<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\









Отличная статья!
А вы используйте Jenkins?
Как-то анализировали в сравнении gitlab-ci и jenkins?
Почему остановились именно на jenkins?
(1) Да, в публикации как раз приведены скриншоты сборочной линии на основе Jenkins. Там, где показаны графики Allure и этапы развертывания базы, выполнения тестов и подготовки cf-файлов.
Jenkins выбрал из-за доступности информации по использованию Vanessa-ADD совместно с ним. Все примеры, которые приводятся разработчиками инструмента да и вообще в сообществе, показывают как использовать для этих целей именно Jenkins c плагином Allure. Все обучающие материалы тоже. Мне, как в первую очередь разработчику 1С, важна доступность информации и поддержка сообщества по теме CI/CD. И в случае с Jenkins она есть.
С Gitlab-CI не сравнивал. Он требует знания Linux, я хоть и изучаю Linux и стараюсь его применять для личных нужд, но пока не готов в продуктиве на работе использовать. Присматривался к Bamboo так как на двух последних проектах использовались и используются продукты Atlassian. Интеграция у этих продуктов просто фантастическая, может быть продолжу изучение.
Кстати, хороший ответ на то, почему Jenkins подходит лучше всего и так широко распространён есть в следующих видео ( указал в ссылках таймстэмпы на то, где начинаются сравнения систем сборок ) :
— Алексей Лустин, Статические анализаторы систем 1С при внедрении менеджмента качества продуктов
— Кирилл Семаев, Сравнение систем CI/CD
Я по Семаеву сейчас Линукс учу 🙂
Описано детально, но слишком много текста в одной статье, на мой взгляд, сходу не осилил все прочитать( бегло пролистал.
I) Я все же считаю, что логично писать тесты по тем пользователем (права), под которым будет запускаться сценарий. На это может влиять множество факторов: интерфейс пользователя, наличие отсутствие кнопок из-за прав и др.
II) Про адаптацию. Тесты должны быть параметрическими; должна быть поддержка импорта (библиотека сценариев); должны быть максимально независимыми от тестируемой системы и др.
III) Генерация данных оптимальна перед запуском цикла тестирования, а вот
Вариант 3 для генерации данных на мой взгляд не очень хорош:
— сценарные тесты наиболее нестабильные — свалится хотя бы из-за api от 1С и все все остальные тесты гарантированно упадут,
— долгие (особенно для большого объема данных) , у нас сейчас сценарные тесты суммарно занимают около 5 часов (каждый тест в среднем 1000 различных действий), и для подготовки для них данных тоже будет адски тяжело.
Вариант 1 согласен — дохлый номер
Вариант 2 самый оптимальный (быстрый, надежный, удобный). Только в данном случае нужно аккуратно подходить к созданию сериализуемых данных и базы сборки:
создается база с условно постоянными данными (справочники, настройки и др.)
в качестве сериализуемых данных брать документы ввода остатков, ключи и др.
для задачи сериализации можно использовать различные сторонние инструменты
(4) Хотел еще описать здесь установку инструментов: Visual Studio Code и необходимых плагинов, OneScript и Vanessa-ADD как библиотеки. Но да, объем материала не позволил это сделать в одной публикации. Придется об этом рассказать в следующий раз.
Применяя Vanessa-ADD, а до этого изучая Vanessa-Behavior, всё время чувствовал нехватку информации так, чтобы она была в одном месте. Её фрагментарность очень напрягала. Поэтому постарался сделать публикацию максимально ёмкой, чтобы полностью закрыть вопрос знакомства с направлениями применения этой библиотеки.
Здесь еще тексты сценариев много места отъедают. Но пример сценария тоже нужен был. Иначе не было бы ответа на вопрос «с чем мы столкнёмся, начав применять Vanessa-ADD и стоит ли оно вообще того». Сквозной пример вообще рассчитан на то, что его можно не только прочитать, но и проработать на демо-базе УТ 11.4 или ERP 2.4.
Да, статья получилась довольно большая. В свое время тоже сталкивался, что нет подробного описания. Информация разрознена.
Однозначно Плюс.
Смущают только примеры.
Показать
Это не верно с точки зрения структуры сценария оригинального Gherkin.
«И» обозначает продолжение предыдущего этапа сценария. В данном случае это продолжение Тогда. Что по смыслу не соответствует задуманному.
Нужно разделить пример на несколько более мелких, которые укладываются в стандартные этапы, если нужны промежуточные проверки на «Тогда». А отдельные этапы «Тогда» могут быть использованы в обширном примере в качестве «Когда».
а нам ванесса не зашла, пользуемся тестером, но статья зачетная!
(6) Эти шаги генерируются «кнопконажималкой» — автоматическим механизмом записи действий пользователя и подставляются из библиотечных шагов, определенных в каталоге OneScript/lib/add/features/libraries. Думаю разработчикам было бы очень сложно заменять «И» на более подходящее ключевое слово анализируя окружающие шаги. При желании это можно сделать вручную, но будет трудоёмко. Vanessa-ADD позволяет даже свои библиотеки шагов писать и применять их в случае необходимости )) Надеюсь получится дойти до этой темы тоже.
(8) ждем продолжения.
Прошу прощения за ламерский вопрос — верно понимаю, что так как все три фреймворка (ваша Ванесса, Тестер и 1С Сценарное тестирование) используют для вызовов форм и кнопок навигационные ссылки, как это делается в той самой древней статье на ИТС? То есть, технология одна и та же? И поэтому, тестировать конфу на обычных формах не получится? Я пробовал Тестер, он успешно подключается к тест-клиенту и видит его, но никакие сценарии не выполняются.
(10)
Все указанные инструменты рассчитаны на работу с управляемым интерфейсом, обычные формы не поддерживаются.
Кстати, по поводу вопросов. Не указал в публикации, есть хорошие ресурсы, где можно получить ответы на вопросы по Vanessa-ADD и другим библиотекам OneScript
В первую очередь это целый раздел форума, посвященный Vanessa-ADD.
И два телеграмм-канала:
(0)
Я недавно узнал, что в моём перфораторе есть три режима: молоток, перфоратор и сверло. Оказывается, с помощью одного инструмента в разных режимах можно и дырки просверлить и гвозди забить. Гвозди, правда, специальные нужны, с дюбелями, но до чего же быстро эти гвозди можно забивать!
Восхитительно, что в Vanessa-ADD совмещено два инструмента для тестирования — можно выбрать наиболее подходящий к ситуации.
Не упущу возможности поворчать на популяризаторов языка Gherkin. Если адаптировать к русскому, то делать это грамотно: вместо жаргонизмов «Функционал» использовать «Функциональность», а вместо «фича-файл» — «Спецификация».
(10) для обычного приложения можно использовать, например, SikuliX.
Или еще вариант — OneScript — WinExt.
(0)
Владимир. Хорошая обзорная статья.
Начинающим — в самый раз.
///////////
В статье есть неточности. Я их отдельными комментами оформлю.
(0)
может использоваться как самостоятельно так и вместе с СППР. Выше уже об этом писали. Исправьте пожалуйста.
(11) Насколько я знаю Vanessa-Automation — это также развитие Vanessa-Behavior, обладающее как минимум теми же возможностями, что и исходный проект.
Развитие не отслеживал, но в тематических телеграмм-каналах видел информацию, что сейчас есть только два инструмента, позволяющие удобно работать со сценариями — Visual Studio Code и следующая СППР.
Vanessa-ADD очевидно ориентирована на VSC, Vanessa-Runner и OneScript как на Open Source и на свободно распространяемые инструменты.
По поводу совместной работы с СППР информации нет — думаю документация по интерфейсам для взаимодействия от 1С в данный момент недоступна широкой публике.
В то же время в документации по VA на github я наоборот не нашел информации о взаимодействии Vanessa-Automation с ранее привычными для этого инструментами.
Поэтому возможно у меня создалось неправильное впечатление. А возможно правильное.
Изменил формулировку на «ориентировано в том числе на СППР».
Также можно писать сценарии не использующие клиента тестирования. Например, можно написать сценарий, который нажимает на кнопки в калькуляторе Windows.
(16) Ок. Изменил формулировку на «ориентированным в том числе на совместное применение с СППР».
В справке всех трёх ванесс (VB, ADD, VA) написано, что используется язык Turbo gherkin а не Gherkin. Синтаксис языка был существенно расширен, по сравнению с оригиналом. Лучше об этом написать.

Прикрепил скриншот.
(18)
И от того же автора.
Список ключевых отличий VA от ADD можно посмотреть .
Документация в разработке. Ещё не было финального релиза СППР 2.0.
Vanessa runner должен работать. Но сам я его не использую.
Обычно финальной стадией создания сценария является добавления «проверочных» шагов. Которые нельзя «накликать». Например, сравнение отчета с эталоном. Это та самая секция «Тогда» в сценарии.
(18) Не много не понятно, про ориентацию. В СППР более удобна работа с фичами, в целом всё. Я использую VSC, так же oscript при работе с VA.
(0)
У вас в отчете Allure 802 сценария. Здорово! Это вместе с дымовыми тестами? Или только сценарные тесты? Можете сказать?
(23) Ох. Неужели я поторопился со сменой формулировки…. ))
PS: Это был ответ на удаленную часть комментария. Поторопился и с ответом ))
Например тег @tree для Vanessa-ADD означает, что сценарий содержит шаги, декомпозируемые на подшаги.
В Vanessa Automation не нужно писать @tree. Он подразумевается по умолчанию.
(21) а что используете вместо него, напишите, пожалуйста.
(0)
Опечатка в слове делать.
(27)
Считается, что он уже написан, поэтому не нужно его вручную прописывать в каждую фичу. (это написано про тег @tree)
(29) Я имел ввиду, что вы используете вместо Vanessa runner.
(24) Это вместе с дымовыми тестами.
В том контуре, который на скришнотах сценариев пока около 20. Смысл в том, что сценарные тесты постепенно заменяют дымовые, если они затрагивают те же самые формы или выполняют те же операции с объектами.
В то же время показалось некорректным разделять сценарные и дымовые тесты на разные отчеты. Это позволило бы получить более красивые графики, но гораздо важнее видеть всю отчетность совместно.
(30)
А, понял. Сорри. Это я про тег @tree писал.
Вместо «Vanessa runner» просто используем запуск VA через /Excecute и передаём нужный JSON.
Это видится несложной задачей.
(32) Есть ли в этом случае возможность получать сообщения о ходе выполнения тестирования в процессе тестирования, а не только по его завершению?
Платформа 1С не умеет работать с stdout и поэтому в сборочной линии мне необходимы возможности Vanessa-Runner для того чтобы видеть информацию о ходе тестирования. Vanessa-Runner эмулирует вывод в stdout через промежуточный файл и перенаправляет вывод результатов сценарного тестирования, в консоль. Это просто необходимая функция не только при отладке сборочной линии, но и при регулярной работе с ней.
Мне кажется что нельзя просто отказаться от Vanessa-Runner в этом случае. Можно только заменить его на другой инструмент. Либо работающий на платформе 1С, либо другой внешний по отношению к ней.
Если использовать инструмент на платформе 1С то мы также лишаемся возможности встроить его в сборочные линии серверов сборок (Bamboo, Jenkins и так далее) ввиду неспособности платформы работать с stdout, а значит и с ssh. По крайней мере удобной возможности взаимодействия. То есть мы вынуждены полностью замкнуться на 1С и потерять возможность использовать единый сервер сборок для всех продуктов компании.
Если же использовать другой внешний инструмент, то в чём резон отказываться от мощных возможностей Vanessa-Runner, где одновременно есть удобные команды для работы с RAS, автоматического выбора версии платформы и куча всего ещё?
(31)
Да, вместе лучше конечно.
Ещё лучше делать группировки к сценариям по тегам или по иерархии каталогов.
В VA сделано на основании иерархии каталогов. Также результаты нескольких сборок объединены в один отчет.
Пример можно посмотреть .
(33)
Vanessa-Runner просто читает лог файл, который отдаёт Ванесса. Эту фичу я делал ещё для оригинальной VB. Там же есть примеры скриптов, которые делают вывод в лог.
Вот выглядит лог сборки у VA. В нём видно статус выполнения тестов в риалтайме.
Кто-то должен читать текстовый файлик, который отдаёт ванесса, и выводить его в консоль. Это, конечно, может быть и Vanessa-Runner.
(0)
Vanessa Automation ещё поддерживает комментарии в виде двух слешей //
(0)
Когда
Тогда
Дано
И
Но
Полный список ключевых слов можно посмотреть .
Там чуть больше. Исправьте, пожалуйста.
(0)
Если, Пока
Ключевое слово Если в языке есть, ключевого слова Пока — нет. Циклы используют другой синтаксис. Исправьте, пожалуйста.
Спасибо за статью.
Если ты помнишь наш (БИТ:ERP) подход — мы используем лайфхак: чтобы сократить затраты на подготовку макулатуры и переписывание мы стараемся соблюдать следующий порядок:
1. прототип (делает консультант), без программирования, но все формы в визуальном режиме сделаны
2. BDD-сценарий (накликивается) по подготовленным формам, а потом редактируется вручную
3. написание кода, приведение форм в приличный вид
Преимущества подхода:
1. прототип можно показать бизнес-пользователям, и они могут понять о чем речь (практика показывает, что bdd-сценарии не читают и не понимают, так же как не читали и не понимали ТЗ). А это значит, что ещё до этапа документирования и разработки мы учтем существенную часть замечаний.
2. BDD-сценарий в режиме накликивания пишется быстрее, и он максимально конкретен и валидируем, в отличие от рукописного написания, где как и ТЗ — это больше литературно-художественное произведение, где допустимы множественные толкования
3. в виде произвольного текста можно позволить себе описывать действительно сложные алгоритмы, которые невозможно нормально объяснить через интерфейс пользователя.
Собственно вопрос: ты так пробовал? Что пошло не так?
(34) Спасибо! Красиво получается. Я так пока не умею ))
Указанные ниже исправления внесу в публикацию чуть позже — надо посмотреть Ваши ссылки.
(40)
//Тот неловкий момент, когда тебя цитируют, а я не помню когда именно это говорил )
При BDD подходе, конечно, разработчик тоже пишет сценарий.
Если задача покрыть тестами то, что уже написано — тестировщик с этим замечательно справится.
(41)
Приходите на партнерскую конференцию весной. На стенд СППР.
Покажу как это работает вживую )
Также есть этот чат для обсуждения ванессы.
(0)
В Vanessa Automation я использую флаг «Искать элементы формы по имени». Его, скорее всего, нет в ADD, т.к. он появился уже после разделения проектов. Этот флаг позволяет сделать сценарии более стабильными относительно изменения заголовка элементов, т.к. генерируются шаги, которые ищут элементы формы по имени.
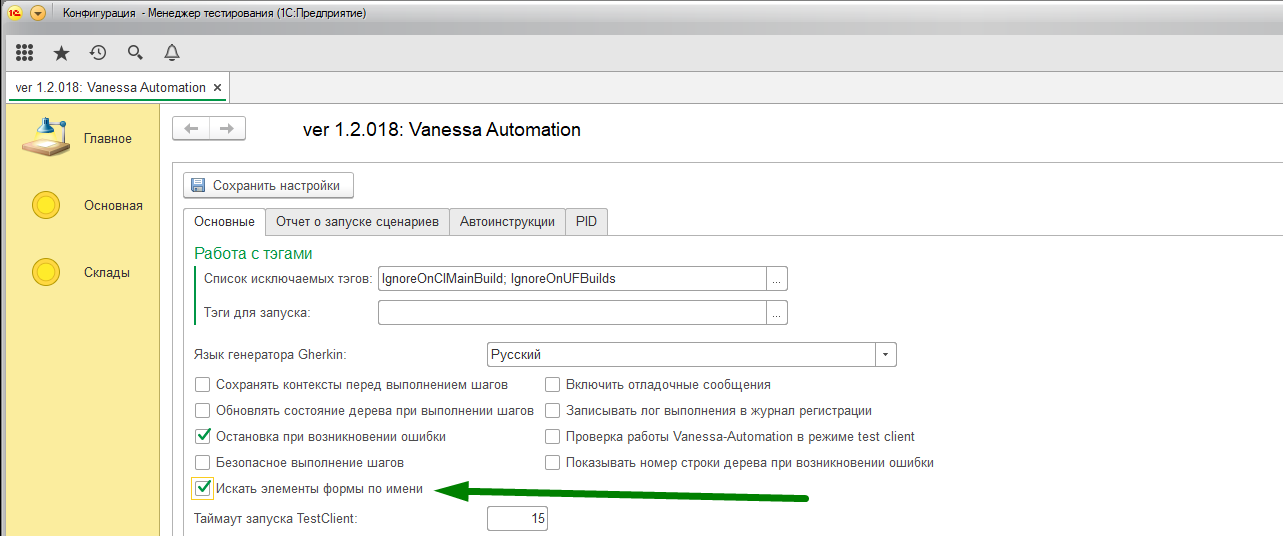
(см скриншот)
(0)
У нас тестировщик просто просит добавить недостающий шаг. Обычно это не занимает много времени.
(0)
Возможно стоило сразу «накликивать» под менеджером по продаже. По крайней мере ту часть, которую делает менеджер. Мы ведь всё-равно собираемся проверять поведение под ним.
