Внутренняя структура файла конфигурации (*.cf) не является секретом. Добрые люди давно разобрали его и создали немало интересных утилит, позволяющих работать с этим форматом. На Инфостарте найдется добрый десяток (если не больше) интересных публикаций, так или иначе читающих содержимое *.cf файлов, так что тема эта совсем не новая.
Однако, хорошей, добротной документации на этот формат, к сожалению, совсем немного. На написание данной статьи меня надоумила публикация глубокоуважаемого awa, который подробно, во всех деталях описал структуру формата файловой ИБ 1С:Предприятия (*.1CD).
Та статья, как мне кажется, стала катализатором для целого ряда разработок, созданных другими авторами. Открытость и доступность информации подтолкнула творческую активность авторов, а всё сообщество получило ряд отличных инструментов по работе с файловыми базами 1С.
Мне кажется, что подробное описание формата CF тоже сможет заинтересовать многих авторов, и, может быть, мы получим возможность увидеть массу новых интересных разработок на тему файлов конфигурации.
Предыстория
Как уже говорилось выше, структура формата давно известна и в сети есть информация по его структуре (хотя, довольно скудная). Мне эта информация понадобилась при разработке программы V8Viewer, работая над которой, я опирался на следующие материалы:
- //infostart.ru/public/15695/, автор brix8x
- http://www.richmedia.us/post/2011/01/18/cf-file-format-1c-8-compatible.aspx, если не ошибаюсь, автор – Elisy
- //infostart.ru/public/15867/, автор awa
Хочется выразить благодарность авторам, за то, что поделились информацией с народом.
Терминология
Перейдем непосредственно к теме нашего обсуждения.
Для того чтобы расставить точки над i, давайте определимся с названием самого формата.
Во-первых, в этом формате создаются не только файлы конфигурации, но также файлы внешних отчетов и обработок. В интернете мне попадалось название Compound-файл. Возможно, оно является устоявшимся среди старожилов 1С, но мне оно не очень нравится.
Предлагаю в рамках данной статьи называть данный формат «контейнер». Если уважаемая публика подскажет в комментариях правильное название, я буду очень рад.
Смотрим внутрь
Логической единицей хранения данных внутри контейнера является документ. Документ, это осмысленный законченный набор данных, который можно прочитать и каким-то образом интерпретировать. Я специально не пользуюсь термином «файл», поскольку, это название я приберегу для другой сущности, о которой чуть позже.
Итак, в общих чертах, файл CF (EPF/ERF) представляет собой контейнер, в котором хранятся документы.
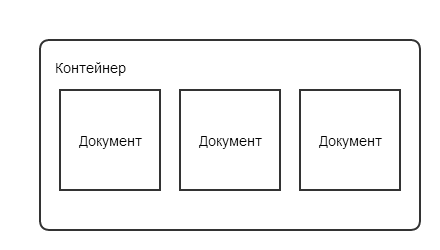
Каждый документ внутри контейнера может быть разбит на блоки. Минимальной физической единицей хранения данных является блок, но осмысленной логической единицей является документ. Иными словами, документы внутри контейнера могут лежать в виде разрозненных кусочков (блоков) и для того, чтобы прочитать содержимое документа, все его кусочки нужно собрать и объединить.
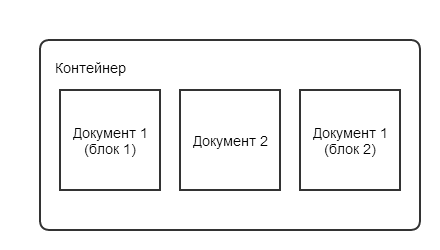
Структура контейнера
Контейнер включает в себя следующие части (по порядку):
- Заголовок контейнера
- Адрес первого пустого блока, в который можно добавлять данные
- Размер блока по умолчанию
- Количество файлов в контейнере
- Документ оглавления контейнера
- Собственно данные, которые перечислены в оглавлении
Для того чтобы прочитать содержимое контейнера, необходимо прочитать документ оглавления. Однако, поскольку, документ состоит из блоков, то прежде необходимо научиться собирать полный документ из этих самых блоков.
Структура блока
Блок состоит из заголовка и тела. В заголовке указывается общий размер всего документа, размер текущего блока и адрес (позиция в файле) следующего блока. Сразу за заголовком идет тело блока – собственно, те данные, которые нам нужны. Тело блока имеет ровно ту длину (в байтах), которая указана в заголовке.
Внутри контейнера тут и там встречается волшебная константа, обозначающая некую «пустоту» – это число 0x7fffffff.
Когда мы собираем документ из блоков, то смотрим в заголовке на адрес следующего блока. Если он равен 0x7fffffff, то «следующего» блока нет, этот – последний.
Константа 0x7fffffff — это значение INT_MAX, т.е. максимальное значение 4-байтового целого числа со знаком.
Логические «файлы»
Я упоминал, что термин «файл» я приберегу до лучших времен. Эти времена настали 🙂
Вся конфигурация хранится в контейнере в виде файлов. Если мы вспомним школьный курс информатики, то вспомним, что «файл», говорили нам – это именованный документ.
Файл отличается от «документа» тем, что у него есть имя, и по этому имени к нему можно обращаться. Если мы будем разбирать содержимое конфигурации и строить дерево метаданных, то найдем внутри файлов очень много упоминаний других файлов. Процедура чтения конфигурации оперирует именами файлов и ссылается на них по имени.
Если подвести итоги, то можно сказать следующее: в контейнере лежат разные документы, но некоторые из них имеют имя. Такие документы называются «файлы» и они носят не служебный, а непосредственно прикладной характер. Именно файлы хранят информацию о метаданных конфигурации.
Компоненты файла
Каждый файл состоит из двух документов:
- Документ атрибутов, который содержит имя файла и даты создания/изменения
- Документ содержимого, который содержит собственно тело файла
Оглавление контейнера
Теперь, когда все составные части озвучены, осталось рассмотреть, пожалуй, самый главный документ контейнера – документ оглавления, в котором указано расположение всех файлов контейнера. Как говорилось выше, документ оглавления это самый первый документ контейнера и он идет сразу же за заголовком контейнера.
Оглавление представляет собой массив записей, каждая из которых указывает на файл. Поскольку, файл состоит их двух документов (атрибуты и содержимое), то запись оглавления указывает на оба из них. Запись оглавления представляет собой три числа INT32:
- Адрес (смещение в файле) документа атрибутов
- Адрес (смещение в файле) документа содержимого
- Число 0x7fffffff (маркер конца записи).

Напоминаю, что каждый документ может быть разбит на блоки (фрагментирован). Алгоритм сборки документа из блоков будет рассмотрен ниже.
Запись оглавления представляет собой 2 значащих числа INT32. Первое число – это адрес документа атрибутов файла. По этому адресу мы попадем на начало 1-го блока документа атрибутов. Из документа атрибутов мы можем узнать имя файла. Второе число – адрес документа содержимого файла. По этому адресу мы попадем на начало 1-го блока документа содержимого, откуда будем читать непосредственно данные файла.
Особенности сжатия данных.
Контейнер может содержать самые разные файлы. Как правило, это текстовые файлы в кодировке UTF-8. Однако среди файлов контейнера могут встречаться другие файлы-контейнеры. Проще всего провести аналогию с файловой системой. Контейнер – это директория, а файлы внутри контейнера – это ее содержимое. Директория может содержать другие директории.
Корневой каталог этой «файловой системы» — это сам файл *.CF. Внутри него могут быть другие файлы-контейнеры, по сути – вложенные директории, которые считываются ровно по тому же самому алгоритму и имеют ровно ту же самую структуру.
Тем не менее, есть одна особенность корневой директории. Все документы содержимого файлов внутри корневой директории сжаты по алгоритму Deflate. Содержимое файлов внутри вложенных директорий уже не сжато. Проще говоря, на верхнем уровне файла-контейнера тела всех файлов сжаты, но если файл внутри контейнера сам является контейнером, то внутри него файлы уже будут записаны в чистом виде (без сжатия).
Цепочка свободных блоков
В результате удаления каких-либо данных из контейнера в нем могут образовываться пустые места. Эти свободные места связываются в цепочку и образуют этакий «документ», данные которого отсутствуют. Иными словами, свободные блоки связаны друг с другом по тому же принципу, по которому связаны друг с другом блоки документов. Адрес первого свободного блока указывается в самом начале заголовка контейнера. Если адрес свободного блока равен INT_MAX, то это значит, что в середине контейнера нет свободных (пустых) блоков.
Краткий итог по теоретической части
- Файл CF(EPF/ERF) записан в формате «контейнера»
- Контейнер начинается с заголовка
- Все содержимое контейнера, за исключением заголовка, записано в виде «документов»
- Документ может быть разбит на блоки
- Документ начинается с заголовка блока, по которому можно узнать, как прочитать весь документ целиком
- Сразу за заголовком контейнера идет документ оглавления
- Оглавление, это набор записей, которые указывают на «файлы» внутри контейнера
- Каждый файл состоит из двух документов – документа атрибутов, где указано имя этого файла и документа содержимого, где, собственно, расположены данные файла.
- Каждая запись оглавления содержит 2 адреса. Первый – адрес документа атрибутов файла, второй – адрес документа содержимого.
- Контейнер может содержать вложенные контейнеры (как бы, вложенные папки)
- Файлы внутри корневого контейнера сжаты по алгоритму Deflate, файлы внутри вложенных контейнеров записаны без сжатия.
Давайте уже пощупаем байты
Итак, настало время рассмотреть, как конкретно устроены все упомянутые выше сущности.
Основным способом чтения данных из контейнера является чтение цепочки блоков, составляющих те или иные документы. Кажется, что правильно будет начать с принципа чтения блочных документов.
Чтение документа по блокам
Каждый документ в контейнере обязательно начинается с заголовка блока. При этом документ может быть разбит на несколько блоков. Для того чтобы прочитать документ, необходимо его «собрать» из блоков.
Итак, заголовок блока представляет собой строку длиной 31 байт. Строка эта имеет следующий вид:
[CRLF][Размер всего документа][Пробел][Размер текущего блока][Пробел][Адрес следующего блока][Пробел][CRLF], где:
- CRLF – стандартный перевод строки Windows, пара символов
(0x0D,0x0A) - Размер всего документа – общая длина документа в байтах. Записана в виде строкового представления hex-числа. Длина – 8 байт.
- Пробел – пробел. Символ 0x20
- Размер текущего блока – длина тела блока в байтах. Записана также в виде строкового представления числа INT32 в hex-формате. Если документ состоит из единственного блока, то размер всего документа либо меньше, либо совпадает с размером текущего блока (что логично)
- Адрес следующего блока – адрес по которому расположен очередной блок документа. Если адрес следующего блока равен INT_MAX, то это значит, что следующего блока нет. Адрес следующего блока также записан в виде строкового представления числа.
Сразу за заголовком блока идет тело блока, которое имеет длину, указанную в поле «Размер текущего блока».
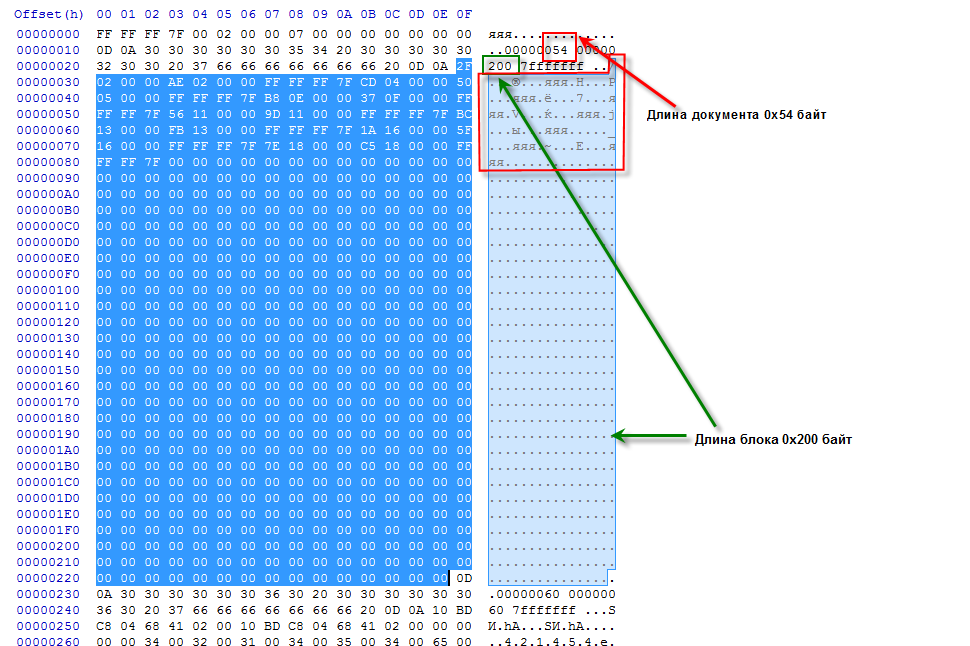
Рассмотрим рисунок: длина всего документа составляет 0x54 байта, красной рамкой выделены эти 0x54 байта. Это данные документа. Длина блока составляет 0x200 байт, т.е. больше чем длина самого документа. По этой причине остальные данные блока составляют «нули» неиспользуемого пространства. Значащие байты — это те, которые отмечены красной рамкой.
Если длина документа больше длины блока, то нужно прочитать следующий блок. Если в поле «Адрес следующего блока» записано значение, отличное от 0x7fffffff, то необходимо считать текущий блок, затем перейти по этому адресу и считать другой блок. Если в этом блоке также будет задан адрес следующего блока, то надо перейти и туда. Таким образом, формируется «цепочка» блоков, из которых состоит документ.
Чтение необходимо продолжать до тех пор, пока в поле «Адрес следующего блока» не встретится значение 0x7fffffff или пока не будет считано количество байт, указанное в поле «Размер всего документа».
Поле «Размер всего документа» имеет смысл только для первого блока. Во всех последующих блоках документа оно имеет значение 0x00000000.
Формат заголовка контейнера
Заголовок контейнера имеет длину 16 байт и состоит из следующих полей:
|
Поле |
Тип |
Пояснение |
|
Адрес первого свободного блока |
INT32 (4 байта) |
Смещение, по которому начинается цепочка свободных блоков |
|
Размер блока по умолчанию |
INT32 (4 байта) |
Блок может иметь произвольную длину, но значение по умолчанию можно использовать для добавления новых блоков, например. |
|
Поле неизвестного назначения (см. комментарии к статье) Часто совпадает с количеством файлов в контейнере |
INT32 (4 байта) |
Число, отражающее некоторую величину, как правило, совпадающую с количеством файлов в контейнере, однако, коллеги в комментариях считают, что это не совсем так. На алгоритм интерпретации контейнера данное число никак не влияет, его можно игнорировать. |
|
Зарезервированное поле |
INT32 (4 байта) |
Всегда равно 0 (всегда ли?) |
Формат записи документа оглавления
Оглавление содержит перечень указателей на файлы, размещенные в контейнере
|
Поле |
Тип |
Пояснение |
|
Адрес документа атрибутов |
INT32 (4 байта) |
Адрес документа атрибутов файла |
|
Адрес документа содержимого |
INT32 (4 байта) |
Адрес документа содержимого файлов |
|
Зарезервированное поле |
INT32 (4 байта) |
Всегда равно 0x7fffffff |
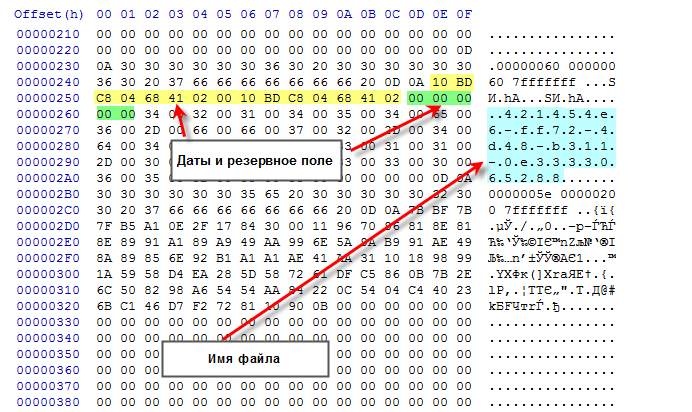
Формат документа атрибутов файла
Документ атрибутов описывает имя файла и даты его создания/изменения.
