



* Есть желание повысить скорость работы медленных алгоритмов! Но…
* Нет времени думать о реализации многопоточности?
* о запуске и остановке потоков?
* о поддержании потоков в рабочем состоянии?
* о передаче данных в потоки и как получить ответ из потока?
* об организации последовательности?
Тогда ЭТО — то что надо!!!
Обновления
Обновление "Менеджер потоков" 2.0.7
Изменения (возможно придется править события разработчика)
- Модуль "мпМенеджерПотоков", разделен на 4: "мпМенеджерПотоковОбщее", "мпОсновнаяПрограмма", "мпМенеджер", "мпПотоки";
- Процедуры и функции размещены в областях;
- параметр инициализации "КоличествоЭлементовКолекцииНаПоток" теперь располагается "СтруктураПараметров.ПараметрыИнициализации.КоличествоЭлементовКолекцииНаПоток" (Ранее располагался: "СтруктураПараметров.ПараметрыИнициализации.ПараметрыОбработкиКоллекции.КоличествоЭлементовКолекцииНаПоток");
- параметр инициализации "ДинамическийРассчетКоличестваПотоков" теперь располагается "СтруктураПараметров.ПараметрыИнициализации.ДинамическийРассчетКоличестваПотоков" (Ранее располагался: "СтруктураПараметров.ПараметрыИнициализации.ПараметрыОбработкиКоллекции.ДинамическийРассчетКоличестваПотоков");
- параметр инициализации "РазрезМенеджеров" теперь называется "РазрезМенеджера";
- параметр инициализации "ПределКоличествоПопытокОбработатьОбъект" теперь называется "КоличествоПопытокОбработкиОбъекта".
Исправленные ошибки:
- связанные с выводом сообщений пользователю;
- связанные с определением "АдресОчереди" при перезапуске потока.
Небольшая оптимизация:
- значение по умолчанию для параметра инициализации "КоличествоПопытокОбработкиОбъекта" = 1 (раньше было: 5);
- обработка по принудительной остановке "Менеджера потоков" входит в поставку;
Обновление 12.03.2026
Восстановил картинки в публикации (видимо при предыдущем обновлении они были утеряны)
Обновление "Менеджер потоков" 2.0.6
Изменения (возможно придется править события разработчика)
- Данные рассчитываемые перед запуском нового потока теперь доступны в потоке(ах) по имени "ПараметрыРазработчикаПередЗапускомПотока" (до этого имя было: "ДанныеРарзаботчикаПередЗапускомПотока")
- Данные рассчитываемые при запуске нового потока теперь доступны в потоке(ах) по имени "ПараметрыРазработчикаПриЗапускеПотока" (до этого имя было: "ДанныеРарзаботчикаПриЗапускеПотока")
Исправленные ошибки:
- При работе с методом "ОбработатьОбъект" могла возникать ошибка (Спасибо Земко Сергей, за найденную ошибку):
- {ОбщийМодуль.мпМенеджерПотоков.Модуль(1514)}: Поле объекта не обнаружено (АлгоритмыРаботыСКоллекцией)
- КодСоздания = пСтруктураПараметров.ПараметрыИнициализации.ПараметрыОбработкиКоллекции.АлгоритмыРаботыСКоллекцией.КодСоздания;
- Событие "ПослеЗавершенияМенеджераПотоков" теперь ВСЕГДА выполняется самым последним. Имели место случаи, когда данное событие вызывалось ДО события "ПередЗавершениемМенеджераПотоков".
- Внесены корректировки в обработку коллекции без потоков (параметр определяется от объема коллекции и параметров инициализации):
- Результат события "ПередЗапускомПотока", теперь доступны по имени "ПараметрыРазработчикаПередЗапускомПотока" (до этого имя было: "ДанныеДляПотока")
- Добавлено выполнение события "ПриЗапускеПотока"
- Добавлено выполнение события "ПриОбработкеМассиваОбработанныхФагментовКоллекции"
- Добавлено выполнение события "ПриОбработкеДополненногоФагментаКоллекции"
- Исключено выполнение события "ПриОбработкеОбработанногоФагментаКоллекции"
P.S. Теперь обработка коллекции без потоков полностью имитирует вызов событий при работе в потоках.
Небольшая оптимизация:
- Скорректированно ожидание "пустых" циклов с 1 сек. до 0.1 сек. (данные циклы исполняются для синхронизации работы фоновых заданий уже после полной обработки данных)
Обновление "Менеджер потоков" 2.0.5
Исправленные ошибки:
- При выполнении метода "ДополнитьКоллекциюОбъектов", возникала ошибка при окончательной сборки новой коллекции.
- При выполнении метода "ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков", если в качестве второго параметра выступали ДвоичныеДанные внешней обработки, не происходила инициализация менеджера потоков.
Небольшая оптимизация:
- После того, как менеджер потоков завершал работу, можно было увидеть большое количество пустых сообщений. Теперь сообщения выводятся, только если они выводились в событии "ПриОбработкеДействияПотока".
Добавлена презентация с ISE 2026
Другие статьи и разработки на данную тему:
Бесплатные и условно бесплатные решения и статьи:
- TaskManagerFor1C — Автор: Евгений Павлюк;
- Многопоточность как способ ускорения некоторых процедур — Автор статьи: Алексей Бочков; (Показан САМЫЙ простой способ организации многопоточности)
- Многопоточная обработка данных — Автор: Алексанрдр Зыков; (Надстройка над конфигурацией позволяющая реализовать многопоточную обработку данных, с настройкой в пользовательском режиме, с отчетами и мониторингом)
- Многопоточное восстановление последовательностей — Автор: Алексанрдр Зыков; (представлен механизм реализации восстановления последовательностей в ЛЮБОЙ конфигурации и использованием "Многопоточной обработки данных". ПРЕДУПРЕЖДЕНИЕ для реализации в типовых конфигурациях может потребоваться корректировка типовых объектов метаданных)
Платные решения и статьи:
- Ускорение процесса восстановления последовательности в 1С 8 УПП с использованием параллельных вычислений — Автор статьи Softpoint (весьма познавательная статья с картинками)
- Параллельное восстановление партий — Автор: 1С-Рарус (Тут больше о достижении 1С-Рарус в решении данного вопроса, а также представлены результаты одного из заказчиков)
Все, что было в первой версии, переработано, улучшено и дополнено. В связи с чем она (первая версия) переходит в разряд статьи с основными объяснениями и картинками.
Сразу договоримся, если в тексте будет указано «v1» — это отсылка к реализации в первой версии, если «v2» — к текущей.
Очень кратко, о чем речь…
Фреймворк в виде одного общего модуля, позволяющего при получении объектов на обработку запускать их в несколько потоков. Особенности:
- Нет необходимости рассчитывать «порции» для обработки;
- Нет необходимости организовывать файловый обмен между потоками;
- Возможность запускать несколько менеджеров потоков одновременно, при этом потоки одного менеджера, могут запускать новые менеджеры со своими задачами и потоками;
- Можно выстраивать граф зависимости объектов, что позволяет, например, избегать взаимоблокировок и/или организовать восстановление партий (на нашем предприятии удалось добиться 10х+ ускорения при 10 потоках в рабочее время – 200+ активных пользователей — Результаты работы механизма);
- Все необходимые "вмешательство" в алгоритмы происходят с помощью событий;
- Возможность описывать алгоритмы событий, как в модуле менеджера, так и в любом другом модуле БД (предпочтительно), а также во внешней обработке.
- Автоматический рестарт потока в случае ошибок;
- Контроль за количеством рестартов по каждому объекту;
- Возможность получать «ответы» от потоков;
- Возможность контролировать работу с помощью «Инструментов разработчика» или иных отчетов;
- Возможность срочного прерывания работы;
- И многое другое…
так было в «v1»
Основные изменения v2 (расширение функционала v1):
- Только полная версия, полностью открытый код;
- Практически полностью переписано ядро и архитектура (кода стало на ~50% больше), механизм обмена данными остался тот же (Хранилище общих настроек);
- Появилось 3 способа обработки:
- Обработка поэлементно:
- Процедура ОбработатьОбъект(); (реализовано v1)
- Обработка коллекций:
- Процедура ОбработатьКоллекцию();
- Процедура ДополнитьКоллекцию ().
- Обработка поэлементно:
- Скорость обработки «зависимых» объектов происходит быстрее на 5-15% по сравнению с «v1», при выполнении одной и той же задачи;
- Появилась возможность передавать в потоки произвольные единожды сформированные данные или рассчитывать их при запуске потока.
- Возможность получать «ответ» об обработке объекта(ов) в «реальном времени» (в «v1» приходилось дополнительно прописывать обвязку из временного хранилища с помощью «СобытийРазработчика», откуда данные можно было получить только в конце обработки);
- Сообщения выведенные в потоках, теперь выводятся автоматически (в «v1» приходилось обрабатывать через «Событиях разработчика»);
- Расчет ресурсов теперь выполняют потоки;
- Изменен состав «Событий разработчика»;
- Изменена структура параметров передаваемых в «События разработчика»;
- Граф теперь является одним объектом (в «v1» он состоял из нескольких не связанных объектов, что могло вызвать затруднения в понимании работы);
- Расширены собираемые данные для анализа работы менеджера потоков (до 11 показателей);
- Предоставлен шаблон функции «ОбработатьСобытиеРазработчика» для своих модулей;
- В статью добавлены примеры;
- Прочие мелочи.
Разработка проводилось на 1С:Предприятие 8.3 (8.3.9.1850) 32x; Режим совместимости 8.2.15
Теперь обо всем по порядку в деталях и с картинками…
Архитектура
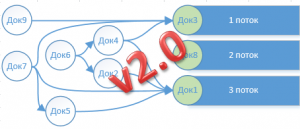
При реализации v1, мне действительно удалось добиться поставленной цели (ускорить восстановление партий в УПП (не РАУЗ) в РАЗЫ), но были некоторые моменты вызывающие неудовлетворенность. Вот схема, примера организации обмена данными для получения ответа по v1. Проблемы обозначил цифрами:

-
1 проблема — расчет ресурса для построения графа. «Менеджер потоков» реализовывался для ускорения работы «Основной программы», а нам пришлось навесить на нее дополнительную работу по расчету ресурсов объектов. (Проведенные тесты показали, что выполнение алгоритма восстановления партий за 1 день, без непосредственного восстановления – просто выборка документов из последовательности и выполнение команд в цикле без проведения, выполняется за 30 сек., но стоит нам добавить расчет ресурсов и эта же работы выполнялась уже за 90 сек.).
- Факты за:
- Основная программа рассчитывает ресурсы и «отбраковывает» объекты не требующие обработки (при восстановлении партий в нашей БД из Результаты работы механизма видно, что таких документов почти 50%);
- «Снижение» нагрузки на СХД – т.к. не все передаются для обработки.
- Факты против:
- По замерам было видно, что периоды, когда не задействовано ни одного потока доходили до 30% времени работы;
- «Основная программа» дополнительно нагружена вычислением ресурсов.
- Факты за:
- 2 проблема – временное хранилище — это «костыль» который каждый раз приходиться описывать разработчику, чтобы иметь возможность получить ответы о результатах обработки объектов.
- 3 проблема – «Менеджер потоков» — это прокладка, в буквальном смысле. Данные из основной программы попадают в потоки, только пройдя «насквозь» через «Менеджер потоков», а проходя «насквозь» приходиться: писать(основная программа)-читать(менеджер), писать(менеджер)-читать(поток), писать(поток)-читать(менеджер) и в конце с помощью «проблемы 2» консолидировано писать(менеджер)-читать(основная программа).
- 4 проблема – длительное ожидание ответа. Ответ в «основной программе» можно было получить только после окончания работы «менеджера потоков» через «проблему 2».
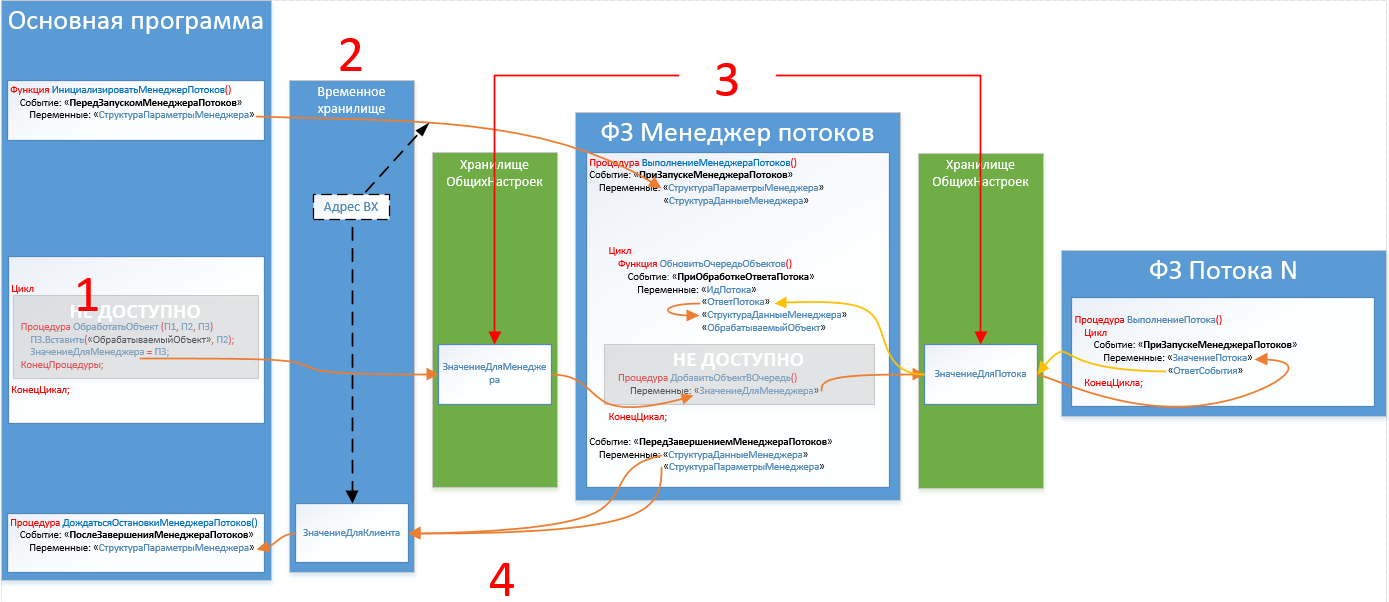
Новая реализация (v2) движения данных:


На первый взгляд может показаться все очень сложно, и количество записей 6 против 4 в v1, но обо всем по порядку:
- 1 – «Основная программа» записывает в хранилище все необходимые данные для обработки.
- 2 – «Основная программа» записывает в зарезервированную для «Менеджера потоков» ячейку массив адресов с размещенными данными.
- 3 – «Менеджер потоков» на каждой итерации опрашивает ячейку с информацией о размещении новых данных.
- 4 – «Менеджер потоков» — считывает полученные данные для проведения анализа и построения графа (несвязанного).
- 5 – «Менеджер потоков» записывает в зарезервированные за каждым потоком ячейки, адреса, откуда потоку взять данные.
- 6 – «Поток» на каждой итерации опрашивает зарезервированную за собой ячейку на предмет появления информации о размещении данных.
- 7 – «Поток» по полученному адресу (п.6) считывает и обрабатывает данные.
- 8 – «Поток» после обработки формирует ответ и записывает его, туда же, откуда были считаны данные.
- 9 – «Поток» при штатном завершении обработки данных производит очистку своей зарезервированной ячейки.
- 10 – «Менеджер потоков» на каждой итерации производит опрос ячеек зарезервированные за потоками, куда были переданы адреса хранения данных для обработки. На данном этапе «Менеджер потоков» отслеживает активность потоков и в случае их «падения» запускает новый поток.
- 11 – «Менеджер потоков» считывает результат обработки и производит дальнейший анализ, при необходимости строит новый граф (связанный) и повторяет п.п. 5-10 (уже для обработки объекта по связям) или см. п. 12.
- 12 – «Менеджер потоков» записывает в зарезервированную для «Основной программы» ячейку информацию о результатах обработки.
- 13 – «Основная программа» на каждой итерации опрашивает ячейку с информацией о результатах обработки.
- 14 – «Основная программа» — считывает результат обработки объекта.
Теперь видно, что данные (они могут быть очень большими) записываются только 1 раз и 1 раз записывается результат обработки, а 4 раза записывается только служебная (короткая) информации. В v1 из-за проблемы 3, данные записывались 2 раза и 2 раза записывался результат обработки.
Результаты по ранее описанным проблемам:
- 1 проблема — расчет ресурса для построения графа. Теперь расчетом ресурсов занимается потоки, а не основная программа.
- 2 проблема — временное хранилище. Теперь в нем нет необходимости. Ответ возвращается туда, куда были помещены данные, обработка происходит через вызываемые события.
- 3 проблема – «Менеджер потоков» — это прокладка. Теперь менеджер потоков — это именно менеджер. Он управляет данными и сообщает другим участникам «Основной программе» и «Потокам», когда, откуда, какую (для «Основной программы») и для каких целей (для «Потоков») взять информацию.
- 4 проблема – длительное ожидание ответа. Теперь результат обработки «Основная программа» получает сразу после окончания обработки объекта.
Способы обработки
В v2, реализован дополнительные способы обработки данных. Теперь их три:
ОбработатьОбъект
Данный способ обработки предназначен для выстраивания зависимостей объектов и их обработки в определенной последовательности (например, восстановление партий, восстановление последовательности расчетов и т.д.).
Со стороны основной программы (внешняя обработка) он реализовывается так:
СтруктураПараметров =
мпМенеджерПотоков.ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков("Тест", Новый ДвоичныеДанные(ЭтотОбъект.ИспользуемоеИмяФайла));
Для каждого ОбъектСсылка из МассивОбъектов Цикл
//тут формируется структура параметров необходимых для объекта
СтрукутраПараметровОбъекта = ...;
мпМенеджерПотоков.ОбработатьОбъект(СтруктураПараметров, ОбъектСсылка, СтрукутраПараметровОбъекта);
КонецЦикла;
мпМенеджерПотоков.ДождатьсяОстановкиМенеджераПотоков(СтруктураПараметров);
текущий способ был изначально реализован в v1 и по сути не изменился.
Следующие 2 метода работают сразу с коллекцией значений (массив, список значений и таблица значений), но с некоторыми отличиями;
ОбработатьКоллекциюОбъектов() — новый
Результатом работы является произвольный объект. Элементом обрабатываемых данных в потоках является фрагмент коллекции. Размер фрагмента зависит от разных параметров уточняемых при инициализации.
Со стороны основной программы (внешняя обработка) он реализовывается так:
СтруктураПараметров = мпМенеджерПотоков.ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков("Тест", Новый ДвоичныеДанные(ЭтотОбъект.ИспользуемоеИмяФайла));
ПроизвольныеДанные = мпМенеджерПотоков.ОбработатьКоллекциюОбъектов(СтруктураПараметров, Коллекция);
Именно при решении таких задач v1, начинала проигрывать стандартным способам, например таким: //infostart.ru/public/182139/. Основная проблема заключалась в затратах на передачу данных поэлементно. В связи с чем, была реализована «обертка» позволяющая разбивать коллекцию на фрагменты и посылать в потоки на обработку сразу несколько элементов. Так же реализован контроль порядка фрагментов коллекции передаваемой в обработку, вне зависимости от времени обработки каждого из фрагментов порядок будет соответствовать первичной «Коллекции».
ДополнитьКоллекциюОбъектов() — новый
Результатом работы является новый объект идентичной структуры и с тем же порядком данных, что и в переданной коллекции. Элементом обрабатываемых данных в потоках является элемент коллекции.
Со стороны основной программы (внешняя обработка) он реализовывается так:
СтруктураПараметров = мпМенеджерПотоков.ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков("Тест", Новый ДвоичныеДанные(ЭтотОбъект.ИспользуемоеИмяФайла));
НоваяКоллекция = мпМенеджерПотоков.ДополнитьКоллекциюОбъектов(СтруктураПараметров, Коллекция);
Можно воспользоваться данным методом, когда не получается «достать/обработать» данные простым запросом сразу по всем объектам. По сути — это доработка метода «ОбработатьКоллекциюОбъектов» — т.к. с его помощью можно добиться такого же результата, но с бОльшими усилиями.
Параметры инициализации
Теперь все параметры структурированы по месту своего возникновения:
- ПараметрыИнициализации;
- ПараметрыОсновнойПрограммы / ПараметрыМенеджераПотоков / ПараметрыПотока;
- ПараметрыРазработчика;
- ПараметрыОбщие.
Отдельно можно сказать только про «ПараметрыРазработчика» — сюда разработчику следует помещать свои произвольные данные и сюда же помещаются результаты работы некоторых событий.
Для работы с коллекциями в структуру параметров было добавлено еще 2 параметра:
- КоличествоЭлементовКолекцииНаПоток – название говорит само за себя. Число (по умолчанию = 0);
- ДинамическийРассчетКоличестваПотоков – позволяет рассчитать количество необходимых потоков, но не больше, чем параметр «КоличествоПотоков». Булево (по умолчанию = Ложь).
Если эти параметры оставить по умолчанию, то обработка коллекции всегда будет идти в потоках (по умолчанию «КоличествоПотоков» = 10), даже если элементов в коллекции будет 4. Просто 6 потоков будут запущены зря.
Примеры
- Размер коллекции = 10 000, КоличествоЭлементовКолекцииНаПоток = 1 500, ДинамическийРассчетКоличестваПотоков = Ложь.
- Результат: Количество запущенных потоков = 10.
- Размер коллекции = 1 000, КоличествоЭлементовКолекцииНаПоток = 1 500, ДинамическийРассчетКоличестваПотоков = Ложь.
- Результат: Количество запущенных потоков = 0. Все выполнение будет происходить в основной программе с эмуляцией вызова событий разработчика, т.к. там прописана вся логика обработки коллекции.
- Размер коллекции = 10 000, КоличествоЭлементовКолекцииНаПоток = 1 500, ДинамическийРассчетКоличестваПотоков = Истина.
- Результат: Количество запущенных потоков = 7.
- Размер коллекции = 100 000, КоличествоЭлементовКолекцииНаПоток = 1 500, ДинамическийРассчетКоличестваПотоков = Истина.
- Результат: Количество запущенных потоков = 10.
- Размер коллекции = 1 000, КоличествоЭлементовКолекцииНаПоток = 1 500, ДинамическийРассчетКоличестваПотоков = Истина.
- Результат: Количество запущенных потоков = 0. Все выполнение будет происходить в основной программе с эмуляцией вызова событий разработчика, т.к. там прописана вся логика обработки коллекции.
События разработчика
Данный раздел так же претерпел некоторые изменения. И вот что получилось:


Пришлось убрать одно событие («ПриОпределенииТипДанныхВПотоке») – честно рад этому, меня оно раздражало J
С точки зрения большего понимания (моего понимания) были изменены названия других событий, место вызова и назначение.
И добавить новые.
Также из-за изменений архитектуры, часть событий поменяли свое место «жительства» (вызов), но кроме того, они изменили способ своей работы с процедуры на функцию. Сделано это для того, чтобы дать возможность передать произвольную информацию, как из «Основной программы» в «Менеджер потоков» или в «Потоки», так и из «Менеджера потоков» в «Потоки». Чтобы поток при обработке объекта или фрагмента коллекции не собирал эту информацию снова или не кэшировал ее «где придется».
Также поменялся состав параметров событий. Если раньше это была хаос из параметров и у каждого события они могли быть уникальны, то теперь параметров 2 обязательных:
- «ИмяСобытия»;
- «СтруктураПараметров»;
И 1 переменный
- «СтруктураДанных» — обычно это та структура, которая передается на обработку.
Детали «Событий разработчика» описаны в самом низу модуля:
//ШАБЛОН ФУНКЦИИ Для своего произвольного модуля
а укороченный вариант представлен в самой функции ОбработатьСобытиеРазработчика()
//МЕСТО ДЛЯ АЛГОРИТМА РАЗРАБОТЧИКА
Шаблон специально добавил, т.к. сам частенько забывал, как с какими событиями работать.
Доступность событий от методов:


Мониторинг
Для понимания, что и как работает, предоставлено 3 отчета для мониторинга деятельности:
- МониторингПорядкаОбработкиОбъектов (На стороне «Основной программы»);
- МониторингОчередиНаОбработку (На стороне «Основной программы»);
- МониторингМенеджераПотоков (На стороне «Менеджера потоков» — сервер 1С).
Включение
Для включения каждого мониторинга необходимо в событии разработчика «ПередЗапускомМенеджераПотоков» или сразу после «ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков» установить значение «Истина» (по умолчанию они установлены в значение «Ложь») для необходимого параметра.
Например, так:
Функция ПередЗапускомМенеджераПотоков(пПараметрыСобытия);
пПараметрыСобытия.СтруктураПараметров.ПараметрыИнициализации.ВестиМониторингМенеджераПотоков = Истина;
пПараметрыСобытия.СтруктураПараметров.ПараметрыИнициализации.ВестиМониторингПорядкаОбработкиОбъектов = Истина;
пПараметрыСобытия.СтруктураПараметров.ПараметрыИнициализации.ВестиМониторингОчередиНаОбработку = Истина;
Сохранение
Кроме того, необходимо в событии разработчика «ПриПолученииМестаХраненияФайловМониторинга», прописать способ определения пути для каждого из результатов.
Например, так:
Функция ПриПолученииМестаХраненияФайловМониторинга(пПараметрыСобытия)
ИмяТаблицы = пПараметрыСобытия.СтруктураДанных.ИмяТаблицы;
Если ИмяТаблицы = "МониторингОчередиНаОбработку" Тогда
Путь = "Z:�1 ТаблицаОчередиНаОбработку.xlsx";
ИначеЕсли ИмяТаблицы = "МониторингПорядкаОбработкиОбъектов" Тогда
Путь = "Z:�1 ТаблицаПорядкаОбработкиОбъектов.xlsx";
ИначеЕсли ИмяТаблицы = "МониторингМенеджераПотоков" Тогда
Путь = "Z:�1 ТаблицаМониторингМенеджера.xlsx";
Иначе
Путь = Неопределено;
КонецЕсли;
Возврат Путь;
КонецФункции
Имена таблиц: «МониторингОчередиНаОбработку», «МониторингПорядкаОбработкиОбъектов», «МониторингМенеджераПотоков» — зарезервированы.
Мониторинг порядка обработки объектов
Данный мониторинг достаточно прост, но позволяет получить реальную картину обработки объектов, какие объекты, когда и как были обработаны. Вот результат сохраненного отчета:


Где:
- ВремяВмс – ТекущаяУниверсальнаяДатаВМиллисекундах()
- Обработанный объект – ссылка или значение обрабатываемого объекта;
- Результат обработки – собственно как объект был обработан. Возможные варианты:
- Ответ — объект обработан штатно и получен «Ответ»;
- Пропуск – по каким-то причинам (событие разработчика «ПриДобавленииВОчередьОбработки» ) было принято решение не включать объект в обработку;
- Ошибка – было произведено несколько попыток (СтруктураПараметров.ПараметрыИнициализации.ПределКоличествоПопытокОбработатьОбъект) обработать объект, но все они закончились неудачно;
- ДополненныйФрагментКоллекции
- ОбработанныйФрагментКоллекции
Объекты обведенные рамкой, это уже ручная работа J, чтоб показать, что ответ приходит в один момент времени по нескольким объектам.
С помощью данного отчета можно увидеть (правда не в 2а клика), какие объекты не соответствуют ожидаемой последовательности, и разобраться с ресурсами.
Мониторинг очереди на обработку
Тоже весьма простой отчет, показывает, как быстро растет очередь на обработку и растет ли. Данные получаются на каждой итерации перед попыткой отправить данные в менеджер потоков. Вот результаты сохраненного отчета:


Где:
- ВремяВмс – ТекущаяУниверсальнаяДатаВМиллисекундах()
- РазмерОчередиВМП – текущий размер очереди для передачи в «Менеджер потоков»;
- К_Свободно – Количество свободных ячеек для обмена с «Менеджером потоков»,
- К_РассчитатьРесурсы – Название колонки содержит название действия («Рассчитать ресурсы») которое необходимо произвести на объектом. Значение показывает, сколько объектов на данной итерации находиться в обработке «Менеджером потоков». Возможные действия:
- Рассчитать ресурсы (см.);
- Дополнить коллекцию (см. );
- Обработать коллекцию (см. ).
Внимательный читатель мог заметить и озадачиться, почему если отчет собирает данные на каждой итерации, то в колонке «РазмерОчередиВМП» вдруг появляются «2» при свободных ячейках. Это связано с тем, что «Основная программа» «пытается» отправить данные в «Менеджер потоков» и если она видит, что данные отправленные в прошлой итерации еще не приняты, то на текущей итерации отправка не происходит, зато в следующей итерации при наличии свободных ячеек, будет отправлено максимальное возможное количество объектов. Вот так выглядит график очереди при восстановлении партий за 1 день в нашей организации, за 57 сек. обработана 1113 документов, при 10 потоках.


На данном графике видны «горбы» — это говорит о том, что цикл перебора объектов «Основной программы» работает быстрее, чем справляются «Потоки» с обработкой и это в принципе правильно. Но к 9 сек. потоки успели обработать всю накопленную очередь (188 док за 9 сек.), т.к. ~ с 5 сек. в выборку стало попадать много документов «Поступление товаров и услуг» (это видно по отчету «Мониторинг порядка обработки объектов») не требующих обработки и очередь упала практически до 0. С одной стороны это хорошо, мы успеваем обрабатывать объекты в «Потоках» со скоростью перебора в цикле «Основной программы» (плюс затраты на пересылку). Но с другой стороны плохо, т.к. потоки получается запущенны напрасно. По факту работает 1-2 и все. Ближе к концу снова начинают появляться документы требующие обработки и очередь снова начинает расти.
Мониторинг менеджера потоков
Мониторинг менеджера потоков
Данный отчет позволяет увидеть все, что происходит в менеджере потоков на каждой итерации, а именно:
- Какой размер графа;
- Сколько объектов получено на обработку;
- Сколько объектов передано в потоки и для каких действий;
- Сколько объектов уже находятся в потоках и какие действия над ними выполняются;
- Сколько объектов ожидают отправки в потоки и для каких действий;
- Сколько объектов и с каким результатом отправлено «Основной программе».
Колонок в отчете может быть очень много и состав их может быть разный в зависимости от выбранного способа обработки. Покажу лишь скриншоты получаемых графиков в Excel (такой график настроить не просто, придется потратить минут 5-10).
Небольшие пояснения:
- расстояние между 2мя вертикальными линиями — это 1 итерация «Менеджера потоков» (М_Итерация);
- «Клиент» – это «Основная программа».
Запуск:


Работа в разгаре:


«Выход на плато» к 11 сек, когда очередь на обработку иссякла (см. Мониторинг очереди на обработку).


Ну и ближе к финишу: к 58 сек. расчет ресурсов завершен. В графе находится 16 объектов, но обрабатываются они только в 3 потока, т.к. «цепляются» друг за друга ресурсами.


Примеры работы и выводы
Теперь посмотрим как с этим работать.
Пойдем от просто к сложному: ДополнитьКоллекцию – ОбработатьКоллекцию – ОбработатьОбъект.
Начальные условия
- Количество потоков = 10 (по умолчанию);
- Количество элементов на поток = 0 (по умолчанию);
- ДинамическийРассчетКоличестваПотоков = Ложь (по умолчанию);
- Коллекция – Список значений
- Размер коллекции 10 000 / 100 000;
- Значение = порядковый номер элемента коллекции.
Функция создать коллекцию
Функция СоздатьКоллекцию(РазмерКоллекции = 10000)
Коллекция = Новый СписокЗначений;
Для Сч = 1 по РазмерКоллекции Цикл
Коллекция.Добавить(Сч);
КонецЦикла;
Возврат Коллекция;
КонецФункции
Процедура линейного выполнения
Процедура ЛинейноНажатие(Элемент)
Коллекция = СоздатьКоллекцию();
ВремяСтарт = ТекущаяУниверсальнаяДатаВМиллисекундах();
Если СпособОбработки = "ДополнитьКоллекциюПометка" Тогда
//...
КонецЕсли;
РассчитатьПродолжительность(ВремяСтарт, "Линейно");
КонецПроцедуры
Процедура выполнения в потоках
Процедура ВПотокахНажатие(Элемент)
Коллекция = СоздатьКоллекцию();
ВремяСтарт = ТекущаяУниверсальнаяДатаВМиллисекундах();
СтруктураПараметров = мпМенеджерПотоков.ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков(СпособОбработки, Новый ДвоичныеДанные(ЭтотОбъект.ИспользуемоеИмяФайла));
НоваяКоллекция = мпМенеджерПотоков.ДополнитьКоллекциюОбъектов(СтруктураПараметров, Коллекция);
РассчитатьПродолжительность(ВремяСтарт, СтрШаблон("В %1 потоков", СтруктураПараметров.ПараметрыИнициализации.КоличествоПотоков));
КонецПроцедуры
Процедура обработки потоков останется неизменной – весь код будет в общем модуле внешней обработки в «событиях разработчика»
ДополнитьКоллекциюОбъектов
Данный способ обработки подразумевает следующую идею: послав коллекцию на обработку, на выходе вы получаете ТОЧНО ТАКУЮ ЖЕ КОЛЛЕКЦИЮ (но не ту же что посылали на обработку), но с пересчитанными/заполненными данными. ВАЖНО!!! в поток для обработки передается ЭЛЕМЕНТ КОЛЛЕКЦИИ.
Пример 1: Дополнить коллекцию — установка пометки
Линейно
Если СпособОбработки = "ДополнитьКоллекциюПометка" Тогда
Для каждого ЭлементКоллекции из Коллекция Цикл
ЭлементКоллекции.Пометка = Истина;
КонецЦикла;
В потоках
Функция ОбработатьСобытиеРазработчика(пПараметрыСобытия) Экспорт
ИмяСобытия = пПараметрыСобытия.ИмяСобытия;
СтруктураПараметров = пПараметрыСобытия.СтруктураПараметров;
РазрезМенеджеров = СтруктураПараметров.ПараметрыИнициализации.РазрезМенеджеров;
ОтветСобытия = Неопределено;
Если РазрезМенеджеров = "ДополнитьКоллекциюПометка" Тогда
Если ИмяСобытия = "ПриОбработкеДействияПотока" Тогда //Поток
ОтветСобытия = ДополнитьКоллекциюПометка_ПриОбработкеДействияПотока(пПараметрыСобытия);
КонецЕсли;
КонецЕсли;
Возврат ОтветСобытия;
КонецФункции
//******************************************************
Функция ДополнитьКоллекциюПометка_ПриОбработкеДействияПотока(пПараметрыСобытия)
ЭлементКоллекции = пПараметрыСобытия.СтруктураДанных;
ЭлементКоллекции.Пометка = Истина;
КонецФункции
Результат


Результат выполнения в потоках – заметно проигрывает из-за накладных расходов на распараллеливание и из-за ничтожной сложности операции.
Пример 2: Дополнить коллекцию — замена на номенклатуру (НайтиПоКоду)
Линейно
ИначеЕсли СпособОбработки = "ДополнитьКоллекциюЗаменаНаНоменклатуруВЦикле" Тогда
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
СпрНоменклатура = Справочники.Номенклатура;
Для каждого ЭлементКоллекции из Коллекция Цикл
Код = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
ЭлементКоллекции.Значение = СпрНоменклатура.НайтиПоКоду(Код);
КонецЦикла;
В потоках
Функция ОбработатьСобытиеРазработчика(пПараметрыСобытия) Экспорт
ИмяСобытия = пПараметрыСобытия.ИмяСобытия;
СтруктураПараметров = пПараметрыСобытия.СтруктураПараметров;
РазрезМенеджеров = СтруктураПараметров.ПараметрыИнициализации.РазрезМенеджеров;
ОтветСобытия = Неопределено;
Если РазрезМенеджеров = "ДополнитьКоллекциюЗаменаНаНоменклатуруВЦикле" Тогда
Если ИмяСобытия = "ПриОбработкеДействияПотока" Тогда //Поток
ОтветСобытия = ДополнитьКоллекциюЗаменаНаНоменклатуру_ПриОбработкеДействияПотока(пПараметрыСобытия);
КонецЕсли;
КонецЕсли;
Возврат ОтветСобытия;
КонецФункции
//******************************************************
Функция ДополнитьКоллекциюЗаменаНаНоменклатуру_ПриОбработкеДействияПотока(пПараметрыСобытия)
ЭлементКоллекции = пПараметрыСобытия.СтруктураДанных;
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
СпрНоменклатура = Справочники.Номенклатура;
Код = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
ЭлементКоллекции.Значение = СпрНоменклатура.НайтиПоКоду(Код);
КонецФункции
Результат


В данном примере операция вроде примитивна, всего-то найти по коду, но это множество микро запросов к серверу СУБД (запрос в цикле) и тут уже потоки выигрывают, т.к. запросы распараллелены.
Кто-то скажет, надо один раз выбрать данные и дальше по ним искать, ок…
Пример 3: Дополнить коллекцию — замена на номенклатуру (выборка 1 запрос)
Линейно
ИначеЕсли СпособОбработки = "ДополнитьКоллекциюЗаменаНаНоменклатуру1Запрос" Тогда
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура";
ТЗ = Запрос.Выполнить().Выгрузить();
Для каждого ЭлементКоллекции из Коллекция Цикл
Код = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
Строка = ТЗ.Найти(Код, "Код");
ЭлементКоллекции.Значение = ?(Строка = Неопределено, Неопределено, Строка.Ссылка);
КонецЦикла;
В потоках
Функция ОбработатьСобытиеРазработчика(пПараметрыСобытия) Экспорт
ИмяСобытия = пПараметрыСобытия.ИмяСобытия;
СтруктураПараметров = пПараметрыСобытия.СтруктураПараметров;
РазрезМенеджеров = СтруктураПараметров.ПараметрыИнициализации.РазрезМенеджеров;
ОтветСобытия = Неопределено;
Если РазрезМенеджеров = "ДополнитьКоллекциюЗаменаНаНоменклатуру1Запрос" Тогда
Если ИмяСобытия = "ПриЗапускеПотока" Тогда //Поток
ОтветСобытия = ДополнитьКоллекциюЗаменаНаНоменклатуру1Запрос_ПриЗапускеПотока(пПараметрыСобытия);
ИначеЕсли ИмяСобытия = "ПриОбработкеДействияПотока" Тогда //Поток
ОтветСобытия = ДополнитьКоллекциюЗаменаНаНоменклатуру1Запрос_ПриОбработкеДействияПотока(пПараметрыСобытия);
КонецЕсли;
КонецЕсли;
Возврат ОтветСобытия;
КонецФункции
//******************************************************
Функция ДополнитьКоллекциюЗаменаНаНоменклатуру1Запрос_ПриЗапускеПотока(пПараметрыСобытия)
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура";
Структура = Новый Структура;
Структура.Вставить("ДлинаКода",Метаданные.Справочники.Номенклатура.ДлинаКода);
Структура.Вставить("ТаблицаНоменклатуры", Запрос.Выполнить().Выгрузить());
Возврат Структура;
КонецФункции
//******************************************************
Функция ДополнитьКоллекциюЗаменаНаНоменклатуру1Запрос_ПриОбработкеДействияПотока(пПараметрыСобытия)
ДанныеРарзаботчикаПриЗапускеПотока =
пПараметрыСобытия.СтруктураПараметров.ПараметрыРазработчика.ДанныеРарзаботчикаПриЗапускеПотока;
ДлинаКода = ДанныеРарзаботчикаПриЗапускеПотока.ДлинаКода;
ТЗ = ДанныеРарзаботчикаПриЗапускеПотока.ТаблицаНоменклатуры;
ЭлементКоллекции = пПараметрыСобытия.СтруктураДанных;
Код = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
Строка = ТЗ.Найти(Код, "Код");
ЭлементКоллекции.Значение = ?(Строка = Неопределено, Неопределено, Строка.Ссылка);
КонецФункции
Прошу обратить внимание, как произошла передача данных из одного события в другое. Сначала мы получили данные в событии «ПриЗапускеПотока», а затем воспользовались его результатами в событии «ПриОбработкеДействияПотока». Таким же образом можно передать данные от «Основной программы» в «Менеджер потоков» и в сами «Потоки». Детали в шаблоне функции в самом конце общего модуля «Менеджера потоков».
Результат


Время выросло, стало даже больше, чем просто «НайтиПоКоду» — связано это с выгрузкой запроса в таблицу значений, там более 100 к строк (да у нас такой большой справочник J) и с поиском по данной таблице.
Сразу следует вопрос «А где фильтр в запросе?». Вот он..
Пример 4: Дополнить коллекцию — замена на номенклатуру (выборка 1 запрос с фильтром)
Линейно
ИначеЕсли СпособОбработки = "ДополнитьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром" Тогда
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
МассивКодов = Новый Массив;
Для каждого ЭлементКоллекции из Коллекция Цикл
ЭлементКоллекции.Значение = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
МассивКодов.Добавить(ЭлементКоллекции.Значение);
КонецЦикла;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура
|ГДЕ Номенклатура.Код В (&МассивКодов)";
Запрос.УстановитьПараметр("МассивКодов", МассивКодов);
ТЗ = Запрос.Выполнить().Выгрузить();
Для каждого ЭлементКоллекции из Коллекция Цикл
Строка = ТЗ.Найти(ЭлементКоллекции.Значение, "Код");
ЭлементКоллекции.Значение = ?(Строка = Неопределено, Неопределено, Строка.Ссылка);
КонецЦикла;
В потоках
Из-за технических особенностей, такой финт не получиться провернуть в данном способе обработки («ДополнитьКоллекциюОбъектов») в потоках. Причина: в потоках есть 2 события «ПриЗапускеПотока» и «ПриОбработкеДействияПотока». Первое событие срабатывается в самом начале запуска потока, когда поток еще не получил ни какие данные и оно подходит, только для установки первоначальных констант. Второе событие срабатывает при обходе каждого элемента фрагмента коллекции и приведет к запросу в цикле.
Но данную оптимизацию можно реализовать с помощью другого способа обработки «ОбработатьКоллекциюОбъектов», т.к. там в событие «ПриОбработкеДействияПотока» передается весь фрагмент, но об этом позже (Пример 5).
Результат


На большом объеме, скорость обработки падает не пропорционально увеличенному объему — проблемы с поиском в большой таблице значений.
ОбработатьКоллекциюОбъектов
Данный способ обработки подразумевает следующую идею: послав коллекцию на обработку, на выходе вы получаете ПРОИЗВОЛЬНЫЙ ТИП ДАННЫЙ. ВАЖНО!!! в поток для обработки передается ФРАГМЕНТ КОЛЛЕКЦИИ.
Все что у нас меняется в обработке – это вызов метода:
//было:
//НоваяКоллекция = мпМенеджерПотоков.ДополнитьКоллекциюОбъектов(СтруктураПараметров, Коллекция);
//
//стало:
НоваяКоллекция = мпМенеджерПотоков.ОбработатьКоллекциюОбъектов(СтруктураПараметров, Коллекция);
Вернемся к недоделанному примеру 4
Пример 5: Обработать коллекцию — замена на номенклатуру (выборка 1 запрос с фильтром)
Линейно (как в 4 примере)
ИначеЕсли (СпособОбработки = "ДополнитьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром")
ИЛИ (СпособОбработки = "ОбработатьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром") Тогда
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
МассивКодов = Новый Массив;
Для каждого ЭлементКоллекции из Коллекция Цикл
ЭлементКоллекции.Значение = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
МассивКодов.Добавить(ЭлементКоллекции.Значение);
КонецЦикла;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура
|ГДЕ Номенклатура.Код В (&МассивКодов)";
Запрос.УстановитьПараметр("МассивКодов", МассивКодов);
ТЗ = Запрос.Выполнить().Выгрузить();
Для каждого ЭлементКоллекции из Коллекция Цикл
Строка = ТЗ.Найти(ЭлементКоллекции.Значение, "Код");
ЭлементКоллекции.Значение = ?(Строка = Неопределено, Неопределено, Строка.Ссылка);
КонецЦикла;
В потоках
Функция ОбработатьСобытиеРазработчика(пПараметрыСобытия) Экспорт
ИмяСобытия = пПараметрыСобытия.ИмяСобытия;
СтруктураПараметров = пПараметрыСобытия.СтруктураПараметров;
РазрезМенеджеров = СтруктураПараметров.ПараметрыИнициализации.РазрезМенеджеров;
ОтветСобытия = Неопределено;
Если РазрезМенеджеров = "ОбработатьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром" Тогда
Если ИмяСобытия = "ПриОбработкеДействияПотока" Тогда //Поток
ОтветСобытия = ОбработатьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром_ПриОбработкеДействияПотока(пПараметрыСобытия);
ИначеЕсли ИмяСобытия = "ПриОбработкеМассиваОбработанныхФагментовКоллекции" Тогда //Основная программа
ОтветСобытия = ОбработатьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром_ПриОбработкеМассиваОбработанныхФагментовКоллекции(пПараметрыСобытия);
КонецЕсли;
КонецЕсли;
Возврат ОтветСобытия;
КонецФункции
//******************************************************
Функция ОбработатьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром_ПриОбработкеДействияПотока(пПараметрыСобытия)
Коллекция = пПараметрыСобытия.СтруктураДанных;
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
МассивКодов = Новый Массив;
Для каждого ЭлементКоллекции из Коллекция Цикл
ЭлементКоллекции.Значение = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
МассивКодов.Добавить(ЭлементКоллекции.Значение);
КонецЦикла;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура
|ГДЕ Номенклатура.Код В (&МассивКодов)";
Запрос.УстановитьПараметр("МассивКодов", МассивКодов);
ТЗ = Запрос.Выполнить().Выгрузить();
Для каждого ЭлементКоллекции из Коллекция Цикл
Строка = ТЗ.Найти(ЭлементКоллекции.Значение, "Код");
ЭлементКоллекции.Значение = ?(Строка = Неопределено, Неопределено, Строка.Ссылка);
КонецЦикла;
Возврат Коллекция;
КонецФункции
//******************************************************
Функция ОбработатьКоллекциюЗаменаНаНоменклатуру1ЗапросСФильтром_ПриОбработкеМассиваОбработанныхФагментовКоллекции(пПараметрыСобытия)
МассивСтруктур = пПараметрыСобытия.СтруктураДанных;
НоваяКоллекция = Новый СписокЗначений;
Для каждого СтруктураОтвета из МассивСтруктур Цикл
ФрагментКоллекции = СтруктураОтвета.ОтветПотока;
КолИндексовКоллекции = ФрагментКоллекции.Количество() - 1;
Для ИндексКоллекции = 0 по КолИндексовКоллекции Цикл
ЗаполнитьЗначенияСвойств(НоваяКоллекция.Добавить(), ФрагментКоллекции[ИндексКоллекции]);
КонецЦикла;
КонецЦикла;
Возврат НоваяКоллекция;
КонецФункции
Результат


При небольшом объеме скорость сопоставима, но при увеличении объема обработка в потоках дает заметное ускорение в работе.
Однако еще одна проблема медленной работы еще не устранена…
Пример 6: Обработать коллекцию — замена на номенклатуру (выборка 1 запрос с фильтром и индексирование)
Основная проблема медленно работы – это поиск по таблице значений. Решение простое, но не всегда применимое – индексирование.
Тут код приводить не буду, просто добавляем в коде (см. пример 5) и в «линейном», и в «потоках» после:
ТЗ = Запрос.Выполнить().Выгрузить();
ТЗ.Индексы.Добавить("Код");
Результаты


В данном варианте линейное выполнение опять выигрывает из –за оптимальности поиска (фильтр по индексу и таблице БД, и в таблице значение) и отсутствия необходимости производить дополнительные операции распараллеливания.
Но попадание в индекс не всегда возможно и такую оптимизацию ни всегда можно применить, т.к. индексы есть не по всем полям и условия могут быть с «пропусками».
Пример 7: Обработать коллекцию — перезапись номенклатуры (выборка 1 запрос с фильтром)
Поменяем направление работы. Сделаем перезапись найденной номенклатуры.
Линейно
ИначеЕсли СпособОбработки = "ОбработатьКоллекциюЗаписьНоменклатуры1ЗапросСФильтром" Тогда
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
МассивКодов = Новый Массив;
Для каждого ЭлементКоллекции из Коллекция Цикл
ЭлементКоллекции.Значение = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
МассивКодов.Добавить(ЭлементКоллекции.Значение);
КонецЦикла;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура
|ГДЕ Номенклатура.Код В (&МассивКодов)";
Запрос.УстановитьПараметр("МассивКодов", МассивКодов);
Выборка = Запрос.Выполнить().Выбрать();
Пока Выборка.Следующий() Цикл
Попытка
Выборка.Ссылка.ПолучитьОбъект().Записать();
Исключение
КонецПопытки;
КонецЦикла;
В потоках
Функция ОбработатьСобытиеРазработчика(пПараметрыСобытия) Экспорт
ИмяСобытия = пПараметрыСобытия.ИмяСобытия;
СтруктураПараметров = пПараметрыСобытия.СтруктураПараметров;
РазрезМенеджеров = СтруктураПараметров.ПараметрыИнициализации.РазрезМенеджеров;
ОтветСобытия = Неопределено;
Если РазрезМенеджеров = "ОбработатьКоллекциюЗаписьНоменклатуры1ЗапросСФильтром" Тогда
Если ИмяСобытия = "ПриОбработкеДействияПотока" Тогда //Поток
ОтветСобытия = ОбработатьКоллекциюЗаписьНоменклатуры1ЗапросСФильтром_ПриОбработкеДействияПотока(пПараметрыСобытия);
КонецЕсли;
КонецЕсли;
Возврат ОтветСобытия;
КонецФункции
//******************************************************
Функция ОбработатьКоллекциюЗаписьНоменклатуры1ЗапросСФильтром_ПриОбработкеДействияПотока(пПараметрыСобытия)
Коллекция = пПараметрыСобытия.СтруктураДанных;
ДлинаКода = Метаданные.Справочники.Номенклатура.ДлинаКода;
МассивКодов = Новый Массив;
Для каждого ЭлементКоллекции из Коллекция Цикл
ЭлементКоллекции.Значение = Прав(("00000000000000000000"+Формат(ЭлементКоллекции.Значение,"ЧГ=")), ДлинаКода);
МассивКодов.Добавить(ЭлементКоллекции.Значение);
КонецЦикла;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ Номенклатура.Ссылка, Номенклатура.Код ИЗ Справочник.Номенклатура КАК Номенклатура
|ГДЕ Номенклатура.Код В (&МассивКодов)";
Запрос.УстановитьПараметр("МассивКодов", МассивКодов);
ТЗ = Запрос.Выполнить().Выгрузить();
Выборка = Запрос.Выполнить().Выбрать();
Пока Выборка.Следующий() Цикл
Попытка
Выборка.Ссылка.ПолучитьОбъект().Записать();
Исключение
КонецПопытки;
КонецЦикла;
КонецФункции
Результат


ОбработатьОбъект
Данный способ обработки подразумевает следующую идею: «Основная программа» в цикле перебирает объекты требующие обработки и на каждой итерации цикла, объект(ы) с необходимыми параметрами отправляется в «Менеджер потоков», где по каждому объекту производиться расчет ресурсов и на основании этих ресурсов строится граф зависимости объектов (если ресурсы 2х и более объектов совпадают, данные объекты становятся связанными).
Ресурсы
Ресурсы — это основной объект для построения связанного графа. О том как они формируются и как на их основе строится граф говорилось тут.
Здесь лишь приведу краткую схему:


Пример будет надуманный, но надеюсь понятный, так же в нем постараюсь показать и работу с ресурсами и пропуск объектов по условию. Оперировать будем все тем же списком с номерами, но перезаписывать номенклатуру будем по определенным правилам.
Пример 8: Обработать объект с зависимостью (Условие «И»).
Условие «И» формирует 1 ресурс по комбинации значений вложенного массива. Порядок значений (типов данных) во вложенном массиве имеет строгое значение (описание: Формирование ресурсов).
Правила построения зависимости: По значению списка значений находим номенклатуру в справочнике по коду (как в предыдущих примерах), далее у найденной номенклатуры определяем «Тип номенклатуры» (Ссылка.ВидНоменклатуры.ТипНоменклатуры) и первую букву «Наименования». Та номенклатура, чей «Тип» И «Группа» букв (буквы разобьем на 6 групп по 5: а-д / е-и / й-н / о-т / у-ч / ш-я и прочие знаки, дабы сократить количество вариантов) будут совпадать обрабатываться будут друг за другом. Кроме того, если в перечень попадет «Группа» — данная номенклатура будет игнорироваться.
Данные тестового примера (первые 30)


Граф
Так будет выглядеть граф для первых 30 позиций (Условие «И»), построен вручную на основе вышеизложенной таблицы.
Объект посылается в обработку только в том случае, если обработаны ВСЕ «Ведущие» объекты с которыми он связан своими ресурсами и если есть свободные потоки.


Мониторинга порядка обработки объектов
Сравним граф с результатами «Мониторинг порядка обработки объектов» и видим, что порядок каждой группы точно соответствует графу (цвета и группы добавлены вручную для ясности):


Мониторинг менеджера потоков
А вот так выглядит график «Мониторинг менеджера потоков», согласно заданных условий. Распараллелить, согласно заданных условий, получилось плохо. Выборка — 100 объектов.


А так выглядит тот же график при выборке (10 000):


Тот же график (10 000 объектов), но ближе:
Как мы видим, начало похоже на то, что было при выборке в 100 объектов, это и логично, порядок подачи объектов в обработку не изменился, но вот распараллеливания с 26 сек при прошлой выборе увидеть не удалось, т.к. выборка была мала.

Результат
Время возросло существенно, но в тоже время быстрее линейного способа обработки без поставленных условий.


Пример 9: Обработать объект с зависимостью (Условие «ИЛИ»)
Условие «ИЛИ» позволяет определить по объекту более одного ресурса и связать объекты по каждому из полученных ресурсов. Порядок ресурсов НЕ имеет значения.
Предпочтительно данное условие применять, если у объекта есть множество однотипных значений, например, табличная часть, хотя все зависит от задачи.
Правила построения зависимости: По значению списка значений находим номенклатуру в справочнике по коду (как в предыдущих примерах), далее у найденной номенклатуры определяем «Тип номенклатуры» (Ссылка.ВидНоменклатуры.ТипНоменклатуры) и первую букву «Наименования». Та номенклатура, чей «Тип» ИЛИ «Группа» букв (буквы разобьем на 6 групп по 5: а-д / е-и / й-н / о-т / у-ч / ш-я и прочие знаки, дабы сократить количество вариантов) будут совпадать обрабатываться будут друг за другом. Кроме того, если в перечень попадет «Группа» — данная номенклатура будет игнорироваться.
В принципе все тоже самое, что в примере 8, изменения коснуться только одного события разработчика «ПриПолученииРесурсов»
Если в примере №8 у каждого объекта один ресурс — комбинация («Группа» И «Тип») и связь между объектами так же одна, то в данном примере, у каждого объекта уже 2а ресурса: «Группа» ИЛИ «Тип». Связь строиться по каждому ресурсу до ближайшего (в обратном порядке поступления на обработку) объекта с таким же ресурсом.
Граф
Объект посылается в обработку только в том случае, если обработаны ВСЕ «Ведущие» объекты с которыми он связан своими ресурсами и если есть свободные потоки.
В данном случае пример получился не самый удачный, т.к. объекты друг за друга цепляются (получилось близкое к v1. Пример 4, а в идеале надо ресурсы собирать как в v1. Пример 5., тогда получиться добиться параллельности обработки).


Мониторинга порядка обработки объектов
Как и предполагали по построенной схеме, что 3 и 5 объекты обработаются одновременно, а все остальные пойдут по порядку.


Результат
Столь медленная обработка обусловлена рядом причин, основная из которых, это не возможность распараллелить выполнение при текущих данных и заданных условиях. Как это выглядит при других данных можно увидеть тут (пример 5), а так же из-за поэлементной передача данных на обработку в потоки.


Выводы
Как можно заметить, распараллеливание не является «панацеей» и все зависит от конкретной задачи, способа реализации и объема данных.
Всегда надо учитывать, что при распараллеливании есть «накладные расходы».
Кроме того, не нужно забывать проводить тестирование на разных объемах данных, чтобы понять, как ведут себя алгоритмы (пропорционально увеличению или нет).
Условия поставок:

Гарантия возврата денег
ООО «Инфостарт» гарантирует Вам 100% возврат оплаты, если программа не соответствует заявленному функционалу из описания. Деньги можно вернуть в полном объеме, если вы заявите об этом в течение 14-ти дней со дня поступления денег на наш счет.
Программа настолько проверена в работе, что мы с полной уверенностью можем дать такую гарантию. Мы хотим, чтобы все наши покупатели оставались довольны покупкой.
Для возврата оплаты просто свяжитесь с нами.
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале