
В самом начале
Всем известно решение 1С:Конвертация данных 2.0 (да и 3.0, конечно, тоже), с помощью которого можно гибко настраивать правила обмена данными между различными решениями на базе платформы 1С. Несмотря на то, что уже вышла версия КД 3.0, предыдущая версия до сих пор остается часто используемым инструментом, ведь работать с ней проще, да и решаемые задачи и подходы к интеграции у обеих версий разные. А сколько еще решений на поддержке с обменом через КД 2.0!
Это информация из старого блога DevelPlatform.ru
Нет, сегодня мы не будем рассматривать возможности конвертации данных, ее применение в обмене данными и другие близкие к интеграции вопросы. Мы коснемся одно из множества способов оптимизации алгоритмов интеграции — ускорение чтения правил обмена данными. Весь материал ниже актуален для старой, доброй УПП. Но с некоторыми модификациями его можно применить и к современным механизмам обмена.
В память об УПП! Ура, товарищи!
Если УПП для Вас — это настоящее, то может быть интересна публикация о внутреннем устройстве прав доступа и настроек пользователей в УПП.
Начнем
Работали ли Вы когда-нибудь с большими конфигурац иями, содержащими несколько сотен объектов метаданных? А были ли у Вас на поддержке правила обмена, которые описывали конвертацию всех эти объектов? Вне зависимости от ответов "Да" или "Нет" я думаю Вы понимаете, что работа с такими объемными правилами может вызвать затруднения, причем не только на этапе их модификации, но и на этапе непосредственного обмена данными. Чем больше размером файл правил, тем больше времени нужно чтобы прочитать все находящиеся в нем правила и подготовиться выполнять обмен.
иями, содержащими несколько сотен объектов метаданных? А были ли у Вас на поддержке правила обмена, которые описывали конвертацию всех эти объектов? Вне зависимости от ответов "Да" или "Нет" я думаю Вы понимаете, что работа с такими объемными правилами может вызвать затруднения, причем не только на этапе их модификации, но и на этапе непосредственного обмена данными. Чем больше размером файл правил, тем больше времени нужно чтобы прочитать все находящиеся в нем правила и подготовиться выполнять обмен.
Сегодня в статье пойдет речь как-раз о решении подобной проблемы. Мы оптимизируем чтение правил обмена на примере конфигурации "Управление производственным предприятием" (УПП) редакции 1.3. Из названия статьи уже можно понять на сколько значительным!
Суть проблемы
Две конфигурации УПП, объемные правила конвертации, односторонний обмен между центральной и периферийной базой, и периодичность обмена раз в 5 минут — это все что нам дано в этой задаче. Ах да, спросите для чего нужно так часто выполнять обмен? Причин может быть много: нужно оперативно смотреть информацию в центральной базе, нужно выполнять оперативный контроль работы и много другое. Для нас это и не важно сейчас. Есть задача сделать такой обмен — так давайте сделаем!
Размер файла XML правил обмена занимает порядка 120 мегабайт. Когда из периферийной базы запускается процедура выгрузки данных, то на этап "Чтение правил конвертации" тратится порядка 5 минут. По условиям задачи обмен должен выполнятся каждые 5 минут, а не чтение правил! Значит придется решить эту проблему. Сначала проанализируем как сейчас выполняется чтение правил обмена.
В конфигурации есть обработка "ОбменДаннымиXML" которая выполняет все основные функции по выгрузке, загрузке, чтению правил обмена и т.д. В модуле объекта обработки за чтение правил обмена отвечает процедура "ЗагрузитьПравилаОбмена":
// Осуществляет загрузку правил обмена в соответствии с форматом
//
// Параметры:
// Источник - Объект, из которого осуществляется загрузка правил обмена;
// ТипИсточника - Строка, указывающая тип источника: "XMLФайл", "ЧтениеXML", "Строка"
//
Процедура ЗагрузитьПравилаОбмена(Источник="", ТипИсточника="XMLФайл", СтрокаСообщенияОбОшибке = "",
ЗагружатьТолькоЗаголовокПравил = Ложь) Экспорт
#Если Клиент Тогда
Состояние("Выполняется загрузка правил обмена ...");
#КонецЕсли
// ...
