
Когда происходит добавление, обновление или удаление строк, то SQL Server устанавливает монопольную блокировку (X) на строку и удерживает ее до окончания транзакции. Как можно понять из названия, монопольная (exclusive) — означает, что только одна сессия может установить эту блокировку в один момент времени. Эта блокировка защищает объект (например, строку) от изменения другими сессиями. Важный момент — монопольные блокировки (X) не снимаются до окончания транзакции независимо от уровня изоляции. Чем дольше длится транзакция, тем дольше сохраняются монопольные блокировки (X).
Блокировки на уровне строк улучшают согласованность данных, но в то же время эти блокировки плохо сказываются на всей системе в целом. Давайте подумаем, в каких случаях может потребоваться монопольный доступ к таблице? Например, когда мы хотим изменить метаданные таблицы или создать новый индекс. Если у нас установлены блокировки только на уровне строк, тогда каждая сессия будет сканировать таблицу в поисках установленных блокировок для каждой строки, а также устанавливать свои блокировки, чтобы предотвратить изменения уже просканированных строк. Как вы уже поняли, это было бы неэффективно с точки зрения операций ввода-вывода и памяти, особенно на больших таблицах. Для этого в SQL Server введено такое понятие, как блокировка с намерением (I*). SQL Server использует их, чтобы показать, что есть блокировки на более низком уровне. Рассмотрим их.
Примечание. Во всех примерах будет использоваться таблица Delivery.Orders, структура которой описана ниже. Эта таблица имеет кластерный первичный ключ OrderId. Другие индексы не используются.
create table Delivery.Orders ( OrderId int not null identity(1,1), OrderDate smalldatetime not null, OrderNum varchar(20) not null, Reference varchar(64) null, CustomerId int not null, PickupAddressId int not null, DeliveryAddressId int not null, ServiceId int not null, RatePlanId int not null, OrderStatusId int not null, DriverId int null, Pieces smallint not null, Amount smallmoney not null, ModTime datetime2(0) not null constraint DEF_Orders_ModTime default getDate(), PlaceHolder char(100) not null constraint DEF_Orders_Placeholder default 'Placeholder', constraint PK_Orders primary key clustered(OrderId) )
Пример на рисунке 1 показывает блокировки сессии, после того, как была выполнена операция обновления строки таблицы. Показана одна монопольная блокировка (X) строки (KEY), и две монопольные блокировки с намерением (IX) для страницы (PAGE) и таблицы (OBJECT). Монопольные блокировки с намерением (IX) всего-лишь показывают, что есть другие монопольные блокировки, но уже на других уровнях (ниже уровня текущей блокировки). Имеется также совмещаемая (S) блокировка базы данных. Совмещаемые (S) блокировки будут рассмотрены ниже в этой главе.
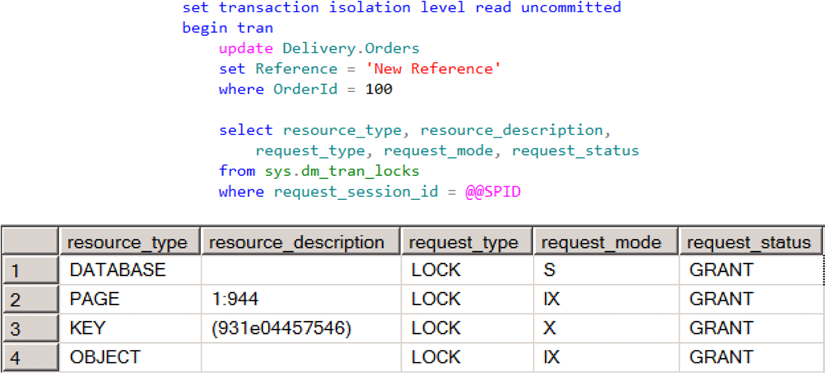
Рисунок 1. Монопольная (X) блокировка и монопольная блокировка с намерением (IX)
Колонка "resourse_description" показывает описание ресурсов, для которых установлены блокировки. Для страницы (PAGE) указывается ее физическое размещение (страница 994 в файле 1 базы данных), для строки (KEY) это хэш ключа индекса.
Теперь, если другой сессии требуется установить монопольный доступ к таблице (OBJECT), то она может проверить блокировки с намерением на этом объекте, а не сканировать всю таблицу.
Еще один важный тип блокировок — блокировки обновления (U). SQL Server устанавливает этот тип блокировок при поиске строк, которые необходимо обновить. После того, как блокировка обновления (U) установлена, SQL Server считывает строку и проверяет, нужно ли ее обновить, сверив значения строки с условиями в запросе. Если строка удовлетворяет условиям, то блокировка обновления (U) меняется на монопольную блокировку (X), затем строка модифицируется. В противном случае блокировка обновления (U) снимается. Давайте посмотрим как это работает на рисунке 2.

Рисунок 2. Блокировки обновления (U) и монопольные (X) блокировки
Сначала SQL Server устанавливает монопольную блокировку с намерением (IX) на уровне таблицы (OBJECT). После этого он устанавливает блокировки обновления с намерением (IU) на страницы и блокировки обновления (U) на строки, а затем изменяет их на монопольные блокировки с намерением (IX) и монопольные блокировки (X). Наконец, когда мы откатили транзакцию, все блокировки снялись.
Стоит отметить, что поведение блокировок обновления (U) зависит от плана выполнения. В некоторых случаях, когда мы обновляем несколько записей, SQL Server может установить сперва на все строки блокировки обновления (U), а затем заменить их на монопольные блокировки (X). В других случаях, когда, например, мы обновляем только одну строку, которая является ключом кластерного индекса, SQL Server может сразу установить монопольную блокировку (X), без установки блокировки обновления (U).
Но самые важное происходит тогда, когда мы сталкиваемся с неоптимальными (с точки зрения плана выполнения) обновлениями. Давайте попробуем обновить одну строку в таблице, основанной на колонке, которая не имеет индексов. Результат показан на рисунке 3.
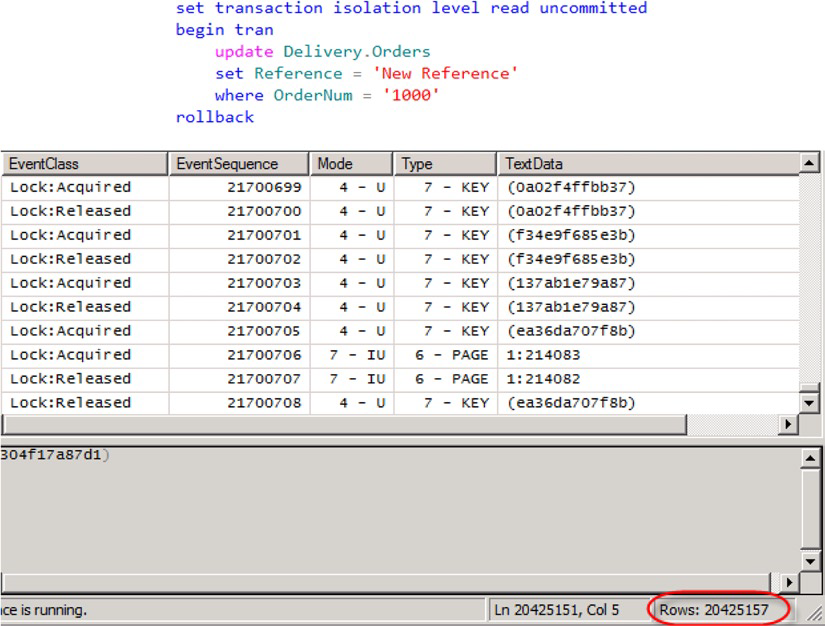
Рисунок 3. Блокировки обновления и неоптимальные запросы
Т.к. по колонке OrderNum нет индексов, то SQL Server вынужден сканировать всю таблицу и устанавливать блокировки обновления (U) на каждую строку, которую прочитал. Даже если нам требуется обновить только одну строку. Что произойдет, если несколько сессий одновременно попытаются установить на те же самые ресурсы? Совместимость блокировок показана в таблице 1.
Таблица 1. Матрица совместимости блокировок
| (IU) | (U) | (IX) | (X) | |
| (IU) | Да | Нет | Да | Нет |
| (U) | Нет | Нет | Нет | Нет |
| (IX) | Да | Нет | Да | Нет |
| (X) | Нет | Нет | Нет | Нет |
Ключевые моменты:
- Блокировки с намерениями (IU/IX) совместимы друг с другом. Это значит, что несколько сессий одновременно могут иметь блокировки с намерениями на уровне объектов/страниц.
- Монопольные блокировки (X) несовместимы друг с другом. Это означает, что несколько сессий не могут одновременно установить монопольные блокировки на один и тот же ресурс. Например, несколько сессий не могут одновременно обновить одну и ту же строку.
- Блокировки обновления (U) несовместимы друг с другом, а также с монопольными блокировками (X). Это означает, что сессия не может установить блокировку обновления (U) одновременно с другой сессией, которая уже установила исключительную блокировку (X) или блокировку обновления (U).
Последний пункт является одним из типичных сценариев блокировок. Предположим, в одной сессии мы установили монопольную блокировку (X) на одну из строк таблицы. В другой сессии мы пытаемся обновить другую строку этой же таблицы и запускаем запрос на обновление с неоптимальным планом, что приводит к сканированию всей таблицы. SQL Server будет устанавливать блокировку обновления (U) на каждую просканированную строку, но в итоге не сможет завершить операцию, т.к. попытается прочитать строку, на которой уже была установлена монопольная блокировка (X). И при этом неважно, что мы хотим обновить совершенно другую строку, для SQL Server необходимо прочитать строку, чтобы установить на нее блокировку обновления (U), и после этого проверить, нужно ли ее обновить.
Для каждой системы, мы можем все выполняемые запросы разделить на две группы: которые модифицируют данные, и которые данные читают. К первой группе относят INSERT, UPDATE, DELETE и MERGE запросы. Ко второй группе относят SELECT запросы. Для запросов, которые только читают данные, существует еще один тип блокировки — совмещаемые (S) (shared). Как можно догадаться по названию, эти блокировки совместимы между собой, т.к. несколько сессий одновременно могут установить эти блокировки на один и тот же ресурс. Вы можете увидеть эти блокировки на рисунке 4.
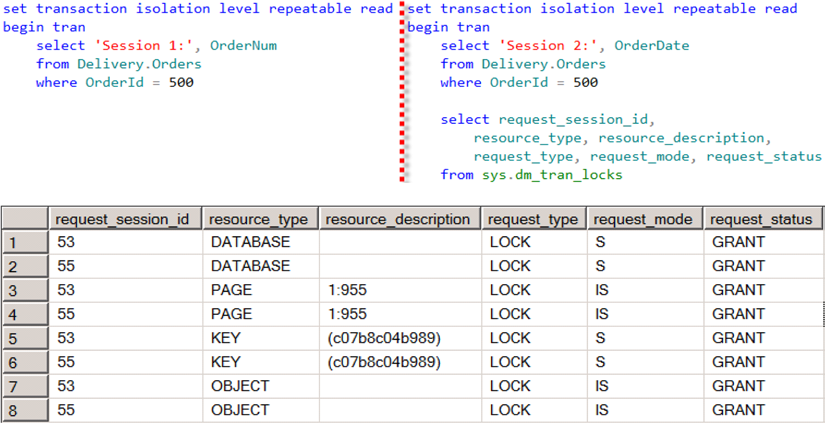
Рисунок 4. Совмещаемые блокировки (S)
В этом примере видны два сессии, одновременно читающих одну и ту же строку. Обе сессии установили совмещаемые блокировки (S) на базу данных, совмещаемые блокировки с намерениями (IS) на таблицу, страницу (1:955) и совмещаемую блокировку (S) на строку, при этом не блокируя друг друга. Добавим совмещаемые блокировки (S) в матрицу совместимости блокировок (таблица 2).
Таблица 2. Матрица совместимости блокировок
| IS | S | (IU) | (U) | (IX) | (X) | |
| (IS) | Да | Да | Да | Да | Да | Нет |
| (S) | Да | Да | Да | Да | Нет | Нет |
| (IU) | Да | Да | Да | Нет | Да | Нет |
| (U) | Да | Да | Нет | Нет | Нет | Нет |
| (IX) | Да | Нет | Да | Нет | Да | Нет |
| (X) | Нет | Нет | Нет | Нет | Нет | Нет |
Несколько ключевых моментов, связанных со совмещаемыми блокировками (S):
- Совмещаемые блокировки (S) совместимы друг с другом, это значит, что несколько сессий одновременно могут читать одни и те же данные не блокируя друг друга.
- Совмещаемые блокировки (S) и блокировки обновления совместимы друг с другом, это значит, что запросы на чтение и обновление данных не блокируют друг друга.
- Совмещаемые блокировки (S) не совместимы с монопольными блокировками. Это значит, что запросы на чтение не могут получить неподтвержденные данные, изменяемые в других сессиях.
Что управляет блокировкой? На блокировки в первую очередь влияют уровни изоляции транзакции. Исторически SQL Server использует 4 пессиместических уровня изоляции: read uncommitted (неподтвержденное чтение); read committed (подтвержденное чтение); repeatable read (повторяемое чтение), и serializable (упорядоченный или сериализуемый). Начнем с них. Существует также два оптимистических уровня изоляции: read committed snapshot (подтвержденное чтение с включенным параметром READ_COMMITTED_SNAPSHOT) и snapshot (изоляция моментального снимка), которые будут рассмотрены далее в этой книге.
Примечание. SQL Server работу с данными всегда выполняет в транзакции. Клиент может сам контролировать начало и окончание транзакции, используя команды BEGIN TRAN/COMMIT. В противном случае SQL Server начинает транзакции неявно для каждого действия. Даже оператор SELECT выполняет в транзакции. При этом в журнал транзакций информация о транзакции при выполнении оператора SELECT не записывается, хотя при этом действуют все ограничения, касающиеся блокировок и параллелизма.
Как мы уже знаем, SQL Server удерживает монопольную (X) блокировку до конца транзакции, вне зависимости от того, какой уровень изоляции используется. При использовании пессиместических уровней изоляции, блокировки обновления (U) ведут себя аналогичным образом. SQL Server будет ставить блокировки обновления на данные, для того, чтобы определить, что требуется обновить, а что нет. Опять же, независимо от используемого уровня изоляции транзакции.
Примечание. Даже при уровне изоляции read uncommitted сеансы, которые пишут данные, могут блокировать друг друга.
Ключевая разница между пессимистическими уровнями изоляции транзакций, это то, как SQL Server работает с совмещаемыми (S) блокировками.
Если используется уровня изоляции read uncommited, то при чтении не накладываются совмещаемые (S) блокировки, поэтому сеанс может прочитать даже те данные, на которые установлена монопольная (X) блокировка. Поэтому этот уровень изоляции часто называют "грязное чтение". С точки зрения параллелизма это означает, что никакой согласованности данных нет. При чтении данных считываются текущие (модифицированные) версии строк, не зависимо от того, что произойдет с ними дальше. Транзакция изменившая строки может откатиться или сами строки могут быть изменены несколько раз. Такое поведение мы можем увидеть на рисунке 5.
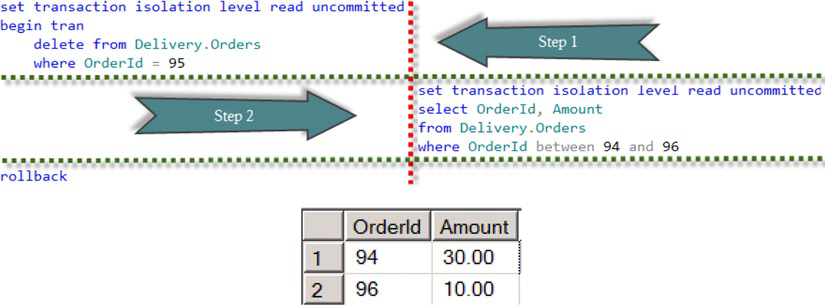
Рисунок 5. Уровень изоляции read uncommitted и совмещаемые блокировки
При чтении данных с уровнем изоляции read commited сразу устанавливаются совмещаемые блокировки (классы событий Lock:Acquired и Lock:Released). Это предотвращает чтение незафиксированных данных, т.к. совмещаемые (S) блокировки несовместимы с монопольными (X) блокировками. Пример показан на рисунке 6.
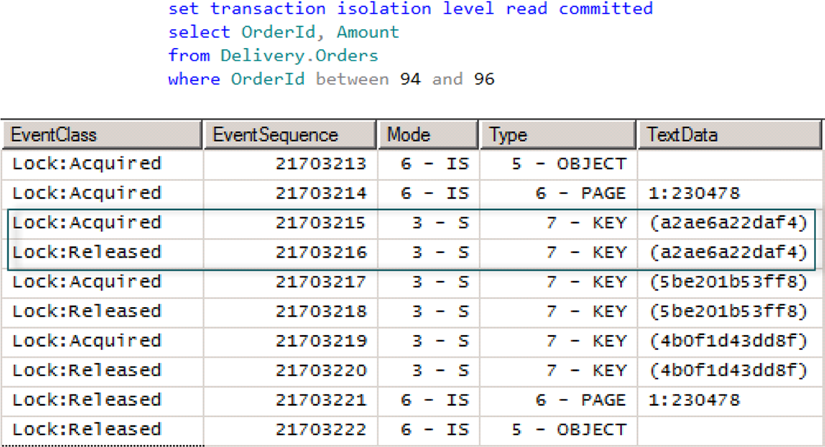
Рисунок 6. Уровень изоляции read committed и совмещаемые блокировки
Примечание. В некоторых случаях, при чтении с уровнем изоляции read commited, SQL Server может оставлять совмещаемые (S) блокировки до тех пор, пока выполняется оператор SELECT, а не снимать их сразу после чтения.
При использовании уровня изоляции repeatable read совмещаемые блокировки при чтении удерживаются до конца транзакции (как показано на рисунке 7). Такое поведение запрещает изменять строки, которые были однажды прочитаны, т.к. на эти данные уже наложены совмещаемые (S) блокировки. Как и в случае с уровнем изоляции read commited, нельзя прочитать данные, которые были изменены в других сессиях.
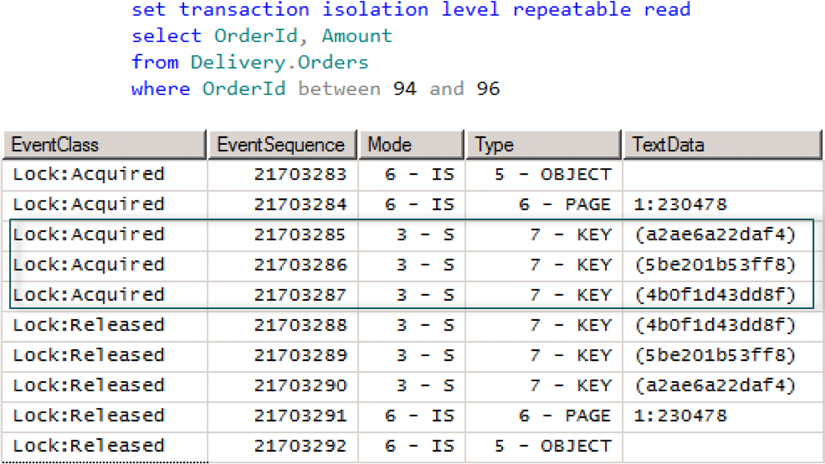
Рисунок 7. Уровень изоляции repeatable read и совмещаемые блокировки
Уровень изоляции serializable работает практически также, как и repeatable read, но вместо отдельных блокировок на уровне строк используются блокировки диапазона ключей (как для совмещаемых (S), так и для монопольных (X) блокировок). Можно увидеть пример такого поведения на рисунке 8.
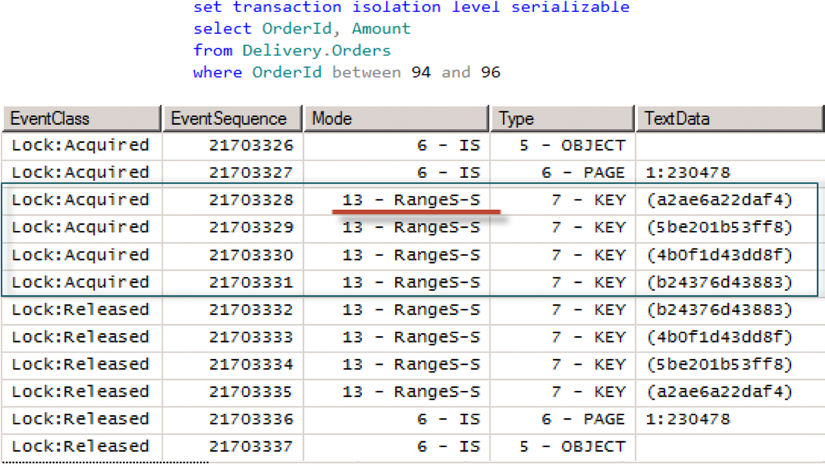
Рисунок 8. Уровень изоляции serializable и совмещаемые блокировки
Примечание. Предположим, что нам необходимо выбрать заказы с OrderID между 1 и 3, при этом у нас нет заказа с OrderID равное 2. В случае с уровнем изоляции repeatable read будут установлены отдельные совмещаемые (S) блокировки для каждой строки (1 и 3). Другие сессии не смогут изменить эти две строки, но смогут вставить третью с OrderID равное 2. При уровне изоляции serializable будет установлена совмещаемая блокировка на диапазон (Range-S), которая будет запрещать как изменять строки, так и вставлять новые, которые попадают в этот диапазон.
В таблице 3 показано, как уровни изоляций транзакций влияют на совмещаемые (S) блокировки.
Таблица 3. Поведение совмещаемых (S) блокировок
| Уровень изоляции | Табличное указание | Поведение совмещаемой блокировки |
| Read uncommitted | (NOLOCK) | (S) блокировки не устанавливаются |
| Read committed | (READCOMMITTED) | (S) блокировки устанавливаются и сразу снимаются |
| Repeatable read | (REPEATABLEREAD) | (S) блокировки устанавливаются и сохраняются до конца транзакции |
| Serializable | (SERIALIZABLE) | Устанавливаются блокировки на диапазон и сохраняются до конца транзакции |
Примечание. SQL Server работу с данными всегда выполняет в транзакции. Клиент может сам контролировать начало и окончание транзакции, используя команды BEGIN TRAN/COMMIT. В противном случае SQL Server начинает транзакции неявно для каждого действия. Даже оператор SELECT выполняет в транзакции. При этом в журнал транзакций информация о транзакции при выполнении оператора SELECT не записывается, хотя при этом действуют все ограничения, касающиеся блокировок и параллелизма.
