
Коротко о методе:
Описание взято на сайте: wikipedia.org.
Сходство Джаро — Винклера представляет собой меру схожести строк для измерения расстояния между двумя последовательностями символов. Это вариант, который в 1999 году предложил Уильям Э. Винклер (William E. Winkler) на основе расстояния Джаро (1989, Мэтью А. Джаро, Matthew A. Jaro).
Каждый символ строки сравнивается со всеми соответствующими ему символами в . Количество совпадающих (но отличающихся порядковыми номерами) символов, которое делится на 2, определяет число транспозиций. Например, при сравнении слова CRATE со словом TRACE, только ‘R’ ‘A’ и ‘Е’ являются совпадающими символами, то есть m=3. Хотя ‘C’ и ‘T’ появляются в обоих строках, они дальше, чем на 1, то есть floor(5/2)-1=1. Следовательно, t=0 . В сравнении DwAyNE с DuANE соответствующие буквы находятся уже в том же самом порядке D-A-N-E, так что никаких перестановок не требуется.


Замечено, что алгоритм превосходит по производительности некоторые другие алгоритмы (например.: алгоритм "Расстояние Левенштейна").
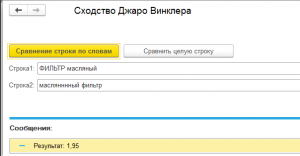
Также присутствует функция сравнения текста по словам. Сначала обе строки разбиваются по словам. Затем поочередно сравниваются и максимальный результат сравнения идет к общему зачету. Максимально возможный результат сравнения равен 1. Соответственно общий максимальный результат может быть равен числу сравнений слов в строках. Пример: сравниваем "зеленая трава" и "трава зеленая" результат будет 2. (1+1).
Обработка создана на управляемых формах, но для программистов не составит труда перенос на обычные формы. Возможен вариант оценки результата в процентах.
Тестировалась: 1С:Предприятие 8.3 (8.3.10.2580) УТ11.3.4.93.
Метод может пригодиться для подбора и сортировки аналогов номенклатуры.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Можешь простыми словами объяснить, что означает результат?
(3) Если речь идет о сравнении по словам, то результат — это сумма попарного сравнения слов в двух строках. Допустим мы сравниваем две строки: «ааа ббб ввв» и «ббб ггг ааа». Сначала из первой строки берется слово «ааа» и поочередно сравнивается со всеми словами из второй строки: «ббб»-результат =0, «ггг»-результат =0 и «ааа»-результат максимальный 1, т.к. слово идентично. К ЗАЧЕТУ в первой итерации принимается максимальный результат 1. Далее сравнение «ббб» из первой строки, результат тоже будет 1. Прибавляем с общему результату. И наконец «ввв» с результатом 0. Итого общий результат будет 2. Можно его назвать своего рода рейтингом сравнения.
А для сравнения слов между собой применяется алгоритм Джаро-Винклера, функция которого и возвращает результат от 0 до 1.
Тут старожили с «семерки» могут вспомнить внешнюю компоненту, которая делала фонетическое сравнение. Т.е. «Джек Дэниелс» и «Jack Daniels» могла сопоставить.
И, по-моему, даже Jek D@nielz тоже могла находить.
(5)При желании транслитерацию в данную обработку не сложно будет добавить.
Хорошо бы конечно более однозначный результат выводить.. например вычислить максимальный результат и выводить %
(7)Согласен, можно и так. На досуге попробуем.
(6) тут не в транслитерации дело, а именно в фонетике. Т.е. в похожести звучания двух слов/выражений
— вот моя семерочная демо на основе strmatch
на основе этой ВК я столько этих нечетких сравнений для разных клиентов и областей написал…
.
было бы, конечно, интересно провести «соревнование» (не 7 с 8 ;-), а того, как ище одно и второе.
принцип простой. на вход двух программ подаем одинаковый список допустим из 1000 наименований, в т.ч. например, наименования книг с ISBN, фармацевтики, электроники и прочее — то есть достаточно смешанный
далее зрители кидают нам строку. любую. в т.ч. могут и из списка кинуть точное совпадение и с вариациями разными. как захотят.
каждая прога выдает 10 наиболее похожих из списка.
судейское жюри оценивает.
проводим батл из 40-50 раундов.. 😉
.
прикольно, а че… хоть какой-то оживляж…
(на сайте есть и другие подобные решения — их авторов тоже можно привлечь)
если что — пишите в личку.
(10) интересно будет в рамках инфостарт ивента… не более думаю. Подкиньте идею своему другу 🙂
Поддерживаю, интересная идея
Делал такое «Программа для нечеткого сравнения строк FuzzyStringComparison»
(9) Кстати, хорошая идея для разработки.
Как-то очень-очень давно (лет 10 или более назад) — делал такое… ну как делал… нашёл алгоритм то ли на SQL, то ли на C++, разобрал и сделал аналог на 1С, применил в обработках.
и
Сам алгоритм — не разбирал, но проверив показатели схожести на реальных справочниках — понял, что при «коэффициенте похожести» от 80 до 100 процентов — идут, обычно, одни и те-же позиции.
Кстати, есть ещё нюанс по поводу сравнения — это учёт аналогичных английских букв (С, О, А, Р, В…) особенно «С» — это самая злостная клавиша на клавиатуре: например, оператор набирает не глядя на экран «Cjcbcrb», понимает что имеет место очепятка — стирает всё, кроме первой буквы (она то нормальная «С») и далее пишет «Cосиски». Довольно частое явление.
Нужная штука. Спасибо.
Плюсую. Хорошо.
— тоже когда-то делал, но на базе алгоритма нахождения расстояния Дамерау Левенштейна.
надо посмотреть — искал что-то подобное с год назад
надо было номенклатуру для заявок из Экселя подобрать
пришел к выводу что ручками снабженцы быстрее набьют
но мысль осталась
(15)
Фонетика — это скользкая тропа, разработки будет очень много. Например, water, произнесённое англичанином, американцем, индусом и русским (с нашим фирменным русским акцентом) будут четыре разных слова. И это только первый уровень абстракции. Внутри самой Британии акцентов несколько десятков, разных, в Америке северозападные иногда и сами тяжело понимаю, что говорят на юговостоке и т.п.