/****** Object: StoredProcedure [dbo].[sp_store_top_cpu_usage_data] Script Date: 20.04.2026 18:09:40 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: Dolinin, Permenergosbyt
-- Create date: 05.04.19
-- Description: This proc collect info about top CPU usages
-- =============================================
CREATE PROCEDURE [dbo].[sp_store_top_cpu_usage_data]
AS
BEGIN
SET NOCOUNT ON;
declare @depth datetime = '01:00:00.000'
declare @period datetime = getdate()
declare @count_of_result int = 100
declare @count_of_primary_data int = 10000
SELECT
*
into #T0 FROM (
select top (@count_of_primary_data)
*
from
sys.dm_exec_query_stats qs
where qs.last_execution_time > (CURRENT_TIMESTAMP - @depth)
order by qs.last_execution_time desc
) as qs
;
SELECT
SUM(qs.max_elapsed_time) as elapsed_time,
SUM(qs.total_worker_time) as worker_time
into #T1 FROM #T0 qs
select
(qs.max_elapsed_time) as elapsed_time,
(qs.total_worker_time) as worker_time,
qp.query_plan,
st.text,
dtb.name,
qs.*,
st.dbid
INTO #T2
FROM
#T0 qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
left outer join sys.databases as dtb on st.dbid = dtb.database_id
order by qs.last_execution_time desc
;
declare
@rec_num int,
@percent_elapsed_time decimal(5, 1),
@percent_worker_time decimal(5, 1),
@elapsed_time bigint,
@worker_time bigint,
@query_plan xml,
@text nvarchar(max),
@sql_handle varbinary(64),
@statement_start_offset int,
@statement_end_offset int,
@plan_generation_num bigint,
@plan_handle varbinary(64),
@creation_time datetime,
@last_execution_time datetime,
@execution_count bigint,
@total_worker_time bigint,
@last_worker_time bigint,
@min_worker_time bigint,
@max_worker_time bigint,
@total_physical_reads bigint,
@last_physical_reads bigint,
@min_physical_reads bigint,
@max_physical_reads bigint,
@total_logical_writes bigint,
@last_logical_writes bigint,
@min_logical_writes bigint,
@max_logical_writes bigint,
@total_logical_reads bigint,
@last_logical_reads bigint,
@min_logical_reads bigint,
@max_logical_reads bigint,
@total_clr_time bigint,
@last_clr_time bigint,
@min_clr_time bigint,
@max_clr_time bigint,
@total_elapsed_time bigint,
@last_elapsed_time bigint,
@min_elapsed_time bigint,
@max_elapsed_time bigint,
@query_hash binary(8),
@query_plan_hash binary(8),
@total_rows bigint,
@last_rows bigint,
@min_rows bigint,
@max_rows bigint,
@dbid int
declare cur cursor FORWARD_ONLY for
select top (@count_of_result)
try_cast(T2.elapsed_time*100/T1.elapsed_time as decimal(5, 1)) as percent_elapsed_time,
try_cast(T2.worker_time*100/T1.worker_time as decimal(5, 1)) as percent_worker_time,
T2.elapsed_time,
T2.worker_time,
T2.query_plan,
T2.text,
T2.sql_handle,
T2.statement_start_offset,
T2.statement_end_offset,
T2.plan_generation_num,
T2.plan_handle,
T2.creation_time,
T2.last_execution_time,
T2.execution_count,
T2.total_worker_time,
T2.last_worker_time,
T2.min_worker_time,
T2.max_worker_time,
T2.total_physical_reads,
T2.last_physical_reads,
T2.min_physical_reads,
T2.max_physical_reads,
T2.total_logical_writes,
T2.last_logical_writes,
T2.min_logical_writes,
T2.max_logical_writes,
T2.total_logical_reads,
T2.last_logical_reads,
T2.min_logical_reads,
T2.max_logical_reads,
T2.total_clr_time,
T2.last_clr_time,
T2.min_clr_time,
T2.max_clr_time,
T2.total_elapsed_time,
T2.last_elapsed_time,
T2.min_elapsed_time,
T2.max_elapsed_time,
T2.query_hash,
T2.query_plan_hash,
T2.total_rows,
T2.last_rows,
T2.min_rows,
T2.max_rows,
T2.dbid
from
#T2 as T2
INNER JOIN #T1 as T1
ON 1=1
order by T2.worker_time desc
open cur
fetch next from cur into
@percent_elapsed_time,
@percent_worker_time,
@elapsed_time,
@worker_time,
@query_plan,
@text,
@sql_handle,
@statement_start_offset,
@statement_end_offset,
@plan_generation_num,
@plan_handle,
@creation_time,
@last_execution_time,
@execution_count,
@total_worker_time,
@last_worker_time,
@min_worker_time,
@max_worker_time,
@total_physical_reads,
@last_physical_reads,
@min_physical_reads,
@max_physical_reads,
@total_logical_writes,
@last_logical_writes,
@min_logical_writes,
@max_logical_writes,
@total_logical_reads,
@last_logical_reads,
@min_logical_reads,
@max_logical_reads,
@total_clr_time,
@last_clr_time,
@min_clr_time,
@max_clr_time,
@total_elapsed_time,
@last_elapsed_time,
@min_elapsed_time,
@max_elapsed_time,
@query_hash,
@query_plan_hash,
@total_rows,
@last_rows,
@min_rows,
@max_rows,
@dbid
set @rec_num=1
WHILE @@FETCH_STATUS = 0
BEGIN
insert into prom_monitoring..top_cpu_usage(
period, rec_num,
percent_elapsed_time,
percent_worker_time,
elapsed_time,
worker_time,
query_plan,
text,
sql_handle,
statement_start_offset,
statement_end_offset,
plan_generation_num,
plan_handle,
creation_time,
last_execution_time,
execution_count,
total_worker_time,
last_worker_time,
min_worker_time,
max_worker_time,
total_physical_reads,
last_physical_reads,
min_physical_reads,
max_physical_reads,
total_logical_writes,
last_logical_writes,
min_logical_writes,
max_logical_writes,
total_logical_reads,
last_logical_reads,
min_logical_reads,
max_logical_reads,
total_clr_time,
last_clr_time,
min_clr_time,
max_clr_time,
total_elapsed_time,
last_elapsed_time,
min_elapsed_time,
max_elapsed_time,
query_hash,
query_plan_hash,
total_rows,
last_rows,
min_rows,
max_rows,
dbid
)
values(
@period, @rec_num,
@percent_elapsed_time,
@percent_worker_time,
@elapsed_time,
@worker_time,
@query_plan,
@text,
@sql_handle,
@statement_start_offset,
@statement_end_offset,
@plan_generation_num,
@plan_handle,
@creation_time,
@last_execution_time,
@execution_count,
@total_worker_time,
@last_worker_time,
@min_worker_time,
@max_worker_time,
@total_physical_reads,
@last_physical_reads,
@min_physical_reads,
@max_physical_reads,
@total_logical_writes,
@last_logical_writes,
@min_logical_writes,
@max_logical_writes,
@total_logical_reads,
@last_logical_reads,
@min_logical_reads,
@max_logical_reads,
@total_clr_time,
@last_clr_time,
@min_clr_time,
@max_clr_time,
@total_elapsed_time,
@last_elapsed_time,
@min_elapsed_time,
@max_elapsed_time,
@query_hash,
@query_plan_hash,
@total_rows,
@last_rows,
@min_rows,
@max_rows,
@dbid
)
set @rec_num=@rec_num + 1
fetch next from cur into
@percent_elapsed_time,
@percent_worker_time,
@elapsed_time,
@worker_time,
@query_plan,
@text,
@sql_handle,
@statement_start_offset,
@statement_end_offset,
@plan_generation_num,
@plan_handle,
@creation_time,
@last_execution_time,
@execution_count,
@total_worker_time,
@last_worker_time,
@min_worker_time,
@max_worker_time,
@total_physical_reads,
@last_physical_reads,
@min_physical_reads,
@max_physical_reads,
@total_logical_writes,
@last_logical_writes,
@min_logical_writes,
@max_logical_writes,
@total_logical_reads,
@last_logical_reads,
@min_logical_reads,
@max_logical_reads,
@total_clr_time,
@last_clr_time,
@min_clr_time,
@max_clr_time,
@total_elapsed_time,
@last_elapsed_time,
@min_elapsed_time,
@max_elapsed_time,
@query_hash,
@query_plan_hash,
@total_rows,
@last_rows,
@min_rows,
@max_rows,
@dbid
END
CLOSE cur;
DEALLOCATE cur;
drop table #T2
;
drop table #T1
;
drop table #T0
;
END
GO
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями) Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Статья открылась с предложения от которого немного повеселело
А так конечно задумка хорошая
Интересно еще как по вашему — какую часть проблем 1С снимает исправление тяжелых запросов, тем более не факт что они неправильные ?
(1) Честно, не понял, от чего повеселело)
По поводу «какую часть проблем…» — свежие выводы.
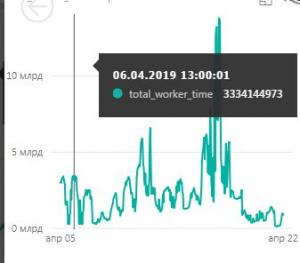
Например, увидели, что большая часть нагрузки приходится за запись (insert) ТЧ определенного вида док-тов. Думаем вот, что нужно поменять архитектуру и отказаться от ТЧ в пользу РС.
Еще увидели, насколько много у нас разыменований определенных справочников. Нашли крупный источник, пофиксили, оценили эффект и решили пока остановиться на этом.
Добавили пару-тройку явно необходимых индексов.
(2)От великая и могучая русская языка )
Какую версию SQL Server используете?
В 2016 и последующих версиях появился Query Store — по-русски вроде называется Диспетчер Хранилица Запросов.
Собирает самую базовую информацию по запросам, которые потребляют много ресурсов, вместе с их планами и аггрегированной основной статистикой.
Не заменит полноценную систему мониторинга типа RedGate, но зато бесплатно и чрезвычайно удобно.
Тут не нашел публикации, поэтому наверное надо написать простую статью :).
(4) Пользуем 2012. Но судя по перечисленному — в служебной вьюхе все это тоже есть. И планы, и аггр статистика.
(5) Добавил описание Query Store здесь —
я так понимаю это все только для MS? Postgre в пролете?
(7) Для PG вроде есть свои источники подобных статистик. Сходу нашел что-то про pg_stat_activity. Ну понятно, что один в один не применить.