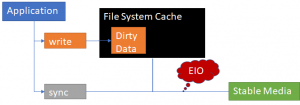
Разработчики СУБД в силу необходимости, озабочены тем, чтобы данные безопасно попадали в постоянное хранилище. Поэтому, когда сообщество PostgreSQL обнаружило, что то, как ядро обрабатывает ошибки ввода-вывода, может привести к потере данных без каких-либо ошибок, сообщаемых в пользовательское пространство, возникло немало недовольства. Проблема, которая усугубляется тем, что PostgreSQL выполняет буферизованный ввод-вывод, оказывается, не является уникальной для Linux, и ее будет нелегко решить даже там.
Крейг Рингер впервые сообщил о проблеме в список рассылки pgsql-hackers в конце марта. Короче говоря, PostgreSQL предполагает, что успешный вызов fsync() указывает на то, что все данные, записанные с момента последнего успешного вызова, безопасно перешли в постоянное хранилище. При сбое буферизованной записи ввода-вывода из-за аппаратной ошибки файловые системы реагируют по-разному, но такое поведение обычно включает удаление данных на соответствующих страницах и пометку их как чистых. Поэтому чтение блоков, которые были только что записаны, скорее всего, вернет что-то другое, но не записанные данные.
Что насчет отчетов об ошибках? Год назад на саммите Linux Filesystem, Storage и Memory-Management Summit (LSFMM) включал в себя сессию по сообщениям об ошибках, в которой это все было названо «беспорядком»; ошибки легко могут быть потеряны, так что ни одно приложение никогда их не увидит. Некоторые патчи, включенные 4.13, в ходе цикла разработки несколько улучшили ситуацию (и в 4.16 произошли некоторые изменения для её дальнейшего улучшения), однако существуют способы потери уведомлений об ошибках, как будет описано ниже. Если это происходит на сервере PostgreSQL, это может привести к автоматическому повреждению базы данных.
Разработчики PostgreSQL были недовольны. Том Лейн описал это "повреждением мозга ядра", в то время как Роберт Хаас назвал "100% глупостью". В начале обсуждения разработчики PostgreSQL достаточно четко понимали, как, по их мнению, должно работать ядро: страницы, которые не могут быть записаны, должны храниться в памяти в «грязном» состоянии (для последующих попыток), и соответствующий файловый дескриптор должен быть переведен в состояние постоянной ошибки, чтобы сервер PostgreSQL не мог пропустить наличие проблемы.
В каком месте что-то пошло не так
Однако еще до того, как в дискуссию вступило сообщество ядра, стало ясно, что ситуация не настолько проста, как может показаться. Томас Мунро сообщил, что Linux не уникален в подобном поведении; OpenBSD и NetBSD также могут не сообщать об ошибках записи в пространство пользователя. И, как выяснилось, то, как PostgreSQL обрабатывает буферизованные операции ввода-вывода, значительно усложняет картину.
Этот механизм был подробно описан Хаасом. Сервер PostgreSQL работает как набор процессов, многие из которых могут выполнять операции ввода-вывода в файлы базы данных. Задание вызова fsync(), однако, обрабатывается в одном процессе checkpointer («checkpointer» process), который касается поддержания дискового хранилища в согласованном состоянии, для восстановления после сбоев. Сheckpointer обычно не поддерживает все соответствующие файлы открытыми, поэтому ему часто приходится открывать файл перед вызовом fsync(). Именно здесь возникает проблема: даже в ядрах 4.13 и более поздних версиях checkpointer не увидит никаких ошибок, произошедших до открытия файла. Если что-то нехорошее случится до вызова open() checkpointer-a, то следующий вызов fsync() вернет успех. Существует несколько способов возникновения ошибки ввода-вывода вне вызова fsync(); например ядро может столкнуться с одной из них при выполнении фоновой обратной записи. Кто-то, вызывающий sync(), может также столкнуться с ошибкой ввода-вывода и «поглотить» полученное состояние ошибки.
Хаас описал такое поведение как неспособное соответствовать ожиданиям PostgreSQL:
Все, что у вас (или у кого-то) есть — в основном это недоказанное предположение о том,
какие файловые дескрипторы могут иметь отношение к конкретной ошибке, но так получилось, что PostgreSQL никогда не соответствовал ему. Вы можете продолжать говорить, что проблема в наших догадках, но мне кажется не правильно предполагать, что мы — единственная программа, которая их когда-либо делала.
В итоге Джошуа Дрейк перенес беседу в список разработки для ext4, включив часть сообщества разработчиков ядра. Дэйв Чиннер быстро охарактеризовал это поведение как "рецепт катастрофы, особенно в кросс-платформенном коде, где каждая платформа ОС ведет себя по-разному и почти никогда не соответствует ожидаемому". Вместо этого Тед Цо объяснил, почему затронутые страницы помечаются как чистые после возникновения ошибки ввода-вывода; короче говоря, самой распространенной причиной ошибок ввода-вывода является извлечение пользователем USB-накопителя не вовремя. Если какой-то процесс копировал на этот диск много данных, результатом будет накопление грязных страниц в памяти, возможно, до такой степени, что системе не хватит памяти для других задач. Таким образом, эти страницы не могут быть сохранены и будут очищены, если пользователь хочет, чтобы система оставалась пригодной для использования после такого события.
И Чиннер, и Цо, вместе с другими, заявили, что для PostgreSQL правильное решение — перейти на прямой ввод-вывод (DIO). Использование DIO дает больший уровень контроля над обратной записью (writeback) и вводом-выводом в целом; это включает в себя доступ к информации о том, какие именно операции ввода-вывода могли быть неудачными. Андрес Фройнд, как и ряд других разработчиков PostgreSQL, признал, что DIO является лучшим долгосрочным решением. Но он также отметил, что не стоит ждать, что разработчики сейчас по уши окунуться в реализацию этой задачи. Между тем, он сказал, что существуют другие программы (он упомянул dpkg), которые также подвержены этому поведению.
На пути к краткосрочному решению
В ходе обсуждения значительное внимание было уделено идее, что сбой записи должен приводить к тому, что затронутые страницы будут храниться в памяти в их грязном состоянии. Но разработчики PostgreSQL быстро отошли от этой идеи и не требовали этого. То, что им действительно нужно, в итоге — надежный способ узнать, что-то пошло не так. Учитывая это, обычные механизмы PostgreSQL для обработки ошибок могут справиться с этим; однако в его отсутствие мало что можно сделать.
В какой-то момент обсуждения Цо упомянул, что у Google есть собственный механизм обработки ошибок ввода-вывода. Ядро было проинструктировано сообщать об ошибках ввода-вывода через сокет netlink; выделенный процесс получает эти уведомления и отвечает соответственно. Все же этот механизм никогда не делал этого на входе. Фрейнд указал, что этот механизм будет «идеальным» для PostgreSQL, поэтому он может появиться в открытом доступе в ближайшее время.
Между тем Джефф Лейтон задумался над другой идеей: установить флаг в суперблоке файловой системы при возникновении ошибки ввода-вывода. Вызов syncfs() затем очистит этот флаг и вернет ошибку, если он был установлен. PostgreSQL checkpointer может периодически вызывать syncfs() для опроса ошибок в файловой системе, содержащей базу данных. Фройнд согласился, что это может быть жизнеспособным решением проблемы.
Конечно, любой такой механизм появится только в новых ядрах; тем временем установки PostgreSQL, как правило, работают на старых ядрах, поддерживаемых корпоративными дистрибутивами. В этих ядрах, по всей видимости, отсутствуют даже те улучшения, которые были включены в 4.13. Для таких систем мало что можно сделать, чтобы помочь PostgreSQL обнаруживать ошибки ввода-вывода. Может хватить запуска демона, который сканирует системный журнал и ищет там сообщения об ошибках ввода-вывода. Не самое элегантное решение, и оно осложняется тем, что разные драйверы блоков и файловые системы, как правило, сообщают об ошибках по-разному, но это может быть наилучшим доступным вариантом.
Следующим шагом, вероятно, станет обсуждение на мероприятии LSFMM 2026 года, которое состоится 23 апреля. Если повезет, появится какое-то решение, которое будет работать для заинтересованных сторон. Однако одна вещь, которая не изменится — это простой факт, что обработку ошибок трудно сделать правильно.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале