Вступление (лирическое)
В работе программистов иногда встречаются задачи, которые не имеют общеизвестных методов решений, и, даже, если они находятся, то не всегда подходят под ваш алгоритм. В такие моменты приходится включать сообразительность на полную катушку и проводить с поставленной задачей практически круглые сутки, обдумывая и проверяя все новые подходы к ее решению.
Итак, мне досталась задача, которая по постановке напоминает транспортную задачу открытого типа и решать ее нужно было непременно в запросе. Сохранившиеся в памяти фрагменты университетского курса по этой проблеме ответов не дали. Поиски в интернете тоже ничем полезным не закончились. Однако в голове сохранялось четкое ощущение того, что решение существует и достаточно простое.
В итоге, примерно за неделю проб и ошибок, было найдено решение, которое можно использовать даже не вникая в методику его получения. Но, думаю, большинству читателей будет интересно проследить ход моих мыслей и проверить их.
Дисклеймер
Собственно, написать эту статью мне было гораздо тяжелее, чем снова придумать то самое решение. От успешно решенной интересной проблемы я получил удовлетворение, а от статьи… Именно поэтому написание текста было отложено на месяц, чтобы собраться с мыслями, а потом еще в течение нескольких месяцев усилием воли приходилось заставлять себя заниматься ее проработкой. Так прошло более полугода.
То, что вышло — это труд, который, тем не менее, ни на что не претендует. А данная публикация является реализацией моего желания сделать “вклад в общее дело”. Какой он вышел, таким и останется.
И второе. Предложенное решение не решает транспортную задачу в ее классической постановке (мы не найдем таким образом оптимальное решение), так как рассматриваем лишь частный случай. Но, все же, полученный результат будет близок или повторять опорный план, найденный методом “северо-западного угла”.
Часть 1. Теоретические основы
Вначале я предполагал, что статья будет содержать только отсылки к источникам, которые необходимы для понимания алгоритма. Но после того, как я представил свое решение коллегам-разработчикам, стало ясно, что читателю будет легче воспринимать материал “от простого к сложному”. В то же время, если намеренно исключить из статьи несколько страниц, то она наоборот будет выглядеть сложной и непоследовательной.
Поэтому в первой части содержится краткое описание того базового знания (с собственными иллюстрациями), которое пригодилось мне.
Если вы уже знакомы с этим материалом и хорошо себе представляете то, о чем идет речь, можете смело первую часть пропускать.
1.1 Списание партий товаров
Первое, что напоминает транспортная задача — это списание партий товаров. Тогда было принято решение прорабатывать проблему в этом направлении.
Ранее мне попадалась на глаза статья Срез последних на каждую дату в запросе (kb.mista.ru), а позднее и такая Использование нарастающих итогов в партионном учете и не только (nashe1c.ru). Последняя вселила в меня надежду, что решение существует и для моей проблемы.
1.2. Срез последних на каждую дату в запросе
Этот пункт знакомит читателя с идеей соединения таблицы самой с собой.
Задача состоит в том, чтобы, например, для всех документов за определенный период пересчитать суммы из одной валюты в другую. Сложность в том, что для курсов валют могут не существовать записи на конкретную дату документа и нужно взять более раннюю запись по той же валюте, поскольку она считается действующей (например, документ находится в выходном дне, а курс валют был установлен в пятницу).

Решение изображено схематически и разбито на группы. Первая группа представляет собой исходную таблицу курсов валют, а вторая — даты документов, для которых мы получаем курс. В третьей группе мы соединяем эти две таблицы по условию ПериодКурса, в результате чего получаем избыточное количество записей. Но достаточно сгруппировать их по дате документа и выбрать максимальное из значений ПериодКурса, как мы получим требуемую таблицу. Она изображена справа в четвертой группе (обратите внимание, что для даты документа 3 января мы получили курс на 31 декабря — что и требовалось). Останется только присоединить к ней исходную таблицу из первой группы, чтобы получить готовый результат.
Для упрощения мы рассмотрели только одну валюту, но вы должны понимать, что дополнительные условия в запросе по валюте никто не отменял.
1.3 Списание по партиям в запросе (вычисление нарастающего итога)
Этот пункт является логическим продолжением предыдущего и демонстрирует читателю еще одну возможность использования соединения таблицы с самой собой.
Всем известна задача списания партий при продаже товаров. В классическом варианте решения она предусматривает получение запросом остатков товаров в разрезе партий и последующий перебор всех строк для нахождения тех, которые были израсходованы.
Такой подход выбивается из актуальных тенденций, когда все движения для документа конструируются запросом, откуда загружаются сразу в коллекцию движений. Приходится получать “сырые” данные, выгружать их в таблицу, обрабатывать и загружать обратно в движения.
Тем не менее, получить уже готовый перечень партий для списания запросом можно. Для этого таблицу партий необходимо будет соединить с ней же.

На рисунке изображена Таблица 1. Это таблица неизрасходованных партий. В системе она, скорее всего, представляет собой таблицу остатков регистра накопления. Таблица 2 — это та же самая таблица неизрасходованных партий. Левым соединением мы соединяем Таблицу 1 с Таблицей 2 по условию Таблица 2.Партия < Таблица 1.Партия. Это означает, что для каждой партии из Таблицы А мы получим те партии из Таблицы Б, которые располагаются выше нее.
Такое соединение позволит нам сгруппировать полученную таблицу по всем полям из Таблицы 1 (включая числовые!), а поле Количество Таблицы 2 просуммировать. В итоге, мы получим Таблицу 3, в которой будем видеть для каждой партии не только количество единиц в текущей строке, но и сумму всех предшествующих строк. Это означает, что мы вычислили нарастающий итог для таблицы партий.
Теперь осталось только его правильно задействовать.

На рисунке изображена Таблица 5, которую мы получили на предыдущем шаге, и Таблица 4, в которой содержится товар(ы) который нужно списать в разрезе остатков партий. Эти таблицы мы соединяем левым соединением (как схематически изображено на рисунке), чтобы получить Таблицу Д. Эта таблица позволит нам увидеть не только возможное размещение строки товаров во всех партиях, но и вычислить конкретные числовые значения для списания из каждой партии.
Делается это следующим образом:
- логическим выражением
Минимум(КоличествоПартии, КоличествоТовара — НарастающийИтогПартии)
- в терминах языка запросов
ВЫБОР
КОГДА КоличествоТовара > КоличествоПартии + НарастающийИтогПартии
ТОГДА КоличествоПартии
ИНАЧЕ КоличествоТовара — НарастающийИтогПартии
КОНЕЦ
Разъяснение здесь простое.
Для случая а). Второй аргумент — это ни что иное, как остаток товара, который еще не был размещен в предыдущих партиях. Для первой строки остаток товара будет равен значению Количество Товара. Для последующих значение будет уменьшено на величину израсходованного. Использование функции Минимум позволяет взять минимальное количество из величины текущей партии и величины товара, оставшейся для размещения в этой партии. Для той строки, на которой количество товара закончится, мы возьмем последний остаток, который будет меньше, чем текущая величина партии. Все последующие строки получат отрицательное решение, поскольку Нарастающий итог будет превосходить количество товара, что означает, что все количество было размещено выше.
Случай б) описывает тот же принцип, но без использования математической функции Минимум (в запросе Минимум будет агрегатной функцией — приходится выкручиваться). Словесное описание следующее. Если товара в текущей строке больше чем в сумме количества накопленного итога и количества текущей партии, то мы расходуем партию целиком (это значит, ни эта строки, ни предыдущие не смогли полностью закрыть требуемое количество товаров). Во всех остальных случаях мы берем разность между количеством товара и нарастающим итогом по партиям. Для последней строки мы также получим последний остаток товара. А все последующие строки будут отрицательными.
В качестве результата мы возьмем только те строки, где значение в колонке Решение больше нуля.
Примечание 1. Мы снова рассматриваем решение только для одной товарной позиции, поэтому в соединении таблиц не присутствует условие по товару.
Часть 2. Постановка задачи и решение
2.1 Постановка задачи
Итак, передо мной была поставлена следующая задача. На склад регулярно поступают различные товары. Все они предварительно заказываются у поставщиков, что отражается в системе документом Заказ поставщику. Далее оформляется Поступление товаров и услуг — о нем вы все знаете. Тем не менее, нередки ситуации, когда менеджер не успевает оформить Заказ поставщику и принимаемый товар записывается как излишек. Если с течением времени будет введен документ Поступление товаров и услуг по этому Заказу, то товар снимается с излишков и все — он уже на складе. А если нет, то имеет место ошибка поставщика, который отгрузил лишний (или вовсе не тот) товар. С течением времени это станет очевидно и его придется вернуть или оплатить.
Уже исходя из этой формулировки можно увидеть, что задача потребует списания излишков по партиям. Здесь партии — это документ Ордер на отражение излишков, который приходует товар на склад, а Поступление товаров и услуг с его табличной частью Товары будет эти партии расходовать. Однако, это еще не все.
Заказы поставщику формируются ответственным менеджером в течение всего дня, а привозят товар фактически вечером (с запозданием в несколько дней), и документ Поступление товаров и услуг вводится один. Это означает, что один такой документ будет содержать информацию из нескольких заказов, и, как один из вариантов, будет содержать повторяющиеся строки номенклатуры (повторения внутри заказа исключены).
Здесь и возникает сложность. Если использовать существующий алгоритм с нарастающими итогами, то для каждой повторяющейся строки товаров он вернет одинаковую последовательность партий для списания, что неправильно. Вторая строка должна получить уже измененную последовательность партий или иметь возможность вычислить остаток в партии по текущим данным строки.
Естественно, задача должна решаться непосредственно в запросе.
Выходит, что партий в задаче две: партии излишков (в документах Ордер на отражение излишков) и партии заказов (в документах Поступление товаров и услуг). Существующая методика не подходит, хотя мысль использовать нарастающий итог по обеим таблицам кажется вполне естественной.
2.2 Транспортная задача
Что пришло в голову первым, когда описание задачи было усвоено? Она очень походит на транспортную задачу открытого типа (ведь любая из партий может израсходоваться не полностью). Решать транспортную задачу запросом никто до меня не пробовал или пробовал, но не описал, или описал, но не на том языке. Во всяком случае, я ничего похожего не нашел.
На рисунке изображено решение Транспортной задачи открытого типа методом северо-западного угла. Меня бы, на самом деле, устроил любой метод, лишь бы найти опорное решение. Никакой целевой функции нет, как нет и затрат на “перевозку”.

В шапке таблицы (меня учили, что там Потребители) размещаем партии излишков. В строках таблицы (Поставщики) размещаются строки заказов. Одна такая таблица позволит найти решение только по одной товарной позиции. Так что, на самом деле мы имеем дело с трехмерной транспортной задачей.

Не смотря на то, что общеизвестного решения мне найти не удалось, интуиция почему-то подсказывала, что оно существует, причем достаточно простое.
2.3. Таблица пересечений
Сходство формулировки моей проблемы с транспортной задачей ничего нового, кроме самого этого факта не принесло. Так что, пришлось вернуться к исходной мысли о том, чтобы построить две таблицы с нарастающим итогом по строкам и решать задачу используя подход рассмотренный в статье Использование нарастающих итогов в партионном учете и не только.

Итак, в качестве примера мы имеем таблицу товаров (Таблица 7). Товар (Номенклатура) здесь обозначен как Н1, а номера строк — С1, С2, С3 и т.д. Третьим столбцом имеем количество товара (в нашем случае, в документе), а в четвертом уже рассчитанный нарастающий итог.
В Таблице 8 представлена таблица излишков. Обозначения товаров совпадают. Партии обозначаются П1, П2, П3 и т.д. И также, как и в таблице товаров, уже рассчитан нарастающий итог.
Требуется сформировать некую “карту” распределения строк товаров на строки излишков, чтобы использовать эту таблицу и для выборки излишков, которые были списаны в результате операции приема, и для выборки строк товаров, которые необходимо принять на склад (за минусом излишков, которые уже в наличии).
В рамках приведенного примера таблица должна выглядеть так, как изображено в Таблице 9.
Таблица 9 представляет собой результат соединения Таблицы 7 с Таблицей 8 с добавлением одной единственной колонки, в которой должно быть рассчитано решение.
Вначале мной предпринимались неоднократные попытки подобрать формулу или набор условий, чтобы на их основе заполнять Таблицу пересечений. Однако локальный успех в рамках одних исходных данных сменялся неудачей при изменении последних.
Пришлось применить научный подход к решению.
2.4. Статус строки
Невозможность решения задачи сходу показала, что необходимо разработать некоторую теоретическую основу, которая, с одной стороны, позволит все систематизировать, с другой, избежать очевидных ошибок в суждениях. Так появилось понятие Статус (состояние) строки.
Если рассматривать процесс заполнения Таблицы пересечений последовательно (сверху вниз), то мы увидим, что каждая строка из таблицы Товаров будет рассматриваться в качестве исходных данных несколько раз. При этом необходимо знать и количество товара израсходованное на предыдущих шагах, и, сколько нам нужно взять в данный момент.
То же самое относится и к строкам таблицы Партий. Мы должны понимать, какой остаток этой партии мы имеем с учетом предыдущих итераций.
Легко заметить, что строки обеих таблиц буду находиться в одном из трех состояний:
- Свободная строка — все предшествующие обращения к строке ее не задействовали, либо эта строка рассматривается впервые.
- Частично задействованная строка — некоторое количество товара (партии) из данной строки было использовано на одной или несколько предыдущих итерациях.
- Полностью израсходованная строка — товара (партии) в данной строке не осталось совсем. На предшествующих итерациях он был израсходован без остатка.
Исходя из предложенного описания, нам не хватает всего одного показателя — остаток товара (партии) в текущей строке. Причем этот параметр должен вычисляться из уже имеющихся четырех характеристик строки Таблицы пересечений.
Комбинация трех статусов партий и трех статусов товаров дает нам 9 возможных сочетаний. Для каждого из этих сочетаний формула расчета будет скорее всего своя. Для наглядности построим таблицу.

В таблице 10 схематически изображены статусы строк таблицы Товаров (в строках) и статусы строк таблицы Партий (в столбцах). На пересечении строки и столбца необходимо указать выражение (или константу), которое позволяет вычислить решение из имеющихся данных.
2.5. Вычисление остатка строк
Теперь осталось лишь найти правило, которое позволяет однозначно вычислить текущий остаток партии или текущий остаток товара на любом шаге алгоритма. Схематически это изображено на следующем рисунке.

Рассмотрим статусы строк в порядке их следования независимо от сочетания друг с другом.
Новая строка товаров. Для этой строки характерно то, что накопленный итог по товарам превосходит или равен накопленному итогу по партиям, Ни >= Пи (напомню, что накопленный итог не учитывает значение текущей строки). Это значит, что все предыдущие строки товаров разместились в соответствующих строках партий, и текущая строка остается полностью неизрасходованной, потому что партий ей попросту не хватило.
Если выполняется равенство, то это означает, что предыдущая строка товаров полностью разместилась в каких-то строках партий. В случае неравенства, предыдущие строки товаров остались не полностью израсходованными, а значит, до текущей строки дело так и не дошло.
Остаток строки товаров в данном случае равен значению количества в текущей строке, Но = Нт.
Частично задействованная строка товаров. Для этой строки характерно обратное неравенство, Ни < Пи. Это значит, что партий было больше, чем строк с товарами, а значит, что из текущей строки мы взяли какое-то количество. Но как вычислить это количество?
Представим перед собой чашечные весы. С правой стороны на них условно лежит итог по партиям. С левой стороны — итог по товарам. И весы, естественно, клонятся вправо. Предположим, что строка товаров была израсходована не полностью. Тогда, если мы поместим на левую сторону текущее количество товаров, то весы начнут перевешивать влево, потому что задействованная часть, назовем ее Нх, вместе с итогом по товарам будут равны итогу по партиям, Ни + Нх = Пи. В то же время остается еще неизрасходованный товар, остаток, который и перевесит чашу.
Нетрудно заметить, что Но + Нх = Нт. В таком случае, путем нехитрых преобразований, получаем Но = Нт + Ни — Пи.
Полностью израсходованная строка товаров. Эта проверка всегда должна быть первой, поскольку принцип ее определения немного отличается от двух других.
Строка товаров считается полностью списанной, если накопленная сумма по партиям превосходит или равна по значению сумме товаров в текущей строке и накопленного итога по товарам, Нт + Ни
Это факт просто пояснить на предыдущем примере с весами. Если при помещении на левую сторону текущего количества товаров положение весов не меняется или выравнивается, то строка товаров уже участвовала в распределении предыдущих строк и была полностью списана там, а значит здесь мы должны получить ноль, Но = 0.
2.6. Построение формулы
Предыдущий пункт дал нам в руки формулы для вычисления недостающих переменных. Остается только составить из них единую конструкцию, которая для двух произвольно выбранных строк позволит вычислить количество, которое будет списано из обеих.
Итак, предыдущий рисунок дает нам универсальную формулу для вычисления результата:
Минимум (
Но,
По
).
Попробуем обобщить формулы для вычисления Но.
| № | Результат | 1 | 2 | Условие | |
| 1) | Но = | Нт | при условии Ни >= Пи | ||
| 2) | Но = | Нт | + | Ни — Пи | при условии Ни < Пи |
| 3) | Но = | 0 | при условии Нт + Ни <= Пи |
Рассмотрим приведение второго случая к первому. Мы можем заменить второе слагаемое нулем, при соблюдении условия первого равенства. Очевидно, что при выполнении второго условия второе слагаемое меньше нуля, в отличие от первого условия.
Таким образом, мы можем составить универсальное второе слагаемое, которое будет представлять из себя следущюее выражение:
Минимум (Ни — Пи, 0).
При положительной разности функция всегда даст ноль, а при отрицательной превратится в выражение второй строки.
| № | Результат | 1 | 2 | Условие | |
| 1) | Но = | Нт | Минимум (Ни — Пи, 0) | при условии Ни >= Пи | |
| 2) | Но = | Нт | + | Минимум (Ни — Пи, 0) | при условии Ни < Пи |
| 3) | Но = | 0 | при условии Нт + Ни |
Тогда искомое выражение примет вид, с учетом зеркальности статусов строк,
Минимум (
Нт + Минимум (Ни — Пи, 0),
Пт + Минимум (Пи — Ни, 0)
)
Обратимся к третьей строке. Преобразуем условие следующим образом:
Нт + Ни — Пи
Часть выражение Ни — Пи нам уже знакома. Именно она делает все выражение отрицательным. И это отрицательное значение выйдет из под выражения
Минимум (0, Ни — Пи).
Более того, этого отрицательного значения будет достаточно, чтобы в сумме с Нт снова остаться отрицательным.
С учетом сказанного преобразуем формулу вычисления решения, исключив возможность появления отрицательного результата.
| № | Результат | Выражение |
| 1) | Но = | Максимум ( Нт + Минимум ( Ни — Пи, 0 ), 0 ) |
| 2) | Но = | Максимум ( Нт + Минимум ( Ни — Пи, 0 ), 0 ) |
| 3) | Но = | Максимум ( Нт + Минимум ( Ни — Пи, 0 ), 0 ) |
То же самое проделаем для формулы общего решения. В результате чего получим окончательную формулу.
Минимум (
Максимум ( Нт + Минимум ( Ни — Пи, 0 ), 0 ),
Максимум ( Пт + Минимум ( Пи — Ни, 0 ), 0 )
)
Далее остается не самое сложное занятие — преобразовать эту формулу в выражение на языке запросов 1С.
ВЫБОР
КОГДА ТаблицаНоменклатуры.ТекущееКоличество + ТаблицаНоменклатуры.Итог <= ТаблицаПартий.Итог
ИЛИ ТаблицаПартий.ТекущееКоличество + ТаблицаПартий.Итог <= ТаблицаНоменклатуры.Итог
ТОГДА 0
КОГДА ТаблицаНоменклатуры.ТекущееКоличество + ВЫБОР
КОГДА ТаблицаНоменклатуры.Итог < ТаблицаПартий.Итог
ТОГДА ТаблицаНоменклатуры.Итог — ТаблицаПартий.Итог
ИНАЧЕ 0
КОНЕЦ < ТаблицаПартий.ТекущееКоличество + ВЫБОР
КОГДА ТаблицаПартий.Итог < ТаблицаНоменклатуры.Итог
ТОГДА ТаблицаПартий.Итог — ТаблицаНоменклатуры.Итог
ИНАЧЕ 0
КОНЕЦ
ТОГДА ТаблицаНоменклатуры.ТекущееКоличество + ВЫБОР
КОГДА ТаблицаНоменклатуры.Итог < ТаблицаПартий.Итог
ТОГДА ТаблицаНоменклатуры.Итог — ТаблицаПартий.Итог
ИНАЧЕ 0
КОНЕЦ
ИНАЧЕ ТаблицаПартий.ТекущееКоличество + ВЫБОР
КОГДА ТаблицаПартий.Итог < ТаблицаНоменклатуры.Итог
ТОГДА ТаблицаПартий.Итог — ТаблицаНоменклатуры.Итог
ИНАЧЕ 0
КОНЕЦ
КОНЕЦ
Возможно, существует и более простое выражение, но я использую это.
Часть 3. Анализ результата
3.1 Запрос VS Цикл
Сразу стоит признать, что я не тратил времени на оптимизацию данного алгоритма, а только попытался понять есть ли выигрыш от использования запроса или нет.
Была написана небольшая обработка, которая решает случайно сгенерированную задачу двумя способами и, если позволяет платформа (8.2.17+), выводит затраченное время в миллисекундах. Моя практика запуска этой обработки на файловой и клиент-серверной базах показывает двукратное преимущество запроса перед программной обработкой.
Возможно, существует способ улучшить программный поиск решения в цикле. Мне ничего нового придумать не удалось. Этот момент я полностью отдаю вам на откуп.
Колоссальный плюс данного решения в том, что все выполняется в рамках нескольких запросов.
3.2 Демонстрация возможностей внешней обработки
Про обработку будет совсем кратко. Она имеет всего четыре настройки: размерность товаров/партий, которые задают количество строк в одноименных таблицах, и максимум в товарах/партиях, которые ограничивают значение колонки количество сверху.
На первой закладке формы расположены сформированная таблица товаров (слева) и таблица партий (справа).
.png)
В командной панели всего две кнопки и их назначение очевидно. Нажатие кнопки Решение приводит к заполнению таблиц на второй и третьей закладке, сравнению результатов и выводу замеров времени.
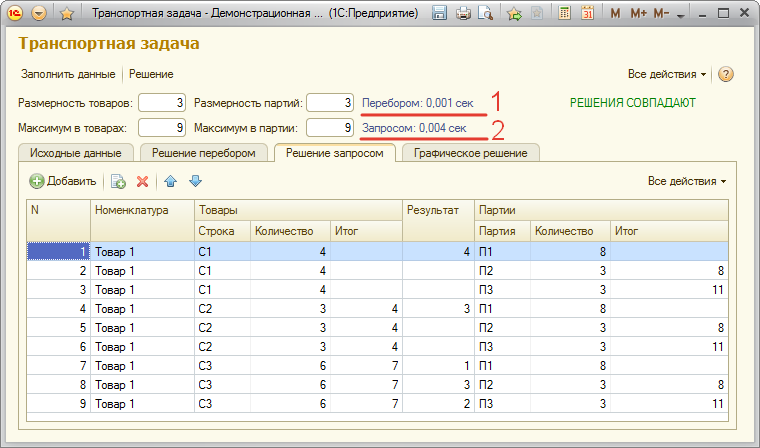
Табличный документ на четвертой закладке заполняется, только если размерность не более 10, иначе СКД начинает тормозить.
.png)
Вот и все!
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Отличное оформление!
Для полноты картины добавлю пару ссылок:
1) — описание не такое детальное и наглядное, но задача та же и условие соединения в запросе чуть проще. Кстати, в комментарии к той статье дается оценка быстродействия запросного метода. Она совсем не такая оптимистичная, как в этой статье, но на примере списания остатков заказов этого заметно не будет. Также в комментарии приведен рисунок — ментальная модель, используемая при синтезе запроса. Это два стоящих рядом столбика приходов и расходов, общие отрезки в которых и образуют результат. Двумерная модель транспортной задачи, приведенная в данной статье, очевидно, нагляднее.
2) — также говорится об использовании аналогии между списанием по партиям и транспортной задачей, правда для скорости она решается не запросом, а программно. Обратите внимание на скриншоты хода решения задачи — они очень похожи на рисунки из статьи.
Ну и остались вопросы по постановке задачи. Что-то из серии «угадал все буквы, но не смог назвать слова» (это я про себя). Понятно, когда есть несколько заказов и требуется закрыть их одним поступлением. Тогда закрываем их по ФИФО. Например, заполняем товары и количество, затем запускаем обработку заполнения табличной части и она разбивает строки по заказам. То есть запрос в ОЗТЧ? Но почему не свернуть ТЧ по одинаковым товарам перед вызовом ОЗТЧ. Это ведь сам подбор делает (серии?). Как кладовщик решает, что заказа нет? В этом случае оформляет ордер? В какой момент на ордер поступление делается? То есть непонятна роль ордера и причины возникновения строк с одинаковым товаром. Или обработка одним запросом сразу много поступлений обрабатывает? — Разъясните, пожалуйста!
(1), спасибо за отзыв.
Интересные ссылки! Жаль, что они мне не попались в процессе работы над задачей.
В первой статье, действительно, интересное решение и его проще осознать. Я бы добавил туда несколько иллюстраций.
Над оценкой трудоемкости запроса я задумался. Мой перебор далеко не оптимален, у него трудоемкость О(n * m). Да и запросы на стороне SQL, как я понимаю, приводят к полному соединению таблиц, и только потом применению условия (я клоню к тому, что трудоемкость не должна делиться на два n * m
/ 2) . Пусть даже так, но почему тогда запрос отрабатывает быстрее? На досуге я над этим поработаю.Мне показалась, что здесь есть над чем подумать. Например, что будет, если я выберу сначала только интервалы из двух таблиц, отсортирую и соединю их с двумя другими таблицами по условию попадания в интервал? Не получится ли сразу искомая таблица?
По поводу постановки задачи. В статье я немного упростил ее. Возможно, в этом причина вопросов.
Начну с кладовщика. У него свой АРМ. В нем он просто сканирует штрихкод товара и переносит его в табличную часть. По нажатию кнопки «Принять» АРМ делает за него всю работу: анализирует остатки по Заказам поставщику, по Поступлениям товаров и услуг и создает соответствующие документы. Если поступления нет — перед нами излишек (Ордер на излишки), а если есть — обычный товар (Приходный ордер на товары). В целях сохранности товара кладовщик не знает какой документ был создан.
А теперь интересное. Нет никакой ОЗТЧ. Сам запрос в обработке проведения (о, ужас!). Подбор в поступление позволяет выбрать только товары из заказов, пусть, даже, нескольких. Таким образом, эти строки никогда не свернутся.
В момент проведения Поступления мы должны закрыть два взаимосвязанных регистра: +Товары к поступлению (какие товары предстоит принять на складе), -Излишки (какие товары из этого поступления уже находятся на складе). Если мы находим товар в излишках, значит, в Товары к поступлению мы его не пишем.
Надеюсь, я не слишком выболтал бизнес-процессы фирмы, и Вам стало яснее.
Шикарно оформлено, прям курсовая работа. И задача интересная.
Однозначно ставлю +, не перевелись ещё на форуме специалисты)))
Это конечно все интересно. Но мне кажется, что в этом примере нет чистоты эксперимента, а именно:
1. Исходный массив данных. На примере рассматривается не большой массив данных тут и так понятно что прямой перебор справится быстрее SQl (SQL — это как межгалактический челнок, но его нужно разогнать). Было бы интересно посмотреть графики скорости с нарастанием объема обрабатываемых данных до сотен тысяч позицый.
2. Может я и ошибаюсь но в эксперименте данные обрабатываются из виртуальной таблицы значений(из кэша памяти), а не поднимаются с файловой системы. В этом случае прямому перебору данные предоставили прямо на блюдечке.
Вот это я понимаю подход! Все с разъяснениями. Подобного рода задачи постоянно приходится решать, например, в ЗУПе когда НДФЛ нужно грамотно перекрыть и не держать остатков по периодам или перекрыть любой отрицательный остаток по регисту положительными остатками по этому же регистру. Но то что это Транспортная задача я даже не задумался.
Спасибо!
Дельный материал доступным языком.
(5), вы немного все переиначили.
То есть, действий запросный метод выполняет больше.
Поставил + за изложение. Но вот за это :
«нередки ситуации, когда менеджер не успевает оформить Заказ поставщику и принимаемый товар записывается как излишек. Если с течением времени будет введен документ Поступление товаров и услуг по этому Заказу, то товар снимается с излишков и все — он уже на складе.»
нужно бить линейкой по рукам того, кто придумал (организатора учета) . Сильно, больно и долго.
Это не уменьшает теоретической и методической ценности статьи.
шикарное оформление, респект!
Спасибо
Оценил
Спасибо. интересно
Отличное практическое применение элегантной теории 🙂
Подскажите, пожалуйста, кто знает, как в примере с курсами валют реализовать на языке запросов следующее: «В третьей группе мы соединяем эти две таблицы по условию ПериодКурса, в результате чего получаем избыточное количество записей. Но достаточно сгруппировать их по дате документа и выбрать максимальное из значений ПериодКурса, как мы получим требуемую таблицу.»
(16), вы можете обратиться к статье , там есть то, что нужно.
(1) (17) так когда будет чектий и конкретный запрос на все эти «графы»?!
Все жду, что вот-вот, создадут идеальный запрос, который можно будет везде использовать без переписывания 2/3.
(17), спасибо. Из этой статьи я понял как объединить таблицу, содержащую все даты периода с колонкой дат известных остатков, а потом уже объединить с колонкой сумм известных остатков.
у Вас же присоединяются сразу две колонки и я не представляю, что потом с этой таблицей делать, чтобы выделить из нее нужное
Отличная статья. Все для производительности.