











Думаю, что многим приходилось сталкиваться с такой задачей как загрузка данных из файлов Excel. Очень редко бывает так, что пользователи строго придерживаются размещения данных в определенных столбцах, поэтому процесс написания загрузки превращается в очень "увлекательное" мероприятие. По этой причине, занимаясь такой загрузкой в 3-4 раз многие программисты начинают задумываться – как решить эту проблему раз и навсегда. Представленное ниже решение проблемы с успехом используется на нашем предприятии и в течении года постоянно дорабатывалось и модернизировалось. Сначала была обработка для толстого клиента, после некоторые доработки в направлении повышения производительности. После несколько модернизировали под работу с тонким клиентом и прикрутили процедуры для работы с буфером обмена, которые одновременно позволяют обрабатывать текстовые документы с символами-разделителями колонок.
Первоначальная обработка с процедурами по работе с буфером представлена здесь:
//infostart.ru/public/166350/
Данное решение позволяет читать в таблицу значений файлы Excel, а так же текстовые данные с символами-разделителями полей, согласно настройкам, хранимым в специальном справочнике. Файл конфигурации содержит сам справочник и необходимые для чтения процедуры. Работа возможна как в тонком, так и в толстом клиенте, при этом справочник использует одни и те же управляемая формы. При загрузке данных необходимо соблюдать одно условие — Заголовки столбцов в Excel должны оставаться постоянными. При обработке разношерстных файлов от разных пользователей иногда приходится эти самые заголовки расставлять самостоятельно, но на этом предобработка файла заканчивается. Что дальше делать с полученной таблицей – решать Вам.
Чтение файлов Excel осуществляется через COM-объект, при этом возможно задание фильтров, позволяющих отбирать только записи с определенным значением в ячейках.
Важно: Для нормальной работы в режиме обычного приложения в свойствах конфигурации должен быть включен флаг "Использовать управляемые формы в обычном приложении". В противном случае требуется создание обычных форм с принудительным перевызовом на основные – управляемые.
Описание реквизитов справочника:
Каталог, МаскаФайла — позволяет задать каталог и маску для поиска файлов для возможности использования при автоматической загрузке. Если таковая использоваться не будет, заполнять не обязательно.
ДопустимыйРазрыв — обязательный к заполнению реквизит. Задает количество пустых строк в файле при достижении которого обработка прерывает чтение, считая, что дальше полезных данных нет. Меньшие значения позволяют читать быстрее, большие – дают возможность чтения файлов низкого качества. Правильный выбор параметра существенно повышает удобство работы. Кто-то спросит — зачем он вообще нужен. Отвечаю — пару раз попадались файлы с несколькими тысячами пустых строк после полезных данных, поэтому просто по последней ячейке листа сие чудо читалось очень и очень долго, а данный параметр позволил заранее отсечь лишнее и в несколько раз повысить скорость прочтения таких образцов.
СлеваНаправо — установка флага позволяет читать данные файлов, расположенные не "вниз", а "вбок".
Внимание: Для текстовых файлов и буфера обмена этот режим не реализован.
Табличная часть – задает соответствие между именем колонки, которое использовано в Excel и именем колонки, которое требуется получить в таблице значений. Помимо этих полей при чтении файла добавляются колонки с именем листа, номером листа и порядковым номером обрабатываемого файла. Параметр Обязательный – позволяет игнорировать при чтении строки (столбцы) с пустыми значениями в отмеченном поле.
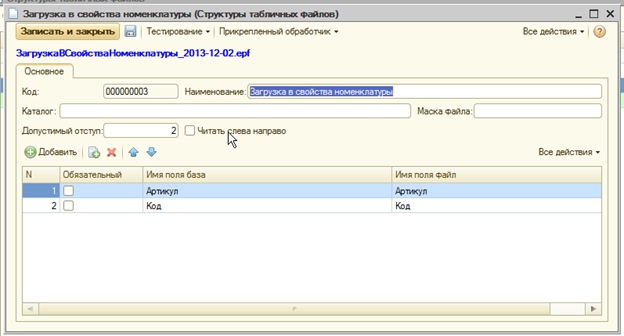
Кроме того, форма элемента справочника содержит кнопки, позволяющие проверить чтение данных по текущим настройкам.
Как это работает:
В первую очередь при загрузке листа Excel или текстового документа выполняется поиск строки с заголовками и запоминаются индексы колонок с данными.
Внимание: Если позиция строки заголовка на листе больше параметра "ДопустимыйРазрыв", то дальнейшая обработка листа не производится.
Для листов, у которых заголовок найти удалось производится считывание данных. при желании могут быть использованы фильтры по значениям. Содержимое ячеек читается как их текстовое представление. Это было сделано намеренно, после некоторых проблем в случае с нашей конфигурацией (преобразование текста к числу при необходимости для нас оказалось более удобным, чем истолкованных Excel как числа текстовых данных в исходное состояние).
ДОПОЛНЕНИЯ от 2013-12-24:
Предела совершенству, как правило, нет, поэтому недавно в очередной раз доработал свое средство для прочтения Excel.
Основной функционал не изменился, но дополнился возможностью прикреплять к записям справочника настройки файлы внешних обработок, позволяющие разместить в них код, который позволяет обработать полученную таблицу так, как это нужно Вам.
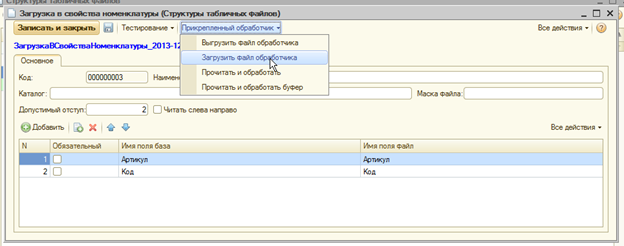
Чтобы прикрепленный обработчик запустился при соответствующем действии, он должен содержать экспортную процедуру "Обработать" с тремя параметрами. В первый параметр будет передана полученная таблица, во второй — ссылка элемента справочника настройки, по которой прочитана таблица, в третий при вызове обработчика непосредственно из конфигурации можно передавать произвольные параметры. При вызове из формы справочника будет передано "неопределено".
В файле обработчика можно использовать параметры авторегистрации:
В экспортной функции ОсновныеПараметры() указываются значения для заполнения шапки справочника настройки

В макете табличного документа под именем "Настройки_Полей" могут быть указаны значения для заполнения табличной части элемента справочника:
Первая колонка соответствует имени колонки получаемой таблицы значений, вторая — заголовку колонки в файле, третья — обязательность заполнения значений в этой колонке (0 или 1)
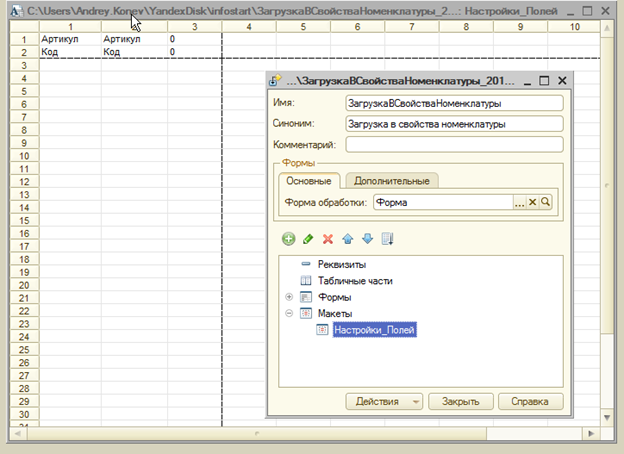
после заполнения настроек полей из параметров авторегистрации можно дополнять или редактировать их в ручном режиме.
Надеюсь, что Вам эти функции будут полезны. Помимо файла конфигурации прилагаю как пример прикрепленного обработчика простейщую обработку, позволяющую сохранять значения прочитанной таблицы как значения дополнительных свойств справочника "Номенклатура" из типовых конфигураций (в частности УПП). По колонкам "код" и "артикул" (включены в параметры авторегистрации) выполняется поиск элементов справочника. Остальные колонки, которые будут указаны в настройках считаются значениями дополнительных свойств, заголовок колонки в файле должен совпадать с наименованием дополнительного свойства.
Внимание: если в вашей базе таких свойств нет, они будут созданы. Значения в базу будут загружены как элементы классификатора, а не как текстовые данные. Если вам требуется иное поведение, обработку следует поправить под свои нужды.
ДОПОЛНЕНИЯ от 2014-12-17:
Продолжаем улучшать то, что можно улучшить. Довелось опробовать свой подход к обработке Excel-файлов за пределами подвластного мне завода. И выяснились следующие факты:
1. Далеко не всем коллегам нравится наличие в конфигурации дополнительных объектов. Более того, у многих и вовсе используется девственно-чистая типовая конфигурация.
2. Многие пользователи не могут или не хотят (или и то и другое сразу) менять настройки считывания и просто пользуются теми, которые однажды сделал программист. В случае вероятных проблем обращаются к нему же.
3. В отдельных случаях использование Excel-загрузок на постоянной основе не требуется, а выполняется единожды.
4. Случается и потребность в обработке однотипных данных в разных базах с отличающимися, но большей частью схожими конфигурациями. (Иными словами — "походная" обработка)
По этим причинам и создал на основе кода, используемого нами (приведено в прошлой публикации на эту тему), полностью автономную обработку чтения Excel-файлов. Данная обработка фактически является шаблоном для быстрого создания обработок загрузки, заточенных под конкретные задачи и содержит все необходимые процедуры чтения файлов Excel (проверено на пустой конфигурации). Вам остается заняться обработкой полученной таблицы.
Т.к. справочника, хранящего настройки в таковой версии нет, его заменил макет табличного документа "Настройки_Полей"

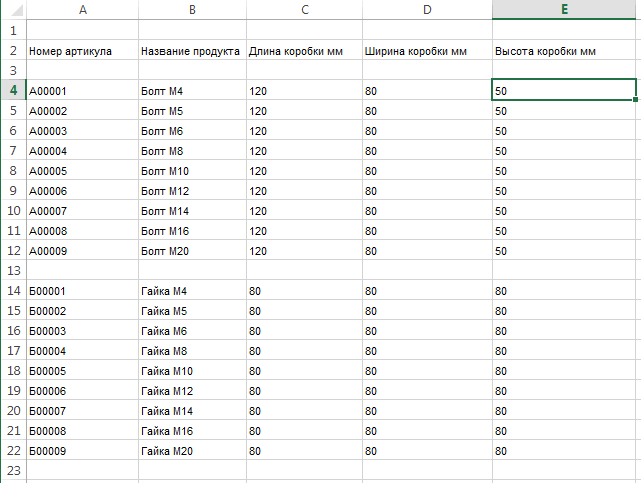
Здесь в первой колонке указываются заголовки колонок таблицы значений, которая должна быть получена в результате чтения файла.
Во второй — соответствующие им заголовки колонок файла.
В третьей — обязательность заполнения значений в файле (строки с незаполненными значениями этих колонок будут пропускаться). 0 — заполнение значений необязательно, 1 — заполнение значений обязательно.
Кроме того — в первой строке в четвертой колонке — параметр, указывающий предельно допустимое количество пустых строк в файле подряд. Большие значения позволяют считывать данные из файлов низкого качества, меньшие — ускоряют работу.
Первая строка пятая колонка — параметр, управляющий направлением чтения (0 — данные расположены "сверху вниз" 1 — данные расположены "слева направо")
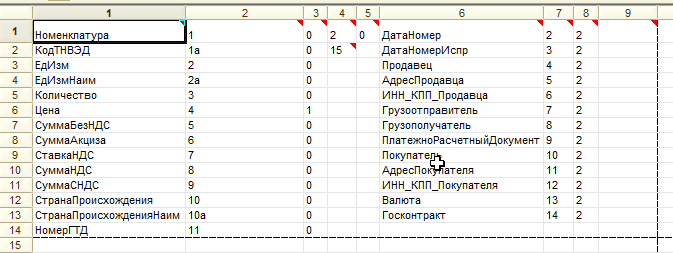
После того как настройки выполнены можно проверять как читаются файлы. Так выглядит наш тестовый Excel-лист:
Открываем обработку, выбираем "Прочитать" и находим нужный файл.
Смотрим что получилось. Именно так будет выглядеть таблица значений, которую нужно обработать. Помимо колонок, которые настроены в макете, автоматически добавляются колонки с числовым идентификатором файла, имя и номер листа книги, с которого получена строка.
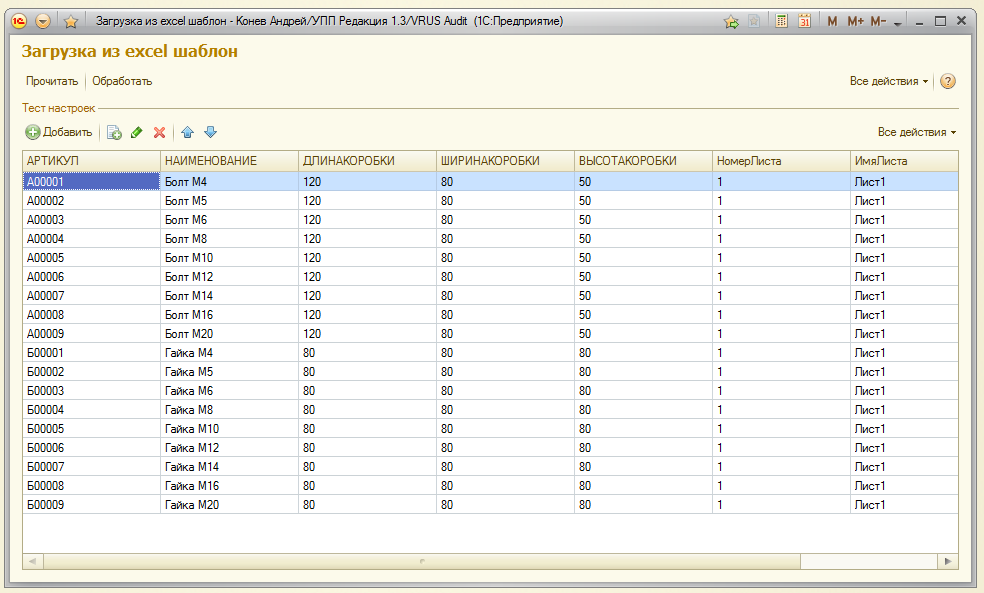
Так как конечную обработку данных на все случаи создать просто не возможно, это право автор оставляет Вам. Вызов соответствующей процедуры необходимо встроить в обработку вместо первого "предупреждения"
Дополнения от 20.07.2026
Продолжаем развиваться. Кардинально новый вариант обработки был разработан еще полгода назад, но публике представляю только сейчас. Что же нового?
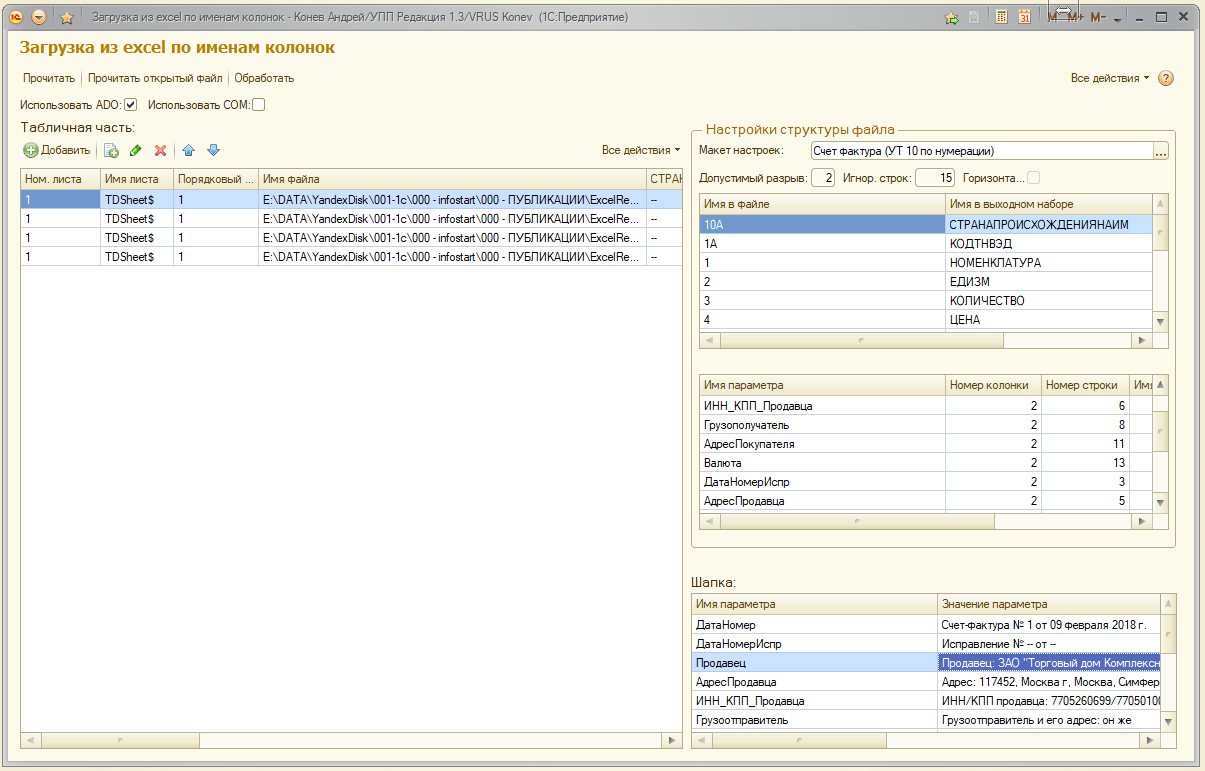
1. Ни для кого не секрет, что чтение данных посредством механизма ADO дело более быстрое, поэтому поддержка такового была добавлена в обработку. Основной принцип остался неизменным – для прочтения табличной части сначала разыскиваем строку с нужными заголовками, затем читаем листы. Можно включать использование механизмов ADO и COM-объекта соответствующими флагами. Если выбраны оба, то первоочередным является ADO, а COM-объект используется только, если ADO вызвал ошибку.
2. Появилась возможность прочесть при необходимости на имеющихся листах параметры шапки по адресам ячеек.
3. В обработке теперь можно хранить множество макетов с настройками. На форму выведены настройки из выбранного макета. Обработку можно использовать и как внешнюю и для встраивания в конфигурацию, в том числе интеграции данной обработки с формами объектов конфигурации.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Идея очень хороша…
Насколько эта обработка гибка при настройке? Например, переварит ли она данные, если они в файле Excel многотабличного вида, при этом таблицы расположены по листу файла как угодно: по нескольку таблиц по вертикали и по горизонтали, разное количество колонок и строк в каждой таблице и т.д. и т.п.
(2) RayCon, Изначально функционал нацелен на извлечение из файла данных, описанных настройками, и сбор в одну сводную таблицу. Из нескольких таблиц, разбросанных бепорядочно по листу, обрабатываться будет первая, соответствующая настройке заголовков. Данные из других таблиц могут так же попасть в нее, если окажутся в соответствующих колонках (т.е. под заголовками первой таблицы) и условие максимального количества пустых строк позволит процедуре чтения до них добраться.
Как правило, своих пользователей приучал обрабатывать такие файлы через копирование нужной таблицы в буфер обмена и нажатие соответствующей кнопки в 1С, хотя такие образцы с трудом вспоминаются. А вот с данными через 10-20 строк были довольно часто.
(2) Николай, ОБМЕН информацией в виде НЕПЛОСКИХ эксельных файлов — очень увлекательное и при этом бесполезное занятие. Максимум что приобретешь — улучшишь скил по навыкам работы в экселе. ВСЕ.
.
активная работа с кучей прайсов, которыми обмениваются всякие «драгдиллеры»-перепродаваны — резюме: никакая обработка не сможет их запихнуть туда куда нам надо. Просто потому что там в однйо ячейке может быть ВСЕ СРАЗУ. и вся работа с таким экселем иначе как вручную с интеллектом человека — невозможна…
.
Основная причина — использование экселя не как электронной ТАБЛИЦЫ — а как большой записной книжки. Причем потрепанной и ведомой неорганизованным человеком.