
Добрый день. В данной статье я хотел бы очень крупными мазками обрисовать архитектуру ИТ системы на базе 1С в крупных (более 1 тысячи пользователей) организациях. Она не несет какой либо образовательной цели, это просто попытка показать – «а как у нас».
Часть 1. Архитектура.
Компания владеет крупной сетью магазинов. На текущий момент в сети где то 2700-3000 магазинов со средним количеством рабочих мест 2,4. Значительное количество операций, связанных с обслуживанием клиентов (продажа и замена сим карт, регистрация контрактов, подключение услуг новым абонентам), с товародвижением (приём и отгрузка товара, проведение инвентаризаций), все розничные операции (работа с кассовыми сменами, продажа товара, акционные механики) выполняются в 1С.
Ежедневное количество активных пользователей порядка 7000

количество чеков в пике достигает 300 в минуту, размер базы ~2.6 Тб.
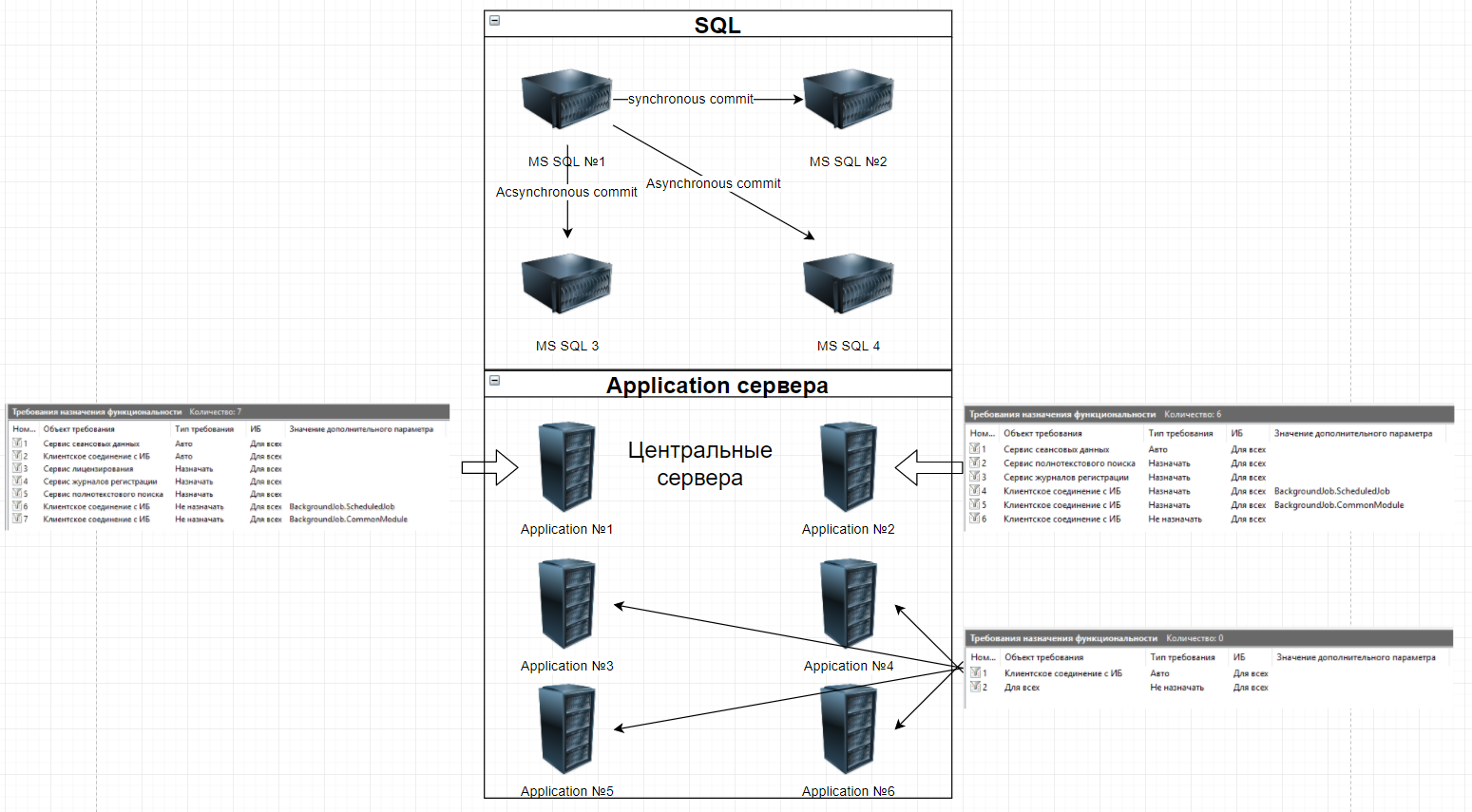
Для обеспечения работоспособности системы создан кластер со следующей архитектурой:
Плюсы решения:
При отказе SQL-сервера активная года автоматически переедет на работающий сервер и работа будет продолжена без прерывания для клиентов (проблему заметят только пользователи, которые запустили транзакцию в момент начала переезда), сам переезд длится порядка 1-2 секунд.
Возможность горизонтального масштабирования application кластера. Добавление нового кластера занимает примерно полдня, но для ускорения процесса в критических ситуациях возможен перевод сервера из тестового стенда в продуктив, на это уйдёт не более 10 минут.
Минусы решения:
Отсутствие полноценной отказоустойчивости. При падении одного из центральных кластеров примерно 50% пользователей получат недоступность системы, им потребуется перезайти в неё.
Особенности:
Дальнейшее я отношу к особенностям решения, а не к минусам, так как изменение архитектуры не может повлиять на ситуацию.
- Практически невозможно в течение дня безболезненно выгнать всех пользователей для срочного обновления. Даже если само обновление конфигурации займет 1 минуту процесс обновления выглядит следующим образом:
- Установка блокировки базы (делается заранее)
- Ожидание, пока все пользователи выйдут из базы (примерно 2-3 минуты с начала блокировки).
- Остановка служб на серверах, где находятся сеансовые данные. (2-3 минуты)
- Очистка сеансовых данных. (1 минута)
- Непосредственно обновление конфигурации. (1 минута)
- Запуск пользователей. (1 минута)
- Стабилизация нагрузки после входа. (3-5 минут)
Таким образом внеплановое обновление занимает в средней 15 минут и всегда связано с высоким стрессом, так как вероятность, что что-то пойдет не так значительно больше нуля, а поправить ситуацию времени нет. Каждая минута — это десятки тысяч рублей недополученной прибыли.
Причина — большой объем сеансовых данных, которые потребуется загрузить одномоментно, в случае если их не очистить (порядка 20 Гб). Практика показала, что система (именно 1С) не справляется с загрузкой такого объема данных за приемлемое время, в результате чего пользователи на протяжении 5-10 минут наблюдают окно с запуском конфигурации.
Для решения данной проблемы мы перешли на 8.3.10 и отказались в конфигурации от режима совместимости (изначально проект стартовал на 8.3.6), так что теперь критичные дефекты выпускаются с помощью расширений, а инциденты закрываются с рекомендацией перезапустить 1С и повторить попытку.
В ближайшее время мы планируем переход на 8.3.12, этим мы хотим закрыть вопрос с падением платформы на клиентах (порядка 2-3 тысяч дампов в день), а также попытаемся с помощью расширений не только исправлять дефекты, но и внедрять новый функционал.
- Зачастую проще оптимизировать нагрузку через создание индексов на уровне SQL, чем пытаться создать их средствами 1С или оптимизировать код. Напоминаю – так делать нельзя, так как это нарушение лицензионной политики 1С.
- Обязательно требуется замерять время обновления, так как несмотря на явный запрет разработчикам добавлять новые реквизиты в большие таблицы иногда всё-таки проскакивают изменения, требующие длительной реструктуризации.
Часть 2. Мониторинг.
Мониторинг мы разделяем на 3 части. 1-ый это стандартный ИТ-шный мониторинг, нагрузка на ЦПУ, занятое ОЗУ, диски, количество таймаутов и дедлоков в единицу времени и прочее-прочее, десятки их.
2 часть – доступность различных внешних ресурсов.
3 часть мониторинга — это бизнес-мониторинг, сюда мы относим:
- Количество чеков в единицу времени.
- Количество замен сим-карт в единицу времени.
- Количество отправленных платежей в единицу времени.
- Среднее время выполнения основных 7 операций.
- Некоторые другие специфические параметры (например отношение ошибочных регистраций контракта к успешным, количество ошибочно подключенных услуг при биллинговых операциях и другие вещи, интересные только внутри компании).
Для сбора информации по 1 и 2 частям мониторинга мы используем конфигурацию «Центр контроля качества», через него же делаем рассылки про основные инциденты, такие как повышенная нагрузка на ЦПУ, появление дампов (падение служб rphost) и пр.
К первой части так же можно отнести сбор логов технологического журнала. Фактически это одно из основных средств для расследования проблем, а также источник данных для сбора части показателей (количество TTimeout и TDeadlock, таймауты и дедлоки на управляемых блокировках, зависание rphost (тут всё достаточно тонко, если будет нужно расскажу дополнительно), среднее (AVG) и общее (SUM) время вызова (CALL и SCALL). Вообще технологический журнал позволяет собирать огромное количество полезной информации, главное научиться парсить многогигабайтные текстовые файлы. У нас за это отвечает отдельный сервис на C#.
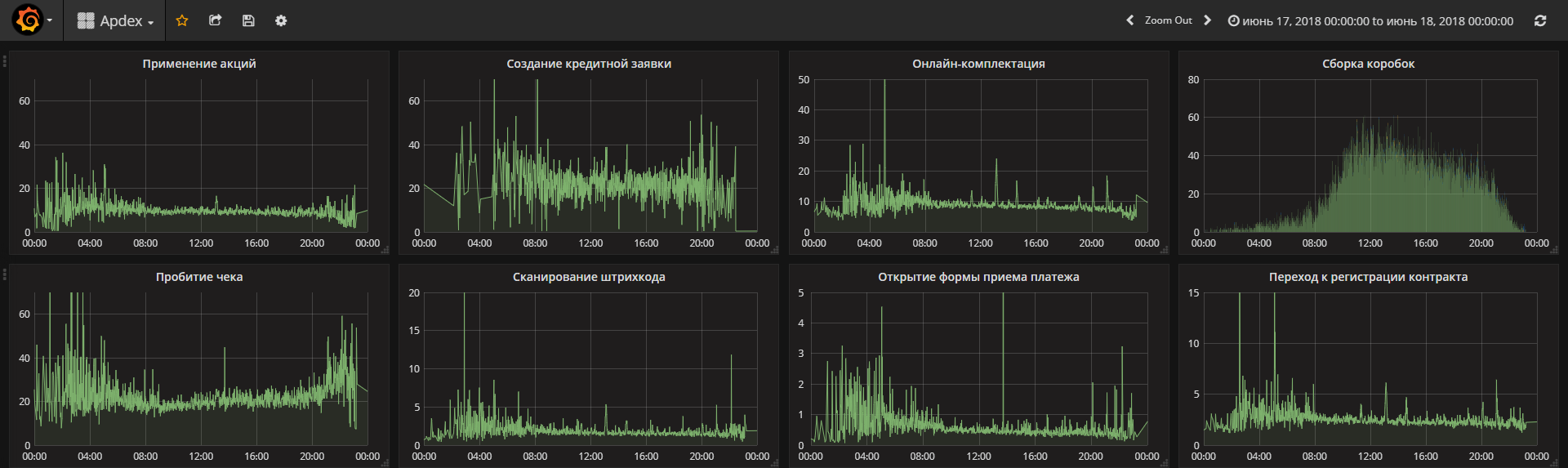
3 часть. Обычно в этой части принято считать apdex, как некий сводный показатель производительности системы, однако мы пришли к выводу что для нас наглядней смотреть просто на среднее время выполнения ключевых операций. Замеры выполняются стандартными средствами 1С и пишутся в регистр сведений, откуда уже читаются прямыми запросами и выводятся в дашборд. Сначала мы пытались изобрести велосипед в части дашбордов, но потом остановились на Grafana. Вот так выглядит график среднего времени выполнения операций за 1 день.
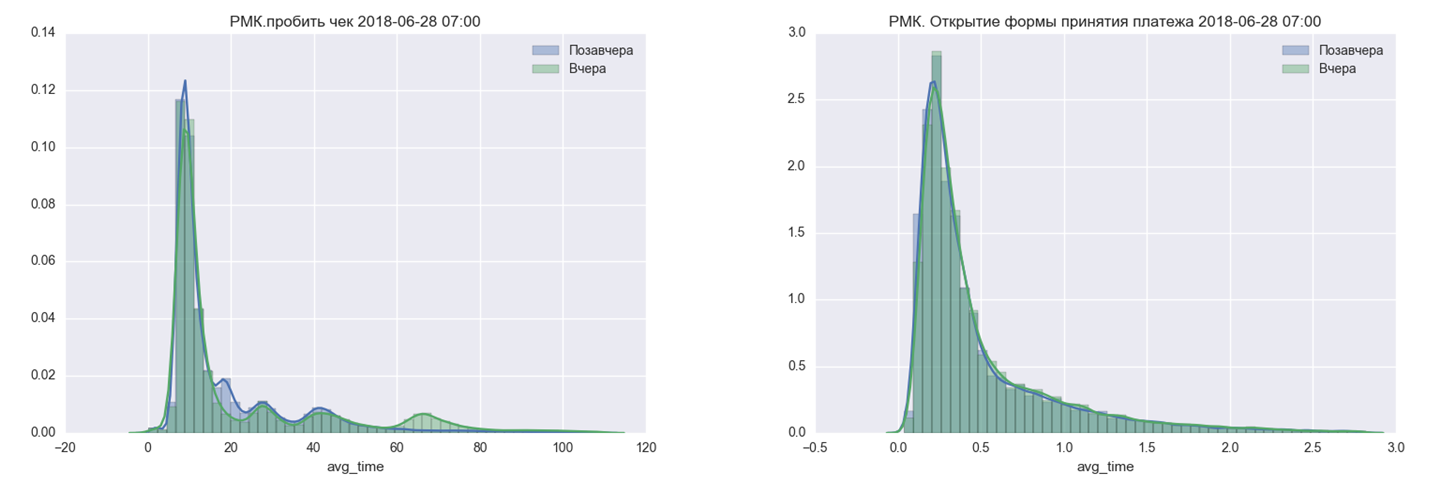
Кроме того ежедневно в почту приходит диаграмма распределения времени выполнения операций за последние два дня, это позволяет быстро понять, не изменилась ли производительность системы.
На этом я закончу вводную часть, если тема интересна – я готов рассказывать некоторые подробности, но так как на проекте уже 3 года информации накопилось очень много, если вы укажете, какое именно направление интересно – я распишу его подробней.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Все пользователи работают в единой базе?
Подключение к базе напрямую или по РДП?
Есть ли мониторинг того, что какой-то магазин не работает в системе (на точке нет интернета и тп)?
Вы работаете напрямую с вендором, как Деловые Линии, например?
Очень круто.
Но теперь надо подробнее.
Какое железо, какие хранилища данных.
Какая конфа.
Как ведете разработку, сколько разработчиков, аналитиков. Как тестируете.
Что за проблема с падением платформы на клиентах.
Тема крайне интереса, здесь есть о чем поговорить и в плане обмена опытом и в плане похоливарить. Эксплуатация больших систем на 1С — тема плохо освещенная, к сожалению. Пишите еще.
Для затравки: у меня, например, многомашинный кластер привносил проблем больше чем пользы (версия 8.3.10), но была возможность нарастить вертикально — в рамках одной машины. Стабилизировать его в приемлемом качестве так и не удалось… В остальном похоже было, отчетность у вас круче, а с обновлением мы экспериментировали, делали автодеплой с фоновой реструктуризацией ради минимального простоя при частых обновлениях — даже работало 🙂
(1) Да, все пользователи работают в одной базе.
Нет, RDP нет, тонкий клиент везде.
Мониторинг есть у сетевиков, то есть они видят, что канал пропал до точки. Мониторинга работоспособности 1С нет, хотя в целом сделать его не сложно, я уже думал об этом. Вопрос, что делать, если мы видим, что точка, которая с точки зрения мониторинга должна работать — не работает. Звонить выяснять, в чем дело? К сожалению ресурсов у нас не так много и свободных на текущий момент нет, хотя в целом, если предложить бизнесу идею — возможно он и готов будет оплатить.
(2) Вы про 1С? Естественно у нас есть РКЛ, кроме того сейчас есть действующий договор с ЦКТП.
(6) Лицензии 1С не КОРП?
(3)
Конфа — УТ 11, естественно переписанная вдоль и поперек.
Падение платформы — если вкратце — иногда при пробитии чека по эквайрингу падает платформа, в итоге имеем списанные у клиента деньги и не пробитый чек.
По железу, разработке и тестированию постараюсь ответить отдельной статьей. В двух словах не опишешь.
(7) КОРП конечно, мы полностью белые, а на обычные лицензии огромное количество ограничений, хотя они и просто лицензионные, а не программные.
(4)
Как раз 1С-овский кластер на текущий момент наиболее устойчивая и менее всего беспокоящая меня тема. Сейчас самое большое это невозможность распараллелить SQL и кривые руки разрабов, которые двумя строками говнокода убивают недели, затраченные на оптимизацию. Конечно эти две строки кода несложно исправить, но ведь их сначала надо найти. В общем стандартная война разработки и эксплуатации.
(10) Как боретесь с зависшими сеансами, утечками памяти? Каким образом чистите сеансовые данные после обновления конфигурации? Нет ли превышения времени ожидания предоставления блокировок при таком количество пользователей?
(9) Спасибо. Если можно, расскажите про КОРП лицензии, что реально дают на практике, чем лучше обычных, насколько качественнее и быстрее техподдержка для КОРП…
(10)Почему бы не нанять пряморуких разрабов? Или направить на курсы для 1с эксперта? Для контроля можно попросит сдать профа по технологическим вопросам. Думаю понимания и косяков будет меньше.
(13) Ну про криворуких я конечно немного утрирую, в основном нормальные разработчики, просто они не думают большими масштабами. Простой пример — при проведении документа разработчик два раза передает контекст формы на сервер, оптимизировав и заменив только на 1 вызов мы серьезно улучшили производительность в дальних регионах, так как пинг там совсем не веселый и такая простая процедура, как передача контекста начинает занимать уже приличное время.
Второй пример — увлеченность разработчиками временными таблицами. Их привычка пихать их к месту и не к месту привела к тому, что у нас SQL начал проваливаться именно по этому показателю.
(11)
Зависшие сеансы это что? Клиентские сеансы? Я что то с таким не сталкивался, можно поподробней, как это выглядит?
Утечки памяти — перезапуск rphost при превышении предельного размера, но происходит это не часто. Дело в том, что у нас вся отчетность вынесена во внешнюю систему, в 1С можно строить отчеты, не превышающие при выводе 10 тысяч строк.
Сеансовые данные чищу ручками. Остановил все службы, удалил файлы. Можно скрипт конечно написать, руки никак не дойдут.
Превышение времени ожидания редко, но бывают. Примерно 1-2 раза в день. На это стоит отдельный счетчик, который сразу начинает верещать. Таймауты не связаны с кодом конфигурации, варианты, которые у нас были:
1. Пользователь запустил два сеанса и пытался одновременно в них провести один и тот же документ (там не пользователь, а робот был на самом деле). Научили его так не делать.
2. Слишком длительное обслуживание индексов. Оптимизировали скрипты и отключили обслуживание тех индексов, которые по нашему мнению не нужны.
3. Какая то проблема в SQL, в результате чего при автообновлении статистики таблица блокировалась зачастую на несколько минут. Отключили автообновление статистик в течение дня, только по ночам.
(14)
Второй пример — увлеченность разработчиками временными таблицами. Их привычка пихать их к месту и не к месту привела к тому, что у нас SQL начал проваливаться именно по этому показателю.
Так ведь это и должно решаться техническим контролем выкладываемых изменений в рабочую базу. Если команда небольшая, достаточно одного специально обученного человека, и будет счастье.
(0)
Расскажите, пожалуйста, еще:
Какой объем базы?
Сколько документов вводится в день?
По сколько записей в самых объемных таблицах? И какие это таблицы?
Как обслуживаете Журналы регистрации? В каком формате их используете (txt/sqlite)?
Каков размер индекса полнотекстового поиска?
Спасибо!
Повторю, тема очень интересная и проект реально крутой по объемам. Прямо очень интересно по-максимуму ознакомиться с опытом.
У меня на обслуживании РИБ. В одном только из узлов которой регистрируются по 5000 документов в день.
Естественно, мы порой встреваем в проблемы производительности. Объемы таблиц опять же не радуют. Сама база весит 500 Гб и растет довольно быстро.
Но пока всё еще руки не доходят «сделать нормально» с мониторингом и анализом ТЖ на текущие показатели. До кластера руки дошли вот только сейчас недавно, да и то — только после того, как сильно просели по производительности.
(16)
Скажите пожалуйста, что должен включать в себя «технический контроль»?
Сотрудник, проводящий контроль релиза, должен проанализировать выполнение кода и спрогнозировать его неоптимальное использование?
(18)
Сотрудник, проводящий контроль релиза, должен проанализировать выполнение кода и спрогнозировать его неоптимальное использование?
Да. Часть проблем видно уже при просмотре кода (излишнее количество виртуальных таблиц, да и лишние вызовы сервера тоже могут быть замечены).
А то, что нельзя увидеть при беглом просмотре, можно отследить на этапе тестирования.
Добрый день.
Касательно долгой реструктуризации — не пробовали новый механизм? В настройке немного муторный и мало описанный в документации, но разработчики обещают ускорение в 4 раза в среднем.
(19)
«то, что нельзя увидеть при беглом просмотре, можно отследить на этапе тестирования»
Как можно отследить излишнее количество виртуальных таблиц на этапе тестирования?
На курсах по Эксперту рассказывали про проблемы производительности из-за репликации сеансовых данных на нескольких серверах. Самому с крупными клиентами работать не приходится, поэтому хотел бы уточнить у Вас — сталкивались ли Вы с какими-либо проблемами производительности из-за репликации сервисов кластера?
Также вопрос — вы постоянно мониторите данные технологическим журналом? (ЦКК) Если да, то не сказывается это на производительности? При таком количестве пользователей событий CALL и SCALL будет невероятно много и какую-никакую загрузку это будет давать.
(21)
Конкретно этот момент можно увидеть ещё при беглом анализе кода. Когда запрос содержит большое количество виртуальных таблиц, можно на него обратить внимание.
Не нравится такой подход — можно при тестировании обращать внимание на время выполнения операций.
Можно отслеживать замеры производительности.
(15)
И сеансы и соединения. Например при отборе по ЖР, когда в качестве отбора указывается конкретная ссылка на объект ИС. ЖР зависает намертво, иногда настолько, что снятие сессии не обрывает соединение. В итоге невозможно обновить конфигурацию, даже если пытаться удалить соединение вручную, оно якобы удаляется и тут же появляется снова. Помогает только перезапуск rphost’ов.
После перезапуска rphost’ов по превышению размера потребляемой ОЗУ появляются сессии-фантомы. Пользователь выключил компьютер не дождавшись выхода из 1С, например программист 1С выключил компьютер будучи находившись в конфигураторе. После перезапуска rphost’ов его фантомная сессия восстанавливается и висит в консоли наряду с еще 50 фантомными сессиями.
(15)
Наши администраторы не дают прямого доступа к серверу. Максимум что доступно — консоль администрирования 1С.
А немного отвлеченный вопрос — почему централизованное решение? Я правильно понял что розница с торговыми точками? На всех торговых точках есть дублированный канал интернет и нужное сетевое оборудование?
(0) Интересно было почитать
(15) Чудны дела, твои…. зависшие фоновые задания, сеансы и/или блокировки — известный бич, все его знают и в случае глюков сервера — чистят сеансовые данные. А вы говорите «не сталкивался». Поделитесь опытом, чтоль — как так пролучается у вас?
(21)
Виртуальных или временных?
(16) О да, мы пробовали выделять человека. Он взвыл через неделю. Выделили другого — продержался не сильно дольше. Пробовали проверять друг за другом по очереди или по просьбе — поехало, хотя и со скрипом. Ревью кода — нудная вещь, выжимает соки.
(30)
Можно чуть подробней? Что конкретно изматывает?
Я делаю ревью, правда постфактум. Запускаю конфигуратор: Конфигурация — Хранилище — Обновить конфигурацию из хранилища.
Затем Конфигурация — Сравнить конфигурации. 1. Конфигурация базы данных, 2. Основная конфигурация. В диалоге сравнения анализирую внесенные изменения с момента последней проверки. Потом жму F7. На следующий день всё заново. Занимает не болше часа в день.
(30)
Человеку должно нравиться то, что он делает. Иначе от любой работы взвоет. Это бесспорно.
(29)
Да, тут в ветке идет обсуждение не виртуальных, а временных таблиц.
(31)
Я тоже так делаю.
Но считаю что это малоэффективно, да и времени на это постоянно не хватает, из-за чего детально анализирую только код тех разработчиков, которые по моему мнению не имеют достаточно высокого уровня, чтобы писать оптимально. По крайней мере явные проблемы у ведущих зубров наблюдаются исключительно редко.
(28)
Коллега, как вы чистите сеансовые данные?
(35) стоп сервера, очистка каталога сеансовых данных, старт сервера. В многомашинной среде — стоп всех машин, чистка всех каталогов, старт всех машин.
(31) Мы использовали git + atlassian crucible. Если бы мы заставляли смотреть код в Конфигураторе через «Сравнение» — у нас бы случаи самоубийств начались. А если замечание возникло — ногами идти к человеку и выдергивать из контекста?
В Crucible к строке кода можно оставить комментарий, автору строки придет письмо. Тут же из коробки переход к таск-трекеру, чтобы посмотреть, а что за задача решалась, и т.д.
Выматывало именно то, что нужно находиться в контексте решаемой задачи, при просмотре ее кода. Когда людей хватало — это решалось внутри команды и было хорошо. Потом кризисы-шмизисы, людей, способных анализировать код, стало меньше, а задач на них — стало больше. Ревью превратился в обузу и заглох.
(4) К сожалению, фоновая реструктуризация и расширения не совместимы
Можно поподробнее.
(12)
Проще всего почитать на ИТС.
(20)
Это одна из основных причин перехода на 8.3.12 (сейчас мы на 8.3.10), прямо сейчас уже разливается на точки новый движок, надеюсь перейти в течение 1-2 недель, обязательно попробуем.
(22)
У нас отказоустойчивость в 0 установлена, к сожалению на текущем движке (8.3.10) есть критический дефект, не позволяющий на нашей площадке включить отказоустойчивость.
(23)
Что вы, упаси господи, ЦКК к большому ТЖ подпускать нельзя ни в коем случае. ТЖ анализируется с помощью самописных механизмов на C#, затем в ЦКК загружаются в виде внешних счетчиков.
А так да, ТЖ собирается постоянно, проблем никаких нет, это прямая рекомендация от 1С — чтобы ТЖ работал непрерывно. Естественно пишется на отдельные диски, не на СХД, где находится база данных.
(26)
Мы с шефом уже участвовали в похожем проекте и предыдущее решение было сделано распределенным. Опыт показал, что централизованное решение в нашей ситуации будет проще в поддержке и более «вкусно» для бизнеса.
Да, это розница с магазинами.
На всех торговых точках есть дублированный интернет канал, так как специфика работы такова, что без связи работа магазина невозможна.
(28)
Тут я пожалуй этот вопрос в отдельную статью выделю.
(40) Там про практический опыт нет ничего, интересно, что из перечисленного там используется и как используется.
(41) не могли бы отписаться о результатах по возможности? Настроить получилось, но протестировать в реальной среде не получилось. Интересны результаты на крупных данных
(42) хм, понял. Довольно инетересно. Спасибо за ответ.
А можете в кратце написать про критический дефект? Или ссылку на багбоард?
(39)
Описал чуть подробней в отдельной статье, пример №3.
(46)
Самое главное — возможность разделить требования назначения функциональности по разным серверам. Это видно на схеме, специально её привел.
Второе — техподдержка от партнёра франчайзи, но здесь главное что мы нашли правильного франча, а в самом франче — грамотного специалиста. Не всем так везет )
(17)
Объем базы 2.6 Тб
Документов в день порядка 200 тысяч.
В самой объемной порядка 300 млн. Это самописный регистр сведений по состоянию сим-карт.
ЖР только для ошибок. Но для информации — первое, что делает любой специалист по оптимизации системы — включает старый формат журнала регистрации. Это уже обсуждалось тысячу раз. 1С никогда не признает официально, что ошиблась с sqlite. но это так.
Про индекс полнотекстового поиска не скажу, как то видимо не упирались в него, а может он отключен у нас, исследую вопрос.
(42) и почти в каждой версии тот или иной дефект, а еще 8.4 с zookeeper как-то замерзла и не едет..
(51) Что значит не признают проблему с sqlite?
Этот вопрос даже в профа по техническим вопросам включен помнится.
По дефолту старый формат не возвращают — это да.
Подобная архитектура просуществует до первого глобального сбоя или до череды инцидентов приводящих к простоям. Таков мой прогноз.
Хотелось бы, конечно, узнать название компании?
Какой штат 1С-ников?
(54)
А какую Вы могли бы предложить альтернативу?
(55) Например (есть и др. варианты):
Розницу(разумеется переделанную под свои особенности) разворачиваем на точках(файловый вариант).
Делаем базу-шлюз(серверный вариант)( ведем там НСИ также) на которую, как на елку, навешиваем web-сервисы для обменов через json, например.
Делаем центральную базу (ЦБ) , куда после выверки в базе-шлюзе сыпятся отчеты о розн. продажах, результатах инвентаризаций, приходах/расходах и тд.Сегментацию, планирование, ценообразование, маркетинг ведем в ЦБ.
Актуальные розничные цены держим в базе-шлюзе забирая актуальные из ЦБ.
Логистику вообще желательно выделитьв отдельную базу, которая опять же через базу-шлюз будет контактировать с центральной базой.
В базе-шлюзе держим инфу о версиях клиентов и инициируем обновления при необходимости.
Много, конечно нюансов, но сбой базы-шлюза или ЦБ никаким образом не отражается на клиентах (точках).
(56) Это еще спорный вопрос, что лучше: пасти весь этот зоопарк с обменами или вовремя предотвращать инциденты.
(53)
Можно ссылку про sqlite?
(48)
К сожалению он не опубликован на bugboard, так что не могу.
(54)
Ну мы уже 3 года работаем. Что вы подразумеваете под глобальным сбоем?
Штат 1С-ников, 6 аналитиков, 12 разработчиков, 8 человек поддержка 2 линии, 22 человека поддержка 1 линии.
(57)
Мы пасли такой зоопарк на предыдущем месте работы, тоже около 2 тысяч магазинов. Обмены это была боль. Поэтому решили на текущем проекте эту боль избежать. Пока ни о чем не жалеем )
(60) Олег, а ты в Цифрограде не работал?
(53)
При создании новой информационной базы в качестве формата по умолчанию используется последовательный формат журнала регистрации.
Источник:
(54) На самом деле тут считать надо, оба варианта имеют право на жизнь, вопрос бюджета…
(30)
О, да))
Ура! Крупные системы потихоньку начинают делиться опытом. Очень надеюсь, что будут последователи.
Олег, почему отказались от апдекса и перешли на среднее время? По идее апдекс более чувствителен к изменению времени операции.
(66)
Давайте тут тоже отдельной статьей отвечу.
Синхронная реплика AlwaysOn не доставляет хлопот?
Мы оставили только асинхронную из-за рисков увеличить время транзакции в основном узле.
(68)
Нет, не доставляет.
(62)
Работал.
(53) Уже вернули. В версии платформы 8.3.12 по умолчанию последовательный формат журнала регистрации.
Сеансовые данные это так называемый кэш сервера 1С? Находится в папке srvinfo?
(72)
Да.
https ://its.1c.ru/db /metod8dev#content:5860:hdoc
(5) почему не сделать на точках отдельные экземпляры базы и обменом сливать все в центральную?
(75) см (61)
(19) чем Вам виртуальные таблицы не угодили? Или все-таки временные?
По поводу долгой реструктуризации огромных таблиц. Есть один финт, который позволит провернуть ее намного быстрее, но работает только при добавлении нового реквизита. На SQL реструктуризируемая таблица переименовывается, создается пустая с новым реквизитом и запускается реструктуризация. Т.к. данных нет, все происходит в считанные секунды, правда, потом средствами SQL необходимо перегнать данные из старой таблицы в новую. Сильное читерство, но иногда спасает, когда без вариантов.
В свете разговоров по оптимизации запросов вопрос. Никто не пробовал написать оптимизатор запросов? Если бы такой продукт появился, вы бы его приобрели?
(44)
А от скорости каналов сильно зависите? Какова минимальная скорость канала для безпроблемной работы кассы в удаленной точке длительное время?
(79) в таком контексте
(80)
Зависим скорее не от скорости канала, а от стабильности пинга и скорости света. На ДВ конечно операции выполняются немного медленней, чем в Москве. Примерно процентов на 30-50.
Сейчас у нас в регламентах прописано 4 Мбит, но это не только для 1С, для всего. Аварийный канал установили в 1 Мб. Для 1С в принципе достаточно будет и 512 Кбит.
(77)
Конечно же, временные. 🙂
И все про себя подумали, но постеснялись спросить: Уж не Магнит ли это? -:)
(84) Магнит симкартами торгует? Не знал…
(50)
И фактически единственное полезное отличие.
Грамотный партнер и специалист у него к КОРП лицензиям отношения не имеет.
(8) Есть решение такой проблемы, перед пробитием чека писать в текстовый документ данные, потом при старте проверять успешно закрылся чек или нет, если нет то погружать в БД.
такой лог спасал нас при работе не только на 1с.
(84) Возможно это Билайн. Как раз 3 года назад они людей набирали на проект внедрения розницы на 3 тыс магазинов и все должно было быть в единой базе.
(15) low priority locks — используете?
(69) можете подробнее рассказать о схеме физических серверов?
Как между собой пересекаются WSFC+AG SQL и 1C-кластер? Это везде физически разные сервера? Или есть пересечения?
Хотелось бы для себя прояснить возможно ли вообще такое «пересечение», если у AG должно быть общее виртуальное имя, а у серверов 1С адреса должны быть разные.
(95) К сожалению у меня нет ответа на ваш вопрос, я его даже не понял, что такое AG, WSFC и пр.
(98) AG — availability groups (группы доступности), WSFC — Windows Server Failover Cluster.
Например, если взять два сервера, настроить failover, alwayson (например, с синхронной репликой). Они будут иметь одно имя подключения.
Теперь, например, на эти же сервера поставить два центральных 1с сервера.
Имеет место такое быть у вас? Или 1с и SQL у вас не встречаются на одном сервере? Или все исключительно на разных?
Проконсультируйте про мой пример: серверы 1с сохраняют свои уникальные имена? Они никак не пересекаются с SQL-ной отказоустойчивостью и не мешают друг другу? Или могу возникнуть вопросы?
(99) Сервера 1С и SQL разнесены на физически разные машины. Серверы 1С каждый имеют свое уникальное имя, два из них центральные (по одному на ЦОД), отказоустойчивость выключена, остальные — соответственно не центральные. Всего app серверов на текущий момент 5. В ближайшее время будет выделен сервер лицензирования, пока он расположен на одном из центральных серверов, это самое узкое место, которое фактически сводит отказоустойчивость на нет.
SQL состоит из 4 машин, два в режиме Synchronous commit, еще два — Asynchronous commit. Первые две машины имеют единое кластерное имя, на которое откликается тот из серверов, который в данный момент является активной нодой.
(100)
Из описаний в интернете и примеров применения технологии так и не понял: синхронные и асинхронные реплики распределяют между собой нагрузку? Балансировка между ними есть? Или только первичная нода все тянет, а вторичная — резерв для мгновенного переключения?
(101) Распределения нагрузки нет, всё тянет первичная нода, вторичная — резерв.
Теоретически на асинхронные реплики можно посадить пользователей, которые только читают данные, но 1С к ней подключить без грязных хаков не получится, так как база read only, а 1С хочет писать во временные таблицы.
(102) спасибо за ответ.
Про асинхронные реплики наслышан. Как к ним обращаться — в теме.
Про синхронные — грусть(.
(5) Олег, спасибо за описание. Только сейчас попались Ваши статьи на глаза.
Подскажите, тонкие клиенты подключаются по TCP или HTTPS? На схемах (в этой статье и других) я не вижу web-сервера, кроме того, который обслуживает различные HTTP и веб-сервисы. В комментариях также не нашел упоминаний, кроме того, что везде тонкий клиент.
Правильно ли я понимаю, что используется TCP-подключение внутри VPN?
Есть ли какие-то противопоказания к использованию HTTPS, о которых можете рассказать?
(114) Используется TCP. Противопоказаний против htts не знаю, кроме того, что на старте проекта мы не умели его готовить, а времени учиться не было.
(50)подскажите контакт 🙂
(116) к сожалению информация уже устарела, теперь растим человека в штате.