
В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.

Медленный запрос
План выполнения PostgreSQL для этого запроса был для нас неожиданным. Несмотря на то, что в обеих таблицах есть индексы, PostgreSQL решил выполнить Hash Join с последовательным сканированием большой таблицы. Последовательное сканирование большой таблицы занимало большую часть времени запроса.

План выполнения медленого запроса
Я изначально подозревал, что это может быть из-за фрагментации. Но после проверки данных я понял, что в эту таблицу данные только добавляются и практически не удаляются оттуда. Так как очистка места с помощью VACUUM здесь не очень поможет, я начал копать дальше. Затем я попробовал этот же запрос на другом клиенте с хорошим временем ответа. К моему удивлению, план выполнения запроса выглядел совершенно иначе!

План выполнения того же запроса на другом клиенте
Интересно, что приложение A получило доступ только к 10 раз большему количеству данных, чем приложение B, но время отклика было в 3000 раз больше.
Чтобы увидеть альтернативные планы запросов PostgreSQL, я отключил хеш-соединение и перезапустил запрос.

Альтернативный план выполнения для медленного запроса
Ну вот! Тот же запрос завершается в 50 раз быстрее при использовании вложенного цикла вместо хэш-соединения. Итак, почему PostgreSQL выбрал худший план для приложения A?
При более тщательном рассмотрении предполагаемой стоимости и фактического времени выполнения для обоих планов предполагаемые соотношения стоимости и фактического времени выполнения были очень разными. Основным виновником этого несоответствия была оценка стоимости последовательного сканирования. PostgreSQL подсчитал, что последовательное сканирование было бы лучше, чем 4000+ сканирований индекса, но в действительности сканирование индекса было в 50 раз быстрее.
Это привело меня к параметрам конфигурации random_page_cost и seq_page_cost. Значения PostgreSQL по умолчанию 4 и 1 для random_page_cost, seq_page_cost, которые настроены для HDD, где произвольный доступ к диску дороже, чем последовательный доступ. Однако эти затраты были неточными для нашего развертывания с использованием тома gp2 EBS, которые являются твердотельными накопителями. Для нашего развертывания случайный и последовательный доступ практически одинаков.
Я изменил значение random_page_cost на 1 и повторил запрос. На этот раз PostgreSQL использовал Nested Loop, и запрос выполнялся в 50 раз быстрее. После изменения мы также заметили значительное снижение максимального времени отклика от PostgreSQL.
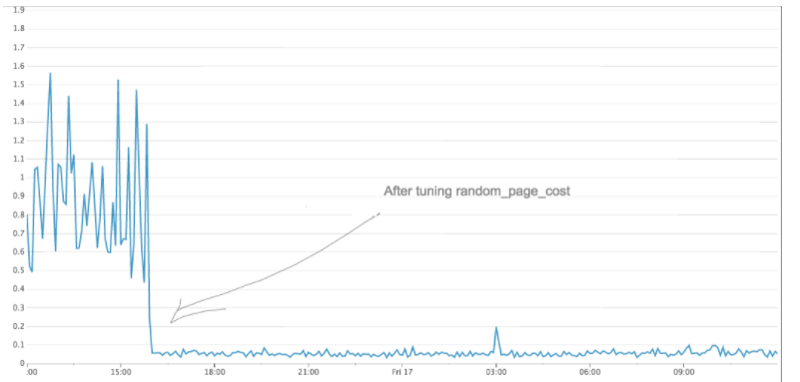
Общая производительность медленного запроса значительно улучшилась
Если вы используете SSD и используете PostgreSQL с конфигурацией по умолчанию, я советую вам попробовать настроить random_page_cost и seq_page_cost. Вы можете быть удивлены сильным улучшением производительности.
От себя добавлю, что я выставил минимальные параметры seq_page_cost = random_page_cost = 0.1, чтобы отдать приоритет данным в памяти (кэш) над процессорными операциями, так как у меня выделено большое количество ОЗУ для PostgreSQL (размер ОЗУ превышает размер базы на диске)
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Респект и звезда! Утащу к себе.
Для повышения рейтинга можно копировать статьи Хабр?
))
Ну то есть Pavan Patibandla получал планы запросов и курил мануалы )
Это не оно случайно ?
(2) статья не моя, а перевод мой — с копирайтами все впорядке, не переживайте
(3) то, что описывают 1С — частные случаи, не всегда приводящие к выигрышу в производительности. Например, рекомендуют отключать Nested Loops. А что получается, когда поиск значений для соединения таблиц идёт с помощью их хэшей (Hash Join) — видно в статье — замедление работы почти в 50 раз по сравнению с поиском с помощью вложенных циклов (Nested Loops). Есть очень хорошая статья на хабре по базам данных доходчиво и очень понятно написано
(5) Ну вообще как бы да, эти настройки описаны в мануалах
Стоимость чтения рандомной страницы, на которую будет опираться оптимизатор (по-умолчанию 4). Практическое значение параметра должно зависеть от «seek time» дисковой системы: чем он меньше, тем меньше должно быть значение random_page_cost (но не менее 1.0) . Излишне большое значение параметра увеличивает склонность PostgreSQL к выбору планов с сканированием всей таблицы (PostgreSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). Оценка стоимости последовательного чтения делается, в свою очередь, с учетом параметра seq_page_cost, который равен по умолчанию 1.
Если вы считаете, что для вашей рабочей нагрузки процент попаданий не достигает 90%, вы можете увеличить параметр random_page_cost, чтобы он больше соответствовал реальной стоимости произвольного чтения. И напротив, если ваши данные могут полностью поместиться в кеше, например, когда размер базы меньше общего объёма памяти сервера, может иметь смысл уменьшить random_page_cost. С хранилищем, у которого стоимость произвольного чтения не намного выше последовательного, как например, у твердотельных накопителей, так же лучше выбрать меньшее значение random_page_cost.
Я понимаю, что название публикации также является переводом заголовка оригинала статьи, но некоторая броскость фразы «улучшило производительность медленных запросов в 50 раз» может дать и обратный эффект.
Народ, особенно, недавно приобщающийся к миру PostgreSQL(тоже пафос…), начнет выключать hash join для любых конфигураций — типовых. нетиповых, «в хлам переписанных», оригинальных самописных. Через некоторое время будет получать просадку производительности(зависания) в тех местах, где этого в принципе не должно было бы быть. Особенно может быть весело, если все типы конфигураций присутствуют одновременно. После чего будут раздаваться обиженно-гневные возгласы — «»Ваш этот Постгрес…» и далее все многообразие «непереводимых идиоматических выражений». «Да лучше бы мы MS SQL купили!»
Я это к тому, что результат изысканий автора статьи надо рассматривать с той точки зрения. что в ряде частных случаев изменение тех или иных параметров(или их совокупности), влияющих на оптимизацию работы СУБД может оказаться приемлемым. Для конкретной базы данных и конкретного запроса к ней. Как и в случае с 1С.
(6) это все понятно. Просто вы знали, что именно изменение этих параметров может настолько увеличить производительность PG? Я вот лично не знал
(8) Там изменение любого параметра может влиять на производительность в самых неожиданных местах, причем как ускорять отдельные запросы, так и замедлять другие. Настройка в соответствии с документацией решает половину проблем
(9)
Меня это как-то немного смущает. А вас?
(10) Нюансы тонкой настройки, есть в этом плюсы, что можно настроить как душе угодно, и минусы, что теряется простота и универсальность. Как по мне, оптимизатор запросов в MS SQL «умнее», но из-за этого им сложнее управлять. Но нельзя говорить что в PG он плохой, просто рассчитан на специалиста.
(11) тут даже сравнивать не стоит. MS, IBM и Oracle — это автоматическая коробка передач, а PG — механика. PG не плохой, просто мне лично из документации не сильно понятна степень влияния каждого параметра на производительность системы в целом. По хорошему за такое должна отвечать автоматика, но трудно требовать такого от свободного ПО, которое пишет некое сообщество
(12)
Вы просто не представляете сколько есть аналогичных настроек у MS. С аналогичным эффектом
seq_page_cost = random_page_cost = 0.1
Так делать нельзя ни в коем случае.
seq_page_cost = 1 не просто так, а потому что является ориентиром всех остальных коэффициентов.
(14) 1C сами рекомендуют понизить seq_page_cost до 0.1 и random_page_cost до 0.4
А вы говорите так делать нельзя ни в коем случае. Каковы основания доверять вашим словам?
У меня снижение параметра seq_page_cost = 0.1
привело к существенному повышению общей производительности. Правда
random_page_cost я ставил 0.4, сохраняя отношение одного к другому. Размер базы уже больше ОЗУ, но производительность не падает.
И спасибо за перевод)
(15)Прочитайте документацию разработчика БД по этому параметру.
Переменные стоимости, описанные в данном разделе, задаются по произвольной шкале. Значение имеют только их отношения, поэтому умножение или деление всех переменных на один коэффициент никак не повлияет на выбор планировщика. По умолчанию эти переменные определяются относительно стоимости чтения последовательной страницы: то есть, переменную seq_page_cost удобно задать равной 1.0, а все другие переменные стоимости определить относительно неё. Но при желании можно использовать и другую шкалу, например, выразить в миллисекундах фактическое время выполнения запросов на конкретной машине.
Т.е. если вы изменили seq_page_cost, то должны пересмотреть все параметры планировщика опираясь на новый показатель.
Почти наверняка было бы достаточно выставить random_page_cost в 1 или 1,1 и получите то же самое, только не нарушая общую работу планировщика во всех других запросах.
Другое дело, если база полностью кэшируется в ОЗУ, вот тогда оба этих показателя можно снизить, так как стоимость выборки страницы, уже находящейся в ОЗУ, оказывается намного меньше, чем обычно.
Общий посыл такой — нет волшебной пули, есть комплекс настроек которые нужно применять в комплексе
Если посмотреть рекомендации 1С поновее чем 2012 год, то:
Стоимость чтения рандомной страницы, на которую будет опираться оптимизатор (по-умолчанию 4). Практическое значение параметра должно зависеть от «seek time» дисковой системы: чем он меньше, тем меньше должно быть значение random_page_cost (но не менее 1.0) . Излишне большое значение параметра увеличивает склонность PostgreSQL к выбору планов с сканированием всей таблицы (PostgreSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). Оценка стоимости последовательного чтения делается, в свою очередь, с учетом параметра seq_page_cost, который равен по умолчанию 1.
(17)
Я проводил тесты и в этих тестах получал уменьшение времени выполнения запроса при снижении seq_page_cost с 1.0 до 0.1. Так что давайте оставим этот теоретический спор
И я писал выше, что у меня большие ресурсы выделены на кэш (effective_cache_size=16GB)
нубский вопрос… В тестах от Гилёва смена этих параметров на количество попугаев никак не влияет, чем бы ещё проверить профит?
(20)
Проверьте наиболее часто используемые запросы в вашей конфигурации в консоле запросов
(7) Те, кто поступит именно так, как вы описали, пусть на самом деле покупают MS SQL. Всё абсолютно верно!
(22)
Купил, поставил и не паришься ) Если денег много — почему нет? )