|
Поле |
Тип |
Пояснение |
|
Время создания файла |
UINT64 (8 байт) |
Время создания файла, выраженное в количестве 100-микросекундных интервалов, прошедших с начала нашей эры (01.01.0001 00:00:00) |
|
Время изменения файла |
UINT64 (8 байт) |
Аналогично |
|
Зарезервированное поле |
INT32 (4 байта) |
Всегда равно 0. Возможно, это флаги атрибутов, что-то вроде «только чтение», «скрытый» и т.п. Однако, я не встречал файлов, где это поле бы отличалось от нуля. |
|
Имя файла |
Строка в формате UTF-16 |
Занимает все оставшееся тело документа (за вычетом 2-х дат и резервного поля) |
Принцип чтения контейнера
Для того, чтобы прочитать контейнер мы должны сделать следующие вещи:
Чтение оглавления
- Собрать из блоков документ оглавления и прочитать его
- Обойти все записи в документе оглавления и прочитать документы атрибутов (имена) файлов контейнера
- Сопоставить каждому полученному имени адрес документа содержимого
- На выходе получается соответствие «Имя файла» -> «Адрес содержимого»
Чтение файлов
- По имени файла получить из оглавления адрес документа содержимого
- Собрать из блоков документ содержимого
- Если это корневой контейнер, то распаковать документ содержимого (он сжат)
- Готово. Полученный результат является данными искомого файла.
Обновление от 25.02.2014
В статью внесены правки, рекомендованные awa в комментариях.
В заключение
Данная статья не является истиной в последней инстанции, вероятно, в ней есть даже ошибки. Тем не менее, если данная тема Вам интересна, то я надеюсь, что эта статья поможет вам в реализации ваших проектов. Удачи!
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
(1) Evgen.Ponomarenko, присоединяюсь, только надо код подправить, а то не сработает :))
(1) Evgen.Ponomarenko,
(2) Uncore,
можное еще и так:
(3) Rothschild, ну тогда лучше так, чтобы постоянно длину строки не брать 🙂
(4) Uncore,
ну тогда лучше так, чтобы постоянно длину строки не брать 🙂
могу на 1$m поспорить, что она один раз «возьмется»!!!
(4) Uncore, ты наверное подумал
(6) Rothschild, затупил, ага. 1 раз берется.
(7) Uncore, значит проспорил???
🙂
(8) Rothschild, да забирай, мне не жалко 🙂
отличная работа! давно уже подумывал написать такую статейку, но лень и постоянная нехватка времени сделали своё чёрное дело
(9) Uncore,
возвратил … шутка это, «не было такого уговора« !
🙂
Предлагаю в рамках данной статьи называть данный формат «контейнер». Если уважаемая публика подскажет в комментариях правильное название, я буду очень рад.
Compound — это из 7-ки. все md/ert являются Compound-файлами, терминология идёт от MS
в исходниках мне кажется весьма удачным обозначение ‘catalog’.
а правильное название можно подсмотреть только во внутренних спецификациях 1С, имхо
(8)(9)(11)
Биржа у нас есть
…
открыть что ли еще КАЗИНО и БУКМЕКЕРСКУЮ КОНТОРУ ???
🙂
насколько я понял, это DateTime(Int64)
Дата и время, представленные в виде нескольких 100-наносекундных интервалов, завершившихся с момента 00:00:00.000 1 января 0001 г. по григорианскому календарю.
