


Что, кстати, очень важно для разработчиков мобильных решений 🙂
Доброе время суток. Сегодня я хочу поговорить про перевод решений на базе 1С.
Для нас это все — достаточно больная тема, так как около года назад мы замахнулись на написание международной конфигурации, которая была бы заточена на расширения и внешние обработки/отчеты/печатные формы для каждой страны, или нескольких стран в одной базе.
И, в момент проектирования нашего решения, одним из ключевых факторов стал – перевод всех этих расширений, макетов и прочего.
Причем не простой перевод, а качественный, и желательно так, чтобы основное ядро писалось на одном языке, а переводы накидывались отдельно.
Т.е. нас интересовал такой концепт:
Программисты не знают о том, что существуют переводчики.
А переводчики не знают о том, кто пишет программу.
Почему? Все просто. Языковой барьер между переводчиками и программистами, стоимость времени программиста, выделение отдельного времени команды на это все и т.д. Все значительно усложняется тестами, и полным CI/CD контуром, при его наличии, а без него — переводить большие конфигурации — не реально.
Итого, писать или не писать свой продукт для перевода — это решение каждой команды отдельно. Например, в нашем случае — у нас было четкое понимание и обоснование.
Основание создания продукта
Прежде чем приступить к созданию — надо попытаться понять то, зачем оно надо, не будет ли дешевле нанять еще одного человека, или просто не обращать на это все внимание, если бы стоимость разработки была в 100 раз больше, чем текущие годовые расходы.
В результате, было посчитано, что в среднем, на команду из 5 человек разработчиков, 3 переводчиков, одного QA инженера и релиз инженера — мы тратили порядка 100 часов в месяц на решение проблем связанных с переводом. Хотя, поддержка на тот момент была всего 2 языка — русский и английский. Т.е. разработчики сами переводили, что не знали — кидали переводчикам, те допереводили, потом вычитывали, правили и т.д.
На какие самые частые ошибки и проблемы мы нарывались:
- Копирование метаданных. В момент копирования реквизита — копируется и его синонимы на всех языках. И если программист поменяет синоним на одном языке, то он должен зайти и поменять потом в другом языке, или очистить его, чтобы потом его обработать и добавить.
- Проблема постоянных конфликтов при мержинге, так как переводчики сидят исправляют ошибки — и поднимают ветку вверх, и правят те же формы и т.д., что приводило к постоянной головной боли человека, который решал конфликты.
- Падала скорость разработки, ибо постоянно надо помнить про другие языки, переводчики дергали разработчиков чтобы те что-то поправили.
- Релиз инженер вообще хотел стреляться, так как он отвечал за часть релиза, но при этом, у него был кусок между разработкой и сборкой, который не мог быть автоматизирован.
- Написание тестов — отдельная боль.
- И т.д.
Итого, компания посчитала, что даже при самой низкой цене сотрудника в 10$ в час (с налогами, рабочими местами, электричеством, конфликтами и т.д.) — выходит, что компания тратит лишнюю 1000$ в месяц на поддержку перевода, и при этом — никто не может дать гарантию качества.
Так как если бороться за качество — надо нанимать отдельных людей, которые будут следить за этой темой, выступать посредниками между переводчиками и разработчиками, при этом не низкой квалификации и это будет стоить еще дороже.
И это только с двумя языками…
Плюс, получается, что тратится очень много времени, которое могло уйти на развитие продукта.
Другими словами — мало того, что фирма тратит больше 12000$ в год на оплату проблемы, так и еще продукт теряет 1200/7/22 = 8 человеко/месяцев. Т.е. около одного разработчика в год тратится в этом случае на то, чтобы поддерживать переводы.
Отсюда, можно сделать вполне резонный вывод — разработчики не должны вообще думать о переводах, а просто писать по стандартам, которые говорит сама 1С про локализацию.
Переводчики же — должны иметь возможность в онлайн смотреть что будет с их переводами, как они будут выглядеть и где что исправить. Причем, если они увидели ошибки в языке исходника, они должны были скинуть быстро заявку, и указать конкретное место текста и что на что надо заменить.
