Содержание:
- Основные техники регистрации изменений.
- Отметка модификации в таблице данных (changetimestamp).
- Отслеживание изменений с данными (changedatacapture).
- Отслеживание изменений без данных (changetracking + планы обмена).
- Планы обмена.
- Физическая структура.
- Таблица плана обмена.
- Таблицы регистрации изменений.
- Индексы таблиц регистрации изменений.
- Операции с анализом SQL кода.
- Регистрация изменений.
- Просмотр изменений.
- Выгрузка изменений.
- Удаление изменений.
- Загрузка изменений.
- Физическая структура.
- Проблемы блокировки.
- Основные конкуренты: регистратор, экспортёр, терминатор, импортёр.
- Выгрузка изменений.
- Удаление изменений.
- Загрузка изменений с одновременной регистрацией на заинтересованные узлы обмена.
- Управление регистрацией изменений.
- Планы обмена: состояние записи об изменении.
- Альтернатива планам обмена: версионирование изменений (общепринятый классический подход).
- Проблемы сохранения целостности данных.
- Невозможность целостного чтения данных связанных объектов метаданных.
- Порционная выгрузка данных, как метод оптимизации.
- Репликация транзакций, как решение проблемы целостности данных.
- Регистр сведений для регистрации изменений с версионированием.
- Получение и сохранение идентификатора транзакции (sys.dm_tran_current_transaction).
- Проблема сохранения целостности данных при транспортировке сообщений обмена.
- Негарантированная доставка (квитирование).
- Гарантированная доставка.
Основные техники регистрации изменений
Существует много различных систем обмена данными, но сегодня я расскажу о тех из них, которые ориентированы на предварительную регистрацию изменений и последующую синхронную выгрузку данных.
В мире существуют разные методики регистрации изменений:
- Одна из них – это когда в основную таблицу добавляется отметка модификации в таблице данных (change timestamp) – какое-то поле с отметкой версии. Обычно это «метка времени» timestamp. При каждом изменении записи в это поле пишется текущий номер версии или отметка времени. Таким образом, мы можем всегда получить те записи, которые были изменены после интересующего нас момента времени. Однако этот механизм имеет один недостаток — если мы удаляем запись, то теряем информацию о её изменении (удалении). Примером использования этого механизма на момент подготовки данного материала является сервис «Мой склад». Он использует его для интеграции с внешними системами.
- Хорошим примером отслеживания изменений с данными (change data capture) является Microsoft SQL-сервер. Он имеет подсистему, которая регистрирует изменения, считывая их из журнала транзакций. В данном случае каждое изменение регистрируется в отдельной таблице регистрации изменений, сохраняя полностью значения всех полей старой версии записи. Таким образом можно не только получить актуальную версию, старые версии, но и отследить историю всех изменений в прошлом.
- Ну и наконец третий распространённый вариант, который в том числе используется 1С — это отслеживание изменений без данных (change tracking + планы обмена). Этот механизм является способом оптимизации хранения огромного количества данных об изменениях, которые мы получаем во втором вышеописанном случае. Далее мы рассмотрим именно этот механизм подробнее.
Три конкурирующие роли
В самом начале я хочу, чтобы вы запомнили очень простую мысль: для таких систем ключевое слово – это регистрация изменений. Всегда, когда речь идет о регистрации изменений, мы имеем три конкурирующие роли. В каком-то смысле, это – история про лебедя, рака и щуку.
- Первая роль – регистратор изменений. Это какой-то кусок кода, который регистрирует изменения и добавляет новые записи об изменениях в таблицу (insert).
- Вторая роль – экспортер изменений. Это некий кусок кода, который эти изменения забирает, куда-то выгружает и фиксирует, что выгрузил (select + update).
- И всегда есть третья роль, которую я назвал «терминатор изменений». Если всё время регистрировать изменения, то таблицы для их регистрации будут разрастаться, вызывая в конечном итоге деградацию производительности системы.Их надо периодически чистить (delete).
Есть еще четвертый случай, но он очень редкий. Это импортер. Он является конкурентом с точки зрения системы регистрации изменений и обмена данными только в том случае, когда ему необходимо зарегистрировать импортированные изменения для передачи в другие узлы-получатели данных. Текущий узел используется как транзитный.
Три основные роли всегда конкурируют между собой за ресурсы и за записи таблицы регистрации изменений.
Физическая структура плана обмена
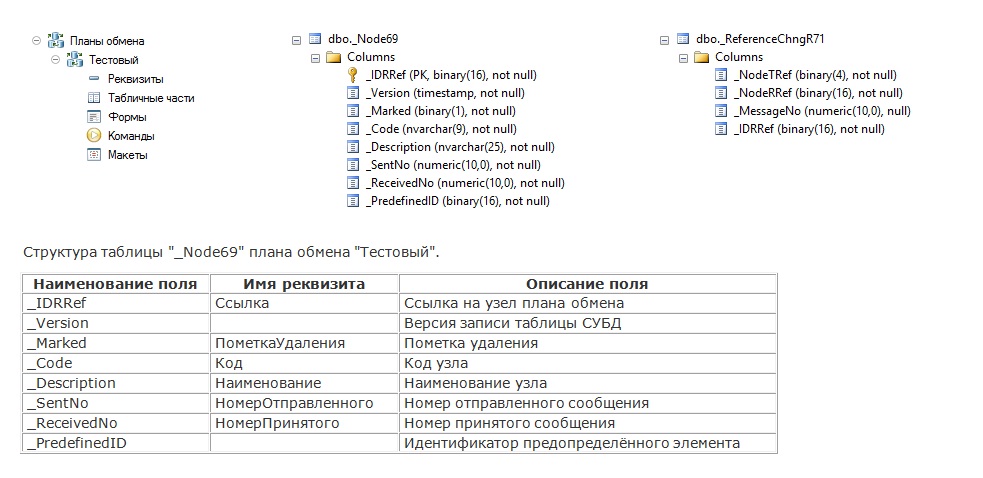
При создании плана обмена в конфигураторе, в СУБД для него создается таблица с полями, которые показаны на слайде – это скриншот структуры таблицы плана обмена из SQL-сервера. На слайде показано, что это за поля и для чего они используются.
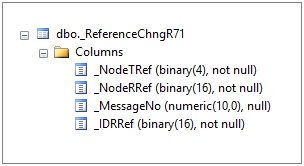
А это – структура таблицы регистрации изменений. В ней хранятся ссылки на объекты, которые изменились в базе. Такая таблица создается на каждый объект метаданных, входящий в план обмена. Я специально взял самый простой случай. Понятно, что бывают дополнительные реквизиты, табличные части для настроек и т.д, но для простоты восприятия они убраны.
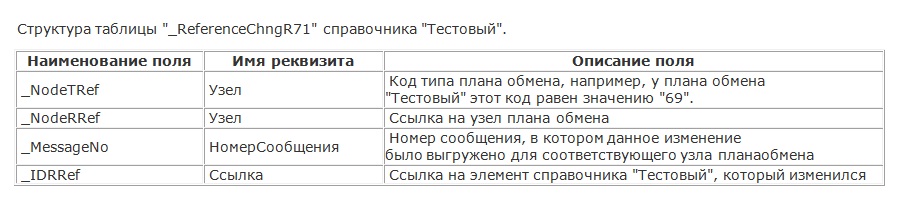
Здесь приведено описание основных полей таблицы регистрации изменений.
Самая ключевая таблица, на которой чаще всего возникают проблемы с блокировками и т.д. – это таблица регистрации изменений. Вы помните, что за право сделать запись в эту таблицу конкурируют три роли.

Для таблицы регистраций изменений создаются два индекса – кластерный и обычный.
Кластерный индекс нужен для того, чтобы работать с конкретными отдельно взятыми объектами, записями. Поля этого индекса следующие:
- Поскольку каждый индекс создается по узлу, то поля «_NodeTRef» и «_NodeRRef» определяют, какой это узел и какого плана обмена. «_NodeTRef» определяет план обмена, а «_NodeRRef» узел этого плана обмена.
- В индекс включены оба этих поля, потому что многие операции, которые используются компонентом плана обмена, всегда делаются в привязке к кому-то узлу.
- Поле «_IDRRef» – это, в данном случае, ссылка на объект. Я для примера взял справочник, который является ссылочным типом данных, но здесь может быть больше полей, если речь идет о регистрах сведений, накоплений и т.д. — табличных типах данных.
Обычный уникальный индекс отличается от кластерного только тем, что к полям, которые мы уже рассмотрели, добавляется поле «_MessageNo», которое позволяет работать в контексте номера сообщения. Порядок следования полей концептуально иной. Мы видим, что сначала по индексу идет узел, потом номер сообщения, а потом уже объекты. Это интересный момент – так в планы обмена интегрируется инфраструктура сообщений.
Операции с анализом SQL кода
Регистрация изменений

Рассмотрим основные операции. Повторюсь, есть три программных роли. Основная роль – это регистрация изменений. На слайде представлен упрощенный для понимания код. Для менеджера ПланыОбмена, вызываем метод ЗарегистрироватьИзменения(), передаем в параметры Узел и Ссылку (в данном случае регистрируется изменение по элементу справочника «Номенклатура»).
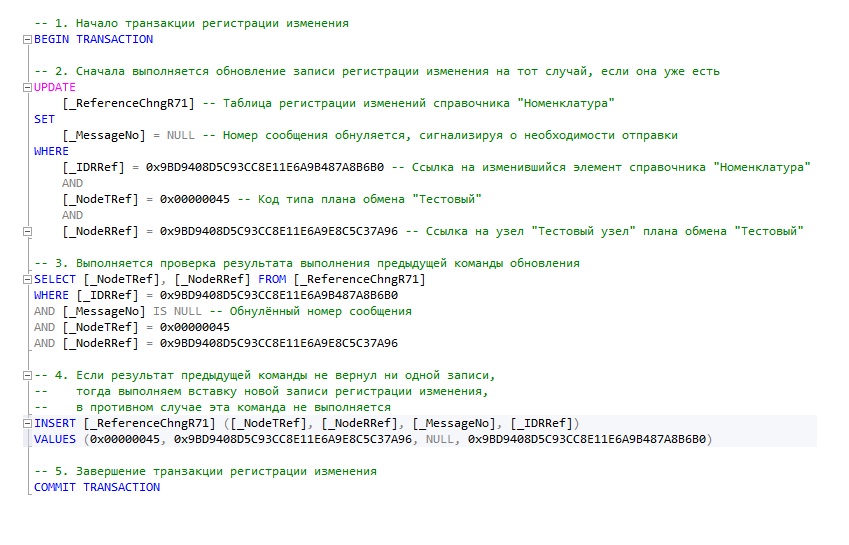
Как производится регистрация изменений на уровне SQL-кода?
- Как только мы вызвали ЗарегистрироватьИзменения(), начинается транзакция, где первой операцией выполняется UPDATE. Как можно увидеть, мы в таблице регистрации изменений меняем номер сообщения («_MessageNo»), устанавливаем ему значение NULL. Обратите внимание, что 1С сразу пытается зарегистрировать этот объект (делает в этой таблице UPDATE), а в понимании 1С у объекта, зарегистрированного к выгрузке, значение «_MessageNo» равно NULL.
- Следующей операцией производится проверка – есть ли там вообще этот объект (прошел ли UPDATE), а для этого выполняется SELECT. Обратите внимание, что не используются условия типа IF @@ROWCOUNT=0, просто с помощью SELECT проверяется, есть ли там что-нибудь. В условии можно увидеть «_IDRRef», он здесь потому, что регистрацию я вначале делал по конкретной ссылке.
- Если SELECT вызывающему коду возвращает, что ничего не зарегистрировалось, то тут же выполняется INSERT. Можно увидеть, что в параметры передается NULL, который будет присваиваться полю «_MessageNo». Если отработает UPDATE, то этого INSERT может и не быть.
В любом случае, запросы UPDATE и SELECT будут выполнены всегда. Кроме этого следует отметить, что транзакция выполняется с уровнем изоляции определённой на уровне СУБД по умолчанию, для SQL Server это Read Commited. Если это версия 1С, которая использует управляемый режим блокировок, то это Read Commited Snapshot.
Я сначала подумал – зачем так сделано? Почему бы сначала не сделать SELECT, а потом решить – делать нам UPDATE или INSERT? Разница есть потому, что когда мы в транзакции сделаем SELECT, а потом захотим сделать что-то еще, другая транзакция в момент сразу же после нашего SELECT’а может успеть изменить запись. Это может нарушить логику регистрации изменений. Поэтому сразу делается UPDATE, что обеспечивает эксклюзивную блокировку записи по условиям предиката WHERE. Таким образом обеспечивается безопасность логики последующих команд SELECT и INSERT.
Момент регистрации изменений
Момент автоматической регистрации изменений:
1. Начало транзакции записи документа.
2. ПередЗаписью.
3. ПередЗаписью (подписка на событие).
4. ПриЗаписи.
5. ПриЗаписи (подписка на событие).
6. ОбработкаПроведения.
7. ОбработкаПроведения (подписка на событие).
8. Регистрация изменения объекта во всех планах обмена, в состав которых он входит, а также для всех узлов этих планов обмена.
9. Фиксация транзакции записи документа.
Теперь давайте разберемся, в какой момент происходит регистрация изменений.
- Если у нас автоматическая регистрация изменений, то это всегда происходит в конце транзакции записи объекта в базу данных перед фиксацией транзакции.
- Если у нас ручная регистрация, то мы вольны сделать это практически в любом месте кода, даже не в транзакции записи объекта.
Чтобы вы поняли важность упрощения кода по регистрации изменений, я составил перечень, показывающий, в какой момент какое событие происходит. Дело в том, что при регистрации изменений объектов программисты 1С очень часто пишут длинные, сложные условия – регистрировать, не регистрировать, почему регистрировать, куда регистрировать. Этот перечень наглядно показывает, что чем сложнее код регистрации изменений, тем дольше будет транзакция записи (или проведения документа), а это повлияет на поведение всей системы, связанное с блокировками и работой пользователей.
Конечно, бывает так, что код для регистрации изменений действительно должен быть сложный, но иногда в целях оптимизации имеет смысл убрать этот код отсюда куда-нибудь в другое место. Пусть какая-то другая подсистема занимается регистрацией изменений, а документы проводятся быстро.
Чтение изменений
Чтение изменений из таблиц регистрации изменений.
Запрос=НовыйЗапрос();
Запрос.Текст ="ВЫБРАТЬ * ИЗ Справочник.Номенклатура.Изменения";
SELECT * FROM [_ReferenceChngR71];
Следующая роль – это чтение изменений. Иногда бывает нужно просто прочитать изменения и посмотреть, что там и как. Для каждого объекта, включенного в план обмена, есть виртуальная таблица изменений, откуда запросом можно эти изменения выбрать.
На уровне SQL эта операция вызывается очень просто, через обычный SELECT.
Иногда, когда оптимизируют обмены, выборку изменений делают не полностью по узлу, а точечно по ссылкам. Изменения сначала получают через запрос, потом их как-то порционируют, а потом делают ПланыОбмена.ВыбратьИзменения(), куда в третий параметр передают массив ссылок , чтобы выбрать только эти изменения и их выгрузить.
Удаление изменений

Третья программная роль – удаление, когда мы чистим все эти регистрации. Вариантов того, что можно передавать вторым параметром – много (это, по сути, фильтры). По факту, ничего особенного тут нет, просто параметр WHERE все время разный.
Условие по узлу есть всегда. Если второй параметр не указывать, таблица изменений по узлу будет очищена полностью.
При удалении по номеру сообщения из таблицы изменений будет удалено все, что было до этого сообщения. В SQL это делается с помощью условия:
_MessageNo <= номер сообщения.
При удалении по конкретной ссылке будут удалены изменения только этого объекта. На слайде вы можете видеть, какой будет WHERE в этом случае.
Все эти варианты работают достаточно быстро, потому что четко попадают в индекс. Я не просто так акцентировал ваше внимание на составе индексов для таблиц изменения. Эти индексы сильно связаны с теми операциями, которые можно делать через менеджер ПланыОбмена (методы ЗарегистрироватьИзменения, УдалитьРегистрациюИзменений, ВыбратьИзменения).
Выгрузка изменений в сообщение обмена

На слайде показан упрощенный код выгрузки изменений. В типовых конфигурациях все это может быть гораздо сложнее, там может быть порядка тысячи строк кода. Но есть основные шаги:
- Создаем запись сообщения – ПланыОбмена.СоздатьЗапись();
- Начинаем запись – ЗаписьСообщения.НачатьЗапись();
- Выбираем изменения – ПланыОбмена.ВыбратьИзменения();
- Записываем куда-то эти изменения, например, в «ЗаписьXML»;
- Закрываем запись сообщения – ЗаписьСообщения.ЗакончитьЗапись();
Здесь важно понимать, что «1С» очень тесно интегрировала инфраструктуру сообщений в планы обмена и интегрировала подсистему регистрации изменений и отправки сообщений таким образом, что без объекта «ЗаписьСообщения» мы не можем поменять номер сообщения в таблице регистрации изменений. Это можно сделать только через объект «ЗаписьСообщения».
Когда мы вызываем ЗаписьСообщения.НачатьЗапись(), в этот момент платформа считывает данные из плана обмена и устанавливает для объекта новое значение свойства «Номер сообщения» – оно всегда равно последнему отправленному номеру плюс единица.
А когда мы вызовем ЗаписьСообщения.ЗакончитьЗапись(), в этот момент зафиксируется, что этот конкретный номер сообщения был отправлен.
Какие возникают основные проблемы?
- Вызовы методов НачатьЗапись() и ЗакончитьЗапись() нужны только в случае, если мы хотим управлять номером записи. Больше нигде не используются.
- А ВыбратьИзменения() – это метод, с которым нужно быть очень осторожным, потому что обычно, когда возникают проблемы с производительностью обменов, именно из-за этого вызова возникают блокировки.
Давайте посмотрим, что происходит на уровне SQL-кода, когда мы вызываем метод ВыбратьИзменения().
Выборка изменений, анализ T-SQLкода.
Третий параметр <ФильтрВыборки> (необязательный): объект метаданных, массив ссылок или ссылка на один объект, набор записей (используется отбор набора). По умолчанию используется значение Неопределено – выбираются все изменения.
Когда мы вызываем метод ВыбратьИзменения(), у него есть необязательный третий параметр – ФильтрВыборки, позволяющий все это отфильтровать, т.е. выбрать не все сразу, а частями. Часто для оптимизации используется массив ссылок – например, можно отобрать 100 или 1000 ссылок.

Вот что происходит, когда мы вызываем ВыбратьИзменения(), в SQL. Понимание этого кода объясняет, почему происходят блокировки.
Начало транзакции по выборке изменений. UPDATE
Как я уже говорил, есть роль экспортера, который должен выбрать изменения, выгрузить их в какую-то промежуточную транспортную систему и затем сделать отметку, что он эти изменения выгрузил. Делается это при помощи UPDATE в начале транзакции. Начинается транзакция, и для всех записей в таблице регистрации изменений в качестве нового номера сообщения устанавливается значение, равное номеру предыдущего сообщения плюс один. Менеджер планов обмена как бы меняет статус для этих записей, говорит системе: «Я их выгружаю».
Важно отметить, что эта транзакция создается для каждого объекта метаданных по отдельности. Когда мы выбираем изменения, мы указываем узел обмена и номер сообщения. В таком вызове будут выбраны все изменения по узлу обмена со всеми объектами метаданных и прочим. Но блокировать записи этот UPDATE будет по каждому объекту метаданных в отдельности, а не так, что взял и начал обновлять всю базу.
Если этот UPDATE изменяет большое количество записей, он может быть очень длительным. Именно из-за этого происходят блокировки. Блокировки происходят по WHERE, т.е. по узлу (поля «_NodeTRef» и «_NodeRRef») и по номеру сообщения (поле «_MessageNo»), который в данном случае равен NULL, т.е. зарегистрировано. Получается так, что помечаются, выбираются только те сообщения, которые были зарегистрированы для обмена (у которых в качестве номера сообщения стоит NULL). А те, которые до этого были отправлены и помечены (например, не прошла выгрузка или не пришла подтверждающая квитанция), он не блокирует.
Блокировки возникают потому, что есть какие-то объекты, документы, с которыми пользователи часто что-то делают. Если у нас такая система, при которой документ создается один раз, записывается, регистрируется и после этого не перезаписывается, то этих блокировок не будет. И вообще проблема блокировок на регистрации изменений касается только больших систем, где бывают выгрузки по 5 тыс. документов за один раз. В маленьких системах эта тема неактуальна, там с блокировками при регистрации изменений не сталкиваются.
Если на SQL-сервере не настроен запрет на блокировку таблицы (запрет на эскалацию блокировок), то, когда к нему прилетает запрос по изменению 5 тыс. и более записей в одной таблице, планировщик SQL очень часто решает, что с точки зрения управления ресурсами оптимальнее всего заблокировать всю таблицу. В таком случае происходит эскалация блокировок, и по данному объекту метаданных блокируется вся таблица регистрации изменений. Выгружая что-то или пытаясь зарегистрировать новые изменения или удалить их, мы ничего не можем сделать, т.к. таблица заблокирована.
Как с этим бороться?
- Обычно на моей практике DBA-шники просто запрещают подобную эскалацию блокировок на уровне SQL-сервера.
- И еще один способ оптимизации связан с тем, что транзакция создается для каждого выгружаемого объекта метаданных по отдельности – можно выгружать каждый объект в отдельном фоновом задании.
Следующий шаг. SELECT
Следующим шагом идет SELECT, который выбирает все сообщения из таблицы регистрации изменений. Поскольку после UPDATE сообщений без номера не остается, SELECT выбирает их все, в том числе и те, которые отправлялись раньше.
Поэтому если мы используя систему квитирования что-то выгрузили, но квиток не получили, то в следующий раз мы выгружаем это заново до тех пор, пока не получим подтверждения о загрузке в базе-приемника. И если у нас возникают какие-то проблемы с подтверждением сообщений, то в больших системах объем выгрузки растет экспоненциально: 10, 100, 150, 200 мегабайт – каждый раз выгрузка все больше.
Запись изменений в сообщения обмена
Когда мы выбрали изменения, мы их куда-то записываем. Обычно все это грузится в XML-файл, в так называемые сообщения обмена. Бывают системы хитрее, которые используют систему сообщений с помощью RabbitMQ или еще что-то и по факту XML-файл не используют – открывают его только для вида, ничего туда не пишут, он остается пустой. Так тоже можно делать. Это уже вопрос транспорта, какой вы хотите использовать. Но в большинстве случаев, в типовых конфигурациях, например, используются сообщения обмена.
Завершение выборки изменений

Далее мы вызываем ЗакончитьЗапись(). В этот момент в таблице плана обмена фиксируется поле «_SentNo» (в данном случае, 26).
Получается, что сначала он устанавливает этот номер в таблице регистрации изменений, но в таблице плана обмена он пока еще остается на единицу меньше. И если у нас в этот момент выгрузка падает, то возникает интересная ситуация. Например, в таблице плана обмена номер сообщения имеет значение 25, а в таблице регистрации изменений уже значение 26. Таким образом, мы можем выбрать из таблицы регистрации изменений то, что должно было быть отправлено, но по какой-то причине не отправилось.
Поэтому надо понимать, что в следующий раз опять появится 26, он не будет инкрементирован до тех пор, пока не выгрузится. Текущий номер сообщения для отправки всегда «плюс 1» от того значения, которое хранится в таблице плана обмена. Это интересный момент, в некоторых случаях его можно использовать.
Почему меняется наименование? Так работает код 1С. Он фиксирует это в таблице плана обмена по узлам – мы же выгрузку делаем по узлам, соответственно, вот это – наименование узла. И 1С почему-то это перезаписывает тем же самым значением. Как вы видите, она перезаписывает все поля. Внутренняя реализация планов обмена не менялась с версии 8.0. Она как была в такой редакции, так с тех пор и не менялась.
Загрузка изменений
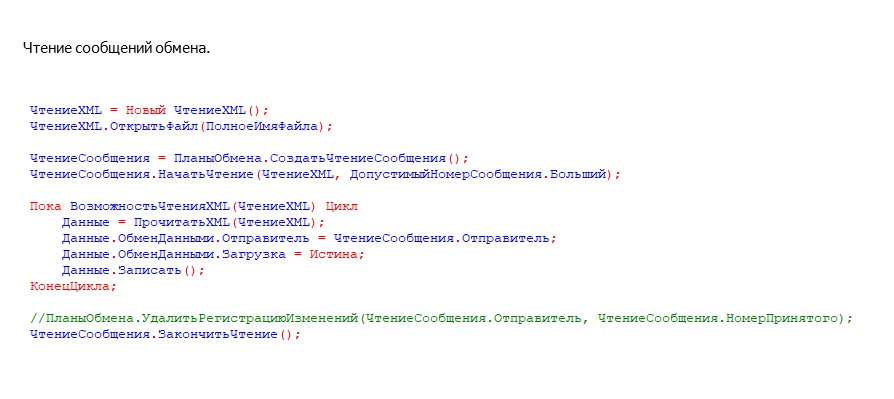
Про чтение сообщений особо ничего рассказывать не буду, можно ознакомиться на слайде.
Жизненный цикл изменений
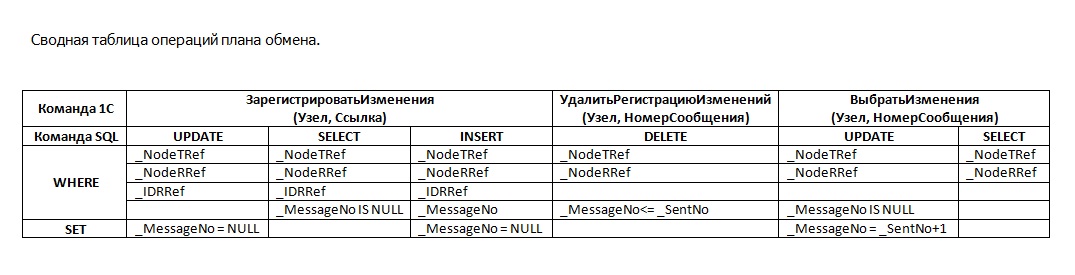
В этой таблице я попытался обобщить основные операции плана обмена в разрезе трех основных ролей.
- У роли регистратора изменений присутствуют три вызова: UPDATE, SELECT, INSERT. INSERT может быть вызван в зависимости от результатов SELECT.
- Роль терминатора делает DELETE.
- Роль экспортера делает UPDATE, SELECT. Здесь еще нужно отдельно отметить, что роль экспортера делает UPDATE для таблицы планов обмена – фиксирует выгрузку.
Я разбил это по значениям предиката WHERE, чтобы было понятно, на каких полях могут возникать блокировки. Эти три роли конкурируют за одни и те же записи, потому что в таблице регистрации изменений плана обмена для каждого объекта всегда одна запись. Именно из-за этого возникают конфликты блокировок, потому что когда мы хотим какой-то объект выгрузить, мы его блокируем и если в этот же момент его захотим еще раз зарегистрировать на выгрузку или удалить, то мы наткнемся на ограничение — для всех целей у нас только одна запись. Это – особенность реализации стратегии выгрузки с использованием предварительной регистрации изменений. Это важно, потому что возникают блокировки. Далее я расскажу, как это обойти.
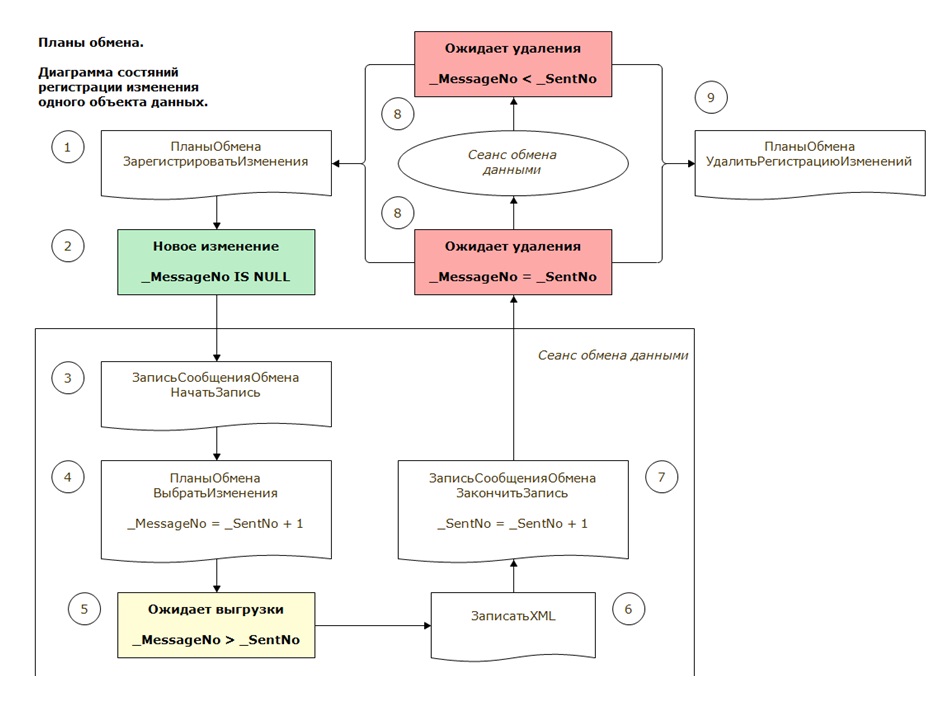
Эта диаграмма, наверное, будет сложна для восприятия. Я на ней хотел показать, что фирма «1С» управляет изменениями при помощи конечного автомата. По факту у нас есть конечный автомат для каждой записи регистрации изменений. Эта запись может быть в трех состояниях.
- Первое состояние – это новое изменение, когда _MessageNo IS NULL.
- Второе состояние, когда запись ожидает выгрузки и у нее _MessageNo > _SentNo. Это происходит в сеансе выгрузки, когда мы вызываем:
- Сначала ЗаписьСообщенияОбмена.НачатьЗапись();
- Далее ПланыОбмена.ВыбратьИзменения() – в этот момент для записи устанавливается _MessageNo = _SentNo + 1;
- Запись переходит в состояние «Ожидание выгрузки» – она еще не выгружена, а просто помечена на выгрузку;
- Следующим шагом идет запись XML;
- И вызовом метода «ЗакончитьЗапись» мы в таблице планов обмена фиксируем, что мы этот номер сообщения выгрузили: _SentNo = _SentNo + 1.
- С этого момента у нас _MessageNo = _SentNo, и запись переходит в состояние ожидания удаления – либо по квитанции, либо, если у нас гарантированная доставка, то мы можем удалять ее сразу. Чаще всего используют квитанции.
Таким образом, сеанс обмена данными, когда мы выбираем изменения, куда-то их записываем, а потом фиксируем завершение операции, является распределенной транзакцией с двухфазным фиксированием.
- На первой фазе устанавливаем значение _MessageNo = _SentNo + 1, т.е. начинаем транзакцию.
- На второй фазе фиксируем _SentNo = _SentNo + 1.
Если кто-то хочет понимать, что у него прервалась транзакция, и нужно получить именно те изменения, которые должны были быть отправлены, но не отправились, эту идею можно использовать.
Классическое решение проблемы блокировки
Какие проблемы возникают с планами обмена?
На операции ВыбратьИзменения(), в случае большого UPDATE происходят блокировки, следовательно, по этим объектам не проходят удаления и новая регистрация изменений.
Как сделать так, чтобы три роли не конкурировали за одну запись? Надо сказать, что фирма «1С» регистрирует изменения не так, как принято во всем мире. Давайте теперь разберемся, как работает классическая модель регистрации изменений.
Введение: фундаментальная проблема обмена данными.
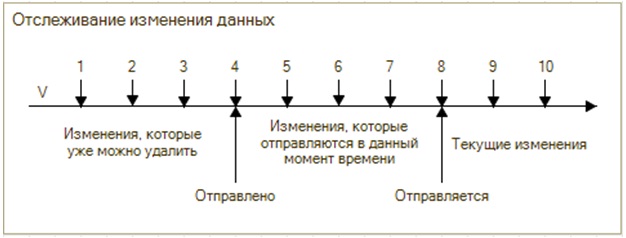
В классике это выглядит следующим образом.
Мы имеем некий объект, например, элемент справочника, у которого есть изменения. Каждое изменение – это версия объекта (1, 2, 3 и т.д.). В классических системах регистрируются именно изменения по версиям, т.е. в таблице регистрации изменений на один объект существует столько записей, сколько раз мы его меняли. Версией может быть что угодно. Это может быть весь объект, либо только те поля, которые изменились. Есть системы регистрации вообще без данных, где регистрируется просто факт того, что эта ссылка менялась, у нее версия такая-то, а при выгрузке берутся данные, которые находятся в основной таблице (так же, как работает 1С с планами обмена).
Таким образом, в таблицу регистрации изменений всегда падает новая запись – производится INSERT, который никем не блокируется, ему никто не мешает, и он всегда фиксируется. Роль фиксации изменений ни с кем не конкурирует, она сама по себе.
Экспортер знает, какую версию отправил в прошлый раз и сразу выбирает текущие изменения (не делает UPDATE, как у фирмы «1С»). Например, он знает, что в прошлый раз отправил версию 8. Он сразу делает SELECT из этой таблицы всех версий, которые у него зарегистрированы на текущий момент, например, версии 9, 10. Их две, но умная система экспорта умеет их схлопывать, понимать, что изменилось и отправлять только одну версию, например, 10. А в системах, где используется репликация транзакций, каждая версия отправляется отдельно – сначала в целевой системе применяется версия 9, потом версия 10.
Удаление происходит следующим образом: роль терминатор, которая удаляет, уже знает, что версии 1, 2, 3 выгружались, а версии 4, 5, 6, 7 еще нет. Он знает, что последняя версия, которую он удалял, например, была 4-ая, поэтому он версии 1, 2, 3 может спокойно удалить. Он ни с кем не конкурирует, никому не мешает.
В классике это разводят вот так – все три роли не конкурируют, и все работает. С другой стороны, объем данных получается больше, потому что нужно больше места для регистрации версий. Это плата за решение проблемы блокировок.
Альтернатива планам обмена
Регистр сведений для регистрации изменений с версионированием
Альтернативная регистрация изменений.
- Периодический регистр сведений "РегистрацияИзменений".
— Период (версия изменения)
— Транзакция (идентификатор транзакции SQLServer)
— Объект (ссылка или уникальный идентификатор)
— Данные (например, XMLпредставление объекта)
— Любые другие измерения, ресурсы или реквизиты (например, узлы-получатели данных)
Как это решить средствами 1С? Я встречал очень много альтернативных систем регистрации изменений. Расскажу об одной, наверное, самой простой.
Создаем обычный регистр сведений и практически дублируем в него таблицу регистрации изменений. Что мы сюда включаем?
- Мы можем включить Период, сделать его периодическим (он будет играть роль версии изменения). Период используют очень часто, но я не очень рекомендую так делать, потому что тогда нам надо постоянно синхронизировать время между серверами. Потому что если в какой-то момент что-то происходит со временем, то в таблице регистрации изменений начинается бардак. Конечно, это бывает редко – у Windows, например, есть достаточно надежная служба синхронизации времени. Но такой риск есть, и я на него в жизни пару раз наталкивался.
- Идентификатор транзакции SQL Server. Мы сейчас это рассмотрим более подробно.
- Ссылка на объект или его уникальный идентификатор в строковом представлении и сами данные.
- Остальные поля необязательны. Сюда можно интегрировать маршрутизацию (узлы, измерения для каких-то выборок и т.д.).
Проблема сохранения целостности данных
Какие проблемы хотелось бы учесть при реализации альтернативной регистрации изменений? Помимо проблемы блокировок у нас иногда возникает проблема целостности данных. Потому что некоторые объекты взаимозависимы друг от друга. Например, мы провели документ и параллельно в этой же транзакции проведения записали в какие-то регистры сведений – что-то очень важное для этого документа. При регистрации получилось несколько объектов метаданных, несколько таблиц регистрации изменений, где хранятся данные для этого документа. Но при выгрузке то, что эти объекты взаимосвязаны, не учитывается.
Конечно, классически, когда мы делаем ВыбратьИзменения() у нас идет выборка изменений по всему узлу. Но в больших системах для оптимизации изменения обычно выгружают кусками – порционируют эти сообщения и делают их как можно меньше, чтобы потом, при их загрузке в принимающую систему, транзакция загрузки была как можно меньше – чтобы выше была конкурентность работы пользователей, и больше пользователей могло работать с системой. Таким образом часто оптимизация заключается в том, что каждый объект метаданных уходит в разных сообщениях. Поэтому может так случиться, что кусок данных для этого документа уйдет в одном сообщении, а регистр сведений в другом. Или у нас может быть несколько связанных документов, например, если мы используем механизм «Интеркампани». Допустим, у нас есть «Реализация», а у другой компании «Поступление» – эти два документа и их движения были образованы в одной транзакции, поэтом должны уехать вместе, а, используя планы обмена и прочее, очень часто бывает так, что документ приезжает, а его движений еще нет.
Как с этим бороться? Напрашивается вывод, что эти объекты нам желательно каким-то образом выгружать в одном сообщении. Как их туда поместить? Нам надо знать, что эти объекты зарегистрировались в одной транзакции. Значит, нам нужен какой-то идентификатор транзакции. Как это сделать средствами 1С я даже не представляю. Нужно специально знать об этом и код 1С уже писать изначально так: начать транзакцию, присвоить ей какой-то идентификатор, и записать идентификатор транзакции в регистр сведений, и только после этого транзакцию зафиксировать. Если этим заниматься в какой-то конфигурации, то придется переписать все. Это нереально.
Выход есть, но не 1С-ный.
Порционная выгрузка данных, как метод оптимизации

Чтобы обеспечивать работу своего кастомного регистра сведений, нужно эмулировать работу плана обмена, т.е. зарегистрировать изменения, удалить изменения и т.д.
Для регистрации изменений можно использовать простую экспортную процедуру ЗарегистрироватьИзменения(), код которой я тут накидал. Эта процедура может быть размещена в каком-то общем модуле, я свой общий модуль назвал МойОбменДанными.
В этой процедуре мы для каждого выгружаемого объекта создаем набор записей и пишем эти данные в регистр сведений с помощью метода Набор.Записать (Ложь). Почему «Ложь»? Потому что будет INSERT и все – нет блокировок, совсем. У нас не будет DELETE, как обычно по отбору, у нас будет сразу INSERT, одна команда SQL, ни с кем не конкурирующая. Мы просто все время дополняем регистр сведений своими версиями объектов.
Функция ПолучитьXML(Объект)
ЗаписьXML = Новый ЗаписьXML();
ЗаписьXML.УстановитьСтроку();
ЗаписатьXML(ЗаписьXML, Объект);
Возврат ЗаписьXML.Закрыть;
КонецФункции
В поле «Данные» я просто сериализую объект с помощью функции ПолучитьXML(). Все просто, работает быстро. Не буду говорить о том, что здесь будут накапливаться большие данные, что это XML, что это не оптимально и т.д. Это сделано для упрощения. Вы вольны делать с этим полем все, что хотите. Я видел систему, где регистрировались только изменения реквизитов, т.е. если изменился один реквизит, например, дата документа, то выгружалась только дата и все. Соответственно, в поле «Данные» у меня каким-то образом упакованные данные изменения.

Далее – процедура ЗарегистрироватьУдаление(). Она у меня выделена отдельно, потому что ссылки надо заворачивать в Новый УдалениеОбъекта(Ссылка), чтобы в целевой системе, когда она приедет, я мог это просто распаковать, вызвать «Записать» или «Удалить». И опять же Набор.Записать (Ложь), т.е. INSERT и все.

Вспомогательная функция ИмяФлагаРегистрацииИзменений. Я ее завернул в отдельную функцию, потому что строковые константы вставлять в нескольких частях кода неправильно. Лучше сделать так, через функцию. Если вдруг вы решили поменять название флага, то вы меняете его только в одном месте.
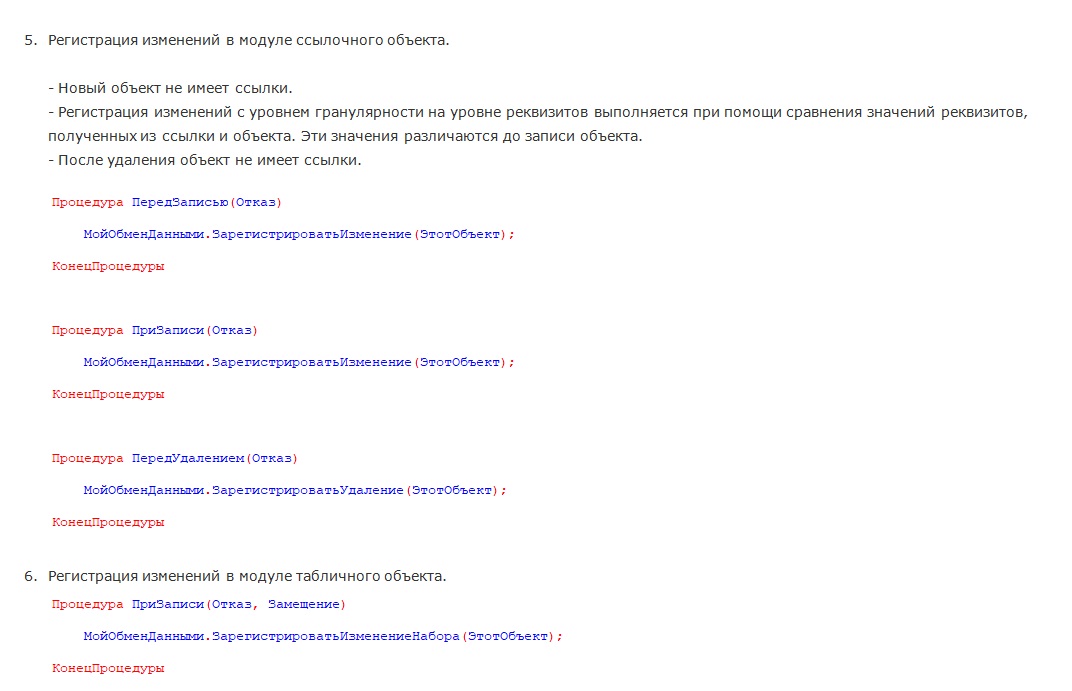
Обратите внимание, что в процедурах ЗарегистрироватьИзменение() и ЗарегистрироватьИзменениеНабора() у нас изменения записываются только в том случае, если у объекта стоит «Истина» в дополнительном свойстве с именем флага. Зачем так было сделано?
Очень часто бывает, что мы хотим регистрировать изменения только в том случае, если объект изменился. Если он не менялся, то зачем его регистрировать и выгружать? Ни к чему. Как это сделать? Если говорить о ссылочных объектах, то разницу значений реквизитов мы можем увидеть только в процедуре ПередЗаписью(). В этой процедуре мы можем проверить, что значения реквизитов в ссылке и в объекте у нас разные. Как только мы вызовем Записать(), они платформой синхронизируются и станут одинаковые.
Поэтому в процедуре ПередЗаписью() мы вызываем нашу процедуру ЗарегистрироватьИзменения().

Когда мы попадаем в эту процедуру в обработчике ПередЗаписью() мы смотрим: если это новый объект, то мы добавляем ему новое дополнительное свойство, присваиваем ему значение «Истина» и возвращаемся. Почему так? Потому что, если мы попытаемся сразу записать ссылку в регистр сведений, то для нового объекта ссылки еще нет. Тут двойная проверка, так как у нас есть не новые объекты, у которых этого свойства пока что нет, и его тоже нужно создать.
Потом в обработчике события ПриЗаписи() мы повторно вызываем процедуру ЗарегистрироватьИзменение(). В этот момент объект уже будет не новый, он посмотрит, установлен ли у него ФлагРегистрацииИзменения, и в зависимости от этого будет записываться в регистр сведений. Эта проверка вставлена сюда на всякий случай, если вдруг мы решили отказаться от регистрации изменений по каким-то причинам. До этого мы флаг добавили, а потом мы можем этот флаг либо удалить из дополнительных свойств, либо поставить ему значение «Ложь».
Репликация транзакций, как решение проблемы целостности данных

Как получить идентификатор транзакции? Допустим, мы действительно хотим сделать репликацию транзакций в 1С. Все говорят, что это нереально, но это не так. Это можно сделать, повесив триггер на таблицу регистрации изменений.
У нас есть таблица нашего кастомного регистра сведений для регистрации изменений, куда мы должны записать Transaction_id. У нас она называется «_InfoRg17». Мы на нее вешаем триггер. В SQL-сервере есть процедура, которая возвращает идентификатор текущей транзакции, и мы его записываем в поле _Fld18, которое соответствует полю «Transaction_id». Теперь у нас есть идентификатор транзакции.
Как бы мы ни меняли объекты в транзакции 1С: документ, регистры, два документа связанных, если они записаны в рамках одной транзакции, то в регистр сведений они попадают через триггер, и мы для всех этих изменений получим один и тот же идентификатор транзакции. Потом мы можем это выгружать, как один монолитный кусок данных. Таким образом, мы сохраняем 100%-ную целостность.
Понятное дело, это нарушает лицензионное соглашение фирмы 1С. Я лишь говорю о возможности, а как ей воспользоваться — решайте сами. Например, продукт построения альтернативной РИБ для 1С от одной достаточно известной фирмы работает с использованием такого триггера.
Проблема сохранения целостности данных при транспортировке сообщений обмена
Негарантированная доставка (квитирование)
Основная проблема: повторная отправка одних и тех же данных.
Запрос для определения повторно отправленных объектов в разрезе узлов плана обмена.

Теперь расскажу, каким образом можно использовать разницу в номерах сообщений, которые фиксируются в таблице планов обмена и в таблицах регистрации изменений.
Если вы используете квитирование, то с помощью запроса, представленного на слайде, вы можете узнать, сколько данных вы отправляете повторно в разрезе узлов плана обмена.
Здесь используется левое соединение с таблицей изменений справочника «Номенклатура», поэтому в данном случае мы получим отчёт в разрезе узлов и номенклатуры. Зная количество объектов, и примерно оценив, сколько каждый объект будет весить, вы можете посчитать даже объем данных. Это может быть нужно, например, для обоснования необходимости отказа от квитирования или просто для мониторинга, чтобы понять какие объемы данных у вас в системе летают просто так.
Гарантированная доставка

С гарантированием основная проблема в том, как сохранить целостность данных, потому что получается так, что мы выгрузили данные, они куда-то приехали, квитанцию мы не ждем, регистрацию изменений удалили, а тот пакет, который мы отправили, где-то умер.
Как с этим быть? Это – проблема экспорта. Нужно передать данные в какую-то транспортную систему, которая будет гарантировать доставку, и мы будем точно знать, что пакет там не умрет, он доедет. Тут сразу возникают вопросы. Наверное, лучше всего для этого использовать специализированное программное обеспечение – очереди сообщений и т.д. В то же время нам нужно пометить, что данные отправлены, т.е. мы сформировали сообщение обмена, положили в какую-то другую транспортную систему, и нам надо как-то отметить у себя, что эти данные мы отправили. Желательно это сделать в транзакции. Если мы этого не делаем в транзакции, то у нас есть риск повторной выгрузки, т.е. мы положили в систему, стали записывать в 1С, что мы это отправили, упали и все. 1С не знает, что оно отправилось. Такое может быть. Получается, что когда система восстановится, она выгрузит это повторно.
По сравнению с квитированием, риск – вообще ерунда. Но если это по какой-то причине страшно, то надо думать, как это сделать в транзакции. Это отдельная тема, потому что тогда мы получаем распределенную транзакцию между двумя независимыми системами. В классике это разрешается через DTC, т.е. Distributed Transaction Coordinator. Есть разные способы, как это сделать. Например, можно использовать в качестве транспорта SQL Service Broker, собственную систему отправки сообщений SQL-сервера. Она полностью поддерживает транзакции, причем локальные. Например, когда вы выгружаете что-то в Service Broker в транзакции, то это локальная транзакция для SQL-сервера, а не распределенная. Это дает огромный выигрыш производительности.
Но в основном, такая 100%-ная консистентность данных не нужна. Она нужна в каких-то финансовых системах, где есть что-то, что касается денег – там это нужно. В обычных системах еще раз отправить пакет – не проблема.
С импортом там примерно такая же проблема, только наоборот. Мы должны сначала из транспорта забрать, применить изменения в целевой системе и удалить в транспорте, т.е. сказать транспортной системе, что я уже получил. Опять же при помощи SQL Service Broker эта проблема решается очень легко.
Заключение
Я акцентировал внимание на трёх программных ролях, которые обеспечивают обмен данными при помощи регистрации изменений. Рассказал о том, каким образом они взаимодействуют и конкурируют между собой.
1С использует метод регистрации изменений без данных. Особенностью реализации этой методики фирмой 1С является наличие только одной записи регистрации изменений для каждого объекта. Именно это порождает конфликты блокировок обмена данными.
Для решения проблем, связанных с использованием планов обмена 1С, предложена альтернативная реализация средствами платформы.
Кроме этого описана возможность реализации аналога репликации транзакций.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 COMMUNITY. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Возможно история данных в последних версиях может как то решить эту проблему, например регистрация изменений может храниться отдельно от таблицы, которая фиксирует факт выгрузки изменений и получения ответа. Место создания объекта конечно тоже интересно (например как префикс к гуидам).
(1) История данных — это попытка реализовать методику фиксации изменений с данными. Я упоминал о ней в статье. Если тема интересна, то рекомендую ознакомиться как это реализовано, например, в SQL Server — см. . Обычно эта методика используется для аудита изменения данных и очень редко для обменов.
У меня вопрос по самостоятельной регистрации изменений. В приведенных примерах мы в регистр сведений записываем последнюю версию объекта, выгруженную в xml, но потом нам надо этот объект отправить в базы получатели. Причем конфигурации баз получателей могут отличаться от конфигурации базы отправителя и следовательно надо произвести какую то конвертацию данных. Также состав баз получателей может зависть от самого выгружаемого объекта, например выгружаем его только в базу определенного филиала. Как Вы предполагаете решать данные задачи?
А как зарегистрировать для обмена записи Регистра сведений?
(2) Дмитрий, у Вас много довольно вдумчивых серьезных публикаций по РИБу, возможно подскажете (может где то есть статья) связанная с причинами и расследованиями пропадания документов, движений документов и прочего. Возможно есть какая то общая методология поиска, кроме как моделировать такие ситуации.
(5) Добрый день! Спасибо.
Какой-то специальной методологии не знаю.
Я пользуюсь моделированием потоков данных.
Определяю точки возможных проблем.
Затем по конкретной ситуации пытаюсь понять как это могло произойти, учитывая текущую модель. Проверяю гипотезу стараясь воспроизвести проблемную ситуацию, используя расширенное логирование.
Могу посоветовать уделить особое внимание тем операциям, которые выполняются вне транзакций СУБД, или событиям, которые происходят асинхронно. Кроме этого необходимо провести аудит кода на правильность обработки исключительных ситуаций.
Например, как может «пропась» документ в РИБ (гипотеза):
1. Пакет ушел из ЦБ в узел.
2. В узле пакет приняли, документ не записался (упал с ошибкой), но пакет в целом приняли.
3. Узел отправил квитанцию.
4. ЦБ квитанцию принял, регистрацию изменений удалил.
(4) По ключу записи или по отбору набора записей регистра сведений.
Кроме этого иногда регистрируют весь набор вместе с отбором.
(7)Лучше поздно, чем никогда… Год уж почти прошел!!!
Да я уже все порешал…… )))))))
(3) Если отвечать коротко, то есть несколько способов.
Например, фильтры миграции данных или, в терминах 1С, правила регистрации объектов, могут применяться до регистрации изменений. Эту проблему часто называют «фильтрация основанная на содержании» или подобным образом.
Правила конвертации объектов могут применяться на принимающей стороне, но никто не запрещает их применять на отправляющей стороне — в XML можно положить уже сконвертированный объект. Это зависит от самих правил конвертации в том числе.
А вообще рекомендую эту книгу для ознакомления: «Шаблоны интеграции корпоративных приложений», Хоп Грегор, Вульф Бобби
(8) Да, я сам посмеялся над собой =)
Но на самом деле ответ не столько для Вас, как для тех, кто попадёт на эту страницу может быть ещё через год =)
(6)
Это типовый РИБ, но возникают вообще нереальные вещи, как то:
1) Номенклатура передалась, но единицы измерения нет — я понимаю что единицы измерения подчиненный справочник и в КД это можно настроить, но в РИБе же нет правил конвертации.
2) Документ передался, но движений нет.
3) Документ пропал в ПЕРЕФИРИИ — по сути откуда он ушел, но есть в центре.
Понятно, что какие то конкретные советы дать нельзя. Дело в том, что протоколирования же никакого нет, что исследовать ЖР ?
(11) Очень сложно давать советы, не зная конкретной ситуации. В общих чертах могу сказать следующее:
1) Можно настроить обмен справочником «ЕдиницыИзмерения». Можно посмотреть в сторону ручной регистрации изменений справочника «Номенклатура» — дописывать данные в обмен.
2) Стандартная проблема для РИБ: как правило документ и его движения попали в разные пакеты данных (сообщения обмена).
3) Интересная ситуация. Чудес не бывает — кто-то документ в переферии удалил. Тут можно посоветовать применить расширенное логирование при помощи подписки на событие документа, например, «ПередУдалением».
Если используете БСП, то посмотрите обработку «КонвертацияОбъектовРаспределенныхИнформационныхБаз».
(12) Спасибо за консультацию от РИБа отказываемся, но интересно разобраться.
А может разная версия движка 1С по разному отрабатывать распределенный обмен ?
(10) Да, мне такое нужно, а то у нас в коде (видимо за неумением) регистрируют весь РС ЦеныНоменклатуры )))))))))))))))))))
.
(13) Если мне память не изменяет, то принципы работы РИБ и планов обмена не менялись ещё с версии 1С:Предприятие 8.0 =) Тут всё стабильно =)
(12) Добрый день еще несколько вопросов:
1) Можно настроить обмен справочником «ЕдиницыИзмерения». Можно посмотреть в сторону ручной регистрации изменений справочника «Номенклатура» — дописывать данные в обмен.
Понятно, что можно сделать ручную регистрацию, когда ты делаешь это на КД, то именно с подчиненными справочниками возникают проблемы. Вопрос следующий — средствами РИБ разве не всегда можно обеспечить корректный обмен?
2) Стандартная проблема для РИБ: как правило документ и его движения попали в разные пакеты данных (сообщения обмена).
Это вообще непонятно, что значит разные пакеты? Пакет всего один — текущая выгрузка с номером N или что то не так ? Вместе с объектом в регистрацию попадают все подчиненные объекты (Ссылочные реквизиты, движения) — или это утверждение некорректно ?
3) Интересная ситуация. Чудес не бывает — кто-то документ в переферии удалил. Тут можно посоветовать применить расширенное логирование при помощи подписки на событие документа, например, «ПередУдалением».
Там оказался «проблемый» сам документ — проводится, но не закрывается транзакция, а транзакция потом откатывается. 🙂
(16)
Дайте, пожалуйста, определение термину «корректный обмен» в контексте Вашей задачи.
Общий ответ: корректный обмен Вам может обеспечить только опытный программист. Никакая технология, в том числе РИБ, не решает проблемы сама по себе — это всего лишь инструмент.
Утверждение корректно, при условии, что все подчинённые объекты записываются вместе с родительским объектом в одной транзакции.
Однако, очень часто, из-за большого количества зарегистрированных в обмен объектов, в целях оптимизации выгрузки, массивы этих объектов делят на разные сообщения. В таком случае всё зависит от программиста =)
Да, такое тоже может быть. Это к вопросу об обработке исключительных ситуаций.
(17)
Спасибо за информацию, с частью вопросов получилось разобраться.
Вопрос следующего характера: иногда возникает ситуация (непонятно когда), что данные «считаются» принятыми, а на самом деле это не так.
Поэтому возникает вопрос: что является признаком «принятости» файла (квитанцией) — изменивший номер принятого сообщения?
В момент получения информации механизм удаляет сообщения из регистрации с номерами меньше либо равно чем?
Вопрос №2. Насколько нормально работает обмен между разными движками: 8.2 и 8.3, по сути все должно быть ок, так как это просто ХМЛ, ну а там кто его знает?
Вопрос №3. В файлах регистрации находятся сообщения для отправки с аномально большими номера, непонятно откуда они там появились. Нормально будет если их удалить?
Вопрос№4 Те планы обмены которые не используются остаются в БД и в них соответственно накапливается регистрация документов, понятно, что обмены с ними отключены. Насколько нормально эти планы просто удалить? Или лучше сделать механизм который не будет регистрировать данные в неактивные планы обмена?
Спасибо.