(14) andrewks, как-то так, да. Я просто не смог этого сформулировать внятно.
Полезная статья, мне пришлось пару месяцев назад написать свою реализацию работы с контейнерами. Эта статья на тот момент ускорила бы работу. А так, даже имея на руках твои исходники, пришлось написать с нуля свой велосипед, чтобы разобраться с форматом:)
(0) Отличная статья! У меня есть только несколько замечаний.
Ну а в целом, все правильно и по делу!
Статья хороша и по сути и в плане стиля изложения.
(17) awa, спасибо за участие, внесу правки. Единственно мне непонятен смысл поля «версия» для контейнера. Для чего это?
(10) andrewks,
У меня аналогичная история произошла с темой стартера. Разработка реализует почти все мои давние идеи для стартера. Это, по-моему, единственный очень достойный стартер, который есть на этом сайте.
У меня осталась еще пара идей, но досадую немного, что пальма первенства уплыла 🙂
(17) awa, насчёт версии не согласен. ну, не версия это никак. с другой стороны, на этом поле клин не сошёлся, можно на него вообще забить 🙂
(20)
нельзя объять необъятного ©
(19)(21) Я сам до конца не понимаю смысл третьего поля в заголовке контейнера. По крайней изменение его значения не приводит к неработоспособности контейнера. Я предположил, что это версия, не версия формата контейнера, а версия данных, содержащихся в контейнере. Возможно, 1С задумывала это поля для упрощения проверки, изменились ли данные с момента последнего считывания. Предположим, мы считали данные из контейнера и запомнили текущую версию. Если с контейнером параллельно может работать кто-то еще, то спустя некоторое время можно просто считать и сравнить номер версии, чтобы узнать, изменились ли данные в контейнере. Но это предположение трудно проверить, так как с внешними файлами cf/epf/erf 1C не работает в режиме изменения, она их каждый раз создает заново. Если мы открываем внешнюю обработку, то при сохранении 1С создает контейнер заново и затем целиком перезаписывает файл epf.
Возможно, что я ошибаюсь, и это поле несет какой-то другой смысл (но не количество файлов, точно!), и в общем, я согласен, что на него можно забить.
(23) awa, внешнюю обработку можно хоть сто раз изменять (не добавляя и не удаляя объекты), значение остаётся одно и тоже.
но, в то же время, при добавлении, например, нового макета значение увеличивается на 1, при удалении — уменьшается.
поэтому я и сказал, что это никак не версия, больше смахивает на счётчик чего-то
(24) Сорри, ты меня просто не понимаешь, я это уже объяснил в (17)
(24) Простейший эксперимент. Открой существующую внешнюю обработку в конфигураторе. Удали на диске файл обработки — он спокойно удалится, 1С не держит файл открытым! Сохрани обработку в конфигураторе — файл снова появился! 1С не изменяет старый файл, ей вообще пофигу, есть он или нет, 1С заново создает контейнер и записывает файл.
(26) awa, и что это доказывает?
(27) Что платформа открывает файл, разлочивает его и освобождает дескриптор в файловой системе.
Не знал про такой фокус платформы.
Знаю, некоторые текстовые редакторы, например pspad, notepad+, не захватывают файлы. Их можно спокойно изменять в другой программе, а редактор просто спросит об обновлении.
(28) да я и раньше был в курсе этого факта. просто непонятно, что это доказывает в контексте предназначения спорного поля
Спасибо за статью!!!
(0) Compound-файл — это файл, начинающийся с заглавных русских букв «РП». В этом формате в основном Офис хранит (хранил) свои файлы и 1С 7.7 (md, ert). cf — не Compound-файл.
P.S. Только сейчас увидел описание в (12)
У меня пара вопросов:
(32) B2B, насколько я понимаю, deflate — это алгоритм, которым могут быть сжаты элементы ZIP. Добавлением байтов, кажется дело не ограничится.
Вот здесь много буков, и я не смог дочитать, но наверное, там все написано.
(28) Я всегда считал, что платформа копирует файл в темповую папку, и что изменяем мы именно его (темповый файл). А при сохранении — заменяет основной файл.