КонецПроцедуры
В этой процедуре читается XML-файл правил и заполняются служебные переменные, такие как:
- реквизит обработки "ТаблицаПравилКонвертации", в которой сохраняются все правила конвертации для дальнейшего использования. Большая часть времени при чтении правил затрачивается именно на заполнение этой таблицы.
- глобальная переменная "Конвертация", в которой сохраняется структура свойств конвертации (имя, ID, обработчики событий и др.)
- глобальная переменные "Менеджеры" и "МенеджерыДляПлановОбмена", которые хранят соответствие, содержащее поля Имя, ИмяТипа, ТипСсылкиСтрокой, Менеджер, ОбъектМД, ПКО.
- переменная обработки "Правила", в которой сохраняются ссылки на ПКО.
- и много другое.
Эти и другие свойства заполняются каждый раз при чтении правил обмена из XML-файла. В цикле выполняется обход всех узлов XML-файла.
Пока ПравилаОбмена.Прочитать() Цикл
ИмяУзла = ПравилаОбмена.ЛокальноеИмя;
// Реквизиты конвертации
Если ИмяУзла = "ВерсияФормата" Тогда
// ...
// События конвертации
ИначеЕсли ИмяУзла = "" Тогда
ИначеЕсли ИмяУзла = "ПослеЗагрузкиПравилОбмена" Тогда
// ..
// Правила
ИначеЕсли ИмяУзла = "ПравилаВыгрузкиДанных" Тогда
// ...
// Алгоритмы / Запросы / Обработки
ИначеЕсли ИмяУзла = "Алгоритмы" Тогда
// ...
// Выход
ИначеЕсли (ИмяУзла = "ПравилаОбмена")
И (ПравилаОбмена.ТипУзла = одТипУзлаXML_КонецЭлемента) Тогда
// ...
КонецЦикла;
Для более подробной информации Вы можете посмотреть содержимое модуля обработки "ОбменДаннымиXML" в составе конфигурации.
И так, при каждом запуске обмена выполняются одни и те же действия по чтению правил и инициализации служебных переменных обработки. Что-то тут не так, не правда ли? Зачем выполнять это действие каждый раз, ведь правила конвертации остаются прежними? Нет, в теории, конечно, правила можно менять каждые 5 минут, то мы такую ситуацию не будем рассматривать =).
И так, вот то самое место, которое требует оптимизации!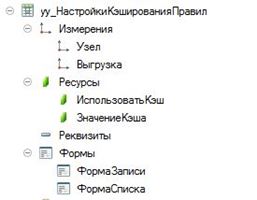
Решение
Решение не простое, а очень простое! Мы сохраним КЭШ инициализированных переменных обработки при первом чтении правил конвертации! При последующих чтениях нужно будет лишь восстановить их сохраненных в КЭШе значений настройки обработки, тем самым сэкономив значительную часть времени на этапе чтения правил конвертации.
Для этого добавим в конфигурацию следующие метаданные регистр сведений, в котором настраивается использования КЭШа правил конвертации и хранится непосредственно само его значение.
Таблица регистр содержит:
- Узел — ссылка на любой узел планов обмена
- Выгрузка — булев флаг, с помощью которого можно настраивать, когда использовать КЭШ — для выгрузки или для загрузки сообщений
- ИспользоватьКэш — булев флаг, с помощью которого можно в любой момент включить или отключить кэширование правил конвертации для выбранного узла
- ЗначениеКэша — ресурс с типом "ХранилищеЗначений", в котором непосредственно сохраняются инициализированные настройки правил конвертации.
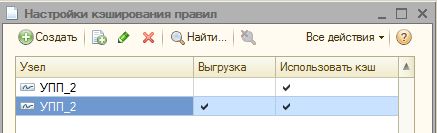
В режиме предприятия нужно выполнить первоначальную настройку в регистре, например, как на следующем скриншоте.
