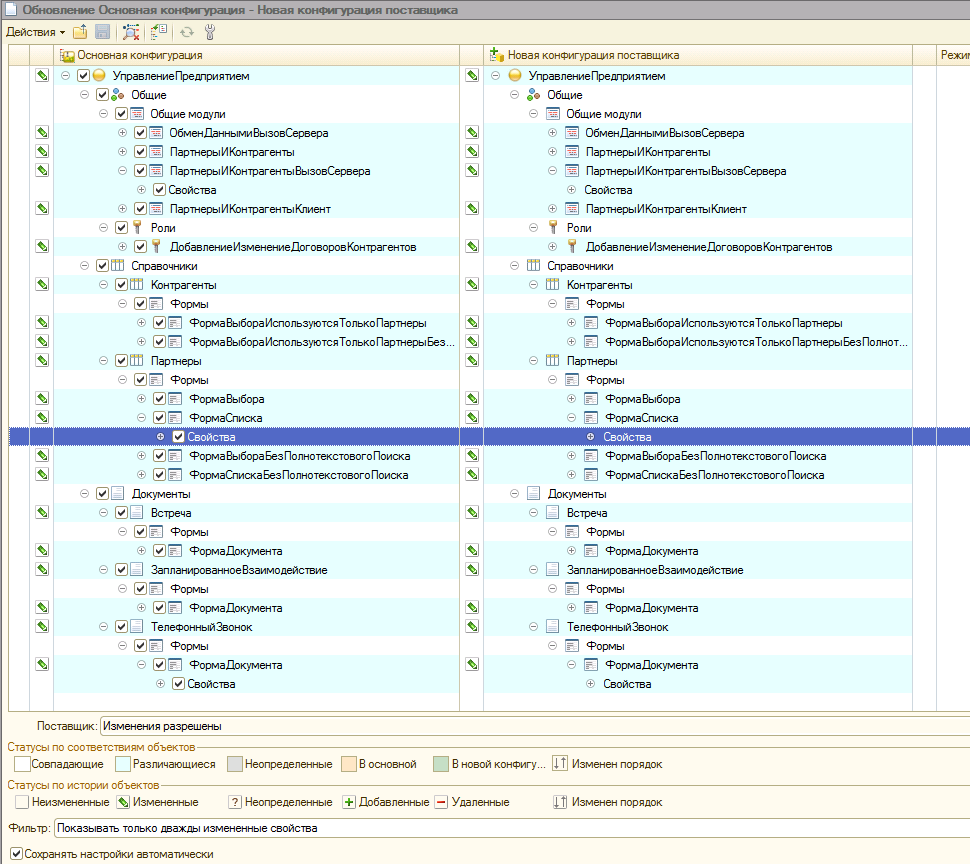
И если с модулями более или менее понятно, что делать, то для ролей и форм объединение с каким-либо приоритетом может дать неожиданные результаты.
Как и говорилось по плану, выбираем «Объединить с приоритетом основной конфигурации» и запускаем сравнение с собранным cf файлом из исходников из каталога в котором делали merge конфигурации.
При этом, если выбрать фильтр с “Показывать только свойства с конфликтами объединения”, то в списке будет совершенно пусто, что ни есть правильно.Осталось теперь выполнить последний шаг в виде сравнения объединения собранного cf файла из исходников и объединить только те объекты метаданных, которые у нас были реально изменены. Дополнительно, хотелось бы отметить, что есть проблема с выгрузкой/загрузкой справочной информации, и даже 8.3.9.1818 не научилась нормально выгружать файлы справки, поэтому в файле mergeSettings.xml советую сразу прописать для всех свойств объектов метаданных правило “DoNotMerge”.
