<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\









(0)
Сергей.
За статью — «плюс» однозначно.
Однако в сообщении #79 темы «Реально написать хитрый запрос»(с) — поставлена другая задача. И Ваше утверждение «Хотя на самом деле проблема может быть всего лишь в неверно выбранном алгоритме»(с) — верно, но не для поставленной Игорем задачи.
Думаю, что любой алгоритм «базируется» на структуре хранения (представлении) данных. А в постановке от Игоря — структура хранения должна быть «только такой», а данные должны храниться и обрабатываться в «реляционной модели», а язык манипулирования данными должен быть «запросного» типа.
Игорь, думаю, специально поставил задачу так, чтобы «Мы писали запросы»… 😉
Выше по его теме и «исходной» темы, было многократно сказано, что изменение структуры хранения данных и ЯМД позволяет решать задачу «разузлования» — быстро и простым алгоритмом.
Исходная тема: с сообщения #151.
Будем плясать от печки. От постановки задачи.
Что мы решаем ? Почему это четко не обозначено в начале темы ?
Придется строить догадки , что же решает автор ?
1. Задачу разузлования в общем виде ?
Тогда нам дана структура таблицы Ссылка, Номенклатура,Количество , в которой содержатся не один граф, а все графы, описывающие все спецификации на предприятии.
Действительно , смешно заводить Справочник для каждого нового сложного изделия.
Поэтому в Справочнике есть спецификации и «паровоза», и «тепловоза», и много чего еще. Из этого вытекает, что перед началом разузлования мы ничего не знаем о графе , который в нем содержится , не знаем какие записи в Справочнике нашего искомого изделия, а какие принадлежат другому изделию , не входящему в исследуемый нами граф.. Повторяю мы Н И Ч Е Г О не знаем о графе. Ни количество связей(510 у автора) , ни количество элементов(61- у автора) , неизвестно повторяются ли элементы в этом графе, есть ли зацикливание ? Неизвестен и уровень графа. Ответ на эти вопросы можно получить только одним способом : обойти все узлы графа. На форуме я безуспешно пытался втолковать это автору. Но может быть я что-то не понял ? и тогда :
2. Решается задача разузлования для искусственного, придуманного мной примера ?
Но пример этот был придуман всего лишь как удобный легкий тест для оценки быстродействия универсального алгоритма обработки произвольного графа. И я не понимаю для чего его здесь решать ? Что это нам даст ?
Задача разузлования для графа с известной повторяющейся структурой — есть задача ТРИВИАЛЬНАЯ . Её не нужно решать.
Но даже решая тривиальную ,никому не нужную задачу получаем у автора :
Какой прок пользователю ведущему работу по спецификациям узнать о какой-то вершине.
Для того чтобы исправить ошибку пользователь должен знать и видеть всю ветку содержащую ошибку начиная от корневого элемента . Еще раз внимательно посмотрите на прикрепленном скриншоте , как нужно показывать ошибки зацикливания пользователю .
Разговор же о том , как сделать алгоритм более устойчивым к повторениям элементов и не попасть на миллиард в произвольном графе:( например,1-1000-1000-1000 ) — достаточно сложен , в реальной практике даже не знаю где встречается и я ,честно говоря, не решаюсь его даже начинать .
Вопрос :
Имеем граф целиком :
Посмотрите на элемент Б0 на третьем уровне. Мы уже раньше побывали в Б0 — это будет считаться зацикливанием ? Такой граф будет решен Вашей обработкой ?
Ребята, я из этой темы на форуме вышел уже давно… т.к. абсолютно бесполезный спор… я привел пример простого динамического списка, у которого всегда есть ссылка на его родитель , тем самым у него никогда не может быть зацыкливания. Пример, иерархия папок в 1С. Например, в Excel если оперировать формулами в ячейках, может быть зацыкливание, однако это решается. Искать решение же задачи, типа «что может быть, а может и не быть», только одними запросами без дополнительных средств, тоже самое, что концатрептив натягивать на голову… Я предложил простой вариант: сделали запрос, выгрузили в промежуточную таблицу, проиндексировали поле, и ищите себе на здоровье…
2(4): Б0 — кто у этого элемента родитель?
блин, нужно завтра на свежую голову перечитать…
(5)
Ярослав.
В ТОЙ теме нет никакого спора. Про циклы — точно, нет спора.
Думаю, вопрос (условие) про цикл поставлено постановкой задачи от Игоря, чтобы НАМ не удалось сделать «простой вариант: запрос — выгрузили в таблицу — проиндексировали — ищите».
Игорь, я — прав? 😉
(5)
+(8)
Т.е. есть четкая, не изменяемая в процессе решения, схема БД. Есть условие — проверять «циклы» и считать количество изделий на нижнем уровне. Делать в реляционной модели БД. Делать на ЯМД реляционной СУБД. Использовать запросы. Всё…
(6) В этом графе три полных ветки :
1. А0-Б0
2. А0-Б1-С0
3. А0-Б1-Б0
Элемент Б0 встречается в первой ветке и в третьей. Вопрос : это зацикливание для представленного автором алгоритма или нет ?
(10)(6) Это не зацикливание.
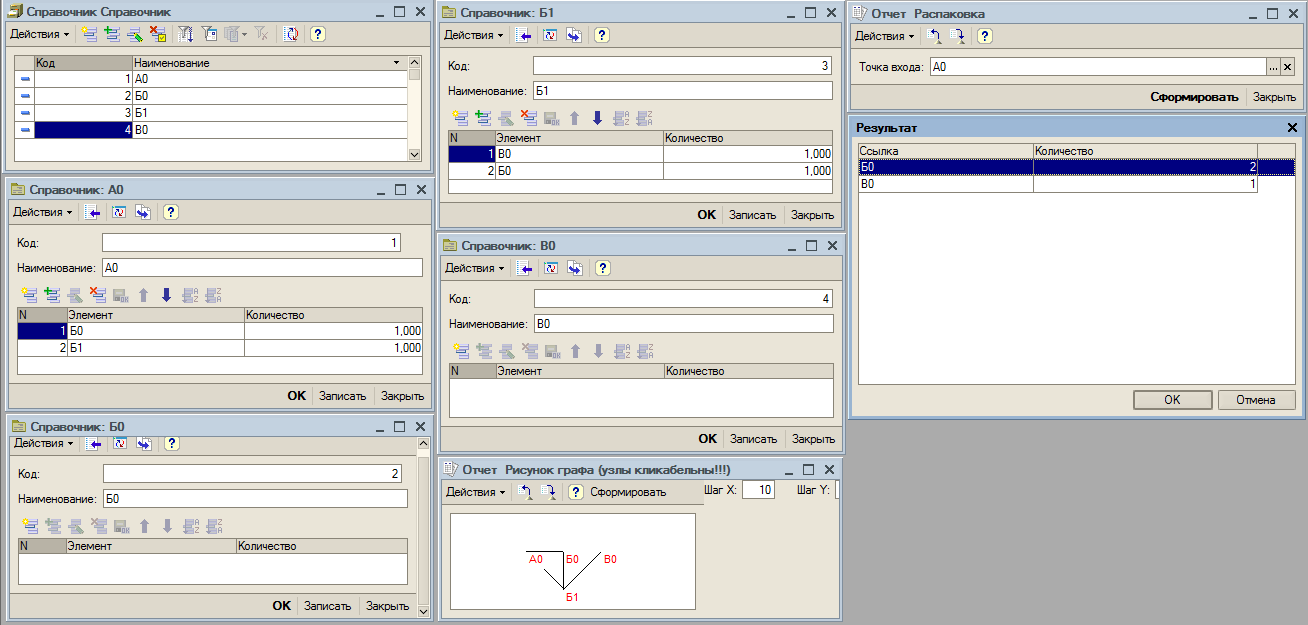
Вот скриншот.
Здесь вес дуг предположен равным 1, а С0 заменена на В0 для вывода рисунка
Исследовал произвольные графы с 1000 узлов и 1000, 2000, 3000, 4000 дуг ( ), а тут появилась эта статья. Будем пробовать и такой граф обходить…
(11) Отлично. Продолжим . Представим , что элемент Б0 из (10) представляет собой Вами первоначально представленный в теме граф 1-10-10-10-10-10-10. Почему нет ? У Вас же универсальная обработка графа, оптимизирующая повторения элементов. Что будет с Вашим алгоритмом ?
(12) Арчибальд , э… ты что-то пропустил. У нас графы начинаются с миллиона узлов.
(14) В данной статье — 510 дуг и 61 узел. Так что в тему 🙂
(13) Игорь! Я буквально придерживался условий Вашей задачи!
В посте (79) сказано
Еще там же сказано
Ж001,Ж002…Ж010 со своими количествами.
Контроль зациклинности обязателен. Т.е. каждая ветка мысленно полученного дерева должна быть проверена на повторение элементов в этой ветке.
Реализовать алгоритм можно каким угодно образом.
В посте (116) сказано
Таким образом дерево 1-10-10-10-10-10-10 Вы строите мысленно и не храните в базе.
Да и зачем его нужно было бы хранить? Чтобы отличать каждую из 100 000 «гаек» на последнем уровне на ней нужно выгравировать серийный номер, потом иметь 10 000 спецификаций на предпоследнем уровне, указав в каждой серийный номер гайки. Такое могут делать разве что в ракетах.
Я согласен, что кроме шести десятков номенклатур в справочнике может быть и другая номенклатура. Задайте, пожалуйста количество других элементов справочника номенклатура, чтобы я смог сообщить Вам время выполнения программы в таком случае, хотя это и не было предусмотрено исходным заданием.
(2) Соглашусь, что не переименовав справочник «Справочник» в справочник «Номенклатура», я усложнил понимание статьи. Вскоре исправлю.
Хотя алгоритм универсальный, из-за применения массива для хранения промежуточных разузлований, он работает для конфигураций, справочник «Номенклатура» в которых содержит до 5-10-ти(?) тысяч номенклатур, а эффективней работает только до нескольких сотен. Это преодолимо — переделаю на таблицы значений.
Также совсем нетрудно распечатывать ошибочный цикл (добавлю один параметр в процедуру Распаковать()).
(16) Начнем всё сначала. Весь смысл беседы на форуме сводился к тому :
Как эффективно работать с произвольным графом ?
Рассматривались родственные задачи . Общим свойством у которых является трудоемкость решения.
Каждый что-то предлагал …
Как же узнать (протестировать) эффективность какого-либо алгоритма работы с произвольным графом ?
Вот и был придуман тест ,как критерий эффективности, который на очень малом количестве данных, мог быстро выявить эффективность предлагаемых решений. Тест этот — 1-10-10-10-10-10 хорош тем что легко , просто реализуется .
В С Ё ! Больше никакой нагрузки этот тест не несет ! Он играет вспомогательную роль !
Тесты не решают , потому что их решения хорошо проверяемы и известны заранее.
Скажите , зачем его решать ? Ведь это частный случай ,»не встречающийся в природе» !
Действительно ,что же я буду выдумывать вспомогательные тесты , а Вы будете находить для них решения ?
Замучаетесь поспевать за мной . Я буду с легкостью опрокидывать Ваши алгоритмы новыми примерами.
Поэтому стоит отказаться от решения частных случаев и вернуться к первоначальному вопросу :
как реализовать универсальный алгоритм работы с графом , чтобы он был «в среднем» оптимален.
Представьте себе что все элементы в Вашем графе 1-10-10-10-10-10-10 уникальны . Нет повторений .
Что будет с Вашим алгоритмом ? у Владимира — это менее 200 сек . А у Вас ?
(18) Алгоритм универсальный, работает с произвольным графом. Для того, чтобы в этом убедиться, достаточно скачать конфигурацию и вручную ввести в справочник структуру этого произвольного графа. Если договоримся о формате, сделаю загрузку из файла.
Могу предложить текстовый файл, в каждой строке которого содержится строка спецификации в виде тройки чисел: код номенклатуры-набора, код номенклатуры-элемента, количество элемента в наборе.
(19) Заполнение Вашего графа 1-10-10-10-10-10-10 уникальными значениями в реквизите «Элемент» займет часа три.
Попробуете ? Если да , то сколько будет работать Ваше «разузлование» для такого примера ?
(18) Алгоритм универсальный, работает с произвольным графом. Для того, чтобы в этом убедиться, достаточно скачать конфигурацию и вручную ввести в справочник структуру этого произвольного графа. Если договоримся о формате, сделаю загрузку из файла.
Могу предложить текстовый файл, в каждой строке которого содержится строка спецификации в виде тройки чисел: код номенклатуры-набора, код номенклатуры-элемента, количество элемента в наборе.
Хотелось бы узнать про практические примеры 10-арных 6-ти уровневых деревьев, элементы которых стоило бы хранить в информационной базе. На мой взгляд в жизни такие задачи практически не встречаются. Сколько у Вас пользователей, у которых в Справочнике «Номенклатура» 1 000 000 элементов, а 100 000 спецификаций?
(20) Сначала я бы хотел, чтобы Вы признали, что поставленная Вами в посте #79 обсуждения «Реально написать хитрый запрос» задача была решена за 0,122 секунды.
Потом, согласились с тем, что графы 1-10-10-10-10-10-10 с уникальными «листьями», которые нужно хранить в информационных базах клиентов, в жизни практически не встречаются.
Ну а потом, я уже получал результат 180 секунд. Могу с этой точки начать оптимизацию.
Но хотелось бы убедиться в актуальности этой новой задачи.
(20) Конечно , Сергей ! Нет таких практических примеров !
Для чего эти тесты ? Для того чтобы выявить предельные возможности того или иного алгоритма.
Ведь если уж алгоритм на миллионе работает быстро , то на реальных задачах (максимум 50 тыс -60 тыс в справочнике) будет просто летать. Вот для чего нужны тесты . А вариант с миллионом уникальных значений не высосан из пальца — и у меня и у Владимира время алгоритма практически неизменно.
Давайте конкретно.
Представьте себе алгоритм :
для Вашего графа в текущей теме 1-10-10-10-10-10-10 — он показывает время 20 сек .
Если в этом графе все значения уникальны — он показывает время 50 сек.
Раскроем 50 сек :
1. Копирование во временную таблицу всего справочника СпецификацииНоменклатуры 8 сек
2. Разузлование как таковое 25 сек.
3. Выгрузка результата запроса в таблицу значений на форме ( 1 000 000 строк) -18 сек.
Т.е. практически время разузлования как такового изменилось несущественно, учитывая что таблица Спецификаций увеличилась в десятки тысяч раз. Было 20 сек — стало 25 сек.
(22)
Признаю , что
поставленная мной в посте #79 обсуждения «Реально написать хитрый запрос» задача была решена Сергеем за 0,122 секунды.
Признаю,
что графы 1-10-10-10-10-10-10 с уникальными «листьями», которые нужно хранить в информационных базах клиентов, в жизни практически не встречаются.
(23)(24) Игорь! Спасибо Вам за задачу.
Меня, конечно, интересует запрос в пункте «2. Разузлование как таковое», тем более, у меня есть свой симпатичный, но пока не эффективный вариант (в обсуждении «Хитрый запрос» я его показывал). Буду ждать Вашей публикации.
Ваш пример о суммировании квадратов средствами СУБД был очень убедителен.
(12) К сожалению, в реальном программировании на 1С графы встречаются редко:
— разузлование;
— маршруты развоза товаров;
— подчиненность документов;
— аналоги номенклатуры;
— везде, где в справочниках или документах есть ссылка (может быть не прямая) на аналогичный объект;
— структура конфигураций, программных модулей.
Какие еще примеры Вы можете привести?
А если это вдруг действительно сложная в вычислительном отношении задача, то решать ее на языке 1С трудно — большие накладные расходы. Здесь лучше применять внешние компоненты. Тем более структуры графов легко транслируются через интерфейсы.
Так что боюсь, результаты исследований будут представлять чисто «академический» интерес.
(26) Подождите чуть -чуть. Я уже месяц откладываю публикацию.
(27) Новый год на носу, однако 👿
(26) Соглашусь. А никто не пробовал прикрутить к 1С matlab (или maple )?
(25)
«Ваш пример о суммировании квадратов средствами СУБД был очень убедителен.»(с)
1) Чтение файла большими блоками, а не по записям.
2) Чтение без использования индекса.
3) При повторном чтении — все данные уже в памяти (фактически в массиве).
4) Суммирование 1000000 «квадратов» в массиве НЕ на 1С — 1.5 миллисекунды.
5) Суммирование 1000000 «квадратов» в массиве на 1С — 1.8 секунды.
В данном примере нет никаких «средств» СУБД.
Арифметика… 😉
(29) 1С + MatLab было бы интересно! Не слышал пока о таком. Возможно, MatLab просто дорог.
(25) Я извмняюсь. Допускаю,что есть какой-то глубокий смысл в перечислении 1)-5).
Но мне он не доступен.
Смысл сравнения миллиона циклов в 1с и суммирования миллиона квадратов с помощью select был только один .
И не тот, что предположил Владимир.
Не в технике тут дело. А в способе работы с данными.
Отсюда прямой вывод :
нужно максимально использовать при обработке возможности сервера SqL Не качать данные туда -сюда (с клиента на сервер) , а обрабатывать данные полностью там , где они хранятся. Это значит в современных СУБД ТОЛЬКО одно — использовать запросы ,
как родной инструмент SQL-сервера. Груубо говоря, SQL- язык не выборки данных для последующей их обработки на клиенте ,
а язык выборки и ОБРАБОТКИ данных (там же на сервере) и передачи на клиента лишь результата вычислений.
В (30) — глубокое непонимание этого назначения SQL.
Рассмотрим п.4,5 в (30):
Суммирование 1000000 «квадратов» в массиве на 1С — 1.8 секунды.
Пример, конечно, убойный.
Владимиру тут всё ясно и обсуждать нечего :»В данном примере нет никаких «средств» СУБД.»
Это значит , замени программное обеспечение на «не 1с» и получи в 1000(!!!!) раз быстрее .
Когда пройдет первая радость от такого счастья , выяснится что прежде чем сложить миллион квадратов на «не 1с»- массиве,
нужно их откуда-то взять… Откуда ? — оттуда, где хранятся данные, только с сервера. Как ? — Выбрать командой select.
Получай, бабушка, свой миллион чисел в оперативную память за 10 сек(!!!!) и складывай
их с сумашедшей скоростью за 1.5 миллисекунды.
Так, может , мы останемся на «медленном» 1с ? выдадим команду на сервер select sum(a*a) from table ,
получим с сервера ОДНО число-сумму и все вместе улыбнемся ?
(32)
Игорь.
Фразы типа «глубокое непонимание этого назначения SQL.»(с) говорите себе. Я могу Вам рассказать всю цепочку действий системы от «тупого» нажатия кнопки в «СКД», до команд ввода/вывода уровня команд порта — in,out.
В моем сообщении #30 сказано, что Ваш пример запроса с Sum() позволяет серверу БД выполнять суммирование «квадратов» на сервер и не передавать строки таблицы клиенту, а передать клиенту только одно число. Кроме этого, по сути SQL запроса, сервер имеет возможность просматривать таблицу без учета индекса и анализа условий отбора. А это означает, что он может применить операции чтения блоками по несколько логических записей. И эти блоки, после чтения с диска, представляют из себя массив (массивы) данных в оперативной памяти. При таких малых размерах таблицы, как в нашем примере — это может быть одним-двумя массивами, если используется специфическая для сервера БД файловая система. Данные в полях хранятся, скорее всего, в числовом, а не символьном виде и это не требует затратных действий по преобразованию типов данных (против языка 1С).
Таблица БД такого размера читается блокам в оперативную память, даже на файловой системе NTFS — за доли секунды. Если сервер использует многозадачность, то при чтении несколькими блоками всей таблицы — может использоваться параллельный подсчет сумм «квадратов».
Игорь, это азбука СУБД… 😉
А Вы упрямо путаете два термина SQL и СУБД.
(32)
+33
Игорь.
Вы в своих изысках на тему «Мы пишем запросы»(с) плавно и логично подошли к «последнему алгоритму» этой темы — обход «дерева». На протяжении всего Вашего цикла я, безуспешно, пытался обратить Ваше внимание, что «запросный» метод обработки информации не подходит для очень большого количества алгоритмов.
Вы упрямо, в своём цикле, «собирали» эти алгоритмы. Вы их собрали — почти все…
Но наличие этих алгоритмы (задач) уже поняли, даже, «разработчики» SQL серверов. Посмотрите внимательно на развитие этого языка. Всё, что добавлялось в него направлено на возможность решать SQL-ем не только задачи по выходным (отчетам) формам.
А Вы — всё упрямствуете… 😉
(32)
+33
Игорь.
Извините, я забыл самое главное написать в своих ответах на Ваше #32 сообщение — конкретику. Вам удалось свой пример про Sum() прицепить к задаче обхода «дерева»? Или это просто пример (ошарашить читателя) скоростями «запросов» безотносительно решаемой задачи? Типа — мы и «дерево» обойдем Sum-ами…
(35)Нет. Использовать sum(), как борбу с повторениями элементов в задаче не удалось.
Хотя тест 1-10-10-10-10-10-10 , казалось бы, просто требует этого.
Но при контроле зацикленности всё усложняется.
Проще говоря : Как нам не попасть на миллиард ? — я отказался от рассмотрения этого вопроса.
Непрактично, маловостребовано. Вообщем , в настоящий момент выгодней считать , что «зелен виноград».
(32) Игорь!
Если Вы заметили, я не спорю с Владимиром. Потому что он говорит правильные вещи.
Но в то же время мне не хотелось бы гасить Ваш энтузиазм в поиске задач, которые эффективней решать в запросной технике. Такие задачи есть. Просто это не все задачи, где «на входе миллион элементов, а на выходе — несколько чисел». Хотелось бы знать более точное универсальное правило, если оно существует. Мне кажется, Ваши поиски, пусть и не во всех случаях удачные, этому способствуют.
Кстати, matlab может работать с odbc совместимыми данными — т.е. и sql server-ом. Очень интересная задача, будет время — надо подумать. Мне кажется 1С несмотря на изворотливость программистов, все таки для таких задач не оптимальный вариант. А вот связка 1С — matlab — sql — была бы интересной, может кто осилит? И все таки описанный в статье метод мне нравится.
(32) Игорь!
Если Вы заметили, я не спорю с Владимиром. Потому что он говорит правильные вещи.
Но в то же время мне не хотелось бы гасить ваш энтузиазм в поиске задач, которые эффективней решать в запросной технике. Такие задачи есть. Просто это не все задачи, где «на входе миллион элементов, а на выходе — несколько чисел». Хотелось бы знать универсальное правило, если оно существует. Мне кажется Ваши поиски, пусть и не во всех случаях удачные, этому способствуют.
(37)(39) начался цикл 😀
(0),(28),(30) Господа . Я старался для вас !
(0) А в чем проблема — рекурсией спуститься до элемента Д0, посчитать сколько там элементо Е0…Е9, запомнить в кэш. Затем до элемента Д1, посчитать и в кэш. …. до Д9… На элементе Г0 уже не надо будет опускаться до элементов Д0-9 — все уже посчитано в кэше.
Итого мы получим 51 операцию разузловки — и никакого страшного миллиона.
PS В чем делали такой прикольный рисунок графа?
(42) Это и не проблема, просто рекурсия проиграет, я думаю, в производительности. (времени выполнения)
(43) если Вы не будете пользоваться кэшем, то моя рекурсия с кэшем победит по скорости.
(42) Именно такой метод и описан в статье. Приведен текст программы (на скриншоте). Она работает с любыми ориентированными графами!!! Вообще любыми. Можете скачать конфигурацию и проверить. Программа на фиг3 построена на массивах. Матрица — это массив массивов. Матрица[ё] — это тоже массив (вложенный) — кэш узла «Упаковка». У массивов недостаток — ограниченное число вершин. Сейчас переписал на соответствия. Решается вообще граф любого размера. В приложенной конфигурации все это есть.
А также обработка, рисующая граф (узлы кликабельны) — присмотритесь к приложенному изображению №2.
И еще — программа на фиг2 решает задачу тест №1 из статьи за 0,122 секунды — в 200 раз быстрее запроса!
Сейчас закончил оптимизацию для графа из 1 111 111 вершин. Пишу тесты.
Статья написана не для Вас, Вы этот метод знаете и не будете пользоваться перебором, а многие пользуются и отказываться не хотят, споря о некой «абстрактной» рекурсии. Присмотритесь к фиг3 — это и есть работающая в этой и вообще в любых задачах разузлования рекурсия.
(43) Именно так! Только рекурсия не Ваша, а наша!
Статью планирую переписать, сделав ее более понятной.
Так что , Сергей ?
Насчет новой темы со сравнительным анализом двух обработок ?
Вдруг рекурсия и правда — выиграет у запроса ? А почему бы и нет ?
Уже по Вашим правилам и тестам .
Почему бы не создать теперь уже не «пулялку» по тестам №1,№2 , а технологичное решение для БП 1.6 и
в сравнительном анализе — утереть всем нос : СМОТРИТЕ — мой товар лучший !
(47) Не вижу смысла:
1. Сравнительный анализ по быстродействию я провел, результаты опубликовал (в Вашей теме), закономерность определил, результаты других тестов будут «бить лежачего» (ваш подход). Зачем это Вам?
2. Сравнивать «юзабилити» (технологичность) в отсутствии Заказчика или объективного судейства невозможно. Хотя я представляю себе, как сделать удобный интерфейс, все же не считаю эту задачу сложной и нужной для себя.
Вам могу посоветовать убрать вкладку «ошибки» и отмечать ошибки цветом прямо на закладке спецификации. Цвет определять, используя «кодинг»-контроль зацикливания.
Кстати, обратите внимание, что в конфигурации, приложенной к статье есть обработка, рисующая граф средствами 1С, с кликабельными узлами! (присмотритесь к скриншоту №2, да и в заголовке — скриншот графа, нарисованной этой обработкой).
3. Будет время, я опубликую обработку, приложенную к данной статье, отдельно, снабдив описанием. Появилась идея еще немного ее ускорить на тесте 1<10<10<10<10<10<10 (улучшить результат 114 секунд) и увеличить число уровней в матрешке 1-1-1-1-1-1-1-1-1-1 -…-1-1. Сможете сами ее опробовать, сравнить со своей.
Ну, а «утирать Вам нос» — не моя задача. Хотел подсказать, объяснить, посоветовать…
(48) Подсказывать , советовать Вам рано.
При тестировании Ваши построения разлетелись вдребезги.
Вам нужно научиться практически доказывать свои измышления.
Я предложил Вам шанс — практически доказать , что Вы можете изготовить не «пулялку».
Вы отказались.
Вот и всё.
(49) Вы много раз повторяете одну и ту же НЕПРАВДУ!
Повторение этой НЕПРАВДЫ ничего не меняет — приложенная к статье обработка на всех тестах работает очень
быстро и абсолютно правильно!
Учиться не отказываюсь, только вот нервируют термины «пулялка», «Сергей засыпался», «измышления», «разлетелись вдребезги», «очередная ошибка Сергея», «советовать Вам рано» в случаях, когда я почти наверняка знаю, что прав!
Свой шанс что-то Вам доказать я использовал по-максимуму — все мои доводы Вы пропустили мимо ушей! Почему?
Кстати, повторюсь, — один интересный для меня тест еще остался — «Электровоз»! Его бы я попробовал!
Всегда готов отбросить предубеждения и рассмотреть интересный практический вопрос.