В модуле менеджера регистра необходимо добавить следующие процедуры и функции:
Сохранение в кэш
Получение из кэша
Структура сохраняемых настроек
Из списка полей для сохранения в кэш были исключены:
- Менеджеры
- МенеджерыДляПлановОбмена
- ПостроительОтчета
- мЗапросСтрокРегистраСоответствияОбъектов
- мЗапросСтрокРегистраОпределенияНаличияВыгрузки
- мЗапросНаличияСтрокВРегистреСоответствия
- мЗапросНаличияПустыхДляИсточникаВРегистреСоответствия
- мЗапросИнформацииОМестеСозданияОбъекта
Причина — в этих переменных хранятся значения, которые не поддерживают сериализацию. То есть мы их просто не можем никуда сохранить. Их придется инициализировать самостоятельно.
Далее нужно внести изменения в модуль объекта обработки "ОбменДаннымиXML" и в общий модуль "ПроцедурыОбменаДанными". Чтобы не усложнять пример, мы будем сохранять КЭШ правил только с флагом "Выгрузка". Перейдем в модуль обработки "ОбменДаннымиXML" и добавим следующее:
Процедура ЗагрузитьПравилаОбменаИзКэша(ЗначениеКэша) Экспорт
#Если Клиент Тогда
Состояние("Выполняется загрузка правил обмена ...");
#КонецЕсли
// Инициализируем менеджеры и начальные значения некоторых переменных
ИнициализироватьМенеджерыИСообщения();
ЕстьГлобальныйОбработчикПередВыгрузкойОбъекта = Ложь;
ЕстьГлобальныйОбработчикПослеВыгрузкиОбъекта = Ложь;
ЕстьГлобальныйОбработчикПередКонвертациейОбъекта = Ложь;
ЕстьГлобальныйОбработчикПередЗагрузкойОбъекта = Ложь;
ЕстьГлобальныйОбработчикПослеЗагрузкиОбъекта = Ложь;
// Заполняем текущие значения полей обработки из КЭШа
Для Каждого Стр Из ЗначениеКэша Цикл
ЗначениеИзКэша = Стр.Значение;
Выполнить(Строка(Стр.Ключ)+"=ЗначениеИзКэша;");
КонецЦикла;
// После извлечения таблицы правил конвертации в ней были потеряны ссылки
// на соответствующие строки из таблицы "ТаблицаПравилКонвертации", т.к.
// эти значения не сериализуются. Восстановим ссылки на строки таблицы
Для Каждого Стр Из Правила Цикл
НайденнаяСтрокаПравил = ЭтотОбъект.ТаблицаПравилКонвертации.НайтиСтроки(Новый Структура("Имя", Стр.Ключ));
Если НайденнаяСтрокаПравил.Количество() > 0 Тогда
ЭтотОбъект.Правила[Стр.Ключ] = НайденнаяСтрокаПравил.Получить(0);
КонецЕсли;
КонецЦикла;
// Аналогично таблице правил конвертации в таблице "Менеджеры" нужно восстановить
// ссылки на строки таблицы "ТаблицаПравилКонвертации"
Для Каждого Стр Из Менеджеры Цикл
НайденнаяСтрокаПравил = ЭтотОбъект.ТаблицаПравилКонвертации.НайтиСтроки(Новый Структура("Источник", Стр.Ключ));
Если НайденнаяСтрокаПравил.Количество() > 0 Тогда
Стр.Значение.ПКО = НайденнаяСтрокаПравил.Получить(0);
КонецЕсли;
КонецЦикла;
// Вызываем событие после загрузки правил обмена
ТекстСобытияПослеЗагрузкиПравилОбмена = "";
Если Конвертация.Свойство("ПослеЗагрузкиПравилОбмена", ТекстСобытияПослеЗагрузкиПравилОбмена)
И Не ПустаяСтрока(ТекстСобытияПослеЗагрузкиПравилОбмена) Тогда
Попытка
Выполнить(ТекстСобытияПослеЗагрузкиПравилОбмена);
Исключение
СтрокаСообщенияОбОшибке = ЗаписатьИнформациюОбОшибкеОбработчикиКонвертации(75, ОписаниеОшибки(), "ПослеЗагрузкиПравилОбмена (конвертация)");
Отказ = Истина;
Если Не ФлагРежимОтладки Тогда
ВызватьИсключение СтрокаСообщенияОбОшибке;
КонецЕсли;
КонецПопытки;
КонецЕсли;
// Инициализируем начальные значения параметров
ИнициализироватьПервоначальныеЗначенияПараметров();
КонецПроцедуры
Думаю, что о назначении процедуры ясно из ее названия, но обратите внимание на фрагмент до заполнение таблиц "Правила" и "Менеджеры". Если запускать стандартную процедуру чтения правил обмена, в эти таблицы будут содержать ссылки на строки другой таблицы "ТаблицаПравилКонвертации". После восстановления этих таблиц из КЭШа ссылки конечно же теряются, т.к. не поддаются сериализации. Выход из ситуации простой — нужно дозаполнить восстановленные таблицы заново, что мы и сделали.
Получение правил обмена для кэширования
В функции "ПолучитьПравилаОбменаДляСохраненияВКэш" мы инициализируем пустую структуру, а потом заполняем ее текущими значениями из обработки. Извините за большой листинг, но все же реализация заполнения важная часть и не хотелось бы ее выпускать из виду.
В принципе у нас уже все готово для работы с КЭШем правил конвертации. Осталось лишь его задействовать при запуске обмена. Для этого в общем модуле "ПроцедурыОбменаДанными"добавим в процедуру "УстановитьПараметрыДляВыгрузкиДанныхXML" следующий код:
Использование кэша правил обмена
Посмотрим результат
Итак, настройки в регистре "Настройки кэширования правил" сделаны, все необходимые изменения внесены в конфигурацию, а значит время тестирования! Выполним первый запуск выгрузки данных, а затем запустим его еще раз, но с уже сохраненным КЭШем правил конвертации. Замеры времени покажут, чего мы добились.
До оптимизации замер времени выполнения чтения правил конвертации из XML-файла следующий:
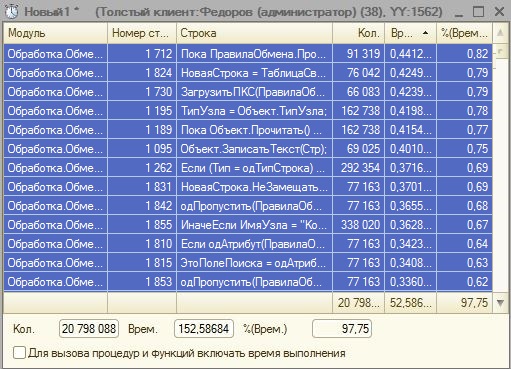 Итого на чтение правил было затрачено 152,6 секунды (~2,5 минуты). А теперь посмотрим сколько времени займет эта же операция при использовании КЭШа правил конвертации:
Итого на чтение правил было затрачено 152,6 секунды (~2,5 минуты). А теперь посмотрим сколько времени займет эта же операция при использовании КЭШа правил конвертации:
 Всего 8 секунд! Похоже я Вас обманул, когда написал в заголовке статьи, что оптимизация даст эффект ускорения чтения правил конвертации в 20 раз, ведь ускорили мы его всего лишь в 19 раз! =)
Всего 8 секунд! Похоже я Вас обманул, когда написал в заголовке статьи, что оптимизация даст эффект ускорения чтения правил конвертации в 20 раз, ведь ускорили мы его всего лишь в 19 раз! =)
В продолжение
Итак, оптимизация проведена успешно! Мы добились значительного ускорения чтения правил конверта ции. Такой подход использовался мной при решении реальных задач. Если развивать тему, то дальше можно сделать автоматическую очистку КЭШа при загрузке новой версии правил конвертации, добавить новый вид транспорта сообщений в УПП 1.3 через веб-сервисы, уменьшить периодичность обмена, сделать отложенную загрузку и выгрузку сообщений обмена по очереди поступления, реализовать поддержку пакетного обмена данными, минимизировать влияние блокировок при обмене, но…меня понесло! Все это уже совсем другая история!
ции. Такой подход использовался мной при решении реальных задач. Если развивать тему, то дальше можно сделать автоматическую очистку КЭШа при загрузке новой версии правил конвертации, добавить новый вид транспорта сообщений в УПП 1.3 через веб-сервисы, уменьшить периодичность обмена, сделать отложенную загрузку и выгрузку сообщений обмена по очереди поступления, реализовать поддержку пакетного обмена данными, минимизировать влияние блокировок при обмене, но…меня понесло! Все это уже совсем другая история!
Напоследок скажу, что данный подход к оптимизации чтения правил конвертации подходит не только для устаревших механизмов обмена, которые присутствуют в УПП 1.3, УТ 10.3 и др. старых версиях конфигураций, но и для новый конфигураций как ERP 2.0, УТ 11.1, БП 3.0 и др. Конечно нужно вносить изменения иначе, но принцип тот же. И даже наличие модулей БСП ничего не поменяет.
Спасибо за внимание!
Другие ссылки
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
А теперь для тех, кого заинтересовала тема заголовка, но разочарован статьей.
1. Применяя описанную методику не забудьте о необходимости проверять факт изменений в правилах обмена прежде чем использовать данные из кэша
2. Данное решение никоим образом не ускоряет чтение правил обмена не находящихся в кэше, хотя это и возможно. При чтении правил обмена выполняется обработка одноуровневого массива несвязанных данных, вследствие чего задача хорошо распараллеливается по одному из двух вариантов:
— В первом случае алгоритм основан на разделении массива правил обмена на чет/нечет, либо первый/второй/третий/четвертый, либо октетная обработка и тому подобное масштабирование. Для каждого фонового задания выгружается собственная копия правил с использованием штатной Универсальной обработки с небольшими модификациями на обработку только правил с указанным совпадением номера с остатком от деления на 2, 4, 8 и т.п., а для несовпадающих номеров использовать крайне быстрый метод обработки XMLЧтение.Пропустить(), после отработки фоновых заданий потребуется выполнить сборку результатов.
— Во втором случае потребуется использовать недавно добавленные в платформу объекты поточной обработки двоичных данных, и за счет применения парного чтения двух копий XML с правилами обмена на открывающий и закрывающий XML-маркер (методом ПропуститьДо(), выполнить нарезку исходного XML файла на объекты на заданной глубине вложенности XML, после чего передать куски XML на десериализацию фоновым заданиям, что увеличивает задачу на 1 месяц разработки, но даёт 15% выигрыш в задержке диспетчера десериализации, а ещё позволяет аналогичным образом в несколько потоков перейти к решению задачи ускорения загрузки файлов обмена, а не только правил.
(1) Вы пошли еще дальше, отлично!
Жаль, что разочаровал. Посыл был в простой демонстрации решения. А то и правда на целый месяц разработка увеличится 🙂
(2) Нет, я не разочарован. Я отлично понимаю, что такое диалог с бизнесом, и что такое business value
(0) решение интересное!
(1) я вас не понял:
1. правила не меняются или так лучше скажу — меняются, но редко — и за этими изменениями следит разработчик — то есть сам автор.
2. данное решение не должно ускорять правила, которые не «в кэше».
вообще тема простая — зная бизнес-логику программы, легко делать оптимизацию. я приведу свой реальный пример для простоты понимания сути: вот есть типовое решение в типовых конфигурациях — использовать во всех документах константу ВалютаРегламентированногоУчета — обращение к ней происходит почти в каждом документе при любой операции — распечатать что-то, провести документ, при изменении данных формы. Тут же происходит пересчет валюты через курс валюты. Но если , к примеру, вы знаете что фирма работает только с Руб. и курс постоянен =1, то можно во всех где хотите местах прописать
это условиеоптимизацию — к примеру убрать проверку на валюту при проведении документа, в запросах упростить сам запрос — убрать пересчет курса.То есть, еще раз, зная бизнес-процесс фирмы и бизнес-логику программы, можно точечно оптимизировать. В этом и заключается одна из сторон автоматизации бизнес-процессов клиентов.