Спасибо за интересную статью.
При выгрузке и повторной загрузке cf-производится дефрагментация документов внутри контейнера?
Или все же имеет какой-нибудь смысл попробовать дефрагментировать документы в cf?
(35) Антон Ширяев, вроде бы всегда cf создается с нуля и подобная операция не имеет смысла.
Еще можно отметить cfu-формат. Это тот же формат cf/epf/erf, но сжатый по стандартному алгоритму, схожему с zip
(37) Elisy, cfu я не изучал. Может расскажете подробнее?
(38) да там deflate идёт
(38) если распаковать cfu, то полученный результат будет совместим с cf-форматом. Сжатие/распаковку можно выполнить в .Net framework классом DeflateStream. В этом все отличие.
(40) Elisy,
1C распаковывает/упаковывает без .Net
Может есть какой-то родной механизм 1С?
(41) Evgen.Ponomarenko, что имеется в виду под родным механизмом?
(41)
Я, к сожалению, не знаю такого механизма. 1С ограничена в низкоуровневых операциях.
(42) cool.vlad4
к примеру ЧтениеZipФайла.
по крайней мере в описании механизма записи видим…
ЗаписьZipФайла.Открыть(,,,МетодСжатияZIP)
МетодСжатияZIP содержит значения:
1.Копирование (Copy)
2.Сжатие (Deflate)
(44) Evgen.Ponomarenko, нет, это совсем не то.
это прекрасно реализуется при помощи внешних компонент
(45) andrewks,
внешние компоненты — это не тоооо… и framework тоже не оооочень.
Чего-то мне не верится… что 1С с Deflate работает, а интерфейса к нему не имеет.
(46) Evgen.Ponomarenko, не имеет из встроенного языка? Да, не имеет. Читать Deflate-потоки из встроенного языка нельзя. Или можно, но какими-нибудь извращенскими способами, о которых я не знаю.
Ну а то, что метод сжатия в синтакс-помощнике называется «Deflate», так это просто английский терм встроенного перечисления, не более.
(46) Evgen.Ponomarenko, я потому и спросил, что имеется в виду под родными. нет, 1С этого не умеет. то, что 1С работает с потоками, это вы путаете, это не 1С работает, это c++ работает, на которой написан 1С. если поковыряться, там вообще куча вещей зарыта. например, регулярки, которые есть в icu, для которых Орефков сделал ВК.
(47)
я так и подумал… но на всяк случай спросил… мож кто доковырялся.
(0) не останавливайся «раскрой все секреты 1С». Такая же статья нужна и по файлам Dt и по файлу хранилища 1С «1cv8ddb.1CD» и по файлам cfu. Кроме того необходимо реализовать в виде dll API для работы с данными типами файлов (например только базовый функционал). И все это должно быть бесплатно… А лицевой счет (какие нибудь там Яндекс-деньги) для выражения благодарности никто не мешает опубликовать.
(47)
да не, он неспроста так называется. алгоритм сжатия используется такой же.
алгоритм, но не формат.
строго говоря, ZIP — формат хранения потоков, которые, в т.ч. (но не только), могут быть закодированы при помощи алгоритма Deflate
(46) Evgen.Ponomarenko,
внешние компоненты — это тоооо!
(50) GoodBeaver,
формат 1CD давно уже описан awa
(53) и кроме того, это описание от awa и стало причиной написания моей статьи. Об этом сказано в самом начале.
Goodbeaver, кстати, что за подражание мне в нике?
awa одобрил разработку. Этого достаточно, чтобы попробовать в использовании.
1С наконец-то выдавило из себя:
(56) fishca, о, фигасе!
(17) awa,
Валерий, здравствуйте. Мне очень, очень, очень нужна Ваша помощь в восстановлении базы 1С.
Здесь ошибка.
Должно быть:
[CRLF][Размер всего документа][Пробел][Размер текущего блока][Пробел][Адрес следующего блока][Пробел][CRLF]
(59) AlexanderKai, да, после каждого числа — пробел. Спасибо, поправлю.