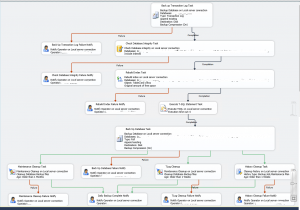


В архиве 2 скрипта. Оба реализуют стандартный комплект действий над списком баз:
- проверить целостность
- перестроить индекс
- очистить процедурный кэш
- [NEW] обрезать transaction log
- с архивировать
- удалить старые архивы
В случае ошибок — послать уведомление на почту администраторам
- serial.sql — выполняет комплект последовательно база за базой
- parallel.sql — пытается выполнить весь комплект параллельно
В результате на малой продуктовом сервере (8 virtual proc Xeon E5-2650v2 2.60 и SSD raid) c 15 базами общим объемом 50Gb получили:
- serial.sql — 13:51 минута
- parallel.sql — 4:22 минуты
Итого быстрее в 3 раза.
технически parallel.sql создает отдельные job для каждой базы и сразу их стартует.
Если кто подскажет идею, как сделать по другому — буду очень благодарен. Т.к. при таком режиме управлять количеством реально запущенных задач не получается.И какая там "параллельность выполнения" сказать тяжело.
[UPD.23/07/2026]
Дошли руки поправить скрипты:
- расширена обработка ошибок (не валимся если база в offline mode например)
- включена возможность бэкапа transaction log
на основном продуктовом сервер с тремя базами общим объемом 150 gb получили:
- serial.sql — 57 минут
- parallel.sql — 28 минут
Ускорение в 2 раза.
PS теперь надо сделать предварительную проверку дефрагментации индексов и делать rebuild/reorg только тем что нужно. Ну и некоторые таблицы вообще не трогать.
[ВАЖНО] Паралельный бэкап на тестовом сервере с 15K дисками и 30 базами объемом в 200Gb поставил сервер колом до окончания процесса. Поэтому на боевых серверах надо быть аккуратным. Во избежании
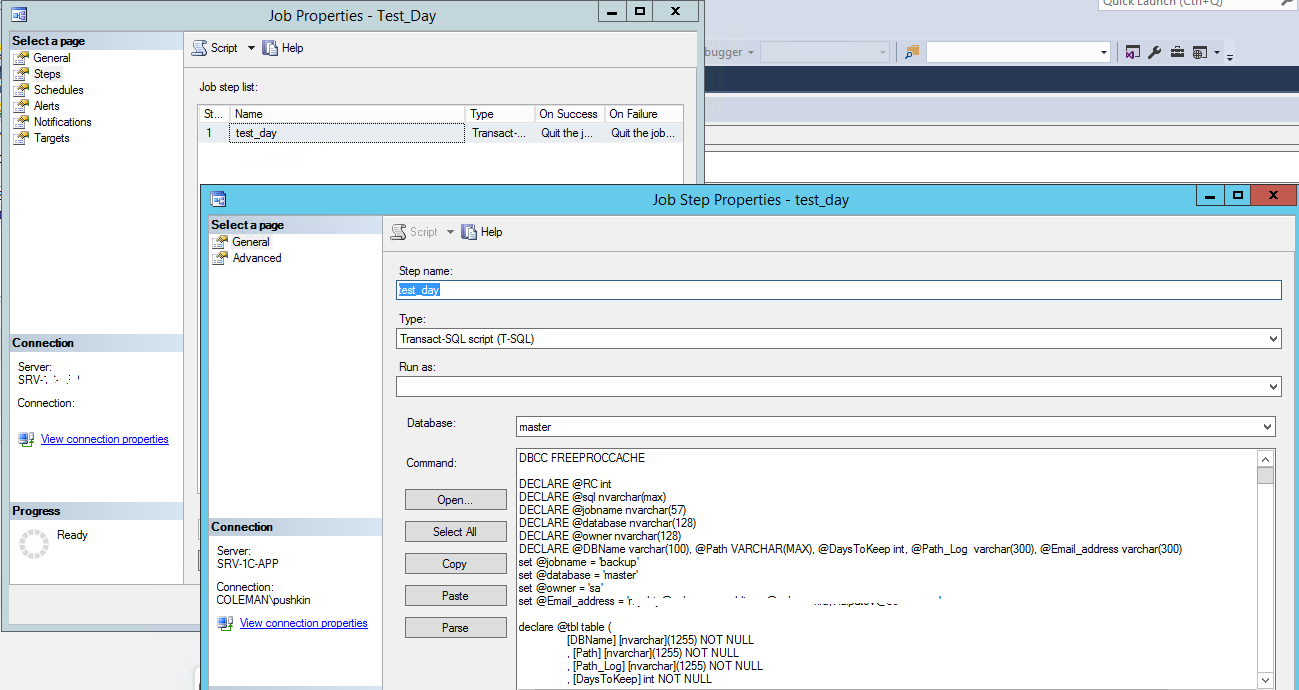
Подключение: 1 step в обычном job куда вводиться текст скрипта:
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
>>Оба реализуют стандартный комплект действий над списком баз
А где статистика, индексы? Эти действия как раз, надо делать перед бекапом.
Согласен с предыдущим оратором.
Как минимум иллюстрация того что ИТС читать все же нужно.
(1)
А вот по поводу — перед бекапом или после — я бы поспорил
Если что то пойдет не так — бекап будет только предыдущий
А так — сделал бекап — делай с базой все что
хочешьнужно(1)»перестроить индекс», который автоматически обновляет статистику не подходит? Тогда что имеется в виду?
(3)Слышали бы вы как MVP Microsoft костерил людей которые вместо пересчета статистики перестраивают индексы.
Если вкратце — физически изнашиваете свой диск
(4) у меня в планах смотреть фрагментированность индексов и в зависимости от этого делать rebuild/reorg/nothing :-). Сделаю — сделаю и обновление статистики. Вопрос не получиться ли дольше по времени…
Ну и как «MVP Microsoft костерил» разработчиков и архитекторов 1С платформы на предмет «они до сих пор не используют все возможности SQL 2008», например, я тоже слышал. И не раз.
(5)Вы найдите в ИТС методичку, а статистика очень быстро обновляется даже на 200 Гб
(6)Я не про статистику, а про анализ фрагментированности индексов и rebuild/reorg/nothing в зависимости от степени.
(2) Это штатные механизмы обслуживания базы, которые сами данные по факту абсолютно не трогают. Если делать бекап до обслуживания у базы с полной моделью восстановления то при восстановлении будем поднимать еще и огоромный лог который делает обслуживание индексов. То есть время поднятия базы можно легко увеличить раза так в 4. Если вы хотя бы раз в неделю поднимаете в тестовую базу из копии размером гигов 50-200 это будет немного напрягать. Ну как немного…
(3)Действительно. Смотрю в книгу вижу фигу.
(8)Я бы не сказал что перестроение индекса не трогает данные особенно кластерного.
И я видел когда такие моменты совпадали с приходом кирдыка по железу например.
Например файл бд переехал на сбойный сектор
И все амба и каюк, бекапа уже не будет
(5)
(10) Ну такой кирдык по железу ( в отсутствии резервирования) может придти и без перестроения индекса, а прост о во время работы….
(11) Оно у меня в закладках и активно используется. Или там есть про запуск параллельных задач, а я пропустил?
(13)там про анализ фрагментированности
(10)Давай попробуем максимально натянуть сову на глобус. Например БД куда-то едет без бекапов. Ситуация конечно технически возможна. Но проблема не в обслуживании в данном случае.
Совершенно не понял, зачем писать параллельный скрипт, если стандартное задание backup database уже бэкапирует базы параллельно.
В качестве аргумента, если я правильно понял, называется неудобство изменения плана обслуживания, если в него добавляется еще одна база — добавлять ее нужно в нескольких заданиях плана обслуживания.
Судя по скриншотам с затертыми именами баз данных, в заданиях вместо опции «Все базы данных» перечисляются конкретные базы. Из-за непонимания важности обслуживания всех баз данных по единому плану и вытекает данное неудобство и предлагаемое автором решение.
Разделение баз на те, которые бэкапируются, и на какие-то другие — серьезная методологическая ошибка. В заданиях плана обслуживания не должно быть явного перечисления баз. Только «все базы» + игнор оффлайновых и не иначе. При этом они бэкапятся параллельно сервером sql без всяких самодельных скриптов, а добавление новых баз не требует изменений в плане обслуживания.
Кроме того, предлагаемый план обслуживания непрофессиональный, и автора совершенно справедливо отправляли в ИТС.
Но раз уж главной темой статьи является параллельность, то сделаем акцент именно на ней. Автор озабочен параллельностью одной единственной задачи (которая на самом деле параллельна штатно), а сам связывает последовательным выполнением, задачи плана обслуживания, которые могут выполняться параллельно.
Потому кроме ИТС, посылаем автора в мануал администратора SQL
(16) «Совершенно не понял, зачем писать параллельный скрипт, если стандартное задание backup database уже бэкапирует базы параллельно. » 10 баз бэкапиться параллельно в 10 потоков? Серьезно?
«Судя по скриншотам с затертыми именами баз данных, в заданиях вместо опции «Все базы данных» перечисляются конкретные базы. Из-за непонимания важности обслуживания всех баз данных по единому плану и вытекает данное неудобство и предлагаемое автором решение.» У меня там 40 баз, списанных в архив. Мне их тоже каждую ночь переиндексировать и бэкапить? Серьезно?
«Кроме того, предлагаемый план обслуживания непрофессиональный, и автора совершенно справедливо отправляли в ИТС. » Конкретные претензии можно? А то на ничем не мотивированный наезд похоже…
«Но раз уж главной темой статьи является параллельность, то сделаем акцент именно на ней. Автор озабочен параллельностью одной единственной задачи (которая на самом деле параллельна штатно), а сам связывает последовательным выполнением, задачи плана обслуживания, которые могут выполняться параллельно. » Вы, простите скрипт смотрели или «чукча не читатель — чукча писатель?»
Отдельно можно вопрос — а параллельностью какой конкретно «одной единственной задачи» озабочен автор? А то он, к сожалению, не в курсе…
(8)
Браво, коллега, вы понимаете очень тонкий момент. Обслуживание индексов фиксируется в логах, и это громадный объем операций. Тянуть это в бэкап логов и в дифбэкапы нет никаких резонов.
Но на время восстановления это не должно повлиять при грамотной организации схемы бэкапирования. Дело в том, что если мы соблюдаем RTO, было бы неправильно восстанавливать базу к моменту сбоя исключительно по логам, иначе мы можем и не успеть, вне зависимости от того, придется ли при восстановлении проходить по логам операции обслуживания индексов или нет. Поэтому для соблюдения RTO за базой неотступно следуют дополнительные опорные точки в виде короткоживущиех дифбэкапов, а с помощью логов восстанавливается только последний хвостик. Именно с помощью последнего дифбэкапа мы и перепрыгнем регламентные операции. Поэтому время восстановления существенно не изменится. В то время как при восстановлении только по логам, время действительно может возрасти кратно.
Но есть и другие причины,
1. В логе после обслуживания индексов зафиксировано слишком много изменений и свободного места в нем практически не остается. Ближайшие операции пользователей или регламентные задания 1С начнут увеличивать лог.
2. Дифбэкапы станут большими. Если их нет, или они короткоживущие и создаются только с целью снизить RTO, данное обстоятельство можно игнорировать. Но схема бэкапирования может предусматривать создание ежедневных дифбэкапов вместо полных. И тогда сильно возрастают накладные расходы на их хранение, а вопросы «до или после» и «с какой периодичностью» начинают имеет существенное значение.
(16)
Расскажите, что делать с тестовыми базами? Их тоже обслуживать и бекапить?
(8) Сделать backup transaction log’ов перед full backup, чтобы их обрезать? Грязновато — зато в Full backup останутся «чистые» данные без лога?
(18) если уж нужен короткий RTO, то может просто always on и не мучаемся?
By the way — уж коль мы дошли до логов — нигде не нашел ответа на вопрос (возможно плохо искал), что у нас происходит с фрагментацией индексов после бэкапа transaction log в full mode?
(20)(18)Давайте еще вприсядку станцуем для полноты картины, вместо того, чтобы просто поменять порядок действий.
(22) Дык работа у нас такая 🙂 Я, к слову, с (8) абсолютно согласен. т.к. главный потребитель бэкапов — это отдел разработки. И dev сервера prod’у ни чета по ресурсам 🙁