Примерно так я убираю (закомменчиваю) в конфигураторе механизмы ЕГАИС и ЭДО во всех местах программы, если знаю что магазин не торгует алкоголькой, это ведь строительный магазин, магазин не использует ЭДО — электронный документооборот…. И так далее и тому подобное — выигрыш в том, что программа начинает быстрее работать даже без замеров производительности.
Огромное спасибо, очень помогли.
(4) если вопросы ко мне, то:
1. Правила могут меняться скол ко угодно раз. При изменении правил кэш очищается. При первом обмене кэш формируется, если его не было. Разработчику можно не следить за этим.
2. Да, если в кэше правил не было, то первый запуск будет без оптимизации.
(6) нет вопросов, все понятно
Очень уважаю автора, но статья странная. Больше подходит новичку, нежели опытному автоматизатору, честно говоря.
Если уж обмен используется часто, а правила меняются редко и разрешено менять конфигурацию, почему вообще не решить проблему кардинально?
Сделать из обработки документ, все методы обмена перенести в него, все реквизиты обработки — в реквизиты документа. Все что можно сериализовать — все в реквизиты с типом Строка или ХранилищеЗначения, все что нельзя сериализовать — написать обработчики заполнения при инициализации объекта документа. Поменялись правила — открыли документ интерактивно, перезаписали их.
Короче, посыл не очень ясен. Думаю, каждый 3-й наш коллега таких «ускорений» делает пяток штук в месяц.
Может не стоит все подряд из старого блога сюда «переносить»? Исключительно ИМХО.
(8) спаибо за отзыв!
Хорошо, что каждый 3-й делает подобные оптимизации в среднем 5 раз в месяц. Автоматизация и компетенции растут!
У вас слишком много «если». А вариант с документом создаст сложности для поддержки типовых конфигураций. Радикальным методом для оптимизации я бы лучше назвал — отказ от типовых механизмов обмена. Да и никто не говорил, что правила меняются редко.
Ваше мнение услышано!
(4)
То есть, еще раз, зная бизнес-процесс фирмы и бизнес-логику программы, можно точечно оптимизировать. В этом и заключается одна из сторон автоматизации бизнес-процессов клиентов.
Примерно так я убираю (закомменчиваю) в конфигураторе механизмы ЕГАИС и ЭДО во всех местах программы, если знаю что магазин не торгует алкоголькой, это ведь строительный магазин, магазин не использует ЭДО — электронный документооборот…. И так далее и тому подобное — выигрыш в том, что программа начинает быстрее работать даже без замеров производительности.
Сомнительная оптимизация.
(10) в чем сомнения, дорогой друг?
(6) Было бы логичнее хэш высчитать массива и хранить кэш в привязке к хэшу, вроде операция не дорогостоящая, но логически корректная. На картинке вижу 52 и 8, а не 152 и 8 ) точно 152 ?
(12)
Хеш хранить для сравнения актуальны ли данные в кэше? Так и делалось.
Про картинку затрудняюсь ответить, почему общий замер 152, а в подвале таблицы только 52 видно. Все таки 6 лет прошло с тех пор 🙂
(11) обращение к константе — тут бессмысленно что-либо делать, даже модуль повторного использования значений не рекомендуется (на итс где-то видел), пересчета как такого нет, ведь идёт сравнение валют, коль обе рубли то и пересчета нет.
егаис и эдо небось от значений функциональных опций зависит, зачем комментировать, если оно итак не работает и соответственно оптимизировать нечего.
(14)егаис и эдо в УТ 10.3,в котором нет функц. опций. Я привёл пример общего принципа. Если и спорить, то не с конкретным примером, а с принципом оптимизации кода (РЕФАКТОРИНГ). Ну а про константу принцип простой — для моей организации эта константа в принципе не нужна, и поэтому все вызовы и пересчёт курса тоже не нужны. Берите шире, смотрите глубже — кроме этой константы много чего ещё можно отключить в конфигурации: нет учёта серий — убираем серии и т.д.
(4) У меня были ситуации когда в один поток обмен не успевал загружать суточный объем данных. Тогда приходит на помощь параллельная разборка xml с данными