
3 марта 2011
Пол Уайт
Авторский перевод статьи, поэтому, если заметите какие-либо неточности, прошу отметить в комментариях.
SQLServer
способен к неявному использованию параллелизма для ускорения запросов SQL. Как он это делает, и как
вы можете быть уверены, что он это делает, не совсем очевидно для большинства из нас. Пол
Уайт начинает серию, которая делает все это простым для понимания, начиная с легкого
уровня подсчета фасоли.
Многие опытные профессионалы баз данных приобрели несколько искаженный
взгляд на параллельное выполнение запросов. Иногда это является следствием
неудачных опытов с более ранними версиями SQLServer. Однако, часто, этот взгляд является результатом заблуждений,
или недостаточностью мастерства владения методами, необходимыми для эффективной
разработки и настройки запросов для параллельного выполнения.
Это первая в серии статей, которая обеспечит читателя с
глубокими знаниями, необходимой информацией для использования параллельных
функций обработки запросов, доступных в Microsoft SQL Server. Часть первая
представляет собой пошаговое руководство по основам параллелизма в SQ LServer, освещая такие понятия,
как «параллельное сканирование и поиск» (“parallel scans and seeks”), «работники» (“workers”), «потоки» (“threads”),
«задачи»(” tasks”), «контекст выполнения» (“execution contexts”) и «операторы
обмена» (“exchange operators”), которые координируют параллельную деятельность.
Будущие статьи обеспечат более полное представление о
внутренней работе databaseengine,
и покажут, как целенаправленный параллелизм может принести пользу не только
хранилищам данных и системам поддержки принятия решений, обычно связанных с его
использованием.
Часто думают, что основная нагрузка на систему ложится, прежде
всего, при обработке транзакций (OLTP), однако, системы часто содержат запросы и процедуры,
которые могли бы выиграть от надлежащего использования параллелизма.
Допускаю, что эта и
последующие статьи содержат довольно глубокие технические описания. Наиболее
эффективное использование параллелизма требует хорошего понимания таких вещей,
как планирование, оптимизация запросов, и механизмов выполнения. Тем не менее,
есть надежда, что даже новичок в этой теме найдет её для себя информативной и
полезной.
Что такое
параллелизм?
Вы, наверное, слышали фразу «Много рук делают легкую
работу». Идея состоит в том, что разделение задачи между несколькими
людьми приводит к тому, что каждый человек делает меньше. С точки зрения
отдельного человека, работа кажется
гораздо легче, хотя это такое же количество работы, что делается в целом. Что
еще более важно, если дополнительные люди могут выполнять их распределенные
работы одновременно, то общее время,
необходимое для выполнения этой задачи уменьшается.
Подсчет
фасоли
Представьте, что вы держите в руках большую стеклянную банку
полную фасоли, и вас попросили её посчитать. Предположим, что вы в состоянии считать
в среднем пять фасолин в секунду, это займет у вас чуть более десяти минут,
чтобы определить, что именно этот сосуд содержит 3027 фасоли.
Если четыре ваших друга предлагают помочь с задачей, вы
можете выбрать из ряда возможных стратегий, но давайте рассмотрим тот вариант,
который четко отражает стратегию SQL Server. Вы усадить своих
друзей за столом с банкой в его центре и одним совком для извлечения бобов из
банки. Вы попросите их, чтобы они использовали совок, когда нужно больше фасоли для подсчета. Каждый из друзей также имеет ручку и листок бумаги, чтобы сохранять
текущую сумму количества фасоли, которое они подсчитали.
Как только человек заканчивает подсчет и находит банку
пустой, каждый отдает свой общий индивидуальный итог вам. Вы собираете каждый
промежуточный итог и добавляете его в общий итог. Когда вы получили
промежуточный итог от каждого из ваших друзей, задача выполнена. С четырьмя
людьми, считающими фасоль одновременно, вся задача выполнена в течение около
двух с половиной минут — четырехкратным улучшением по сравнению с тем, если бы
вы считали их все самостоятельно. Конечно, четыре человека работали в общей
сложности десять минут (плюс несколько секунд, которые потребовались вам для того, чтобы добавить последний итог в общий итог).
Данная задача хорошо подходит для параллельной работы,
потому что каждый человек способен работать одновременно и независимо друг от
друга. Желаемый результат получается гораздо быстрее, не увеличивая общую
работу в целом.
Подсчет
фасоли с SQL Server
SQL Server
не может подсчитывать фасоль, поэтому мы попросим его подсчитать количество
строк в таблице. Если таблица небольшая, SQL Server, скорее всего, будет
использовать план выполнения, как показано на рисунке 1.
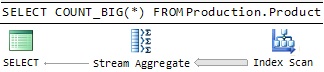
Рисунок 1: Последовательный план подсчета (Serial Counting Plan)
Этот план запроса использует одного рабочего — считает всю
фасоль самостоятельно. Сам план очень прост: оператор “Stream Aggregate” подсчитывает
строки, которые он получает от оператора “Index Scan” и возвращает результат как только все строки были
обработаны. Вы могли бы выбрать подобную стратегию, если банка с фасолью была
бы почти пуста, так как вы вряд ли сэкономите много времени, разделив небольшое
количество фасоли среди ваших друзей, и дополнительные работники могли бы даже
замедлить процесс, в связи с дополнительной стадией подсчета итогов.
С другой стороны, если таблица является достаточно большой,
оптимизатор SQL Server
может выбрать дополнительных работников, используя план запроса, как показано
на рисунке 2.

Рисунок 2: Параллельный план подсчета (Parallel Counting Plan)
Маленькие желтые значки со стрелками показывают операции,
которые включают несколько работников. Каждому работнику назначается отдельная
часть работы, и частичные результаты затем объединяют с получением конечного
результата. Как показано в примере ручного подсчета фасоли, параллельный план
имеет все шансы, чтобы завершиться значительно быстрее, чем последовательный
план, потому что несколько работников будут активно подсчитывать строки одновременно.
Как
параллелизм работает
Представьте себе на минуту, что SQL Server не имеет встроенную
поддержку параллелизма. Вы могли бы попытаться повысить производительность
оригинального запроса подсчета строк, вручную разбив запрос на одинаковые по
размеру кусочки и запустив каждый из них одновременно на отдельном подключении
к серверу.

Рисунок 3: Ручной параллелизм (Manual Parallelism)
Каждый запрос на рисунке 3 написан для обработки отдельного
диапазона строк таблицы, гарантируя, что каждая строка из таблицы
обрабатывается только один раз в целом. Если повезет, SQL Server запустит
каждый запрос на отдельном блоке обработки, и вы могли бы рассчитывать на
получение трех частичных результатов примерно в треть времени. Естественно, вам
все равно потребуется выполнить дополнительную стадию объединения результатов,
чтобы получить правильный конечный результат.
Параллельное
выполнение как множество последовательных планов
Пример «Ручного параллелизма» не столь далек от того, как SQL Server фактически
осуществляет свою параллельную работу с запросами. Вспомним план параллельных
запросов на рисунке 2, и предположим, что SQL Server выделяет три дополнительных работника на запрос во время
его выполнения. Концептуально, мы можем перерисовать параллельный план, чтобы
показать, что SQL Server запускает три последовательных плана одновременно (это
представление не совсем точно, но мы это исправим в ближайшее время).

Рисунок 4: Множество последовательных планов (Multiple Serial Plans)
Каждому дополнительному работнику присваивается один из трех
ветвей плана, которые сливаются в
оператор Сбора Потоков (Gather Streams operator).
Обратите внимание, что только оператор Сбора Потоков (Gather Streams operator) содержит маленькую желтую
иконку параллелизма; это сейчас единственный оператор, который взаимодействует
с несколькими работниками. Эта общая стратегия подходит SQL Server по двум основным
причинам. Во-первых, весь код, который SQL Server необходимо выполнить для реализации последовательных
планов уже существует и был оптимизирован в течение многих лет и релизов
продукта. Во-вторых, этот метод очень хорошо масштабируется: если больше
работников доступно во время выполнения, SQL Server может легко добавить дополнительные ветви плана чтобы
распределить работу на большее количество работников.
Количество дополнительных работников, которых SQL Server присваивает
каждой области параллельного плана во время выполнения известно как степень
параллелизма (Degree of parallelism
— часто сокращенно DOP).
SQL-сервер выбирает DOP непосредственно перед
началом выполнение запроса, и это значение может меняться между выполнениями
запроса без необходимости повторной компиляции плана. Максимальная DOP для каждой параллельной
области определяется количеством логических блоков обработки (logical processing units) видимых SQL Server.
Параллельное
сканирование (Parallel Scan) и поставщик параллельных страниц (Parallel Page Supplier)
Проблемой в концептуальном плане, показанном на рисунке 4,
является то, что каждый оператор Index Scan будет считать каждую строку во всей совокупности ввода. Левая
часть некорректна, план будет выдавать неправильные результаты и, вероятно,
займет больше времени для выполнения, чем последовательная версия. Ручной
пример параллелизма избежал этой проблемы, используя явное «ГДЕ» (“WHERE”) в каждом запросе и
разделил входные строки на три одинаковых по размеру диапазона.
SQL Server
не использует тот же подход, потому что, распределяя работу равномерно, можно
предположить, что каждый запрос будет получать равную долю доступных
вычислительных ресурсов, и что каждая строка данных потребует одинаковое усилие
для обработки. В качестве простого примера, такого как подсчет строк в таблице
(на сервере без другой деятельности) эти предположения вполне могут иметь
место и три запроса могут действительно вернуть свои частичные результаты
примерно за то же время.
В целом, однако, можно легко привести примеры, где эти
предположения не будут допускаться в реальном мире, в связи с некоторым числом
внешних или внутренних факторов. Например, один из запросов может быть
запланирован на тот же логический процессор, который занят продолжительной массовой загрузкой, в то время как другие остаются
без нагрузки. В качестве альтернативы рассмотрим запрос, который включает в
себя операцию соединения (Join),
где объем работ, необходимых для обработки конкретной строки сильно зависит от
того, соответствует ли она условию соединения или нет. Если некоторые запросы
содержат больше соединяющих строк, чем другие, то время выполнения может варьироваться
в широких пределах и общая производительность будет ограничена скоростью самого
медленного работника.
Вместо того чтобы выделять фиксированное количество строк для
каждого работника, SQL Server
использует функцию хранения под названием поставщик параллельных страниц (Parallel Page Supplier) для распределения
строк среди работников по требованию. Вы не увидите Parallel Page Supplierв
графическом плане запроса, потому что он не является частью процессора
запросов, но мы можем продлить иллюстрацию рисунка 4, чтобы показать, где он
будет находиться и его связи:

Рисунок 5: Поставщик параллельных страниц (Parallel Page Supplier)
Важным моментом является то, что это схема на основе спроса;
Parallel Page Supplier
отвечает на запросы работников, обеспечивая партию строк любому работнику,
который должен еще поработать. Возвращаясь к аналогии подсчета фасоли, Parallel Page Supplier представлен совком,
используемым для извлечения фасоли из банки. Один общий совок гарантирует, что
нет двух людей, подсчитывающих ту же фасоль, с другой стороны, нет ничего, что
может препятствовать человеку забирать больше фасоли для подсчета по мере
необходимости. В частности, если один человек работает медленнее, чем другие, то
этот человек просто реже пользуется совком, и другие работники будут подсчитывать
больше фасоли, чтобы компенсировать это.
В SQL Server
медленный работник делает меньше запросов к Parallel Page Supplier и таким образом обрабатывает
меньше строк. Это не влияет на работу других работников, и они продолжают
обработку строк в их максимальной производительности. Таким образом, схема на
основе спроса обеспечивает определенную степень устойчивости к изменениям в
рабочей пропускной способности. Вместо того чтобы
быть связанным по скорости самого медленного работника, производительность
схемы на основе спроса уменьшается незначительно, если у отдельного работника
снижается производительность. Тем не менее, тот факт, что каждый работник может
обрабатывать значительно отличающиеся количества строк, в зависимости от
условий среды выполнения, может вызвать другие проблемы (к этой теме мы
вернемся позже в этой серии).
Обратите внимание, что использование Parallel Page Supplier не мешает SQL Server использовать
существующие оптимизации, такие как сканирование опережающего чтения (read-ahead scanning) (предварительную
выборку данных из постоянного хранения). На самом деле, это может быть даже
немного более эффективным для трех работников потребляющих строки из одного, базового
физического сканирования, а не из трех отдельных сканов областей, которые мы
видели в ручном примере параллелизма.
Parallel Page Supplier
также не ограничивается использованием сканирования индексов; SQL Server использует Parallel Page Supplier всякий раз, когда
несколько работников совместно читают структуру данных. Эта структура данных
может быть массив, кластерная таблица или индекс, и операция может быть либо
сканирования (scan) либо
поиска (seek). Если последний
пункт удивляет вас, считают, что Index Seek лишь частичное сканирование (scan) т.е. она стремится найти первую отобранную
(qualifying) строку, а
затем сканирует до конца отобранного диапазона.
Контексты
исполнения (Execution Contexts)
Обратимся теперь к отдельным серверным соединениям,
используемым в ручном примере параллелизма для достижения одновременного
выполнения. Это не было бы эффективным для SQL Server, фактически создать несколько новых
соединений для выполнения каждого параллельного запроса, но реальный механизм
во многом похож. Вместо того, чтобы создавать отдельное соединение для каждого
последовательного запроса, SQL Server
использует облегченную конструкцию, известную как контексты исполнения (Execution Contexts).
Контекст выполнения происходит от части плана запроса, во
время выполнения, заполняя детали, которые не были известны в то время, когда
план был скомпилирован и оптимизирован. Эти детали включают ссылки на объекты,
которые не существуют до момента выполнения (временная таблица, созданная в
рамках одного пакета, например) и значения любых параметров и локальных
переменных. Более подробная информация о контекстах — Microsoft White Page.
SQL Server запускает параллельный план, выводя контексты выполнения DOP для каждой параллельной области
плана запроса, с использованием отдельного работника для запуска части
последовательного плана содержащегося в каждом контексте. Для облегчения
понимания концепции, на рисунке 6 показаны четыре контекста выполнения созданных для параллельного плана подсчета,
над которым мы работали до сих пор. Каждый цвет определяет область контекста
исполнения, и хотя это не показано явно, Parallel Page Supplier снова используется
для координации индексов.
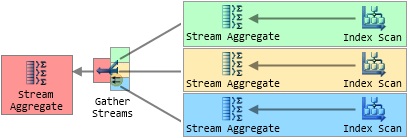
Рисунок 6: Контексты выполнения параллельного плана
Самый левый контекст выполнения плана параллельного запроса
(отображается красным цветом, на рисунке 6) играет особую координирующую роль и
выполняется работником подключения , отправившего запрос. Это
«первый» контекст выполнения известен как нулевой контекст
выполнения, и связанный работник известен как нулевой поток (thread zero). Мы определим некоторые
из этих терминов более точно в следующем разделе, а пока предположим, что
«работник» и «поток» (thread)
означает примерно то же самое.
Чтобы получить более конкретное представление абстрактных понятий,
введенных в этом разделе, Рисунок 7 показывает информацию, полученную путем
запуска параллельного запроса подсчета строк, с помощью опции SQL Server Management Studio (SSMS), «Include Actual Execution Plan».
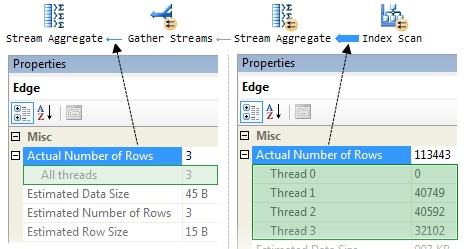
Рисунок 7: параллельный план подсчета строк
Выноски показывают количество строк, обработанных каждым
работником (потоком) в двух различных точках в плане. Информация поступила из
окна SSMS Properties,
которое может быть доступно при нажатии на оператора (или соединительной линии)
и клавиши F4. Кроме
того, вы можете щелкнуть правой кнопкой мыши на операторе или линии и выбрать «Свойства»
(«Properties») из
всплывающего меню.
Читая справа, мы видим сколько строк рассчитывает каждый из
трех работников в параллельной части плана; прошу заметить, что два работника
обрабатывают приблизительно равное количество строк (около 40 000), а третий
получает всего 32 000 строк из Parallel Page Supplier.
Как уже говорилось ранее, процесс основанный на спросе означает, что точное
число строк, обработанных каждым работником зависит от временных показателей и
загрузки процессоров (в числе прочего) и часто колеблется между выполнениями
запросов, даже на легкозагруженой машине.
Левая часть диаграммы показывает три частичных результата
(по одному от каждого параллельного работника, выполняется в своем собственном контексте
исполнения), которые собираются вместе и подвел их к одному результату ‘thread zero’. Это причуда окна SSMS Properties что “thread zero” помечен как “thread 0”в параллельных
частях графического плана, и как “all threads” в последовательной области. Если вы посмотрите на XML, на котором основан
графический план, ‘Счетчик выполнения
каждого потока’ всегда относится к «thread 0», никогда «All Threads».
Планировщики, работники и задачи (Schedulers, Workers, and Tasks)
В этой статье до сих пор используется взаимозаменяемые
термины, такие как «thread»
и «worker» (поток и работник).
Теперь, кажется, настало время, чтобы точнее определить некоторые термины.
Планировщики (Schedulers)
Планировщик в SQL Server представляет собой логический процессор, который может
быть физическим процессором, ядром процессора, или, возможно, одним из
нескольких аппаратных потоков, работающих в пределах ядра (Hyper Threading). Основная цель
планировщиков заключается в том, чтобы позволить SQL Server точно управлять собственным
планированием потоков, а не полагаться на общие алгоритмы, используемых в
операционных системах Windows. Каждый планировщик гарантирует, что только один совместно
выполняющийся поток является работоспособным (насколько позволяет операционная
система) в любой момент, который может иметь важные преимущества, такие как
снижение переключения контекста, и снижение числа вызовов в ядре Windows. Часть третья этой
серии охватывает внутреннее планирование задач и их исполнение более подробно.
Информация о планировщиках показана в просмотре системы
динамического управления (DMV),
sys.dm_os_schedulers.
Работники и Потоки (Workers and Threads)
Работник SQL Server
является абстракцией, что представляет собой либо один поток операционной
системы или набор потоков (fiber)
(в зависимости от настройки конфигурации “lightweight pooling”). Очень немногие системы
работают с включенным режимом “fiber-mode scheduling”, таким образом
многие тексты (в том числе большая часть официальной документации) ссылаются на
«рабочие потоки» (worker threads)
— подчеркивая тот факт, что, для большинства практических целей, работник
является потоком. Работник (поток) привязан к конкретному планировщику для
всего срока службы. Информация о работниках показана в sys.dm_os_workersDMV.
Задачи (Tasks)
Онлайн книги так говорят о задачах: Задача представляет
собой единицу работы, которая планируется на SQL Server. Работа может быть связана с одной или несколькими задачами.
Например, параллельный запрос будет выполнять несколько задач.
Чтобы расширить этот довольно краткое определение, скажем,
что задача – это часть работы выполняемая работником SQL Server. Работа, которая
содержит только последовательные планы выполнения является одной задачей, и
будет выполнена (от начала до конца) на одном подключении, предоставленном
работнику. Это тот случай, когда даже если для выполнения запроса необходимо
сделать паузу, чтобы дождаться некоего события для завершения (например, для
чтения с диска). Одному работнику назначается одна задача, и он не может
выполнять другие задачи, пока текущая задача не будет завершена полностью.
Контексты исполнения (Execution Contexts)
Если задача описывает работу, которую предстоит сделать, то контекст
выполнения описывает где эта работа будет происходить. Каждая задача
выполняется внутри одного контекста исполнения, которые были определены в
колонке exec_context_id в sys.dm_os_tasksDMV(вы
также можете увидеть контексты выполнения с помощью “ECID” колонки в просмотре обратной
совместимости sys.sysprocesses).
Оператор обмена (The Exchange Operator)
Чтобы кратко резюмировать, мы видели, что SQL Server выполняет параллельный
план путем совместного запуска нескольких экземпляров последовательного плана. Каждый
последовательный план является одной задачей, выполняемой в отдельном рабочем
потоке внутри собственного контекста выполнения. Последний ингредиент в
параллельном плане оператор обмена, который является ‘клеем’ для SQL Serverи
используется для соединения контекстов исполнения параллельного плана. В целом,
комплексный план запроса может содержать любое количество последовательных или
параллельных областей, соединенных операторами обмена.
До сих пор мы видели только один вариант оператора обмена, а
именно «Gather streams»,
но оператор обмена может появиться в графических планов в других вариантах:

Рисунок 8: Логические операторы обмена
Все виды операторов обмена служат для перемещения строк
между одним или несколькими работниками, распределяя отдельные строки среди них.
Различные виды логических операторов используются SQL Server, чтобы ввести новую
последовательную или параллельную область или перераспределить строки на
границе раздела между двумя параллельными областями.
Один физический оператор обмена более гибкий, чем его три
логических варианта. Он может не только разделить, объединить, или
перераспределить строки среди рабочих, подключенных к нему, но также:
·
использовать одну из пяти различных стратегий,
чтобы определить какие исходящие данные направить на ввод строки
·
при необходимости сохранять порядок сортировки
входных строк
Большая часть этой гибкости проистекает из его внутренней
конструкции, поэтому мы рассмотрим это в
первую очередь.
Внутри обмена
Оператор обмена имеет две различных субкомпоненты:
·
Производителей (Producers), которые соединяются с
рабочими на его входе
·
Потребители (Consumers), которые соединяются с работниками на его выходе
На рисунке 9 показано увеличенное изображение (разноцветное)
“Gather Streams”
оператора с рисунка 6.
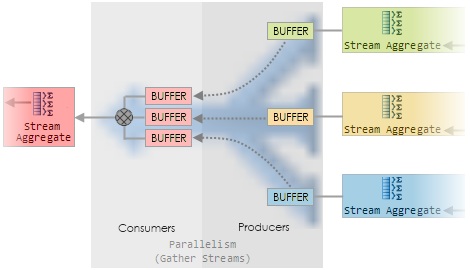
Рисунок 9: Внутри оператора обмена Gather Streams
Каждый производитель собирает строки на его входе и
упаковывает их в одном или нескольких буферах памяти. После того, как буфер
заполнен, производитель отдает его потребителю. Каждый из производителей и
потребителей работает на том же рабочем потоке в качестве контекста выполнения,
к которому он подключен (общая раскраска). Потребитель обмена читает строку из
буфера обмена, каждый раз, когда его попросил один из его родительских
операторов (обозначенный красным цветом Stream Aggregate, в этом случае).
Одним из главных преимуществ данной конструкции является то,
что сложности обычно связанные с обменом данными между несколькими потоками
исполнения могут быть урегулированы SQL Server внутри одного оператора. Остальные, необменные операторы в
плане работают последовательно, и не должны иметь дело с этим механизмом.
Оператор обмена использует буферы, чтобы свести к минимуму издержки
и реализовать основной вид управления потоком (чтобы предотвратить быстрых
производителей уйти слишком далеко вперед медленной работы потребителей,
например). Точное расположение буферов зависит от типа обмена, требуется или нет
сохранять порядок, и решение какому потребителю производитель строки должен её
направить.
Маршрутизация Строки (Routing Rows)
Как уже отмечалось, оператор обмена может решать, к какому
потребителю производитель должен направить конкретную строку. Это решение
зависит от типа разделения (PartitioningType)
указанного для обмена. Существует пять вариантов:
·
Хэш (hash) – наиболее распространен. Потребитель выбирается исходя из
оценки хэш функции по одному или нескольким значениям столбцов в текущей строке
·
Круговая система (RoundRobin) – каждая новая строка
посылается к следующему потребителю в определенной последовательности
·
Трансляция (Broadcast) – каждая строка отправляется всем потребителям
·
Спрос (Demand) – строка отсылается первому потребителю, который попросит
её. Это единственный тип разделения, где строка направляется от производителя
посредством потребителя внутри оператора обмена
·
Диапазон (Range) – Каждому потребителю присваивается неперекрывающийся
диапазон значений. Диапазон, в который попадает входной столбец определяет
какой потребитель получит строку.
Типы разделения «Спрос» и «Диапазон» встречаются гораздо
реже, чем первые три, и, как правило, их можно увидеть только в планах
запросов, которые работают с секционированными таблицами (Partitioned Tables). Тип «Спрос»
используется в совместно размещенных разделах соединений для назначения
идентификатора раздела к следующему рабочему потоку. Тип «Диапазон»
используется, например, при создании секционированных индексов. Типы разделения,
которые использовались, и любые значения столбцов, используемые в процессе,
видны в графическом плане запроса:
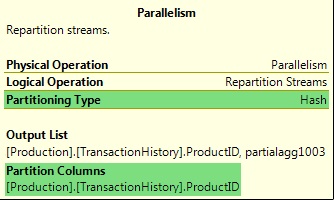
Рисунок 10: Информация о разделении обмена (Exchange Partitioning
Information)
Наиболее распространенные типы разделения будут подробно
описаны в следующих публикациях.
Сохранение порядка ввода
Оператор обмена необязательно может быть сконфигурирован так,
чтобы сохранить порядок сортировки. Это полезно в планах, где строки, входящие
в обмен уже отсортированы (сохраняя предыдущую сортировку, или как следствие упорядоченного
чтения из индекса) таким образом, что полезно для более позднего оператора. Если
обмен не сохранил порядок, оптимизатор должен будет ввести дополнительного
оператора сортировки после обмена, чтобы восстановить необходимый порядок. К общим
операторам, которые требуют отсортированные входные данные относятся Stream Aggregate, Segment, и Merge Join. На рисунке 11
показан сохраняющей порядок Repartition Streams обмен в действии:

Рисунок 11: An Order-Preserving
Repartition Streams Exchange
Строки, прибывающие на трех входах в обмен в определенном
порядке (отсортированные, с точки зрения отдельных работников).Сохраняющей
порядок обмен, известный как обмен слияния (merging exchange),
гарантирует, что работник (и) на его выходе получать строки в том же порядке сортировки
(при том, что распределение, как правило, разное, конечно).
Обмен сбора потоков (Gather Stream Exchange) также может
сохраняют порядок сортировки, при необходимости (также как обмен распределения
потоков (Distribute Streams Exchange)).
В любом случае, если обмен является обменом слияния (merging exchange), оператор обмена
имеет атрибут «Сортировать по» (Order by) ,
как показано на рисунке 12:

Рисунок 12: Атрибут «Сортировать по» обмена слияния (The ‘Order By’ Attribute of a Merging Exchange)
Обратите внимание, что обмен слияния (Merging Exchange) не выполняет никакой
сортировки; она ограничивается сохранением порядок сортировки строк,
поступающих на его входы. Обмен слияния может быть гораздо менее эффективным,
чем вариант, не сохраняющий порядок и это связано с определенными проблемами
производительности. Это уже другая тема, которую мы рассмотрим более подробно
позже в других публикациях.
Резюме
В введении в параллелизм мы использовали простой запрос, и
связанный с ним реальный пример, чтобы исследовать модель, используемую SQL Server, чтобы позволить
запросам автоматически извлечь выгоду из дополнительной вычислительной
мощности, предоставляемой современными многоядерными серверами, не требуя от
разработчика учитывать некоторые сложности, обычно связанные с многопоточной конструкцией.
Мы видели, что план параллельных запросов может содержать
любое количество параллельных и последовательных областей, связанных оператором
обмена. Параллельные зоны расширяются на несколько последовательных запросов,
каждый из которых использует один рабочий поток для обработки задачи в пределах
контекста выполнения. Операторы обмена используются для распределения строк
между работниками, и эти операторы существуют только в параллельном плане
запроса, и которые взаимодействуют
непосредственно с более чем одним работником. Наконец, мы увидели, что SQL Server обеспечивает поставщика
параллельных страниц, который позволяет нескольким работникам совместно
сканировать таблицу или индекс, гарантируя правильные результаты.
Следующая часть этой серии основана на фундаментальных
понятиях, рассмотренных в этом введении, и показывает как использовать контекст выполнения, рабочие потоки, и операторы
обмена в запросах, которые используют параллельный хэш (parallel hash) и соединения слиянием (merge joins). Мы также более
подробно рассмотрим типы разделения обмена (Exchange Partitioning Types), оптимизацию запросов,
которая возможна только в параллельных планах; ту оптимизацию, которая может привести к выполнению
параллельного запроса, используя меньше процессорного времени, чем аналогичный
последовательный запрос и быстрее возвращая результат запроса.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Интересно, но в 1С малоприменимо 🙂
З.Ы. Если быть более точным, то «в учетных системах 1с».
(1) ну почему же, многие с успехом используют «ручной параллелизм»
(2) jan27,
вот как-раз об этом-то и хотелось бы почитать поподробнее на соответствующем ресурсе 🙂
(3) так читайте
(4) jan27,
Вот там вот я читал. Я думал, вы имеете в виду, что эти многие используют «ручной параллелизм» именно средствами MS SQL.
Например, могу я перед запуском транзакции на сервере включить какой-нибудь могучий флаг?
(5) если средствами MS SQL, то это уже не ручной параллелизм. А так, в настройках сервера есть Maximum Degree of Parallelism
(2) jan27,
Ручной параллелизм — это, конечно, хорошо.. Но дюже геморройно будет выбирать данные для обработки так, чтобы они еще и не пересекались и не влияли на результаты друг друга..
(7) если появится такая необходимость — почему нет?
(7) вообще речь не о ручном параллелизме, а о параллелизме под управлением SQL сервера, который работает при MDOP, отличном от 1
(9) jan27,
Если вести речь о неручном параллелизме, то можно наткнуться на:
Transaction was deadlocked on thread communication buffer resources with another process and has been chosen as the deadlock victim
И везде решается эта проблема только отключением параллелизма как раз ) Или, быть может, есть другие методы? Я в скуле новичок, собсн — было бы интересно узнать мнение более опытных людей )
(10) очевидное решение проблемы с параллелизмом — отключить его
обычно рекомендуют посмотреть какой запрос или транзакция приводит к такой ошибке
сколько процессоров, какой MDOP?
(10)- 11 пост к 10
(11) jan27,
Я как бы сам с такими запросами не встречался, но в процессе подготовки к сдаче экзамена ЭТВ неоднократно наталкивался на подобные рекомендации вида:
Да и на самом тренинге по эксперту отношение к оной опции (Max DOP) было неоднозначное..
(13) почему то все игнорируют вариант оптимизации запроса 🙂
(14) jan27,
Наверное потому, что напрямую изменить запрос SQL из 1С нельзя ) Плюс не всегда есть возможность вообще что-то менять в конфигурации..
И сами MS разработчики, как я понимаю из обсуждений, не предусматривали, что параллелизм будут использовать в OLTP-системах.. Ну, то есть, работать-то он будет, но предназначен не для них )
(15) зачастую, достаточно оптимизировать запрос 1С + отключение параллелизма имеет смысл на сервере с малым количеством процессоров (2-4)
(16) jan27,
А каким образом его оптимизировать для того, чтобы он мог исполняться параллельно? Например, вот получил я интраквери параллелизм еррор — дальше куда глядеть, опции максдоп, конечно? )
(17) , например
(18) jan27,
Как бы профайлер я видел, и даже оптимизировал запросы — это да )
Но вот как средствами профайлера проанализировать запрос, упавший на внутренней самоблокировке? Полагаю, что тут скорее вот
(19) ссылка не открывается
(20) jan27,
чота со ссылками у инфостарту..
ЗЫ Сегодня таки залез попробовать у одного клиента параллелизм — в свойствах у него оказалось и так стояло maxdop = 0. Но значков, подобных тем, что в статье, я в профайлере почему-то не увидел.. Ну то есть графическое представление плана как было, так и осталось тем же.. Там надо какие-то специфические события для этого включать в трассу?
(21) посмотри в Activity Monitor Последние тяжелые запросы + в запросе должны быть какие-либо соединения
(21) Deadlocks:
(22) jan27,
Ага,попробую — там как раз 2008 скуль стоит в отличии от большинства моих клиентов с 2005 )
Соединений-то в запросе не то, что гора, но очччень даже порядком )
(24) вот здесь пример 1С запроса, который вызывает параллельный план