
Добрый день, меня зовут Сергей Поликарпов, я возглавляю группу локализации компании 1С International. Расскажу о том, как мы локализуем конфигурации, с чего начали, к чему пришли, и чем это может быть полезно для вас.
Что нужно для успешной локализации интерфейса

Что нужно для успешной локализации интерфейса:
-
Как мы все знаем, 1С как платформа дает разработчику огромные возможности для влияния на интерфейс прямо из кода. Но первоначально, чтобы у вас появился интерфейс на другом языке, вам его нужно перевести. Соответственно, у вас должна быть некая среда, в которой вы это сделаете.
-
И вам обязательно придется доработать ваш продукт для того, чтобы этот интерфейс в нем вообще работал, запустился.
Вторая часть для вас, я думаю, более понятна. А с первой я начну.
Выбор инструмента перевода

Когда мы только занялись вопросом выбора инструмента для перевода, мы, естественно, обратились к самой платформе – что в ней есть для того, чтобы можно было прямо там создавать интерфейс, как-то с ним дополнительно работать? И достаточно быстро поняли, что в платформе нет практически ничего. Есть места, где интерфейс хранится, есть возможность точечного изменения локализации. В принципе, есть возможность создания продукта сразу же на нескольких языках, если у вас есть какая-нибудь универсальная группа разработчиков, которая может вести проект сразу же на нескольких языках. Но отсутствуют даже такие базовые вещи, как возможность просто выгрузить весь интерфейс и загрузить обратно в те же места без изменения.
Поскольку этим вопросом мы занимались еще в самой компании «1С», а там так исторически сложилось, что если решение нужно, значит, его нужно написать – был создан «1С:Переводчик». Это был 2011-2012 год. Тогда это был огромный скачок вперед. У нас не было ничего, и тут нам дали что-то, с чем можно работать, что решало все наши задачи и писалось специально под нас при нашем участии. Поначалу, когда мы только ввязались в это дело, «1С:Переводчик» полностью закрывал наши потребности. Но мы стали переводить конфигурации, которые все больше по размерам, и уже на уровне Библиотеки Стандартных Подсистем (БСП) столкнулись с тем, что особенности платформы и используемых решений приводили к тому, что уже на объемах БСП (которая меньше, чем любая конфигурация, куда БСП входит) некоторые действия переводчика обрабатывались до 5 минут. Работа строилась так: пользователь создает для элемента перевод, сохраняет его, после чего 5 минут ждет, пока программа анализирует, все ли он сделал хорошо, ничего ли не нарушил, не испортил. Это, естественно, очень сильно повлияло на стоимость перевода. Потому что, во-первых, тратилось много времени, а во-вторых, самых лучших переводчиков мы из-за этого стали терять. Люди отказывались работать по своей обычной сдельной ставке, потому что, если из-за особенностей продукта им приходится делать в три раза меньше, то либо это будет стоить в три раза дороже, либо мы разрешим им работать на том инструменте, который их устраивает, либо «ищите других людей». До определенного этапа мы пытались с этим как-то бороться, но, когда стартовал перевод на английский язык интерфейса конфигурации 1С:ERP, оказалось, что засунуть эту конфигурацию в «1С:Переводчик» просто нельзя.
Соответственно, поскольку наша внутренняя схема перестала работать, у нас было два возможных решения – взять какой-то готовый продукт и поставить его себе, либо взять какой-то готовый облачный продукт.
Из готовых продуктов, который мы могли бы себе установить, мы рассматривали, например, Trados – это лидер рынка, все переводчики его знают. Найти людей для работы с ним очень легко. Но проблема в том, что стоимость подобных продуктов зависит от количества пользователей, либо от объемов текстов. А поскольку у нас на проектах на текущий момент (2026 год – прим. редакции) работает 62 человека (подавляющее большинство — внешние подрядчики), а размеры интерфейсов некоторых конфигураций исчисляются миллионами слов, то, если бы мы взяли подобные решения, расширение списка продуктов, для которых мы готовим интерфейсы, стоило бы очень дорого.
Поэтому мы пошли в сторону облачных решений и остановились на Smartcat.
Обеспечение качества переводов в Smartcat

Что такое Smartcat? Это платформа для переводов, которая закрывает две задачи.
-
Во-первых, это сама среда, где мы переводим.
-
Во-вторых, это некий маркетплейс, где можно взять сотрудников и переводчиков.
Что нам дает среда? За счет чего мы делаем переводы быстрее, дешевле и без потери качества?
-
Во-первых, когда мы переводим продукт на новый язык, прежде чем дать его переводчику, мы вместе со специалистами нарабатываем некий глоссарий. Это – те термины, те обязательные переводы, которые переводчик может использовать. Либо это запрещенные термины и запрещенные переводы, которые переводчик не может использовать.
-
Очень важно, что эта среда позволяет нам полностью переиспользовать все, что мы писали до этого. Начиная от полной подстановки совпадающих сегментов, до подсказок (если строка отличается на одно слово или в целом похожа), которые тоже можно переиспользовать. Возможность запоминания уже сделанных переводов и автозаполнения повторяющихся фрагментов позволила нам создавать на некоторых проектах новый интерфейс и поддерживать его в 5 раз быстрее и, соответственно, в 5 раз дешевле, чем то, что мы делали до этого.
-
Дальше – нас многие спрашивают, работают ли у нас на переводе носители конечного языка? Например, переводят ли у нас на английский носители английского? Мы тоже с этого начали, но поскольку изначальные тексты могут быть очень технически сложные, мы пришли к тому, что у нас на самых ответственных проектах, как правило, работа идет в три этапа – есть переводчик, редактор и корректор. Причем, переводчик – это всегда носитель исходного (в большинстве случаев, русского) языка. Если мы в качестве переводчика сразу же ставим англичанина, американца, то на выходе получаем красивый текст, который по смыслу не очень совпадает с тем, что мы имеем. Причем, есть проекты, где исходный язык не русский, например, 1С:Drive, там исходный язык английский, и с английского мы уже переводим на все остальные языки.
-
В текстах могут использоваться настраиваемые плейсхолдеры – это те части текста, которые переводчик не должен испортить, например, параметры, которые подставляются в сообщение пользователю. Для переводчика – это просто единый неделимый символ, который он обязан использовать в переводе, который он никак не может заменить, пропустить, забыть про него.
-
И сниппеты – это окружение, контекст, слепки текста.
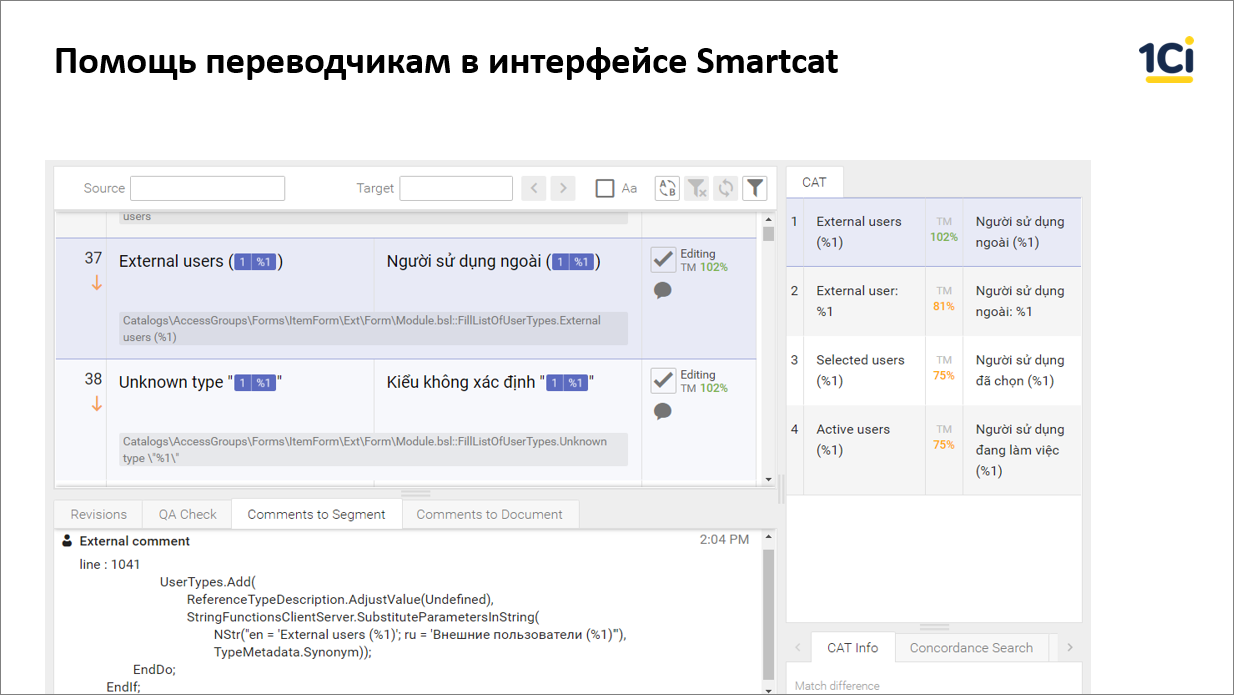
Вот как все это выглядит:
-
У нас есть подсказки – либо полное совпадение, либо частичное;
-
У нас есть параметры в виде плейсхолдеров, которые переводчик не может испортить;
-
У нас есть кусок кода, если это идет из кода;
-
И есть еще очень много других подсказок.
Этот текст – пример того, как мы переводим 1С:Drive с английского на вьетнамский.
Где взять переводчиков

После того, как мы определились со средой для переводов, где нам взять переводчиков?
-
За последние 6 лет у нас уже наработана очень большая база переводчиков. Мы их не скрываем и делимся этой базой с теми партнерами, которые тоже столкнулись с задачей перевода 1С-ных конфигураций, даем им рекомендации.
-
Дальше – если мы выходим на какой-то новый рынок, то обычно начинаем с того, что обращаемся к партнеру 1С, который работает в этой стране, к его опыту – наверняка он уже с кем-то работал, сталкивался с проблемой перевода. Даже если мы ищем переводчиков сами, их все равно верифицируют партнеры в конечной стране.
-
Как я уже говорил, сам Smartcat – это еще и биржа фрилансеров, где мы объявляем большие наборы. На каждый из них к нам обычно приходит порядка 80-90 тестовых работ.
Проверка уровня переводчика при подборе

Итак, как вообще понять, что переводчик, который прислал тестовое задание, либо ваш сотрудник, который говорит, что может сразу же писать код и создавать интерфейс на английском, действительно – того уровня, о котором заявляют?
Мы наработали специальные тестовые задания. Их фишка в том, что они все состоят из подводных камней, и эти камни такие, что мы можем видеть, на каком уровне потенциальный кандидат их прошел, даже не зная конечного языка. Естественно, мы туда вставляем название наших продуктов. Например, в продуктах 1С название всегда пишется без пробела после двоеточия. Если переводчик этого не заметил – это плохо. Это видно сразу, даже если перевод на румынский, на польский, на любой.
