
Для MS SQL 2008/2012 рекомендации ИТС уже устарели, кроме того и раньше они не всегда помогали. В статье попытался собрать наиболее полный комплект информации по данному вопросу.
В своё время в одном месте всего этого не нашел, поэтому думаю будет полезно.
Популярная статья ИТС http://its.1c.ru/db/metod81#content:2373:1 устарела — теперь уменьшение размера журнала транзакций стало не самой простой операцией.
Собственно там рекомендуется следующий скрипт:
BACKUP LOG Имя_Базы_Данных WITH TRUNCATE_ONLY
go
DBCC SHRINKFILE(Имя_Файла_Журнала_Транзакций)
go
Если выполнить его в MS SQL 2008/2012 получите ошибку:
‘truncate_only’ is not a recognized BACKUP option
Что теперь делать?
Решения, собственно два:
1)
USE [Database]
ALTER DATABASE [Database] SET RECOVERY SIMPLE
go
DBCC SHRINKFILE ([Database]_log, 1);
ALTER DATABASE [Database] SET RECOVERY FULL
go
2)
USE [Database]
BACKUP LOG [Database] TO DISK=’NUL:’
go
DBCC SHRINKFILE ([Database]_log, 1)
go
Если «Урезанием лога» не злоупотреблять (т.е. сокрашать лог вместе с полной копией) то по большому счету не принципиально каким методом пользоваться.
Второй вроде как правильнее, зато первый «надежнее».
На этом казалось бы можно и остановиться, но зачем тогда отдельную статью писать. Нет, конечно это ещё не всё. Обычно вопросы про урезание лога возникают когда это сделать не получается.
Притом способы, описанные выше, как правило, описаны не раз, все их освоили и проблем не вызывают.
Итак, если все действия, описанные выше не помогли — лог файл по-прежнему занимает N гигабайт. Переходим к плану B:
select log_reuse_wait_desc from sys.databases
В результате можете получить 3 варианта:
а. Пусто — Обычно это означает что у БД лог можно хоть сейчас полностью сократить, могу предложить только попробовать ещё раз Shrink, а если не поможет — переходить к плану C
b. Log_Backup — Нормальный варинат. В данном случае говорит о том, что Backup Log не выполнено, или выполнено некорректно
b. Replication — значит что ваш лог не обрезается из за репликации — скорее всего ошибки.
с. Active transactions — Самая частая ситуация — в базе есть подвисшие транзакции, с ними нужно разобраться.
Replication — Репликация для систем на платформе 1С, пожалуй, бессмысленное дело. Потому как Read only баз MS SQL не бывает, средства создания распределенных систем в 1С есть собственне (да, я про РИБ). Для обеспечения отказоустойчивости гораздо лучше подходят кластерные технологии. Собственно рекоммендация простая:
sp_removedbreplication ‘[Database]’
Собственно после этого бэкап и Shrink помогут. Если же вопреки здравому смыслу вы всё-таки хотите сохранить репликацию БД то конечно выполнять эту команду нельзя, а нужно разбираться с ошибками репликации. Но это уже тема отдельной статьи.
Active transactions — наиболее популярная история. В базе есть транзакции, которые не завершены, и чего то ожидают. Чащи всего такие транзакции получаются при потере сетевого соединения или «вылете» клиента 1С в момент записи в БД. В этом случае нужно собственно узнать какая транзакция «повисла»:
DBCC OPENTRAN
После выполнения этой команды вы получите примерно следующий результат:
Transaction information for database ‘master’.
Oldest active transaction:
SPID (server process ID) : 52
UID (user ID) : -1
Name : user_transaction
LSN : (518:1576:1)
Start time : May 5 2014 3:30:07:197PM
SID : 0x010500000000000515000000a065cf7e784b9b5fe77c87709e611500
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Из этого обилия информации ключевым является Start Time и SPID. Если транзакция в базе 1С выполняется боле нескольких секунд это уже означает что что-то не так. А если start Time будет минут 10 или более от текущего времени — такие транзакции (сеансы) нужно завершать. Но предварительно я бы рекоммендовал узнать что эта транзакция делала.
Для завершения процесса можно ввести команду
KILL [Process ID]
Где Process ID — это тот самый SPID полученный на предыдущем шаге. При этом незавершенные транзакции откатятся средствами MS SQL Server. Возможно при «убийстве» процесса будут завершены и несколько сеансов 1С, но вряд ли много. Сервер 1С поддерживает собственный пул соединений с MS SQL, соответственно соединения из этого пула используются только тогда, когда серверу что-то нужно от СУБД. При этом если соединение занято (а оно как видим занято) вряд ли оно будет использоваться для других процессов.
Но предварительно (!) если хотите всё-таки разобраться в проблеме рекомендую выполнить скрипт вроде:
DECLARE @sqltext VARBINARY(128)
SELECT @sqltext = sql_handle
FROM sys.sysprocesses
WHERE spid = [Process ID]
SELECT TEXT
FROM sys.dm_exec_sql_text(@sqltext)
GO
В результате вы получите текст команды SQL Server, на которой, собственно, всё и «зависло». Из неё вам нужна будет таблица в которую производилась запись, далее используя функцию «ПолучитьСтруктуруХраненияБазыДанных()» вы определите таблицу в терминах объектов метаданных в которую производилась запись и смотрите код. Как правило такие неприятные последствия происходят:
1) Ошибки в сетевых подключениях (для толстого клиента в т.ч. в сетевых подключениях клиентов, для тонкого — только в проблемах сети между сервером 1С и MS SQL).
2) Каких то неправильных действиях (отправка почты, запись в файл, запуск внешних обработок, чтения из файла) производимых в транзакциях (при записи, при проведении)
Собственно от них надо избавляться.
Если ничего не помогло (или план B)
ВНИМАНИЕ! Перед выполнением процедур, описанных ниже, сделать полную резервную копию файлов БД MS SQL нужно обязательно!!!!
Есть ещё один — более радикальный способ решения вопроса роста журнала транзакций MS SQL. Но я лично его бы не рекомендовал к использованию. Тем не менее, специалисты Microsoft тоже могут ошибаться,
и SQL Server может содержать ошибки, о которых мы регулярно читаем в BugFix, или же наблюдаем сами, поэтому приведу и этот способ.
Суть его заключается в том что журнал транзакций просто удаляется и создается новый. При этом вы конечно теряете информацию из него и БД можно будет восстановить только из полной копии (которую вы конечно перед этим сделали).
Конечно при этом, особенно если в базе были всё-таки не зафиксированные может быть нарушена логическая целостность, но для этого запускается CheckDB которая в общем и целом приводит базу в порядок. Для аналогии это то же самое что в 1С проврять ссылочную целостность с опцией «Удалять если не найден». Если транзакция полностью не зафиксирована, но от неё остались частично данные, что противоречит принципу атомарности транзакций — эти данные будут удалены.
Итак приступим:
1) Detach БД из списка
2) Фал *.ldf удаляем (вы же его сохранили уж, да?)
3) Файл *.mdf переименовываем (в любое имя какое нравится)
4) В MS SQL создаём новую (!!!) БД с тем же именем, с каким была «больная» БД
5) Останавливаем MS SQL Server
6) Новый *.mdf файл удаляем, а старый переименовываем под «старое имя», подменяя тем самым файл новой БД
7) Запускаем MS SQL Server. При этом будет «битая БД», далее мы её исправляем
8) ALTER DATABASE [Database] SET EMERGENCY
9) exec sp_dboption [Database], ‘single user’, ‘TRUE’
Монопольный режим работы с БД
10) DBCC CHECKDB ([Database], REPAIRALLOWDATA_LOSS)
Ключевая операция — «возвращает БД к жизни». Может выполняться достаточно долго — до получаса на больших БД. Ни в коем случае не прерывайте эту операцию. Результат, где будут собраны исправленные ошибки
на всякий случай сохраните
11) exec sp_dboption [Database], ‘single user’, ‘FALSE’
Сбрасываем монопольный режим
12) ALTER DATABASE [Database] SET ONLINE
Делаем базу доступной.
После чего получаем БД с чистым новеньким логом. На самом деле операция достаточно проста и в большинстве случае не несёт никаких критических последствий. Но всё-таки рекомендую прибегать к ней только в крайнем случае. Описана она не раз и в разных вариациях. Привожу свой вариант, который показался наиболее простым и понятным.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Если вопрос незакрытых транзакций или пересчетов итогов не принципиален, и есть полная копия, то проще переключиться на простую модель восстановления данных, сжать лог файл, и переключиться на полную опять. Причем при определенных обстоятельствах это можно делать регламентно, даже с пересчетом итогов из 1С. Но это разговор за отдельную плату 🙂
(1) AlexProg,
Ну написал про это:
USE [Database]
ALTER DATABASE [Database] SET RECOVERY SIMPLE
go
DBCC SHRINKFILE ([Database]_log, 1);
ALTER DATABASE [Database] SET RECOVERY FULL
go
Только если есть подвисшие транзакции всё равно не поможет…
(2) не так. target_size можно указать до нуля. Тогда он все не закрытые страницы выведет в конец, и таким образом не надо «ждать», пока он до них дойдет. Всё просто.
А если вы хотите побороться с незакрытыми, повисшими, ошибочными транзакциями, для этого есть отдельная методика, скрипты. Вовсе не обязательно ножом работать.
ALT ER DATABASE … SET SINGLE_USER WITH ROLLBACK IMMEDIATE
(3) AlexProg,
Как то жестоко… Мой вариант Kill [Process ID] как то лояльнее к пользователям 🙂
«Потому как Read only баз MS SQL не бывает». Бывают и даже работают с 1С.
«Второй вроде как правильнее, зато первый «надежнее».» Оба не правильные, правильный это регулярный бэкап лога либо отказ от полной модели восстановления.
Эти методы необходимы только если если возникли проблемы с регулярным бэкапом лога, и в некоторых случаях при операциях с обслуживанием баз (дефрагментация индексов и т.д.)
Делайте бекап ldf(журнал транзакций) каждый час и все! Не шринкуйте лог! или шринканите один раз после включения бекапа лога, потом этого делать не нужно! ибо вы заставляете сервер все время расширять ldf, на что тратится время. Так же делайте каждый день полный бекап или если не возможно каждую неделю(это все таки лучше бекапа 1с, особенно если его не жать). И все ! После включения полного бекапа и бекапа лога, после каждого бекапа, лог пишется с начала файла и перестает расширяться, расширится он только в момент серьезных транзакций ну и пусть висит на размер макс транзакции, все таки время когда мы дрожали за гигабайты прошло.
(5) Babuin,
:)))) О чём и речь. Если проблем с бэкапом лога нет, то всё что написано выше изначально «неправильно» 🙂
А вот тут поподробнее? 1C при запуске пишет кое чего в таблицы… Вам удалось это победить?
(6) rar_xxx, НачатьТранзакцию() Записать() Пока 1 Цикл КонецЦикла
И бэкапьте/не бэкапте тогда лог…
(8) )) зачем так делать ?) Если надо шринкануть самый простой вариант — переключаешь на простой режим восстановления, режешь, переключаешь на полный и Делаешь полный бекап! иначе идея восстановления по журналу транзакций накрываться. Причем все это можно делать на работающей базе.
(9) rar_xxx,
Если перефразировать ваши слова на язык MS SQL:
USE [Database]
ALTER DATABASE [Database] SET RECOVERY SIMPLE
go
DBCC SHRINKFILE ([Database]_log, 1);
ALTER DATABASE [Database] SET RECOVERY FULL
go
О чём и пишу… и писал в (2)… и продолжаю писать что не всегда помогает 🙂
(10) Ну я описал простым языком что надо сделать(не все знают что такое transact — sql и куда его писать), и у вас нет упоминания о обязательном полном бекапе после этого действа. Ну а если честно я изначально не въехал в тему и думал что тут обсуждают как ежедневно шринковать журнал.
comol — странно слышать от вас такие советы… Больше похоже на вредные советы Григория Остера. Эти советы для тех кто не разобрался в SQL? Типа наделайте чего нить не вникая и будет вам еще
лучше?согласен с rar_xxx. Зачем его трогать вообще? Ведь если лог растет значит это кому нибудь нужно 😉
Если по простому — то MS SQL работает по принципу «не тронь технику и она не подведет». А если по сложному, то надо статьи читать про механизмы работы sql, транзакций, моделей восстановления, закольцованности логов и пр. Но итог один — не надо урезать лог. Разработчики MS SQL в новом релизе сервера даже убрали такую возможность, чтобы разом сделать нерабочими советы из таких вот статей по всей Сети. Нет же, находятся «добрые саморитяне» с обходными решениями запретов….
(12) adapter, статья поможет тем, у кого лог разросся в силу тех или иных причин и никак не хочет урезаться. За что автору статьи спасибо. Свел воедино рецепты из интернета 🙂
А по феншую, конечно, лучше делать бэкап лога.
(12) adapter,
так работает не SQL сервер, а, к сожалению, очень большая доля горе-программистов :((. А потом можно увидеть «транзакцию-долгожителя» которой недельки так две… и LOG который раз в 5 превышает не маленькую и без того базу… Если вы работаете только с типовыми конфигурациями в которых сугубо бухгалтера и их не более нескольких 10-ков, при этом есть квалифицированные системные администраторы конечно можете пропустить эту статью — оно для других ситуаций
(7)
На 8.2 проблем не возникало, если что то и пишет то во временные таблицы. Возможно в 8.01 было по другому.
Работает нормально и как через снэпшот зеркальной базы, так и в AlwaysON AG. Жаль только что AlwaysON AG доступно только в Enterprise редакции…
(15) Babuin,
это не о том. Я про Rad Only. Т.е. про репликацию. В таблицу params пишет точно и 8.2 при запуске
(16)
репликация, зеркалирование, доставка журналов, не суть. 1С точно может работать с read_only базами, прямо сейчас у меня подключена к снэпшоту зеркальной базы типовая УПП, работает отлично (соответственно только на чтение-просмотр).
Профайлером смотрел, при запуске ничего не пишется, только во временные.
Возможно не умеет работать именно с репликацией (с ней не извращался), но с зеркалированием точно могет.
Проверить легко, берете тестовую базу переводите в MS SQL в режим read_only и пробуете зайти
как работает большая доля программистов и кто из них относится к «горе» это конечно очень интересная тема. Хотите развить ее по подробнее?
А что касается журналов транзакций то я еще раз говорю категорическое нет. из таких урезаний ничего хорошего не выйдет.
Факты:
— SQL умеет «зацикливать» файлы. т.е. в файле журнала будет по кругу использовать одно и то же место, без дополнительного роста
— «зависшие» транзакции обрабатываются самим SQL без помощи ему корявыми руками
— привести в идеальное состояние файлы и базы можно бакапами, регламентными заданиям, перезагрузкой сервера наконец
— команды T-SQL по вмешательству в работу сервера, или удалениеподмена баз это инструменты квалифицированного специалиста sql. Если нет опыты и понимания то вслепую их применять копипастом из Инета на «боевом» сервере НЕ НАДО.
— журнал растет чтобы обработать потребности базы. Типа реструктуризации всей базы в 1С. Значит уменьшая журнал транзакций мы не уменьшаем потребности, а уменьшаем возможности. Потребности останутся те же, но выполняться будут дольше, журнал опять вырастет. На его рост уйдет время
— нет места на журнал? (денег на железки — мы крутая фирма, у нас 100 гигов мусора в базе мы гордимся этими и вообще мы мегареспектные, а не то что всякие там недоноски с 10 бухами) — поставь модель восстановления Simple, поменяй стратегию архивирования и забудь по рост журнала. Про автомобили будет наглядней? Я купил майбах, но его обслуживать надо в сервисном центре за дорого и спецами — че я дурак что ли ? Пусть вон Петя в гаражном автосервисе за рубль все делает.
— бакапы уже жмутся самим серверов, поэтому «пустое» место в журналах никак не мешает
p.s. у меня ни в одной из 23 региональных баз нет зависших на «две недельки» транзакций, которые еще и чем то журналам мешают. Ни в типовых, ни в отраслевых, ни в собственных. Хотя отвалы интернет-соединений и пр. якобы причины которые указаны в начале статьи часто и густо в любом филиале. А мониторю я их постоянно….
(18) adapter,
Не хочу, извиняюсь. Просто не всегда могу сдержать эмоции когда вижу фразы вида «работает не трожь».
Что касается ваших знаний о
и
Они оставляют желать лучшего….
Дело в том что отсутствие checkpoint в журнале влияет на время восстановления и резервного копирования. Т.е. подвисшая транзакция в журнале приведёт в итоге к тому что база будет «In recovery»… сотвтетствено.
А сколько там пользователей? :)))) Если более 100 тогда можно о чём то говорит :))
Но больше спорить не буду — получится «разговор слепого с глухим».
Ну с утра пока вот так набежало…..
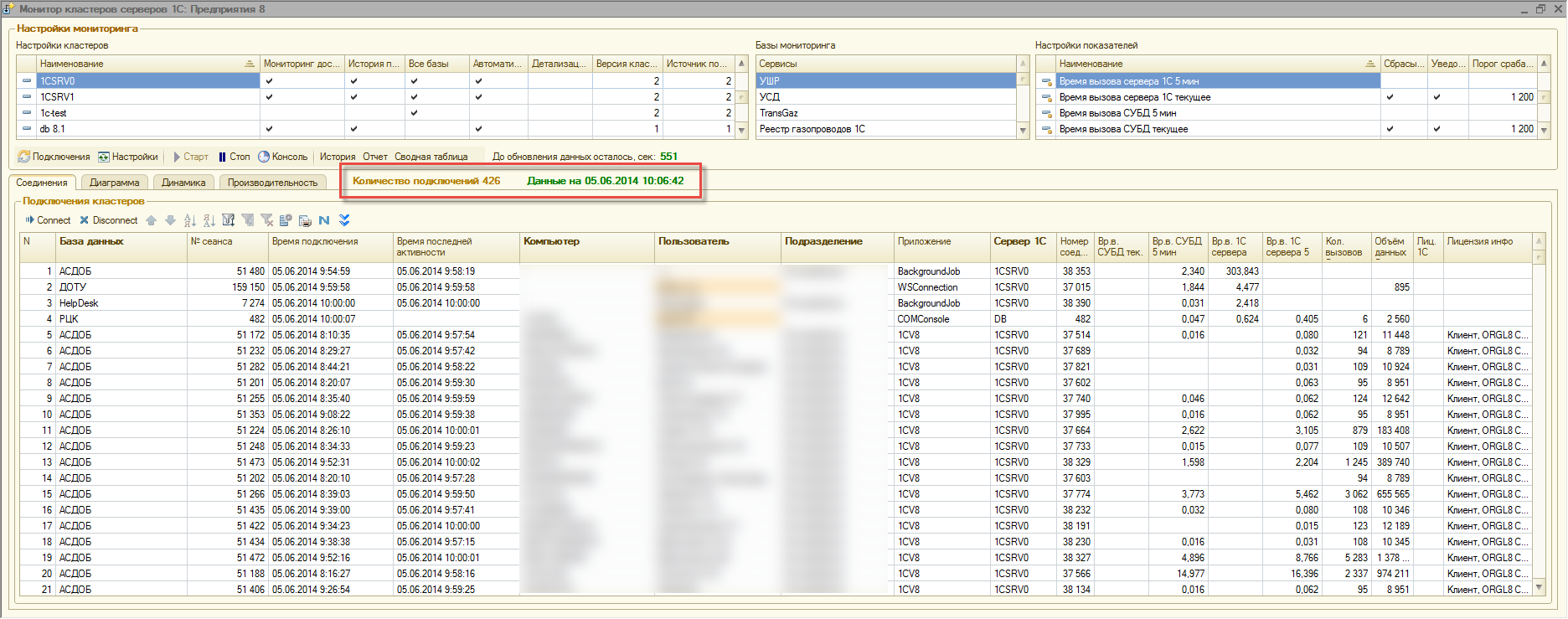
ну и раз уж пошли по скринам…. Вот интересная картинка
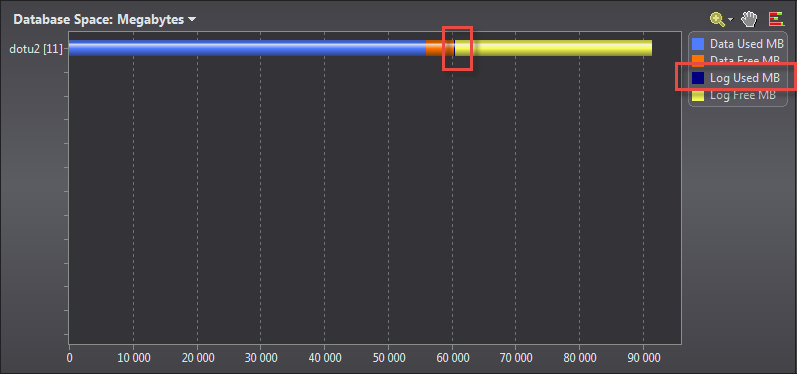
из 30 гигов журнала транзакций используются копейки, остальное — зерованный кусок файла, который уже понадобился когда то базе для выполнения запросов, поэтому «держится» sql сервером наготове.
Начали с того как зарубить журнал транзакций не смотря на то, что сервер почему то не дает, а кончили фразой вырванной из контекста «что отсутствие checkpoint в журнале влияет на время восстановления и резервного копирования». Типа как «Было бы величайшей ошибкой думать» В.И. Ленин.
насчет слепого с глухим согласен… и желание продолжать общение пропало. Тем более выяснилось что мы тут пользователями меряемся, и вообще оказывается факты работы sql уже даже и не факты, а так… Да Вы еще вдруг решили оценивать мои знания……
(20) adapter, Нуу если у вас 25 баз по 400 пользователей.. респект, что я ещё могу сказать. Если внимательно за базами следить, есть админ MS SQL , какие-ить Quest — овские (судя по скринам) продукты. Весь код написан правильно, прошел рефакторинг. Важно — не подключено ТО к базам… ещё лучше если на УФ, проблемы можно избежать.
Ну не буду я тут всю «матчасть» объяснять. Поэтому «из контекста». Хотя бы по-минимум сначала ознакомьтесь с с и с и всё о чём пишу там изложено. Этим вопросам уже 50 лет, любой админ SQL «делал это» хоть раз да приходилось, прекратите плз. «мусор в комменты»
минус в карму? детский сад 🙂
вы бы сами почитали ссылки эти. А то прям нарочно не придумаешь. там как раз описано как sql сервер зацикливает журнал
(22) adapter, Ткну пальчиком в книжечку Как в детском садике, кстати :))) название «When log records remain active for a long time transaction log truncation is delayed, and potentially the transaction log can fill up» переводить на русский не буду, сорри. В кратце там написано что всё это работает и работает круто, кроме перечисленных 14-ти причин :). Но чтобы вам это всё понять изначально лучше начать читать с первой статьи…
Блин, давайте не путать теплое с мягким. В ссылке приведены возможные причины задержки усечения журнала транзакций. Ваша статья про сжатие файла журнала. Это принципиально разные вещи.
Усечение (truncate) системный процесс который происходит на сервере автоматом, происходит на логическом уровне, на уровне чекпоинтов и напрямую связан с механизмом зацикливания, поэтому в 99% не влияет на физический размер файла.
Сжатие (shrinkfile) — физическое уменьшение размера файла, сервер дает его эффективно выполнить только после логического усечения, закрытия зависших, выполнения бакапа и пр. условий.
Вы же сами это наглядно показали в первом t-sql скрипте статьи и всех последующих ссылках, которыми пытались что то доказать мне. Кстати спасибо, мне даже гуглить не пришлось 🙂
Хорошо конечно что мы тут с вами затеяли этот древний холивар. Народ почитает, задумается. Плохо только что Ваш стиль общения как то направлен на попытки уязвить оппонента. Вам не идет.
В статье не хватает главного — причины уменьшения журнала транзакций? Кому и для чего это надо?
(24) adapter,
А в принципе человека начинает интересовать Transaction Log если он «не сжимается», а не сжимается он потому что «не усекается». В первом скрипте BACKUP LOG Имя_Базы_Данных WITH TRUNCATE_ONLY — это усечение. И по сути 99% статьи про него. Но рад, что вы наконец то разобрались…
P.S. если бы не фраза «Работает не трожь» которая для меня как «красная тряпка» конечно стиль был бы другой.
(24) adapter,
Причина одна, нужно быстро освободить закончившееся место на диске.
1) сломалась СРК
2) выполнялась регламентная операция обслуживания бд или иб 1с.
3) выполнялись большие массовые изменения данных
4) выполнялся «неоптимальный код»
я рад что вы тоже разобрались чем одно от другого отличается. Потому что в статье каша. И в ссылках что вы приводите тоже. То вы отрицаете что журнал кольцуется, то «съезжаете» что речь идет о сжатии. Хотя вначале статьи явно сказано что вот мол новый скул не дает сжимать (не работает DBCC SHRINKFILE), и вот вам обходные маневры ….
Да все еще агрессивно и с мнимым превосходством. Фу гадость.
(27) adapter,
О_о
(27) adapter,
я больше так не бууудууу… он пееервый начааал :). Всё, «давайте жить дружно».
Согласен. мир, дружба, жвачка 🙂
Подскажите, пожалуйста, а как могло получится, что select log_reuse_wait_desc from sys.databases возвращает для базы Replication, если репликацию никто никогда не настраивал?
(31) HolodZar, По-моему при восстановлении из бэкапа такие глюки бывают…
(32) спасибо.
Статья пригодилась.
подключение базы без лога
EXEC sp_attach_single_file_db @dbname = ‘Имя_Базы’,
@physname = ‘полныйпутьИмя_Базы.mdf’
Этот пункт нужно выполнить взамен всем пунктам с 3 по 12 последнего способа
будет выдано такое сообщение
Сбой при активации файла. Возможно, физическое имя файла «полныйпутьИмя_Базы.LDF» неправильное.
Создан новый файл журнала «полныйпутьИмя_Базы.LDF».
при реструктуризации журнал вырастит
Хорошие заметки, но по мне лучше их не применять вообще, лучше потратить время на разработку плана обслуживания, чем потом веселиться с оптимизацией и восстановлением баз, с непредсказуемым результатом.
(36) сделал план обслуживания на полный бекэп и бэкап лога, а толку — лог разросся до 125 гигов при базе в 10 гигов.
Помог способ 2 — оказалось лог ощищается только при повторном (двойном) бэкапе и шринке, а в первый раз уменьшается незначительно.
(37)Нет, лог очищается после резервного копирования, у вас скорее всего были проблемы в базе или с лог файлом(в момент резервного копирования открылась долгая транзакция, зависшие транзакции, ошибки в базе) поэтому сервер не смог урезать файл, второй раз проблем такого рода не было. по пробуйте скорректировать план так что бы к базе было минимум обращений к базе, за синхронизируйте фоновые задания с планом быкапа.
Из документации:
Урезание логов производится автоматически, в зависимости от модели восстановления:
• В простой модели (Simple) — после достижения контрольной точки;
• В модели полного восстановления (Full) — после создания бэкапа логов, при условии что со времени предыдущего бэкапа была достигнута контрольная точка.
А все остальное, это если что-то сломалось.
А если такая статья возникала, значит у вас полная модель восстановления, и не настроен корректно бекап транзакций.
(39)
Да вообще наша работа это только «если что-то сломалось» :))))