Для формирования файла mergeSettings можно воспользоваться получением информации об измененных файлах по результатам merge “git diff —name-only —cached” и сформировать простейшим скриптом необходимый нам mergeSettings. В результате получаем такой пример объединения конфигураций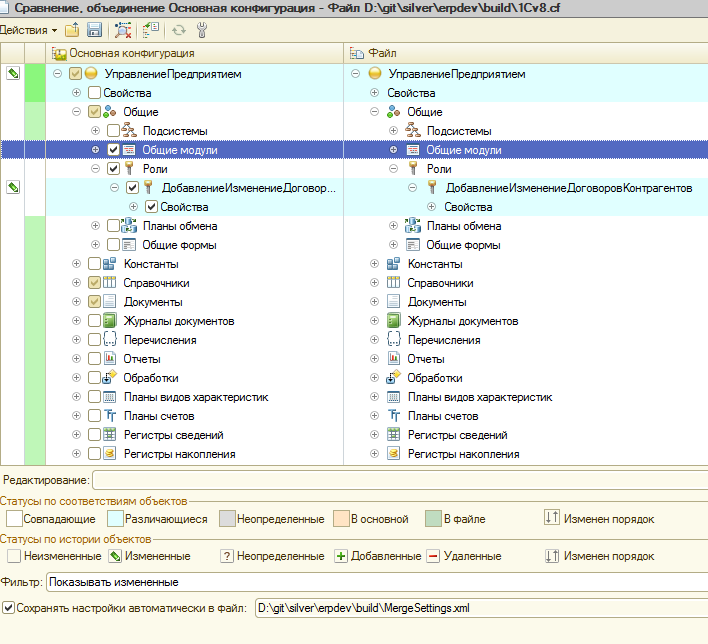
Нам осталось только выполнить объединение, обновление конфигурации базы данных, но это все обычные действия с которыми все знакомы, и провести итоговый запуск тестов для проверки, что у нас все работает и поведение наших доработок не отличается от ожидаемого.
В git результат обновления и объединения будет выглядеть так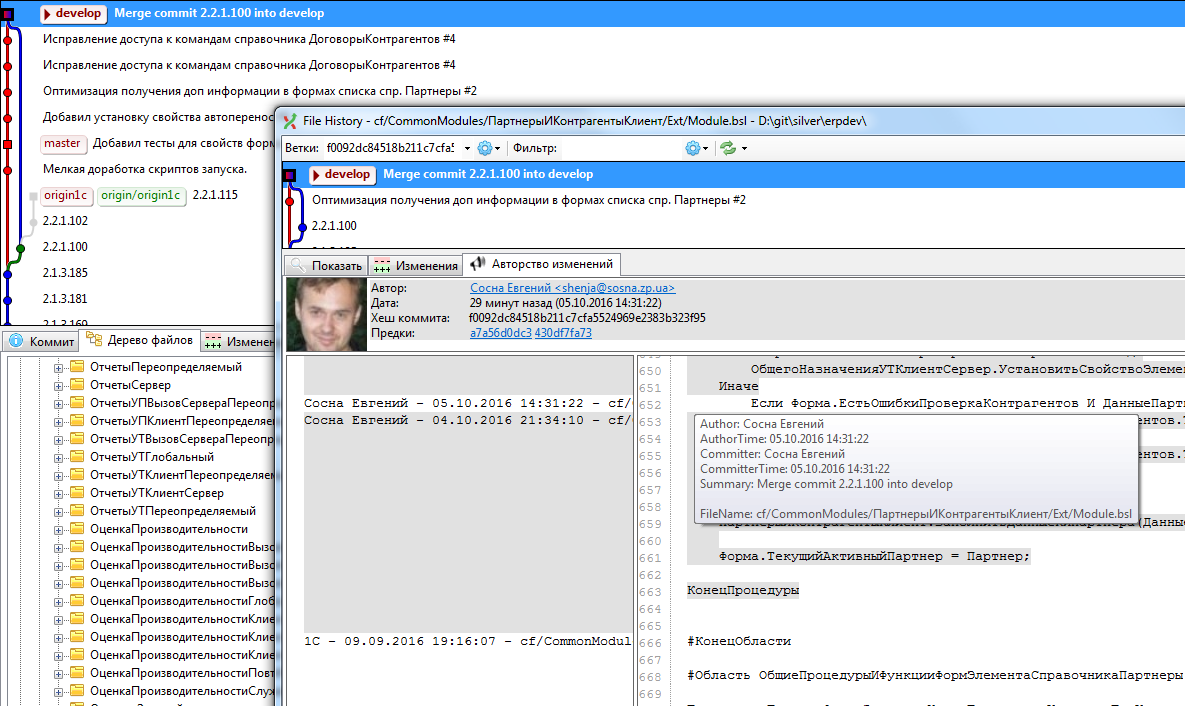
p.s.: все вышеописанные действия поддаются автоматизации, кроме разрешения конфликтов. Все файлы патчей представлены в этом репозитории https://goo.gl/9UB91i











Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Очень познавательно.
Я периодически натыкаюсь на статьи по TDD и BDD, но системного восприятия все равно нет и это мешает в полной мере оценить мощь этого подхода.
Автор, подскажите с чего по порядку можно начать изучение этой темы?
Например, как развернуть и настроить окружение (git+»черепаха»+Vanessa+1C) для разработки/доработки по описанной вами методике?
что такое Vanessa-behavior, feature файлы и как научиться с этим управляться?
может ссылки есть наготове?
Спасибо.
(1) Makushimo, ИМХО, начать лучше с изучения git и начала работы с ним. Так как это система версионирования, то она требует внимания. Затем начать курить мануалы по работе с docker и vagrant — они помогут быстро без особых усилий разворачивать рабочие пространства, которые будут требоваться в работе над разными проектами, дабы не засорять основную операционную систему.
После этого можно приступить к изучению методологий TDD и BDD.
Часто в личных разработках или на фрилансе методологии эти сложно применить, хорошо сработают работе в команде. ПОсле того как будет постигнут начальный уровень дзен разработки по промышленным стандартам можно начать изучать системы автосборок, скриптописания. Что касается Vanessa-behavior — это опенсорц фреймворк для автотестирования с написание БТ на языке геркин вот тут подробнее
Женя, это шикарная статья)
(1) Makushimo, извините, но я не смогу вам ответить в полной мере, т.к. ссылки не храню, а доверяю их гуглу.
Как минимум на infostart есть пару статей обзорных
Есть даже курсы по обучению, насколько я знаю Никита Грызлов как раз готовит такой по непрерывной интеграции и научит вас готовить jenkins.
Могу только посоветовать гуглить precommit1c, vanessa-behavior (посмотреть вебинары Леонида Паутова по использованию инструментария), учить базовые понятия git и присматриваться к jenkins — это тот стек, который я использую.
На скриншоте
процедура ЯОткрываюФормуСоСвойствомИЗначениемИСохраняюВКонтекст. Хотя по предыдущему рисунку там только Дано: я открываю форму «…ФормаДокумента» и сохраняю в контекст
(4) kraynev-navi, для уменьшения скрина я просто не включил эту процедуру, по факту она вызывает ЯОткрываюФормуСоСвойствомИЗначениемИСохраняюВКонтест, это можно посмотреть в самом файле patch
А где про него прочитать?
А как с точки зрения безопасности посмотреть на хранение данных к этой учетной записи?
Предположим нехороший человек внутри компании может узреть логин-пароль какой-нибудь «всевидящей» роли и просто похаживать под ней, посматривая на запрещенные для его статуса данные. Как-то ограничивать, наверное, надо? Какая здесь практика?
(6) kraynev-navi,
это просто теги, по которым в дальнейшем можно отфильтровать те feature которые хочешь запустить в определенный момент.
Использовать не рабочую базу, а если хотите использовать копию рабочей, то сделать простейшую обработку, которая сбросит пароли пользователям после копирования, а для БСП конфигураций, вам еще необходимо установить прокси на несуществующий или mock (soapUI) адрес, установить признак, что это копия информационной базы и т.д.
(6) kraynev-navi, фиче-файлы прогоняются на пустой минимально заполненной базы. Никакой пользы от демо-доступа в приемочную базу да ещё и на изолированном ci-контуре у злоумышленника не будет.
(7)(8) Да я ужо понял, что ерунду по утру спросил
(0)
1. Политика веток/меток чересчур упрощенная, если она точно такая же в боевой работе, то это не гуд.
2. Я правильно понимаю, что механизм поставки от 1С при этом выкидывается? Само по себе это нормально, пока итоговое решение на поставке одной конфы, но 2 конфигурации поставщика ваша схема без доработки не прожуёт. Про механизм расширений — не знаю, не могу сходу применимость оценить.
3. Самая вкусная тема механизма поставки — видеть одновременно старую конфигурацию поставщика, наши изменения относительно неё и новую конфигурацию. Собственно, задача «внести свои изменения в типовую, чтобы я всегда мог их видеть и идентифицировать» нормально решается и gitом, и поставкой — это лёгкий кейс. Кейс, который реально проверяет методику — «мы тут командой написали кучу кода для 1.2.3.4, а вчера 1С выпустила 1.2.4.5 и нам надо на неё быстро-быстро переезжать, потому что регуляторные требования». Сразу скажу, что «мега-черри-пик» хорошей идеей не выглядит 🙂
4. Еще одна печаль для git — сравнение табличных документов, графических схем и прочей подобной ерунды. Если формы еще как-то сравнибельны, то табличные документы….
В задаче «с 1.2.3.4 на 1.2.4.5» git тоже поможет, но совесем по-другому. Например, не надо будет выполнять трёхстороннее сравнение без права на промежуточные сохранения (ага, я протычивал тыщи галочек при обновлении УПП, еще помню, больше не хочу).
(10) speshuric,
Да на практике, конечно их больше, но это уже зависит от моих «извращений», есть ветки висящие мертвым грузом. Но стараюсь придерживаться: master — то что в продакшине, develop — в разработке, ну и куча feature/* от hotfix пока профита не получил, чаще проще было на develop обновится, она более или менее стабильна всегда.