Есть и более сложные задания – в некоторых из них, например, мы используем названия сторонних общеизвестных продуктов и пишем их с ошибками. Примерно один из сорока замечает и исправляет. Как я говорил, мы обычно получаем 80-90 тестовых работ, из них выбираем одного-двоих. После того, как мы сами откидываем всех, кто прислал гугло-перевод, и не справился с простейшими заданиями, мы отправляем избранных на проверку к партнеру, и только после того, как партнер готов принимать от нас продукты в переводе с этим человеком, мы берем его в работу.
Автоматизация выгрузки текстов. Наше решение 1Ci SmartSync
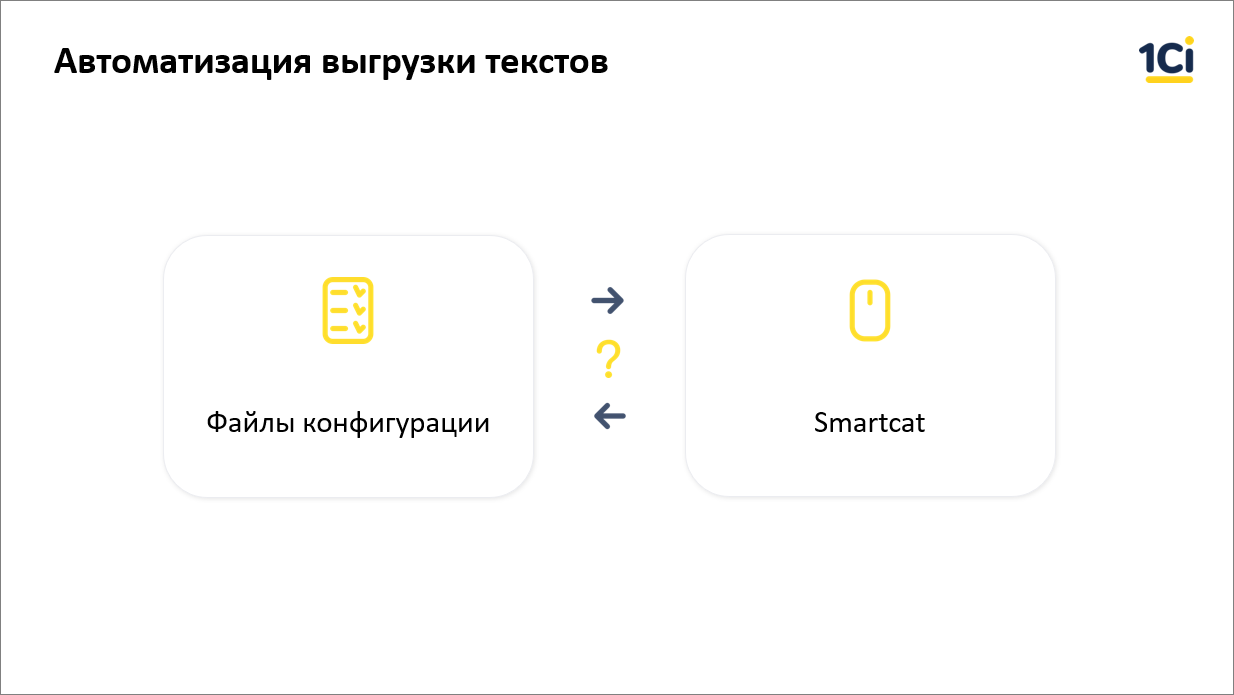
Итак, работаем мы с файлами конфигураций, потому что, как я уже говорил в начале, из платформы при помощи конфигуратора можно выгрузить тексты интерфейсов, но нельзя загрузить их обратно четко по своим местам. Поэтому у нас есть: файлы конфигурации и CAT-платформа, где мы все собираемся переводить, и где у нас уже «заряжены» переводчики. Но между файлами и платформой у нас изначально ничего не было.
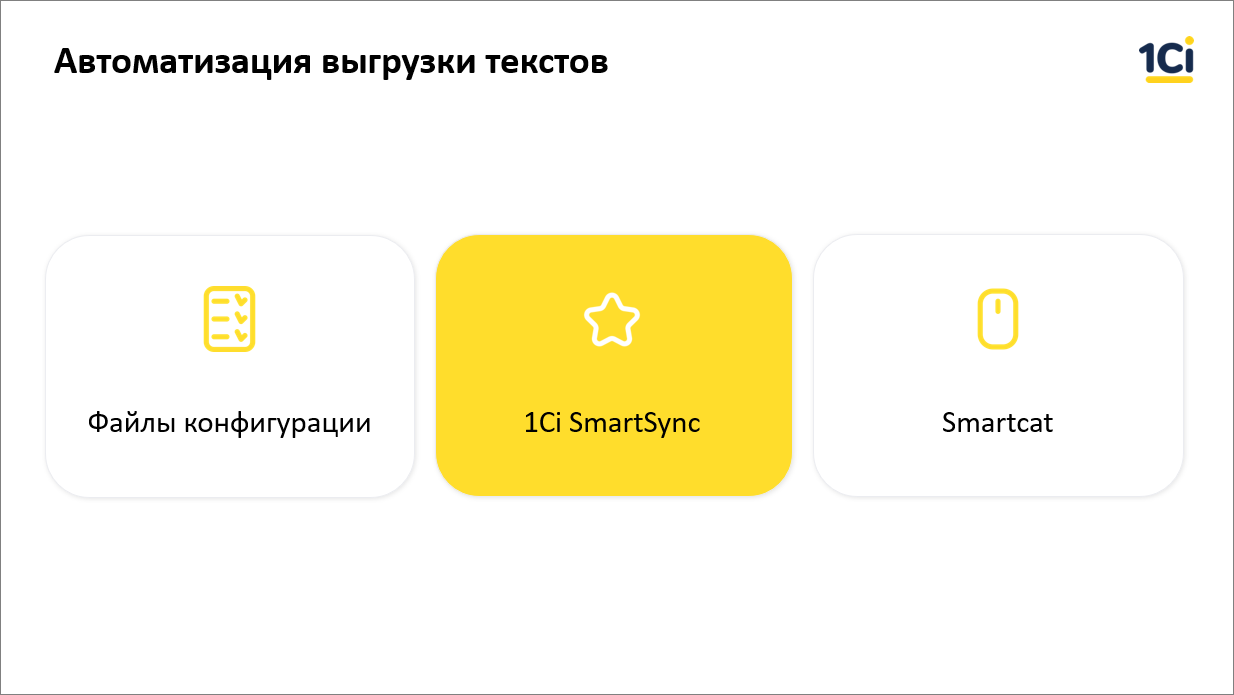
Не было до тех пор, пока мы не создали специальную утилиту SmartSync. Основное ее предназначение – выделять тексты, которые должны пойти в перевод из конфигурации, отправлять в платформу переводов, а после того, как весь перевод завершен, забирать обратно и расставлять по конфигурации.
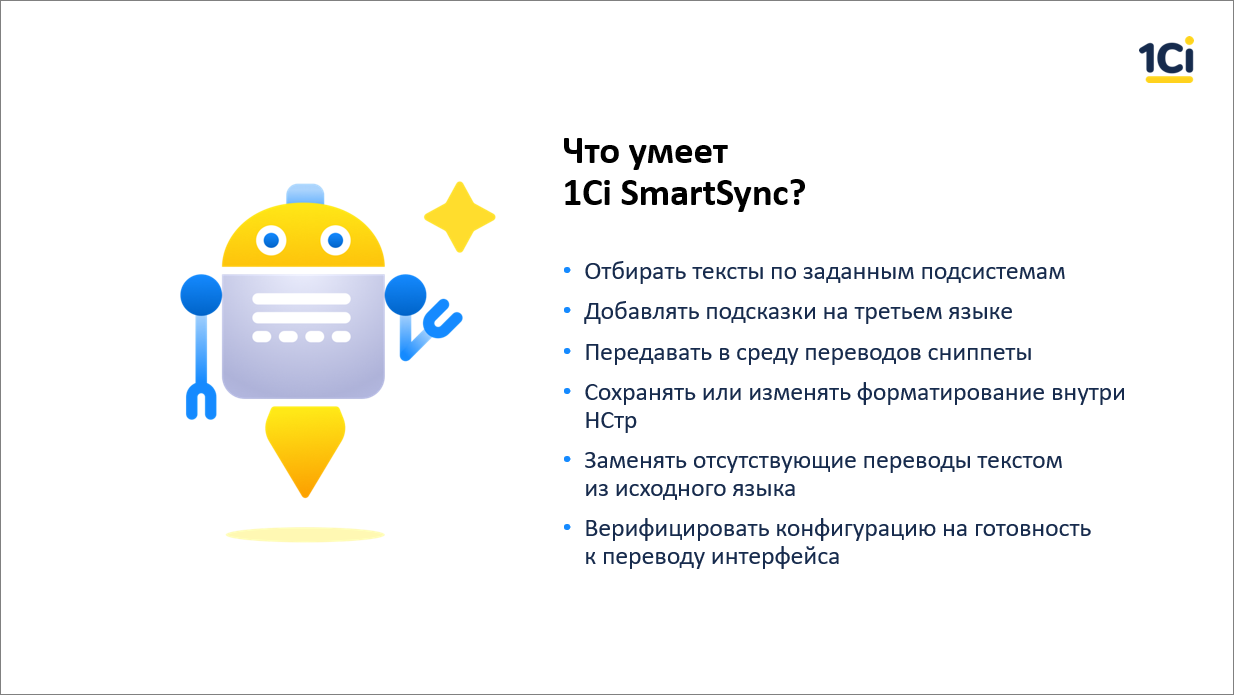
Чему мы научили утилиту SmartSync?
-
Работать только с текстами по выбранным подсистемам. Очень часто, особенно в начале, либо на этапе продажи, либо на пилотных проектах полный перевод не используется. Если мы или партнер пытаемся «выйти в страну», и нам в первом кейсе нужны только продажи/закупки, мы переводим только продажи/закупки плюс всю базовую функциональность
-
Мы научили нашу утилиту добавлять подсказки на третьем языке. Что это значит? Например, если мы готовим интерфейс под вьетнамский язык, и у нас уже есть интерфейс на русском, а продукт на английском, то к переводчику в каждом сегменте уходит и английский исходник, и русский перевод. Потому что, например, в том же Вьетнаме, очень многие, кто переводит с английского на вьетнамский, знают и русский – им проще и понятнее.
-
Передаем сниппеты (максимально контекст) для тех подсистем или для тех частей, которые не переведены.
-
Умеем подставлять исходный текст в перевод. То есть, если нам 1C:Drive нужно быстро перевести на какой-то язык, мы можем перевести только несколько подсистем, а остальные оставить на английском.
-
И, важная часть, умеем верифицировать конфигурацию на готовность интерфейса к переводу.
Проверка готовности продукта к добавлению нового интерфейса

Что значит проверять готовность интерфейса к переводу?
Чтобы перевод интерфейса можно было загрузить в конфигурацию и предоставить пользователю, нам важно пройти несколько шагов и несколько проверок.
-
Во-первых, на то, что интерфейс вообще готов к переводу – начиная с самого простого – с проверки наличия НСтр везде, где нужно, и заканчивая чуть более сложными проверками.
-
Во-вторых – готовность продукта к запуску на новом языке. Это – то, о чем я говорил в начале про работу с интерфейсом из кода – здесь все изменение интерфейса из кода, естественно, всплывает. Мы попытались систематизировать, описать и заложить в проверки все наши кейсы, с которыми мы встречались, и те, которые как-то описаны в стандартах на ИТС.
-
И последнее – это то, о чем почему-то забывают – что все эти изменения в конфигурации надо кому-то делать. На больших проектах уровня ERP у нас выходит, что 45% ресурсов – это непосредственно перевод, а еще 55% – это работа команды разработки, чтобы этот перевод вообще «взлетел», чтобы им можно было пользоваться. То есть, для нового продукта объем доработок кода чуть-чуть превышает объем работы по переводу самого интерфейса.

Здесь перечислены основные проверки, которые реализованы в 1Ci SmartSync.
Процесс перевода интерфейсов конфигурации в Smartcat

Итак, как у нас сейчас выглядит перевод интерфейсов?
Мы работаем с XML-файлами конфигурации, выгруженными стандартными средствами конфигуратора. Дальше наша утилита проводит валидацию конфигурации. Причем, после того как мы получили отчет о том, сколько нам вообще придется работать внутри кода и дорабатывать, очень часто дальше проекты идут в параллель – разработчики вносят изменения, а мы уже переводим интерфейсы. Дальше тексты извлекаются из XML-файлов, отправляются на перевод. Переводим в SmartCat с использованием всех наработок, которые у нас были до этого. То есть, если в конфигурации есть БСП, то все старые переводы БСП приезжают сами. Загружаем переводы обратно, собираем и отправляем на тестирование.
Что может предоставить 1Ci для ускорения и удешевления переводов

Что мы сможем предложить для вас в следующем году?
Мы планируем сделать нашу утилиту общедоступной для партнеров 1Ci в личном кабинете, причем, также мы хотим сделать общедоступными все наши наработки – глоссарии, словари, переводы. Все это будет доступно, если вы станете партнером 1Ci и будете пользоваться нашим сервисом. Мы, естественно, планируем делиться и рекомендациями по переводчикам.

Для партнера процесс перевода будет выглядеть следующим образом:
-
Пункт 0 – стать партнером;
-
Пункт 1 – загрузить конфигурацию в виде cf-файла к нам;
-
Получить отчет о валидации, обработать его, исправить ошибки;
-
Если вы считаете, что конфигурация готова для перевода, разрешить отправку текстов в Smartcat;
-
Перевести;
-
И собрать конфигурацию обратно.
Важная часть – Smartcat как сервис бесплатен, он монетизируется только за счет оплаты работы переводчикам. А если вы регистрируетесь в Smartcat, и у вас переводчиками работают только ваши сотрудники (либо вы сами), то сервис абсолютно бесплатен.
Вопросы:
-
А с обычными формами работает эта утилита?
-
С обычными формами эта утилита не работает, потому что с обычными формами мы сами уже больше не работаем.
-
Речь о переводе только интерфейсов или самого кода?
-
Речь о переводе только интерфейсов. Изыскания по переводу кода проводятся.
-
Я так понял, что используется выгрузка в XML конфигурации, почему не используется штатная выгрузка текстов интерфейсов из конфигурации?
-
Штатная выгрузка текстов интерфейсов хорошо работает на выгрузку, но не работает на загрузку. Если вы делаете выгрузку, вы можете включить поле, которое описывает место вхождения перевода. А при загрузке это поле не используется. Соответственно, все тексты из 1-2 слов, которые переводятся по-разному, обратно приедут вперемешку. Когда мы стали работать с XML-файлами, мы решали именно эту проблему.
-
То есть, у вас перевод выполняется с привязкой к месту? Одни и те же фразы в разных местах конфигурации переводятся несколько раз?
-
Если они должны быть переведены по-разному, то они переводятся несколько раз. Наш опыт – это куски интерфейсов, состоящие из трех и менее слов. Поэтому, если нам на перевод приходит текст из пяти слов, который уже был переведен, мы его переводим автоматически. Если к нам на перевод приходит сегмент, состоящий из одного слова «Вид» (слово, имеющее в английском интерфейсе 4 различных перевода) – мы смотрим по месту, и подставляем термин, который подразумевается в данном конкретном случае.
-
Но в Smartcat вы их храните с привязкой к месту?
-
В Smartcat все хранится с привязкой к месту, просто если большие куски встречаются несколько раз, их можно перевести один раз, и все проставится автоматически.
-
А что с макетами, со справкой?
-
Макеты также переводятся. Справка также переводится. Как раз наша утилита умеет переводить их не в те же самые макеты, а в отдельные. То есть, если макет стандартный – то можно держать несколько языков прямо в нем. А если это doc-файл или что-то еще, тогда перевод приезжает в отдельный файл, и здесь как раз должна сразу же команда завестись на то, что есть несколько макетов. И дальше уже идет работа по адаптации структуры конфигурации с учетом добавленных макетов.
-
Планируется ли встроить в EDT какой-то плагин, в котором пишешь, например, НСтр, и чтобы система сразу же подсказывала перевод, чтобы сразу синхронизация с переводом была?
-
Мы пока разработку такого плагина не планируем.
-
А инструмент SmartSync пока не доступен? Его можно как-то получить?
-
Мы им уже пользуемся, а партнеры смогут им пользоваться в обозримом будущем.
-
Планируется ли в ближайшие месяцы провести какой-то вебинар, чтобы увидеть, как это будет?
-
Конечно, мы будем рассказывать про этот сервис, мы планируем сделать его доступным как в виде веб-сервиса, а для партнеров компании 1Ci это будет бесплатный сервис, они смогут переводить свои конфигурации в любом количестве. Ну и, конечно, мы проведем вебинар, запишем обучающее видео для того, чтобы люди поняли, как это работает, чтобы можно было зайти, посмотреть.
-
Переводите ли вы в интерфейсе все? Например, если есть какие-то скрытые, невидимые для пользователя группы – переводите ли вы их?
-
Да, мы переводим все, включая скрытые группы. Это еще одна задача, которая ложится на плечи разработчиков, потому что очень часто заголовками скрытых групп пренебрегают – и туда что автоматически подставилось, то и остается. Если название сформировано автоматически, то мы уже научили SmartSync в некоторых кейсах эти названия вырезать, потому что они не нужны. Мы считали это проблемой, от которой надо избавляться, и мы начали избавляться. Мы пытаемся скрытые группы вырезать.
-
Очень часто программисты забывают написать синонимы для элементов формы. А если нет синонима, то нет тега синонима, и при парсинге XML-файла с помощью XSLT-преобразования ничего не находится.
-
Это – тоже одна из проверок, которую мы делаем на этапе валидации, и которая попадает в отчет по валидации. Причем, если с синонимами более-менее просто – там сложностей немного, их все можно отловить, там есть гораздо более сложная аналогичная проблема в СКД. Но ее мы тоже уже научились находить.
-
Подскажите, как будет возможно ли при поставке конфигурации выбрать интересующий язык? В частности, 1С:Drive будет поставляться как мультиязычное решение? Или можно будет сгенерировать его для конкретного языка, который меня интересует? Например, мы пользуемся украинской УТ3.0, но используем в ней только русский язык. И у меня в практике была проблема, когда в ряде обновлений начало происходить 90% изменений конфигурации. В первом обновлении в 1С решили изменить префикс удаленных объектов (с «Удалено» на «Видалено»). А на следующем релизе ко мне пришли изменения, которые я вообще видел, а проблема была в том, что они английскую «i» заменили на украинскую, которая визуально ничем не отличается. Вопрос в том, что, если выходить на рынок и выпускать мультиязычные решения – как лучше делать? Бандлами или на каждый конкретный язык отдельно? Чтобы люди, которые занимаются поддержкой локального решения для локального рынка не страдали тем, что они вынуждены обновляться и искать подводные камни, связанные с локализацией, которая их в принципе не интересует.
-
У нас была такая ситуация, когда в конфигурации везде в конце предложений проставили точки, и к нам все это приехало на перевод как новые тексты. Как мы решаем эту проблему у нас? Разработка ведется только на одном языке. Все переводы хранятся в Smartcat, а Smartcat умеет отлавливать «серьезность» изменений в сегменте. Когда приезжает новая версия, технически мы можем сделать сборку с любым набором языков. С каким будем делать – зависит от запроса. Стандартно, когда к нам приезжает 1C:Drive, мы делаем сборку со всеми внешними языками. Но опять же, технически нам совершенно не сложно в нашей системе реализовать сборку для конкретного языка. И, соответственно, для партнеров, которые будут потом пользоваться нашим сервисом, набор языков на выходе может быть любой.
-
Мы столкнулись с тем, что, когда перевод планируется на большое количество языков, код 1С превращается просто в кашу. Допустим, есть фраза «Не хватает остатка на складе». Мы у себя в интерфейсе делали эксперимент – делали для нашей конфигурации через Crowdin перевод на 30 языков, грубо говоря, просто через Google Translate. Все это подгрузили, просто чтобы посмотреть, что это будет. Во-первых, 30 языков у нас не запустилось, платформа падала, мы ограничились 25. Но в итоге, мы открываем в конфигураторе модуль, видим вызов метода СообщитьПользователю, и на полэкрана перечисление всех этих переводов. Отсюда вопрос, как нам, как разработчикам ядра, быть? Вроде все просто – берем, пишем на английском код, дальше просто патчим конфигурацию и получаем эту портянку. А конечным потребителям (разработчикам конфигурации) приходится работать с этой портянкой. У них половина экрана занимает этот НСтр. В итоге мы вообще отказались от такого указания НСтр, сделали переопределение через переопределяемые общие модули и мы там сделали отдельный кластер с описанием всех этих локалей, а там, где идет вызов, мы сделали аналог вызова языка из файловых ресурсов (по аналогии с языками, которые изначально ориентированы на мультиязычность, где все сделано через rstring-файлы). Я так понимаю, что вы тоже столкнулись с такой же проблемой, есть ли какие-то мысли о том, куда двигаться в этом плане, чтобы на это не нарываться?
-
Мы решили эту проблему следующим образом. SmartSync, когда расставляет переводы, выводит текст на каждом новом языке с новой строки. У нас идет НСтр, далее первым, как правило, английский (или русский, если это перевод русского). Портянка читаемая, нет длиннющей строки, все тексты ровно друг под другом. Причем, это можно регулировать с помощью опции «Сохранять или изменять форматирование внутри НСтр».
-
Получается, что, если у меня текст состоит из двух кусков НСтр, между которыми переменная, этот текст разобьется?
-
Если у вас одно предложение, собираемое сложением нескольких НСтр, это ошибка, которую нужно исправлять, потому что в разных языках порядок слов разный. Поэтому все предложения, которые собираются динамически при помощи конкатенации, мы выкатываем в отчет об ошибках на этапе валидации и исправляем.
-
Существует практическая задача – есть конфигурация, которая используется только в России, но компания возит грузы в Китай, и необходимо печатать документ на китайском языке. При этом конфигурация на обычном приложении 8.2. Может ли ваша практика как-то помочь в решении этой задачи?
-
Сложный вопрос. Если это решение основано на старых методах, вам, вероятнее всего, придется адаптироваться, иначе придут те, кто пользуются уже новыми методами.
-
Был ли у вас опыт или потребность в локализации существующих данных?
-
Естественно, данные локализуются, но это еще один такой же доклад. Например, во всех конфигурациях, которые мы делаем, у нас есть демоданные на конечном языке.
-
Я имею в виду, когда я задаю наименование номенклатуры, я хочу задать его на нескольких языках – если конфигурация используется в разных регионах, в разных странах одновременно.
-
Платформа не поддерживает стандартно ведение самих данных на нескольких языках. Мы пришли к тому, что сами демоданные (просто дословно переведенные), как правило, не нужны. Мы под каждую страну создаем свой набор.
А с обычными формами работает эта утилита?
С обычными формами эта утилита не работает, потому что с обычными формами мы сами уже больше не работаем.
Речь о переводе только интерфейсов или самого кода?
Речь о переводе только интерфейсов. Изыскания по переводу кода проводятся.
Я так понял, что используется выгрузка в XML конфигурации, почему не используется штатная выгрузка текстов интерфейсов из конфигурации?
Штатная выгрузка текстов интерфейсов хорошо работает на выгрузку, но не работает на загрузку. Если вы делаете выгрузку, вы можете включить поле, которое описывает место вхождения перевода. А при загрузке это поле не используется. Соответственно, все тексты из 1-2 слов, которые переводятся по-разному, обратно приедут вперемешку. Когда мы стали работать с XML-файлами, мы решали именно эту проблему.
То есть, у вас перевод выполняется с привязкой к месту? Одни и те же фразы в разных местах конфигурации переводятся несколько раз?
Если они должны быть переведены по-разному, то они переводятся несколько раз. Наш опыт – это куски интерфейсов, состоящие из трех и менее слов. Поэтому, если нам на перевод приходит текст из пяти слов, который уже был переведен, мы его переводим автоматически. Если к нам на перевод приходит сегмент, состоящий из одного слова «Вид» (слово, имеющее в английском интерфейсе 4 различных перевода) – мы смотрим по месту, и подставляем термин, который подразумевается в данном конкретном случае.
Но в Smartcat вы их храните с привязкой к месту?
В Smartcat все хранится с привязкой к месту, просто если большие куски встречаются несколько раз, их можно перевести один раз, и все проставится автоматически.
А что с макетами, со справкой?
Макеты также переводятся. Справка также переводится. Как раз наша утилита умеет переводить их не в те же самые макеты, а в отдельные. То есть, если макет стандартный – то можно держать несколько языков прямо в нем. А если это doc-файл или что-то еще, тогда перевод приезжает в отдельный файл, и здесь как раз должна сразу же команда завестись на то, что есть несколько макетов. И дальше уже идет работа по адаптации структуры конфигурации с учетом добавленных макетов.
Планируется ли встроить в EDT какой-то плагин, в котором пишешь, например, НСтр, и чтобы система сразу же подсказывала перевод, чтобы сразу синхронизация с переводом была?
Мы пока разработку такого плагина не планируем.
А инструмент SmartSync пока не доступен? Его можно как-то получить?
Мы им уже пользуемся, а партнеры смогут им пользоваться в обозримом будущем.
Планируется ли в ближайшие месяцы провести какой-то вебинар, чтобы увидеть, как это будет?
Конечно, мы будем рассказывать про этот сервис, мы планируем сделать его доступным как в виде веб-сервиса, а для партнеров компании 1Ci это будет бесплатный сервис, они смогут переводить свои конфигурации в любом количестве. Ну и, конечно, мы проведем вебинар, запишем обучающее видео для того, чтобы люди поняли, как это работает, чтобы можно было зайти, посмотреть.
Переводите ли вы в интерфейсе все? Например, если есть какие-то скрытые, невидимые для пользователя группы – переводите ли вы их?
Да, мы переводим все, включая скрытые группы. Это еще одна задача, которая ложится на плечи разработчиков, потому что очень часто заголовками скрытых групп пренебрегают – и туда что автоматически подставилось, то и остается. Если название сформировано автоматически, то мы уже научили SmartSync в некоторых кейсах эти названия вырезать, потому что они не нужны. Мы считали это проблемой, от которой надо избавляться, и мы начали избавляться. Мы пытаемся скрытые группы вырезать.
Очень часто программисты забывают написать синонимы для элементов формы. А если нет синонима, то нет тега синонима, и при парсинге XML-файла с помощью XSLT-преобразования ничего не находится.
Это – тоже одна из проверок, которую мы делаем на этапе валидации, и которая попадает в отчет по валидации. Причем, если с синонимами более-менее просто – там сложностей немного, их все можно отловить, там есть гораздо более сложная аналогичная проблема в СКД. Но ее мы тоже уже научились находить.
Подскажите, как будет возможно ли при поставке конфигурации выбрать интересующий язык? В частности, 1С:Drive будет поставляться как мультиязычное решение? Или можно будет сгенерировать его для конкретного языка, который меня интересует? Например, мы пользуемся украинской УТ3.0, но используем в ней только русский язык. И у меня в практике была проблема, когда в ряде обновлений начало происходить 90% изменений конфигурации. В первом обновлении в 1С решили изменить префикс удаленных объектов (с «Удалено» на «Видалено»). А на следующем релизе ко мне пришли изменения, которые я вообще видел, а проблема была в том, что они английскую «i» заменили на украинскую, которая визуально ничем не отличается. Вопрос в том, что, если выходить на рынок и выпускать мультиязычные решения – как лучше делать? Бандлами или на каждый конкретный язык отдельно? Чтобы люди, которые занимаются поддержкой локального решения для локального рынка не страдали тем, что они вынуждены обновляться и искать подводные камни, связанные с локализацией, которая их в принципе не интересует.
У нас была такая ситуация, когда в конфигурации везде в конце предложений проставили точки, и к нам все это приехало на перевод как новые тексты. Как мы решаем эту проблему у нас? Разработка ведется только на одном языке. Все переводы хранятся в Smartcat, а Smartcat умеет отлавливать «серьезность» изменений в сегменте. Когда приезжает новая версия, технически мы можем сделать сборку с любым набором языков. С каким будем делать – зависит от запроса. Стандартно, когда к нам приезжает 1C:Drive, мы делаем сборку со всеми внешними языками. Но опять же, технически нам совершенно не сложно в нашей системе реализовать сборку для конкретного языка. И, соответственно, для партнеров, которые будут потом пользоваться нашим сервисом, набор языков на выходе может быть любой.
Мы столкнулись с тем, что, когда перевод планируется на большое количество языков, код 1С превращается просто в кашу. Допустим, есть фраза «Не хватает остатка на складе». Мы у себя в интерфейсе делали эксперимент – делали для нашей конфигурации через Crowdin перевод на 30 языков, грубо говоря, просто через Google Translate. Все это подгрузили, просто чтобы посмотреть, что это будет. Во-первых, 30 языков у нас не запустилось, платформа падала, мы ограничились 25. Но в итоге, мы открываем в конфигураторе модуль, видим вызов метода СообщитьПользователю, и на полэкрана перечисление всех этих переводов. Отсюда вопрос, как нам, как разработчикам ядра, быть? Вроде все просто – берем, пишем на английском код, дальше просто патчим конфигурацию и получаем эту портянку. А конечным потребителям (разработчикам конфигурации) приходится работать с этой портянкой. У них половина экрана занимает этот НСтр. В итоге мы вообще отказались от такого указания НСтр, сделали переопределение через переопределяемые общие модули и мы там сделали отдельный кластер с описанием всех этих локалей, а там, где идет вызов, мы сделали аналог вызова языка из файловых ресурсов (по аналогии с языками, которые изначально ориентированы на мультиязычность, где все сделано через rstring-файлы). Я так понимаю, что вы тоже столкнулись с такой же проблемой, есть ли какие-то мысли о том, куда двигаться в этом плане, чтобы на это не нарываться?
Мы решили эту проблему следующим образом. SmartSync, когда расставляет переводы, выводит текст на каждом новом языке с новой строки. У нас идет НСтр, далее первым, как правило, английский (или русский, если это перевод русского). Портянка читаемая, нет длиннющей строки, все тексты ровно друг под другом. Причем, это можно регулировать с помощью опции «Сохранять или изменять форматирование внутри НСтр».
Получается, что, если у меня текст состоит из двух кусков НСтр, между которыми переменная, этот текст разобьется?
Если у вас одно предложение, собираемое сложением нескольких НСтр, это ошибка, которую нужно исправлять, потому что в разных языках порядок слов разный. Поэтому все предложения, которые собираются динамически при помощи конкатенации, мы выкатываем в отчет об ошибках на этапе валидации и исправляем.
Существует практическая задача – есть конфигурация, которая используется только в России, но компания возит грузы в Китай, и необходимо печатать документ на китайском языке. При этом конфигурация на обычном приложении 8.2. Может ли ваша практика как-то помочь в решении этой задачи?
Сложный вопрос. Если это решение основано на старых методах, вам, вероятнее всего, придется адаптироваться, иначе придут те, кто пользуются уже новыми методами.
Был ли у вас опыт или потребность в локализации существующих данных?
Естественно, данные локализуются, но это еще один такой же доклад. Например, во всех конфигурациях, которые мы делаем, у нас есть демоданные на конечном языке.
Я имею в виду, когда я задаю наименование номенклатуры, я хочу задать его на нескольких языках – если конфигурация используется в разных регионах, в разных странах одновременно.
Платформа не поддерживает стандартно ведение самих данных на нескольких языках. Мы пришли к тому, что сами демоданные (просто дословно переведенные), как правило, не нужны. Мы под каждую страну создаем свой набор.
***************************************************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 EDUCATION. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке