

Пост уважаемого Elisy о парсере сайтов для 1С:Предприятия заслуживает на мой взгляд большего внимания, в связи с чем решил написать о своем опыте парсинга HTML и о том, зачем для этого использовались компоненты ElisyNetBridge и HtmlAgilityPack.
Зачем это нужно?
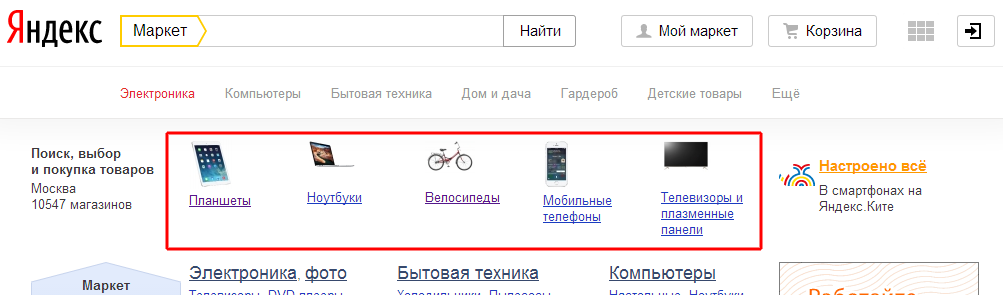
XPath позволяет простым способом получить перечисления нужных элементов HTML страницы, например список популярных категорий товаров (вверху заглавной страницы Яндекс.Маркет) можно получить так:
Разделы = HAP.DocumentNode.SelectNodes("//ul[@class='b-flex-gridb-popular-categories']");
мы получим контейнер, хранящий объекты категорий
соответственно код
Подразделы = Разделы.get_Item(0).SelectNodes(".//a[@class='name']"); Для i = 0 По Подразделы.Count - 1 Цикл Раздел = СокрЛП(Подразделы.get_Item(i).InnerHtml); Ссылка = СокрЛП(Подразделы.get_Item(i).Attributes.get_Item(1).value); КонецЦикла;Вернет названия и ссылки на все категории популярных товаров с заглавной страницы. Перейдя по ссылке категории и выполнив код
Для Каждого ЭлементНоды Из СписокНодРаздела Цикл HAP.LoadHtml(appIE.Document.documentElement.innerHTML); КонтейнерПроизводителей = HAP.DocumentNode.SelectNodes("//a[text()='Популярные']/preceding::div[1]"); Производители = КонтейнерПроизводителей.get_Item(0).SelectNodes(".//li[@class='pop-vendors__vendor']"); Для e = 0 По Производители.Count - 1 Цикл Сообщить("Производитель №" + СокрЛП(e + 1) + " " + СокрЛП(Производители.get_Item(e).InnerHtml)); КонецЦикла; КонецЦикла;Можно получить всех текущих производителей данной категории со ссылками на страницы с перечнем их товаров
Почему не RegEx?
Почему не стоит использовать регулярные выражения для парсинга HTML хорошо написано тут.
Зачем HtmlAgilityPack?
XPath может работать только с валидным XML, каковым HTML страница в большинстве случаев не является, т. к. браузеры не требовательны к валидности XML — достаточно одного <br> и стандартные компоненты для работы с XPath просто не смогут загрузить документ для дальнейшей обработки.
Зачем ElisyNetBridge?
Не уверен, есть ли варианты проще для подключения HtmlAgilityPack в 1С, кроме ElisyNetBridge. Ссылка на бесплатную версию компоненты любезно выложена автором в его статье, компонента также есть в приложенной обработке.
Как тестировать выражения XPath?
В состав HtmlAgilityPack входит HAP Explorer (на скриншоте), загрузив в него HTML исходной страницы можно тестировать различные выражения и смотреть полученные результаты. Правда бывает падает при сложных выражениях 🙂
Вроде бы все понятно, но…
К статье прикреплена обработка с примером использования ElisyNetBridge и HtmlAgilityPack. Прошу не судить строго за синтаксис XPath — перебор категорий популярных товаров сделан для примера, XPath предлагает широкие возможности для перебора нужных элементов, наверняка есть варианты получше.

Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Спасибо за статью-продолжение. Полезным, например, для меня было узнать про HAP Explorer. Думаю эта утилита сократит время на разработку XPath. Забавно также описание, почему нельзя использовать RegEx в мире Html со вставками вида <i>he an​*̶͑̾̾​̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̳̟̍ͫͥͨ</i>
Статья полезная. Вот только название плохое. Думал, разбор на языке 1С, даже открывать не хотел.
(1) Можно использовать 1С альтернативу HAP Explorer от Yashazz и статья у коллеги хорошая
Evaluation limitation
All unregistered versions (evaluation copies) of Elisy .Net Bridge component show a message box when first accessed from 1C:Enterprise.
All unregistered versions (evaluation copies) of Elisy LinqTo1C component support generation of up to 7 tables.
Сегодня только нашел альтернативное чтение Xpath Тоже неплохо читается
Попробуйте один тег не закрывать и поймете зачем нужен HtmlAgilityPack
(6) Вы правы. Придется в таком случае обработать ошибку , ТипЗнч(responseCode)=Неопределено и дальше обрабатывать сайт,
очень хорошо описаны функции msxml2.domdocument.6.0
Уверяю вас, большинство страниц не содержит валидного html. Соответственно весь сайт будет ТипЗнч(responseCode)=Неопределено.
HtmlAgilityPack преобразует невалидный html в валидный xml. За ссылку спасибо.
Установите компоненту C:Users…AppDataLocalTemp\ElisyNetBridge.exe — не запускается обработка, вроде все установил, но все пишет установить компоненту.. Что делать?
Попробуйте скачать необходимый компонент
(9) husky, перейдите к этому файлику. Это архив с расширением exe. Распакуете, будет внутри искомое. После установки разочаруетесь.
Вот простоя связка
1) Bitrix ENV (Bitrix Environment for Windows) или посложнее — Denwer
2) Простой редактор PHP (Scite)
3) НЕтриальный и БЕЗограничений firepath-0.9.7-fx1.xpi (простой, понятный, Уверене, применяли FireBug, так вот FirePath 0.9.7 — отлично работает.
Поверили? Есть время попробовать?
Тогда a) ищем архивную версию Firefox firefox-portable-12-0-28432-en-setup.exe
б) firebug-1.9.2.xpi , с которым будет работать
в) и наконец-то firepath-0.9.7-fx1.xpi
г) запускаем firefox-portable под другим пользователем, чтобы настройки мозиллы остались нетронутыми
В прикрепленном файле этот архив с этими файлами есть.
Автору статьи, который утверждает, что Xpath дает преимущества при парсинге — огромное уважение за такой заголовок. Ну не правда-ли, лаконично и на скорую руку можно парсер сделать.
<?php $xpath = new DOMXPath(conn(«http://www.zava.ru/catalog104_1.shtml»)); foreach($xpath->query(«.//*[@class=’goods_h1′]/a») as $a) { echo $a->getAttribute(‘href’).»; } function conn($Urlf) { $ch=curl_init(); $dom = new DOMDocument(); $DOM->validateOnParse = true; @$dom->loadHTML($html); return $dom; }Показать
(11) Bublik2011, хочу попробовать, но можно по-подробнее описать пункты 1-3 (ну так чтобы для тупых) и что значит под другим пользователем? и самое главное зачем все это нужно?
добавлю свои 5 копеек. раньше использовал htmlagilitypack, и даже здесь на сайте советовал его. сейчас все больше использую csquery. как-то с css селекторами мне лично проще. тем более в большинстве случаев селектор тупо копируется из css на сайте прямо в браузере, того элемента, который нас интересует.
PS кстати что htmlagilitypack не покрывает всего множества xpath, что csquery не покрывает всех css селекторов. вот такая беда. но как правило можно просто переписать xpath либо селектор.
к htmlagilitypack также есть расширение fizzler + fizzlerex , которое добавляет css селекторы.
ps еще могу посоветовать restsharp . это библиотека http клиент, который из коробки может много чего. . я использую связку restsharp+csquery
еще по-оффтоплю. есть fiddler, про него многие знают. а к нему есть плагин , с помощью которого генерируется код запроса. очень удобно при парсинге, где есть заморочки, типа авторизации или всяких ajax . можно получить код и его проанализировать, подправить и т.п.
(12) husky, советует firepath (это плагин к firefox для проверки xpath запросов прямо в браузере на странице) . у меня он тоже стоит. замечание по таблицам — firefox достраивает таблицы с тегом tbody(это делается как я понимаю согласно стандарту). так, что при написании xpath запросов лучше не использовать тег tbody. а второе совет — это использовать php в качестве языка парсинга. по мне так второй совет — сомнителен. уж лучше python, не нужен будет никакой ни denwer и иже прочее. на хабре целый фрэймворк был для python-а по парсингу сайтов описан. grab называется. а так этих библиотек по парсингу для python-a как грязи.
Совсем без регулярных выражений не обойтись. Сейчас делаю проект, в котором есть разбор HTML. Сам html разбираю с помощью построителя DOM, а некоторые данные приходится выцеплять регулярными выражениями.
Cам HTML парсить регулярками не комильфо. Про некоторые данные вопросов нет.
(12) husky, очень буду рад очень подробно все описать, если при ближайшей возможности смогу объявить xpath=Новый COMОбъект(«V8.DOMXPath») . У меня есть скриншоты и тексты, на написание которых вдохновили посты habrahabr.ru про преимущества xpath.
Соглашусь в Вами, husky, про Elisy .Net Bridge надо в заголовке написать про ограничения. Очень неприятно, знаете, с уважением изучать тексты описаний методов AgilityPack и уже чуть позже понимать, что еще есть риски при использовании — какие-то ограничения и весьма неопределенная сумма за снятие ограничений , приобретение лицензии за подключение dll HtmlAgilityPack.
(15) cool.vlad4, я Вам доверяю, мне тоже п.1 нравится 🙂 Захотелось перейти на grab . Буду рад узнать о том , что grab эффективнее и доступнее.
А как конвертировать и сохранить html страницу в валидный xml, который можно будет уже спокойно обработать 1сным DOM’ом
нашел в справке метод, но XmlTextWriter где его взять в 1ске)
HtmlWeb..::..LoadHtmlAsXml Method (String, XmlTextWriter)
Loads an HTML document from an Internet resource and saves it to the specified XmlTextWriter.
public void LoadHtmlAsXml(
string htmlUrl,
XmlTextWriter writer
)
или на вход пустить текст html страницы, а на выходе получить валидный xml .
Не подключается Elisy через ПодключитьВнешнююКомпоненту в вашей обработке.
Попытался через Новый ComОбъект но потом зависает на выполнении команд.
Естественно всё необходимое установил. Из вашей обработки только не устанавливается Elisy, из другого источника установил. NetFramework так же установил и т.д.
Стоит Window7 64x как у вас то работает?
Очень легко парсить аля JQuery
Наперезагружался, поиграл с правами и т.д. Таки заработало частично, но через ComОбъект. Но вот на строке assemblyBytes = net.CallStatic(«System.Convert», «FromBase64String», ДвоичныеДанные);
Зависает, не продвигается дальше. Такое ощущение, что работает только на 32х разрядных системах
(23) Вот это
Работает под любой разрядностью
А вот это кроссплатформенно
Простите что не в тему))…Пытаюсь пропарсить цены через Соединение.Получить(АдресСайта). Адреса сайтов забиты уже в базе и привязаны к номенклатуре. перехожу по ним циклом.
После работаю через построительДОМ.
Но это очень долго!!!! Условно товар в секунду парсится. Дольше всего работает именно Соединение.Получить(АдресСайта).
50 тыс товаров так парсить это анриал.
Может есть ещё какие варианты?