
Сразу хочу сделать небольшую ремарку относительно моих знаний в этой области: я не могу отнести себя к разряду «линукс-гиков» – ядро по ночам не пересобираю и патчи не накладываю. Но, тем не менее, у меня накопились кое-какие наработки, которыми я с вами сейчас хочу поделиться.
Выгоды OpenSource
Итак, зачем использовать OpenSource в целом и Linux в частности?
Я намеренно не собираюсь затрагивать вопросы денег и открытого исходного кода, мне просто хочется рассказать, какие преимущества при использовании альтернативных OpenSource-инструментов открылись лично мне:
- Первое из этих преимуществ заключается в том, что в мире OpenSource и открытых исходников нет и быть не может версий программ с ограниченной функциональностью и подобными искусственными ограничениями. Как правило, общедоступные в OpenSource разработки будут одинаково вести себя как на учебном (или тестовом стенде), так и в продуктиве.
- Второй плюс, который я для себя открыл – это то, что использование альтернативных инструментов, как ни крути, заставляет нас повышать свои собственные компетенции и взглянуть на выполнение наших задач несколько иначе.
В использовании OpenSource-программ, конечно, есть и минусы:
- То, что нужно поменять подход к решению задач – это одновременно и плюс, и минус.
- На пути к цели вам нужно будет четко понимать, что вы хотите сделать и как это сделать.
- Найти решение методом «тыка», скорее всего, не получится – вам неизбежно придется некоторое время потратить на поиск и изучение материалов.
Это те затраты, которые потребует использование альтернативных инструментов.
Но здесь есть нюанс:
- Можно платить на регулярной основе вендору коммерческого ПО.
- А можно вкладывать средства в повышение компетенции собственных специалистов, а уже они, следуя инженерному подходу, будут автоматизировать рутинные операции, такие как настройка и обслуживание инфраструктуры; подготовка тестовых площадок, автоматическое тестирование создаваемых продуктов.

В этом случае использование OpenSource-продуктов поможет научиться инженерному подходу:
- Сами продукты бесплатны и общедоступны, их можно легко скачать и попробовать.
- Так как исходные коды доступны, есть возможность изучить внутренности, посмотреть, как это работает (или не работает), применить эти возможности на своих проектах и при желании что-то к этому добавить.
Это к вопросу обмена компетенциями.
Несколько слов об эффективности – я всегда готов агитировать за автоматизацию рутины: сделал что-то руками два раза подряд, подумай, как это можно автоматизировать.
- Можно использовать для автоматизации какие-то bat-ники, shell, cmd-скрипты.
- Но лучше реализовать автоматизацию на более высоком уровне – такую, как на слайде.
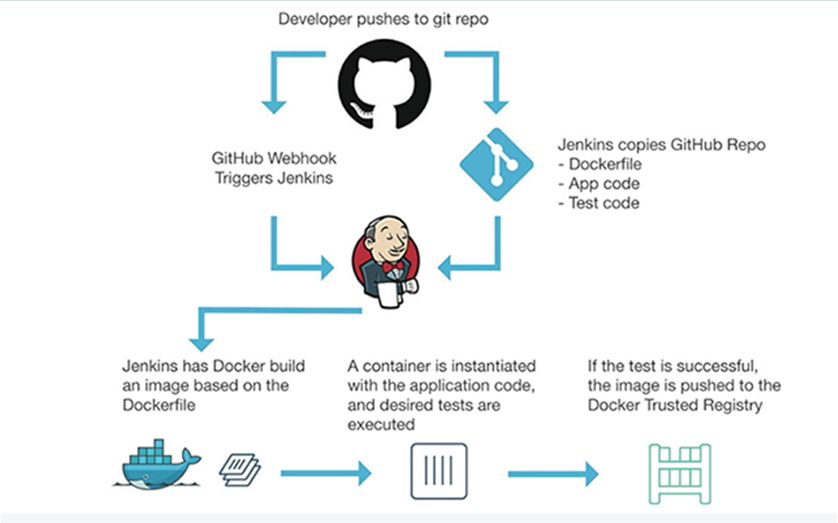
Это все, что я хотел сказать про идеологию.
Инфраструктура
Теперь про конкретные инструменты и то, где их можно использовать.
Вот всем известная картинка, где показана типовая схема инфраструктуры при работе с кластером серверов 1С.
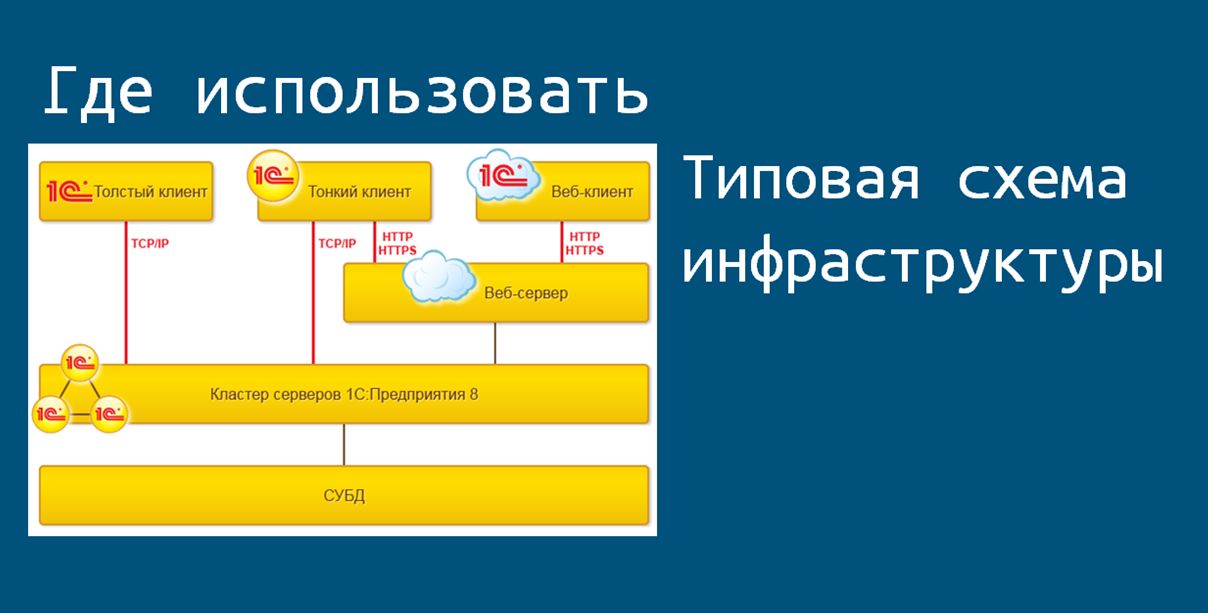
Какие составляющие этой схемы мы можем перевести на платформу Linux?
Оставим в стороне рабочие станции пользователей, пусть они работают на Windows, как привыкли (хотя и здесь есть примеры успешного перехода). И остановимся на серверном ПО – использование альтернативной платформы в этой области, как правило, наименьшим образом может повлиять на работу любимых бухгалтеров.

Развернем эту схему горизонтально и рассмотрим ее в разрезе конкретных используемых OpenSource-разработок. Здесь мы видим только один слой, где находится продуктивное окружение.
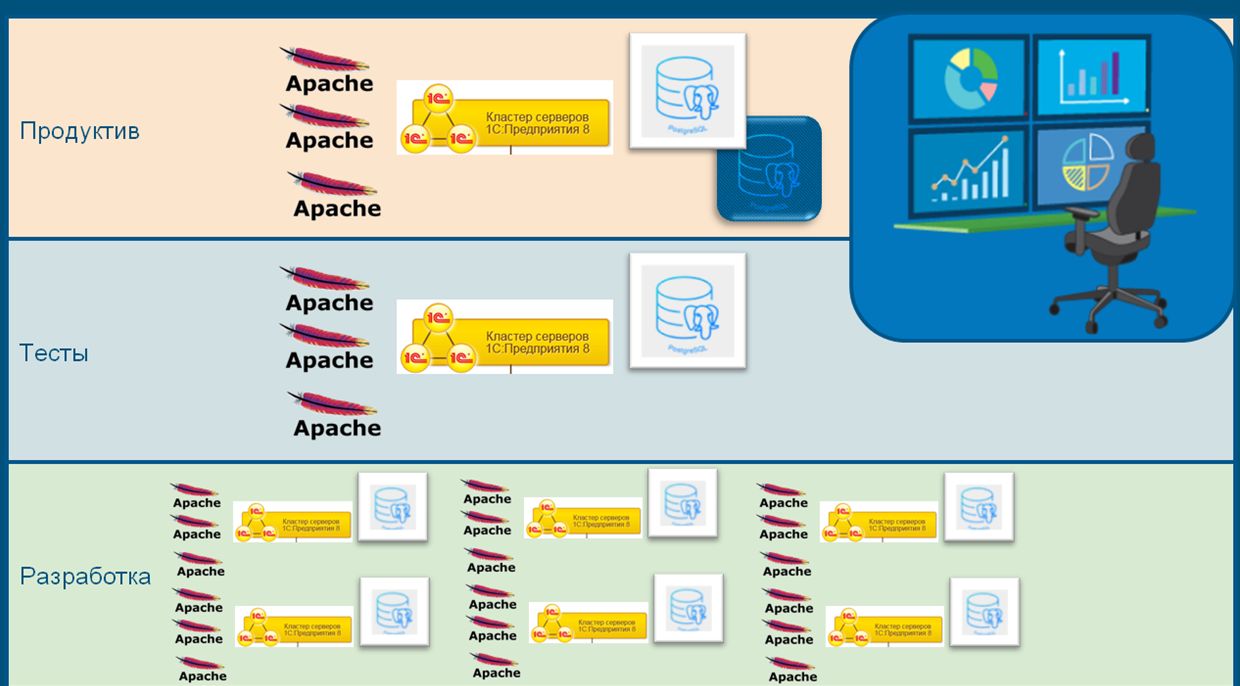
Но в реальности слоев гораздо больше:
- Есть еще и тестовое окружение, где производится приемочное тестирование.
- Также у каждого разработчика есть отдельная «песочница», где он может проводить эксперименты и работать, не мешая остальным.
- И еще неплохо бы все эти слои покрыть мониторингом и сбором статистики.
Соответственно, на выходе мы получаем несколько типов используемого ПО. Давайте по порядку их рассмотрим.
Виртуализация
Начнем с самого нижнего уровня – с голого железа.
Сейчас повсеместно наблюдается тренд по использованию виртуализации – с этим можно даже, наверное, не спорить. Мы виртуализацию используем.

Есть большой выбор OpenSource-продуктов, которые можно попробовать и, если не страшно, внедрить у себя в Production.
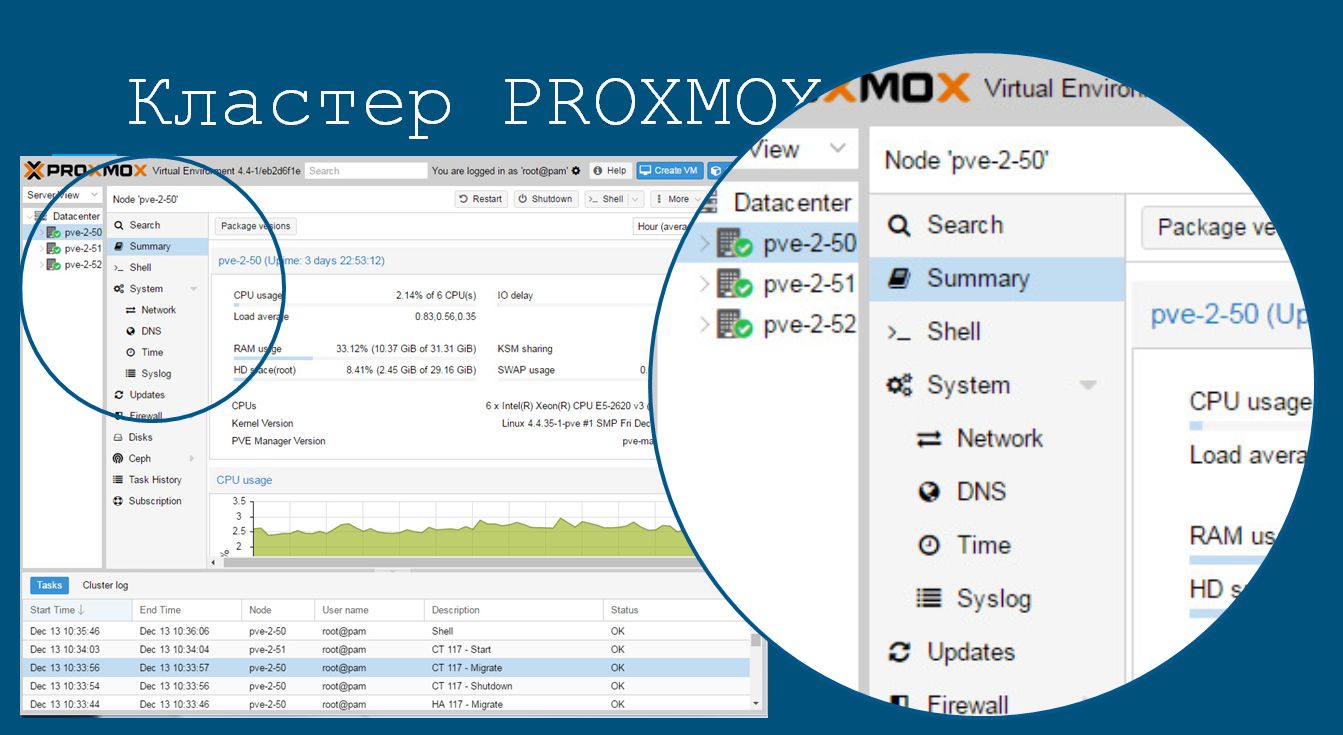
Для быстрого развертывания кластера виртуальных серверов можно взять дистрибутив Proxmox. Его установка на один узел занимает около 15 минут, умножаем на количество необходимых узлов и прибавляем еще минут 30 на настройку кластера. При этом лист аппаратной совместимости у Proxmox шире аналогов.
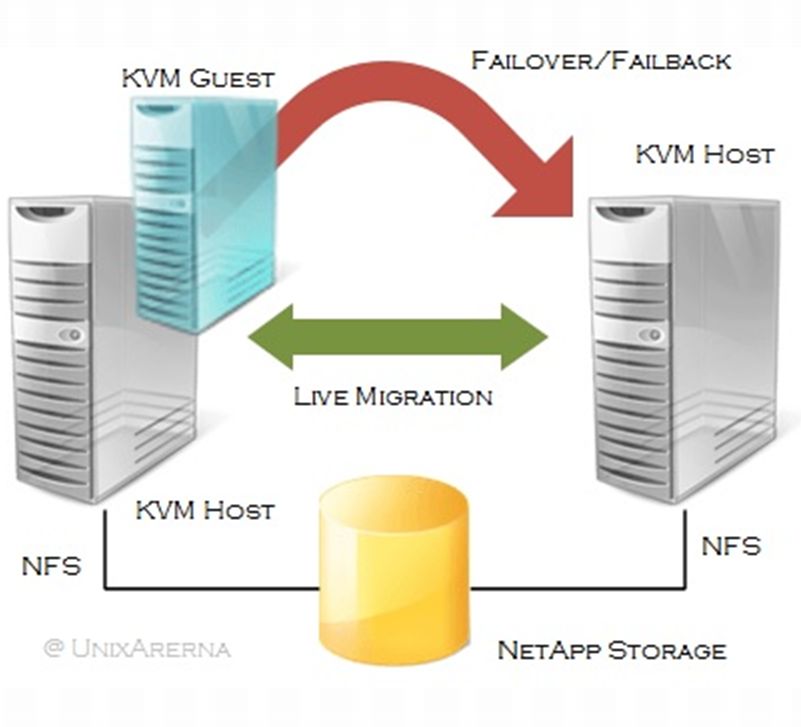
После перевода рабочих серверов в виртуальную среду процесс их обслуживания сводится к миграции виртуальных машин с одной аппаратной «железки» на другую практически без прерывания работы, возможно даже в режиме безостановочной миграции. Proxmox это умеет.
Виртуальные машины позволят вам не переживать при возникновении проблем с оборудованием: особенно это касается решений с использованием программных лицензий, которые привязываются к оборудованию. И такие лицензии есть не только у 1С.
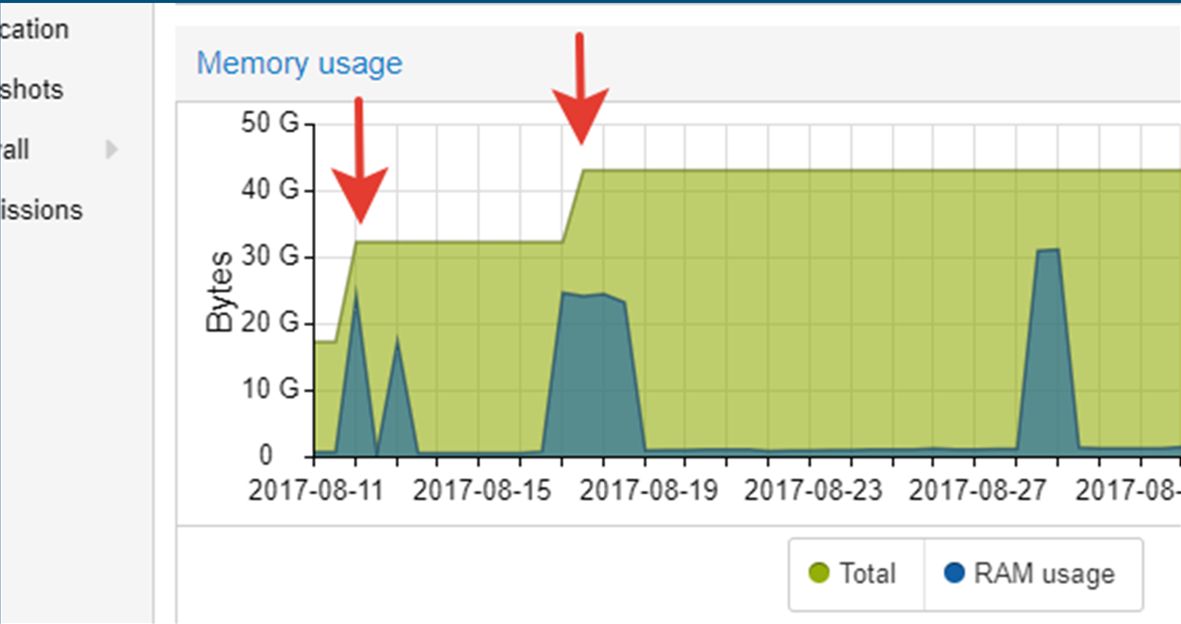
Есть еще одна интересная особенность – это возможность увеличения ресурсов, отдаваемых приложению, «на лету», без остановки работы. Это в Proxmox также доступно «из коробки», все работает.
Конфигурационное управление

Несколько слов об управлении рабочими серверами в Production.
Скрипты bat, shell – это, конечно, здорово, но если бы с ними не было проблем, то SCM-системы (системы управления конфигурациями) не получили бы такое большое распространение.
Существует множество SCM-систем, доступных на основе той или иной открытой лицензии. Наибольшее распространение среди них получили те, что представлены на слайде. Это:
- Представители «второй волны» систем управления конфигурациями – Chef, Puppet.
- А также представители «третьей волны» – Ansible и SaltStack.
Каждая последующая «волна» появляется, как ответ на несовершенства предыдущей.
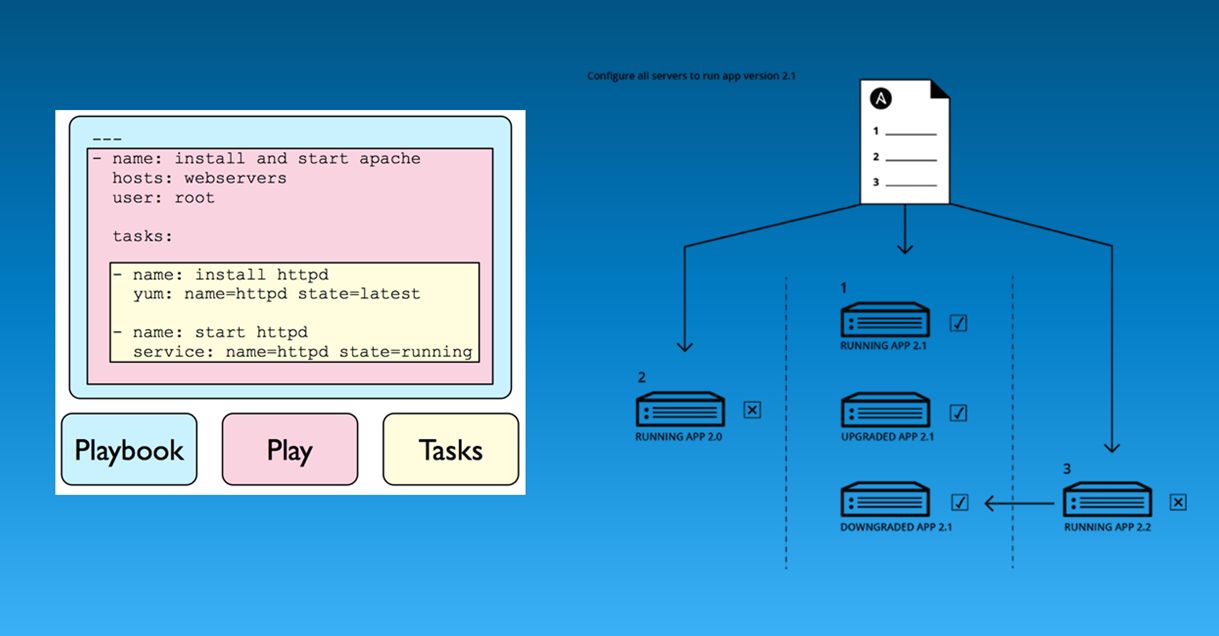
Отдельно хочу немного рассказать про Ansible.
- Он задумывался как простой ответ более сложным SCM-системам. Его главное преимущество – он крайне прост в освоении и имеет низкий порог входа.
- Второе его преимущество – на управляемые хосты не нужно устанавливать никаких агентов, никакого дополнительного ПО.
- В Ansible мы в некотором Playbook просто описываем то требуемое состояние или те команды, которые нам нужны. Пример со слайда выше: установим web-сервер последней версии и запустим его службу.
- И потом эту настройку мы можем применить как для одного сервера, так и для десятка или даже тысячи серверов.
Основной посыл такой: нужно обеспечить работающий сервис, имея только резервную копию данных, голое железо и описание конфигурации.
Рабочие серверы
Сервер приложений 1С
Переходим к рабочим серверам – непосредственно к серверу 1С.

Чтобы система управления конфигурации могла взаимодействовать с сервером 1С, обязательно создаем и запускаем службу RAS-сервера удаленного администрирования «1С:Предприятия».
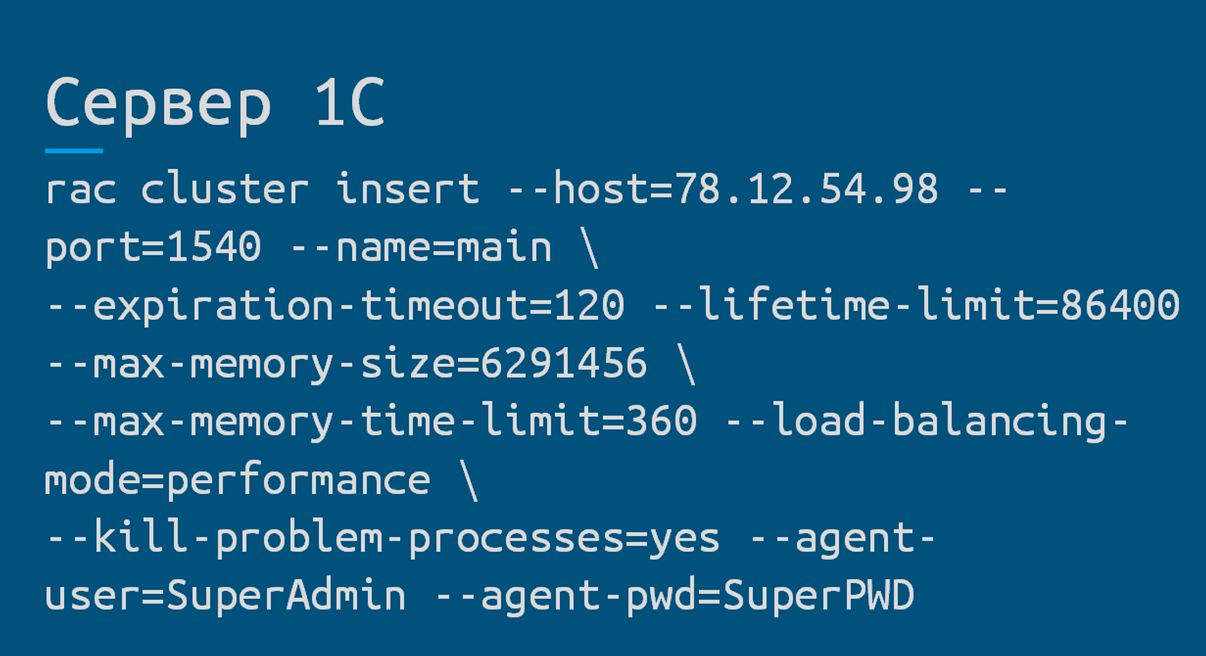
После этого в SCM-системе выполняем настройки кластера, вызывая команду, аналогичную показанной на слайде.
А фирме «1С» хочу сказать отдельное спасибо, что не забывают про ленивых системных администраторов и реализовывают возможность автоматизации управления.
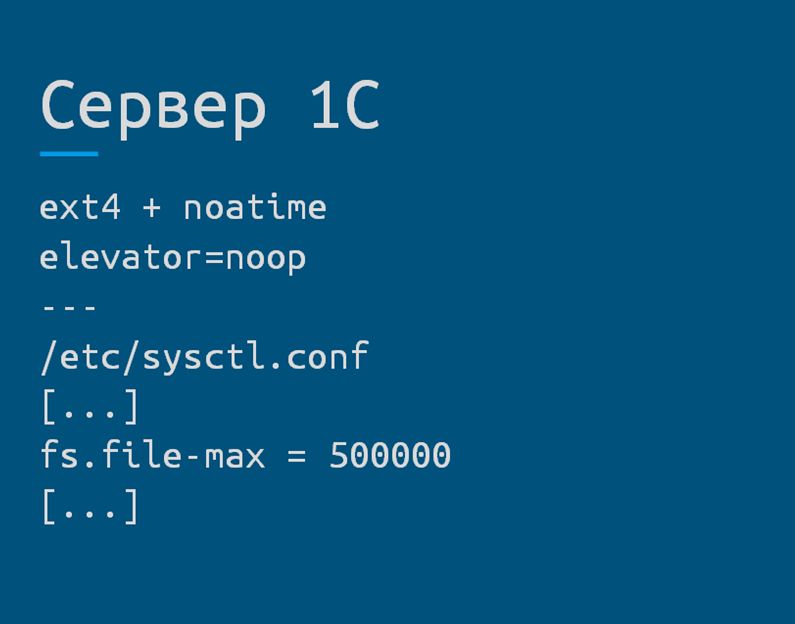
Чтобы не столкнуться с узким местом в значениях «по умолчанию» нужно внимательно посмотреть показатели операционной системы Linux:
- Тип используемой файловой системы и опции ее монтирования;
- Какой используется планировщик запросов;
- Настройки ядра по умолчанию.
При необходимости эти показатели нужно изменить, чтобы не упереться в «бутылочное горлышко».
Сервер СУБД
Переходим к серверу баз данных. С ним все немного проще – тут выбор не так велик.
В качестве сервера СУБД используем PostgreSQL, а точнее сборку от компании PostgresProfessional.

Настройка под конкретные задачи выполняется с помощью онлайн-утилиты PgTune от Алексея Васильева. В его книге «Работа с PostgreSQL» есть рекомендация: «Использовать настройки по умолчанию в PostgreSQL крайне не рекомендуется, нужно всегда делать настройки под конкретное программно-аппаратное обеспечение». В принципе это справедливо для многих ИТ-продуктов.
На слайде показан интерфейс PgTune. С помощью этой утилиты вы можете привести конфигурацию сервера PostgreSQL в соответствие с выделенными аппаратными ресурсами и расчетной рабочей нагрузкой.
В диалоговом окне этой утилиты нужно указать:
- Исходные параметры вашей системы;
- Количество выделяемой оперативной памяти;
- Ожидаемое максимальное количество клиентских соединений.
На выходе получаем готовый конфигурационный файл.

Также можно воспользоваться рекомендациями на портале ИТС – они будут примерно такие же, как и в сервисе PgTune.
В настройки операционной системы, помимо тех рекомендаций, которые были для сервера приложений, можно добавить настройки работы с памятью. В частности:
- Для версий PostgreSQL > 9.4 можно включить поддержку больших страниц памяти;
- Также следует обратить внимание на параметры работы с «грязными» страницами и файлом подкачки.
Веб-сервер
Теперь по тюнингу веб-сервера.
- На текущий момент максимальная поддерживаемая версия Apache для 1C – 2.4. Соответственно, если используется 2.2, надо бы уже поменять.
- Для использования параллельной обработки запросов нужно обязательно включить режим worker (вместо prefork) и настроить его:
- MaxClients – указываем исходные данные по расчетной нагрузке (те же самые, что и для Postgres);
- GZIP – включаем сжатие;
- KeepAlive – включаем ожидание соединений.
Если про ожидаемую нагрузку пока что ничего не известно, обратимся к собранной статистике работы или настроим логирование операций, чтобы выставить окончательное значение позже. О том, как это сделать, я покажу в блоке анализа.
Резервное копирование
Сейчас нужно не потерять данные – поэтому перейдем к разделу резервного копирования.
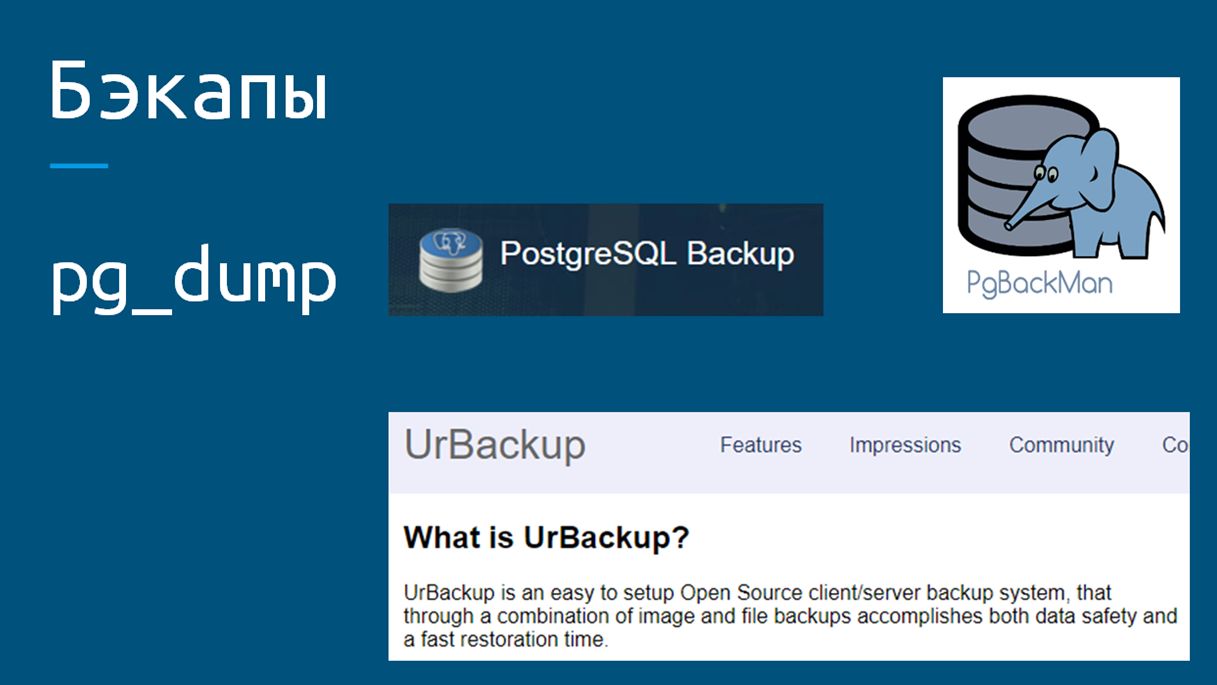
PostgreSQL позволяет выполнять три типа резервного копирования:
Первый тип – это pg_dump, полный дамп кластера серверов, либо отдельной базы. Он подходит для редко изменяющихся баз, где безопасная глубина потери данных может доходить до суток и более. В топе выдачи поисковых систем, вы, как правило, увидите примеры именно такого типа резервного копирования.
Чаще всего для его использования предлагаются различные консольные команды и прочая, не сразу понятная магия. Однако для этого типа резервного копирования есть достаточно удобный менеджер с графическим интерфейсом – это PostgreSQL Backup. Также можно использовать такие консольные программы, как PgBackMan и UrBackup. Они тоже упрощают работу с этим типом резервного копирования.
Второй тип резервного копирования – это pg_basebackup, физический бэкап файлов БД. В этом случае у нас уже появляется возможность копировать только изменения, делать инкрементальное резервное копирование. Но этот, как и предыдущий тип резервного копирования, имеет недостаток в том, что глубина потери данных, особенно с большими базами, все равно еще достаточно велика – сутки и более.
Если же на проекте требуется что-то более серьезное и нужно обеспечить минимально возможную потерю данных, используется встроенный механизм PostgreSQL – стратегия непрерывной архивации и восстановление на конкретный момент времени (point in time recovery – PITR). В этом случае глубина потери данных будет стремиться к нулю.

Для того чтобы упростить настройку непрерывной архивации PITR есть инструмент PgBarman (PostgreqsSQL Backup And Recovery Manager).
Он позволяет:
- Выполнять настройку архивации;
- В автоматическом режиме отслеживать изменения;
- Выполнять архивацию в соответствии с принятой стратегией резервного копирования;
- Следить за выполнением архивации.

- А также позволяет реализовать восстановление:
- На конкретный момент времени;
- На конкретную транзакцию;
- На конкретную метку (если была сделана метка бэкапа).
Анализ логов
С бэкапами разобрались. Переходим к анализу логов.

Настройка логов требует отдельной большой обзорной статьи, но если коротко – то логи нужны независимо от используемого типа ПО. Их можно и нужно анализировать.
Логирование лучше не выключать, тем более что сервер баз данных и сервер приложений позволяют получить очень подробный вывод в лог-файл о своей работе именно.
Давайте посмотрим, как можно анализировать логи.
Набор «Инструменты разработчика»
Существует такой замечательный набор «Инструменты разработчика». В нем есть как минимум две кнопки, которые будут полезны администраторам. Это:
- Настройка технологического журнала;
- И анализ технологического журнала.
Для оперативного расследования проблем, чтобы быстро выявить какие-то проблемные запросы и что-то еще, эти инструменты подойдут как нельзя лучше.
Стек ELK
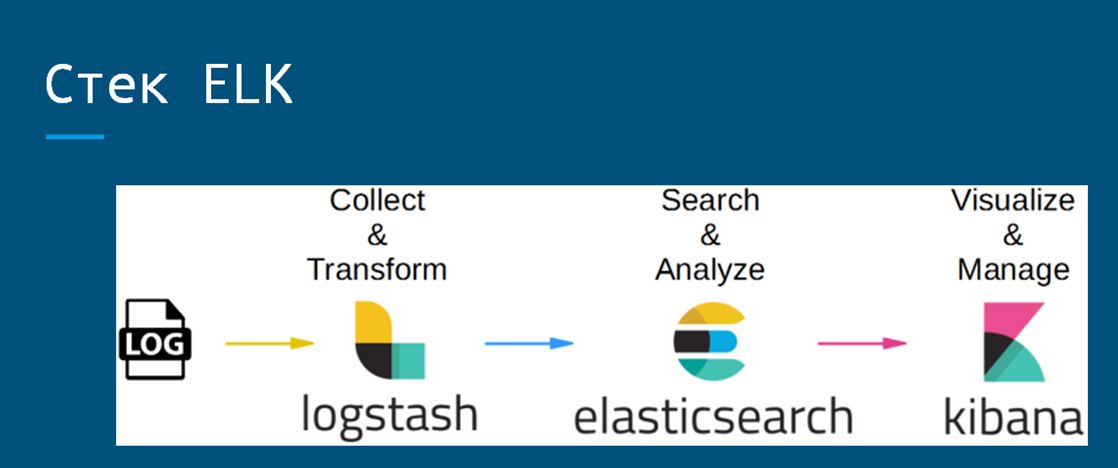
Если нужно провести более серьезный анализ поведения в системе, берем стек ELK, и настраиваем на рабочих серверах ротацию журналов и их архивацию.

Отмечу, что классически для работы с логами используется Logstash, но его клиент достаточно тяжеловесный в этом стеке, поэтому от тех же разработчиков, компании Elastic, был выпущен легковесный набор клиентов Beats, которые работают гораздо быстрее и занимают крошечное количество ресурсов (около 0,5 Мб оперативной памяти).
А для удобного отображения результатов анализа есть инструмент Grafana, к которому в качестве источника подключается база ElasticSearch, откуда могут быть выведены какие-либо данные.
PgHero

Для оперативного анализа проблем на уровне СУБД можно взять инструмент PgHero, который на основе собранной внутренней статистики сервера СУБД PostgreSQL в режиме алертов выведет ключевые показатели и покажет самые проблемные места:
- Здесь не хватает такого-то индекса;
- Здесь длинный запрос – надо посмотреть туда-то.
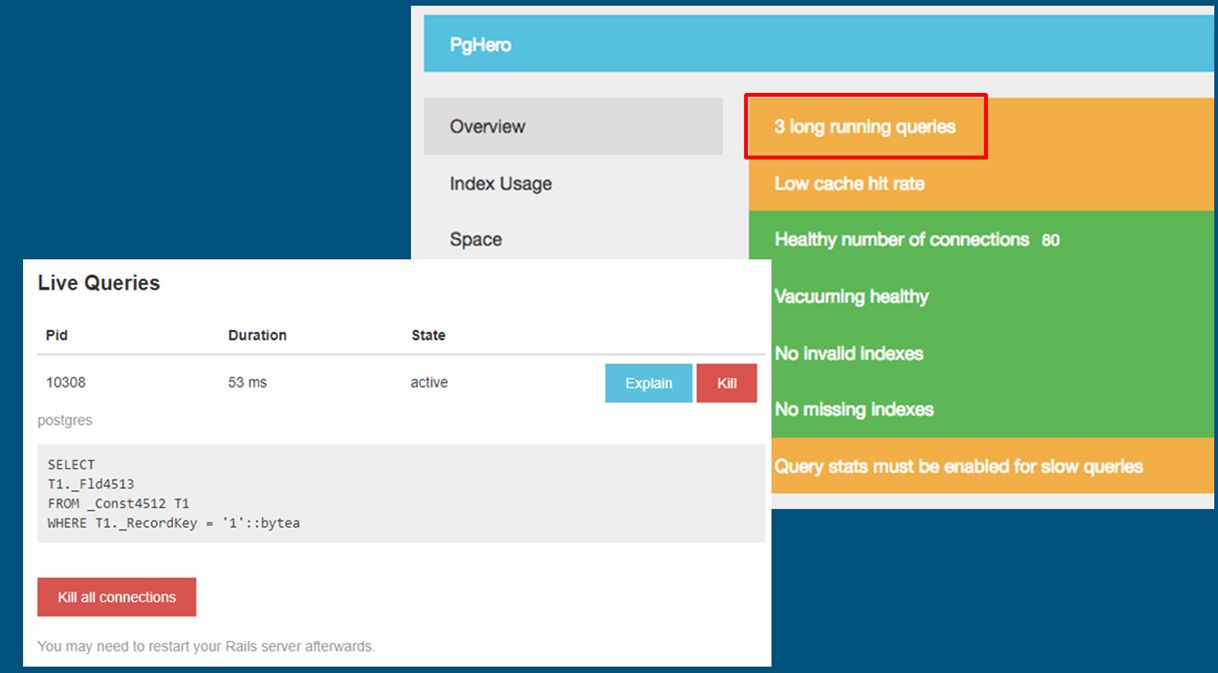
При использовании этого инструмента приходит понимание, где в базе беда и куда нужно посмотреть более пристально.
POWA
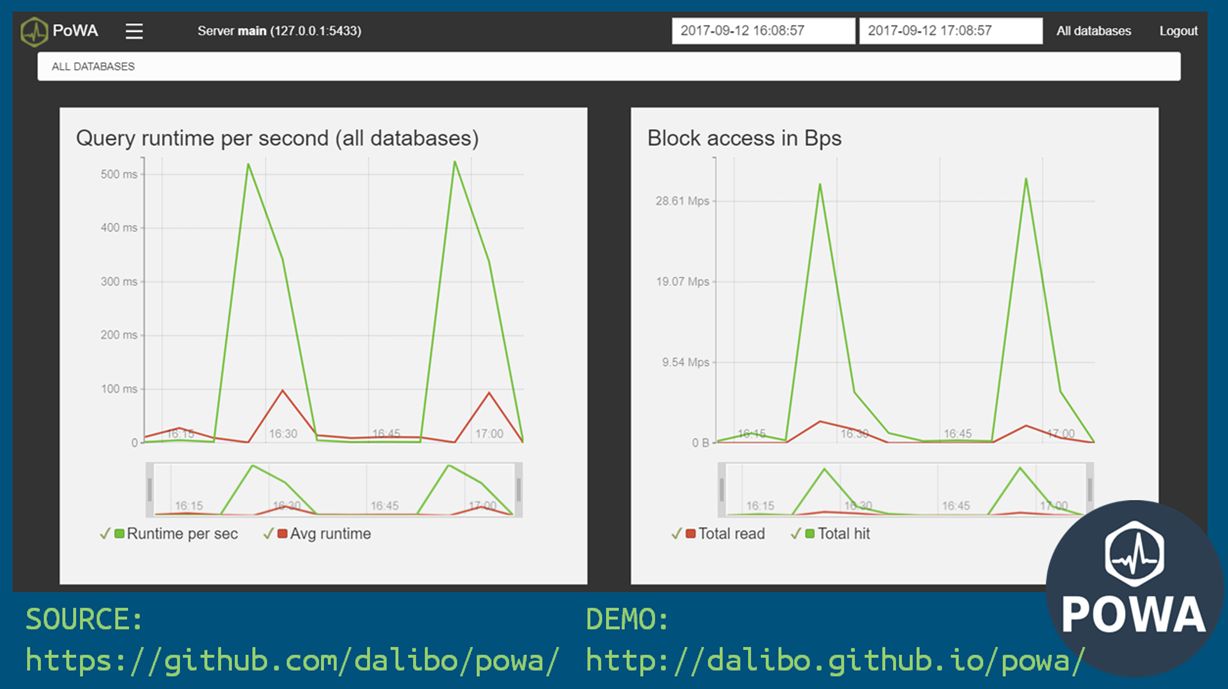
Для анализа динамики показателей работы за период удобно использовать графический инструмент POWA – он также показывает блокировки и длительные запросы.
HypoPG
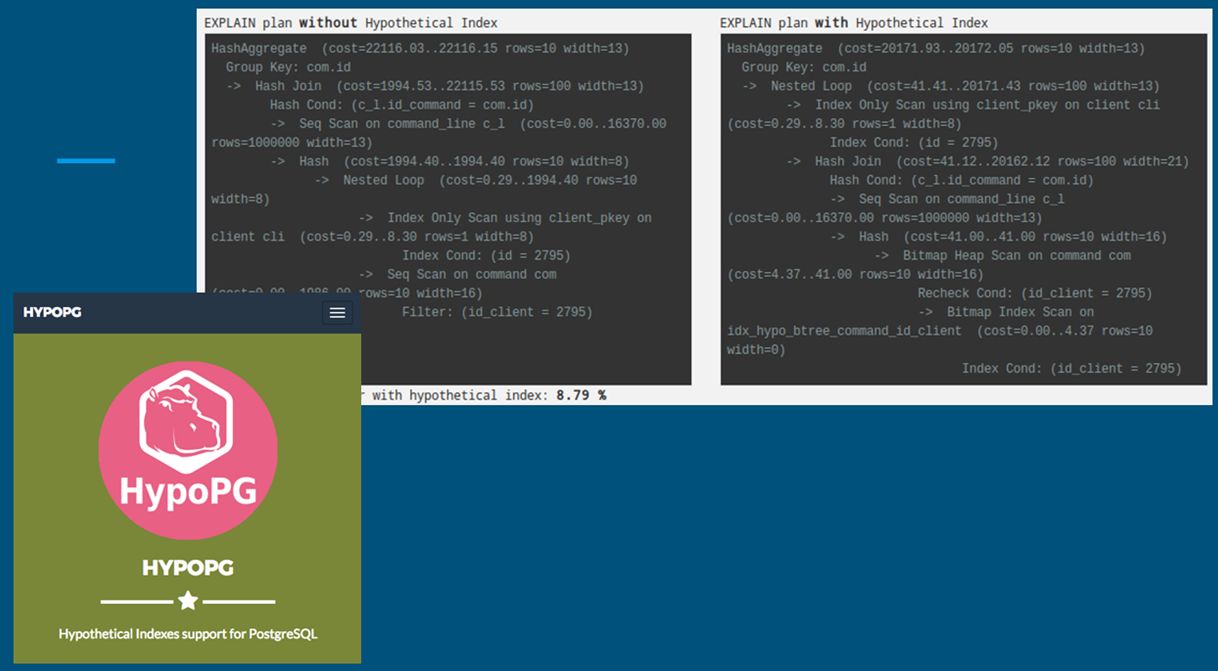
С помощью расширения HypoPG в процессе выполнения запросов сервером СУБД производится их анализ, и составляются рекомендации по созданию недостающих индексов, которые могут существенно ускорить выполнение запроса.
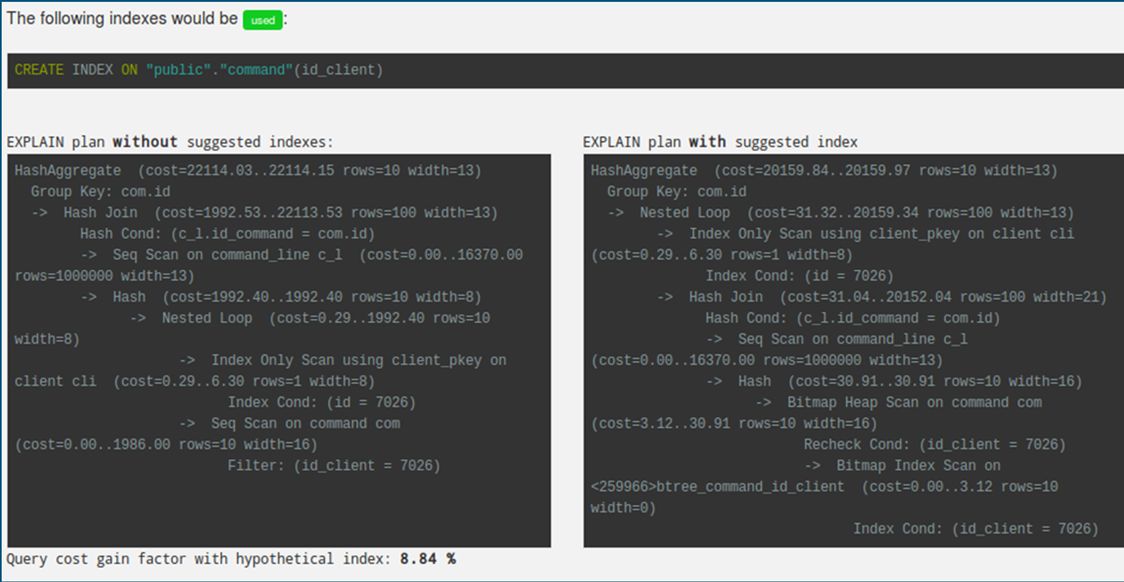
Сразу же выдается предложение рассчитать показатели с учетом добавленного индекса. Самое важное, что этот индекс не создается, а только предварительно рассчитывается. Соответственно, нет тяжелой операции записи на диск. На слайде показано, как выглядит расчет для предлагаемого индекса.
pgBadger
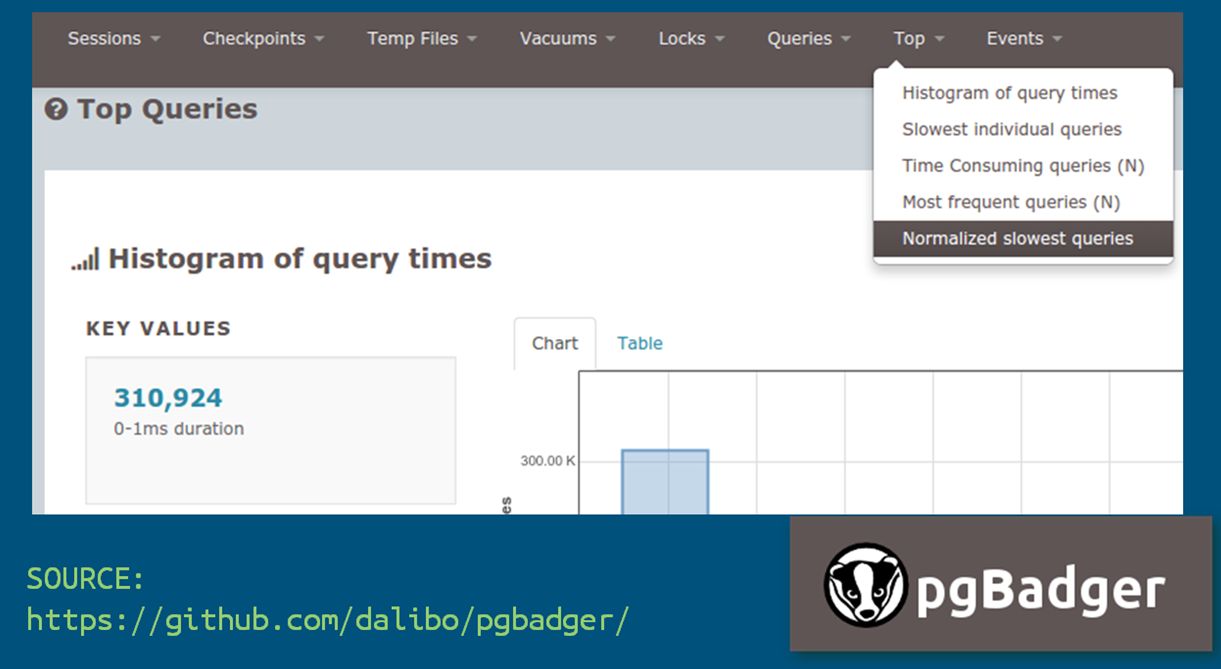
Еще один инструмент – pgBadger показывает агрегированную статистику, полученную на основе логов работы с СУБД. Его данные могут быть использованы для расследования поведения сервера в длительном периоде. Формируется страничка HTML, на которой можно выбирать период и смотреть, анализировать.
Специализированные инструменты анализа логов от 1С
Конечно, для анализа работы платформы есть специальные инструменты от самой фирмы «1С» – все о них знают. Но они имеют два минуса:
- Эти инструменты платные;
- Они требуют определенной компетенции.
Счетчики и уведомления

Еще один существенный недостаток у специализированных инструментов – в них нельзя получить агрегированную статистику по всему ландшафту, включая инфраструктуру и сетевые соединения.
Для этого собираем различные метрики и на основании показателей счетчиков настраиваем уведомления о проблемах (по содержимому, по общему состоянию). Это позволит нам «спать спокойно», вернее, просыпаться от SMS-сообщения о том, что назревает проблема, а не от звонка руководителя, спрашивающего, почему встала работа.
Для работы с этими счетчиками и уведомлениями существует большое количество OpenSource-систем мониторинга. Их многообразие создает проблему выбора. Недавно на Хабре вышла статья «Летний обзор OpenSource-систем мониторинга». Их набралось 47 штук. Чтобы выбрать что-то конкретное под себя – нужно постараться.
Zabbix
Я давно работаю с системой Zabbix (с версии 1.8). Соответственно, и мониторинг я предпочитаю тоже заводить на него.
Zabbix – это кроссплатформеная система мониторинга, которая обладает огромными возможностями по аналитике и уведомлениям пользователя. У нее есть документация на русском языке, и разработчики тоже русскоговорящие.
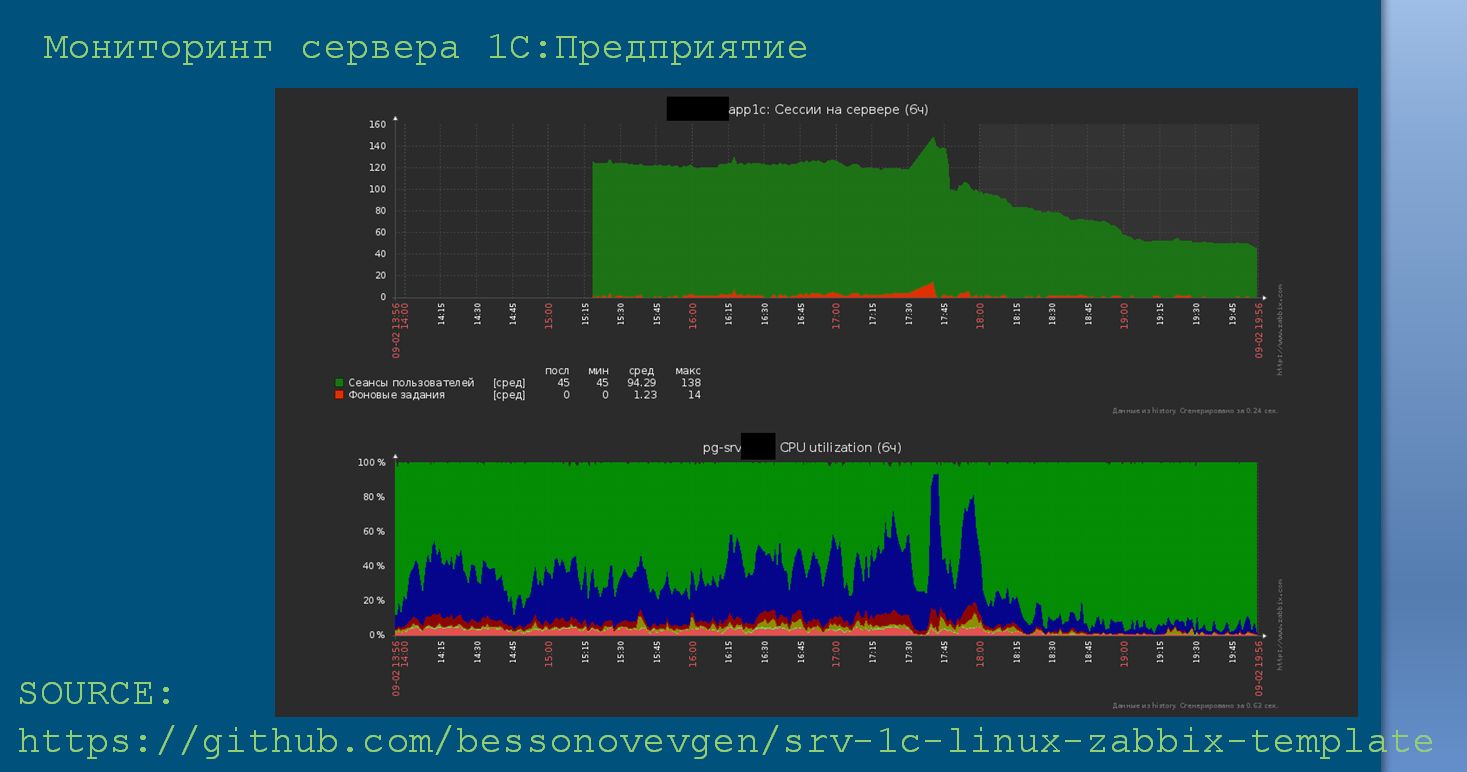
Для мониторинга сервера приложений 1С я создал репозиторий, в котором есть пример конфигурационного файла и готовый шаблон для импорта в Zabbix.
- Взаимодействие агента мониторинга и сервера приложений 1С обеспечивает сервер удаленного администрирования.
- Используется загрузка уведомлений по событиям.
- Проект доступен на GitHub.
- Порядок работы следующий:
- Настраиваете свой сервер приложений;
- При необходимости добавляете в шаблон свои метрики;
- Получаете по ним значения и историю.
Чтобы вручную не настраивать множество узлов для мониторинга, у Zabbix есть инструменты автообнаружения. А также, когда необходимо сделать какой-то более сложный мониторинг, можно воспользоваться возможностями встроенного API.
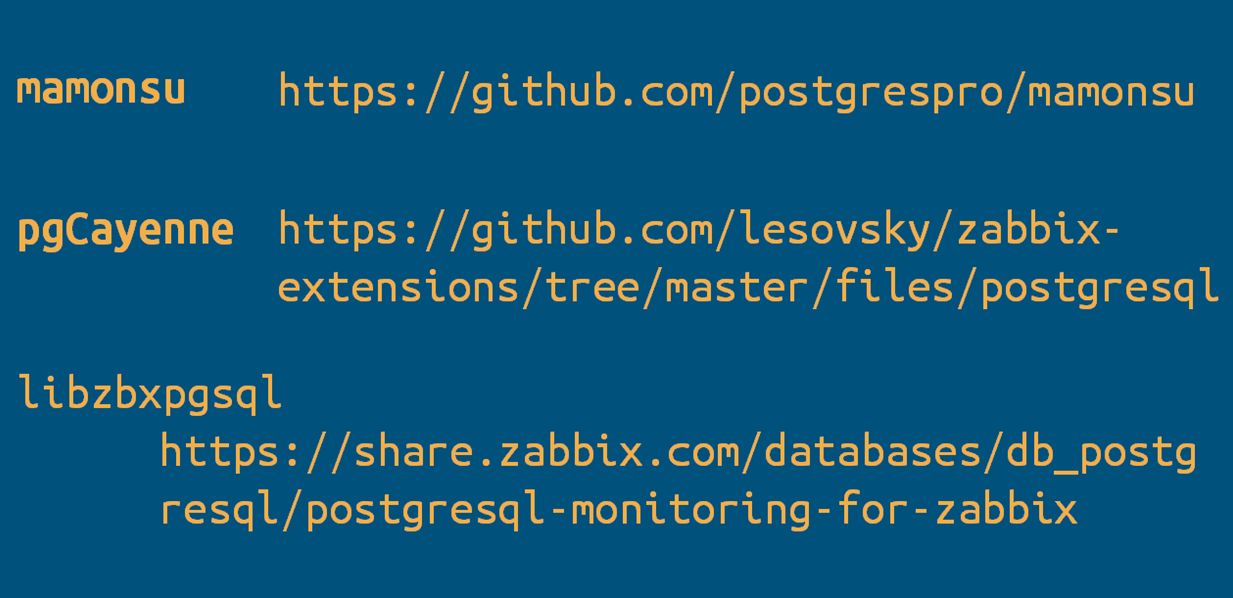
Для Zabbix есть готовые шаблоны по мониторингу сервера СУБД PostgreSQL:
- mamonsu от компании PostgresProfessional;
- pgCayenne;
- libzbxpgsql;
- И множество других готовых шаблонов, которые можно будет загрузить и настроить по ним уведомления (мониторинг).
Проблемы при переездах

При переходе организации с Windows на альтернативную платформу могут возникнуть некоторые проблемы. Они особенно обостряются, если в совершенно другую среду переводится все «скопом» – сервер СУБД, сервер приложений и, не дай Бог, рабочие станции. В этом случае взаимное влияние особенностей может дать грандиозный эффект синергии и породить множество проблем, о которых даже не подозревают.
Поэтому при переходе на использование альтернативных инструментов всегда нужно:
- Провести планирование того, как все это будет происходить.
- Обязательно организовать какую-то тестовую площадку, на которой проверять поведение системы при новых условиях.
- Сам перевод серверов на Linux можно сделать в два этапа – сначала перевести сервер СУБД, затем – сервер приложений.
- При переводе сервера приложений могут возникнуть проблемы из-за использования каких-либо решений, которые завязаны на Windows. Переделка таких механизмов может потребовать большое количество времени и ресурсов.
- После этого делаются уже окончательные расчеты стоимости перевода всего ландшафта из Windows в Linux. В различных ситуациях может потребоваться разная детализация расчетов.
Другими словами, примерный план перехода следующий:
- Планирование;
- Настройка тестового окружения;
- Проверка поведения системы;
- Корректировка изначального плана;
- Расчет стоимости.
В процессе переезда возникает еще и глобальная проблема – это нежелание специалистов изучать новое. Гораздо привычнее делать так, как всегда делали. Понятно, что выход из зоны комфорта может не приносить большой радости в процессе, но результаты, как мы знаем, могут быть очень интересные.
Заключение

И в заключение я хочу сказать, что в принципе неважно, на какой платформе работать и какое программное обеспечение использовать. Важно делать это продуманно, используя инженерный подход. Работать должны системы, а люди должны организовать этот процесс.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 COMMUNITY. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Каков по Вашему мнению должен быть размер инфраструктуры, чтобы использование всего вышеописанного имело смысл, учитывая, что есть windows server hyper-v, который бесплатен, а счётчики etc. — штатная возможность системы?
(1)
Система виртуализации то бесплатна, а за гостевые системы придется платить.
Все указанное в статье однозначно нужно для тех компания, где инфраструктура 1С своя и её регулярно адаптируют под задачи бизнеса.
Конечно, если уровень бизнеса еще на этапе «один раз настроил типовую и забыл», то разговор другой.
Хороший обзор общепринятой практики DevOps в контексте поддержки 1С-решений. Актуально те только для экосистем на Linux.
Думается, что если бы это неплохо дополнительно оплачивалось(тем же работодателем, например), число нежелающих изучать новое заметно бы сократилось.
А так, «зона комфорта» создана за счет работодателя(Win Server + MS SQL Server), в ней все хорошо работает, зачем что-то менять…
Невозможно читать из-за того, что половина текста на жирном. Надо брать текст, копировать, удалять жирность и спокойно читать.
Жирность предназначена для пары ключевых слов, автор же использовал для половины текста, пздц какой-то.
(4)
Период, когда другие люди решают что вам изучать, а главное — мотивируют это делать, заканчивается лет в 17 получением аттестата о среднем образовании. Что делать дальше, решаете только вы. Можно чему-то научиться и затем конвертировать эти знания в деньги. Можно с грустной моськой сидеть и жаловаться.
Даже внутри экосистемы «1С» каждый год появляется что-то новое, и это новое надо изучать, иначе — вылет с рынка труда.
А работодателю всегда выгоднее найти готового спеца на стороне, чем думать как замотивировать что-то изучать своего лентяя.
(1) Юрий, вся прелесть инструментов в том что «все вышеописанное» сразу применять необходимости нет.
Анализируем что «болит» и выбираете инструмент.
Мой путь был следующий:
1. «Железные» серверы выходили из строя и требовали человеческого внимания, причем было требование что это внимание нужно оказывать, простите, ночью. Была выбрана миграция сначала в виртуальную среду на один гипервизор, а затем в кластер.
2. Счетчики производительности: можно ходить по серверам и смотреть, а хватает ли ресурсов сервера. Правда если вдруг нужно расследовать что там было день или два или неделю назад, то ой. Поэтому расставил агенты мониторинга и собрал данные в одном месте.
3. Нужно было сделать быстрое разворачивание контуров — описание инструкций в виде «Далее, далее» работают если есть человек который эти кнопки будет жать, но время людское нужно экономить и переложить на плечи машины: поэтому инструкции были сделаны для системы управления конфигурацией. И зафиксированы в системе управления версиями.
(5) Спасибо за обратную связь ;-).
Выделены те участки которые должны попасть в зону внимания при просмотре статьи по диагонали.
(7)Система, описанная Вами достаточно стройная, интересная и на столько-же непростая. Полагаю, что Вы не будете ее рекомендовать компаниям, в которых скажем всего пяток серверов (или если будете, то какие части из вышеперечисленного?). Вот и возникает вопрос, о том, начиная с какого размера инфраструктуры, становится оправданным использование всех тех сервисов и приложений, о которых Вы упомянули в статье.
Можно и не ходить :), а настроить счетчики, логгирование, отправку оповещений и все вот это централизовано штатными средствами (речь о Windows).
Ну так и Ваши хосты, являясь «железными серверами» будут требовать такого-же внимания и ухода.
1.Общеизвестно, что администраторам Linux платят больше, потому что им голову ломать приходится больше. Руководители предприятий и сотрудники, знакомые больше с Windows, совсем не в восторге бывают от желаний переходить на Linux.
2. 1С лучше работает на Windows.Да и во многом другом Майкрософт добилась успеха.Слоны тормознее MS.
3.На многих российских предприятиях Windows используют бесплатно, без обновлений и вполне удовлетворены, в том числе «ничейный» ХР.(под лозунгом: пусть за океаном обеднеют)
4.Получить адекватную помощь в изучении всего вышеперечисленного, даже при сильном желании, бывает проблематично. Например, автор статьи не потрудился даже в обзорной статье на пальцах внятно объяснить, чем его скрипты для автоматизации не устраивают. Чего уж говорить о получении детальных объяснений. Пусть кто-то из линуксоидов затратит столько же денег,сколько MS на образование масс.
(10)
Нифигашеньки. Хороший виндовый админ стоит ой каких денег. Другое дело, что сейчас любой эникей может поставить спираченый Win2k16 datacenter edition. И даже худо-бедно его настроить. И среднего размера компанию результат даже устроит. Но админом он от этого не станет.
Весьма спорное утверждение.
Вы просто не умеете их готовить.
Это не говорит о преимуществах винды, скорее об особенностях менталитета. Вот вам еще мысль — винда стоит денег, уголовная ответственность за контрафакт наступает от 50 тыр, и под суд пойдет не абстракное «предприятие», а вполне конкретный исполнитель. Если бы ответственность ложилась не на человека, а на компанию — бесплатных виндов стало бы заметно меньше.
Ищите и обрящете, стучите и отворят вам
(9)
Вариант А: 15 железных хостов, каждый из которых отвечает за какай-то кусочек бизнеса. Чтобы остановить хоть один даже для профилактики нужно подгадывать время. О том, что случится, если он вдруг упадет, даже подумать страшно.
Вариант Б: 3 железных хоста в кластере, каждый из которых отвечает «за все и ни за что конкретно». Вы можете вывести один в maintenance в любое удобное время и бизнес этого даже не заметит, как и падения, при привильно приготовленном HA
Для меня выбор очевиден, а для Вас?
(12)Да собственно с тем, что кластеризация удобна — никто и не спорит. Так, что в этом плане наши мнения совпадают. Что не отменяет необходимость обслуживания этих самых хостов.
Ну и в контексте 1с, вариант А также вполне работоспособен. Кластер 1с + кластер СУБД на железных хостах решает проблемы выхода из строя оборудования. Что дешевле — надо считать.
(9)
Можно начинать использовать или хотя бы посмотреть по сторонам ровно с того момента как
какая-то часть системы начинает задалбыватьначали чесаться руки что-то сделать.Можно, я не осилил :-). А еще хотелось чтобы мониторинг был универсальным: на тот момент были и сетевые железки и ИБП.
Ниже уже ответили (12), но я повторюсь: действительно именно миграция в виртуальную среду значительно снизила количество ночных выездов.
И также появилась возможность более оптимально использовать имеющиеся аппаратные ресурсы.
(3) Спасибо.
(10)
Я и не призываю отказываться от Windows систем. Но посчитать стоимость лицензий иногда бывает полезно. Посчитать — поосознавать.
1С — вы имеете ввиду сама платформа или какие-то конкретные конфигурации? И какое участие приняла конкретно сама компания Майкрософт в том чтобы 1С (платформа или конфигурации) стала работать быстрее?
Ну и да, про слонов нужно ребятам из Яндекса, Авито, да что уж там и PostgresPRO рассказать ;-).
То что используют, это личные трудности самих компаний. В нашей компании после первого (ознакомительного) звонка из местного представительства Майкрософт и заполнения опросной анкеты руководство озадачило вопросом расчета стоимости лицензирования и составления плана закупок.
Про скрипты «на пальцах»: не знаю получится ли. У меня осознание нужности использования уже готового решения по автоматизации управления конфигурациями пришло после написания первого скрипта который устанавливал антивирус с параметрами в зависимости от места расположения рабочей станции. Еще вспоминается фраза из области тестирования («Жизнь слишком коротка для ручных тестов»), но только вместо «ручных тестов» мне хочется сказать «для написания скриптов». И еще: вы же ведете разработку в какой-то высокоуровневой среде или прямо на ассемблере бухучет делаете?
Что касается Майкрософт и образования:
1. Наверное да, денег они знатно «потратили» до середины 2000-х, в эпоху расцвета «пираток».
2. Потом видимо одумались и решили взяться за ум и сельских учителей.
3. А вот в том что свежеиспеченные айтишники могут и не подозревать о наличии других операционных систем кроме windows и офисного пакета кроме офиса, тоже наверное заслуга американской компании?
(14)То, есть наверное имеет смысл начинать с мониторинга производительности текущей инфраструктуры с последующей миграцией в виртуальную среду (если я правильно понял). Соответственно возникает вопрос: как обстоят дела с поддержкой оборудования описанным ПО и сертификацией данного ПО у различных вендоров?
P.S.
Хозяйке на заметку: для мониторинга сетевых устройств можно использовать PowerShell + скажем такую библиотеку
До 2020 г. бюджетные учреждения должны перейти на ПО из данного официального реестра: (Федеральный закон от 29 июня 2015 г. N 188-ФЗ)
Это означает что все бюджетники перейдут на Linux, PostgreSQL и LibreOffice из разрешенного списка.
А между тем, большинство ФБУ находятся сейчас не в том агрегатном состоянии, чтобы нанимать линуксоидов.
(16)
Отличная фраза. Думаю, сюда можно добавить «и стоимость владения», которая включает в том числе з.п. среднестатистического win/nix админа и навыки работы пользователей с определённым пакетом ПО.
(17)
Ну в общем да. Только скорее мониторинг не детальный и целостный, а скорее анализ на предмет того «вот конкретно мне в данный момент чем поможет миграция куда-либо».
ПО для мониторинга? Касаемо Zabbix: актуальная информация доступна тут
По сертификации, вам лично зачем нужна сертификация у «различных вендоров»? Что это за вендоры (ПО, железо)?
За библиотеку спасибо.
(20)Нет, конечно же не zabbix, а software, которое Вы предлагаете использовать для виртуализации и кластеризации.
Сертификация нужна для того, чтобы при возникновении проблем, к примеру с производительностью хранилища, обратившись в поддержку вендоров я не получил ответ: ваша конфигурация не сертифицирована и не поддерживается.
Всё-таки мы же рассматриваем реальную систему, а не выполняем лабораторную работу.
(19)
Я бы без особой и острой необходимости не стал трогать конечных пользователей. Ведь отчасти мы все такие автоматизаторы для них стараемся. Из опыта: лицензии на ПО для пользовательских компьютеров занимало хорошо если четверть расчетного бюджета.
По зарплатам я согласен с тем что их можно в принципе приравнять (конечно при схожих зонах деятельности).
Так что думаю да, нужно подумать еще и над оставшимися частями «стоимости владения».
(19)
Да, принято считать именно стоимость владения считать, а не только стоимость приобретения. В этом хитрая уловка автора.
(22)
Не приравнивайте зарплаты линукстов к windows-администраторам. Именно на этой разнице линукс сильно проигрывает. Посмотрите на сайт hh.ru
В свое время windows вытеснил dos именно за счет удобного графического интерфейса.
(21) Да, вы правы. Скорее сертификация вендоров — это не сильная сторона открытого ПО. Но что-то мне подсказывает, что в тех инфраструктурах где используются термины «хранилище», «поддержка вендоров» работают такие профи для которых данная публикация будет как детский рассказик.
С другой стороны сертификация под определенное железо сразу накладывает отпечаток: за уралом даже в городе-миллионнике нередко придется подождать неделю другую пока приедет нужная железка.
В противовес этому можно отмигрироваться хоть на бытовой сервер «под столом» и продолжить работать.
(23) Уж извините, но и в мыслях не было никого хитро улавливать. Я повторюсь, затраты будут, вопрос только в том на что эти средства будут отправлены.
(18)
До 2020 г. сто раз передумают и отложат.
(25)
Дело не в том, семечки или нет :). Вот один из примеров из жизни (правда не 1С). Кластер виртуальных машин hyper-v, MS Exchange 1000 пользователей, что в общем-то немного, обычное хранилище (общий дисковый массив) с FC начального уровня, продуктивная среда. При определенных условиях, случайных, катастрофически падает производительность хранилища и НЕ возвращается в исходное состояние. Все оборудование и software находятся в HCL листах MS и производителя оборудования. В вышеописанном случае, проблема была решена в течении суток, совместно с производителем оборудования. Что делать системному администратору, или по молодежному — DevOps инженеру в Вашем случае?
Куда и как Вы предлагаете отмигрироваться?
(32) Дмитрий, спасибо за такой подробный комментарий. Думаю он будет полезен как мне для анализа того на что обратить внимание, так и другим участникам сообщества, особенно если кто-то захочет выступить на осенней конференции.
Все же основная цель статьи не сагитировать переезжать на opensource ПО, а рассказать о том какие есть вообще альтернативы и как выглядят.
Что касается графических инструментов: выбор же за конечным пользователем системы (в нашем случае это администратор) и если вам приятнее консоль и ssh, то это ваш выбор.
Про автоконфигурирование под выделенные ресурсы и web серверы — да, наверное стоило более детально что-то рассказать.
Про конкретный кейс — это скорее формат мастер класса, насколько я понимаю как раз ближайшая возможность это сделать будет в октябре в Питере. Возьметесь?
(29)
Встречный вопрос: при расчете инфраструктуры на эту 1000 пользователей какие факторы учитывались? Если только стоимость ПО, то конечно ответ будет не из приятных. Если же в стоимость была заложена возможность обращения за поддержкой, то обращаться за поддержкой.
Если речь не про вышеобозначенную тысячу пользователей, то в моей практике была ситуация когда в буквальном смысле несколько виртуальных машин (не сильно нагруженных, но все же обеспечивающих работу 50 человек) были смигрированы на обычный бытовой компьютер (4 ядра, 32 гб памяти) без остановки работы примерно за 30 минут.
(32)
Кстати, в отличие от винды, в Linux это сделать проще простого…
Предположу, что тут проблема будет не с постгрей и дохлой нодой, а с 1С, которая сдохнет раньше с ошибкой SDBL, чем система обнаружит недоступность ноды и произведет ремеппинг.
(34)
Как раз таки учитывались все факторы, поэтому проблема и была решена с помощью вендора.
Для оборудования известных производителей, в стоимость оборудования уже включена стоимость поддержки. Дело в том, что если используемая конфигурация не сертифицирована вендором, то он не сможет вам ничем помочь.
Вы предлагаете к использованию определенный стек технологий. Из Вашего предыдущего ответа следует, что с сертификацией у вендоров оборудования дела обстоят никак. Если я неправильно понял — пожалуйста поправьте меня. Соответственно риски бизнеса возрастают. Вопрос в том — знает ли бизнес об этих рисках и принимает ли он их. У Вас в статье ничего об этом не сказано.
Поэтому мой изначальный вопрос и был о размене и хаактеристиках инфраструктуры, для которой Вы рекомендуете описанные решения.
(29) Извините, что втискиваюсь в диалог, но не все организации находятся в пределах видимости производителя (или желания видимости). Помню как-то из сибирского мааааленького городка пришлось тащить сервер в охапку в Москву (4 тыс км), чтобы представители производителя дали консультацию. Они ж (производители) тоже часто в снобизм скатываются. Так что твёрдо на них рассчитывать как минимум опасно.
Примечание: Сервер от Поликома. Всё официально. Контора крупная.
(37)Да, и так бывает. Жизнь она такая штука 🙂
По всей видимости решить проблему удаленно не получилось, а ближайшее представительство вендора было в Москве. Я так понимаю — это специализированное hardware?
И тем не менее, я так понимаю, Вы получили консультацию etc. А что бы Вы предприняли в аналогичной ситуации, если бы сервер был noname?
Тут скорее проблема в том (если это не уникальное hardware, заточенное для решения определенных задач) что перед выбором вендора необходимо учитывать и расположение сервисов/доступность инженеров etc. Возможно в этом случае Вы бы отвезли Вашу железку скажем в Новосибирск, что наверное несколько ближе.
А полагаться ни на кого не надо. Надо минимизировать риски бизнеса, связанные с различными факторами, в том числе и с качеством предоставления сервиса вендором в Вашем регионе.
Собственно в описанном автором статьи стеке software есть риски, связанные с отсутствием достаточных компетенций для его использования и устранения возможных проблем. Эти риски возможно некритичны скажем для Яндекса или гугла, однако возможно критичны для компаний поменьше, либо для компаний, чей бизнес не связан с it. Поэтому я и просил автора очертить целевую аудиторию, для которой все вышеописанное может быть использовано.
(38)
Полностью поддерживаю.
Про наш случай можно и так сказать (если матерные слова опустить) — просто динамили, предлагая купить другой сервер. Пока его возили в Москву, вместо него использовали старенький радвижн. Ничего, выкрутились. Просто ситуация неприятная.
Если рассматривать железо не такое дорогое и специализированное, то в мелкие конторы (до 100 торговых точек) часто выгодней покупать железо в соседнем ларьке. Т.к. в случае неприятности можно быстренько сбегать и купить/докупить недостающие комплектующие. И да, уверяю, это иногда на много выгодней, нежели ждать месяцы гарантийного решения.
Повторюсь — последний абзац про мелкие конторки.
(39)ну может быть, в Вашем случае имело смысл эскалировать проблему и обратиться не к дистрибьютору а к вендора напрямую. На моей памяти был случай, когда авторизованный сервисный центр в одном из городов нашей страны отказывался прислать инженера бесплатно, несмотря на то, что условия гарантии подразумевали обслуживание на месте, если объект находится в пределах 100 км от сервисного центра. Обращение к вендору позволило решить этот вопрос в течении минут сорока.
А в общем да, все зависит от конкретной ситуации, рисков, вероятности их наступления, потерями и затратами на их предотвращение
(36)
И снова здравствуйте, прошу прощения за некропостинг. Вопрос мне кажется по прежнему актуальным.
Так вот, выдалась возможность поближе познакомится с решениями вендоров (HP и VMware).
И моё мнение, озвученное в статье в общем то только утвердилось.
Итак: использовать описанные инструменты я считаю можно и нужно даже если ты микрокомпания. Основной посыл, тот же: кому ты будешь платить? И здесь две составляющие: развитие себя и своей команды и избавление от зависимости от конкретного вендора. Уверен что до сих пор существуют товарищи которые считают что нет операционной системы кроме windows, базы данных — кроме MSSQL, и системы виртуализации кроме — VMware.
Что касается поддержки вендора: то есть компания RedHat — её продукты сертифицируются многими известными вендорами железок, но при этом — это Linux и мир открытых исходных кодов.
(41)Да, вопрос таргетирования на мой взгляд актуален.
использовать описанные инструменты я считаю можно и нужно даже если ты микрокомпания
Тогда, пожалуйста озвучте, что в Вашем понимании — микрокомпания? Ну скажем компания с 10 рабочими станциями — это микрокомпания (в разрезе ит инфраструктуры)? Соответственно какие из перечисленных Вами инструментов можно воспользоваться и какой эффект получить?
(42) Пусть будет что, да. За десятью рабочими станциями вполне может быть (но может и не быть: см Basecamp). В любом случае когда пользователям на этих десяти рабочих станциях становится необходима совместная работа, вот тогда и появляется вопрос куда двигаться. Кто-то предпочитает SAAS. Кто-то свое. SAAS — это, как правило, вендор лок. Если свое, то, на мой взгляд приоритет нужно отдавать вендоронезависимым решениям. Тогда в случае необходимости замены чего-то больше степень свободы. И в обоих вариантах собственнику, либо администратору лучше вникать как и что работает.
(42) Ну и посыл к управленцам: подход «сделайте мне все хорошо и я не хочу вникать о чем вы на своем птичьем разговариваете» — ведет к разрастанию пропасти между ИТ и бизнесом. Поэтому движение должно быть с обоих сторон.