(0)
Каюсь за это решение )))))))))))))
Был момент, когда мне пришлось выбирать, создавать парные шаги для поиска элемента по имени, или решить это как-то по-другому.
Например, использовать спецсимволы для поиска по имени, например так
И я ищу элемент «!ИмяЭлемента».
Здесь спецсимвол — это восклицательный знак.
Так, по-моему, сделано в Тестере.
Но тогда казалось важным минимизировать доработки оригинального Gherkin, и я пошел по пути парных шагов.
Возможно стоит поддержать оба варианта.
Как считаете?
(0)
Расскажите, пожалуйста, подробнее, зачем делать секцию «Контекст» — большой. Из статьи я не понял, почему шаги, которые «накликивают» некоторые документы находятся в контексте, а не в теле сценария. Они ведь тоже занимаются проверкой поведения. Да и секция конектста полезна, когда у нас сценариев больше одного.
(0)
Писать тесты на копии рабочей базы — это слишком сурово )
Лучше подготовить эталонный DT, с минимальным набором необходимых данных.
(0)
То есть данные готовятся один раз так, чтобы они подходили под сценарии. Сериализуются в файл. Затем перед запуском сценариев десериализуются и загружаются в базу.
Все виды сериализации данных с последующей загрузкой плохо подходят для типовых. Метаданные сильно меняются. Мы на ERP не пользуемся загрузкой из макетов или подобным.
(0)
Тоже хороший вариант. Знаю проекты, которые так делают.
(47) Кстати идея с селекторами мне нравится.
Создал ишью
(48) Скорее всего делается портянка в одном сценарии из-за того, что нет последовательности выполнения, как в схеме бизнес-процесса в СППР.
Можно посмотреть видео (если есть доступ к ИТС , там Леня рассказывает о декомпозиции сценариев из портянки в отдельные блоки с последовательной передачей результатов одного процесса тестирования следующему.
(47)
Кажется, что для полного понимания со стороны пользователей было бы достаточно просто таких названий :
(54)
Этот вариант рассматривался, но предполагалось, что большая часть элементов будет искаться по заголовку и поэтому это было принято по умолчанию.
(55)
Тогда может быть достаточно такого?
вместо
На самом деле это мелочь и к этому быстро привыкаешь. Но если мы хотим сделать инструменты для сценарного тестирования более распространенными , то здесь важна скорость знакомства новичков с ними, а для этого нужно уменьшить количество WTF на этапе начала работы с инструментами. А мелочей много ))
(56)
Вы имеете ввиду изменить описание шага?
(57) Да, раз сам шаг изменять нецелесообразно, то можно изменить описание. Пользователи на него тоже ориентируются.
Таких шагов много и ни в описании шага ни в сигнатуре не указывается, ведется работа с заголовком или с именем элемента формы, заданным в конфигураторе :
(58)
Ок. Исправлю.
Завел задачу на это.
Хорошая статья, давно не хватало практических примеров. Вы немного затронули тему разных инструментов, и возможно имело бы смысл отдельной статьей рассмотреть их не с точки зрения что хорошо, а что не очень, а в направлении какой инструмент для чего задумывался. Например Тестер, идейно создавался для разработчиков и очень хорошо уживается со сценарным тестированием от 1С (СТ). И с ванессой он разнится настолько, что оба могут жить каждый в своей зоне. Это еще важно и потому, что каждая компания, принимая решения об использовании того или иного инструмента, может и не задумываться о том, что они при этом теряют. Мне приходилось быть частым свидетелем ситуаций, когда СТ начинали с разработчиков, а потом постепенно делегировали отдельным тестировщикам, оставляя программистов в “покое”, т.е. ни с чем по части внутренних механизмов улучшения качества на базе автоматизации их тестов.
Как организован порядок запуска тестов, если их раскиданы по разным каталогам?
(61) Все файлы из всех каталогов загружаются и исполняются в произвольном порядке. На самом деле порядок конечно есть, в идеале порядок запуска тестов должен быть не важен и управлять им не нужно. И в приведенном примере на этапе сборочной линии «Сценарное тестирование» это действительно так. Фича-файлы и даже сценарии в них должны быть независимы друг от друга. Ведь фича-файлы соответствуют отдельным функциональным возможностям системы и отдельным User Story.
Порядок определен для таких разных этапов как :
1) Запуск подготовительных сценариев. Они генерируют тестовые данные и больше ничего, чтобы не делать слишком большим контекст основных сценариев (как в примере в этой публикации). Этот этап можно заменить на запуск внешней обработки, создающий тестовые данные программно. На самом деле я использую оба подхода, запуск обработки использую для сброса паролей пользователей и назначения необходимых ролей.
Обеспечить запуск сначала только подготовительных сценариев можно либо разместив их в отдельном каталоге, либо отметив их специальным тегом, например @Подготовка, и указав в настройках запуска необходимые фильтры по тегам.
2) Запуск основных сценариев — проверка поведения, опирающаяся на созданные тестовые данные.
3) Дымовые тесты.
При таком подходе порядком исполнения управляет Jenkins на уровне этапов сборочной линии. Вы можете увидеть это на скриншотах в этой публикации. Можно сделать управление и на уровне простого bat/sh скрипта, если не хочется сразу Jenkins изучать. Но в любом случае это реализуется через запуск и завершение отдельных сеансов тест-менеджера и тест-клиента.
А в рамках одного сеанса фича-файлы, сценарии и дымовые тесты должны быть независимы.
Выше уже писали что в будущей версии СППР возможен другой вариант, но это уже другой идеологический подход. Если больше нравится подход с низкой связанностью и декомпозицией, то лучше выбирать независимость сценариев. Если низкая связанность не кажется ценностью, то можно выбрать вариант с зависимостью сценариев друг от друга. Возможно причина в том, что у меня сейчас мало сценариев, но сейчас мне больше нравится идея с низкой связанностью.
(60) Более того хотелось бы видеть детальную таблицу сравнения возможностей и подходов.
Например, попробовав и Тестер и Ванессу, могу с уверенностью сказать что Тестер мне (программисту) удобнее.
В синтаксисе Ванессы я чувствую себя связанным по рукам и ногам. Структур данных нет, выражений нет, процедур нет. Хорошо хоть условия добавили. Понятно, что я могу под капотом реализовать любой шаг, но мне гораздо проще это делать напрямую без Ванессы.
Непрограммистам удобна наоборот Ванесса, и причина та же. Структур данных нет, выражений нет, процедур нет…
Палка о двух концах.
Делать кликеры и там и там можно, и выглядят они практически одинаково.
Но ведь тестирование не про кликеры…
(63) Для этого потребовалось бы иметь соответствующий опыт.
Возможно разделы «Различие между подходами: BDD или покрытие тестами» и «Преимущества сценарного тестирования с Gherkin» частично покрывают этот вопрос. Но конечно только частично.
Также ответ можно найти в документации:
A common misunderstanding of TDD and BDD is that they are testing techniques. They’re not. As the name suggests, TDD and BDD are about software development.
It is the process of approaching your design and forcing you to think about the desired outcome and API before you code.
Automated tests are a by-product of TDD and BDD.
Мне кажется, что если составить сравнительную таблицу, то может оказаться так, что у одного инструмента все плюсы будут в одной половине этой таблицы, а в другой пустота, а у другого инструмента с точностью до наоборот )) В этом случае наверное лучше говорить о концепциях, а табличное сравнение может выглядеть не очень наглядно.
Кстати, преимущества Тестера, точнее подхода к тестированию без языка Gherkin и элементов BDD, уже очень хорошо описаны во вводной части публикации посвященной Тестеру, ссылка на которую дана в самом начале этой публикации : .
Я при выборе еще исхожу из перспектив применения инструментов :
• более тесная связь с OneScript, наличие курсов и вебинаров по их совместному применению
• связь с библиотеками для автоматизации деятельности разработчика и релиз-инженера
• публикации на ИТС
(0) Большое спасибо за отличную огромную статью.
И большущее спасибо за популяризацию тестирования.
Нас, активных, становится все больше.
Рад, что используешь и дорабатываешь Ванесса-АДД!
(65) Спасибо за оценку, это важно!
До участия в доработке мне ещё далеко.
Вообще не помешал бы отдельный мануал или вебинар не только по использованию инструментов, но и по участию в Open Source проектах для платформы 1С. Думаю многих останавливает от участия в доработках отсутствие доступной информации и примеров как это делать. Если с git в любом случае скоро всем придётся познакомиться, то механизм коллективной разработки на github для многих останется незнаком.
А как Вы верно заметили, интерес к этому растет. Было бы классно что-то такое увидеть, может быть участников разработки стало бы больше.
(65) Артур, а зачем вы ?
(58)
Решено в VA 1.2.019.
Коллеги, кто использует модульное тестирование в ADD?
Поделитесь, насколько удобно в реальной работе, насколько зрелое решение?