
Что происходит при записи регистра в различных режимах? Что такое на самом деле «СрезПервых» и «СрезПоследних»? Как оптимально выбрать структуру регистра?
Это та информация, владея которой, начинаешь лучше понимать как это работает и как правильно использовать регистры сведений.
Публикация имеет характер исследования, поэтому подробная и объемная. Кто не любит много букв — можно начать с выводов, они специально выделены в содержании.
Для тех, кто только делает первые шаги в 1С: не смотря на подробность изложенной информации и её справочно-обучающую интонацию, тут нет самых азов. Подразумевается, что читатель уже имеет базовое понимание и практику конфигурирования в 1С. Статья не учит как программировать, но она помогает найти ответы на вопросы «А как правильно и почему именно так?».
Для тех, кто все это знает: возможно, у вас есть свои выводы и своя точка зрения, делитесь ими в коментах. Спасибо!
1. Архитектура регистра на уровне СУБД.
— индексы непериодического, независимого регистра сведений
— индексы непериодического, подчиненного РС
— индексы периодического, независимого РС
— индексы периодического, подчиненного РС
— индексы периодического РС с периодичностью «По позиции регистратора»
— индексы таблицы итогов среза первых и среза последних
2. Разбираемся с записью регистров
Независимые регистры сведений.
Подчиненные регистры сведений.
— запись с замещением и признаком обмена данными
— запись без замещения с признаком обмена данных
— подчиненный РС с периодичностью по позиции регистратора
Промежуточные выводы. Сравниваем 8.2 и 8.3, независимые и подчиненные регистры.
— запись с замещением («по умолчанию»)
подчиненные регистры с таблицей итогов
3. Как работает СрезПоследних (СрезПервых) в запросе
срез последних на языке 1С для регистра с периодичностью <> по позиции регистратора
срез последних на языке 1С для регистра с периодичность «По позиции регистратора»
самая частая ошибка при фильтрации среза
отличия 8.2 и 8.3 для запросов среза
когда используется таблица итогов
Все примеры будут даны для версий 1С 8.3.6 — 8.3.8. На 8.2.19 логика на 99% совпадает с работой 8.3, есть несколько отличий, про которые обязательно упомяну.
Работа платформы с регистрами сведений несколько раз менялась. 8.3 стала более оптимальной и как бы мне не хотелось «потыкать палочкой» в 8.1 и в ранние версии 8.2, дабы показать как все было плохо, решил этого не делать. Кому станет любопытно «как было» — получит мотивацию изучить вопрос.
Вводная.
Основное назначение регистров сведений — хранить информацию НЕ ссылочного типа в разрезе комбинации измерений и, как частный случай, хранить изменяемые во времени значения. По большому счету, в регистре можно хранить что угодно, но получить ссылку на саму запись регистра и сохранить её (ссылку на запись) в реквизитах другого объекта, например справочника, уже не получится. Собственно отличие ссылочных типов от не ссылочных — это один из краеугольных камней 1С т.ч. кто прогуливал — учим мат часть.
1. Архитектура регистра на уровне СУБД.
Спустимся с уровня абстракции «конфигуратор» на уровень «СУБД» и вспомним, в очередной раз, что все данные базы хранятся именно в СУБД. Это может быть файловая база (тут в роли СУБД платформа 1С), PosgreSQL, IBM DB2, Oracle и MS SQL Server.
Регистр сведений на уровне СУБД представляет собой обычную плоскую таблицу, в которой колонки это наши измерения, ресурсы и реквизиты, а строки — записи регистра. Узнать какая таблица СУБД соответствует конкретному регистру, можно используя метод платформы ПолучитьСтруктуруХраненияБазыДанных(), либо воспользоваться одной из множества обработок, уже опубликованных на INFOSTART.
Отличия ресурсов от реквизитов на уровне хранения данных отсутствуют, это сугубо логическое разделение. Предполагается, что реквизит это некая дополнительная информация, а ресурс — основное значение, которое нам и требуется хранить в разрезе комбинаций измерений.
Отличие измерений от ресурсов и реквизитов в том, что измерения в полном составе присутствуют во всех индексах таблицы. Порядок следования измерений в индексе такой же, как в конфигураторе. Если у ресурса (реквизита) установлено свойство «Индексировать», то будет создан индекс, в котором на первом месте этот ресурс (реквизит), а далее все наши измерения. Установить свойство «Индексировать» можно и у измерения, в этом случае будет создан дополнительный индекс, в котором на первом месте «проиндексированное» поле, а следом за ним оставшиеся измерения.
До версии 8.2.15 непериодический регистр сведений не имел кластерного индекса, начиная с этой версии, платформа создает кластерный индекс, состоящий из измерений (в том порядке, как они заданы в конфигураторе).
Версия 8.3 принесла еще несколько важных изменений:
- для периодических регистров кластерным стал индекс, в котором сначала следуют все измерения, а на последнем месте колонка Период (в 8.2 кластерным будет являться индекс, в котором на первом месте стоит Период, а затем перечислены все измерения);
- появились физические таблицы итогов для хранения среза первых и среза последних. Создавать или нет эти таблицы — решает разработчик, установив соответствующее свойство в конфигураторе.
Давайте посмотрим, какие индексы создаются в зависимости от версии платформы, периодичности и подчиненности регистра. Сразу оговорюсь, что информация на ИТС не точна в части кластерных индексов, верить написанному ниже:
Непериодический, независимый регистр
| Индекс | Условие и описание | Кластерный |
| Измерение1 + [Измерение2 +…] | Есть хоть одно измерение регистра. Индекс, включающий все измерения в том порядке, в котором они заданы при конфигурировании. | начиная с 8.2.15 и 8.3 |
| ИзмерениеN + Измерение1 + [Измерение2 +…] | Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не первое и не единственное измерение. Первое поле — ИзмерениеN, затем все остальные измерения в том порядке, в котором они заданы при конфигурировании. | — |
| Реквизит + Измерение1 + [Измерение2 +…] | Реквизиту «Реквизит» задано свойство «Индексировать». Индекс, в котором первое поле — Реквизит, затем все измерения в том порядке, в котором они заданы при конфигурировании. | — |
| Ресурс + Измерение1 + [Измерение2 +…] | Ресурсу «Ресурс» задано свойство «Индексировать». Индекс, в котором первое поле — Ресурс, затем все измерения в том порядке, в котором они заданы при конфигурировании. | — |
| SimpleKey (удалено в 8.3.3 и старше) | Количество измерений больше одного. Используется для обхода регистра при реструктуризации, а также для выборки записей с использованием оптимального порядка обхода. | — |
Непериодический, подчиненный регистр
| Индекс | Условие и описание | Кластерный |
| Регистратор + НомерСтроки | Создается всегда. | Да, всегда |
| Измерение1 + [Измерение2 +…] | Есть хоть одно измерение регистра. | — |
| ИзмерениеN + Измерение1 + [Измерение2 +…] | Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не первое и не единственное измерение | — |
| Реквизит + Измерение1 + [Измерение2 +…] | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Измерение1 + [Измерение2 +…] | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
| SimpleKey (удалено в 8.3.3 и старше) | Количество измерений больше одного. Используется для обхода регистра при реструктуризации, а также для выборки записей с использованием оптимального порядка обхода. | — |
Периодический, независимый регистр
| Индекс | Условие и описание | Кластерный |
| Период + [Измерение1 + …] | Создается всегда. | для 8.2 |
| Измерение1 + [Измерение2 +…] + Период | Есть хоть одно измерение регистра. | для 8.3 |
| ИзмерениеN + Период + Измерение1 + [Измерение2 +…] | Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не единственное измерение. | — |
| Реквизит + Период + [Измерение1 + …] | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Период + [Измерение1 + …] | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
Периодический, подчиненный регистр
| Индекс | Условие и описание | Кластерный |
| Регистратор + НомерСтроки | Создается всегда. | — |
| Период + [Измерение1 + …] + [Активность]* | Создается всегда. | для 8.2 |
| Измерение1 + [Измерение2 +…] + Период + [Активность]* | Есть хоть одно измерение регистра. | для 8.3 |
| ИзмерениеN + Период + Измерение1 + [Измерение2 +…] + [Активность]* |
Измерению «ИзмерениеN» задано свойство «Индексировать» или свойство «Ведущее» и при этом это не единственное измерение. |
— |
| Реквизит + Период + [Измерение1 + …] + [Активность]* | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Период + [Измерение1 + …] | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
* только для 8.3
Периодический, с периодичностью «По позиции регистратора»
| Индекс | Условие и описание | Кластерный |
| Период + Регистратор + НомерСтроки | Создается всегда. | для 8.2 |
| Регистратор + НомерСтроки | Создается всегда. | — |
| Измерение1 + [Измерение2 + …] + Период + Регистратор + НомерСтроки + [Активность]* | Есть хоть одно измерение регистра. | для 8.3 |
| Измерение + Период + Регистратор + НомерСтроки + [Активность]* | Измерению «Измерение» задано свойство «Индексировать». | — |
| Реквизит + Период + Регистратор + НомерСтроки + [Активность]* | Реквизиту «Реквизит» задано свойство «Индексировать». | — |
| Ресурс + Период + Регистратор + НомерСтроки | Ресурсу «Ресурс» задано свойство «Индексировать». | — |
* только для 8.3
Индексы таблицы итогов среза первых и среза последних. Только для 8.3.
| Индекс | Условие и описание | Кластерный |
| Измерение1 + [Измерение2 + …] | Есть хоть одно измерение регистра. | — |
| Реквизит + [Измерение1 + …] | Реквизиту «Реквизит» задано свойство «Индексировать» | — |
| Ресурс + [Измерение1 + …] | Ресурсу «Ресурс» задано свойство «Индексировать» | — |
Замечание. Если вы в своей базе видите отличия от того, что приведено в таблицах, то, скорее всего, вы работаете в режиме совместимости с 8.2. Так же при переходе с 8.1 на 8.2 структура индексов сама не меняется, необходимо сделать реструктуризацию.
Можно сказать, что в 8.3 структура индексов продумана лучше — в индексы добавлена «Активность», использование в качестве кластерных индексов вида «Измерение1 + [Измерение2 +…] + Период» снижают ресурсоемкость запросов (это ни в коем разе не панацея, но ниже рассмотрим примеры запросов и еще раз затронем тему эффективности индексов). При этом к 8.3 есть и вопросы, например не понятно, почему при индексировании ресурса в периодическом регистре в индекс не добавляется «Активность» и почему нет кластерного индекса в таблицах срезов.
- Порядок измерений, заданный в конфигураторе, влияет на структуру индексов и, как следствие, может влиять на скорость выборки данных. Дело в том, что индекс «не работает» если нет фильтра по первому его полю, при этом поля, по которым накладываются фильтры, должны идти в индексе друг за другом.
Например, есть непериодический, независимый регистр со следующими измерениями: Организация, Склад, Номенклатура. В СУБД получаем таблицу с одним индексом Организация + Склад + Номенклатура. Теперь рассмотрим различные варианты запросов к этому регистру:
- запрос с условием отбора только по Номенклатуре …ГДЕ Номенклатура = &Номенклатура — индекс «работать» не будет.
- запрос с фильтром …ГДЕ Склад = &Склад И Номенклатура = &Номенклатура — индекс так же не будет «работать» т.к. и в том и в другом случае нет отбора по Организации.
- запрос с отбором …ГДЕ Организация = &Организация И Номенклатура = &Номенклатура — индекс будет работать, но не эффективно — все данные по Организации будут получены быстро, но потом все они будут просканированы (построчно просмотрены), проверяя та ли Номенклатура в этой строке. А т.к. организаций обычно всего одна, а Номенклатур очень много, то прочитаны будут все строки регистра.
Для этого набора запросов самым оптимальным будет поменять местами измерения Организация и Номенклатура (получим индекс Номенклатура + Склад + Организация), тогда вопрос с эффективным использованием индекса будет только для запроса …ГДЕ Организация = &Организация И Номенклатура = &Номенклатура. Если в базе только одна организация, то индекс можно назвать подходящим т.к. условие по номенклатуре уже вернет малое число строк, которые очень быстро проверятся на соответствие условию по организации. Если организаций много, то правильным решением будет дополнительно создать индекс Организация + Номенклатура [+ Склад].
Итоговый универсальный вариант: измерения в порядке следования Номенклатура, Склад, Организация, у измерения Организация ставим свойство Индексировать.
Из этого примера можно сделать очень интересный вывод — спроектировать оптимальную архитектуру регистра можно только при известном пуле запросов, которые будут к нему обращаться, и понимании как будут распределяться данные!
- Стремитесь к тому, что бы кластерный индекс регистра покрывал потребности самых частых запросов. Кластерный индекс содержит в себе все данные таблицы, для простоты понимания можно сказать, что кластерный индекс это надстройка над данными. Некластерный содержит только значения тех полей, из которых он состоит. Например, есть периодический независимый регистр сведений «ЦеныТоваров» с измерениями Товар + ВидЦены и ресурсом Цена. Самая частая задача — зная товар и вид цены получить актуальную цену товара, т.е. по значениям измерений получить значение ресурса «Цена». Для этой цели идеально подходит типовой индекс «Товар + ВидЦены + Период». В 8.3 этот индекс будет кластерным и значение цены будет получено сразу. В 8.2 этот индекс некластерный, что означает необходимость дополнительно «залезть» в таблицу данных и получить нужное значение.
- Не желательно создавать регистры с большим числом измерений. Обратная сторона индексов — накладные расходы на их содержание. Чем «легче» индекс, т.е. чем меньше полей в него входит и чем меньше места занимают данные в этих полях, тем быстрее происходит запись и поиск данных. Это не стоит расценивать как табу, задачи бывают разные, но если вы проектируете регистр, для которого важна быстрая вставка больших объемов данных, то старайтесь снизить и число измерений и число индексов в этой таблице.
Особо отмечу, что индекс не может содержать более 16 полей и периодический регистр с 16ю измерениями платформа усечет поля в индексах — создаст без последнего измерения: [Период + Измерение1 + … + Измерение15], а второй индекс не будет содержать поле Период: [Измерение1 + … + Измерение16]. Работа с таким регистром может вызвать проблемы со скоростью получения данных, хотя с прикладной точки зрения ошибок не будет. Стоит учитывать составные типы, одно измерение составного типа в СУБД будет состоять из нескольких полей (в самом жестком случае — до 7 полей на одно измерение).
Знания что такое индекс, как он работает, чем отличается кластерный от не кластерного — очень важны, кто не уверен в своих силах, могу посоветовать доклады Дмитрия Короткевича.
2. Запись регистра.
Казалось бы, простая запись регистра, в чем тут разбираться? Но у набора записей существует три режима записи, да еще и менеджер записи добавляется т.ч. «будем посмотреть».
Вводные: база на 8.3 (проверено на 8.3.6 — 8.3.8), несколько регистров сведений и MS SQL Server. Разбираться, что происходит в СУБД, будем путем трассировок запросов (Profiler).
Независимые регистры сведений.
Структура регистра:
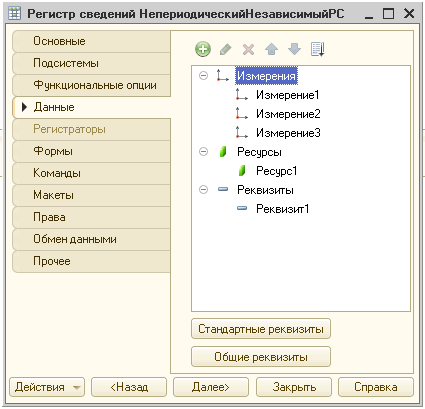
Выполняемый код 1С:
ОбъектРегистр = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьНаборЗаписей();
ОбъектРегистр.ОбменДанными.Загрузка = РежимЗагрузки;
СтруктураОтбора = Новый Структура();
СтруктураОтбора.Вставить("Измерение1", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение2", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение3", Новый УникальныйИдентификатор);
ОбъектРегистр.Отбор.Измерение1.Установить(СтруктураОтбора.Измерение1);
ОбъектРегистр.Отбор.Измерение2.Установить(СтруктураОтбора.Измерение2);
ОбъектРегистр.Отбор.Измерение3.Установить(СтруктураОтбора.Измерение3);
ЗаполнитьЗначенияСвойств(ОбъектРегистр.Добавить(), СтруктураОтбора);
ОбъектРегистр.Записать(Замещать);
Независимые РС. Режим 1. Запись «по умолчанию».
// (!)Режим загрузки при замещении не влияет на генерируемые платформой запросы
ОбъектРегистр.ОбменДанными.Загрузка = <Любой>;
// ...
ОбъектРегистр.Записать(Истина);
Генерируемые запросы:
1.1. Открываем транзакцию
BEGIN TRANSACTION
1.2. Удаление записей по значению установленного отбора записываемого набора. Обращаю внимание, что этот запрос выполняется всегда.
DELETE FROM T1 FROM dbo._InfoRg288 T1 WHERE T1._Fld289 = @P1 AND T1._Fld290 = @P2 AND T1._Fld291 = @P3
если установить отбор только на Измерение1 и Измерение2, то условие сократиться до <<…WHERE T1._Fld289 = @P1 AND T1._Fld290 = @P2 >>, если отборы не установлены — удаляться все записи.
1.3. Вставляем запись в таблицу.
INSERT INTO dbo._InfoRg288(_Fld289,_Fld290,_Fld291,_Fld292,_Fld293) VALUES(@P1,@P2,@P3,@P4,@P5)
таких запросов будет ровно столько, сколько строк в записываемом наборе записей
1.4. Фиксируем транзакцию
COMMIT TRANSACTION
Как видим — все достаточно просто, сначала удаляем записи, затем вставляем. Кстати, в 8.2 поведение аналогичное. В чем минус? Только в том, что удаление происходит всегда, даже если вы точно знаете, что вставляемые записи являются новыми.
Независимые РС. Режим 2. Запись без замещения.
ОбъектРегистр.ОбменДанными.Загрузка = ЛОЖЬ;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);
Генерируемые запросы:
2.1. Открываем транзакцию
BEGIN TRANSACTION
2.2. Создаем временную таблицу той же структуры, что и регистр.
CREATE TABLE #tt1(_Fld289 NVARCHAR(10), _Fld290 NVARCHAR(10), _Fld291 NVARCHAR(10), _Fld292 NVARCHAR(10), _Fld293 NVARCHAR(10))
временная таблица однотипной структуры создается только однажды в рамках одного и того же соединения с СУБД. Проще говоря, если пользователь записывает тот же регистр второй и более раз, то создание временной таблицы у него будет только при первой записи
2.3. Вставляем строку регистра во временную таблицу.
INSERT INTO #tt1(_Fld289,_Fld290,_Fld291,_Fld292,_Fld293) VALUES(@P1,@P2,@P3,@P4,@P5)
таких запросов будет ровно столько, сколько строк в записываемом наборе записей.
2.4. Проверяем, есть ли в таблице записи с таким же набором измерений
SELECT
T1._Fld289
T1._Fld290
T1._Fld291
T1._Fld292
T1._Fld293
FROM #tt1 T1 WITH(NOLOCK)
INNER JOIN dbo._InfoRg288 T2
ON T1._Fld289 = T2._Fld289 AND T1._Fld290 = T2._Fld290 AND T1._Fld291 = T2._Fld291
если запрос не пустой — выдаем ошибку. Для периодического регистра в условия соединения таблиц добавляется условие по полю _Period.
2.5. Вставляем данные из временной таблицы в таблицу регистра
INSERT INTO dbo._InfoRg288(_Fld289, _Fld290, _Fld291, _Fld292, _Fld293) SELECT
T1._Fld289
T1._Fld290
T1._Fld291
T1._Fld292
T1._Fld293
FROM #tt1 T1 WITH(NOLOCK)
2.6. Фиксируем транзакцию
COMMIT TRANSACTION
2.7. Очищаем временную таблицу. Обращаю внимание, что вспомогательную таблицу 8.3 очищает вне транзакции, что логично.
TRUNCATE TABLE #tt1
Сразу скажу про отличия с 8.2 — запросы пунктов 2.6 и 2.7 поменяны местами, т.е. в 8.2 сначала очищаем временную таблицу и только затем фиксируем транзакцию. Повторюсь, поведение 8.3 выглядит более логичным. Так же 8.2 дополнительно, после пункта 2.2, выполняет еще один запрос примерно такого содержания:
INSERT INTO #tt1 SELECT * FROM _InfoRg288 T1 WHERE 1=0
этакая пробная вставка, честно говоря, сложно определить его точное назначение, возможно для совместимости, возможно проверка каких-то прав, установка блокировок.
Итак, очевидно, что запись без замещения содержит больше запросов и будет проигрывать записи с замещением. Тут нет подводных камней, просто используйте режимы по прямому назначению, если при записи набора надо к уже существующим данным добавить новые строки, то Записать(ЛОЖЬ), если записать новый или перезаписать целиком существующий набор записей, то Записать().
Вопрос, что делать, если при вставке новых записей хочется убрать все лишние запросы и заставить 1С только вставлять записи? Для этого есть хитрый режим, который появился только в 8.2.19 и 8.3.
Независимые РС. Режим 3. Запись без проверок.
ОбъектРегистр.ОбменДанными.Загрузка = ИСТИНА;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);
Генерируемые запросы:
3.1. Открываем транзакцию
BEGIN TRANSACTION
3.2. Вставляем запись в таблицу.
INSERT INTO dbo._InfoRg288(_Fld289,_Fld290,_Fld291,_Fld292,_Fld293) VALUES(@P1,@P2,@P3,@P4,@P5)
таких запросов будет ровно столько, сколько строк в записываемом наборе записей
3.3. Фиксируем транзакцию
COMMIT TRANSACTION
Этот режим является самым быстрым для заливки новых данных, но его сфера применения ограничена — логика кода и архитектура решения должна гарантировать, что записываемые данные являются уникальными. При попытке записать дублирующие строки ошибка все равно будет, но уже от самой СУБД:

Выше приведены запросы для непериодического регистра, но отличия от периодического, не содержащего итогов, минимальны — в запросах перед полям измерений добавляется поле _Period, логика и структура запросов, при этом, ровно такая же.
Да, чуть не забыл про менеджер записи регистра сведений. Первое отличие — у менеджера нет свойства ОбменДанными, следовательно, записать в режиме загрузки с его использованием не выйдет. Отличия в запросах СУБД тут появляются только при определенных обстоятельствах. Для случая простой записи данных, например:
МенеджерЗаписи = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Измерение1 = Новый УникальныйИдентификатор;
МенеджерЗаписи.Измерение2 = Новый УникальныйИдентификатор;
МенеджерЗаписи.Измерение3 = Новый УникальныйИдентификатор;
МенеджерЗаписи.Записать(Замещать);
поведение платформы будет ровно такое же. Оно изменится в следующем случае:
МенеджерЗаписи = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Измерение1 = "Измерение1";
МенеджерЗаписи.Измерение2 = "Измерение2";
МенеджерЗаписи.Измерение3 = "Измерение3";
МенеджерЗаписи.Прочитать();
Если МенеджерЗаписи.Выбран() Тогда
// тогда будет отличаться от записи набора записей
Иначе
// записи не существует, а значит
// ранее установленные значения измерений "сбросились"
// поэтому необходимо установить их заново
МенеджерЗаписи.Измерение1 = "Измерение1";
МенеджерЗаписи.Измерение2 = "Измерение2";
КонецЕсли;
// меняем значение измерения
МенеджерЗаписи.Измерение3 = "Измерение4";
МенеджерЗаписи.Записать(Замещать);
и при условии, что прочитанные данные существуют. Фактически мы изменяем существующее значение измерения в записи. При этом платформа добавляет запрос (сразу после начала транзакции) на удаление старых данных:
DELETE FROM T1 FROM dbo._InfoRg288T1 WHERE T1._Fld289=‘Измерение1′ AND T1._Fld290=‘Измерение2′ AND T1._Fld291=‘Измерение3′
Обращаю внимание еще на одну особенность, при чтении, если значение какого либо измерения не указано, то отбор устанавливается по пустому значению этого типа данных:
МенеджерЗаписи = РегистрыСведений.НепериодическийНезависимыйРС.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Измерение1 = "Измерение1";
МенеджерЗаписи.Измерение2 = "Измерение2";
// Измерение3 не указываем
МенеджерЗаписи.Прочитать();
выполняется примерно следующий запрос:
SELECT * FROM dbo._InfoRg288T1 WHERE T1._Fld289=‘Измерение1′ AND T1._Fld290=‘Измерение2′ AND T1._Fld291=»
все логично — конкретная запись однозначно характеризуется комбинацией значений всех измерений (в том числе периода для периодического регистра), следовательно, хотите прочитать одну запись — укажите значения всех этих «характеристик».
Для себя определился только с одной областью применения — изменять значение измерения у конкретной записи. Подытожу цитатой с ИТС:
…Таким образом, основное назначение менеджера записи — обеспечить без дополнительных сложностей редактирование отдельных записей в интерактивных режимах. С точки зрения производительности использование наборов записей будет максимально эффективным. Использование менеджера записей в некоторых случаях будет столь же эффективным, а в некоторых менее, так как будут выполняться лишние действия.
Тест 2. Подчиненные регистры сведений.
Структура регистра:
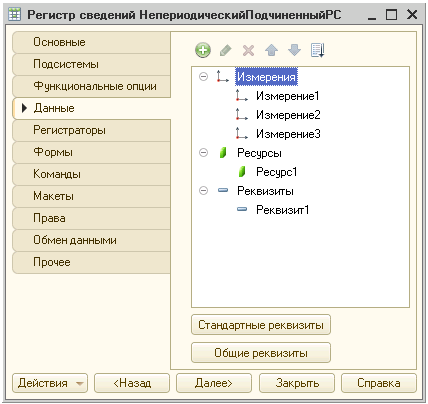

Исполняемый код:
ОбъектРегистр = РегистрыСведений.НепериодическийПодчиненныйРС.СоздатьНаборЗаписей();
ОбъектРегистр.ОбменДанными.Загрузка = РежимЗагрузки;
Регистратор = Документы.Тест.ПолучитьСсылку(Новый УникальныйИдентификатор);
ОбъектРегистр.Отбор.Регистратор.Установить(Регистратор);
Запись = ОбъектРегистр.Добавить();
Запись.Регистратор = Регистратор;
Запись.Период = ТекущаяДата();
Запись.Измерение1 = Новый УникальныйИдентификатор;
Запись.Измерение2 = Новый УникальныйИдентификатор;
Запись.Измерение3 = Новый УникальныйИдентификатор;
ОбъектРегистр.Записать(Замещать);
Подчиненные РС. Режим 1. Запись «по умолчанию».
ОбъектРегистр.ОбменДанными.Загрузка = ЛОЖЬ;
// ...
ОбъектРегистр.Записать(ИСТИНА);
Генерируемые запросы:
1.1. Открываем транзакцию
BEGIN TRANSACTION
1.2. Читаем 100 000 плюс одну запись регистра
SELECT TOP 100001
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
запрос выполняется только для управляемого режима блокировок. Судя по всему, запрос используется для установки управляемых блокировок по значению измерений и определения надо ли делать эскалацию блокировок. В 8.2 запрос меняется на «SELECT TOP 20001…» и добавляется явно ненужная сортировка по номеру строки «ORDER BY T1._LineNo DESC«.
1.3. Удаляем все записи по регистратору
DELETE FROM T1 FROM dbo._InfoRg301 T1 WHERE T1._RecorderRRef = @P1
1.4. Создаем временную таблицу
CREATE TABLE #tt1(
_RecorderRRef BINARY(16),
_LineNo NUMERIC(9, 0),
_Active BINARY(1),
_Fld302 NVARCHAR(10),
_Fld303 NVARCHAR(10),
_Fld304 NVARCHAR(10),
_Fld305 NVARCHAR(10),
_Fld306 NVARCHAR(10))
напоминаю, что этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД
1.5. Заполняем временную таблицу
INSERT INTO #tt1(_RecorderRRef,_LineNo,_Active,_Fld302,_Fld303,_Fld304,_Fld305,_Fld306) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
таких запросов будет столько, сколько строк в записываемом наборе регистра
1.6. Проверка на уникальность по составу измерений.
SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
INNER JOIN dbo._InfoRg301 T2
ON T1._Fld302 = T2._Fld302 AND T1._Fld303 = T2._Fld303 AND T1._Fld304 = T2._Fld304
для периодического регистра в условия соединения добавится соединение по полю _Period
1.7. Вставляем записи в таблицу регистра из вспомогательной таблицы
INSERT INTO dbo._InfoRg301(_RecorderRRef, _LineNo, _Active, _Fld302, _Fld303, _Fld304, _Fld305, _Fld306) SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
1.8. Завершение транзакции
COMMIT TRANSACTION
1.9. Очищаем вспомогательную временную таблицу
TRUNCATE TABLE #tt1
Подчиненные РС. Режим 2. Запись с замещением и признаком обмена данными.
ОбъектРегистр.ОбменДанными.Загрузка = ИСТИНА;
// ...
ОбъектРегистр.Записать(ИСТИНА);
Генерируемые запросы:
2.1. Открываем транзакцию
BEGIN TRANSACTION
2.2. Для установки управляемой блокировки удаляемых данных читаем 100 000 плюс одну запись регистра (подробно в п. 1.2)
SELECT TOP 100001
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
2.3. Удаляем все записи по регистратору
DELETE FROM T1 FROM dbo._InfoRg301 T1 WHERE T1._RecorderRRef = @P1
2.4. Вставляем записи в таблицу регистра
INSERT INTO dbo._InfoRg301(_RecorderRRef,_LineNo,_Active,_Fld302,_Fld303,_Fld304,_Fld305,_Fld306) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
запросов выполняется для каждой строки записываемого набора движений
2.5. Фиксируем транзакцию
COMMIT TRANSACTION
Т.к. это обмен данными, то нет смысла выполнять проверку на уникальность и, как следствие, использовать временную таблицу.
Подчиненные РС. Режим 3. Запись без замещения.
ОбъектРегистр.ОбменДанными.Загрузка = ЛОЖЬ;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);
Генерируемые запросы:
3.1. Открываем транзакцию
BEGIN TRANSACTION
3.2. Определяем последний существующий номер строки
SELECT TOP 1
T1._LineNo,
T1._Active
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
ORDER BY T1._LineNo DESC
3.3. Читаем 100 000 плюс одну запись регистра
SELECT TOP 100001
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304
FROM dbo._InfoRg301 T1
WHERE T1._RecorderRRef = @P1
только для управляемых блокировок (подробнее чуть выше, в п. 1.2)
3.4. Создаем временную таблицу
CREATE TABLE #tt1(
_RecorderRRef BINARY(16),
_LineNo NUMERIC(9, 0),
_Active BINARY(1),
_Fld302 NVARCHAR(10),
_Fld303 NVARCHAR(10),
_Fld304 NVARCHAR(10),
_Fld305 NVARCHAR(10),
_Fld306 NVARCHAR(10))
[этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД]
3.5. Заполняем временную таблицу нужными данными
INSERT INTO #tt1(_RecorderRRef,_LineNo,_Active,_Fld302,_Fld303,_Fld304,_Fld305,_Fld306) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
запросов выполняется для каждой строки записываемого набора движений
3.6. Проверка на уникальность
SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
INNER JOIN dbo._InfoRg301 T2
ON T1._Fld302 = T2._Fld302 AND T1._Fld303 = T2._Fld303 AND T1._Fld304 = T2._Fld304
для периодического регистра в условия соединения добавится соединение по полю _Period
3.7. Вставляем записи в таблицу регистра
INSERT INTO dbo._InfoRg301(_RecorderRRef, _LineNo, _Active, _Fld302, _Fld303, _Fld304, _Fld305, _Fld306) SELECT
T1._RecorderRRef,
T1._LineNo,
T1._Active,
T1._Fld302,
T1._Fld303,
T1._Fld304,
T1._Fld305,
T1._Fld306
FROM #tt1 T1 WITH(NOLOCK)
3.8. Фиксируем транзакцию
COMMIT TRANSACTION
3.9. Очищаем вспомогательную временную таблицу
TRUNCATE TABLE #tt1
Подчиненные РС. Запись без замещения с признаком обмена данных.
ОбъектРегистр.ОбменДанными.Загрузка = ИСТИНА;
// ...
ОбъектРегистр.Записать(ЛОЖЬ);
вынужден расстроить, так не работает:

Режим 4. Подчиненный РС с периодичностью по позиции регистратора.

Периодические подчиненные регистры рассматривать отдельно смысла нет — совсем чуть-чуть меняются запросы пунктов 1.6 и 3.6 в части соединения двух таблиц — добавляется условие соединения по полю _Period. Но периодичность по позиции регистратора изменяет логику т.к. уникальность набора записей, дэ-факто, определяется и значениями измерений и значением регистратора и делать проверку из 1.6 нет смысла.
Исполняемый код остается тем же, нас интересует режим записи с замещением (запись по умолчанию).
// (!)Режим загрузки при замещении не влияет на генерируемые платформой запросы
ОбъектРегистр.ОбменДанными.Загрузка = <ЛЮБОЙ>;
// ...
ОбъектРегистр.Записать(ИСТИНА);
Генерируемые запросы:
4.1. Открываем транзакцию
BEGIN TRANSACTION
4.2. Для установки управляемой блокировки удаляемых данных читаем 100 000 плюс одну запись регистра (подробно в п. 1.2)
SELECT TOP 100001
T1._Active,
T1._Fld283,
T1._Fld284,
T1._Fld285
FROM dbo._InfoRg282 T1
WHERE T1._RecorderRRef = @P1
4.3. Удаляем все записи по регистратору
DELETE FROM T1 FROM dbo._InfoRg282 T1 WHERE T1._RecorderRRef = @P1
4.4. Вставляем записи в таблицу регистра
INSERT INTO dbo._InfoRg282(_RecorderRRef,_LineNo,_Active,_Fld283,_Fld284,_Fld285,_Fld286,_Fld287) VALUES(@P1,@P2,@P3,@P4,@P5,@P6,@P7,@P8)
запросов выполняется для каждой строки записываемого набора движений
4.5. Фиксируем транзакцию
COMMIT TRANSACTION
Запись этого регистра с замещением
ОбъектРегистр.Записать(ЛОЖЬ);
будет ровно такой же, как в пункте 3. (Подчиненные РС. Режим 3. Запись без замещения.)
Разбираемся в нюансах. Пример: у вас есть документ с табличной частью из 50 000 строк и при проведении вся таб часть помещается в подчиненный регистр сведений. После перехода с 8.2 на 8.3 этот документ будет дольше перепроводиться за счет того, что платформа будет читать все его старые движения (запрос «..SELECT TOP 100001..»). В то же время, перепроведение этого документа в 8.2 хоть и будет быстрее, но вызовет эскалацию управляемой блокировки на весь регистр и никто другой в это время не сможет его (регистр) изменять. В 8.3 эскалации не произойдет и можно параллельно перепроводить другие документы, изменяющие данные регистра. Аналогичное сравнение и с режимом блокировок — в управляемом режиме (на платформе 8.3) документ будет дольше перепроводиться, но будет возможна многопользовательская работа с этим регистром, а в автоматическом режиме блокировок перепроводиться док будет быстрее, но работать сможет только один пользователь из-за эскалаций блокировок уже на уровне СУБД.
Для этого примера интересным решением будет использовать независимый регистр сведений с индексированным реквизитом ДокументДвижение, используя его как аналог Регистратора. В этом случае можно будет получить профит при записи регистра.
Тест 3. Регистры сведений с итогами.
В 8.3 появилась возможность создать таблицу итогов для периодического регистра, максимально это две таблицы — итоги для среза первых и среза последних. Разработчик сам решает нужны ли ему итоги и какие. По сути, таблица итогов для одной комбинации значений измерений содержит только одну запись (либо самую первую либо самую последнюю), значительно ускоряя получение среза запросом. Но какой ценой нам обходится поддержание этих данных в актуальном состоянии? Для этого посмотрим трассы СУБД в момент записи регистра сведений.
Для экспериментов возьмем периодический независимый регистр с уже известной структурой и установим свойство «Разрешить итоги: срез последних»
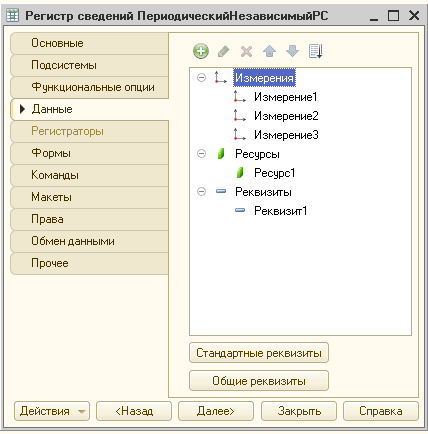

После реструктуризации, в SQL мы получим 3 таблицы:
_InfoRg276 — основная таблица, содержит все записи регистра.
_InfoRgSL296 — таблица итогов, в данном случае срез последних, для среза первых имя таблицы будет содержать «_InfoRgSF…». Очевидно, логика наименования от английских First и Last.
_InfoRgOpt297 — таблица настроек, хранит флаг отключены или нет итоги. Создается своя для каждой таблицы среза.
Исполняемый код:
ОбъектРегистр = РегистрыСведений.ПериодическийНезависимыйРС.СоздатьНаборЗаписей();
ОбъектРегистр.ОбменДанными.Загрузка = РежимЗагрузки;
СтруктураОтбора = Новый Структура();
СтруктураОтбора.Вставить("Период" , ТекущаяДата());
СтруктураОтбора.Вставить("Измерение1", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение2", Новый УникальныйИдентификатор);
СтруктураОтбора.Вставить("Измерение3", Новый УникальныйИдентификатор);
ОбъектРегистр.Отбор.Период.Установить(СтруктураОтбора.Период);
ОбъектРегистр.Отбор.Измерение1.Установить(СтруктураОтбора.Измерение1);
ОбъектРегистр.Отбор.Измерение2.Установить(СтруктураОтбора.Измерение2);
ОбъектРегистр.Отбор.Измерение3.Установить(СтруктураОтбора.Измерение3);
ЗаполнитьЗначенияСвойств(ОбъектРегистр.Добавить(), СтруктураОтбора);
ОбъектРегистр.Записать(Замещать);
Периодические регистры с таблицей итогов. Режим 1. Запись с замещением.
// (!)при записи с замещением режим загрузки не влияет на генерируемые платформой запросы
ОбъектРегистр.ОбменДанными.Загрузка = <ЛЮБОЙ>;
// ...
ОбъектРегистр.Записать(ИСТИНА);
Генерируемые запросы:
1.1. Открываем транзакцию
BEGIN TRANSACTION
1.2. Читаем настройки регистра.
SELECT T1._SliceUsing FROM dbo._InfoRgOpt297 T1
определяем отключены итоги или нет
1.3. Создаем временную таблицу для сохранения текущих итогов
CREATE TABLE #tt1(
_Period DATETIME,
_Fld277 NVARCHAR(10),
_Fld278 NVARCHAR(10),
_Fld279 NVARCHAR(10),
_Fld280 NVARCHAR(10),
_Fld281 NVARCHAR(10))
[этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД]
1.4. Сохраняем данные из таблицы итогов
INSERT INTO #tt1 WITH(TABLOCK)(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T1._Period,
T1._Fld277,
T1._Fld278,
T1._Fld279,
T1._Fld280,
T1._Fld281
FROM dbo._InfoRgSL296 T1
INNER JOIN dbo._InfoRg276 T2
ON T2._Fld277 = T1._Fld277 AND T2._Fld278 = T1._Fld278 AND T2._Fld279 = T1._Fld279
WHERE T2._Period = @P1 AND T2._Fld277 = @P2 AND T2._Fld278 = @P3 AND T2._Fld279 = @P4
состав условия WHERE зависит от того, какие отборы установлены в записываемом наборе
1.4а. Если запрос выше не пустой, то выполняется удаление считанных данных
DELETE FROM T1
FROM dbo._InfoRgSL296T1
INNER JOIN dbo._InfoRg276T2
ON T2._Fld277=T1._Fld277 AND T2._Fld278=T1._Fld278 AND T2._Fld279=T1._Fld279
WHERE
(T2._Period=@P1 AND
T2._Fld277=@P2 AND
T2._Fld278=@P3 AND
T2._Fld279=@P4)
AND(T2._Fld277=T1._Fld277 AND
T2._Fld278=T1._Fld278 AND
T2._Fld279=T1._Fld279)
состав условия WHERE в первых скобках зависит от того, какие отборы установлены в записываемом наборе
Условие во вторых скобках выглядит избыточным т.к. оно дублирует условие внутреннего соединения таблиц.
1.5. Удаляем старые записи в регистре
DELETE FROM T1 FROM dbo._InfoRg276 T1 WHERE T1._Period = @P1 AND T1._Fld277 = @P2 AND T1._Fld278 = @P3 AND T1._Fld279 = @P4
состав условия WHERE зависит от того, какие отборы установлены в записываемом наборе
1.6. Создаем временную таблицу для записи данных в регистр
CREATE TABLE #tt2(
_Period DATETIME,
_Fld277 NVARCHAR(10),
_Fld278 NVARCHAR(10),
_Fld279 NVARCHAR(10),
_Fld280 NVARCHAR(10),
_Fld281 NVARCHAR(10))
[этого запроса вы можете не увидеть в трассе т.к. временные таблицы однотипной структуры «кэшируются» в рамках одного и того же соединения с СУБД]
1.7. Добавляем данные во вспомогательную таблицу
INSERT INTO #tt2(_Period,_Fld277,_Fld278,_Fld279,_Fld280,_Fld281) VALUES(@P1,@P2,@P3,@P4,@P5,@P6)
таких запросов будет столько, сколько строк в записываемом наборе
1.8. Вставляем данные в регистр из вспомогательной таблицы
INSERT INTO dbo._InfoRg276(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T1._Period,
T1._Fld277,
T1._Fld278,
T1._Fld279,
T1._Fld280,
T1._Fld281
FROM #tt2 T1 WITH(NOLOCK)
1.9. Обновляем существующие данные в таблице итогов
UPDATE T6 SET _Period = T1.Period_, _Fld280 = T1.Fld280_, _Fld281 = T1.Fld281_
FROM
(SELECT
T5._Period AS Period_,
T5._Fld277 AS Fld277_,
T5._Fld278 AS Fld278_,
T5._Fld279 AS Fld279_,
T5._Fld280 AS Fld280_,
T5._Fld281 AS Fld281_
FROM
(SELECT
T3._Fld277 AS Fld277_,
T3._Fld278 AS Fld278_,
T3._Fld279 AS Fld279_,
MAX(T3._Period) AS MINMAX_PERIOD_
FROM dbo._InfoRg276 T3
INNER JOIN #tt2 T4 WITH(NOLOCK)
ON T3._Fld277 = T4._Fld277 AND T3._Fld278 = T4._Fld278 AND T3._Fld279 = T4._Fld279
GROUP BY
T3._Fld277,
T3._Fld278,
T3._Fld279) T2
LEFT OUTER JOIN dbo._InfoRg276 T5
ON T5._Fld277 = T2.Fld277_ AND T5._Fld278 = T2.Fld278_ AND T5._Fld279 = T2.Fld279_ AND T5._Period = T2.MINMAX_PERIOD_) T1
INNER JOIN dbo._InfoRgSL296 T6
ON T6._Fld277 = T1.Fld277_ AND T6._Fld278 = T1.Fld278_ AND T6._Fld279 = T1.Fld279_
WHERE T6._Period < T1.Period_
в запросе вычисляется срез (в данном случае срез последних) и если период нового среза больше периода в таблице итогов, то обновляем значения периода, ресурсов и реквизитов.
Практический пример — добавили свежий курс валюты, соответственно этот запрос обновит значение период, курс и кратность в таблице среза.
1.10. Вставляем в таблицу среза те строки, по которым ранее не было итогов.
INSERT INTO dbo._InfoRgSL296(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T5._Period,
T5._Fld277,
T5._Fld278,
T5._Fld279,
T5._Fld280,
T5._Fld281
FROM
(SELECT
T2._Fld277 AS Fld277_,
T2._Fld278 AS Fld278_,
T2._Fld279 AS Fld279_,
MAX(T2._Period) AS MINMAX_PERIOD_
FROM dbo._InfoRg276 T2
INNER JOIN #tt2 T3 WITH(NOLOCK)
ON T2._Fld277 = T3._Fld277 AND T2._Fld278 = T3._Fld278 AND T2._Fld279 = T3._Fld279
WHERE
NOT(EXISTS
(SELECT
1.0
FROM dbo._InfoRgSL296 T4
WHERE
T3._Fld277 = T4._Fld277
AND T3._Fld278 = T4._Fld278
AND T3._Fld279 = T4._Fld279))
GROUP BY
T2._Fld277,
T2._Fld278,
T2._Fld279) T1
LEFT OUTER JOIN dbo._InfoRg276 T5
ON T5._Fld277 = T1.Fld277_ AND T5._Fld278 = T1.Fld278_ AND T5._Fld279 = T1.Fld279_ AND T5._Period = T1.MINMAX_PERIOD_
если итоги по этим измерениям уже есть, причем не зависимо от значения периода, то строки не добавляем.
Практический пример — для новой валюты добавили первую запись в регистр курсы валют.
1.11. Добавляем не достающие итоги, которые могут появиться при удалении данных.
INSERT INTO dbo._InfoRgSL296(_Period, _Fld277, _Fld278, _Fld279, _Fld280, _Fld281) SELECT
T4._Period,
T4._Fld277,
T4._Fld278,
T4._Fld279,
T4._Fld280,
T4._Fld281
FROM
(SELECT
T2._Fld277 AS Fld277_,
T2._Fld278 AS Fld278_,
T2._Fld279 AS Fld279_,
MAX(T2._Period) AS MINMAX_PERIOD_
FROM dbo._InfoRg276 T2
INNER JOIN #tt1 T3 WITH(NOLOCK)
ON T3._Fld277 = T2._Fld277 AND T3._Fld278 = T2._Fld278 AND T3._Fld279 = T2._Fld279
GROUP BY
T2._Fld277,
T2._Fld278,
T2._Fld279) T1
LEFT OUTER JOIN dbo._InfoRg276 T4
ON T4._Fld277 = T1.Fld277_ AND T4._Fld278 = T1.Fld278_ AND T4._Fld279 = T1.Fld279_ AND T4._Period = T1.MINMAX_PERIOD_
WHERE
NOT(EXISTS
(SELECT
1.0
FROM dbo._InfoRgSL296 T5
WHERE
T5._Fld277 = T4._Fld277
AND T5._Fld278 = T4._Fld278
AND T5._Fld279 = T4._Fld279
AND(T5._Period >= T4._Period)))
практический пример — удалили последнюю запись курса валюты. В этом случае актуальная запись среза удалится запросом 1.4а, в тоже время таблица #tt2 будет пуста и предыдущий запрос (п.1.10) итогов не добавит, поэтому выполняем отдельную вставку.
1.12. Очищаем вспомогательную таблицу
TRUNCATE TABLE #tt1
1.13. Фиксируем транзакцию
COMMIT TRANSACTION
1.14. Очищаем вспомогательную таблицу
TRUNCATE TABLE #tt2
Для таблицы итогов среза первых выполняются запросы, похожие на 1.3, 1.4, 1.4а и 1.9 — 1.12, отличия только в том, что вместо MAX(T…_Period) будет MIN(T…_Period), а в 1.9 и 1.11 инвертируются условия больше-меньше для поля _Period. Приводить их не стану, думаю логика процесса понятна.
Периодические регистры с таблицей итогов. Режим 2. Запись без замещения.
ОбъектРегистр.Записать(ЛОЖЬ);
В полной трассе нет ничего нового, логика аналогична записи без замещения независимого регистра, плюс добавляются запросы по расчету таблицы итогов из трассы выше, это 1.9 и 1.10.
Подчиненные регистры с таблицей итогов.
При исследовании была найдена ошибка записи подчиненных регистров с итогами. Они просто не записываются, причем не в 8.2, ни в 8.3. Появляются такие ошибки:
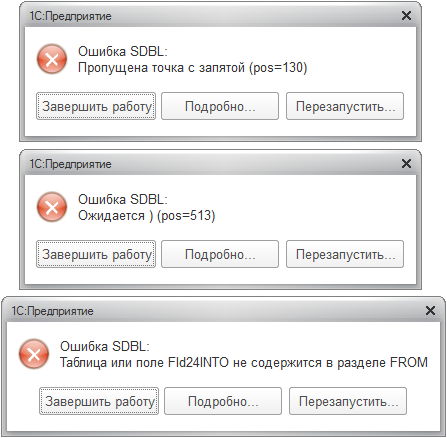
Ошибка зарегистрирована в 1С (клик):

Еще одна полезность данного исследования. Статью обещаю дополнить, как выйдет релиз с исправлением.
Выводы по регистрам с итогами. Начну с отличий от регистров накопления. В таблице итогов регистров сведений, по комбинации значений измерений, всегда хранится только одна — самая актуальная запись. В регистрах накопления итоги хранятся помесячно + текущие итоги. Таким образом, таблица среза будет меньше таблицы остатков, но зато таблицу остатков можно использовать при получении данных за прошлые периоды, а использовать таблицу среза для получения, например, актуального курса валюты на начало прошлого месяца уже не получится.
Второй и очевидный момент — поддержание таблицы среза в актуальном состоянии штука не бесплатная и стоит осознавать, что поток запросов увеличится. Сами по себе запросы потребляют мало ресурсов и выполняются быстро, но количество рано или поздно переходит в качество. Поэтому, если ваш документ записывает с десяток регистров сведений и у каждого из них вы включите обе таблицы итогов, то закономерно ожидать увеличения общего времени проведения документа. Если таких документов проводится много, либо большим числом пользователей, то есть риск заметного увеличения утилизации процессора и на сервере СУБД и на сервере 1С.
3. Как работает СрезПоследних (СрезПервых) в запросе
Чаще всего, когда создается периодический регистр сведений, подразумевается, что получать из него мы будем не все записи, а только одну — самую актуальную. Для этого используется конструкция СрезПоследних, реже — СрезПервых.
Итак, возьмем из примера выше уже известный периодический, независимый регистр с периодичностью «В пределах секунды» и разрешёнными итогами для среза последних.
Исполняемый код:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ПериодическийНезависимыйРССрезПоследних.Измерение1,
| ПериодическийНезависимыйРССрезПоследних.Измерение2,
| ПериодическийНезависимыйРССрезПоследних.Измерение3,
| ПериодическийНезависимыйРССрезПоследних.Ресурс1
|ИЗ
| РегистрСведений.ПериодическийНезависимыйРС.СрезПоследних(
| &ТекущаяДата,
| Измерение1 = ""А""
| И Измерение2 = ""Б""
| И Измерение3 = ""В"") КАК ПериодическийНезависимыйРССрезПоследних";
Запрос.УстановитьПараметр("ТекущаяДата", ТекущаяДата());
Запрос.Выполнить();
и посмотрим какой на самом деле формируется запрос в СУБД:
SELECT
T1.Fld277_,
T1.Fld278_,
T1.Fld279_,
T1.Fld280_
FROM
(SELECT
T4._Fld277 AS Fld277_,
T4._Fld278 AS Fld278_,
T4._Fld279 AS Fld279_,
T4._Fld280 AS Fld280_
FROM
(SELECT
T3._Fld277 AS Fld277_,
T3._Fld278 AS Fld278_,
T3._Fld279 AS Fld279_,
MAX(T3._Period) AS MAXPERIOD_
FROM dbo._InfoRg276 T3
WHERE T3._Period <= @P1 AND((((T3._Fld277 = @P2) AND(T3._Fld278 = @P3)) AND(T3._Fld279 = @P4)))
GROUP BY
T3._Fld277,
T3._Fld278,
T3._Fld279
) T2
INNER JOIN dbo._InfoRg276 T4
ON T2.Fld277_ = T4._Fld277
AND T2.Fld278_ = T4._Fld278
AND T2.Fld279_ = T4._Fld279
AND T2.MAXPERIOD_ = T4._Period
) T1
Запрос использует таблицу _InfoRg276 — это непосредственно наш регистр сведений ПериодическийНезависимыйРС. Вопрос «Где наша таблица итогов» оставим на вкусное, а пока давайте разберемся с этой конструкцией т.к. именно она будет использоваться чаще всего. А в 8.2 без вариантов — только так и работает.
Так как в запросе участвует одна таблица — непосредственно наш регистр, то логику запроса СУБД можно воспроизвести в запросе 1С.
Аналог конструкции СрезПоследних() на языке 1С для регистра с периодичность НЕ равной «По позиции регистратора»:
ВЫБРАТЬ
Т1.Измерение1,
Т1.Измерение2,
Т1.Измерение3,
Т1.Ресурс1
ИЗ
(ВЫБРАТЬ
Т4.Измерение1 КАК Измерение1,
Т4.Измерение2 КАК Измерение2,
Т4.Измерение3 КАК Измерение3,
Т4.Ресурс1 КАК Ресурс1
ИЗ
(ВЫБРАТЬ
Т3.Измерение1 КАК Измерение1,
Т3.Измерение2 КАК Измерение2,
Т3.Измерение3 КАК Измерение3,
МАКСИМУМ(Т3.Период) КАК MAXPERIOD_
ИЗ
РегистрСведений.ПериодическийНезависимыйРС КАК Т3
ГДЕ
Т3.Период <= &ТекущаяДата
И Т3.Измерение1 = «А»
И Т3.Измерение2 = «Б»
И Т3.Измерение3 = «В»
СГРУППИРОВАТЬ ПО
Т3.Измерение1,
Т3.Измерение2,
Т3.Измерение3) КАК Т2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийНезависимыйРС КАК Т4
ПО Т2.Измерение1 = Т4.Измерение1
И Т2.Измерение2 = Т4.Измерение2
И Т2.Измерение3 = Т4.Измерение3
И Т2.MAXPERIOD_ = Т4.Период) КАК Т1
Повторюсь, это абсолютно тот же запрос, что выполнился в СУБД, более того, он полностью рабочий и будет возвращать идентичный результат. Тут отчетливо видна логика, по которой делается «срез» и то, что запрос имеет два уровня вложенности.
Аналог конструкции СрезПоследних() на языке 1С для регистра с периодичность «По позиции регистратора»:
ВЫБРАТЬ
T1.Измерение1,
T1.Измерение2,
T1.Измерение3,
T1.Ресурс1
ИЗ
(ВЫБРАТЬ
T6.Измерение1 КАК Измерение1,
T6.Измерение2 КАК Измерение2,
T6.Измерение3 КАК Измерение3,
T6.Ресурс1 КАК Ресурс1
ИЗ
(ВЫБРАТЬ
T3.Измерение1 КАК Измерение1,
T3.Измерение2 КАК Измерение2,
T3.Измерение3 КАК Измерение3,
T3.MAXPERIOD_ КАК MAXPERIOD_,
МАКСИМУМ(T5.Регистратор) КАК MAXRECORDERRRef
ИЗ
(ВЫБРАТЬ
T4.Измерение1 КАК Измерение1,
T4.Измерение2 КАК Измерение2,
T4.Измерение3 КАК Измерение3,
МАКСИМУМ(T4.Период) КАК MAXPERIOD_
ИЗ
РегистрСведений.ПериодическийПоПозицииРегистратораРС КАК T4
ГДЕ
T4.Период <= &ТекущаяДата
И T4.Измерение1 = «А»
И T4.Измерение2 = «Б»
И T4.Измерение3 = «В»
СГРУППИРОВАТЬ ПО
T4.Измерение1,
T4.Измерение2,
T4.Измерение3) КАК T3
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийПоПозицииРегистратораРС КАК T5
ПО T3.Измерение1 = T5.Измерение1
И T3.Измерение2 = T5.Измерение2
И T3.Измерение3 = T5.Измерение3
И T3.MAXPERIOD_ = T5.Период
ГДЕ
T5.Измерение1 = «А»
И T5.Измерение2 = «Б»
И T5.Измерение3 = «В»
СГРУППИРОВАТЬ ПО
T3.Измерение1,
T3.Измерение2,
T3.Измерение3,
T3.MAXPERIOD_) КАК T2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийПоПозицииРегистратораРС КАК T6
ПО T2.Измерение1 = T6.Измерение1
И T2.Измерение2 = T6.Измерение2
И T2.Измерение3 = T6.Измерение3
И T2.MAXPERIOD_ = T6.Период
И T2.MAXRECORDERRRef = T6.Регистратор) КАК T1
Периодичность по позиции регистратора подразумевает, что в одну и ту же секунду может быть несколько записей с одинаковым значением измерений, поэтому одной группировки с расчетом максимального периода не достаточно, необходимо сделать еще одну, вычисляя максимальный регистратор. Запрос имеет уже 3 уровня вложенности и является более сложным для оптимизатора СУБД, как следствие, больше рисков получить не оптимальный план запроса.
Давайте рассмотрим самую частую ошибку при работе с виртуальными таблицами — перенесем фильтры в условие ГДЕ:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ПериодическийНезависимыйРССрезПоследних.Измерение1,
| ПериодическийНезависимыйРССрезПоследних.Измерение2,
| ПериодическийНезависимыйРССрезПоследних.Измерение3,
| ПериодическийНезависимыйРССрезПоследних.Ресурс1
|ИЗ
| РегистрСведений.ПериодическийНезависимыйРС.СрезПоследних(&ТекущаяДата, ) КАК ПериодическийНезависимыйРССрезПоследних
|ГДЕ
//!!! это ошибка !!! отборы по измерениям необходимо делать в виртуальной таблице
| ПериодическийНезависимыйРССрезПоследних.Измерение1 = ""А""
| И ПериодическийНезависимыйРССрезПоследних.Измерение2 = ""Б""
| И ПериодическийНезависимыйРССрезПоследних.Измерение3 = ""В""";
Запрос.УстановитьПараметр("ТекущаяДата", ТекущаяДата());
Запрос.Выполнить();
Аналог данного запроса будет выглядеть так:
ВЫБРАТЬ
Т1.Измерение1,
Т1.Измерение2,
Т1.Измерение3,
Т1.Ресурс1
ИЗ
(ВЫБРАТЬ
Т4.Измерение1 КАК Измерение1,
Т4.Измерение2 КАК Измерение2,
Т4.Измерение3 КАК Измерение3,
Т4.Ресурс1 КАК Ресурс1
ИЗ
(ВЫБРАТЬ
Т3.Измерение1 КАК Измерение1,
Т3.Измерение2 КАК Измерение2,
Т3.Измерение3 КАК Измерение3,
МАКСИМУМ(Т3.Период) КАК MAXPERIOD_
ИЗ
РегистрСведений.ПериодическийНезависимыйРС КАК Т3
ГДЕ
Т3.Период <= &ТекущаяДата
СГРУППИРОВАТЬ ПО
Т3.Измерение1,
Т3.Измерение2,
Т3.Измерение3) КАК Т2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.ПериодическийНезависимыйРС КАК Т4
ПО Т2.Измерение1 = Т4.Измерение1
И Т2.Измерение2 = Т4.Измерение2
И Т2.Измерение3 = Т4.Измерение3
И Т2.MAXPERIOD_ = Т4.Период) КАК Т1
ГДЕ
Т1.Измерение1 = «А»
И Т1.Измерение2 = «Б»
И Т1.Измерение3 = «В»
т.е. в отличие от предыдущего варианта мы сначала выбираем ВСЕ записи регистра с периодом меньше указанной даты, группируем их вычисляя последний период, соединяем с таблицей для получения значений ресурсов и только после этого фильтруем по измерениям. Как результат — мы читаем значительно больше данных, чем требуется.
Справедливости ради стоит отметить, что продвинутые СУБД, в частности MS SQL 2012 и 2014 (на 2005 — 2008 не тестил, но думаю поведение аналогичное) в обоих случаях построят одинаковый план запроса и разницу в скорости выполнения вы не заметите. Но файловая база так не умеет, она будет действовать строго по инструкции — написано выбрать все записи, значит надо выбрать все. И нет, это не значит, что если база на SQL, то можно косячить))
На этом же примере хочу показать влияние структуры индексов на план запроса.
Сравним два плана однотипного запроса, выполненного в 8.2 и в 8.3 (СУБД: SQL 2014), исполняемый код тот же (разумеется рассматриваем вариант без ошибки). Напомню, что для 8.2 кластерным будет индекс [Период + Измерение1 + Измерение2 + Измерение3], а в 8.3: [Измерение1 + Измерение2 + Измерение3 + Период].
План запроса для 8.2:
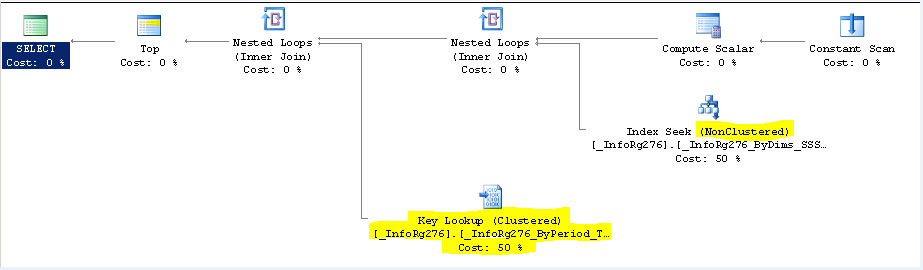
тот же запрос для тех же данных но в 8.3:
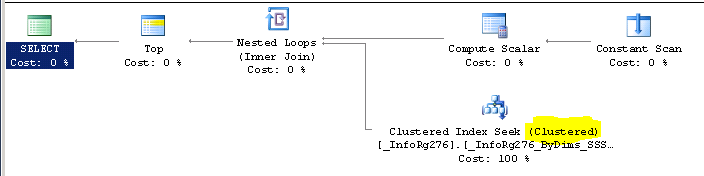
Почему в 8.2 выполняется больше операций? Если рассмотреть условие по периоду «… Т3.Период <= &ТекущаяДата …», то становится понятно, что из-за оператора «меньше или равно» эффективно использовать индекс [Период + Измерение1 + Измерение2 + Измерение3] не получится — под это условие могут попасть вообще все записи регистра, каждую из которых потом придется проверить на соответствие фильтрам по измерениям. Поэтому СУБД выбирает индекс [Измерение1 + Измерение2 + Измерение3 + Период], но т.к. в 8.2 он не кластерный то он не содержит значения ресурсов и реквизитов регистра. Вот за этими значениям и приходится «лезть» в таблицу (читай в кластерный индекс), на плане запросов это операция Key Lookup. Результат — количество прочитанных данных для 8.3 может быть в половину меньше, чем в 8.2.
Давайте вернемся к вопросу, зачем мы делали таблицу итогов, если запрос все равно её не использует, как же так…
Как уже говорил выше, когда разбирались в отличиях итогов регистра накопления и регистра сведений, таблица среза всегда хранит только одну — самую актуальную запись среза. Поэтому, когда 1С «видит» запрос среза на какую то дату /..СрезПоследних(&ТекущаяДата, …) /, то она не использует итоги т.к. не может гарантировать, что в них будет находиться актуальный для этой даты срез. Таблица итогов будет использована только если нужен самый-самый актуальный срез, т.е. если в виртуальной таблице не указан параметр периода:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ПериодическийНезависимыйРССрезПоследних.Измерение1,
| ПериодическийНезависимыйРССрезПоследних.Измерение2,
| ПериодическийНезависимыйРССрезПоследних.Измерение3,
| ПериодическийНезависимыйРССрезПоследних.Ресурс1
|ИЗ
| РегистрСведений.ПериодическийНезависимыйРС.СрезПоследних(
| ,
| Измерение1 = ""А""
| И Измерение2 = ""Б""
| И Измерение3 = ""В"") КАК ПериодическийНезависимыйРССрезПоследних";
Запрос.Выполнить();
в этом случае в СУБД увидим такой запрос:
SELECT
T1.Fld277_,
T1.Fld278_,
T1.Fld279_,
T1.Fld280_
FROM
(SELECT
T2._Fld277 AS Fld277_,
T2._Fld278 AS Fld278_,
T2._Fld279 AS Fld279_,
T2._Fld280 AS Fld280_
FROM dbo._InfoRgSL296 T2
WHERE ((((T2._Fld277 = @P1) AND(T2._Fld278 = @P2)) AND(T2._Fld279 = @P3)))
) T1
Бинго! Вот она, наша таблица итогов — _InfoRgSL296. Видим, что запрос стал гораздо меньше и проще. И его можно сделать еще более эффективным, если индекс таблицы итогов станет кластерным. Будем ждать от 1С этой оптимизации.
Рассмотрим ситуацию, когда число записей в самом регистре очень близко к числу записей в таблице среза. Например, данные в вашем периодическом регистре меняются очень редко и в 90% случаев он содержит только одну запись для уникальных значений измерений, а в остальных 10%: 2-3 записи. В этом случае использование итогов лишено смысла т.к. теряется основной профит — нет сокращения объема читаемых данных.
- Простая конструкция СрезПоследних может легко превратиться в достаточно сложный запрос с двумя, а то и с тремя уровнями вложенности. Это необходимо иметь в виду, особенно при соединении срезов с другими таблицами и вложенными запросами.
- Включение итогов по срезам поможет оптимизировать только те запросы, где срез делается без указания даты /..СрезПоследних(, …)../, в противном случае — напрасные накладные расходы на поддержание актуальности таблиц итогов.
- Периодичность «По позиции регистратора» следует использовать осторожно из-за сложного запроса получения среза. Если согласно закладываемой логике два документа, в одну и ту же секунду, НЕ могут сделать запись с одинаковыми значениями измерений, то использование этой периодичности является избыточным.
Заключение.
Что планировал — рассказал. Надеюсь для вас работа с регистрами сведений станет более прозрачной и эффективной.
Пишите, чем еще можно дополнить исследование, какие моменты раскрыть более детально. Дополняйте статью комментариями о своем опыте и фишках.
Успехов!
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Фундаментальненько. Особенно порадовала картинка, как раз ХЗ сейчас слушаю. Сейчас почитаем…
Очень полезно. Спасибо. Оказывается грешил постоянными срезами последних с указанием даты. Кажется пора переписывать запросы ))
Видишь пост автора — плюсуй, не читая!
Очень хорошая статья, в закладки однозначно. Надеюсь, что автор не закончит на регистрах сведений и будет продолжать нас радовать подобными статьями и далее.
(2) ruizave, если в запрос передается «текущая дата», то да, пора переписывать)) Регистров накопления это, кстати, тоже касается…
(3) Evil Beaver, я рассчитываю, что читать все-таки будут 😉
Статья — алмаз!
Люблю такие фундаментальные статьи, когда все по одной теме собрано вместе и просится в закладки)
Темная лошадка — раскрыта!
Огромное спасибо. В закладки
Капитально. Многое, конечно, уже опубликовано в сети и есть в «Проф.разработке» или у Филиппова, но в целом — внушает. Спасибо)
Статья отличная!
Таблицы итогов регистров сведений в платформе можно было бы сделать по аналогии с регистрами накопления — Таблица текущих итогов (фактически она сейчас и реализована в платформе) и таблица ежемесячных итогов (срез последних/первых на каждый месяц). При выполнении запроса СрезПоследних(&Дата) опять же аналогично регистрам накопления можно было сделать дорасчет среза от ближайшего ежемесячного итога. Понятное дело, что это — в разы сложнее и объемнее доработка, но считаю что СрезПоследних(&Дата) достаточно часто встречается в прикладных решениях, чтобы эти затраты были оправданы. Самое сложное будет пересчитывать ежемесячные итоги при записи, но опять же большая часть логики будет реализована по аналогии с уже отлаженной для регистров накопления.
(11) tormozit, Лучше РН сделать, как сделали РС. Т.е. хранить только актуальные итоги.
(12) Так а сейчас что мешает оставить в РН только текущие итоги?
(13) genayo, Я что-то пропустил? В РН можно управлять итогами остатков?
(14) В 8.2 для остаточных регистров можно оставить только текущие итоги, правда не совсем штатными средствами, отредактировав служебные таблицы регистров в СУБД напрямую. Проверено, работает…
Сколько ж автор потратил времени на сей труд?
(16) genayo, Редактировать таблицы напрямую после каждого проведения?
(14) Можно, нужно просто не использовать итоги и не пересчитывать их — и их не будет, останутся только текущие итоги.
Параметры:
<Признак> (обязательный)
Тип: Булево.
Признак использования итогов.
Описание:
Устанавливает признак использования итогов. Если использование итогов отключено, то при записи набора записей регистра не будет производиться пересчет итогов, но при этом будут не доступны виртуальные таблицы расчета остатков и оборотов.
(18) gubanoff, Рука-лицо.
(17) Нет, в служебную таблицу регистра _AccumRgOpt в поле _Period записать дату из далекого прошлого, в поле _UseTotals Ложь, в поле _ActualPeriod 1
(11) tormozit, (12) mkalimulin, мое мнение (из опыта), какие итоги вести должно настраиваться разработчиком — задачи разные бывают. И, в идеале, таблиц итогов должно быть две — «ежемесячные» итоги и текущие итоги. Так проще будет выполнять регламентные операции (таблица «простых» итогов будет реже фрагментироваться).
Оставить в РН только текущие итоги достаточно просто, надо установить период рассчитанных итогов на дату, раньше которой в регистре нет движений, после этого пересчитать итоги.
>но опять же большая часть логики будет реализована по аналогии с уже отлаженной для регистров накопления
тут можно поспорить, т.к. для РН все проще — у них ресурсы только цифровые и в итогах нет реквизитов. Следовательно и «апдейтить» итоги проще — добавить или вычесть новое значение ресурса. В РС придется удалять все рассчитанные итоги и создавать заново и чем больше месяцев надо хранить срезы, тем больше будет накладных расходов. Да и профит от дорасчета (а это плюс UNION) будет далеко не всегда, при текущей структуре индексов в 8.3, СУБД достаточно эффективно рассчитывает «срез», если обратили внимание на скрины планов запросов — таблица регистра читается один раз, хотя в запросе есть JOIN.
(6) ну и читать обязательно, конечно ))
Условие виртуальной таблицы тоже не должно быть сложным, например, соединение виртуальной таблицы без условиия с временной с целью выбрать только записи, существующие во временной таблице, будет в большинстве случаев эффективнее, чем условие виртуальной таблицы ххх В (Выбрать из ВременнаяТаблица). MSSQL 2012 такие нюансы точно сам не понимает, а на 2014 не проверял — там другие проблемы с новым cardinarity estimation.
Планы показывать лень, поверьте на слово.
кстати о планах: фактические планы будут выглядеть на иллюстрациях гораздо нагляднее. А текстовые — еще нагляднее, только их мало кто читать умеет 🙂
(11) tormozit, бессмысленно. При расчете среза (т.е. результата на конкретный момент) регистра накопления имеют значение все его предыдущие записи. Для регистра сведений — только единственная запись — самая старшая предыдущая.
Добротно.
Пара нюансов:
Кстати, моё мнение: Регистры сведений — одна из самых костыльных структур в 1С, как это не странно. Если интересно могу обосновать с примерами.
(24) Не обязательно хранить в таблицах итогов регистров сведений значения ресурсов и реквизитов. Достаточно хранить только значение последнего/первого периода по каждому набору измерений.
(25) speshuric
Конечно интересно!
(25) speshuric,
Возможно и стоит поговорить, но это функционал, напрямую не связанный с регистрами.
С составными типами хорошо знаком, но, опять таки, это отдельная большая тема и понимание принципа работы с составными типами должно быть общим (не побоюсь этого слова — глобальным), хотя зародить зерно знаний на каком то примере можно, подумаю.
Кстати, в 8.3.8 структура индексов для составных типов сильно изменилась (), теперь все поля входят в один индекс. А уже в 8.3.6 (может и раньше, не замечал), фильтр вида <<…ГДЕ Реквизит_ВсеПримитивы_ЛюбаяСсылка = 10 >> преобразуется в запросе к такому условию:
Показать
т.ч. платформа постепенно вырастает из детских болячек (ну и есть повод обновить статью 😉 )
Согласен. Сначала подумать, проверить план запроса и подумать еще раз))
Точно, забыл! Спасибо, отличная тема для дополнения статьи.
(25) speshuric, (27) присоединяюсь к вопросу, очень интересно.
Мне казалось, что РС — это одна из самых простых и понятных структур.
С чтением вроде бы вообще все хорошо.
С индексами на все случаи не угодишь, когда период последний в индексе, это не во всех случаях лучше, да и физике не отвечает, в которой привычнее первым время действия называть.
С записью MERGE, наверное, не хватает.
Так что про «костыльность» было бы очень интересно узнать.
Таких горе-спецов как (20) гнать с работы за такое.
Своими корявыми ручонками лезут в таблички, а потом делают круглые глазки, типа это оно само, когда отчеты врать начинают.
Или когда ошибки после перепроведения появляются.
Насмотрелись на таких.
(36) speshuric,
В статье есть ответ, при использовании Записать(Истина) всегда выполняется удаление «старых» строк. Проблемы будут только для независимых РС в режиме строк, т.е. ОбменДанными.Загрузка = Истина и Записать(Ложь), но тут и режим специфичный, его бездумно применять нельзя.
Касаемо описанных кейсов использования РС, однозначно согласен, что возможностей «взрослых» СУБД в платформе не хватает.
Но сценарий 3 включают в себя несколько прикладных задач и решать их следовало бы отдельно, а суть проблемы как раз в том, что «1С-ник не задумываясь создаёт РС»(с) т.к. РС описанной архитектуры имеет смысл для задач «Какой текущий статус заказа N ?» и «Какой статус был у заказа N на дд.мм.гггг?». Задачи «какие заявки были не в конечном статусе на дату ДД.ММ.ГГГГ» и «Сколько заняла обработка заявок из статуса ЧешемЖёлуди до статуса ВаляемКоня» надо решать отдельно и да, скорее всего регистрами накопления.
Я не верю в универсальное назначение таблиц, точнее сказать не верю в их эффективность и оптимальность. Да, есть задачи, когда можно удачно заюзать один объект под разную логику, но чаще всего это выливается в экономию места на диске ценой бо’льших затрат CPU и RAM.
(37)
Конечно, я имел в виду и с Записать(Ложь). Засада в том, что пока индекс уникален хотя бы СУБД бдит за целостность. И потенциально разное поведение на разных СУБД. В общем меня эта штука напрягает.
LAST_VALUE — это не «возможности взрослых СУБД», а то, что включили в стандарт SQL2003. 13 уже лет как. Так что пора бы и в 1С начать запихивать (так и слышу Ага, вот прямо завтра, как с утра, зубы почистим, EXISTS в язык запросов добавим, баги починим и сразу же займемся)
На курсах, в книгах, в типовых статусы прямо учат делать на РС. Так что наш «средний 1Сник» неуиновен. РН тоже противное решение. Вот если интересно — реально попробуй сделать на 1С хорошее решение по этому кейсу на 10М заявок в год и 3 статуса (новый, в работе, закрыт). Каждая заявка закрывается случайно за 1-10 часов.
В любом случае спасибо за статью — не так часто уже что-то новое про 1С узнаётся, а тут целая революция в индексах.
(38) speshuric,
Интересно, каковы у тебя критерии «хорошего решения»? У нас реализована задача похожая на «Сколько заняла обработка заявок из статуса ЧешемЖёлуди до статуса ВаляемКоня» для документа количеством почти 20М в год и числом статусов 10-15. Сделано на РС, но то самое «время обработки» вычисляется сразу.
(40) speshuric, конкурс это клевая идея!
(40) speshuric,
на примере, что б не было вопросов:
Заявка1; 01.01.16 Статус = Новый
Заявка1; 02.01.16 Статус = ВРаботе
Заявка1; 10.01.16 Статус = Сделано
Заявка2; 01.01.16 Статус = Новый
Заявка2; 03.01.16 Статус = ВРаботе
Заявка2; 04.01.16 Статус = Сделано
Заявка3; 01.01.16 Статус = Новый
Заявка3; 04.01.16 Статус = ВРаботе
<Заявка3 так и не закрыта>
Т0 = 05.01.16, в выборку должны попасть и Заявка1 и Заявка3, так?
(43) только Заявка3, имхо
(44) user_2010, имхо это было бы слишком просто)) Честно говоря не вижу реальных задача, когда и Заявка1 и Заявка3 должны попадать в выборку, но часто заказчик просит «хочу видеть как было на дату N» и хоть ты тресни — делай.
(45) да, ошиблась, вы правы 1 и 3.
(46) user_2010, Корнет, вы женщина? )) По сабжу — классная статья, деллину привет. Может попинаете одноэсов, когда они научатся булькать в темпы?
(48) Allexe8.1,
Алексей, привет!
О чем речь?
(50) Извини, может не по адресу, конечно)
Говорю о том, чтобы из внешних источников (условно, ТЗ, стандартно — файлы) — можно было инсертить во временные таблицы не построчно (как оно происходит), а через bulk insert. Просто жалуюсь на самом деле)
(52) Allexe8.1, эт на партнерский форум надо, описать что хочешь и зачем конкретно надо. Помимо ответа «пожелание записано», есть шанс получить подсказку от сообщества, например «булькать» во внешние источники данных 😉
Извиняюсь, что долго не отвечаю.
(43) Конечно, 1 и 3
(49) Вы верно ухватили мысль, что стандартные индексы B-Tree не решают эту задачу без костылей. Полезные кейворды «interval tree», «spatial index» (второе в чистом виде обычно для геометрии/географии, но есть применения и для интервального поиска). К сожалению, на первый взгляд у меня есть сомнения, что ваша реализация сработает, посмотрю внимательнее, прокомментирую могу ошибаться.
(51) Вы нашли неплохое решение (фактически это фильтрованные по неконечным значениям итоги для регистров сведений). Сам я решал близким способом. Но в вашем варианте неочевидно решение для «среднее время по заявкам». Опять же — в ближайшее время посмотрю внимательнее.
(54) speshuric, поясню чуть-чуть свое решение:
Пусть начало и конец интервала представлены строковым представлением времени.
Если начало и конец укладываются в одну секунду, то интервал получает индекс — полное представление времени с секундами,
Иначе если начало и конец укладываются в десятку секунд, то интервал получает индекс в виде представления времени, где на месте единиц секунд — прочерк,
Иначе если начало и конец укладывается в минуту, то интервал получает индекс, где на месте секунд — два прочерка,
Иначе если … в десяток минут, то … на месте единиц минут и секунд — три прочерка,
…
Иначе если … в один год, то … на месте месяца, дня, часа, минут, секунд — прочерки
и так далее.
Для поиска интервалов конкретного состояния, включающих заданный момент, достаточно поискать его в интервалах секунд (будет полное совпадение), десятков секунд (будет совпадать при простановке прочерка на место единиц секунд), минут, десятков минут, часов и так далее. Хорошо бы еще LIKE тут было бы использовать, пока думаю над этим.
Наверное, понятно, что более аккуратным будет использовать не строковое, а двоичное представление моментов времени, как в (49).
В базе данных к таблице регистра сведений добавляется только один реквизит — индекс интервала, и поисковой индекс строится по состоянию и этому дополнительному реквизиту. Который меняется один раз при записи следующего состояния этой заявки. Этот индекс позволяет определить заявки, актуальные в заданный момент времени (точнее, существенно сузить область поиска), и далее уже решать стандартным образом все остальные задачи.
Решение из (51), как мне кажется, нарушает условие квадратичной зависимости объема. Так как если будет хотя бы один процент заявок, зависших не в конечном состоянии, то база будет расти как n * n / 100.
Если смотреть в сторону менее хитрых сложно-сочиненных решений, то я бы предложил посмотреть в сторону регистров накопления, где итоги — это уже готовый механизм отбора актуальных в моменте заявок (через остатки).
Например — один независимый непериодический регистр сведений для текущего статуса заявок. Измерение — заявка, ресурсы: состояние и момент его начала. И регистр накопления для истории. С измерениями: заявка, статус, ресурсом количество — число(1, 0). При смене статуса делается две записи: одна +1 в момент начала предыдущего статуса, вторая -1 в момент начала нового. Здесь не нужно никаких особых состояний, регламентных заданий. Период итогов выбирается исходя из статистики смены состояний (интересен расчет оптимума). Среднее тогда можно посчитать как в статье
(55) ildarovich,
Насчет роста базы, вы правы, там возможно не так все просто (зависимость n*ln(n) надо еще доказать), попробую позже дать более точную оценку (там все сложнее так как 1% заявок зависает дольше 30 дней но не висит бесконечно, процент зависших бесконечно или долее 30 непонятен и все зависит от времени, поэтому формула роста будет, думаю, несколько другого вида чем n*n/100)
По поводу регистров накопления, я их специально сразу исключил, так как по условию задачи понял что нельзя брать никакие регистры с регистратором.
Думаю, нужно уточнение, прав ли я что нельзя использовать регистры накопления?
(55) ildarovich, Я поддержу Вас. Действительно, подобная задача (при правильной постановке) оптимально решается регистром накопления
Объясню свое уточнение — при правильной постановке. К сожалению, случайное изменение статусов (типа могло быть в статусе «приостановлен», а могло и не быть) не позволяет нормально использовать механизм регистра остатков.
Т.е. при переходе в новый статус, предыдущий должен быть «определябельным» по новому статусу. Тогда механизм не нарушится.
Иначе может быть ситуация, когда задача завершается. Ее переводят в статус завершено, но «случайно» не провели перевод из статуса «новый» в «в работе».
Тогда в регистре остатков появляется запись — «новый» + «завершено», а при проведении случайно не проведенного документа либо -«Новый» + «в работе», что лучше, чем -«завершено» + «в работе».
В варианте строгого рабочего потока, даже если статес завки «новый» и ее завершают, то проводка будет -«в работе» + «Завершено». И по остаткам будет видно, что заявка находится одновременно в ситатусах новый и завершено, и даже «в работе», но со знаком минус. Что явно указывает на пропущенный этап.
(66) При вашем решении возможно более оптимальное решение.
Для Вашего п.2. достаточно при записи следующего статуса записать в документ, который его устанавливает время действия предыдущего статуса, не заводя регистра оборотов.
И тем более не выполняя регламентных заданий. Тогда
Срез остатков на дату начала даст те заявки, которые находились на указанный момент времени в начальном статусе.
Анализ движений между указанными датами найдет документы перехода в новый статус, по которым мы получим время.
Остались те заявки, которые до не завершились в установленный промежуток времени (не сменили статус)
По этим заявкам просматриваем ВСЮ историю с начала времен и ищем дату установки статуса. Думаю даже такое решение уже удовлетворяет выдвинутым критериям.
Т.е. достаточно одного регистра остатков.
А если так уж хочется ускорить определение текущего статуса, для этого можно так уж и быть завести периодический регистр сведений.
Тогда срез последних на заданную дату окончания периода даст ответ на вопрос, когда был установлен статус. (И опять таки обошлись без оборотного регистра)
(67) Ovrfox, идеологически это не верное решение т.к. обращаться в отчетах к документам — мувитон. Задачу остатков тож можно решить на документах, нет никаких проблем написать такой запрос.
Второй момент, использую таблицу агрегата, рассчитанную на каждый день, вы получите по статусу одну запись в сутки, т.е. объем читаемых данных будет не сравнимо меньшим.
З.Ы. пока вам отвечал, понял, что в оборотном регистре не хватает полей..
(66) корректировка решения 2 в том виде не считает среднее, необходимо в оборотный регистр добавить ресурс Количество, которое всегда заполняем единичкой и запрос получения среднего будет такой:
Показать
(40) speshuric, (66)
По поводу регистра накопления, так и остался открытым главный вопрос.
Исходя из условий задачи, я понял, что регистр накопления мы полностью исключаем ( в задаче есть косвенное указание, что нельзя использовать никакие регистраторы)
speshuric, прав ли я что нельзя никоим образом использовать регистры накопления по условию задачи?
Хотя для решения регистр накопления,конечно, оказался бы далеко не лишним что бы получить на любую дату остаток по статусам и заявкам использую итоги
(70) MaxMNSH, жесткого запрета нет, но используя регистр накопления сложно обеспечить условие:
>Размер БД должен расти не больше чем O(n*ln(n)). Уж точно не квадратично.
(54) speshuric,
Поясняю по поводу расчета среднего времени перхода м-ду Статус1 и Статус2, привожу пример реального запроса. (насчет общей оптимальности его отдельная тема, но первоначальные выборки во временный таблицы у нас ВСЕГДА ограничены по ДатаЗаписи и следовательно время его работы слабо зависит от общего объема БД)
ВЫБРАТЬ РАЗЛИЧНЫЕ
Регистр2.Заявка КАК Заявка,
Регистр2.ДатаУстановкиСтатуса КАК ДатаУстановкиСтатуса
ПОМЕСТИТЬ ВТСтатус1
ИЗ
Регистр2 КАК Регистр2
ГДЕ
Регистр2.ДатаЗаписи МЕЖДУ &НачПериодCУчетомNДней И &КонПериодCУчетомNДней
И Регистр2.Статус = &Статус1
И Регистр2.ДатаУстановкиСтатуса <= &ДатаКон
;
////////////////////////////////////////////////////////////
ВЫБРАТЬ РАЗЛИЧНЫЕ
Регистр2.Заявка КАК Заявка,
Регистр2.ДатаУстановкиСтатуса КАК ДатаУстановкиСтатуса
ПОМЕСТИТЬ ВТСтатус2
ИЗ
Регистр2 КАК Регистр2
ГДЕ
Регистр2.ДатаЗаписи МЕЖДУ &НачПериодCУчетомN И &КонПериодCУчетомN
И Регистр2.Статус = &Статус2
И Регистр2.ДатаУстановкиСтатуса МЕЖДУ &ДатаНач И &ДатаКон
;
////////////////////////////////////////////////////////////
ВЫБРАТЬ
СУММА(РАЗНОСТЬДАТ(ВТСтатус1.ДатаУстановкиСтатуса,
ЕСТЬNULL(ВТСтатус2.ДатаУстановкиСтатуса, &ДатаКон), СЕКУНДА))
/ КОЛИЧЕСТВО(ВТСтатус1.Заявка) КАК СреднееВремяПереходаСтатус1ВСтатус2
ИЗ
ВТСтатус1 КАК ВТСтатус1
ЛЕВОЕ СОЕДИНЕНИЕ ВТСтатус2 КАК ВТСтатус2
ПО ВТСтатус1.Заявка = ВТСтатус2.Заявка
(55) ildarovich,
Попробую, как и обещал, дать оценку роста более точно
берем 8640 заявок в день (каждые 10 секунда создается заявка)
берем 3 статуса
Берем 366 дней
берем 10 лет
берем настройку периода N дней = 31
8640*3*366*10 = 95 милионов, округлим до 100 млн
Далее считаем численно рост базы за 10 лет для самого плохого случая (когда 0.01 заявок висят в 2х неконечных статусах более 30 дней, самых плохой вариант висят бесконечно)
считаем сразу, опять самых плохой вариант что у нас на 0 Лет уже есть 100 млн заявок из которых 0.01 зависло более 31 дня на бесконечность (берем так потому что за 10 лет у нас их больше стать не может и если возьмем сразу 100млн то худшего варианта нет)
получаем наибольший рост объема за 10 лет как: n + n*0,01(процент)*2(статуса)*120(месяцев, т.е. каждый месяц количество записей добавляется из-за зависших)
подставляем 100млн + 100млн*0,01*2*120 = 100млн + 240млн = 340 млн (это самых плохой случай, реально будет всегда меньше)
теперь берем n*ln(n) для 10 лет, получим 100млн * ln(100млн) = приближенно 100млт * 18 = 1800 млн
т.е. на участке 10 лет мы ТОЧНО уложимся в зависимость n*ln(n) для регистр2
при тех же нач условиях если посчитать, это сохранится более 50 лет (для 50 лет худший вариант 6 500 млн записей, для n*ln(n) это 10 000млн записей), что рост будет меньше чем n*ln(n)
Далее уже может стать больше чем n*ln(n), но зависимость не квадратичная. А участок порядка 50 лет нам гарантирован, что мы уложимся в зависимость из условия задачи
При уменьшении Nдней конечно же рост будет увеличиваться пропорционально N и статистики перехода статусов для этого N
Полную формулу роста вывести тут не просто, поэтому ограничился здесь численным расчетом гарантированного периода для N = 31 дней
(69) (67) Можно просто добавить реквизит (не измерение) в регистр остатков и заполнять его, если не нравится в документе.
В том то и дело, что таком варинате вы получаете только одну запись на весь период, а не на каждый день, и такой вариант значительно менее нагружает систему.
А за необходимость регламентных заданий для заполнения я даже не считаю.
(71) Пока все решения без регистра остатков записывают больше записей. Я не уверен , что в регистре остатков к-во записей больше, чем ограничение.
n описывает к-во дней? Или к-во Заказов?
Если заказов, то все зависит от того, будет или нет неограниченное по дате состояние заказа. Если ВСЕ заказы закрываются меньше чем за 1 год, а заказов больше 1 миллиона, а периодичность остаткков 1 месяц, то условие выполняется с запасом.
(73) MaxMNSH, Вы посчитали только дополнительный рост регистра, а основной рост почему не учли?
(75) Ovrfox,
Это в случае, получения остатка одна запись? Например остаток на последнюю дату месяца? Плюс «анализ движений между датами» (ваши слова) и там тож не одна запись.
(78) Вы не правы, именно анализ движений между датами вернет одну запись. Проанализировать движения нужно будет по фильтру полученных по остаткам заказов
В варианте с регистром оборотов (если он даже рассчитывается ежедневно, что нонсенс) вам нужно отобрать за тот же период обороты, которые вам вернут не одну, столько записей, сколько дней длился переход между периодами.
И на всякий случая — я знаю что такое группировка, но это не означает, что записи не будут прочитаны.
Выигрыш во времени, возможно будет при условии, что все заказы выполняются более месяца и стандартные периоды запросов по пару лет. Тогда за счет предрассчитаннных итогов обороты будут быстрее.
И то не уверен.
(77) Ovrfox,
100 млн + 100млн*0,01*2*120
здесь первое слагаемое 100 млн и есть основной рост (если бы не было дублирующих записей регламентым заданием то регистр за 10 лет дорос бы до 100 млн записей)
другой вопрос что в моем решении у нас еще есть таблица обычного периодичесткого регистра = это еще + 100 млн и так же таблица где хранятся заявки для регламентного задания это еще 100*2 = 200млн максимум
т.е. в этом случае получим для 10 лет суммарно 640 млн записей в 3х таблицах с очень большим избытком от реальности.
я считал рост только регистра2 решения так как вопрос был по нему.
и кстати, условия выбрал с оч. большим избытком. реально рост будет прилично меньше (количественно, а качественно тенденция похожа)
но если добавить туда и саму таблицу заявок и обычный периодический регистр и таблицу регистрации заявок то все равно уложимся в гарантированный срок 50 лет при заданных нач условиях
(80) Ovrfox,
возможно сходу не вижу красоту задумки, можно пример запроса?
(82) Обычная выборка движений по регистру остатков
У нас уже известны заказы, зачит что типа
Выбор Заказ, регистратор, кводней(атрибут) из РегистрОстатков.НашРегистр где Период между &НачДат и &КонДат и заказ в (&мЗаказов) и статус = &КонСтатус
(82) Ovrfox, Извините, в запросе забыл указать условие по типу движения — только приход.
(84) Ovrfox, так там не будет «заказ в (&мЗаказов)», только период и статус… и для одного статуса в движениях будет явно не одна строка. В агрегах же, по задумке разработчиков, хранится свернутая информация в тех разрезах, которые мы сами указываем.
(87) цитирую
Выбор Заказ, регистратор, кводней(атрибут) из РегистрОстатков.НашРегистр где Период между &НачДат и &КонДат и заказ в (&мЗаказов) и статус = &КонСтатус
Известны заказы, потому что перед запросом движений мы уже получили остатки.
Будет ТОЛЬКО одна запись я предполагаю из того, что Один статус назначается только Один раз.
ОДНА запись для каждого ЗАКАЗА, а не всего.
В противоположность ОДНА запись для каждого ДНЯ действия Статуса.
(91) Ovrfox, Сколько будет заявок в статусе ВРаботе? Если совсем грубо прикинуть, то 8640*80%(это только те, что берут в работу в течении дня)=6912, период отчета обычно 5 дней т.е. 34560 движений. Цитирую вас:
Что бы агрегат для статуса «Новый» накопил такое число строк, надо что б заявки зависали на 94 года… Напомню, что это решение было вне конкурса т.к. имеет очевидные недостатки, но не те, за которые цепляетесь вы.
Вы бы оформили свое решение отдельно, с описанием архитектуры и примерами запросов, а то по кусочкам приходится восстанавливать картинку и пытаться понять как и что планируется считать.
(92) Для одной заявки надо просмотреть историю одной заявки, для которой ВНЕ ЗАВИСИМОСТИ от срока ее выполнения одна запись в промежутке запроса (или ни одной, тогда она еще не завершена)
В вашем предложении, насколько я понял, к-во записей для 1 заказа равно к-ву дней его перехода, в худшем случае это равно промежутку запроса , в лучшем 1 запись.
Умножим теперь это на к-во заявок и получим искомое. А именно, каждый день только 20 % заявок меняют свой статус, в остальных, 80 % случаев будет сделана повторная запись .
Это слишком много записей. Попробуйте оценить свое решение по к-ву записей в регистр. (во все регистры решения)
(96) Ovrfox, кхммм…
в агрегате измерение Заявка отключаем:
так сколько будет строк? Одна строка в сутки будет, не для каждого заказа одна строка, а реально одна строка.
P.S. а я все в толк не возьму о чем вообще тут можно спорить.
(97) цитирую ваше решение
Т.е. как я понимаю для КАЖДОЙ заявки вы КАЖДУЮ ночь увеличиваете время на сутки. Я так понял, что с помощью записи оборотов в соотвествующий регистр.
Но после ваших слов засомневался. Вы что, собирались увеличивать исходную запись? А как в этом случае отработать перепроведение документа, если потребуется? А как узнать — отработало ли регламентное задание? Или вдруг оно отработало дважды?
Поясните подробнее свое решение, какая именно структура оборотного регистра и какие именно записи вы собирались записывать при смене статуса и в регламентном задании.
А также ответьте на вопрос регламентное задание должно записать новые записи или откорректировать уже записанное ранее?
(98) Ovrfox
Время обработки корректируем изменяя исходную запись.
С перепроведением и прочим не вижу проблем, что то вроде
соответственно двойное выполнение не страшно. Отработало ли регламентное — совсем другая задача, достаточно легко решаемая.
(101) speshuric,
1. Что касается 0-вых остатков — да, они есть, но их относительно немного, особенно с учетом того, что 80% заявок завершается за 5 дней. Согласно моим подсчетам менее 1.3%
Т.е пересчитывать не нужно.
2. пересчет последовательности и хрупкость для определения предыдущего состояния — это именно мое замечание. И он обходится, если мы можем всегда ответить на вопрос, какое было предыдущее состояние без запроса к регистру. Как я и предлагал
3. Остается проблема изменений задним числом, которая работает, хоть и тяжко в варианте с регистром остатков.
Вопрос как эта проблема решается в других предложенных системах? Полным перебором истории? Разве это лучше , чем в варианте с регистром остатков?
Это лирика
А вообще с Вашим выбором решения я согласен. Оно самое компактное. (по кол-ву записей)
(102) Ovrfox,
чет мало насчитали…
Например, создали заявку, сделали запись «Приход» Статус=Новый, Заявка=№1. Через 30 минут заявку взяли в работу, т.е. добавляем запись «Расход» для Статус=Новый, Заявка=№1 и запись «Приход» Статус=ВРаботе, Заявка=№1. Еще через сутки заявку сделали, т.е. еще запись «Расход» для Статус=ВРаботе, Заявка=№1. Таким образом в итогах останутся две строки и обе с количеством 0. В сутки минимум будет появляться 80% от новых заявок, т.е. 6912 нулевых записей, плюс еще закрытые и заявки прошлых дней. Скорее всего не меньше 10 000 не нужных пустых строчек.
(101) speshuric,
Ок, с победителем определились! Кстати, обязательно ждем эталонного решения 😉
Хочу предложить еще один вариант, думал как решить задачу используя только одну таблицу и при этом достаточно оптимально с точки зрения получения данных. Это, есессно, крайность и при строгой трактовке требований задачка получается не решаемой, но тем интереснее был поиск решения.
Получилось следующее: независимый, непериодический регистр сведений с измерениями: Статус; ДатаСменыСтатуса; ДатаЗаписи; Заявка. Ресурсов и реквизитов нет. Отвечаю на вопрос «Почему не периодический?» – просто, что б получить более оптимальный индекс т.к. стандартными средствами получить индекс [Статус; ДатаСменыСтатуса; Период] проблематично.
Принцип записи: При изменении статус добавляем новую строку, в которой ДатаСменыСтатуса=01.01.3999, ДатаЗаписи=ТекущаяДата(). При этом, находим строку регистра с предыдущим статусом и обновляем у неё ДатаСменыСтатуса= ТекущаяДата(). Таким образом, если у записи ДатаСменыСтатуса=01.01.3999, то статус этой записи является текущим статусом заявки. Тексты запросов будут при этом такими:
Задачка 1:
Показать
это слабое место данного решения т.к. чем глубже в истории мы выбираем точку Т0, тем больше данных мы будем читать, но за «минимализмы» чем то приходится платить. Хотя если Т0 не залезает глубже недели-двух, то вариант вполне можно рассматривать как рабочий.
Задачка 2:
Показать
(103) 0-вые текущие не переносятся при пересчете остатков на следующий месяц
В 0-вых старых остануться только те записи, которые корректировались задним числом или при переходе через период расчитанных итогов.
Вот я только их и учитывал.
(104) Для попадания в ваш индекс запрос к задаче 1 нужно передалть примерно так
Показать
(106) Ovrfox, т.е. в моем варианте в индекс не попадет?
(107) Скорее всего не попадет. Можно попробовать отследить план в профайлере.
А вообще условия вида Парам в (Список) не попадают в индекс. Нужно делать внутренее соединение, чтобы пападать.
(108) Ovrfox, т.е. вы даже не проверили, но советы советуете? Понимаете, что вот кто то прочитает, так сказать «услышав звон и не поняв про что речь» и в дальнейшем будет постоянно ошибаться.
Антинаучно. Суть процесса одна — получить данные из таблицы с фильтрацией по нескольким значениям. Только в первом случае значения передаются списком параметров, во втором — таблицей.
(109) Дык если я прав, то в чем антинаучность?
В том , что я не расписал о том, что на самом деле виноват оптимизатор SQL? Что если запросы писать напрямую на SQL , то я точно не прав?
А какая разница, если для 1С выполняется то, что я сказал?
Кстати, речь шла о индексе, состоящем из более чем одного поля, в котором одно из полей используется в условии с «в».
(110) Ovrfox, я привел три плана запроса и во всех них используется тот же самый индекс (состоит из 4х полей). Запросы написаны не в SQL (что заметно в использовании конструкции exec sp_executesql), а просто отловлены в профайлере в момент выполнения в консоли запросов. Заскринить план в профайлере или поверите наслово, что он такой же?
Почему не научно, тож объяснил.
Нельзя давать такие советы, особенно на простых запросах как в (104). В оптимизации запросов вообще мало по истине универсальных советов и уж точно отказ от IN к ним не относится.
(111) Я правильно понял, что Вы утверждаете, что для составного индекса (В вашем примере он не составной, но замедления все равно нет) ВСЕГДА будет попадание в индекс, если часть условия на индекс находится в конструкции «В», а часть в простом условии на больше меньше?
Т.е. Вы не согласитесь со мной (к сожалению, я и не привожу конкретных ссылок, подтвержлдающих мои слова), что оптимизатор SQL в таком случае может ошибится и не использовать индекс. А для 100% попадания в индекс лучше использовать простые операторы странения.
Я советую Вам почитать форум MS и самостоятельно найти подтверждение моим словам и ли привести пример, когда мой совет может привести к плохому результату ( Вариант к тамоу же как и оператор «в» -не подходит, разве что вы докажете , что это будет в 100% случаев)
(112) Ovrfox, Олег, я всего лишь прошу аргументировать, а вместо этого получаю еще один совет. Попадание в индекс продемонстрировано.
У меня большая практика оптимизации и запросы, в которых отказывались от IN, так же встречались, но это было вызвано сложностью самого запроса (много условий и таблиц), иногда характером распределения данных, поэтому я б не рискнул давать такие рекомендации без анализа ситуации. Даже для одинакового запроса, но на различных данных, SQL может компилить разные планы.
Если вам известно об ошибках в SQL, желательно привести ссылки или описать проблемы подробнее, указав версию SQL и порядок воспроизведения.
(112) Ovrfox,
Вы зря спорите. Даже зная структуру и запрос нельзя наперед сказать, будет ли использован индекс. В этом смысле приведенный код
вполне имеет шансы задействовать индекс (Статус, ДатаСменыСтатуса), если ДатаСменыСтатуса не сильно древняя. MS SQL обычно вполне справляется и с вложенными запросами, и с IN, и с EXISTS, если, конечно, семантика одинаковая. Это сильно зависит от частотной статистики, работы cardinality estimator (который в 2014 поменяли, кажется), от parameter sniffing и еще от горы вещей. И соединение тут ни фига не панацея, а иногда даже яд. Мне вот прям десятки раз приходилось на конкретных примерах показывать, почему (в том конкретном случае) надо использовать вложенные запросы, «В» вместо соединения, «ИЛИ» вместо ОБЪЕДИНИТЬ ВСЕ, и условие ГДЕ вместо параметров виртуальных таблиц. То есть практически всё что рассказывал уважаемый К. Рупасов, только наоборот. Проблема лишь в том, что это рекомендации для конкретной ситуации.
В отношении «Поле В (&Парам1, &Парам2)» лично я бы пошёл именно по пути Sergey.Noskov — написал корректный семантиически запрос с «В», и лишь потом, если он ведёт себя не так, как ожидается — попробовал «оптимизировать»: через ОБЪЕДИНИТЬ ВСЕ или другими приемами.
(114) speshuric, Все, что я сказал — это дал рекомендацию, когда для условия в используется два значения и есть дополнительное условие по второй части индекса, то рекомендовал использовать условие на равенство и объединить все. Протому что в таком варианте записи запроса мы однозначно попадем в индекс, но даже если и условие «В» тоже попадет в индекс, то мы не проиграем в производительности.
Т.е. я рекомендовал решение, которое в некоторых случаях ускорит запрос, а в некоторых его НЕ ЗАМЕДЛИТ.
Что касается сложных запросов в условии «В», то я так же, по своему собственному опыту работы с 2005 и 2008 серверами, пришел к выводу, что часто условие «В» замедляет запрос, а полное соединение нет.
Уважаемый оспорил мой опыт и сказал. что он неверен, т.е. его использовать нельзя. Я просто попросил привести пример, когда нельзя использовать, т.е. когда он приведет к замедлению запроса. К сожалению, уважаемый даже не смог привести правильный пример, иллюстрирующий упомянутое мнение.
Поэтому голословными утверждениями занимается уважаемый Сергей, а я просто пытаюсь его успокоить, чтобы он не спорил по пустякам, особенно когда мои рекомендации работают, а он рекомендаций вообще не дает.
(114) speshuric, кстати, меня заинтересовал вариант, когда «объединить все» и условие равенства дает худший результат, чем условие вхождения в список.
До сих пор я был уверен, что это как минимум не хуже. Более того, я помню, что читал статью, где был описан один из способов оптимизации запросов внутри MS SQL. И там было сказано, что в некоторых случаях именно так и преобразовывается запрос . Т.е. Вы просите MS SQL использовать условие «В», оптимизатор думает и принимает решение использовать равенство и «объединить все».
(101) speshuric, Что же Вы призовой фонд зажали? А как же обещание выдать его MaxMNSH?
(117) Ovrfox, Это моя ошибка, отметил лучшим ответом комент speshuric’а. Исправимся.
(104)
Проводил эксперименты с выборкой половины из двух миллионов записей по условию «<» с не кластерным индексом. Оказалось, что MSSQL делает это меньше, чем за полсекунды. Так, что неделя — если за нее приходит порядка миллиона заявок, а если во всей базе заявок меньше миллиона (так в большинстве случаев), то беспокоится вообще не о чем — не нужно вообще ничего дополнительного придумывать (даже ДатаСменыСтатуса добавлять).
Из этого как будто бы следует, что серьезность проблемы (всей этой «интересной» задачи) оказалась сильно преувеличена. Рост времени выполнения запроса, с которым нужно бороться, проявляется (в MS SQL) в таблицах с многими миллионами записей. А много ли реальных практических задач с такими количествами записей в периодических регистрах сведений?
Это я к тому, что решение, которое я предложил в (49) и объяснял в (55) оказалось вполне рабочим, но вот досада — чтобы показать его преимущества на MSSQL приходится генерировать таблицы с многими миллионами записей.
(124) ildarovich,
Речь о «классическом» регистре сведений Период/Заявка/Статус?
(125) да, как будто при двух и меньше миллионах записей выбрать заявки с нужным статусом на конкретную дату из периодического регистра сведений с измерением — заявка и ресурсом статус — не проблема. Тесты как будто не должны замечать разницы времени выборки из 0,4; 0,8; 1,2; 1,6; 2,0 миллиона записей.
Это я так думаю по результатам своего эксперимента с таблицей Ключ, НачалоИнтервала, КонецИнтервала, Значение. Так вот,
работает даже на миллионе записей слишком быстро, чтобы что-то изобретать.
(126) ildarovich, не все так просто, если мы говорим про классический регистр, мы не можем ограничивать период слева т.к. не знаем дату первого события и для, того, что бы отфильтровать по статусу на дату, придется сначала сделать полный срез, что то вроде:
Выбор * из РегистрСведений.СтатусыЗаказов.СрезПоследних(&Т0,) как Т1 ГДЕ Т1.Статус в (&Статусы)
думаю очевидно, что этот запрос прочитаем все строки таблицы с периодом <= Т0.
В случае с <<..ГДЕ &ВыбранныйМоментВремени МЕЖДУ НачалоИнтервала И КонецИнтервала…>> ситуация другая, мы сразу ограничиваем читаемые строки и выбираем только те, где НачалоИнтервала>=&ВыбранныйМоментВремени. Если &ВыбранныйМоментВремени каждый раз будет равноудаленной от текущей даты, то число попадаемых в условие строк почти всегда будет одинаковым, а в первом варианте — чем дольше живем, тем больше чтений.
(127) я это хорошо понимаю, даже приходилось применять решение типа (104). Оно мне кажется довольно симпатичным: чем дальше по времени мы хотим заглянуть в историю, тем больше времени должны потратить: своего рода мягкий вариант архивации.
Я хотел донести другую мысль, но сначала ответьте:
думаю очевидно, что этот запрос прочитаем все строки таблицы с периодом <= Т0
— сколько примерно времени по вашему придется потратить, чтобы прочитать
, если в таблице целых ДВА МИЛЛИОНА записей, а момент Т0 в середине истории. Какое число приходит в голову, если не проводить измерений? Сколько секунд хотя бы примерно? Насколько пугающим является это число? И стоит ли бороться за уменьшение этого времени?
PS: Кстати, чтобы не ломать структуру обычного регистра в вашем предложении, можно использовать такой ход — назначить каждому статусу свой столетний (например) диапазон, сделать ДатаСменыСтатуса реквизитом (индексированным), задавать его для каждого статуса в своем диапазоне. Тогда в одном поле фактически будут объединены поля Статус и ДатаСменыСтатуса и будет работать штатный индекс реквизита в проверке Статус = Х И ДатаСменыСтатуса < Т0.
(128) ildarovich, Идея же, глобально, не в том, как быстро выполнится запрос, а в том, как эффективно он тратит ресурсы. Даже секунда это может бы очень много, например, если этот запрос выполнит 100 юзеров, то потребуется почти 100 секунд процессорного времени и на 80ти ядерной машине вы получите нагрузку на CPU в 100%, что приведет к заметной деградации производительности всех пользователей. Второй важный момент — архитектура должна обеспечивать скорость работы не зависимо от продолжительности ведения учета. Из своей практики могу сказать, что рост может быть экспоненциальным и 2млн строк к концу года легко превращаются в 100млн.
(122) speshuric, заждались уже))
В защиту своего решения из (49) пришлось провести небольшое исследование и написать по его результатам статью .
В статье рассмотрена более общая задача, но также и задача из (40), как частный случай более общей задачи.
К статье прилагается каркасная конфигурация с обработками заполнения базы данными по условию задачи (40), отчетами, решающими задачи 1 и 2 типовым методом и предлагаемым в (49).
Для трех лет в базе получилось 10 миллионов заявок. Типовой метод работает по первой задаче 16 сек, предлагаемый — 0,59 сек. Вторая задача решается методом из (49) примерно 1,5 секунды (для недельного интервала).
Приглашаю ознакомиться со статьей всех, кто интересовался конкурсом и задачей из (40).