
Лет этак 25-30 назад весьма активно обсуждалось/развивалось потоковое программирование – в частности, «японский вызов» и ряд других проектов супервычислителей пятого поколения в той или иной степени предполагали использовать управление потоками данных. Способ потокового управления в его простейшей интерпретации состоит в реагировании на события всего одного вида – готовность блока данных к дальнейшей обработке. Важными принципами становится при этом единственность присваивания – каждая переменная (массив, коллекция, файл) инициализируется в процессе вычислений только один раз – а также отсутствие «побочных эффектов» исполнения операций, которые, как известно, являются источником самых труднообнаруживаемых ошибок в программах. Потоковые программы, в отличие от «обычных» становятся, таким образом, верифицируемыми.
Напомним (для тех, кто не ходил по первой ссылке), что потоковое программирование представляет программу в виде ориентированного графа, в котором ребра соответствуют потокам данных, а вершины — действиям, которые над ними производятся.
Конечно, идея управления потоками данных никуда не исчезла и продолжает активно (и плодотворно) эксплуатироваться, в том числе, разработчиками компьютерного «железа». Накоплен и солидный теоретический багаж. Имеются потоковые языки программирования и их трансляторы/интерпретаторы.
Я же хочу обратить внимание на то, что графические схемы могут успешно применяться при проектировании систем обработки данных (СОД). Например, нам захотелось реализовать проект «Большой брат» — систему всеобъемлющего контроля производственного процесса. На разных участках его работают некие АСУТП, фиксирующие отдельные параметры, входные и выходные потоки ТМЦ (сырье, продукция, технологические материалы, полуфабрикаты) фиксируются в учетных конфигурациях 1С (ага, вот при чем здесь 1С). Нам требуется оптимизировать производство хотя бы в части минимизации потерь на воровство и разгильдяйство.
Поскольку мы сейчас системные аналитики, будем пользоваться системотехническими принципами. В частности, принципом рекуррентного объяснения, который гласит, что свойства систем данного уровня выводятся из постулируемых свойств элементов – систем непосредственно нижестоящего уровня и связей между ними. На практике это означает, что на первом шаге мы рассматриваем будущую СОД как «черный ящик» с известным набором входных воздействий (данных) и необходимым набором выходов (отчетов):
(Y1, Y2, Y3,…) = F(X1, X2, X3,…)
Заметим, что так же описывается вершина (ориентированного) графа вместе с инцидентными ей дугами. Идея предлагаемой формализации проектирования СОД состоит в том, чтобы определить набор корректных преобразований (композиций и декомпозиций) схем счета (графов). Имея такой набор и взяв в качестве исходной точки упомянутый «черный ящик» (подграф из единственной вершины), реализующий полный алгоритм обработки, легко установить индукцией по числу шагов декомпозиции корректность программного проекта (например, однозначность результатов счета).
Математическая формализация (построение функционально полного класса корректных преобразований) не очень громоздка – две машинописные странички – но приводить ее здесь я не считаю целесообразным. Ну, разве что в качестве приложения. Отмечу только, что для построения наборов допустимых последовательностей вычислений мне пришлось дополнить область значений логических операторов {Истина, Ложь} значением «Не определено».
Опять трехзначная логика на службе корректности алгоритмов…
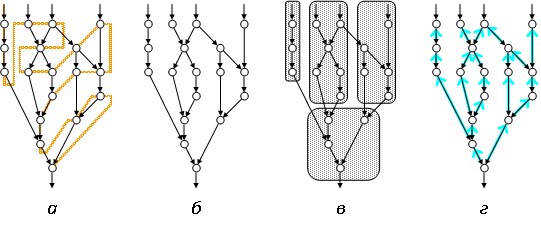
На картинке из лекции по потоковым ВС приведены возможные вычислительные модели: а – фон-неймановская; б – потоковая; в – макропотоковая; г – редукционная. У меня описывается декомпозиция по варианту в.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке