
В платформе 8.3.9 произошло долгожданное событие – кластер серверов 1С заработал. С того момента, когда о нем объявили в 8.3.6, до момента, когда он в 8.3.9, наконец, заработал, прошло много лет. В 8.3.10 его уже можно использовать.
На прошлой конференции мне задавали очень много вопросов по поводу кластера серверов 1С, настроек сервера 1С и т.д., поэтому на этой конференции я хочу поделиться с вами этой информацией.
Уровень отказоустойчивости, какой выбрать в каком случае?
Один из первых вопросов, который возникает при проектировании серверов 1С, это какой уровень отказоустойчивости выбрать – 0, 1, 2, 3, 8, 10?
На практике в 99% случаев почти на любых высоконагруженных системах хватает уровня «ноль». Главное, грамотно настроить соотношение центральных и рабочих серверов 1С.
Есть такой критерий: если стоимость показа ошибки пользователю больше, чем стоимость еще одного сервера 1С и его лицензирования, то поднимайте уровень отказоустойчивости выше нуля. Потому что:
- Когда уровень отказоустойчивости равен нулю, но есть хотя бы два центральных сервера, то при отказе одного из центральных серверов, те пользователи, сеансы которых к нему подключены, просто получат ошибку с предложением перезапустить 1С. Перезапустят 1С, подключатся ко второму центральному серверу, и все заработает.
- Но если есть пожелание, чтобы переброс сеанса на работающий сервер отрабатывал автоматически, и пользователь не видел никаких сообщений и ошибок – чтобы было максимум две-три секунды торможения, и работа опять шла дальше, то выбивайте бюджеты на третий центральный сервер и устанавливайте уровень отказоустойчивости больше нуля. В этом случае с тремя серверами вы сможете перебрасывать сеансы пользователей без перезапуска.
Главное – помнить, что количество работающих в данный момент центральных серверов 1С в кластере должно быть на единицу больше, чем настроенный уровень отказоустойчивости.
При уровне «один» вам нужно уже как минимум три сервера, поскольку вы уже настраиваете кластер, а он по умолчанию отказоустойчивый, и при выходе одного центрального сервера два должны остаться в работе. Но если из строя выйдет еще один центральный сервер – кластер откажет в соединении.
Центральный сервер vs Рабочий сервер, в чём разница?
В 1С помимо центральных серверов есть такая сущность в кластере, как рабочие сервера. В чем разница?
- Центральный сервер – это самодостаточная единица, он может все. Он может принимать на себя клиентские соединения, он обслуживает любые сервисы и выполняет все математические расчеты.
- Рабочий сервер – это «рабочая лошадка» кластера. Он не может принимать соединения напрямую – к нему ни клиент не может напрямую подключиться, ни фоновое задание на нем напрямую запустить нельзя. Все это делается только по указанию центрального сервера 1С – на рабочий сервер передается какая-то задача, он ее выполняет и отдает результат. Все счастливы.
Есть определенный критерий, когда к имеющимся одному, двум, трем центральным серверам (которые служат в основном для отказоустойчивости) нужно добавление еще и рабочих серверов. Этот критерий простой: если стоимость модернизации текущего центрального сервера дороже, чем покупка нового (а такое бывает), то купите еще один сервер, лицензируйте его и назначьте рабочим. Это позволит вам организовать фактически безграничное горизонтальное масштабирование кластера – вы сможете свободно распространять мощность по базам.
Нужно помнить, что любой центральный сервер можно превратить в рабочий, а любой рабочий – в центральный. Главное, не забывать при этом «условие отказоустойчивости» – чтобы центральных серверов у вас не стало меньше, чем «уровень отказоустойчивости плюс один».
Во время сбоя превращать рабочий сервер в центральный нельзя. Это нужно делать заранее, во время регламентного обслуживания. Представим ситуацию, что у вас один центральный и один рабочий сервер, и администраторы сказали, что центральный сервер надо поставить на профилактику.
Одной галочкой мы превращаем рабочий сервер в центральный – на него тут же мгновенно передаются все блокировки и все списки баз. Теперь он знает, на каком сервере СУБД какая база обслуживается, и может спокойно принимать на себя соединения.
После этого вам осталось настроить клиентские 1С так, чтобы через точку с запятой были указаны два сервера, а не один. Затем вы спокойно ставите первый сервер на профилактику – ваши запросы в это время обслуживает второй сервер.
Для пользователя все это практически прозрачно. Единственное, если какой-то пользователь в это время все-таки был в системе, он получит ошибку и предложение переподключиться.
Требования назначений функциональности, как это готовить?
Все эти «чудеса», в основном, настраиваются с помощью «Требования назначения функциональности». Это – основной механизм работы кластера 1С. Поначалу кажется, что все очень сложно и запутанно: нужно какие-то приоритеты, какие-то сервисы куда-то назначить, что-то оставить в «Авто», а что-то вообще не трогать. Но, на удивление, потом все работает так, как настроили.
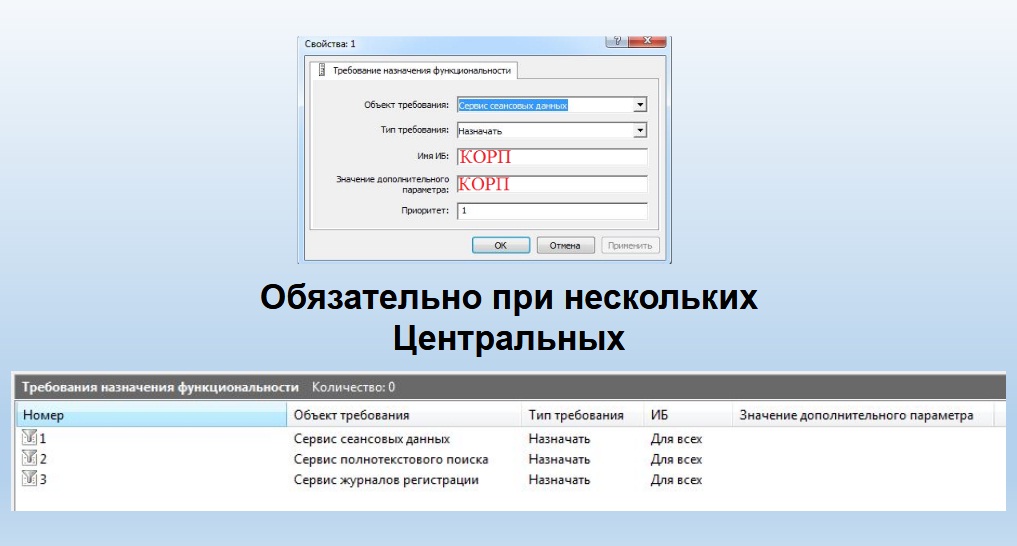
Настройки сводятся к указанию нескольких параметров:
- Первое, что вы должны указать – это «Объект требования». Например, можно указать «Сервер сеансовых данных» – тогда сеансовые данные будут писаться именно на тот сервер 1С, где вы настроили объект требования назначения функциональности «Сервис сеансовых данных»,
- Далее указываете «Тип требования» – в данном случае, «Назначать».
- И обязательно, если у вас центральных серверов больше чем один, указываете какой-то приоритет. Тогда сеансовые данные всегда будут писаться на этот сервер. Если вы это не сделали, сеансовые данные будут писаться, как решит механика сервера в конкретный момент.
В «Требовании назначения функциональности» есть несколько ограничений, а именно:
- Пункт «Имя БД» можно трогать, только если вы счастливый обладатель лицензии на платформу уровня КОРП. Если вы имеете профессиональную платформу, то указывать конкретное имя базы данных в «Требовании назначения функциональности» нельзя.
- Также в пункте «Значение дополнительного параметра» указывать тип клиента (тонкий, толстый, веб-клиент, конфигуратор) и вид фонового задания можно только в КОРП-версии. Для ПРОФ-версии можно указывать только общие назначения (например, что на этот сервер можно отдать все бэкграунды – указать конкретный бэкграунд нельзя).
Если у вас в кластере есть несколько центральных серверов, нужно обязательно настроить несколько «Требований назначения функциональности».
Нужно настроить, на каком из центральных серверов будут сеансовые данные. Причем, это нужно настроить на всех центральных серверах и на каком-то из них нужно указать приоритет выше, чем на другом. Тогда при нормальной рабочей нагрузке системы сеансовые данные всегда будут предсказуемо писаться на один сервер. Если сервер выходит из строя, системе надо знать, куда их писать. Для этого на втором сервере (где в рабочей нагрузке эта запись не ведется, поскольку приоритет ниже), вы должны указать это требование назначения функциональности с пониженным приоритетом, и механика сервера переключит туда сеансовые данные.
То же самое касается журналов регистрации. Очень частая ошибка, что про этот сервис забывают, не указывают, а потом удивляются, почему у них журнал регистрации три дня ведется на одном сервере, а пять дней на другом. И, когда нужно собрать общую информацию, кто заходил в базу, кто что менял – ничего не могут найти и ничего не могут собрать. Все это настраивается в «Требованиях назначения функциональности». Здесь нужно четко указать по приоритетам, где и что.
- Помимо этого, нужно настроить сервер полнотекстового поиска, чтобы не нагружать серверы лишней работой. Пусть он крутится на одном сервере. Иначе он будет обновлять индекс то там, то здесь, и нагружать другие серверы лишней, никому не нужной работой – зря использовать их мощность.

Как механика сервера выбирает, куда назначить конкретное соединение?
Сервер может быть в нескольких состояниях.
- Например, в состоянии «Авто». Это – состояние любого сервера по умолчанию, т.е. он все принимает все, любые требования назначения.
- Он может быть в состоянии «Назначать» – этого высокоприоритетное состояние, т. е. он как бы выиграет выборы.
- Он может быть в состоянии «Назначать», но с приоритетом ниже, чем тот, который этот же сервер назначает на себя с более высоким приоритетом.
- Он может быть в состоянии «Не назначать» – это полный отказ обслуживать этот вид сервиса этим сервером, т.е. запрет на уровне администрирования кластера.
- И сервер может вообще не работать, он может быть выключен.
Как происходит выбор? Например, запускается запись журнала регистрации. Что сделает механика кластера серверов 1С?
- Сначала выстроит все серверы так, как указано в консоли кластера, фактически по алфавиту.
- Затем оттуда будут убраны все серверы, у которых четко написано «Сервис журнала регистрации» – «Не назначать».
- Затем из оставшихся серверов будут оставлены серверы с типом требования назначения функциональности «Назначать».
- Если серверов с требованием «Назначать» несколько, будет выбран тот, у которого выше приоритет.
- Если с этим приоритетом несколько серверов, то будет выбран тот, у которого на данный момент наиболее высокая производительность.
Производительность определяется кластером серверов 1С, отправляя раз в несколько секунд эталонную задачу на каждый рабочий сервер. После того, как сервер решает эту задачу и дает ответ, механика определяет, за какое время он ее решил. Чем быстрее решил, тем больше коэффициент производительности у этого сервера. Именно он возьмет на себя соединение, либо сеанс, либо этот сервис. Он выиграет эти выборы.
То же самое происходит, если мы ничего не настроили. Например, мы не настроили журнал регистрации. Для механики это значит, что сервис журнала регистрации стоит в состоянии «Авто». Это – состояние по умолчанию, его устанавливать бесполезно, такая настройка ничего не решит. Соответственно, среди серверов, у которых тип требования «Авто», будет выбран сервер с наиболее высоким приоритетом (если мы ему этот приоритет настраивали, указав тип требования «Авто»), и из них будет выбран сервер с наиболее высокой производительностью.
Наибольшая производительность вычисляется с погрешностью 25%. Не удивляйтесь, если у вас в консоли кластера видно, что производительность одного сервера 100, а второго 90, но при этом сеанс назначился на тот сервер, у которого производительность 90, хотя, казалось бы, должен быть выбран тот, у которого производительность выше. Разница в производительности будет определена однозначно только при 25% различия – если у первого сервера производительность будет 100, а у второго – 75, тогда выбор однозначно будет за первым.
Настройки кластера и сервера 1С, какая на что влияет?
Перейдем к настройкам кластера и сервера 1С. Тут нас ждет наследие платформы 8.2, где было только одно окно свойств, и оно было в кластере (в консоли сервера платформы 8.2 задать свойства можно было только кластеру в целом).
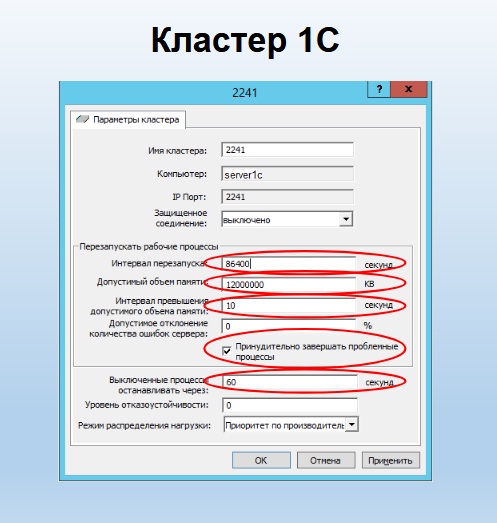
При этом, как ни странно, окно свойств кластера 1С настраивает свойства процесса сервера (rphost). Тут многие путаются.
Настройка №1, которую стоит иногда менять, – это «Интервал перезапуска» процессов сервера (rphost). Когда платформа была нестабильной, эта штука была нужной, потому что иногда возникали утечки памяти, из-за которых rphost разрастался, и его нужно было периодически перезапускать. Поэтому кластер настраивали так, чтобы он перезапускался раз в сутки, а потом удивлялись: «У меня иногда почему-то начинаются тормоза, которые длятся минуты две, потом все приходит в норму. Спасите-помогите, ничего не могу понять».
Дело в том, что секунды, которые мы указываем в «Интервале перезапуска», начинают считаться с момента старта процесса. Но предсказать, когда у вас в 8.3 процесс запустится, очень сложно. Механика его сама по разным причинам стартует, например: вы вышли за лимит баз на процесс, или за лимит соединений на процесс, или за лимит памяти на процесс. Допустим, процесс у вас стартовал 21 сентября в 11:00. В 11:00 часов 22 сентября при настройке перезапуска раз в сутки вы получите тормоза на всех соединениях, которые были на этом процессе. Откуда взялись эти тормоза? Ровно через сутки после своего запуска этот rphost будет помечен как неактивный. Системе нужно будет передать все его активные сеансы на новый процесс. Если никакого другого rphost в системе запущено не было, система запускает процесс, начинает втягивать в оперативную память этого процесса весь контекст конфигурации и только тогда, когда она туда затянет, начинает переключаться. Переключились, через две-три секунды у всех начинаются тормоза, а потом все приходит в норму. Настройка по умолчанию стоит 0, т.е. «никогда не перезапускать». Общая рекомендация – оставьте 0. Настройки, как на скриншоте – это устаревшая вещь. Не нужно их использовать. Лучше боритесь с утечками памяти.
Следующая настройка – «Допустимый объем памяти». Тут тоже очень тонкая вещь. Несмотря на то, что эта настройка находится в свойствах кластера – это максимальный объем оперативной памяти одного серверного процесса, одного rphost, а не всего кластера. Этой настройкой вы не перекроете, что сервер 1С не займет на вашем сервере больше 12 гигабайт. Это один rphost не займет больше 12 гигабайт. Что произойдет, когда он, например, занял 12 гигабайт? Если настройку «Интервал превышения допустимого объема памяти» оставить 0 (по умолчанию), то ничего не произойдет.
Это тоже очень частая ошибка в настройках кластеров. Система зафиксировала 12 гигабайт, но ничего не происходит, потому что она не знает, сколько секунд ждать превышения по памяти (свойство «Интервал превышения допустимого объема памяти»). Обязательно нужно указать, сколько времени процесс сервера (rphost) может превышать объем оперативной памяти. Например, мы указали 10 секунд. Система запускает счетчик. Если в течение 10 секунд rphost не вернулся в указанный лимит, система помечает его неактивным – на него больше не назначаются сеансы. Текущие сеансы по возможности переключаются на другой rphost.
Здесь есть еще одна классическая ошибка настройки кластера 1С – отсутствие галочки «Принудительно завершать проблемные процессы» и указание нулевого времени для остановки самого процесса. Что это означает на практике? Мы указали 12 гигабайт, 10 секунд – все замечательно. Процесс помечен неактивным, стартовал новый rphost, на него переключились все текущие сеансы, но наш rphost, который из-за каких-то утечек памяти весит 12 гигабайт, так и остался в системе, так и занимает 12 гигабайт. И пока мы не перезагрузим сервер 1С, с ним ничего не произойдет.
Чтобы проблемный процесс автоматически удалился из системы, обязательно поставьте галочку «Принудительно завершать проблемные процессы» и установите время остановки процесса (свойство «Выключенные процессы останавливать через»). Как вычислить это время? Очень просто. Запустите конфигурацию, в которой вы работаете, засеките время от первого входа до появления логина и пароля, умножьте это время на два и укажите в настройках. Почему нужно сделать именно так? Например, «УТ 11» при первом запуске запросит логин и пароль через 15 секунд. «Комплексная автоматизация 2.0» и «ERP» – через две минуты, они и три минуты могут грузиться. Если здесь время в секундах указано меньше, чем скорость загрузки контекста конфигурации в сервер 1С, вы никогда сеансы прозрачно не переключите, они будут завершаться раньше, все будут получать ошибку соединения «Сеанс завершен администратором». Да, конечно, после перезагрузки они зайдут на новый сервер, и все будет работать. Но, чтобы можно было переключиться на него прозрачно, без перезапуска, необходимо установить сюда время, вычисленное, как двойное время загрузки первого входа в конфигурацию.
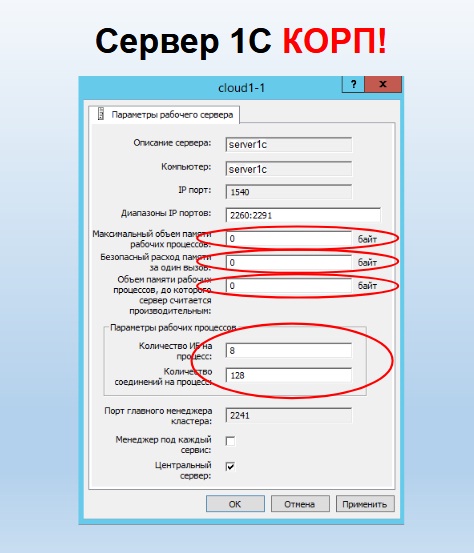
Следующая настройка – это настройка сервера 1С. Здесь – то же самое ограничение: изменять значения по умолчанию можно, только если вы счастливый обладатель корпоративной лицензии на платформу. Если корпоративной лицензии нет, вы обязаны оставить все по умолчанию.
Хотя тут есть с чем «поиграться».
Первое – «Максимальный объем памяти, занимаемой рабочими процессами». Несмотря на то, что эта настройка относится к параметрам рабочего сервера 1С, это – тот объем памяти, который могут занимать все рабочие процессы кластера 1С. Вот такая путаница. Обратите внимание, что 0 – это не бесконечность, это 80% оперативной памяти, доступной в операционной системе, на которой запущен кластер. В отличие от настройки кластера, где объем оперативной памяти измерялся в килобайтах, здесь он в байтах. Очень многие путаются, забывают указать еще три ноля и удивляются, почему у них ничего не успевает запуститься. Rphost стартовал, набрал 100 мегабайт и сразу завершился, не запустившись. Думают, что он будет 100 гигабайт набирать, забывают указать три ноля. Обратите внимание на подписи, там байты.
Второй момент – это «Безопасный расход памяти за один вызов». Тут вообще шаманство. 0 – это не ноль, а 5% от памяти, занятой всеми процессами сервера на данный момент. Как это работает? Начинается сеанс пользователя, либо какое-то соединение. Механика фиксирует, сколько всего оперативной памяти мы на данный момент занимаем всеми рабочими процессами. Например, сейчас мы занимаем 10 гигабайт, а общее ограничение по кластеру у нас 11 гигабайт. Параллельно механика для каждого вызова считает, сколько памяти он займет – раз в две секунды она эту информацию обновляет. И в какой-то момент может оказаться, что вызов займет 3, 4, 5, 6 гигабайт. Такое бывает – либо программист ошибся, либо пользователь не наложил правильные отборы – у него выводится, что попало, и на это тратятся гигабайты оперативной памяти. Система проверяет, не превышает ли изначальный объем оперативной памяти на весь кластер, плюс память на этот вызов сумму максимального объема памяти на кластер и максимального расхода памяти на вызов. Если превышает, то этот сеанс будет завершен. Не rphost, как в настройках кластера 1С, где мы просто завершаем rphost при совпадении ситуации, когда он выбрал лимит оперативной памяти. Здесь будет завершен конкретный сеанс пользователя, т.е. конкретный главный бухгалтер получит ошибку «Сеанс завершен администратором». Это очень удобно, чтобы протестировать, где у вас программист написал неправильный отчет. Один и тот же пользователь будет постоянно жаловаться на то, что этот отчет никогда не формируется. При этом остальные пользователи даже не заметят, что что-то произошло, и система продолжит стабильно работать.
Еще одна «сладкая» настройка для стабильности и спокойного сна администраторов – это «Объем памяти рабочих процессов, до которого сервер считается производительным». Здесь 0 – это настоящий 0, т. е. мы этот объем памяти вообще не контролируем. Здесь можно указать тот лимит памяти, при котором выборы механикой сервера, куда назначать сеанс, закончатся неудачей для сервера, если он уже израсходовал столько оперативной памяти, сколько мы ему указали. Например, мы, согласно своему опыту, считаем, что этот сервер не может быть работоспособен, если он уже израсходовал 40 гигабайт оперативной памяти. И, если вы сюда это указали, то, несмотря ни на какие проверочные тесты, в которых он показывает механике сервера, что он быстрый и готовый, на него сеансы назначаться не будут, если он этот лимит превысил.
Следующие настройки, которые почему-то все любят менять, – это «Количество информационных баз на процесс» и «Количество соединений на процесс» (не путать с количеством сеансов – именно количество соединений на процесс). В принципе, эти настройки уже нормально отрегулированы по умолчанию. Rphost давным-давно многопоточный, 64-битный и обслуживать 128 сеансов либо 8 баз данных не является проблемой. При этом «Количество соединений на процесс» можно менять и при ПРОФ лицензии.
Могу еще сказать, что никакие настройки кластера или сервера 1С не заставят вашу 1С работать быстрее. Все настройки необходимы исключительно для того, чтобы система в целом работала стабильнее, а не быстрее. Быстрее – это вопрос к программисту, пусть код переписывает. Либо к DBA – пусть сервер базы данных настраивает. Все настройки сервера 1С касаются только стабильности и отказоустойчивости. Никакая настройка не действует на скорость. Сервер 1С всегда пытается выдать максимальную скорость математики. Он ничего не скрывает, не работает вполсилы, он просто старается этими настройками сделать крепче сон администратора, и чтобы у него не сдавали нервы.
Настройка инфраструктуры с сервером программного лицензирования 1С
Следующий момент – это сервер программного лицензирования. До сих пор на практике мы встречаемся с высказываниями: «Ой-ой, только не программная лицензия, они все слетают, а весь мир виртуальный, 1С это тоже не обошло».
Да, мы все давно ушли в виртуальность. Да, известная проблема, что если виртуалка по отношению к своим ресурсам динамическая, то программная лицензия будет «слетать». Чтобы этого избежать, и был сделан сервер программного лицензирования.
Первая его особенность – он не требует себе серверные лицензии. Фактически, это полностью бесплатная вещь. Просто поставьте сервер 1С и настройте «Требования назначения».
Вторая его особенность, которую мы вывели на практике, – не злоупотребляйте тем, чтобы сервер программного лицензирования выдавал серверные лицензии. Пусть он выдает только клиентские лицензии. Почему? Если у вас высоконагруженная система, более 1000 пользователей, и вы сделаете так, что у вас сервер программного лицензирования серверу 1С выдает его серверную лицензию, то при каждом серверном вызове этих 1000 пользователей, сервер 1С будет запрашивать у сервера программного лицензирования свою лицензию, проверять есть или нет. В итоге, сервер программного лицензирования не справится с нагрузкой – и сеть «ляжет», и процессоры «лягут», и вся система хором «ляжет». Поэтому нагружать сервер лицензирования программными серверными лицензиями не надо. А клиентские лицензии он выдает очень успешно, поскольку они выдаются гораздо реже. 1000 штук – не проблема.
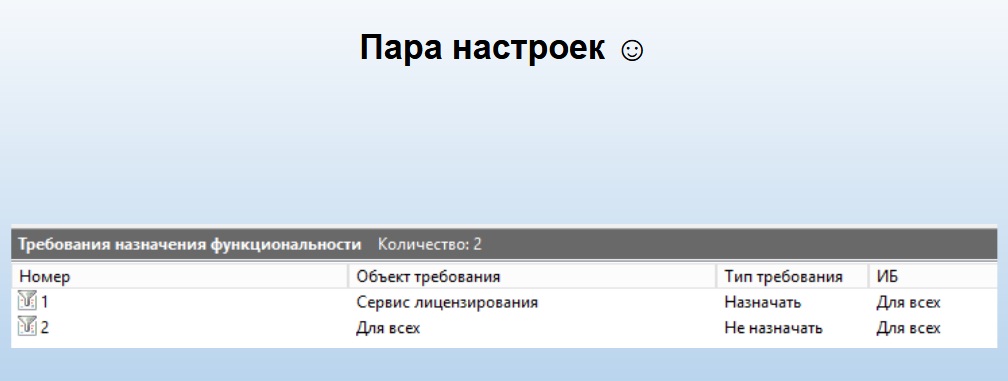
Настроить сервер лицензирования – это всего лишь пара «Требований назначения функциональности».
Что первое мы должны указать? Раз у него собственной лицензии нет, мы должны для него указать, что этот сервер для всех сервисов «Не назначать». Чтобы, когда механика сервера делала выбор, куда ей назначить данное соединение или сервер, она ни в коем случае не назначила его на сервер лицензирования (поскольку для клиентского соединения нужна программная лицензия, а у сервера лицензирования ее нет). Если вы так не настроите, механика сервера в какой-то момент выберет его из-за высокой производительности, запустит туда бухгалтера, и он получит ошибку «Отсутствует программная лицензия сервера».
Вторая настройка, которую нужно сделать в «Требовании назначения функциональности» – это, наоборот, назначить ему и только ему сервис лицензирования. В кластере в идеале может быть только один сервер лицензирования. Можете сделать и два с разными приоритетами, но особого смысла в этом нет, поскольку программная лицензия – это не HASP, можно и 300 файлов положить, и ничего страшного не случится.
Единственный момент, который нужно соблюсти, когда вы в свою инфраструктуру встраиваете сервер лицензирования – это стабильное «железо».
- Это может быть локальная машина.
- Либо это может быть виртуалка, но тогда у нее должны быть заданы полностью статические параметры.
- Либо у вас может быть настроен отказоустойчивый кластер виртуальных машин, где виртуалки переезжают с одного хоста на другой. В этом случае на этих хостах должно быть все одинаково, вплоть до модели процессора.
Если сервер лицензирования переедет на другую модель процессора, то вы, несмотря на то, что в параметрах виртуалки все вроде бы статично, получите ошибку программного лицензирования.
Во всех последних версиях платформы: 8.3.10 и 8.3.9 (начиная с версии 2170) есть защитный механизм, который немного спасает в таких случаях. Если лицензия сбросилась из-за смены железа на сервере лицензирования, 1С еще сутки будет работать. Ровно через сутки она выдаст ошибку, что время вышло и теперь сервер нужно перелицензировать. После переактивации пин-кода сервера для новых параметров системы можно счастливо пользоваться 1С дальше.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 COMMUNITY. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Мне кажется, или запрашивать лицензию на каждый серверный вызов — это довольно странное поведение? Он точно так делает?
Не очень понятно, автор опровергает официальную документацию Клиент-серверный вариант. Руководство
администратора или перепечатывает ее ?
Таким образом, можно вывести следующую формулу, связывающую количество центральных серверов в кластере
и уровень отказоустойчивости: Количество центральных серверов = Уровень отказоустойчивости+1.
© документация 1С
Про 0 в настройках ограничения памяти много букв, но нет букв про настройку «-1» это как раз и есть отсутствие ограничений по памяти
Максимальный объем памяти, занимаемой рабочими процессами и Безопасный расход памяти за один вызов лучше как раз в «-1» выставлять
Ну и каламбур напоследок:
никакие настройки кластера или сервера 1С не заставят вашу 1С работать быстрее
а вот никакие настройки кластера или сервера 1С заставят вашу 1С работать медленнее
это уж точно — 100%
(1)Я бы рекомендовал писать например как Пушкин — Ума холодных наблюдений / И сердца горестных замет — автора.
Но никак не рекомендация для последователей
А всем остальным не верить слепо всему что здесь написано
Коллеги, кто-нибудь может поделится опытом. Насколько в настоящий момент отказоустойчив отказоустойчивый кластер серверов 1С?
Если есть необходимость обеспечить работу 500-1000 пользователей с порядка 100 ИБ с разными функциональными задачами, то можно ли полагаться на решение — один кластер серверов 1С с N серверами. Или стоит все же разделить ИБ на группы и для каждой группы организовать кластер серверов?
(2)
Максимальный объем памяти, занимаемой рабочими процессами и Безопасный расход памяти за один вызов лучше как раз в «-1» выставлять
И вы положите на лопатки сервер 1С в самый неподходящий момент.
Напишите ваше сообщение
(1)
К сожалению это поведение повторяется и на последних платформах, я не могу за разработчиков платформы 1С ответить — нормальное это поведение или нет.
Но то что расположение серверных лицензий на отдельном сервере лицензировании приводит к неработоспособности кластера при высоких нагрузках — это печальный факт.
Напишите ваше сообщение
(2)
администратора или перепечатывает ее ?
Ни в коем случае! Я делюсь реальным опытом, а не просто цитирую ИТС.
(4) Какой режим отказоустойчивости предполагается? Система 24/7 или как?
Базы достаточно изолированы по бизнесу? Т.е. можно ли без последствий отключить доступ к группе баз на время или они все связаны друг с другом?
Напишите ваше сообщение
(2)
Вы точно не путаете Сервер 1С и Сервер БД?
Настройки Сервера 1С по умолчанию обеспечивают отличный уровень скорости.
Дополнение
Безопасный расход памяти за один вызов связан с Максимальный объем памяти, занимаемой рабочими процессами, сеанс будет прерван если было превышено оба предела, а не только связан Безопасный расход памяти за один вызов
(8) Есть несколько подразделений, в каждом эксплуатируется по 4 ИС с разными функциональными задачами. В 3-х из них есть периоды, в которые производится массовое формирование документоврасчетов. Периоды эти совпадают и по дням и по времени (практически) во всех подразделениях.
Я точно понимаю, что SQL серверов будет несколько, т.к. ни одна железка не вытянет такую нагрузку, а вот как организовать серверы 1С, исходя не из теоретических возможностей платформы, а из практического опыта коллег.
(11)
Я бы тогда сделал так:
На каждое подразделение создаём свой кластер с их базами.
Тогда при необходимости перезапустить rmngr, а такое может случится, то рисков задеть другое подразделение нет
Серверов 1С сделал бы 2, оба центральные с распределением нагрузки по производительности и уровнем отказоустойчивости = 0
По лицензиям — тоже надо порешать правильно, но тут много вариантов, поэтому нужно отталкиваться от того какого вида есть лицензии и какое количество + какая нагрузка на базы в пик и т.д.
Если нужна более подробная проработка инфраструктуры, то пишите в личку
(10)Да, всё верно.
Вот цитата из статьи «Система проверяет, не превышает ли изначальный объем оперативной памяти на весь кластер, плюс память на этот вызов сумму максимального объема памяти на кластер и максимального расхода памяти на вызов. Если превышает, то этот сеанс будет завершен.»
Вроде то же самое, но другими словами)
(5) с чего бы я интересно положу сервер 1С ?
при таких настройках серверу 1С будет доступна вся память на сервере не более того,
даже если он ее всю займет система будет дико свопить но не устанет
а с какой целью оставлять 20 % ?
(7) я к тому что в документации другое мнение насчет кластера чем у вас
Таким образом, можно вывести следующую формулу, связывающую количество центральных серверов в кластере
и уровень отказоустойчивости: Количество центральных серверов = Уровень отказоустойчивости+1.
© документация 1С
(9) Настройки Сервера 1С по умолчанию обеспечивают отличный уровень скорости при неограниченных ресурсах сервера
т.к. они в принципе настраивают ограничения по памяти
В таком варианте и сервер БД не надо настраивать — там тоже все по максимуму по умолчанию (не касается Postgres)
а в реальной жизни — 100 пудняк надо настраивать
(12)
вообще не предполагает отказоустойчивости
(17)всё сильно зависит от задачи. 1 тоже не равно отказоустойчивость при неправильно спланированной структуре ит
(15)а в реальной жизни немного по другому)
Если у вас 2 центральный и уровень =1, то при выходе из строя одного сервера у вас уже не кластер.
(14)А Вы рискните и попробуйте поставить -1 на реально нагруженной с системе, где тысячи сеансов и /или сотни баз…
Прекрасная статья, одно из самых подробных встреченных описаний )) Вопрос — это реальный опыт? Сколько примерно серверов (баз данных и приложений), баз, пользователей? Хотя бы примерное описание. Спасибо.
(21)Спасибо!
Да, опыт реальный.
Есть несколько систем.
В одной 400+ баз, 600+ сеансов, 4 сервера в кластере, внутри серверов по 10 кластеров 1с
В другой 20 баз, 2000+ сеансов, 12 серверов в 4 кластерах
Ещё в одной, 1 база, пока 300 сеансов, но будет 1000, тут пока 2 сервера в кластере
Это те инсталяции что могу разглашать хотя бы в цифрах)
(20) но и смысла оставлять там 20% незагруженной памяти согласитесь смысла нет
Ох как внезапно некоторые утверждения расходятся с ИТС.
При уровне «один» вам нужно уже как минимум три сервера
что это? Просто рекомендация, а не требование?
Несмотря на то, что эта настройка относится к параметрам рабочего сервера 1С, это – тот объем памяти, который могут занимать все рабочие процессы кластера 1С
т.е. память всех серверов в кластере? Что разработчики по этому поводу говорят? Может это ошибка? Задавали вопрос? Дайте ссылку на партнёрку.
Есть ещё вопросы по реплициремым сервисам между ЦС при уровне отказа=1.
В 8.3.12 поведение мне кажется отличается от 8.3.9 и 8.3.10. Сам ещё в процессе теста, не готов нечего утверждать, но стоит всем обратить внимание, что ситуация может отличаться на актуальных релизах
(19) Я просто ставлю под некоторое сомнения
потому что на своем опыте знаю и в документации буквами по белому написано что это не так.
Возможно что-то поменялось в этом мире ,тогда меня поправят знатоки
(23)не соглашусь. Смысл есть, так как именно такой запас не заставит систему свопить, что крайне негативно может сказаться на работе 1С
Поймите — настройка сервера и кластера 1С преследуют цель СТАБИЛЬНОЙ работы, поэтому чем-то придётся жертвовать ради стабильности. Где-то это будут запасы ресурсов, где-то удаление сессии по лимиту памяти, где-то выключение рабочего процесса опять же по лимиту и т.д.
Если цель — максимальная утилизация ресурсов, тогда можно и -1 везде поставить, только о стабильности в этом случае останется только мечтать
Напишите ваше сообщение
(24)
что это? Просто рекомендация, а не требование?
— рекомендация.
(24)
— не задавал так как нет смысла, это поведение описано на ИТС и не является ошибкой, я просто обратил на это внимание, так как с чисто интерфейсной точки зрения возникает путаница
(25)
На счёт этой фразы, да, тут я некорректно выразился, к сожалению. Тут немного смешалась рекомендация и требования.
Уровень отказоустойчивости определяет минимальное кол-во ЦС, при которых кластер считается работоспособным.
Фраза в докладе относится к уровню = 2
Спасибо!
(22)
Очень важно, каков режим эксплуатации ИС и количество «ключевых» объектов в базах.
Могут 200 человек вводить заявки сервис-деска и в этом случае нагрузка будет очень вялой, а может один человек запускать пакетный расчет счетов на оплату в биллинговой системе на 300 тыс. абонентов и это будет очень большая нагрузка на серверы.
Например, кейс:
30 БД ИС ЗУП , среднее количество сотрудников в каждой — 1000. Расчет ЗП производится практически в одно и тоже время. Количество расчетчиков в каждой ИС ~ 10.
Какое количество серверов (особенно SQL серверов) с грубой оценкой ОЗУ и ядер процессора Вам представляется достаточным?
(29)Пальцем в небо не гадаю)
Нужно производить замеры и только тогда формировать инфраструктуру.
(29)
— полностью согласен!
(27) «Максимальный объем памяти рабочих процессов»
Максимальный объем памяти (в байтах), доступный всем рабочим процессам кластера на данном рабочем сервере.
Каждый рабочий процесс кластера определяет объем памяти, занимаемой всеми рабочими процессами кластера на этом рабочем сервере…….. и т.д
Вот поэтому и возник вопрос. Везде и всегда говорится, что это память отдельного сервера в кластере, а не память всех серверов в кластере.
Можете дать ссылку, где «это описано на ИТС»?
(31) Кроме того, возникает вопрос, если на уровне одного рабочего сервера задается настройка для кластера в целом, то что будет, если задать разные значения этой настройки для разных рабочих серверов одного и того же кластера? Какая из них будет более приоритетной?
Скорее всего здесь все таки неточность и настройка «Максимальный объем памяти рабочих процессов» все таки относится к рабочим процессам одного рабочего сервера.
(
(32) да, вы правы, тут неточность.
Видимо во время выступления неточно выразился.
Делал акцент на то что это совокупная память всех рабочих прцессов рабочего сервера.
Ещё раз спасибо за внимательность!
Добрый день. можно уточнить фразу в шапке?
В платформе 8.3.9 произошло долгожданное событие – кластер серверов 1С заработал. С того момента, когда о нем объявили в 8.3.6, до момента, когда он в 8.3.9, наконец, заработал, прошло много лет
я правильно понимаю, что если настроен 1 центральный сервер на одной тачке и рабочий сервер на 2ой тачке, то в случае падения центрального сервера все пользователи «переедут» на рабочий сервер и для них всё будет выглядеть комфортно, но новые пользователи подключиться к базе не смогут?
Очень умиляет, что 1С в погоне (пусть и очень оправданной) не разграничивает лицензирование серверов на Простые и Корп, а только парой строк в лиц. соглашении — что если у вас не Корп, то вот эти настройки трогать вам нельзя, хотя они доступны и работают.
Это называется доверие и уважение клиентов, которые подняли свой бизнес вместе с 1с от базовой до корп версии. Сейчас оно несколько не современно выглядит, время такое.
(34)Нет, не правильно. В случае если центральный сервер 1 и он упал, то вся работа с 1С прекращается у всех. И зайти тоже никто не сможет
Напишите ваше сообщение
(35)Такой халявы остался примерно год, в одной из новых версий платформы (пока точно не известно какой) ограничения будут работать на техническом уровне
(37) то есть, центральных серверов может быть несколько ?
(39)Да
Вы лучше напишите какую задачу хотите решить?
(40) задача очень проста — реализовать отказоустойчивый сервер 1С.
(41)Эта задача очень не проста)
Не буду пересказывать статью, в ней по идее прям инструкция по настройке.
Пробуйте и потом спрашивайте, если что-то не получится
(42) так и думал) вы спросили — я ответил)
(38) То есть они вынесут доступность настроек «на ключ» и наконец починят балансировщик нагрузки, самоотчистку кешей у серверов в останове, управление лицензиям и кучу проблем с формуа разработчиков? 🙂 или , как вы думаете, это будет просто фига за отдельные бабки?
(44) Вынесут, по крайней мере такие планы озвучивались на партнёрском семинаре.
Починить всё невозможно и все это понимают.
Я не думаю что будут прям отдельные версии корп-платформы с меньшим количеством ошибок)
Опять же, это моё мнение, и оно может сильно отличаться от мнения разработчиков платформы
Мне очень стыдно за мою узкую 1сность, в теории и в лабораторных условиях (стенд) я делал и тестировал отказоустойчивый кластер.
2 виртуальные машины под серверы 1С, 1 виртуалка — клиент, 1 виртуалка СУБД.
Потестировал, убедился, забыл.
Но при этом убей не знаю как быть с сервером СУБД в том случае, если нужно разнести ноды отказоустойчивого кластера по разным датацентрам. 2 СУБД? На каждом ЦС указывать адрес «своей» СУБД? а как СУБД будут ли они синхронны? Не будет ли потерь данных, если, например, вырубить одну ноду по питанию?
Очень интересует инфа и по MS SQL, и по PG.
С СУБД всё намного сложнее.
1С не умеет работать с несколькими серверами субд для одной базы у указать для каждого ЦС свой адрес базы бд невозможно, поэтому отказоустойчивость субд отдана на откуп самой субд.
В случае с ms это always on
В случае с pg это синхронная/асинхронная (в зависимости от задачи) репликация + система переключения в случае отказа мастера
При вырубании ноды потеряются незавершенные транзакции в случае синхронных реплик, в случае асинхронных есть риск потери помимо незавершённых ещё некоторого количества транзакций.
На практике в 99% случаев почти на любых высоконагруженных системах хватает уровня «ноль». Главное, грамотно настроить соотношение центральных и рабочих серверов 1С.
Если поставить 0, то выход из строя центрального сервера, остановит работу всего кластера.
Так зачем же 0 оставлять?
Начало статьи полностью противоречит ИТС инструкциям и картинкам.
(48) Вы полностью неправы.
Перечитайте ИТС, а лучше попытайтесь настроить и протестировать работу кластеров 1С с уровнем 0, но 2-мя центральными серверами.
(49) Вполне возможно, я и рад буду если не прав.
А в чем тогда смысл «отказоустойчивости», если по факту она как бы не вулючается — уровень отказоустойчивости = 0.
Но при этом по описываемой вами схеме юзер все равно может переключиться на другой центральный сервер.
Тут я запутался.
(50) Сможет переключиться, но только перезапустив 1С, это единственный минус этой схемы.
(51) Если так, то вполне приемлимо.
Скажите, а можно ли рассматривать в самом простом случае схему из 2 центральных серверов как «рабочий» вариант?
(52)Да, это как раз самый рабочий вариант
(53) А накладные расходы в этом случае насколько существенны? Если оба сервера центральных, то как я понимаю тратятся ресурсы на их синхронизацию.
(54) Там совсем немного, главное это обеспечить 1Гбит-сеть между серверами
Пытаемся, пока без особых успехов увеличить быстродействие сервера 1С.
Сейчас используем 1С:Предприятие 8.3 (8.3.14.1565) 64бит на виртуалке
Intel® Xeon® CPU E5-2690 v2 @ 3.00GHz 12 ядер 32 гб памяти. Не менее 10Гб памяти в пике нагрузки остается свободной. БД Oracle 11
Параллельно работе пользователей крутятся файловые обмены с примерно 200 базами. Обмены идут в 5 потоков, запуск через каждые 5 минут, где то за 3 — 4 минуты все 200 баз обмениваются. И всё бы хорошо, но периодически (каких то четких периодов нет, то через 5 минут идет залипание, то через 20 минут) 1С залипает и тогда пользователи (пользователей не больше 30) получают неадекватно долгий (десятки секунд) отклик системы и обмены тоже уже не за 4 минуты, а могут и 10 минут работать. Если эти обмены отключить, то залипаний нет.
Пробовали устанавливать виртуалку на SSD — видимых улучшений нет. Нагрузка на БД не значительная. В основном, судя по консоли ММС идет время серверных вызовов.
Еще пробовали плодить рабочие процессы, но механизм не рабочий. При заходе новых пользователей рабочий процесс rphost создается, а вот при старте фонового задания — нет. В итоге фоновые задания, которые не влезли в процесс отваливаются с ошибкой.
Так же, не знаю зачем ставили галку — менеджер под каждый сервис. Тоже глюк. фоновые задания после перезагрузки сервера перестали выполняться по расписанию — иногда запускаются, но в основном нет.
Еще пробовал ставить ограничение потребления ресурсов на процессорное время. По началу вроде заработало. Обмены стали идти медленнее, залипания пропали. Но после перезагрузки сервера 1С из за этого ограничения пользователи не могли зайти в программу.
Нагрузка на процессор — в общем 20 — 30% но нагрузка на ядра распределена очень неравномерно, какие то ядра вообще почти простаивают. Гилев тест показывает 10 — 12.
Кто то может что то посоветовать? Где еще этот ОдинЭс подкрутить?
Доброго дня!
Имеется дилетантский вопрос на который не могу найти конкретного ответа:
Вот падает у нас первый центральный сервер, как на сетевом уровне клиент при переподключении поймёт как ему подключиться к второму центральному серверу? Всё через порты?
Здравствуйте, вопрос возможно не совсем по этой теме, но все же:
возможно ли Имя кластера указать как base.mydomen.ru ?
чтобы в хосте на удаленных компьютерах не прописывать ip | имя кластера…
(57)если 2 центральных, то у клиента прописывается 2 сервера через запятую в параметрах подключения к базе.
(58)для работы удаленно правильно использовать http-публикацию 1С и тогда никаких проблем.
Напрямую подключиться к базе без бубна можно только внутри локалки
Добрый день!
Вопрос по лицензированию.
Допустим у нас есть 3 сервера в кластере:
srv1
srv2
srv3
srv1 и srv2 Центральные сервера на отдельных машина с серверными лицензиями
srv3 Рабочий сервер
Нужна ли srv3 серверная лицензия?
(61)да
Добрый день.
Уточните пожалуйста
«При уровне «один» вам нужно уже как минимум три сервера, поскольку вы уже настраиваете кластер, а он по умолчанию отказоустойчивый, и при выходе одного центрального сервера два должны остаться в работе. Но если из строя выйдет еще один центральный сервер – кластер откажет в соединении.»
Почему три сервера ? Если всего два центральных сервера — разве кластер будет неработоспособен ? Да, он будет уже не отказоустойчив, но работоспособен и сессии переедут на второй. Верно ?
(63)
— верно!