Мы можем управлять совмещаемыми (S) блокировоками с помощью уровня изоляции транзакций и табличных указаний. Это позволяет в одном запросе, объединяющем несколько таблиц, указывать свой "уровень изоляции" для каждой таблицы. Например, код в листинге 1 возвращает два результирующих набора. В первом наборе данных мы использует уровень изоляции read commited (таблица customers), а во втором serializable (таблица orders). Совмещаемые (S) блокировки для таблицы customers снимутся сразу после чтения строк, но для таблицы orders останутся до конца транзакции. Другие сессии смогут изменять строки для таблицы customers, но не смогут изменить данные таблицы orders, которые были прочитаны при выполнении запроса.
Листинг 1. Контроль поведения блокировок, используя табличные указания (table hint)
begin tran select c.CustomerName, sum(o.Total) from dbo.Customers c with (readcommitted) join dbo.Orders o with (serializable) o on o.CustomerId = c.CustomerId group by c.CustomerName select top 10 o.OrderNum, o.OrderDate from dbo.Orders order by o.OrderDate desc commit
Примечание. Дополнительную информацию по табличным указаниям (table hint) можно получить перейдя по ссылке: https://msdn.microsoft.com/ru-ru/library/ms187373.aspx
Мы можем изменить тип устанавливаемой блокировки при чтении с помощью табличных указателей (UPDLOCK) и (XLOCK). Это может быть полезно, когда нужно обеспечить последовательный доступ на чтение к некоторым данным, таких как счетчики таблиц, когда нужно выбрать некоторое значение из таблицы, выполнить обработку и обновить строку. В этом случае, использование блокировки обновления (U) или монопольной (X) блокировки запретит чтение данных до тех пор, пока первая сессия не завершит транзакцию. Пример показан в листинге 2.
Листинг 1. Управление блокировками, используя табличные указания (table hint)
begin tran -- placing update (U) lock on the row to prevent multiple sessions to select the value from -- the same counter simultaneously due update (U) locks incompatibility select @Value = Value from dbo.Counters with (updlock) where CounterName = @CounterName update dbo.Counters set Value += @ReserveCount where CounterName = @CounterName commit
Примечание. Код в листинге 2 показан только для примера. Он не обрабатывает ситуацию, когда конкретного счетчика нет в таблице. Лучше использовать последовательности (SEQUENCE) где это возможно, а не счетчики таблиц.
В заключение рассмотрим несколько типичных проблем несогласованности данных с точки зрения уровней изоляции и блокировок.
Грязное чтение: Грязное чтение — это ситуация, когда сессия читает незафиксированные (грязные) данные других незавершенных транзакций. Очевидно, что в такие моменты мы не знаем, будут ли активные транзакции фиксироваться или откатываться; а может данные будут изменены несколько раз. Представим, что пользователь хочет перевести деньги с текущего счета на сберегательный. Есть две физические операции с данными: это списание со счета и зачисление на счет. Логически эти две операции должны выполняться в одной транзакции. Если другая сессия в этот момент читает остатки в режиме грязного чтения в промежутке между операциями (между двумя обновлениями данных), тогда данные будут неправильные.
Как мы помним, сессия устанавливает и удерживает монопольные (X) блокировки на строки, которые изменила. Единственный случай, когда мы можем прочитать эти (измененные) строки, когда мы не используем совмещаемые (S) блокировки при чтении, т.е. используем уровень изоляции read uncommitted. Все остальные пессиместические уровни изоляции устанавливают совмещаемые (S) блокировки и не могут получить грязное чтение.
Неповторяющееся чтение: Несоответствие данных возникает, когда данные изменены или удалены между чтениями в пределах одной транзакции. Представим ситуацию, когда мы готовим отчет в системе приема заказов, который выводит список заказов конкретного клиента, и выполняет еще один запрос с итоговыми данными (например, общая сумма, которую клиент тратит на ежемесячной основе). Если после считывания данных первой частью отчета другая сессия изменит или удалить один из заказов, то суммы не сойдутся.
Такое может произойти, если мы не защитили/заблокировали данные между операциями чтения. Подобная ситуация случается, когда мы читаем данные с уровнем изоляции read uncommitted (в котором не устанавливаются совмещаемые (S) блокировки), или с уровнем изоляции read committed (при котором совмещаемые (S) блокировки устанавливаются и сразу снимаются). Уровни изоляции repeatable read и serializable удерживают совмещаемые (S) блокировки до конца транзакции, поэтому после чтения данные уже не могут быть изменены другой сессией.
Фантомное чтение: Это ситуация, когда повторное чтение в пределах одной транзакции возвращает новые строки (те, которые мы не читали ранее). Рассмотрим предыдущий пример с отчетом, только в этот раз заказ будет не изменен или удален, а добавлен новый. Даже уровень изоляции repeatable read не спасет нас в этом случае. Мы устанавливаем совмещаемые (S) блокировки при чтении строк, но ключевой диапазон при этом не защищен. Чтобы избежать подобных проблем необходимо использовать уровень изоляции serializable, т.к. он устанавливает блокировки на диапазон.
Существуют еще два других случая, связанных с перемещением данных при изменении значения ключа индекса.
Дублирующееся чтение: Предположим, у нас есть запрос, который возвращает список заказов за определенный интервал времени и использует индекс по колонке Дата заказа. В момент выполнения этого запроса другая сессия может изменить дату одного из заказов, который мы уже успели прочитать, тем самым переместив строку из обработанной запросом части индекса в еще необработанную. В этом случае запрос прочитает одну и ту же строку дважды. Такая ситуация возможна, если мы при чтении данных не удерживаем совмещаемые (S) блокировки (уровни изоляции read uncommitted и read committed) до окончания выполнения запроса. Для уровней изоляции repeatable read и serializable эта проблема неактуальна, потому что эти уровни удерживают совмещаемые (S) блокировки до конца транзакции.
Пропущенные строки: Тоже самое, что и дублирующееся чтение, но вторая сессия перемещает данные из необработанной части индекса в обработанную. Запрос первой сессии не прочитает измененную строку и не включит в выборку. Уровень изоляции repeatable read не спасет, потому что совмещаемые (S) блокировки устанавливаются на отдельные строки, но при этом есть возможность добавлять данные между ними. Только уровень изоляции serializable позволит избежать подобных проблем.
Таблица 4. Уровни изоляции транзакций и несоответствия данных
| Грязное чтение | Неповторяющееся чтение | Дублирующееся чтение | Фантомное чтение | Пропущенные строки | |
| Read uncommitted | Да | Да | Да | Да | Да |
| Read committed | Нет | Да | Да | Да | Да |
| Repeatable read | Нет | Нет | Нет | Да | Да |
| Serializable | Нет | Нет | Нет | Нет | Нет |
Как вы могли заметить, уровень изоляции, который избавлен от всех видов несогласованности данных — serializable. Но этот уровень изоляции плохо влияет на параллельность работы, потому что запросы на чтение и запросы на запись работают с одними и теми же наборами данных в системе.
К счастью, есть решение подобной проблемы: оптимистические уровни изоляции транзакций — read committed snapshots и snapshots, которые мы рассмотрим в следующей статье.
Важно понимать, как работают различные типы блокировок. Знания об их поведении и совместимости помогут нам избавиться от множества проблем. А также позволят разработать такую стратегию обработки транзакций, чтобы обеспечить оптимальную согласованность данных и параллелизм в наших системах.
———————————
При написании статьи использовались материалы из книги Дмитрия Короткевича «Pro SQL Server Internals» (2014 г.)
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Надо запомнить статейку. Пора по-серьезному SQL заняться.
Пока не понимаю, чем это поможет в проектировании системы на 1С:Предприятие
(2)
возможно вы перестанете писать кривые запросы и задавать вопросы почему они медленно работают. а всё это следствие никчемного проектирования системы
Можно я утащу кусочек себе в статью? Ссылку на вас вставлю.
(4) Да, пожалуйста