

Решил развенчать мифы по поводу "тормознутости" технологии COM при работе с Microsoft Excel и оперировании большими объемами данных.
Большими объемами данных в данном случае будет считаться матрица 50к х 20 элементов, т.е. 1Миллион элементов.
Для этого была создана простейшая обработка (проверена на платформе 8.3.14.1565), которая один и тот же табличный файл может читать как с привлечением MS Excel на клиенской машине, так и с помощью нативной возможности платформы 1С 8.х, появившейся уже достаточно давно.
Итак, первым в забеге был MS EXCEL.
Т.к. тест проводился в клиент-серверной базе, и на сервере приложения 1С не установлен MS Excel, то в данном случае придется передавать большой объем данных с клиента 1С на сервер 1С.
Результаты теста следующие:
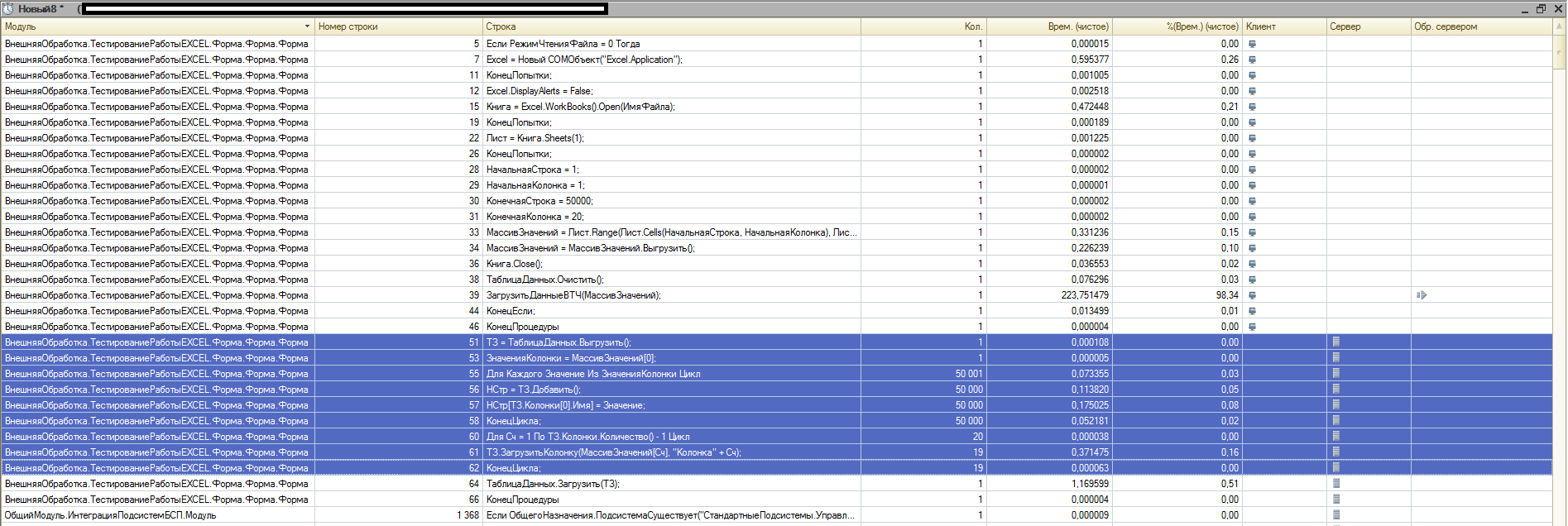
Выделенные строки — это ЧИСТОЕ время формирования ТЗ на 1миллион значений. Чистое время составляет 0.785961 секунды. Время получения самого массива данных из MS Excel в 1С:

Т.е. 0.557474 секунды.
ИТОГО: 0.595377(создание COM-объекта MS EXCEL) + 0.472448(открытие файла) + 0.785961 + 0.557474 = 2.41126 секунды.
Время на передачу массива между клиентом и сервером не считаем, т.к. на сервере 1С установлен MS Excel.
Вторым был нативный метод чтения табличных документов платформой 1С.
Т.к. тест проводился в клиент-серверной базе, в данном случае придется передавать сам файл с клиента 1С на сервер 1С. Время передачи файла — 0.770753 секунды.
Результаты теста следующие:
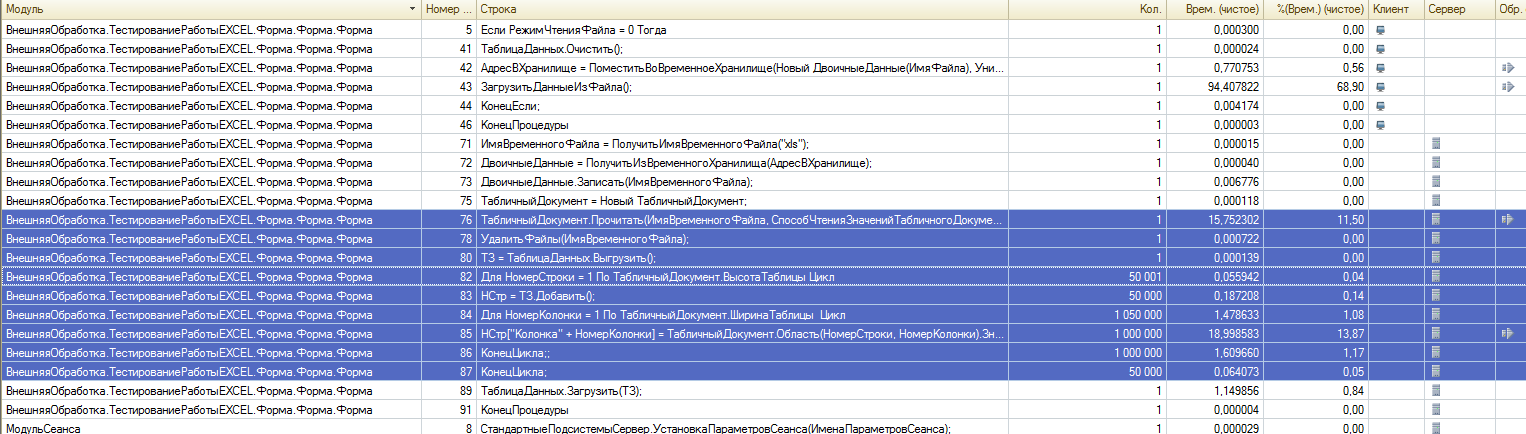
Выделенные строки — это ЧИСТОЕ время формирования ТЗ на 1миллион значений. Чистое время составляет 22.394099 секунд.
ИТОГО: 0.770753(время на передачу файла с клиента 1С на сервер 1С) + 15.752302(время на чтение табличного документа из файла) + 22.394099 секунд = 38.917154 секунды.
Внимательный читатель спросит: "почему при чтении через COM не учитывается время на передачу файла с клиента 1С на сервер?"
Ответ: Вносим корректировки в результаты.
Вариант1:
ВремяПередачиФайлаСКлиентаНаСервер = 0.770753 секунды
ОбщееВремяФормированияТЗ = 2.41126 секунды
Итого: 0.770753 секунды + 2.41126 секунды = 3.182013 секунды
Мораль сей басни такова: не стесняйтесь использовать Microsoft Excel на сервере 1С — это ЗАМЕТНО увеличивает скорость выгрузки/загрузки данных в/из табличных документов.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
медленный в том случае, если считывать по ячейкам (через Cell), а если через COMSafeArray — то быстро.
а с использованием ADO?
(2)ADO использует тот же COM, только умеет работать с массивами.
(0), если можно код приведите чтения средствами платформы. Что-то ощущение, что происходили какие-то ненужные операции в цикле, которые совсем не нужны.
(4)Ничего там не используется, кроме тупого перебора всего миллиона ячеек, в отличие от варианта с MS Excel.

(4) Перезамерил время. Вот так более информативно.
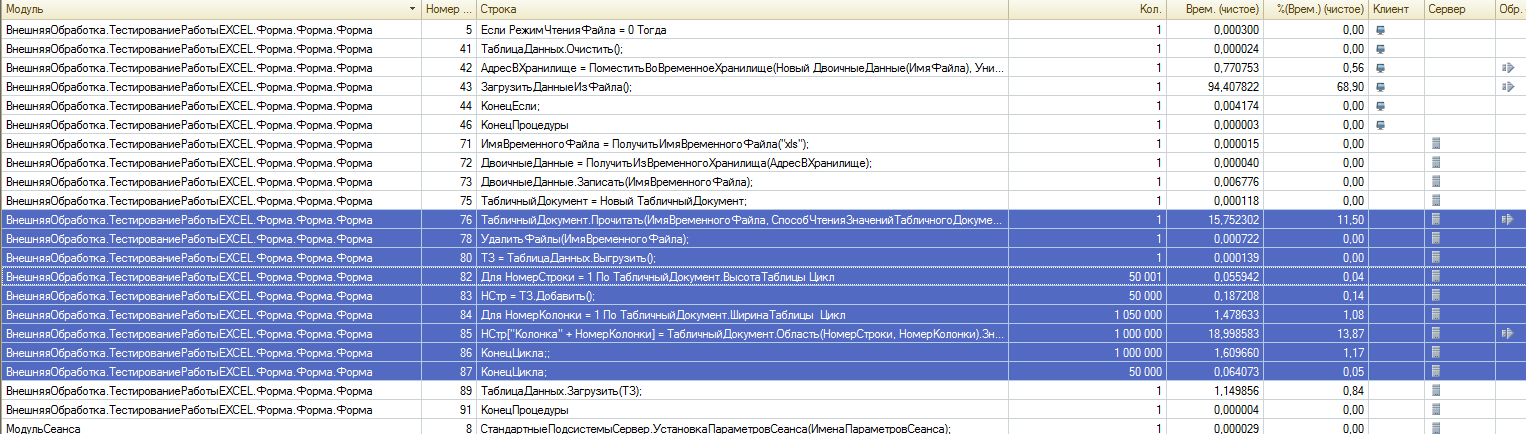
(5), очень странно.. Я понял, что я был не прав в первом случае про циклы, т.к. не учел что надо перевести еще данные в ТЗ. Но можете попробовать тот же фокус с форматом xlsx? На сколько будет отличаться скорость чтения.
(7) Да без разницы.
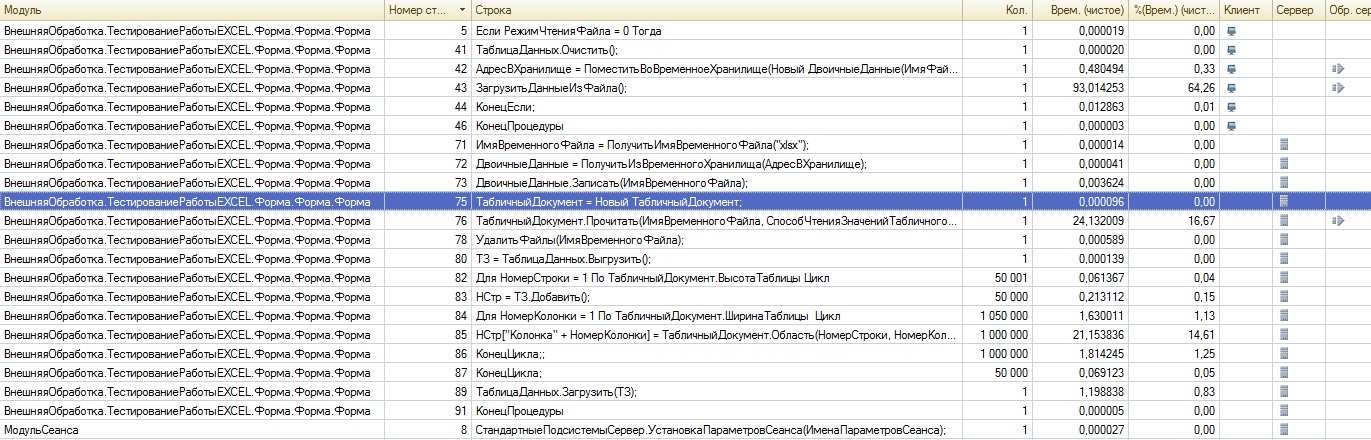
обойти миллион значений — ДОЛГО в любом случае.
Для того, что бы было быстро, ТабДок должен уметь делать
И
Пока этого не будет — MS Excel будет вне конкуренции.
Причем МассивМассивов должен содержать в себе массивы по колонкам, а не по строкам, как это делает Ado.Recordset и OpenOffice/LibreOffice.
Немного не корректно в статье указаны замеры чтения для COM, если сравнивать с чтением через табличный документ.
Вы либо включите в замер создание ком объекта, а также всю работу с ком объектом в первый замер, либо из второго уберите ТабличныйДокумент.Прочитать().
На результат конечно это особо не повлияет, платформа читает дольше, но хотя бы сравниваться будут одинаковые действия.
(9) Время на создание COM-объекта и открытие файла было добавлено в самом конце в количестве 1 секунды на все.
Переделал, добавил это время во время формирования ТЗ.
Не корректно измерять производительность цикла в миллион итераций в режиме отладки. Отключите отладку. Используйте ТекущаяУниверсальнаяДатаВМиллисекундах() в коде. Для чистоты эксперимента цикл запишите в строку.
(11)Вы серьезно считаете, что все эти меры драматически ускорят процесс чтения 1М ячеек циклом 1С?
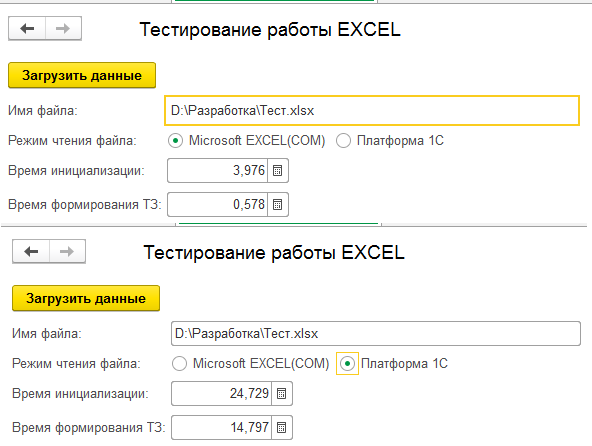
Хорошо. Вот результаты:
Время расчитывалось вот так:
Как было ~10-кратное превосходство, так и осталось.
(12)На 8.3.16 пробовали?
Тут пишут, что оптимизировали потребление памяти в табдоке.
Может он и работать побыстрее будет.
(13) Да проблема не в памяти вообще, оно не может быстрее работать, потому что 1М итераций в любом случае выполнить придется, в отличии от 50к итераций в случае MS EXCEL. Если бы ТЗ умела как массив создаваться сразу с определенным количеством строк, то и этих 50к итераций не было бы.
Как только платформа 1С научится работать с ТабДоком, как это делает MS EXCEL(см. (8)), так про EXCEL можно забыть сразу же.
У меня пока нет тестового сервера 8.3.16 версии. Пробовал на 8.3.14.1565.
(14)
Это на самом деле не важно сколько итераций.
Не всем и не всегда надо грузить файл с размером 50к х 20.
Замедление наблюдается при получении значений свойств табдока и его областей.
Если в платформе починили работу с памятью, может и работать будет быстрее.
Как само чтение, так и обращение к нему.
(15)В данном конкретном случае как раз таки ОЧЕНЬ важно общее количество итераций, т.к. значения из ТабДока можно получить ТОЛЬКО обходом ВСЕХ нужных ячеек, в случае с MS EXCEL — это вообще не так, там 1М ячеек обходится за 50к итераций и то ТОЛЬКО для того, чтобы сформировать нужное количество строк в итоговой ТЗ.
(16)
Отличие MS EXCEL и чтения через таб.док я понимаю.
Речь не о данный конкретный случай.
У меня много задач по работе с таб.доком.
Поэтому было интересно, какие будут результаты вашего теста на 8.3.16, по сравнению с замерами в статье.
Я могу на своей рабочей машине протестировать в файловом варианте, если вы такой результат будете считать удовлетворительным.
(18)Если несложно, было бы хорошо=)
(19) Как-то так:
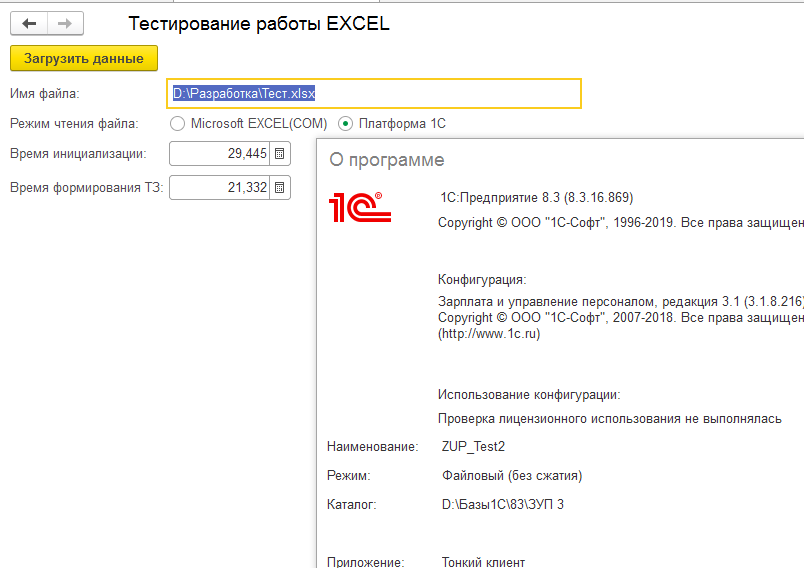
(20)Спасибо
(12) Правда ваша.