<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\









Магия.
Респект и уважуха!
Подскажите что можно взять за основу для определения интервалов чисел.
Например есть массив: 1,2,3,6,7,8,11,12,15.
Надо получить интервалы 1-3,6-8,11-12,15-15.
Спасибо.
(3) В статье задача 2.
(4) а с использованием запроса?
(5) Тогда там же, но задача 14. В задаче речь идет о датах, но будет работать и на числах
65.
Показать
Не работает если учитывать условие «ни больше ни меньше». Когда больше — запрос отрабатывает неверно.
Проверяю на БП 3.0 на запросе:
Показать
Допустим возьмём контрагента у которого КПП 3 строки: 775003035, 773601001 и 631050001
В запрос передадим массив КПП: 775003035; 773601001 и МассивКППКоличество = 2;
Запрос возвращает результат — этого контрагента, хотя у него 3 сроки!
Рабочий запрос:
Показать
(8) Вы правы, проблему увидел, в ближайшее время исправлю.
42 — da, eto zhestko
(8) Все же решил исправить по-своему. Для старых версий платформы так:
Показать
Для новых, где логическое выражение можно записывать сразу в поле запроса, так:
Показать
В числе строчек даже получился выигрыш.
Спасибо за внимательность!
Оглавление
72. Очистка строки от нецифровых символов
71. Определение суммарного покрытия перекрывающихся интервалов
70. Определение пересечения интервалов в кольце
69. Быстрое удаление строк в таблице значений
68. Получение интервалов неизменности курсов валют
67. Определение пропусков в последовательности чисел
66. Инвертирование периодов в запросе
65. Проверка совпадения таблиц
64. Проверка совпадения таблиц путем сравнения полного и внутреннего соединения
63. Получение списка простых чисел в запросе
62. Определение периодов работы сотрудников по данным СКУД
61. Найти документы, во всех строках которых колонка количество меньше либо равна нулю
60. Определение плановых остатков товара с учетом предшествующих фактических и будущих плановых продаж
59. Сравнение плановых и фактических дней отпуска
58. Получить дату по номеру дня недели и его порядковому номеру в месяце
57. Получение предпоследнего курса валюты
56. Определить элементарные интервалы, образующиеся при пересечении всех исходных интервалов
55. Найти количество записей, повторяющихся подряд несколько дней
54. Сравнение набора товаров, проданных сменами
53. Найти документ, состав табличной части которого соответствует параметру — таблице значений
52. Распределение товаров по ячейкам в запросе
51. Объединение пересекающихся периодов в запросе
50. Выделение разрядов числа без использования округления и деления по модулю
49. Посчитать запросом суммарную длительность различных состояний
48. Разбиение произвольного периода на интервалы в запросе
47. Поиск свободного штрихкода внутри одного префикса
46. Выбор записи по номеру из НЕПРОНУМЕРОВАННОЙ таблицы
45. Как в запросе секунды преобразовать в часы и минуты
44. Убрать префикс и лидирующие нули из номера
43. Перебор всех строковых комбинаций «0» и «1» в порядке возрастания числа единиц («00000″->»00001″->»00010»-> …»01011″…)
42. Транслитерация в запросе
41. Заполнение пропусков в таблице цветов
40. Количество дней недели (понедельников/вторников/…) в заданном диапазоне запросом
39. Свернуть строки в таблице значений конкатенацией
(12) Спасибо, сделаю это оглавление в самой статье.
67. следующий вариант работает на порядки быстрее для больших таблиц (если не ПЕРВЫЕ 1 — выбирает все пропущенные значения и следующее по порядку):
ВЫБРАТЬ ПЕРВЫЕ 1
Т1.Х + 1
ИЗ
Дано Т1
ЛЕВОЕ СОЕДИНЕНИЕ
Дано Т2
ПО
Т2.Х = Т1.Х + 1
ГДЕ
Т2.Х Есть Null
УПОРЯДОЧИТЬ ПО
Т1.Х
З.Ы. на таблице в 1 млн. записей с индексированием по полю X (иначе какой смысл искать «дырки» в большой таблице и оставлять это поле неиндексированным) данный запрос выполняется за доли секунды в том случае как предложенный — десяток секунд.
(14)
все же бывают случаи и неиндексированных таблиц (например, если это временная таблица) и файловых баз и других СУБД, поэтому знать и уметь сравнивать разные варианты, кроме очевидных, бывает нужно.
может кому пригодится: нормализация представления числа
Показать
Пример1: ЗначениеМантисса = 0,1; ЗначениеПорядок = 0; НормализованнаяМантисса = 1; НормализованныйПорядок = -1 (0,1)->(1·10#k8SjZc9Dxk-1)
Пример2: ЗначениеМантисса = 10; ЗначениеПорядок = 6; НормализованнаяМантисса = 1; НормализованныйПорядок = 7; (10·10#k8SjZc9Dxk6)->(1·10#k8SjZc9Dxk7)
Пример3: ЗначениеМантисса = 500; ЗначениеПорядок = 0; НормализованнаяМантисса = 5; НормализованныйПорядок = 2; (500)->(5·10#k8SjZc9Dxk2)
Тоже поделюсь.
1. Количество знаков после запятой (максимум 27).
2. Проверка наличия заполненных значений в колонке. Пустые значения в колонке должны быть одного типа, т. е., не должны встречаться вместе, например, NULL и Неопределено.
По поводу «Быстрое удаление строк в таблице значений» есть сомнение в приведенном способе.
1. Если таблица значений занимает более 100-ни Мб в ОЗУ, то получаем лишний расход ОЗУ (на 1-ю и 2-ю таблицу)
2. Если в значениях таблицы значений есть ссылочные данные, то получаем нагрузку на процессор
Вариант синтаксиса: Скопировать по отбору
Описание:
Если указан отбор, то только строки из отбора будут скопированы. Если отбор не указан, то будут скопированы все строки таблицы значений. Если указаны колонки, то только эти колонки будут скопированы. Иначе, будут скопированы все колонки таблицы значений
Наилучшим решением будет удаление по отбору по индексированной колонке
(18) Сомневаться нужно, но, чтобы сделать выводы, нужны замеры. «Лишнего» расхода ОЗУ, нагрузки на процессор (видимо, имеется ввиду работа со структурой для работы сборщика мусора). Просто сказать «наилучшим решением будет» в данном случае недостаточно. Выигрыш приема из (69) был настолько большим (в моих измерениях), что его указанные минусы не перекрывают. — Попробуйте сделать замеры сами!
Пожалуйста вот замеры, обратите на 2-ю строку, отбрасывая все лишнее, только процесс удаления и создания:

1. Удаление не вашим способом
2. Удаление вашим способом

Почему так происходит? Понимание приходит, если кодить не только в 1С, а например кодить в ООП, в Java. На самом деле при вашем способе создается НОВЫЙ объект, в который копируются данные из СТАРОГО объекта, причем при наличии ссылочных типов, идет нагрузка на процессор (можно почитать про коллекции в Java, там ясно объясняется разница между insert/delete с примитивными типами и object). Я не могу тут привести размеры ОЗУ и нагрузку на процессор (придется заморочится), но поверьте я часто работаю с большими данными и вообще я считаю наиболее оптимальным способом является удаление через запрос.
Со всем уважением к вам! Ваши статьи лаконичны и самое главное практичны!
(20) считаете вышеприведенные варианты равнозначными?
«РабочаяТаблица.Индексы.Добавить(«КУдалению»);» Это ничего не говорит?
А теперь провести тесты с этим кодов в обоих способах и без этого кода. Результаты изменились? Неожиданно?
Я просто отметил, что быстрее будет удалить
А то что, без этой строки
будет дольше, это и так понятно. С самого начала я отметил — удаление по отбору по индексированной колонке.
(22)
А почему отказываете в индексации в другом примере? Где сказано, что в 69 обязательно не индексированная колонка?
С моей точки зрения там сказано, что при прочих равных условий будет быстрее создать новую таблицу, чем удалять строки.
Вы нашли «неравные» условия и сравниваете.
Рассматривая Ваше высказывание: «Наилучшим решением будет удаление по отбору по индексированной колонке», можно ответить:
«Быстрее всего удаляются строки путем копирования оставшихся строк по условию, обратному к условию удаления». При достаточно большой ТЗ, когда индексация начинает оказывать положительный результат, с индексацией нужной колонки
Но последнее предложение должно пониматься нормальным разработчиком по-умолчанию.
(23)
Хорошо вот вам равные условия:
результат
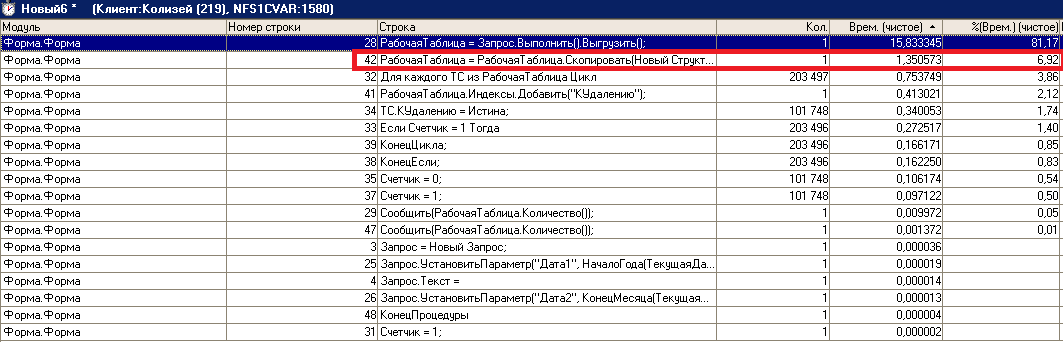
и соответственно
результат
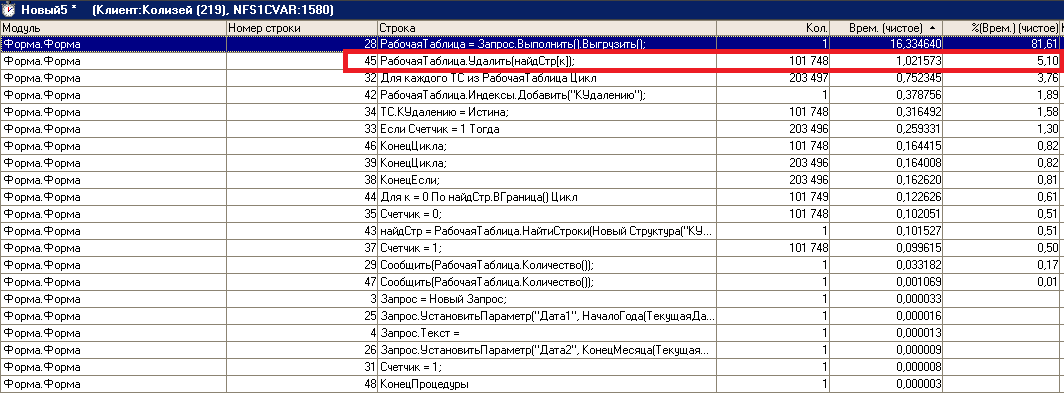
(23)
Порадовало 🙂 автор пишет, что:
которое оказывается на самом деле — это:
Быстрее всего удаляются строки путем копирования оставшихся строк по условию, обратному к условию удаления». При достаточно большой ТЗ, когда индексация начинает оказывать положительный результат, с индексацией нужной колонки
Ну и конечно напоследок
Но последнее предложение должно пониматься нормальным разработчиком по-умолчанию
Я бы дописал
Нормальные разработчики — это разработчики, у которых есть телепатическая супер сила. Это шутка :)! Да, я прочитал ссылку выше к задаче 69. И все равно считаю, что удалить моим способ быстрее и самое главнее надежнее. Представьте у вас в ТЗ ярды строк, способ предложенный автором на короткое время создаст 2 копии ТЗ с 2-кратным потреблением ОЗУ (на 1-ю и 2-ю ТЗ), потом конечно 1-я удалится. Но что если у вас ОЗУ на 2 ТЗ не хватит? Получите банально «Недостаточно памяти».
Со всем уважением!
(24) снова не то смотрите.
Код:
Показать
Замеры:
300 000
Кол-во элементов: 150 000
Время выполнения удалением: 2 014
Кол-во элементов: 150 000
Время выполнения копированием: 222
Кол-во элементов: 150 000
Время выполнения удалением: 2 000
Кол-во элементов: 150 000
Время выполнения копированием: 225
Кол-во элементов: 150 000
Время выполнения удалением: 1 973
Кол-во элементов: 150 000
Время выполнения копированием: 224
Кол-во элементов: 150 000
Время выполнения удалением: 2 025
Кол-во элементов: 150 000
Время выполнения копированием: 227
Кол-во элементов: 150 000
Время выполнения удалением: 1 989
Кол-во элементов: 150 000
Время выполнения копированием: 222
Что-то еще нужно доказывать?
(26)
Ну что же, теперь понятно, почему у вас отличные результаты чем у меня
вот как выглядит мой тест
Показать
я подаю на вход ТЗ из запроса, вы — нет….поэтому результаты тестов у нас разные
Так что и я прав и вы правы…..
(27)
Это шутка такая? Не смешно.
Показать
Что покажет этот код?
(28)
я тестирую на 1С 8.1 и смотрю через замер производительности
(28)
Опять же по поводу как формируется ТЗ. ТЗ можно формировать по разному, но вот удалить строки, как автор утверждает — быстрее всего ТАК!
Ремарка к «Это шутка! Не смешно»
Я тз к удалению подаю через запрос.
Удаление строк в таблице значений
Быстрее всего удаляются строки путем копирования оставшихся строк по условию, обратному к условию удаления:
РабочаяТаблица = РабочаяТаблица.Скопировать(Новый Структура(«КУдалению», Ложь))
(28)
ОШИБОЧКА У меня 🙂 я неправильно выполнял тесты. Сейчас вижу, что был неправ!
ВЫ правы коллега, я перепроверил еще раз — метод Автора быстрее.
В споре рождается истина — рад был поспорить с вами.
Единственно, все еще пока сомневаюсь — это расход ОЗУ.
Со всем уважением!
Спасибо автору за интересные публикации.
Хочу поделиться своей версией минимализма для задачи 57:
ВЫБРАТЬ ПЕРВЫЕ 1
КурсыВалют.Период,
КурсыВалют.Валюта,
КурсыВалют.Курс
ИЗ
РегистрСведений.КурсыВалют КАК КурсыВалют
ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБРАТЬ
МАКСИМУМ(КурсыВалют.Период) КАК Период,
&ВалютаСсылка КАК Валюта
ИЗ
РегистрСведений.КурсыВалют КАК КурсыВалют
ГДЕ
КурсыВалют.Валюта = &ВалютаСсылка) КАК МаксПериодКурсаВалюты
ПО (МаксПериодКурсаВалюты.Период > КурсыВалют.Период)
И (МаксПериодКурсаВалюты.Валюта = КурсыВалют.Валюта)
УПОРЯДОЧИТЬ ПО
КурсыВалют.Период УБЫВ
Протестировал оба варианта на таблице из 65 тысяч записей, этот вариант отрабатывает в два раза быстрее.
Опять просмотрел все статьи… как всегда очень интересно, а местами забавно)
но что то меня начали пугать «минимализмы» в запросах….
Могу добавить в копилку: Знак числа
70. Это точно работает?Если в переменных start и end задать «с 8 до 9», а с 9 до 10 интервал существует, то условие некорректно
(35) Тестировал в свое время достаточно внимательно, работать должно
Следовательно,
Вторая часть условия выполнится и из-за «или» станет истинным все условие.
Получится, что интервалы пересеклись.
Если хотите, чтобы они не пересекались, задайте значения
end = ЗаписиНаРемонт.ОкончаниеВыполнения = 8:59:59, тогда у интервалов не будет общей секунды.
(36) Неудобно отнимать секунду…
Пришлось воспользоваться (где я также и ваше решение увидел в комментах).
Заменил на
Показать
из первого примера:
SET @start:=4;
SET @end:=8;
SEL ECT * FR OM `table`
WHERE
(`start` >= @start AND `start` < @end) /*смещение вперед*/
OR
(`end` <= @end AND `end` > @start) /*смещение назад*/
OR
(`start` < @end AND `end` > @start) /*вхождение — на самом деле здесь не обязательно оно обработается одним из предыдущих выражений*/
OR
(`start` >= @start AND `end` <= @end)/*поглощение и совпадение*/
Показать
Очень полено, спасибо 🙂
Спасибо! (51. Объединение пересекающихся периодов в запросе) — очень помогло для слияния периодов в запросе!
Работаю над задачей определения «находится ли геоточка внутри геополигона». Вроде нашел новое решение, хотел с Вами связаться, обсудить. Пока тестирую в реальном времени. Не гуглом и не Постгри, их таинственные методы не описаны.
(41) Это интересно, готов к обсуждению
44. Убрать префикс и лидирующие нули из номера
ломается с эксепшином Преобразование значения к типу Число не может быть выполнено.
Номер содержит пробелы.
(43) Да, на пробелы в номере (?) или последний пробел в «префиксе» этот вариант не рассчитан. А, по вашему, должен был?
(44) Пробелы в номере — это уже не номер) — или должен обговариваться как исключение.
А вот пробел в префиксе (он же может быть произвольным) — это вполне нормально.
Так что я за универсальность, и против ограничений (из-за неполноты решения) на входные данные.