Да, сознательно выкидываю и в репозиториях прописываю в gitignore *.cf и Parent*.bin, т.к. нет нормального механизма описания поставки и только лишнее место занимают. При этом для разработчика выдается обязательно *.dt файл, в котором как раз и есть актуальный срез конфигурации с конфигурацией поставщика, что-бы видеть замочки.
С расширениями тема пока вызывает вопросы, т.к. неизвестно как их сравнивать, как документировать и насколько может поменяться логика работы конфигурации после незначительного обновления, при этом забыли проверить расширение не переопределялся ли там модуль и т.д., пока проблем больше чем вариантов решений. И если с изменением конфигурации это можно выявить хоть примерно на этапе сравнения, то с расширением — беда.
не рассматривали не мега коммит «Обновление типовой на 1.2.4.5» от имени 1C, а несколько коммитов по подсистемам и потом merge в origin1c, тогда можно как черри-пик, так и мелкий merge сделать (имхо в таком варианте merge будет предпочтительней с включенным модулем rere)
просил у 1C xsd схемы для таких метаданных, но они сказали «в планах публикации такого нет», поэтому вскоре попробую сам создать пару примеров и попытаю счастья с merge EMF пакетов в Eclipse, возможно будет хорошее решение.
Для форм и предопредленных данных или метаданных помогает xmldiff консольная утилита, т.к. чаще всего это добавление в дерево нового узла.
(0) Отличная практическая статья, давно такой не хватало! Подписываюсь на комментарии 🙂
На такие статья нужно подписываться в обязательном порядке!
Переопубликовал где только мог. Фундаментально!
Хорошая статья, спасибо, заинтересовало.
(15) necropunk, что именно git или тесты или и то и другое?
(16) с тестами вообще круть, но для меня пока недосягаемо. Работа с git впечатлило, тут пока папку разработки внешних обработок через OneScript к Git подключил — семь потов сошло, в статье вообще высший пилотаж, конечно…
А если серьезно, то давно пора взяться за изучение.
pumbaE, ты все-таки добил 1С своими патчами:
Осталось дождаться 8.3.11 (
Вот тут интересней 😉
А мне вот интересно как вы поступали с переименованиями. К примеру, переименовали справочник из НенужныйСправочник в УдалитьНенужныйСправочник или форму или ещё что-нибудь. Как с этим быть?
Если в типовой конфигурации это в 90% будут переименования с добавлением приставки Удалить, то в моей разработке при рефакторинге бывают совершенно другие переименования. Я просто не знаю, что с ними делать, чтобы сохранялась их история. Вручную про них незабывать совершенно нереально.
И если в каком-нибудь старом коммите обнаружил, что переименование прошло как удаление и добавление, можно ли как-нибудь ручным приводом этот старый коммит исправить, чтобы всё встало на свои места?
(21) sashocq, обычно git сам определяет, что это переименование файла или каталога, конечно если вы не будете сильно менять содержимое файлов, но есть и ручная команда git mv староеИмя новоеИмя.
Если вам необходимо исправить историю, то тут только checkout на этот коммит, исправление и потом последующий rebase.
Не могли бы пояснить: как я понимаю для интеграции с репозиторием используется стандартный функционал конфигуратора по выгрузке (/загрузке) конфигурации в файлы xml.
А готов ли этот механизм для того чтобы заменить хранилище git-ом? Для примера, выгрузил cf из УТ11, потом выгрузил в файлы и собрал из них новый cf-ник (попутно получил предупреждения о каких-то картинках).
Итого:
1. Разница в размере cf — примерно 5Мб.
2. Если сравнить получившуюся конфу с cf, обнаруживаются различия в ряде обработок и нескольких документа (различия правда отображаются пустыми).
(23) очень полезно:
* выгрузить УТ11 в git
* закомитить
* загрузить конфигурацию из git
* выгрузить после этого еще раз выгрузить конфигурацию в git
* сделать git diff
* офигеть 😉
и пойти смотреть
(24) Спасибо за наводку. Однако, если закоммитить, загрузить и выгрузить снова — «nothing to commit, working tree clean»
(1)
и не более. все это перекрывается одним костылем, следовательно малопригодно для практического применения
Евгений, а не поделитесь «простейшим скриптом» который помогает сделать необходимый нам mergeSetting из патча git? 😉
Спасибо за статью!
(28) Нужен такой скрипт! Удалось найти?
(29) Да я в итоге написал сам:
В 1с можно тесты делать?
(31) да. есть куча фреймворков для тестирования, от unit-тестов до behavior- и сценарных тестов.