







В данной статье будет рассмотрена методика удаления данных запросом в MSSQL-студии.
Отказ от ответственности
Делайте архив.
Проверяйте, пожалуйста, текст скрипта перед выполнением. Понимайте, что делаете. Помните, что ответственность лежит целиком на Вас!
С особой внимательностью рекомендую проверять скрипт перед выполнением, если в Вашей базе есть случаи, когда период записей регистров отличается от даты регистратора.
Основная цель применения
Прикладная задача, в процессе решения которой родилась данная методика: свертка базы (ввод остатков, удаление документов и движений регистров в прошлых периодах). То есть: удаление документов (вместе с табличными частями, разумеется) до определённой даты, и их движений. Иногда обработка использовалась для удаления данных с более сложными условиями, но они менялись вручную уже в SQL-студии.
Предыстория
Проблема: свертка стандартными средствами происходила неприлично долго. Точней, именно этап удаления старых данных. Остатки вводятся быстро, а вот удаление движений регистров, пометка на удаление документов, само удаление — по нашим оценкам на наших объёмах (500ГБ) заняло бы недели.
Решение: удалить данные средствами SQL, чтоб миновать механизмы платформы 1С, ненужные при данной операции, но отнимающие драгоценное (в рамках данной задачи) время.
Препятствия: Данные в SQL хранятся в разных таблицах. Таблиц много, как их связать — не всегда понятно. То есть мало очистить сам документ (шапку), надо очистить также данные табличных частей, и движений документа. Движения по разным регистрам. Для одного документа регистров может быть много. Каждый регистр в свою очередь хранит данные также в нескольких таблицах. Наименования таблиц — неосмысленные.
Теория
Варианты (операторы) удаления в SQL.
- DROP — полное удаление таблицы из структуры данных (вместе с данными). То есть очищаются не только данные, но и метаданные. Работает мгновенно.
- TRUNCATE — полная очистка таблицы с сохранением структуры таблицы (очищаются только строки таблицы, колонки остаются прежними). Работает мгновенно.
- DELETE — удаление записей в таблице по определенному условию. Занимает определенное время.
Оператором DROP на практике я почти не пользуюсь. TRUNCATE — иногда пригождается, когда по условию задачи возможно удалить всю таблицу (данные не нужны совсем, либо можно после удаления загрузить откуда-то только нужную часть). В остальных случаях (в том числе в рамках данной методики) используется DELETE.
Для того, чтоб удалить данные целостно по ряду связанных таблиц документа (шапка, ТЧ, движения) — сперва я рассматривал вариант честно отобрать данные документа по дате, а потом уже связать с другими таблицами через JOIN. То есть очистить поочередно все связанные таблицы, после чего удалить основную (так как только в ней есть реквизит, по которому решаем удалять объект или нет)
В итоге была выбрана и реализована следующая стратегия
- Удаляем движения регистров, которые двигает нужный вид документа, по связке с основной таблицей документа
- Удаляем строки табличных частей документа, по связке с основной таблицей документа
- Удаляем основную таблицу документа
- Очищаем целиком таблицы журналов, где участвует документ (нехорошо, но в нашем случае — не критично, можно и не трогать)
- Опционально можно очистить таблицы регистрации изменений для обмена
Таблиц много + названия неудобные + конструктора запросов нет = очень много рутины с высокой вероятностью ошибки и дороговизной ошибок. Поэтому был создан инструмент, берущий большую часть рутины на себя.
Устаревшая стратегия (альтернатива)
Первое решение, от которого я впоследствии отказался. Хотя вначале оно казалось более удобным и простым. А именно — очистить шапку. А потом все связанные таблицы поочередно, у кого нет "пары" в основной таблице (ссылка/регистратор = "битая" ссылка).
Данный вариант не работает для движений документа. Так как после удаления основной таблицы документа — IS NULL даёт истину после соединения таблицы движений регистра и основной таблицы документа в 2х случаях
- Когда действительно записи сделаны этим видом документа, и эти документы были удалены (тут всё хорошо)
- Когда записи были сделаны документами других видов, и в этом случае записи удаляются ошибочно (так нельзя!). Чтоб решить эту проблему надо связывать таблицу регистра со всеми возможными типами регистраторов, а это слишком сложно
Вобщем порядок был такой (отличия в пунктах 2 и 3)
- Удаляем записи регистров, которые двигает нужный вид документа, по связке с основной таблицей документа
- Удаляем основную таблицу документа
- Удаляем записи табличных частей документа, у которых Ссылка после соединения = IS NULL
- Остальное (как в основном варианте, журналы и регистрация изменений)
Но в процессе эксплуатации выяснилось, что удаление по пустой шапке на больших объёмах работает медленно, поэтому по умолчанию от данной стратегии пришлось отказаться (по крайней мере, на нашем примере), но эта опция по-прежнему доступна по соответствующей галочке на первой закладке.
Особенности
- Доступна опция порционного удаления.
- На данный момент, обработка существует только для обычного приложения.
- Обработка сама не подключается в SQL и не запускает скрипт там на выполнение. Только формирует текст скрипта. Считаю, что скопировать-вставить нетрудно, а если нет навыков работы в SQL-студии, то и запускать подобное, возможно, рано.
- Исходный код открыт.
Порядок действий
- Делаем архив
- Составляем список удаляемых данных (самые большие таблицы, которые удалить стандартными средствами слишком долго / неудобно / не хочется разбираться с тем, что удаляемые данные зарегистрируются к обмену и "пойдут" куда не надо)
- Запускаем обработку, при желании сверху ставим отбор
- Выделяем в списке нужные виды документов (обязательно выделяем ОСНОВНЫЕ таблицы, то есть таблицы шапок, а не табличных частей)
Можно сразу несколько с Ctrl-ом (доступно множественное выделение) - Переходим на вторую закладку и выбираем нужный нам вариант удаления (например по дате)
- Нажимаем соответствующую кнопку по формированию скрипта
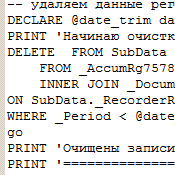
- Получаем в окне сообщений готовый скрипт на удаление данных на языке SQL
- Копируем в буфер, вставляем в SQL Management Studio
- При надобности корректируем. Например через замену (Ctrl+H) можно заменить "<" на ">=", и получится скрипт удаляющий данные документов не до указанной даты, а, наоборот, — начиная с неё. Либо отбор по дате можно заменить на пометку документа на удаления (_Marked = 1). Либо чтоб удалялись только непроведенные (_Posted = 0).
- Запускаем на выполнение, дожидаемся завершения, наблюдаем за статусом на закладке Messages
- Проверяем результат в 1С
- Обязательно пересчитываем итоги затронутых регистров накопления и бухгалтерии, так как таблицы итогов не обрабатываются
При желании протестировать/посмотреть "что именно будет удаляться" предусмотрена соответствующая опция (галочка справа внизу), в этом случае скрипты будут формироваться с оператором SELECT, а не DELETE. Можно выделить нужный кусок, запустить на исполнение, посмотреть результаты, прежде чем запускать на удаление.
Вместо эпилога
Конструктивную критику, вопросы и пожелания — прошу в комментарии!
Спасибо за прочтение!
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Обработка просто огонь, удобно делать тестовые копии с урезанными данными!
Полезна для изучения структуры таблиц в SQL
1. Удобно было бы из ОСНОВНЫЕ таблицы заложить в фильтр (решается сортировкой нужной колонки)
2. Вывод сообщений скрипта в SQL немного не удобен, особенно при обработке большого количества документов
3. Сдвиг дат
Иногда проскальзывает сообщение ‘Недопустимое имя столбца «_Period»‘
Похоже в скрипте
(3) Спасибо большое, комментарии приняты, постараюсь реализовать/поправить, но из-за нехватки времени сроки обещать не могу.
По 1 — есть некое решение уже, сам столкнулся, доведу чуть до ума, поделюсь
2. Сейчас есть неудобство, когда начинает чистить какую-то таблицу — сообщает о начале вместе с сообщением о завершении. Не знаю с чем связано, но постараюсь решить. Если есть предложения — внимательно слушаю.
3. Не понял честно говоря, о чём речь
4. ‘Недопустимое имя столбца «_Period»‘ — Да, тоже замечал, такое бывает когда идёт попытка очистить регистр, у которого регистратором является выбранный документ, но регистр непериодический. В этом случае регистр не очищается. Посчитал нестрашным для наших задач, поэтому пока не успел поправить.
UPD Обновлена версия обработки. Бета.
[*] Редизайн интерфейса, повышение юзабилити.
[+] Добавлена возможность целостного удаления документов на отдельной закладке
[+] Частично реализована опция порционного удаления. Порциями удаляются данные при выборе произвольной таблицы, а также при целостном удалении документов — основная таблица документа. Продолжение следует.
[*] Рефакторинг системы вывода сообщений. Теперь сообщения выводятся мгновенно, и выглядит всё более коротко и информативно
(3)
2. Вывод сообщений скрипта в SQL немного не удобен, особенно при обработке большого количества документов
Улучшено в новой версии
[↑] Доделано и протестировано порционное удаление
[fix] Исправлено
Ух, крутая штука, скоро пригодится!
Вчера пользовался, работает корректно, но остаются ссылки в «присоединенных файлах». Наверное, вручную буду удалять.
(10) Спасибо за обратную связь!
Ссылки в «присоединённых файлах» (то есть ссылки на удаляемые произвольные документы в произвольных справочниках) как почистить на уровне SQL в процессе свёртки базы — пока не вижу вариантов… Видимо да, проще на уровне 1С сделать
[+] Добавлена возможность удалить все записи выбранных регистров накопления ДО определённой даты
После свертки очередной базы выяснилась одна особенность-недоработка. Стали сверять остатки после свертки на свёрнутой базе и оригинальном исходнике. Обнаружили расхождения — движения документов без регистратора.
Чтоб удалить их был добавлен новый функционал в обработку, а именно удобное удаление движений регистров накопления без привязки к документам до определённой даты
Свёртка — дело хорошее. Но как убедиться, что остатки свёрнутой базы совпадают с оригинальной базой? Отдельная интересная задачка.
Можно выгрузить в табличный документ и сравнить через «Сравнить файлы», но хотелось сделать что-то удобней, быстрее и надёжней.
Есть методика, когда обрезанная база подключается через универсальный веб-сервис в оригинальную базу, выполняет произвольный запрос (чтоб получить «оригинальные» остатки до обрезки) и сверяет другим запросом со свернутой базой. См. скрины.
Если кому-то интересно — ставьте лайки, пишите что-нибудь. при наличии спроса и времени — сделаю чтоб запускалось на произвольной конфигурации и опубликую!
Спасибо.
Было бы круто добавлять произвольные отборы на документы
(14)
Было бы интересно посмотреть на такую обработку.
, а не проще com-соединением получить остатки из базы?
(16) COM — хорошо, но очень он требовательный. Если базы для сравнения на разных серверах и не очень толстым каналом, COM, к сожалению — не вариант.
ОК, принято, обязательно оформлю через какое-то время! Наверное уже в марте. Если срочно — напишите в личку пожалуйста
Добрый день.
Извините, не увидел, а с БП 3.0 как отработает Ваша обработка?
(18) Здравствуйте! Думаю, что точно так же, как и на любой другой конфигурации. Но непременно в режиме обычного приложения её придётся запускать для получения скрипта. Если возникнут проблемы — пожалуйста, пишите, готов попробовать доработать в марте.
Добрый день.
В марте не актуально.
Спасибо.
Попробовали.
При запуске в режиме 8.2 отработало штатно.
За это отдельно спасибо.
Удаление объектов на нашей базе (100 ГБ на SQL) прошло ровно и заняло чуть более 2-х часов.
А вот ТиИ длится уже 12 часов к ряду…
Пока «рубит» версии объектов.
Как долго будет продолжаться? Не знаю.
Посоветуете что-нибудь?
(20) Всем добрый день.
…
Судя по всему, удаление версий объектов будет идти около 20 дней.
За сутки прошло 5%.
Увы.
Без решения этого момента выигрыш от обработки полностью теряется.
На сегодня отработала штатная свёртка.
Жаль.
Первые впечатления были более позитивные.
к сожалению, в том виде и с теми комментариями (инструкциями/объяснениями) как есть, использовать обработку бесполезно.
(20) Спасибо за отзыв!
А что значит «версии объектов»? Регистр сведений, откуда хочется убрать битые ссылки на документы? Или…?
(21) Почему выигрыш теряется? Иными словами, что делаете? Какова цель операции? Чего достичь хочется? Уменьшить размер базы удалением ненужных данных, основная часть которых находится в «версиях..»? Или…?
Добрый день.
Отвечу по пунктам.
1. Почему выигрыш теряется?
Идея была в сокращении времени на удаление объектов после штатной свёртки баз.
Этого не произошло, т.к, используя штатную свёртку удалось закончить много раньше.
2. А что значит «версии объектов»?
Согласно рекомендаций, после удаления информации на дату, требуется провести ТиИ.
Это нормально.
Но то, что за трое суток прошло только 5 % от проверки логической целостности версий объектов в регистре сведений, это не нормально.
У меня за 40 часов отработала штатная свёртка.
Отсюда понимаю, либо что-то не доработано в обработке, либо что-то не досказано в описании.
(24)
На вашем месте я бы пробовал выгрузить нужные версии до свёртки (например в XML).
Потом сворачивал базу, удалял данные (регистры, документы).
Потом удалял бы таблицу версий целиком.
А потом бы загружал из файла нужные версии.
А так — получилось, что сами объекты удалены, а версии — остались.
Хотя всё равно конечно странно, почему ТиИ идёт так долго.
Возможно, оборудование не справляется.
(24)
Обработка не удаляет наборы записей регистров, не подчинённых регистратору (в режиме удаления документов с движениями и ТЧ). Я надеялся, что это понятно из интерфейса
Добрый день всем.
После серии проб и ошибок…
***
Ситуация: база БП КОРП 100 Гб. на SQL.
По совокупности причин, приняли решение обрезать на 01/01/2019г.
С помощью стандартной свёртки от 1С рассчитали остатки и создали операции ввода начальных остатков.
Типовое удаление старых документов прервали, ибо бессовестно долго и нет гарантированного результата.
Время: 1,5 часа.
С помощью данной обработки полностью очистили версии объектов.
Время: 30 минут.
После этого, с помощью данной обработки, удалили документы до даты.
Заняло 70 минут.
После этого пересчитали итоги.
Заняло ~1,5 часа.
Нашли ~ 20 «потерянных» записей и отработали их вручную.
База работает штатно, весит 25 Гб.
***
Спасибо.
(27) Очень рад, Александр! Спасибо за отзыв!
Добрый день, а по организации умеет удалять?
(29) Нет.
Можете попробовать вот эту разработку
Здравствуйте ! Обработка очень удобна, Спасибо. Есть замечания:
При тестировании сначала сделал выборку данных Sel ect используя удаление порциями… скрипт отрабатывает с ошибкой.
Для исправления немного изменил процедуру:
Показать
(31) Шикарно, исправил, благодарю, коллега!