
Я никого не призываю и не рекомендую так делать, но если время дорого, а свернуть базу хочется, то без этих запросов никак. Обработки по свертке даже с SQL запросами были опробованы и оставлены только для автоматического создания остатков и свертки регистров. Документы они все удаляют крайне долго, даже те, в которых нет контроля целостности ссылок.
У меня камнем преткновения были документы Заказ покупателя, которые имели 4 табличных части и вели свою историю аж с 2005 года. Накопилось там документов порядка полутора миллионов, казалось бы, не так уж много, но удаление их занимало адское количество времени и не давало провести свертку до утра, в связи с чем родился такой маленький sql.
В принципе это применимо к любым документам, но лучше сначала на котятах потренироваться. Пока таблицы вашей sql базы не станут вам родными и вы не сможете по памяти набивать названия таблиц основных регистров и документов.
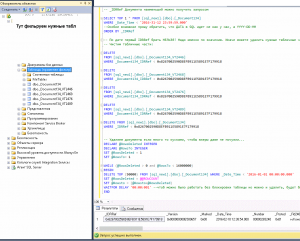
/****** Набор запросов для очистки документов заказы покупателей по дате ******/
—Как реально быстро почистить документы от даты…. А то обработки на Инфостарте тормозят дружно, даже где написано SQL
—Не забудьте свернуть регистры по документам. Например обработкой свертка и ввод начальных остатков.
—Имена таблиц в SQL можно получить любой обработкой их полно, например SQL БАЗОМЕР (заодно посмотрите, с чего начать)
—После удаления больших таблиц документов и закрытия регистров, даже штатная свертка отрабатывает на ура и быстро.
—Только на тестовой базе сначала, и BACKUP BACKUP BACKUP!!!!!
— _IDRRef Документа наименьший можно получить запросом
SELECT TOP 1 FROM [sql_new1].[dbo].[_Document134]
WHERE _Date_Time < ‘2026-01-01 00:00:00.000’
ORDER BY _IDRRef
— По дате первый IDRRef брать НЕЛЬЗЯ! Надо именно по значению. Иначе можете удалить нужные табличные части заказов.
— Чистим табличные части:
DELETE
FROM [sql_new1].[dbo].[_Document134_VT2446]
WHERE _Document134_IDRRef < 0x8267002590D8EFB911E5891E7F179918
DELETE
FROM [sql_new1].[dbo].[_Document134_VT2468]
WHERE _Document134_IDRRef < 0x8267002590D8EFB911E5891E7F179918
DELETE
FROM [sql_new1].[dbo].[_Document134_VT2476]
WHERE _Document134_IDRRef < 0x8267002590D8EFB911E5891E7F179918
DELETE
FROM [sql_new1].[dbo].[_Document134_VT2489]
WHERE _Document134_IDRRef < 0x8267002590D8EFB911E5891E7F179918
— И сам документ
DELETE
FROM [sql_new1].[dbo].[_Document134]
WHERE _IDRRef < 0x8267002590D8EFB911E5891E7F179918
— если много, удаляем кусками, чтобы юзеры даже не почуяли…
DECLARE @RowsDeleted INTEGER
DECLARE @RowsTo INTEGER
SET @RowsDeleted = 1
SET @RowsTo= 1
WHILE (@RowsDeleted > 0 and @RowsTo < 16000000)
BEGIN
DELETE TOP (50000) FROM _Document134 WHERE _Date_Time < ‘2026-01-01 00:00:00.000’
SET @RowsDeleted = @@ROWCOUNT
SET @Rowsto = (@Rowsto+@RowsDeleted)
— WAITFOR DELAY ’00:00:001′ —чтоб можно было работать без блокировки таблицы, можно удалить
END
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Реально быстрая очистка
изобретение велосипеда, серия 100500-я
зачем изучать что было сделано до тебя, когда можно самому изобрести велосипед… )))
нужное во временную таблицу, остальное транкейтим, потом из временной таблицы назад нужное…
битые ссылки в борьбе за 5 гигов места … шел 2018 год
Delete — плохо
Truncate — рулит
(3) Ну, так-то в нашей базе на 500+ гиг таким варварским методом можно базу процентов на 10-20 уменьшить… Но метод ужасен, да
Еще до кучи — SELECT — остатки товаров
—DECLARE @XXX binary(16)
—SET @XXX = (SELECT _IDRref
—FROM _Reference55
—where _Code = ‘ЦБ005’)
—SELECT @XXX
—SELECT _AccumRg6465._Period AS Период, _AccumRg6465._Fld6469 AS Количество, _Reference55._Description AS Организация,
— _Reference52._Description AS Номенклатура, _Reference70._Description AS СкладКомпании
—FROM _AccumRg6465
—LEFT OUTER JOIN
— _Reference70 ON _AccumRg6465._Fld6467RRef = _Reference70._IDRRef LEFT OUTER JOIN
— _Reference52 ON _AccumRg6465._Fld6466RRef = _Reference52._IDRRef LEFT OUTER JOIN
— _Reference55 ON _AccumRg6465._Fld7882RRef = _Reference55._IDRRef
—WHERE (_AccumRg6465._Period BETWEEN CONVERT(DATETIME, ‘2010-12-31 00:00:00’, 102) AND CONVERT(DATETIME, ‘2010-12-31 23:59:59’, 102))
SELECT COUNT(_AccumRg6465._Fld7882RRef)
FROM _AccumRg6465
— UPDATE_ВзаиморасчетыКомпании
DECLARE @XXX binary(16)
SET @XXX = (SELECT _IDRref
FROM _Reference55
where _Code = ‘ЦБ005’)
—SELECT @XXX
update
— UPDATE_ДенежныеСредстваКомпании
— DECLARE @XXX binary(16)
SET @XXX = (SELECT _IDRref
FROM _Reference55
where _Code = ‘ЦБ005’)
—SELECT @XXX
update
(2)
Delete в цикле позволяет делать фоном.
(3)
Не за 5 гигов места, а за производительность в бекапах, да и отрезать надо было начало учета, где вообще все сверхкриво велось.
(5)
не про это было, а про дополнение к обработкам свертки, которые делетят намного медлннее. Выигрыш, не в объеме, а в производительности (у меня допустим индексы очень много занимают и я хочу чтобы они целиком в оперативке были) и в бекапах.
(4)
Да кто спорит, но тут можно на работающей базе споконой чистить хвосты постепенно. Truncate замечательно конечно, но это надо и таблицы создавать и тд…А если таблица весит 50 гигов, а стереть надо в ней только первые 2-3 года…
(8)
Регистры неплохо сворачиваются автоматически обработками по свертке базы. Там нажал получил. А документы просто долго реально любыми, поэтому после свертки документы почистить можно либо delete либо как выше рекомендуют селектами в овременные, но там телодвижений больше, а тут запустил и забыл.
(14) да, если это не остатки, то можно и прямо во время работы.
А если остатки?
В теории тоже можно скулем самому очистить движения до даты, и остатки до даты, а первые остатки записать в движения на какой-либо регистратор (даже битый — пофиг). Если вдруг кто-то пересчитает итоги — все будет норм.
А если это хозрасчетный? А если нужно в остатках поправить пустые ссылки в валюте, неверные типы в субконто и прочие косяки древних кривых данных? Все становится не так просто. Без монопольного доступа к регистру — никак.
Ну и представьте, что из 500 млн строк нужно удалить 400 )))))) делете будет выполняться день как минимум. А если это full recovery ??? (Даже и представить не могу, что может быть у кого simple)
меня пугает
_IDRRef < 0x8267002590D8EFB911E5891E7F179918
тк обычно _IDRRef — случайное значение для разных сессий, а в пределах сессии — инкрементальное.
(17) Серьезно? оно сквозное на всю таблицу, как оно случайным может быть?
(18) тогда подумайте логически , сколько в базе должно быть документов , чтобы достичь значения 0x8267002590D8EFB911E5891E7F179918
для инкрементального счетчика 4 байт хватилобы вместо 16
(19) Ну в 1с много что сделано с запасом. А все же откуда уверенность в случайности? или случайное все же берется больше чем последнее?
1. Удалять нужно периодами
2. Про журналы документов нужно еще не забыть, т.к. это отдельная таблица.
3. Табличные части / движения документов, потом сами ссылки
(20)
(22) Убедили, но проверка на практике говорит, что все же он может и местами случайный, но инкрементальный. То что там много байт длина это не значит что значимые не последние 5-6 всего, а начало уникально для базы или справочника
(23) инкрементальный в том смысле, что возрастающий ,а не что a++
(22) ну напрочь рандомны он там только на справочниках , а на регистрах там он генерится из даты… другое дело что там в дате похоже разряды перемешаны, Поэтому прям от номера отрезать нельзя, можно зацепить полдня того же, вы правы, я еще раз перепроверю как оно вживую происходит.
(17) Тоже режу базу таким же макаром. У нас PostgreSQL. Ну и, чтобы, совсем не бояться _IDRRef решил вот так делать:
DELETE FROM _document397_vt9019 WHERE _document397_vt9019._document397_idrref IN (SELECT _idrref FROM _document397 WHERE _date_time < ‘2016-01-01 00:00:00’);
DELETE FROM _document397 WHERE _date_time < ‘2016-01-01 00:00:00’;