Переводы не должны иметь никакого отношения к веткам и репе, где находится проект, в силу решений конфликтов, и того, что тот, кто будет их решать — не может знать все языки мира, и может принять не верное решение, либо git просто объединит автоматом что-то, не пойми как.
Это тот из не многих случаев, когда должно быть единое хранилище переводов. Переводы должны делаться по API и т.д. Т.е. в данном случае — в любом варианте — для переводов надо единое место хранения. Откуда будут браться конечные варианты приоритетов.
Первая версия продукта. Интеграция с внешними сервисами
Что можно было бы написать за месяц? Можно написать простейший парсер, прямо на самой 1С, который умел бы парсить исходники 1С и вычленять оттуда НСтр (из bsl) и lang тег из xml.
И потом собирать все это в кучу. Но дальше надо думать — что делать с этим всем? Т.е. это надо бы где-то переводить…
Переводить в Excel? Да, наверное, но разве что объемы до 1000 строк и только один проект. А если их десяток тысяч, и десятки обработок и расширений, и это только начало, видь все проекты имеют свойство увеличиваться…
Поэтому, можно использовать внешние сервисы, и сделать выгрузку в CrowdIn и там переводить. Тем более — там есть версии проектов и много всяких других чудес. Но, не забудьте посмотреть на цены, а они тут весьма не низкие:

В реальности — максимальный план не подходит для крупных проектов, типо ERP, УТ11, УНФ.
Есть другой вариант — Smartcat. Он может купить тем, что он бесплатный (в некоем роде), и там большая база фриланса.
Но… Сбор статистики, анализ плейсхолдеров, выгрузка и загрузка данных — отнимают мега много времени.
А если задача стоит — проверять все постоянно, и иметь полноценный CICD, т.е. именно deploy, то тогда время это один из очень критических факторов.
Создание системы перевода
В итоге — мы собрали некие критические особенности, которыми должна обладать такая система:
- Перевод не должен влиять на разработку
- Разработка делается только на одном языке
- Визуальная проверка результата переводов интерфейсов и макетов
- Встраивание в CICD контур
- Интеграция с GIT
- Максимальная помощь для переводчиков
- Высокая скорость переводов
- Не верить программистам 🙂
Функционал, который критически необходим:
- Переводить нужно конфигурации, обработки, расширения, макеты и т.д.
- Исходники могут быть в виде xml формата 1С или EDT формат, поддержка OS скриптов, так что не хардкодьте везде bsl
- Очень важен контроль шаблонов — %1, %Склад%, [Контрагент], %Пользователь …
- Неограниченное количество языков для добавления в конфигурации и их урезание
- Быстрое исправление и поиск ошибок перевода в том числе, в старых конфигурациях
- Версионирование и группы проектов
- Перевод справки, и/или ее размножение на другие языки
Работа с системой должна быть очень простая, например:
- Выгружаем конфигурацию и т.д. в xml, или сразу берем в EDT формате
- Удаляем все, что не нужно переводить, там драйвера всякие, классификаторы и т.д.
- Загружаем эти данные в переводчик
- Выполняем перевод, в том числе при помощи Yandex переводчика или других
- Скачиваем переведенные файлы обратно
Но, если есть git то – все это надо уметь делать автоматом, из нужных реп и веток, и туда же в другую ветку пушить уже переводы.
Наше представление реализации контура переводов
Мы разработали для себя две схемы — одна для отдела разработок, с тестами и прочим, и вторая — которая используется нашими клиентами, которые сами поддерживают внедренный продукт с переводами, и не могут позволить себе такие контуры как наши. Либо, когда надо на быструю руку прогнать перевод какой то новой конфы своими словарями, и посмотреть – чего где получилось.
Полный цикл мы видим вот так
Сокращенный цикл
Обратите внимание на зеленые и желтые области. Это зоны ответственности команд. Зеленая — разработчики, а желтая — переводчики. Главное в этой модели то, как они разнесены. Т.е. программисты — работают без переводов, и даже не подозревают о них. Они просто выгружают все в гит, потом анализируют ошибки в сонаре и тестах. И единственное место, где они обращают внимание на переводы, это если тесты упали в переводах, или сонар выдал ошибки, отличные от тех, которые в ветке без переводов.
Тут причин несколько — или программист где-то ошибся, например, не правильно написал локализированную строку НСтр, и переводчик ее не перевел, и программа вылетела в крит, например, так как не нашла параметры на другом языке.
И все. Остальное программистов не особо волнует, если они делают правильно, по стандартам. В свою очередь — переводчики вообще не понимают, как и где идет разработка программы.
Им в некий мессенджер/задачник приходит инфа, что появились новые документы для перевода, и они пошли переводить. Плюс, они сами могут инициировать поиск новых строк или же патчинг новой версии новыми переводами. Ну и они делают переводы в режиме онлайна (мы это реализовали через расширение для Firefox).
Подробнее о функционале
Переводить нужно конфигурации, обработки, расширения, макеты и т.д.
Тут на самом деле речь идет про то, что надо систему писать так, чтобы она просто патчила файлы bsl и xml, и ей было пофиг что патчить – конфу, расширение, обработку.
Такой подход имеет ряд существенных преимуществ:
Можно переводить конфу частями
Можно не хранить бинарные данные и другие данные, которые не нужны для перевода
Нет проблем в переводе обработок/отчетов, так как разбирать на файлы можно только при наличии конфы, где они писались, иначе потеряются ссылки
Нет разницы между тем, что патчить – формат EDT или формат xml самой 1С платформы
Вы не привязаны к версиям платформы, где были созданы обработки/ отчеты/ конфигурации/ расширения и т.д.
Очень важен контроль шаблонов — %1, %Склад%, [Контрагент], %Пользователь …
Самая большая проблема в том, что переводчикам надо как-то объяснять, что такое шаблоны, чтобы они их не пытались переводить. Профи конечно знакомы с такими терминами и понятиями, но увы, не всегда ясно — где надо что-то переводить, а где нет.
Сама 1С пишет следующее про это все:
В связи со сложившейся практикой, допускается использовать именованные параметры подстановки (параметры, включающие имя аналогично переменной, а не номер) только в двух вариантах: [Параметр], %Параметр%. Здесь Параметр должен удовлетворять требованиям стандарта Правила образования имен переменных.
Правильно:
СообщениеОНехватке = НСтр("ru='Не хватает товара %Товар% на складе %Склад%.'")
СообщениеОНехватке = СтрЗаменить(СообщениеОНехватке, "%Товар%", НаименованиеТовара);
СообщениеОНехватке = СтрЗаменить(СообщениеОНехватке, "%Склад%", НаименованиеСклада);
Но, лично я — КАТЕГОРИЧЕСКИ против такого стандарта. Так как перевод русской конфигурации перевсти на английский – не сложно, а вот на немецкий – лучше переводить с английского, не с русского. Это будет и дешевле, и корректнее. Но, представьте себе немца, которые перевод вот такую строку на немецкий с английского:
("ru=’Not enough items %Товар% at %Склад%.’")
Вот какой у него должен быть фейспалм от сего? Но, на самом деле – и вариант с %1 и %2 не очень-то и понятен. Однако, мне кажется, что он все же приоритетней, и лучше добавить комментарий к таким местам. На том же английском. Или эти параметры изначально писать на английском. Так как с английского перевод более корректный у всяких онлайн переводчиков, чем с русского, на другие языки. Но это только мое мнение.
Но, какой бы вариант вы не выбрали – все равно стоит задача контроля для переводчиков в том, чтобы у них не было желания перевести эти самые плейсхолдеры. Особенно важными являются такие как %1, %2 и т.д., так как функция СтрШаблон – вылетит в крит, если не найдет нужный параметр. А переводчики любят %1 переделать в 1%, например.
Ну и тут же — не советуем использовать шаблоны в макетах, лучше разносить на параметры и текст, или просто текст генерировать кодом.
Неограниченное количество языков для добавления в конфигурации и урезание лишних
Если с добавлением все понятно, то урезание тоже не менее важный функционал. Представим себе ситуацию, что вы взяли конфигурацию, например, УТ11 и добавили туда славянский язык. И теперь есть два пути:
- Взяли конфу, перевели ее. Накатили на прод, и разработку ведете в базе с двумя языками. Теперь выходит обновление, и если его попробовать накатить, то будет подсвечена куча объектов к изменению. В этом случае – вы можете вырезать из копии прода все языки, накатить обновление, а потом снова перевести прод. Конфу с которой вы делаете обновление не всегда получится перевести, так как иногда – это просто файл обновления, который нельзя разобрать.
- Работа идет в конфе с одним языком, потом патчится конфа переводами и накатывается на прод. Тогда проблема обновлений решена. Но, не редко случается ситуация, когда надо взять прод с их свежими данными, и накатить это все на тестовую базу. В проде то куча языков. Теперь надо вырезать их все. Еще хуже становится, если оказывается, что некий гений решил доработать в проде кучу механизмов. Тогда уже просто натянуть конфу с одних языком на тестовый прод не выйдет. Надо вырезать языки и мержить конфигурации.
Быстрое исправление и поиск ошибок перевода в том числе, в старых конфигурациях
Очень важная функция, помогает, когда есть какая-то ошибка переводчика. И вот клиент говорит – тут слово написано с ошибкой, исправьте. И теперь надо найти это место, исправить перевод, потом поискать это слово в остальных местах. А потом поискать на исходном языке это слово, проверить все словари, и места перевода – правильно ли везде оно применено. Особенно это актуально для старых конфигураций, которые переводились по ходу дела, и там уже черт ногу сломит – где что.
Версионирование и группы проектов
Эта вещь достойна отдельной статьи, но в двух словах – не привязывайтесь в системе перевода к конкретным версиям, так как это может работать только для конфигураций и расширений, но главная идея – что надо рассматривать все продукты, которые основаны на одном ядре – как просто версии одного и того же продукта.
Например, ERP, KA, УТ11 – это все надо рассматривать как просто подверсии одной конфигурации. И если вы исправляете перевод в одной конфе – он должен подтянуться в остальные. Особенно, если это механизм из БСП.
Так же само надо рассматривать и, например, типовая УНФ и допиленные УНФ для моих 3 клиентов. Это все один и тот же проект, грубо говоря, просто разные его версии.
Т.е. вы должны ориентироваться на то, что версии в переводе — никак не связаны с версиями в конфигурации. Т.е. работать по принципу гита, в каком то смысле — один проект, это одна ветка, и в зависимости от того, что вы послали в эту ветку на перевод — все что будет найдено, из того, что было ранее переведено — должно превестись, а если есть новые места и строки (т.е. не только если поменяли текст, но и его положение) — вы должны подгрузить как новый объект перевода. Который, в случае изменения положения (например, сдвинули группу вниз) — будет иметь перевод, но вы должны его подтвердить, что все ок, что он влазит, что не случилось такого, что после переноса в другое место — перевод теперь обрезается.
Перевод справки, и/или ее размножение на другие языки
С переводом справки все много интереснее, так как так как если говорить про перевод формы документа, то это один и тот же документ, где надо просто добавить в некоторые места несколько новых тегов. Но справка – это значит надо создать новые html файлы под все языки, и еще прописать это все в специальном файле Help.xml…
В чем проблема самой справки, например, есть конфигурация на русском языке, с русской справкой. Добавим туда украинский язык и белорусский. Т.е. пользователи заходят в украинский или белорусский интерфейс. Все хорошо. НО! Справки не будет ни у кого из них. Она будет пустая. Хотя, казалось бы – русский знают многие люди в этих странах.
Поэтому, в таких случаях, возможно, справку переводить не нужно, но ее нужно размножить по всем языкам. Причем опять-таки – надо размножать всегда только одну главную справку, иначе – в ней что-то поменяется, а другие не обновятся. А если справка на английском языке и на русском, то лучше размножать их по странам. Например, для пользователей из Германии – лучше английскую ставить, из Белоруссии – лучше русскую. И т.д.
Визуальное изменение переводов
Кроме всего остального – важно переводчикам дать как можно больше визуальных инструментов. Чем больше – тем лучше. Это поможет меньше отвлекать разработчиков.
Например, переводчики должны на лету менять тексты интерфейсов и макетов и смотреть, например, вот так:
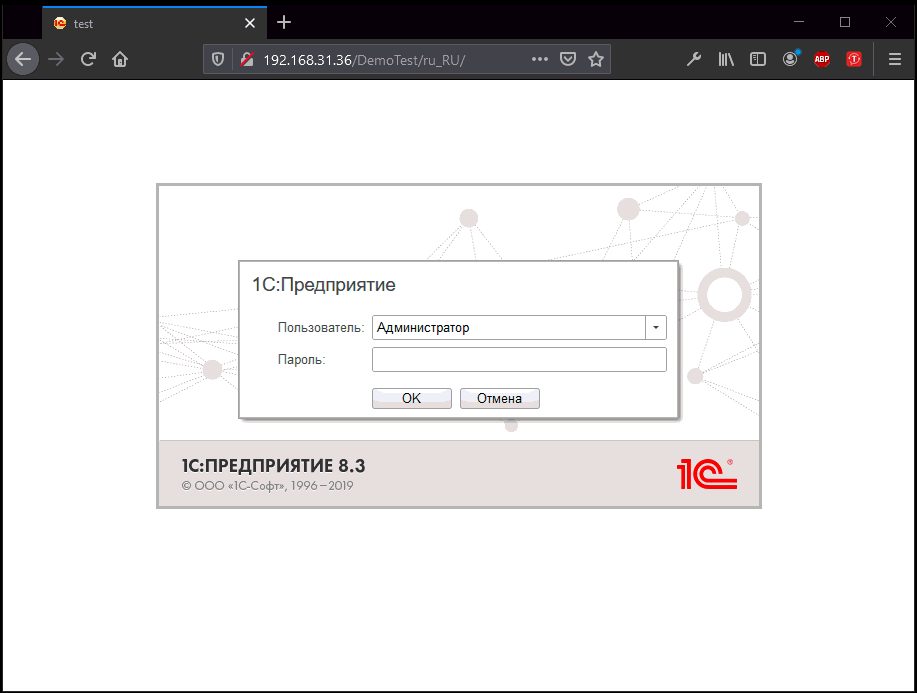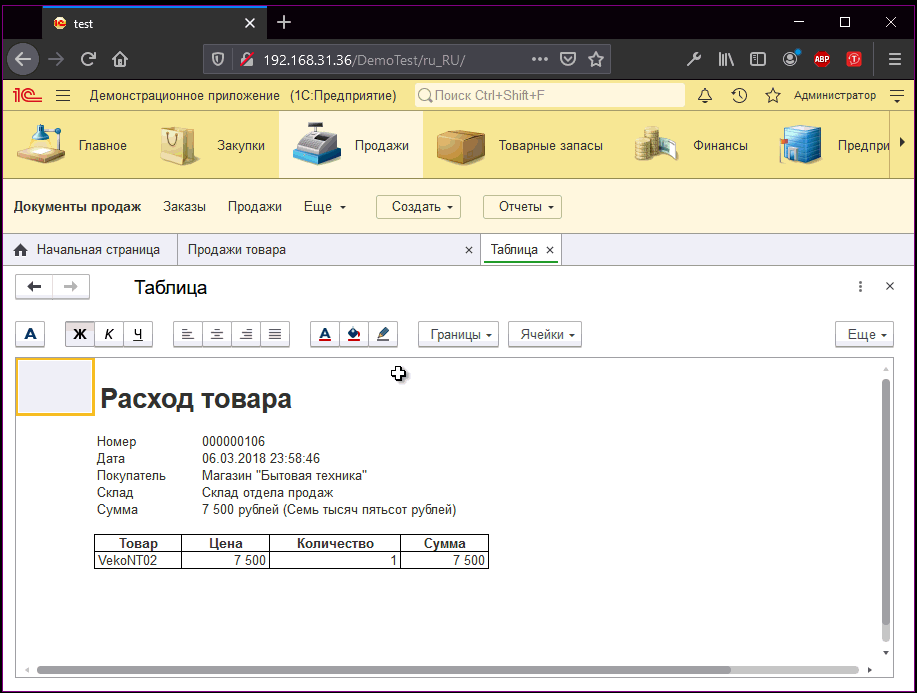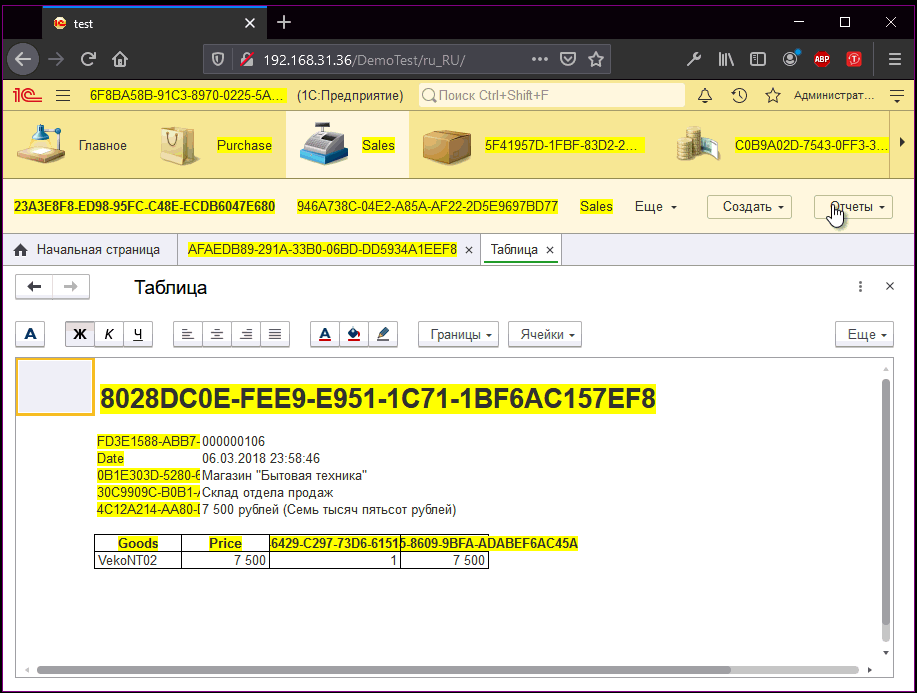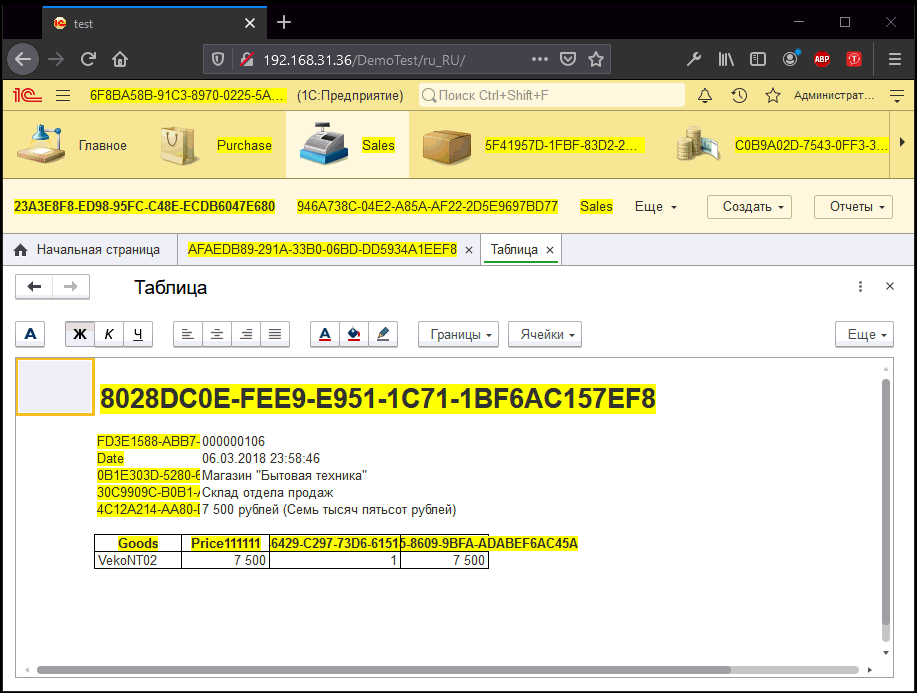
Либо — иметь возможность без обновления программы проверить макет mxl, все ли тексты влезут в печатную форму и т.д.
Итого
В итоге хочу отметить следующее — нам удалось добиться просто неимоверных результатов, особенно, если учесть, что все было сделано на платформе 1С (которая как бы не особо предназначена для этого).
- Скорость пероводов такая, что позволяет взять текущую русскую ERP (где есть английский интерфейс), загрузить ее как словарь в систему, что занимает около 30-40 минут (без макетов с классификаторами). Взять УТ11 и перевести ее словарями из ERP — около 30-40 минут. Т.е., за пару часов получить двуязычную версию УТ11, практически с нуля.
- С легкостью поддерживать текущие ERP от 1С, писать обработки/отчеты на русском, потом патчить их теми же словарями, что и ERP. Т.е. не будет разночтений.
- Если программист написал новую обработку, он просто ее скидывает в slack или telegram, и бот возвращает ему переведенную обработку. Т.е. программист вообще не парится о том, что он там копировать реквизиты мог, что в обработке этой уже был английский и т.д., так как система сама выпилит старый английский и добавит новый.
- Кстати, вы тоже можете проверить как работает наш бот @Bilist_1C_Translator_bot, но правда он переводит только Яндекс переводчиком и не мега быстрый 🙂
- Для этого подключитесь к боту, укажите ключ яндекса для переводчика, и отправьте архив с выгруженными в xml файлами обработки/расширения, конфигурации и т.д., и бот вернет архив с переводами. Только стоит ограничение на объем файлов (до 100кБ zip архив).
- Есть возможность проанализировать ошибки кода, например, не заполненные синонимы, не верно написанные НСтр
- Если клиент предоставляет переводчиков, то мы можем переводить систему на вообще любые языки, в любых количествах и любых комбинациях.
Лучше один раз увидеть, чем 100 раз услышать. Поэтому мы решили записать короткое видео, для того, чтобы показать — чего удалось добиться нам, и как мы в реальности работаем с этой системой.
Например, поставим такую задачу — есть некая обработка, и она нужна на разных языках. Например, перевод вот такой системы, которая используется для сценарного тестирования, и не только:
https://github.com/Pr-Mex/vanessa-automation
По итогам видео — надеюсь, что я смог донести основную мысль, когда разработчики пишут по стандартам и даже не подозревают о том, что их разработки переводят на другие языки. А тут было именно так, т.е. мы уже пол года переведим нужные нам инструменты, и никого не тревожим своими проблемами. Точнее, их отсутствием 🙂
В режиме CICD — Jenkins сам запускает все переводы по регламенту, и отправляет их на тесты. Или, переводчики могут сами инициировать переводы проектов через Slack.
С другой стороны, возможно кому-то подойдут готовые решения от вендора.
Например, в этой статье идет речь про систему переводов, которая может интегрироваться со SmartCat.
//infostart.ru/public/1149523/
И не стоит забывать, для тех, кто уже перешел на EDT, что сейчас в активной фазе находится Language Tool.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Есть еще очень быстрый бесплатный вариант перевода: 1) Выгружаем из конфигуратора тексты интерфейсов (можем там выкинуть ненужные объекты) 2) Загружаем в google sheets 3) Применяем ко всем строка формулу перевода 4) Загружаем всё обратно через конфигуратор
(1) Ну для обработки в 100 строк — да, сойдет. В реальном проекте — увы 🙁
Проверните такое хотябы с розницей, да так, чтобы перевод был адекватный, и система хотя бы запустилась. Уверен, что сразу навретесь на плейсхолдеры при первом же старте.
(2) ну мы не первый год в теме; а перевели таким образом на французский около 10к строк и фраз совсем недавно
(3) Тогда снимаю перед Вами шляпу. (без сарказма).
Я просто представляю себе все страдания, через которые вы прошли.
( 4 ) спасибо! но к сожалению, страдаем до сих пор, особенно когда edt (или даже порой конфигуратор) вырезает выстраданный для отчетов скд перевод, оставляя только английский например.
(5) мы не решились так делать, начали, но когда встали проблемы с плейсхолдерами и с тем, что разработчики копируя реквизиты и меняя их английский синоним не меняли/не очищаи на других языках, и это приводило к постоянной вычитке всего и всея. То мы отказались от такой модели. Если интересно, можете мне в личку написать, пообщаемся детальнее.
(3) А это что то типовое и рутинно «поддерживаемое» от 1С или что то свое?
(7) механизм платформы, но не знаю, можно ли им пользоваться через консоль.
Для выгрузки из конфы: Правка -> Редактрирование текстов интерфейса -> Действия -> Экспорт в табличный документ.
Для загрузки обратно: Правка -> Редактрирование текстов интерфейса -> Действия -> Заполнить тексты.
Восхищен проделанной работой по организации переводов!
(8) я про сам продукт который переводится, платформой можно единоразово перевести что то не большое, но рутинно поддерживать переведенную типовую конфигурацию через конфигуратор и накактывать обновления зачустую финансово не целесообразно.
(9) Спасибо 🙂 Если интересно покопаться в ней — пишите в личку
А как Вы решали задачу работы разноязычных юзеров в одной базе? Если конечно решали. Мы храниили в РС локализованные наименования для основных справочников и подставляли на форме вместо наименования в поля выбора элементов этих справочников.
(12) мы тоже эту проблему решаем. Так как в основной нашей системе работают люди из разных стран в одной базе.
Но мы выбрали немного другую методику — общих реквизитов.
Так как у нас поддаются локализации 95% данных, т.е. Все кроме служебных (типо модулей саас, иниеграционных и т.д.). Ну и такая модель позволяет без лишних левых соединений строить представления на разных языках во всех местах конфигурации. И все внешние отчёты и обработки — не должны думать о том, где хранятся данные. Но, для ускорения вывода данных — надо иметь возможность строго указать конкурентный язык.
В случае РС — есть проблема поиска по подстроке, составной тип измерения, сложные запросы, типо если нет одного языка — берём другой и так пока не найдём не пустой. И автономная запись в сам регистр, что подразумевает, что у вас должно быть обычное наименование товара и вы в него должны писать конкретный язык.
В нашем же случае — наименование должно быть, но на любом языке. А сами языки добавляются и удаляются прям через расширение, или основную конфу просто копированием одного общего реквизита.
Вобщем как то так, надеюсь что смог донести идею.
Такая технология у нас работает вроде несколько лет 🙂
Интересен финансовый аспект: кто спонсор разработки? На чем зарабатывается основной доход компании? Я так понимаю, никто не покупает сам перевод, покупают некий продукт, а перевод — это одна из ваших составляющих продукта. Что за продукт развиваете?
(14) Это сложный вопрос. На самом деле мы предоставляем доступ к нашей системе переводов для партнеров 1С или коненых клиентов, у кого стоит задача переводов.
Плюс — мы сами заимаемся локализацией решений, например, у нас типовая розница работает в 6 странах, и в 3 языках интерфейсов.
Ну а в целом, эта система разрабатывалась как инструмент, для основной конфигурации которую мы пишем на международный рынок, где уже есть три интерфейса, а в скорем времени планируется до 10.
Это что за язык такой?
(16) не знаю. Но системе перевода пофиг. Можно и на него перевести.
Если взять старословянский и его обогатить новыми словами 21 века:) наверное…
(16) а что тебя смущает?! Как и сейчас есть славяне это и украинцы, белорусы, русские, поляки и т.д. Давай вылазь из своей 1С и узнай историю своих предков.
(18) Ну, допустим, есть некие славяне. Как ты сам сказал, это несколько народностей и, соответственно, языков.
Как предлагаешь понимать «добавить в УТ 11 славянский язык«?