















• Я расскажу про различные методики организации переносов данных.
• Мы рассмотрим рекомендуемые способы оптимизации правил конвертации, которые позволят вам быстрее выполнять свои переносы.
• Также мы разберем, какие могут возникнуть сложности в ходе переноса данных.
• Я покажу сравнительный анализ по ряду параметров инструментов «Конвертация данных» второй редакции и третьей, которая вышла уже более года назад.
1С:Конвертация данных 2.0. Преимущества и недостатки

Основной акцент в статье будет сделан именно на «Конвертацию данных» второй редакции. Дело в том, что на этой технологии до сих пор основано наибольшее количество типовых обменов между конфигурациями. Кроме того, если вы будете сталкиваться с задачами перехода на новые редакции программ 1С, вам также придется иметь дело с правилами, разработанными в «Конвертации данных» второй редакции.
Итак, какие преимущества и недостатки есть у «Конвертации данных» второй редакции? Начнем с преимуществ:
- «Конвертация данных» второй редакции стала сейчас основным стандартом разработки переносов и обменов. Эта технология существует с 2001 года, и знания в этой области являются популярным требованием при приеме на работу, потому что задачи использования этой технологии очень распространены, и в типовых конфигурациях активно используются.
- У «Конвертации данных» 2.1 есть широкие возможности: вы можете настраивать обмены и переносы данных не только с продуктами 1С (любых редакций – как 8.х, так и 7.7), но и с продуктами других разработчиков.
- А также, что является большим плюсом, для этой технологии есть множество готовых решений. Например, если у вас есть некие нетиповые конфигурации, для которых нужно выполнить перенос данных в другую программу 1С, вы можете взять типовой перенос и его доработать. Или взять готовые обработки в интернете, и, таким образом, существенно сэкономить свое время и силы. Это позволит вам выполнить свою задачу буквально за дни – не тратить на это месяцы.
Какие минусы?
- У Конвертации данных 2.1 нет многопоточности.
- Формат представления данных – это xml, который имеет свои минусы. Об этом мы позже поговорим подробнее.
- Нет защиты от сбоев. Вы можете сутки выполнять выгрузку данных из программы, а она прервется по какой-нибудь битой ссылке в одном из объектов, после чего вам придется исправлять эту ошибку в данных и заново начинать свой перенос.
- Можно сказать, что для нее неудобно выполнять отладку. Я сейчас говорю, в основном, про обработку «Универсальный обмен в формате XML» – у нее есть возможность отладки, но для этого вам придется создавать отдельную обработку, в которую должны быть встроены модули всех используемых правил конвертации, и подключать эту обработку к универсальной обработке обмена. На мой взгляд, это неудобно.
- И нет хорошего контроля переполнения кэша. Например, когда у вас объектов много, они будут копиться, и каждая следующая тысяча объектов будет выгружаться все медленнее и медленнее.
Методические рекомендации. Подготовка базы-источника
Итак, чтобы провести перенос, нужно подготовить информационные базы: и базу – источник данных, и базу – приемник. Допустим, мы сейчас с вами будем говорить про перенос данных из УТ 10.3 в УТ 11.3. Какие действия необходимо совершить заранее и как подготовить исходную информационную базу?
- Во-первых, нужно подготовить свою нормативно-справочную информацию – вычистить справочники от ненужной информации:
- Удалить дубли элементов справочников,
- А также удалить все помеченные на удаление объекты.
- Следующим шагом необходимо выполнить закрытие отчетного периода и прочие регламентированные действия. В частности, рассчитать себестоимость.
- В некоторых случаях вам потребуется сделать изменения настроек учета и перепровести после этого все документы. Например, в старых редакциях таких программ, как УТ10.3, КА1.1, УПП1.3 есть такие настройки параметров учета, при которых вы не сможете после перехода получить себестоимость товаров в разрезе различных складов – она у вас усреднится, поскольку в регистрах не будет необходимой для этого информации.
- Разумеется, нужно будет проверить свои данные в отчетах, чтобы не было нулевых сумм и отрицательных остатков. Например, в УТ10.3, КА1.1 и УПП1.3 вам необходимо следить за тем, чтобы количественные остатки по регистру «Партии товаров на складах» не отличались от остатков по регистру «Товары на складах», потому что остатки берутся из регистра «Товары на складах», а себестоимость берется из партий (в других регистрах ее нет).
- Если информационная база большого размера, то стоит задуматься о том, чтобы очистить те таблицы, которые вы не будете использовать при переносе. Например, почистить такой регистр сведений, как «Версии объектов». При уменьшении размера базы запросы смогут работать быстрее.
Методические рекомендации. Подготовка базы-приемника
Как подготовить базу-приемник? Мы рассмотрим случай, когда переход на новую программу выполняется переносом данных в пустую базу. Что нужно сделать?
- Создать новую базу.
- Установить необходимые настройки учета, включить требуемые функциональные опции: например, использование нескольких валют, нескольких организаций.
- Загрузить или ввести вручную техническую информацию (такую, как адресные классификаторы и курсы валют). Конечно, вы можете перенести их вместе с остальными данными, но такой перенос займет много времени. Поэтому рекомендуется в базе-приемнике все эти классификаторы загрузить предварительно (перед запуском переноса), потому что если они будут пустые, программа может работать некорректно – если при проведении документов по валютным договорам курс доллара окажется равным единице, данные учета исказятся.
- И, если вам известны ошибки типовых релизов, то первоначально необходимо их исправить. Например, в «Управлении торговлей 11» у роли «Полные права» может не оказаться полных прав. Так было в релизе 11.2. А если у вас нет полных прав, то, разумеется, могут возникнуть проблемы при проведении загруженных данных.
Методические рекомендации. Перенос с помощью обработки vs через план обмена

Далее я хочу рассказать вам о том, что есть разница между выполнением синхронизации данных с использованием универсальной обработки обмена и с использованием планов обмена. Это также касается и разработки самих правил конвертации. Например, в правилах выгрузки регистров сведений при использовании планов обмена переменная Объект будет иметь тип значения РегистрСведенийНаборЗаписей, а при переносе с помощью универсальной обработки обмена эта переменная будет иметь тип значения РегистрСведенийЗапись. И если отладку правил вы выполняли с помощью универсальной обработки, а потом встроили эти правила в план обмена, то не исключено, что вы встретитесь с такой ошибкой.
В чем отличия правил конвертации для универсальной обработки обмена и для планов обмена? Какие у них могут быть особенности?
Для универсальной обработки обмена:
- Имеет смысл настроить правила конвертации так, что они будут самостоятельно устанавливать в программе-приемнике настройки параметров учета (в обработчике «Перед загрузкой данных») – например, включать использование нескольких расчетных счетов для организаций и т.д.
- Если размер информационной базы источника значительный, вам нужно соблюдать баланс между использованием кэша при переносе и его отключением. Про это я расскажу далее. Это очень важный параметр.
А какие особенности у правил, написанных для плана обмена, когда мы уже регулярно выполняем свой обмен между программами 1С?
- При регулярном обмене у нас есть таблица регистрации изменений, куда будут попадать только зарегистрированные изменения. Таким образом, как правило, выборка будет меньше, и при регулярном запуске обмена он будет выполняться быстро и с небольшой выборкой.
- Соответственно, имея небольшую выборку, мы можем позволить себе по максимуму кэшировать объекты, на которые есть большое количество ссылок.
- А также в зависимости от своей задачи нужно отслеживать то, что те данные, которые мы переносим (допустим, документы) могут быть изменены пользователями в базе-приемнике. И в зависимости от своих целей нам нужно их либо перезаписывать, либо отказаться от перезаписи. Это можно реализовать различными способами.
Методические рекомендации. Разработка правил конвертации
Какие приемы оптимизации разработки правил конвертации я хочу вам сегодня описать?
- Как я уже говорил, это – правильная настройка кэша правил конвертации;
- Отключение выгрузки свойств «по ссылке» в правилах конвертации (там, где это оправдано);
- Использование собственных таблиц кэша в глобальных параметрах конвертации;
- А также корректное и обдуманное использование глобальных обработчиков конвертации данных.
А теперь давайте каждый из этих приемов разберем подробнее.
Настройка кэша правил конвертации
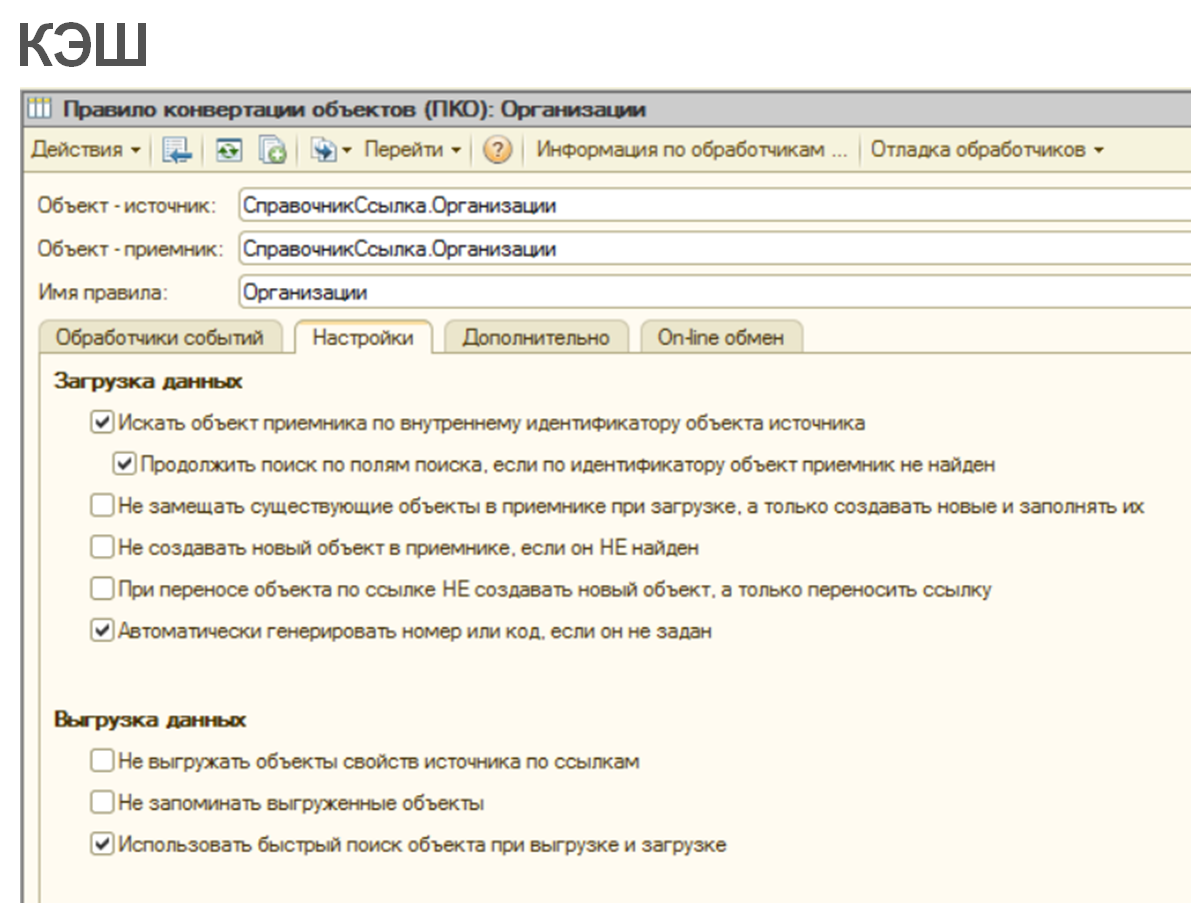
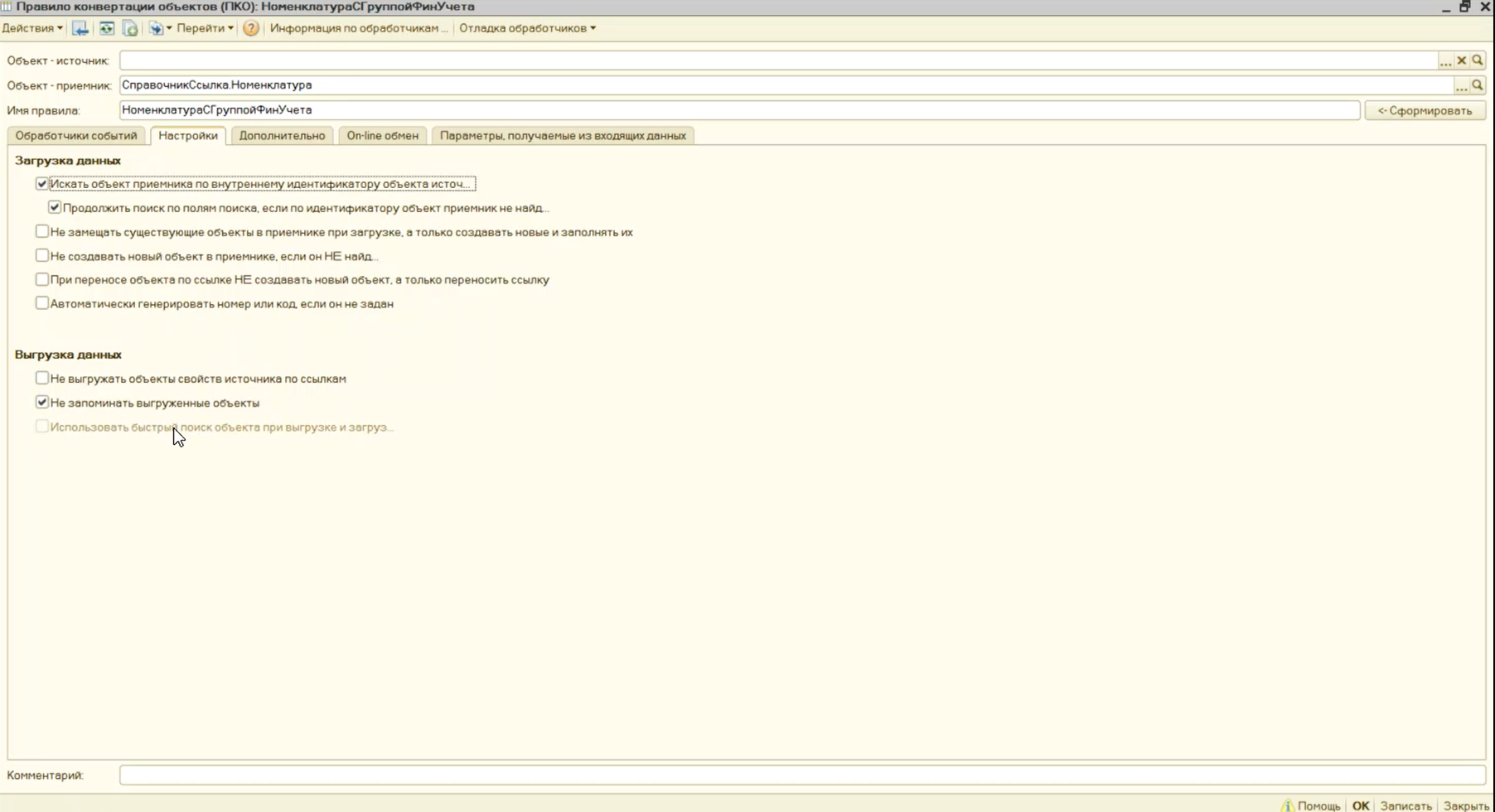
Объекты малой выборки, на которые есть большое количество ссылок в базе, нужно кэшировать. Например, таким объектом может являться справочник «Организации». Включить использование кэша очень просто – для этого достаточно поставить галочку «Использовать быстрый поиск объекта при выгрузке и загрузке».
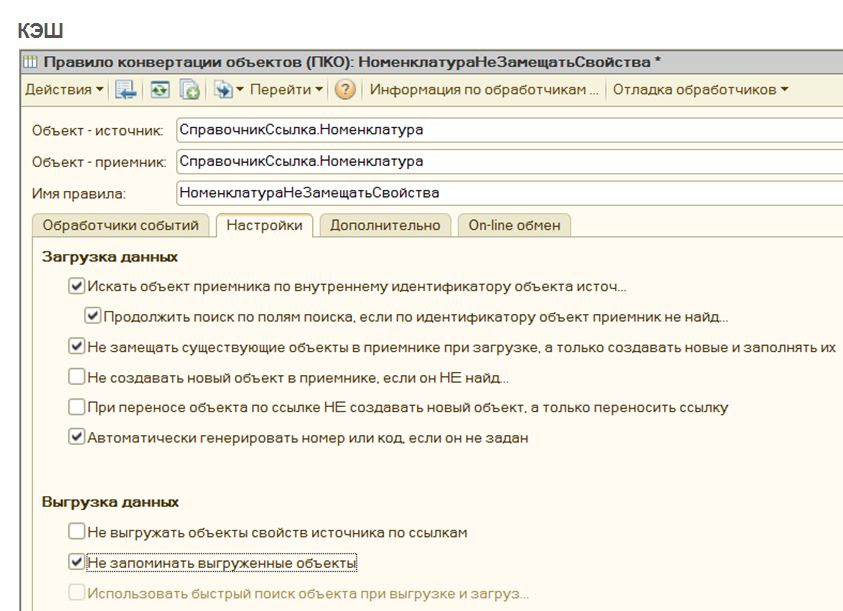
А для тех объектов, выборка которых в данной задаче переноса будет большая, а ссылок на них – мало (например, это могут быть элементы справочника «Номенклатура») – кэширование, наоборот, лучше отключить, поставив флажок «Не запоминать выгруженные объекты».
Однако в случае, если вы переносите торговые документы, такой флажок для справочника «Номенклатура» ставить не стоит, потому что здесь, наоборот, ссылок будет много, а поскольку вы их не запоминаете, у вас получится огромный файл выгрузки.
Отключение выгрузки свойств «по ссылке». Оптимизация правил конвертации на примере справочника «Номенклатура»
А теперь давайте на примере справочника «Номенклатура» рассмотрим демонстрацию того, как можно оптимизировать правила конвертации так, чтобы выполнить перенос с хорошей скоростью и соблюсти баланс занимаемой памяти на диске.
В этом примере я также покажу вам, как можно оптимизировать правила типовых переносов из программы УПП в ERP и из УТ10 в УТ11, чтобы не использовался «запрос в цикле».
Во-первых, оптимизация заключается в том, что мы создаем два правила конвертации справочника «Номенклатура»: «НоменклатураНеЗамещатьСвойства» и «НоменклатураСГруппойФинУчета».
В правиле «НоменклатураНеЗамещатьСвойства» мы выгружаем всего шесть основных свойств, которые используются для поиска (для остальных свойств установлен флажок «Отключить»).
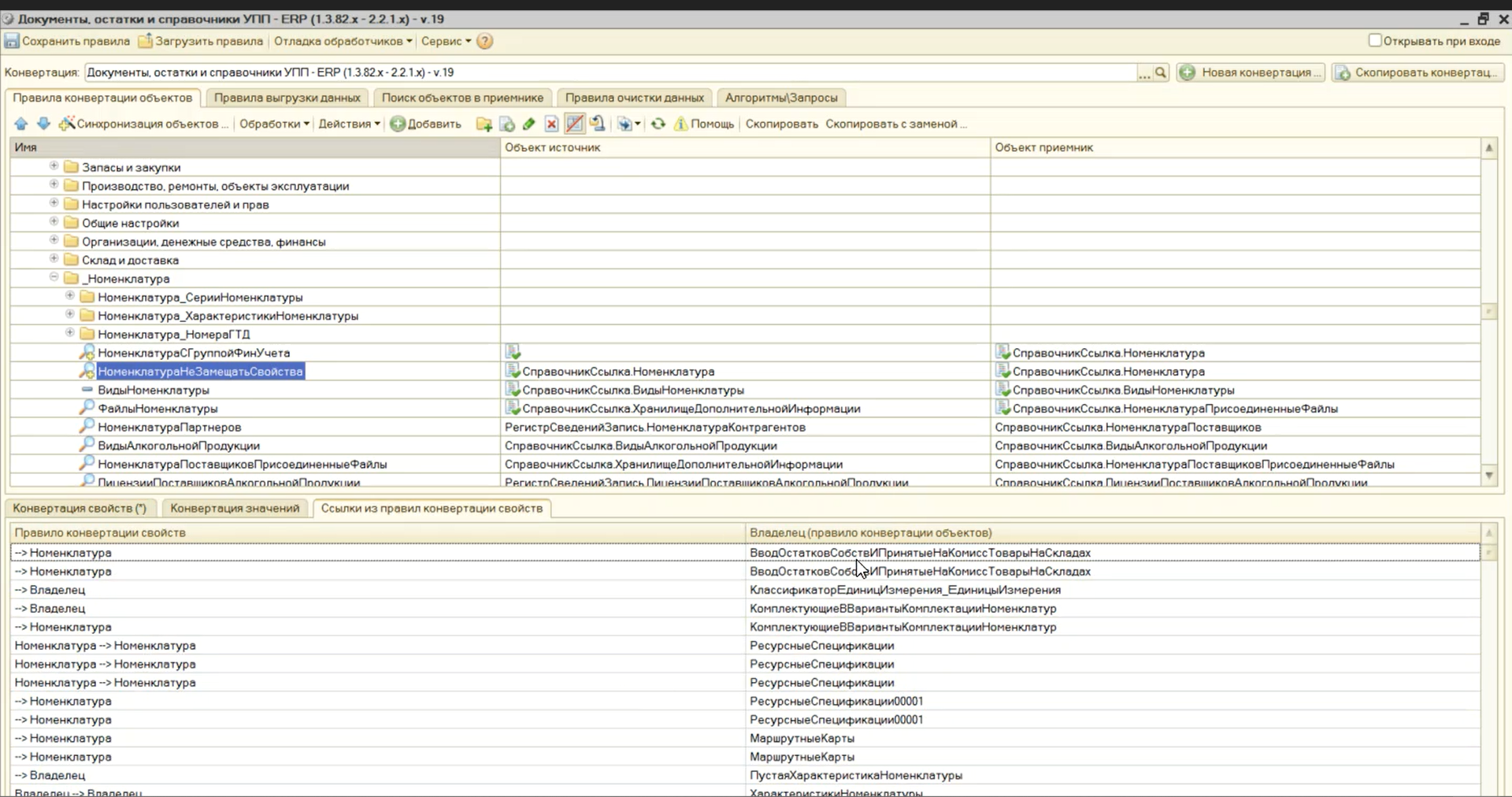
Если включить опцию «Показать ссылки на ПКО», в нижней части экрана появится закладка «Ссылки из правил конвертации свойств», где будет видно, что правило «НоменклатураНеЗамещатьСвойства» указано по ссылке в каждом другом правиле конвертации программы.
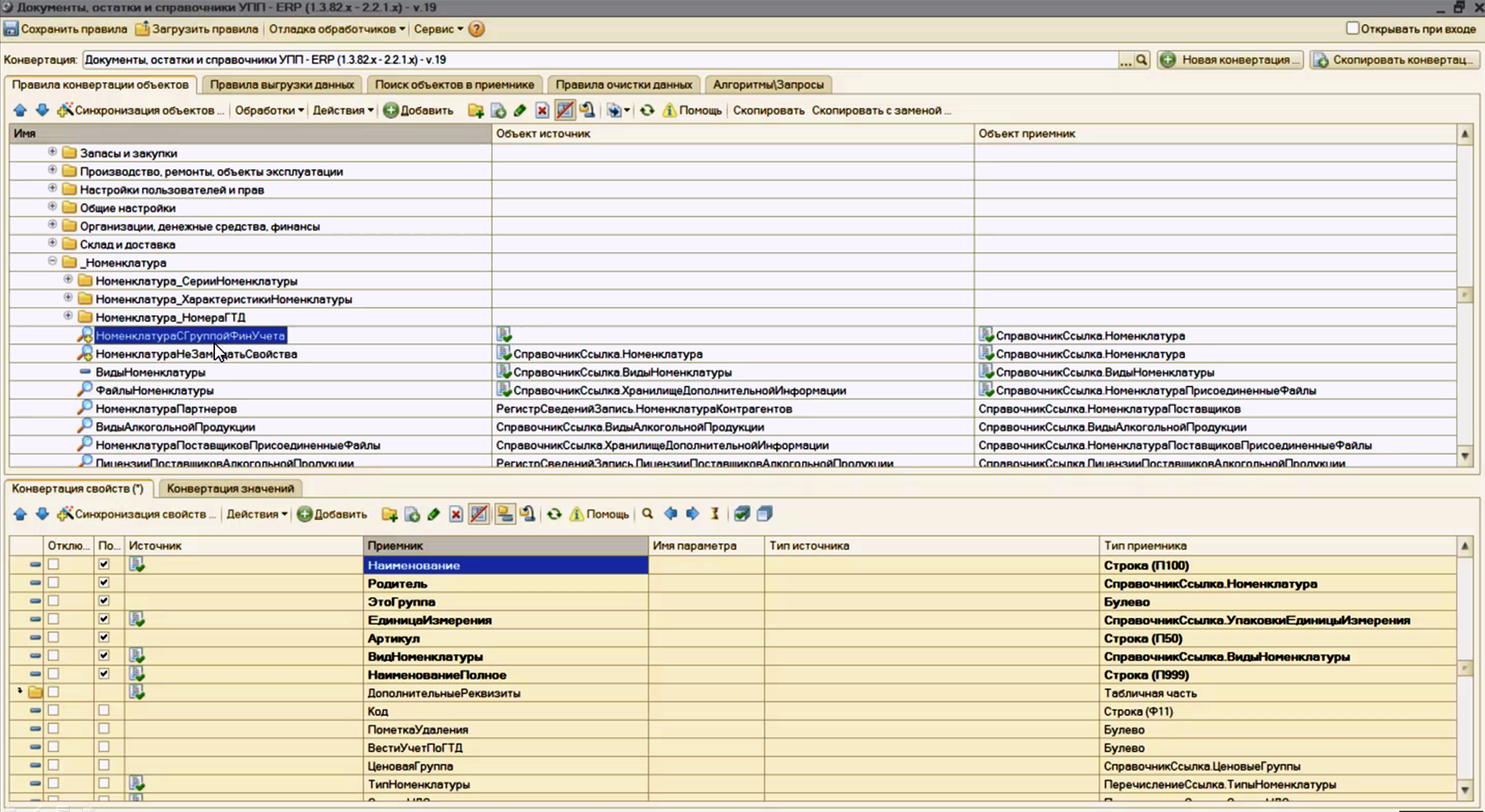
И есть второе правило «НоменклатураСГруппойФинУчета», где выгружаются все свойства.
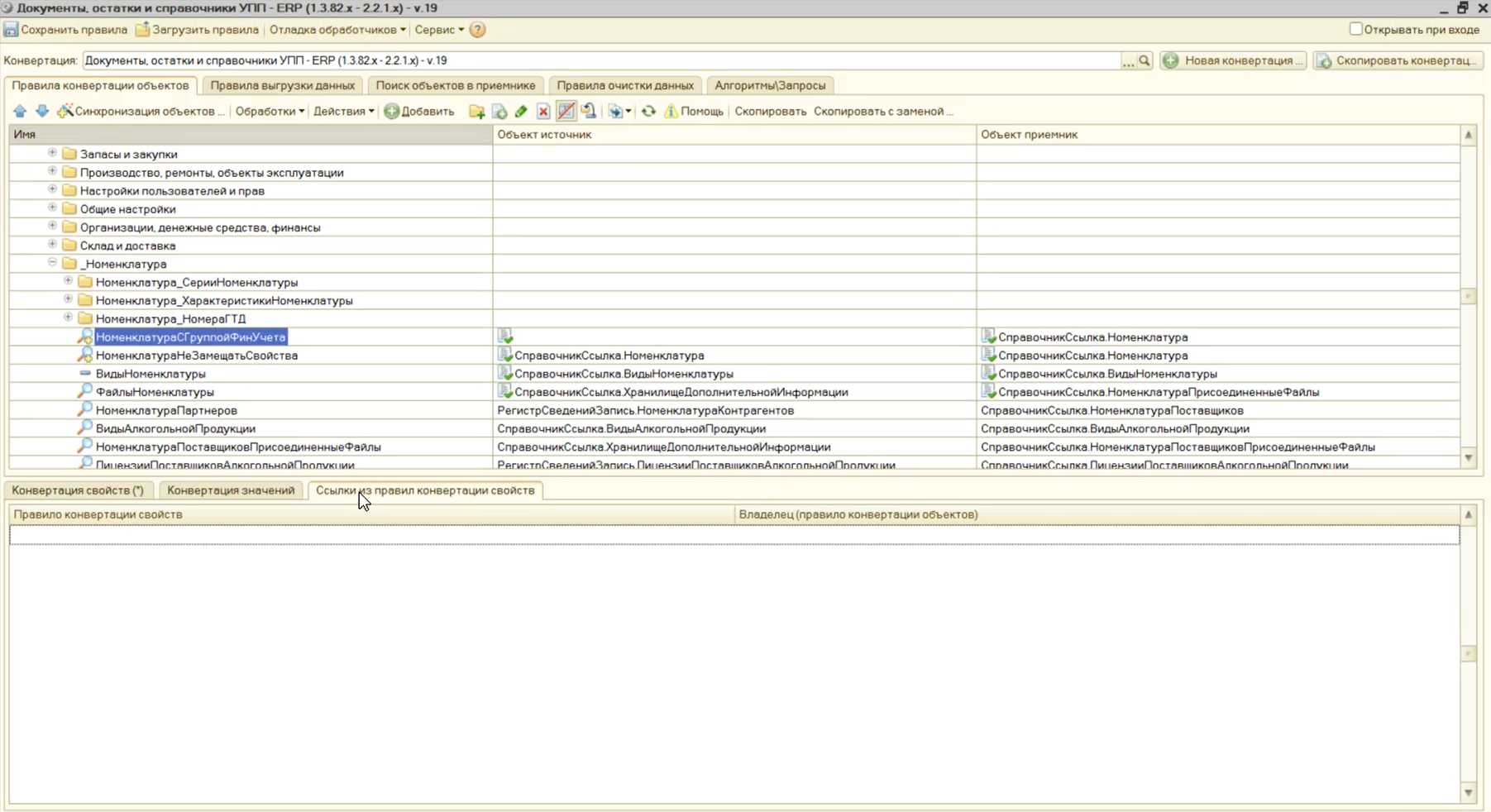
Но на него нет ни единой ссылки.
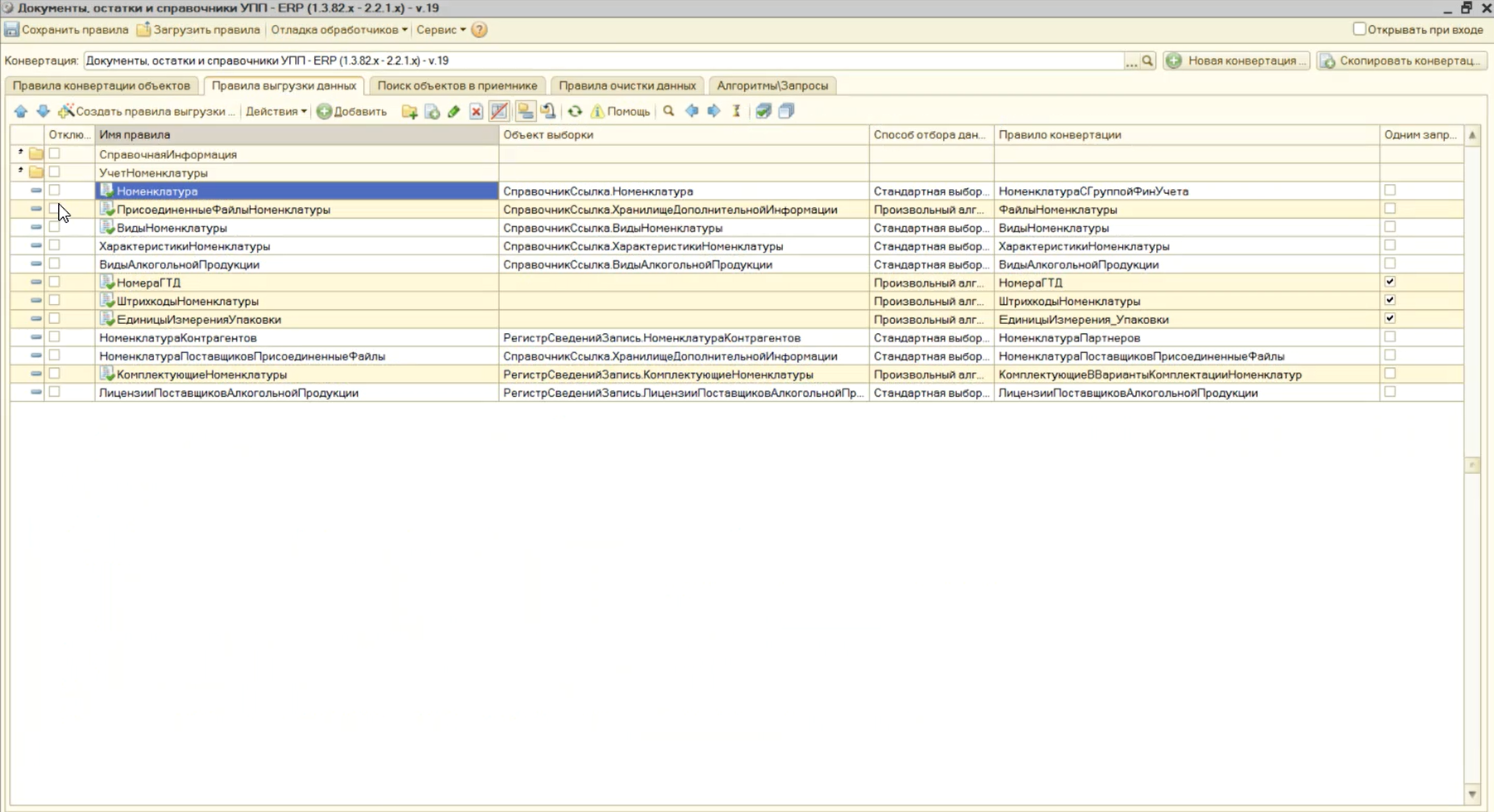
Зато оно используется в правиле выгрузки данных по справочнику «Номенклатура».
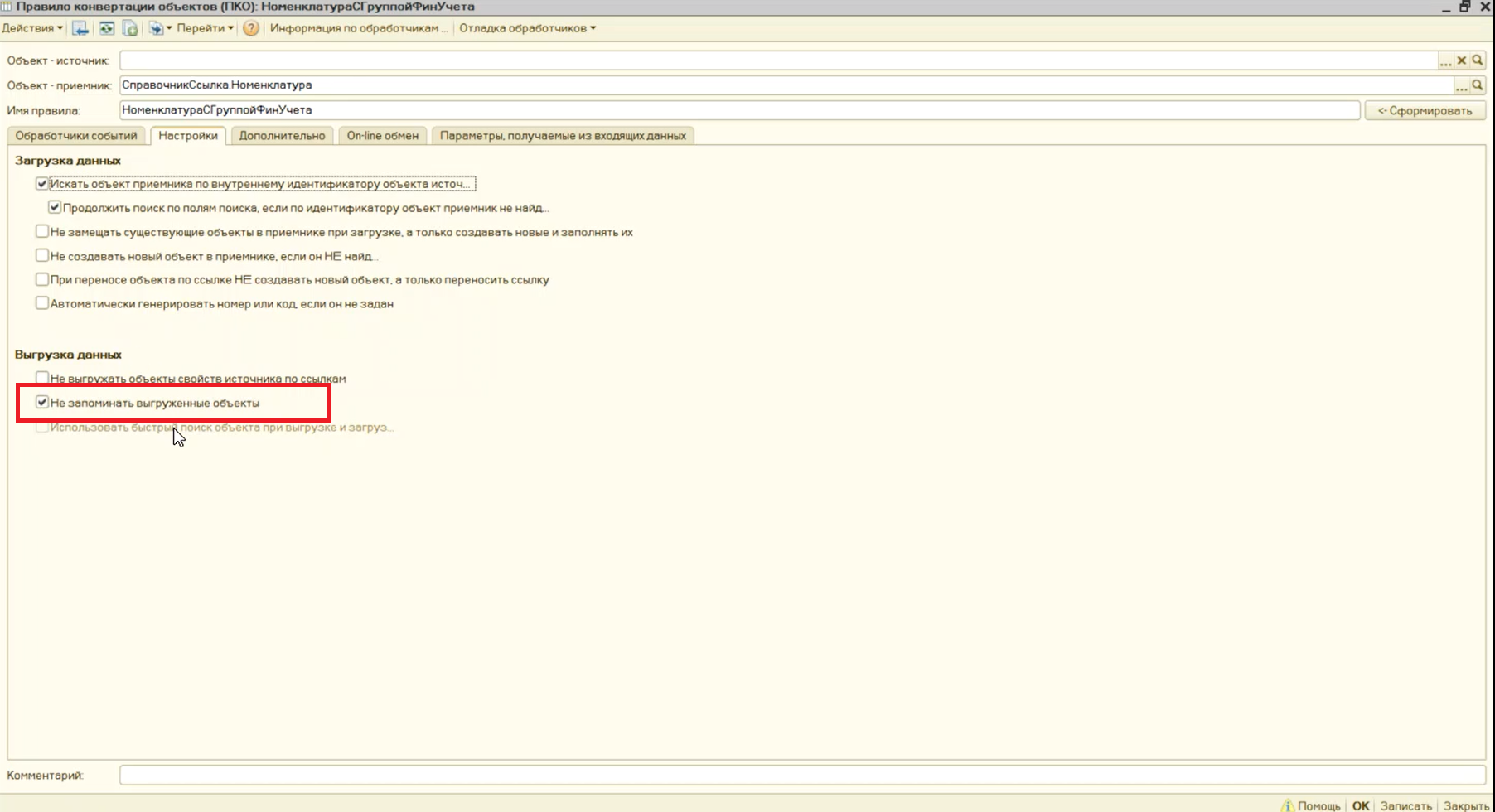
Поскольку на правило «НоменклатураСГруппойФинУчета» нет ни одной ссылки, мы отключаем для него кэш.
А в правиле «НоменклатураНеЗамещатьСвойства» мы:
- Во-первых, отключаем выгрузку свойств «по ссылке»;
- А во-вторых, используем обычный кэш (не принудительный). Разумеется, при этом мы должны будем помнить, что это будет таблица и какие-то миллионы записей все равно выгрузиться не смогут – кэш будет слишком большой.
Вы видите, что правило конвертации «НоменклатураСГруппойФинУчета» используется для выгрузки данных по справочнику «Номенклатура». Давайте посмотрим, как выглядит это правило выгрузки данных.
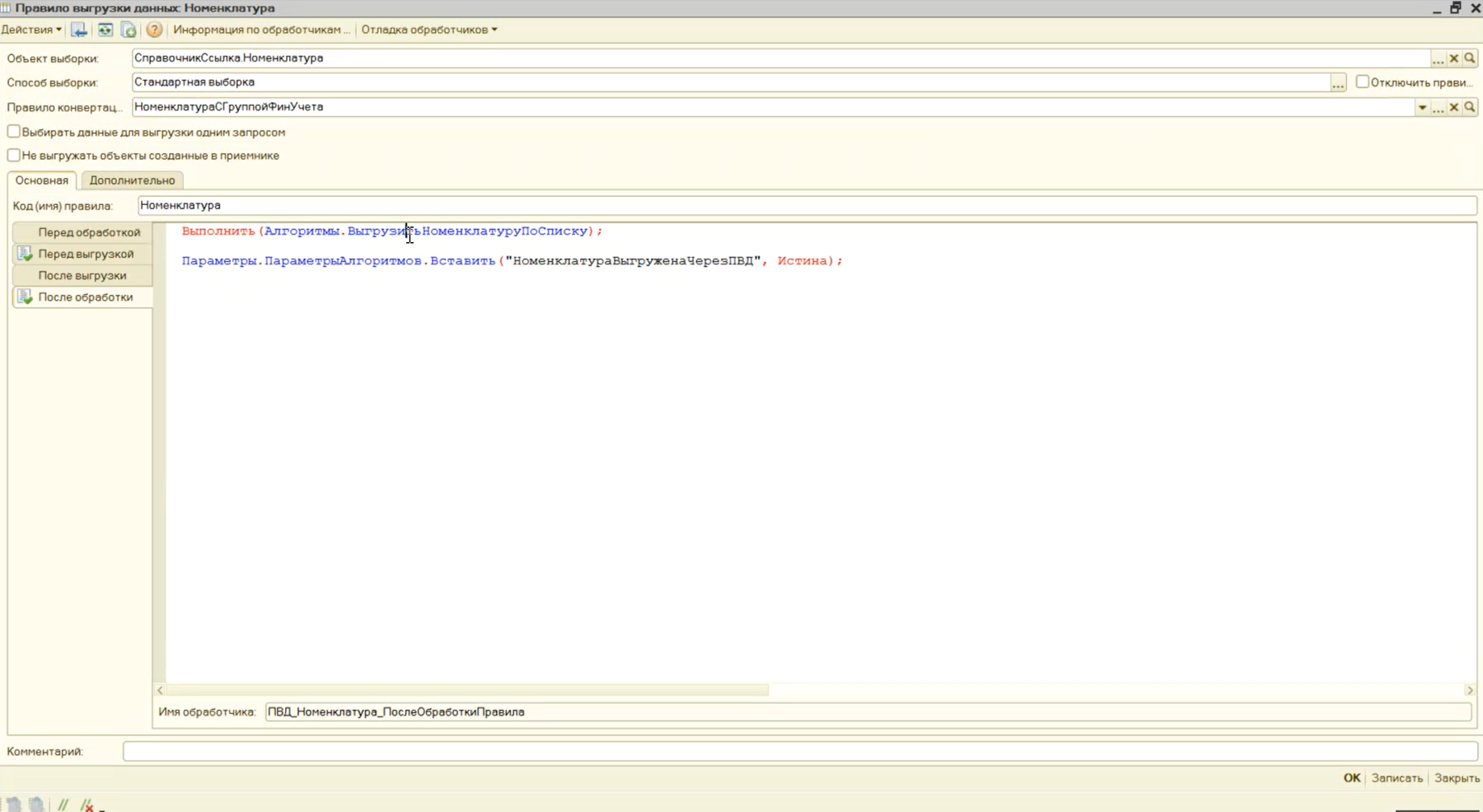
В его обработчике «После обработки» мы запускаем алгоритм «ВыгрузитьНоменклатуруПоСписку».
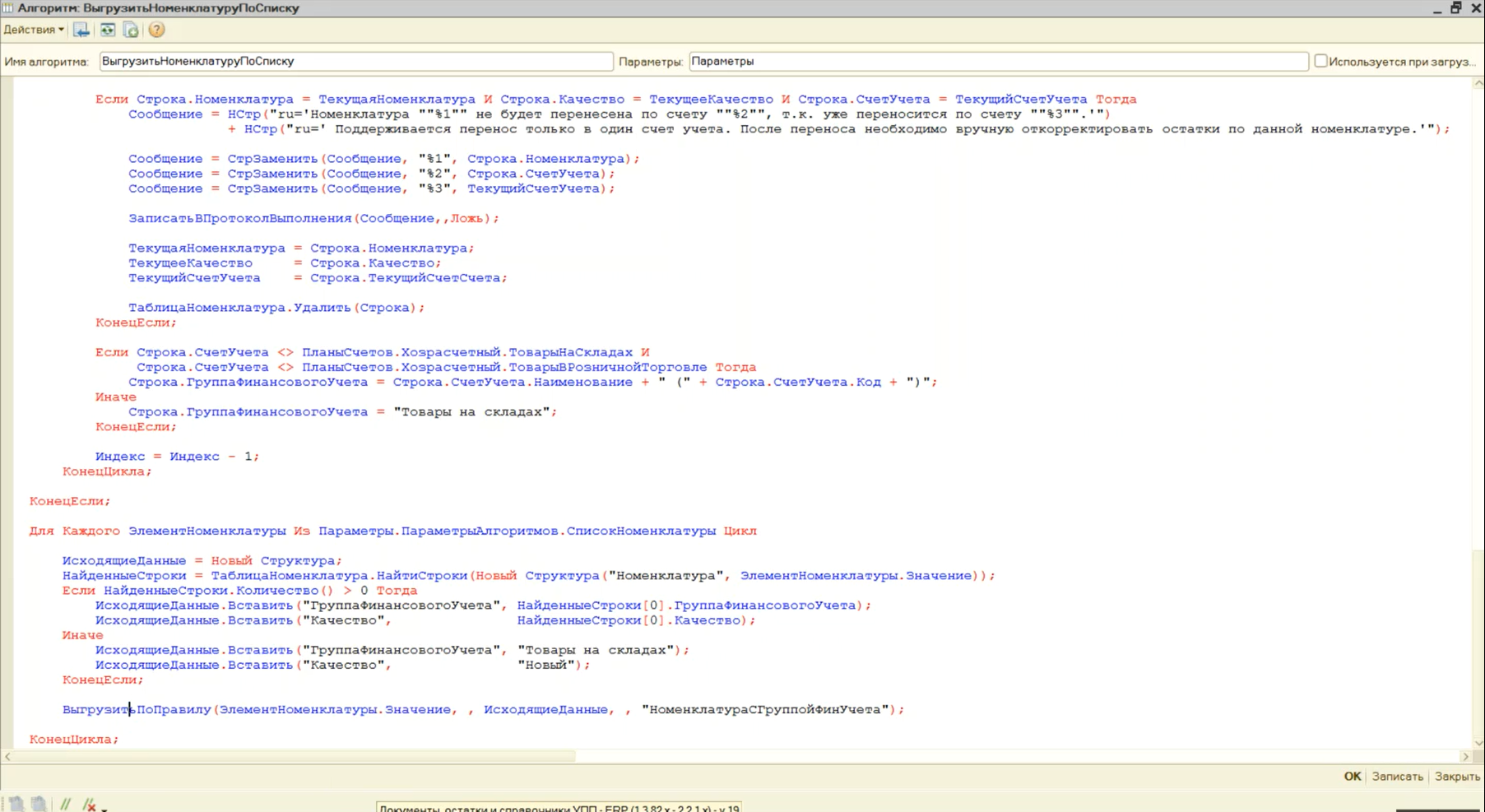
Вот как выглядит этот алгоритм. Здесь мы выгружаем объекты справочника со всеми свойствами в цикле по списку номенклатуры. Обратите внимание, где мы этот список заполняем.
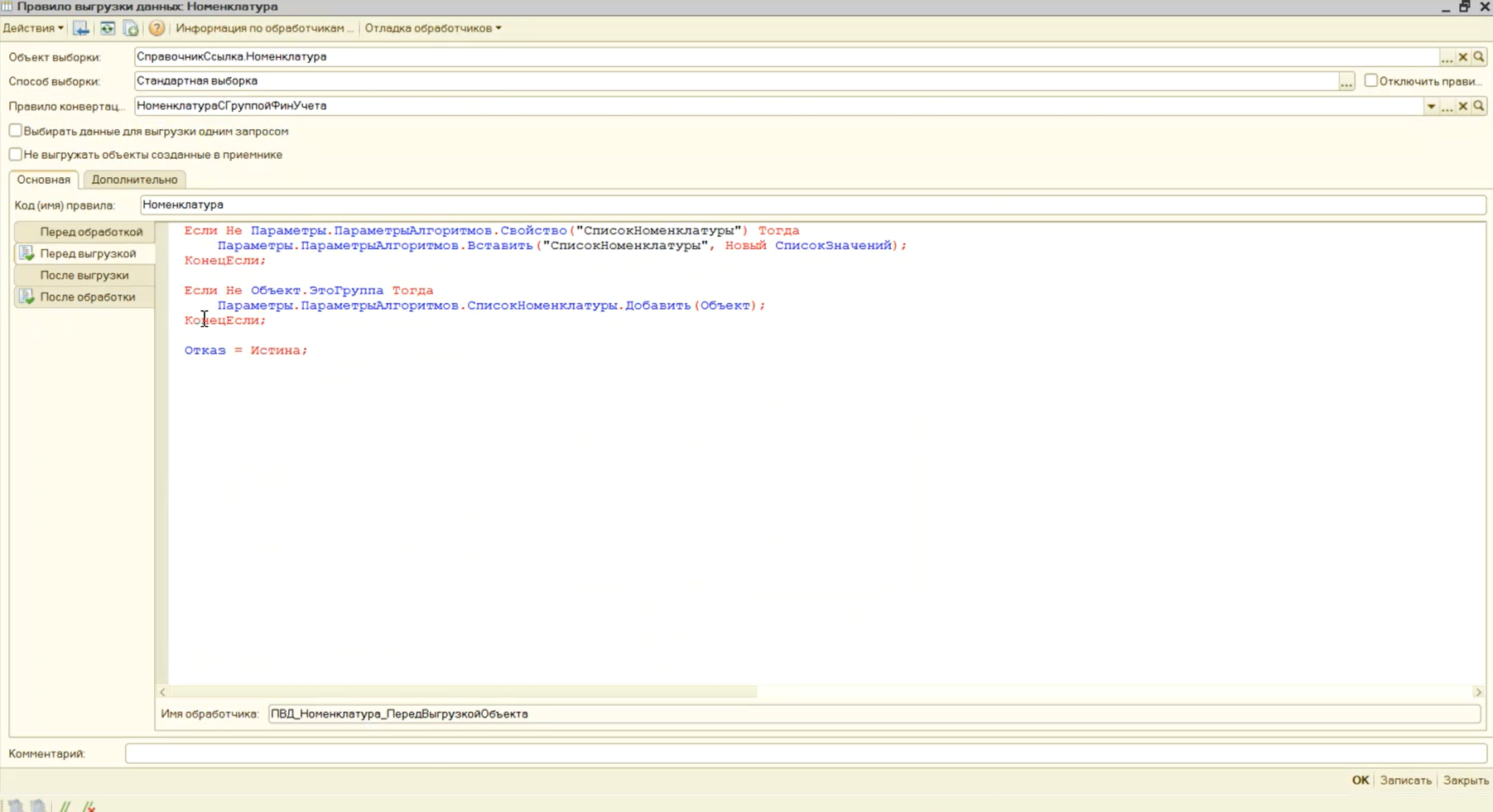
Параметр «СписокНоменклатуры» мы заполняем в обработчике «Перед выгрузкой» и сразу делаем Отказ – это значит, что, обрабатывая элементы справочника «Номенклатура», мы только заполняем список, а реально выгружаем все данные в обработчике «После обработки» (все вместе за один раз).
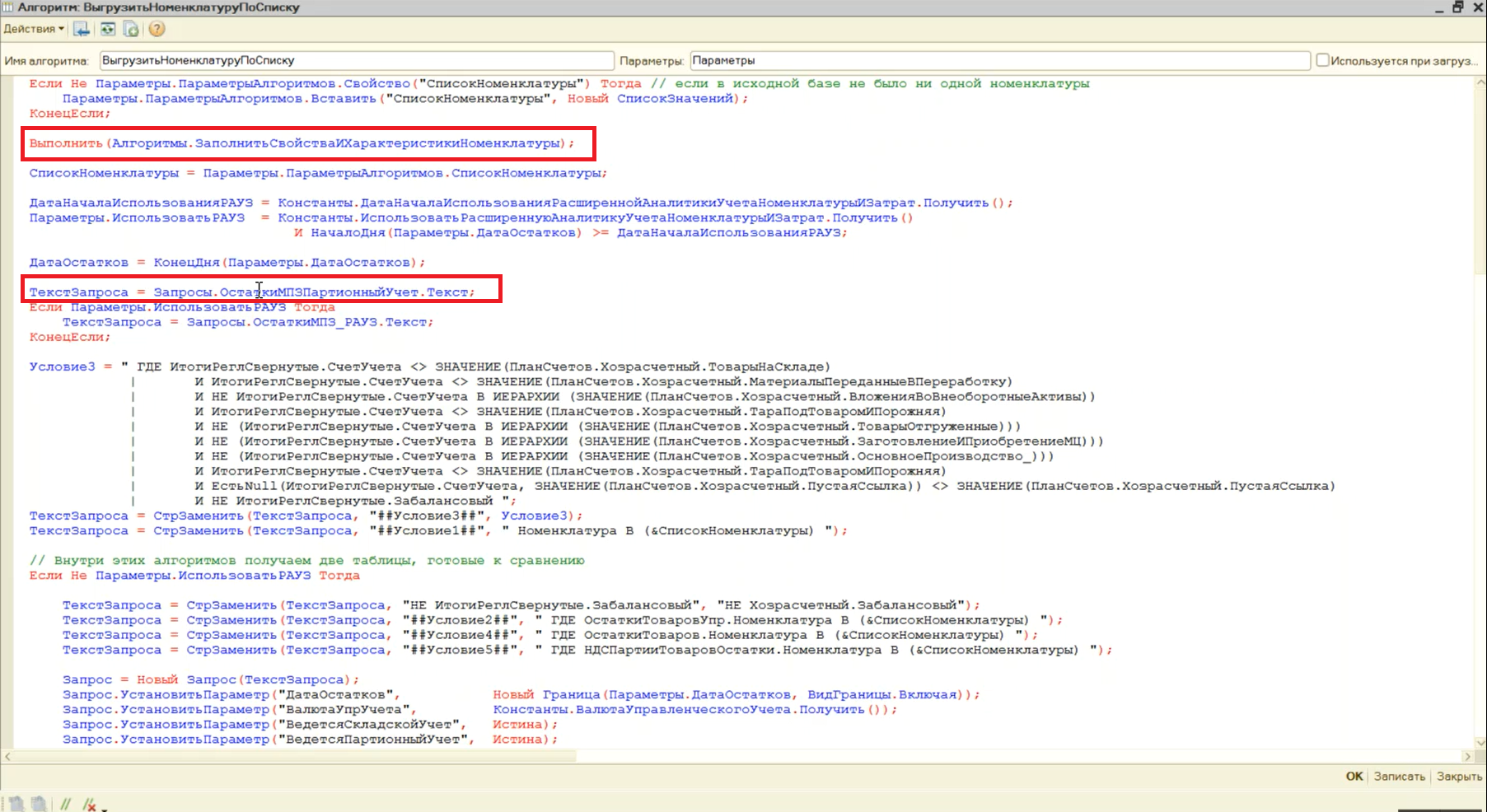
При этом мы также можем один раз выполнить запрос по заполнению свойств и характеристик номенклатуры. И один раз выполнить запрос к остаткам номенклатуры для заполнения группы финансового учета и качества номенклатуры.
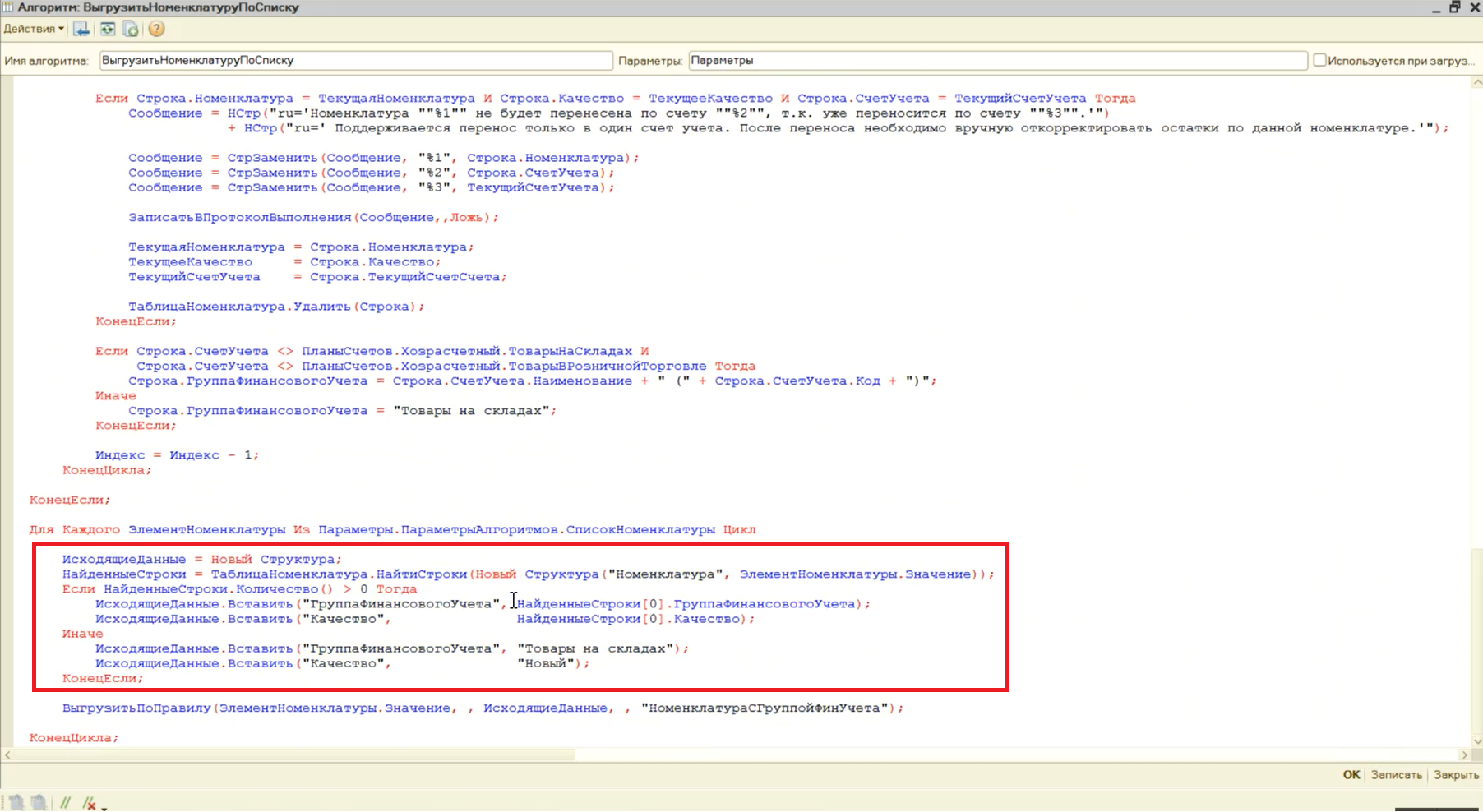
Свойства «ГруппаФинансовогоУчета» и «Качество» в ERP являются обязательными для заполнения. Таким образом, мы можем выполнить запрос один раз, а не выполнять его в цикле.
Итак, а что же будет, если пользователь возьмет и выключит правило выгрузки данных по справочнику «Номенклатура»?
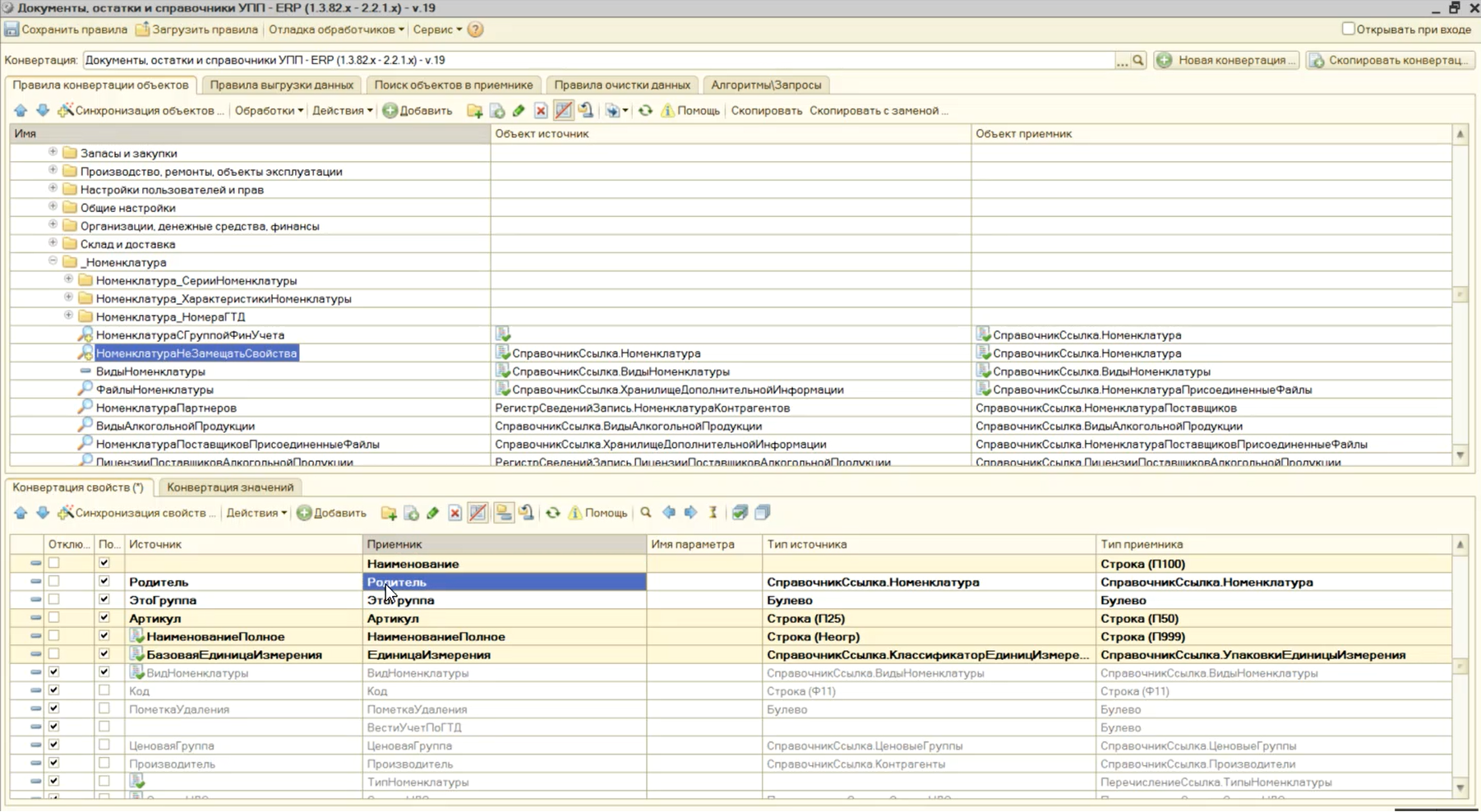
Мы помним, что по ссылке в правиле «НоменклатураНеЗамещатьСвойства» у нас указано всего шесть свойств. Мы что – получим информационную базу, в которой у номенклатуры заполнено всего шесть свойств? Это же будет некорректно, не устроит наших пользователей.
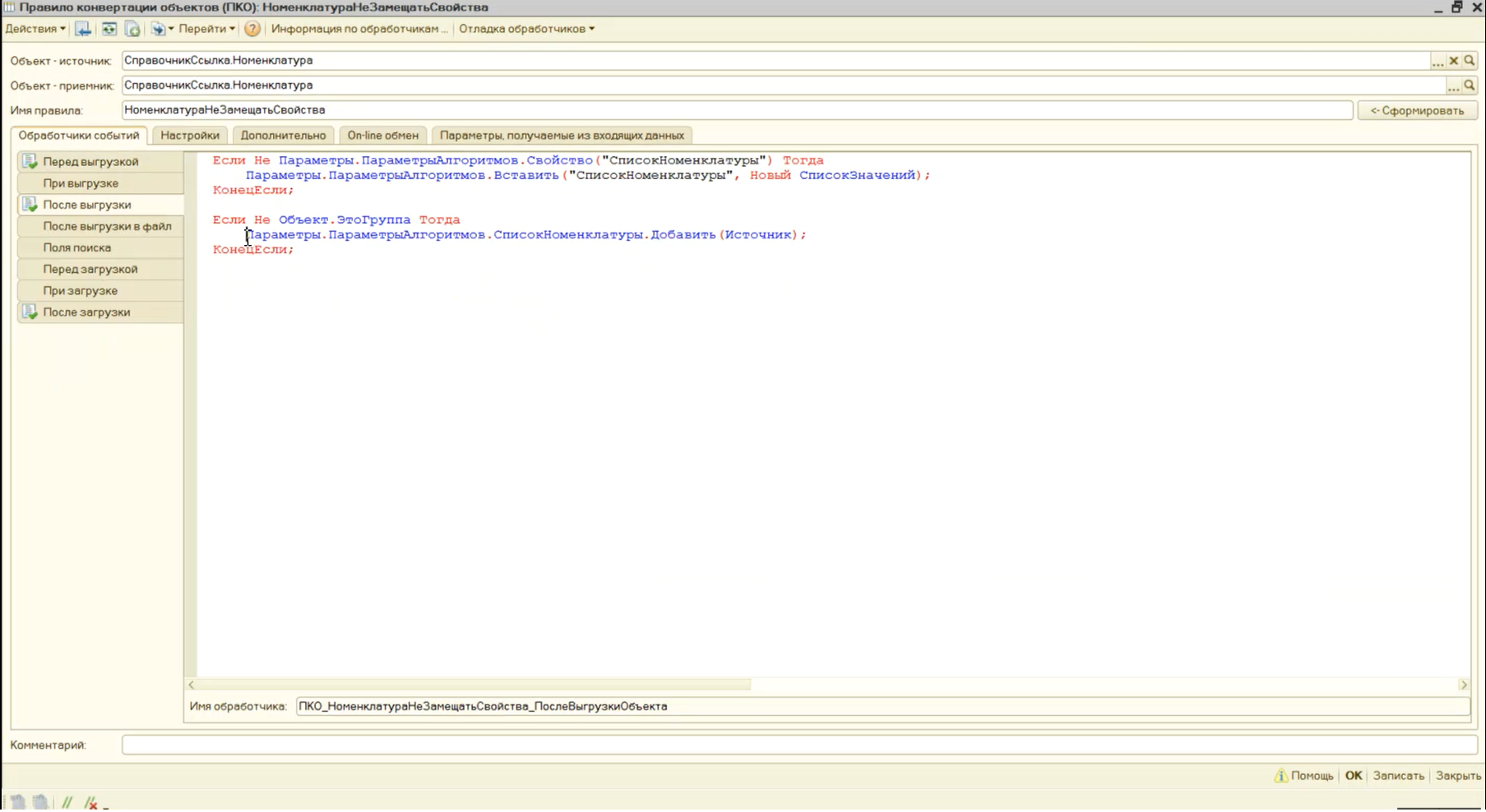
Нет, такого не будет, потому что в обработчике «После выгрузки» в правиле конвертации «НоменклатураНеЗамещатьСвойства» мы также заполняем список номенклатуры.
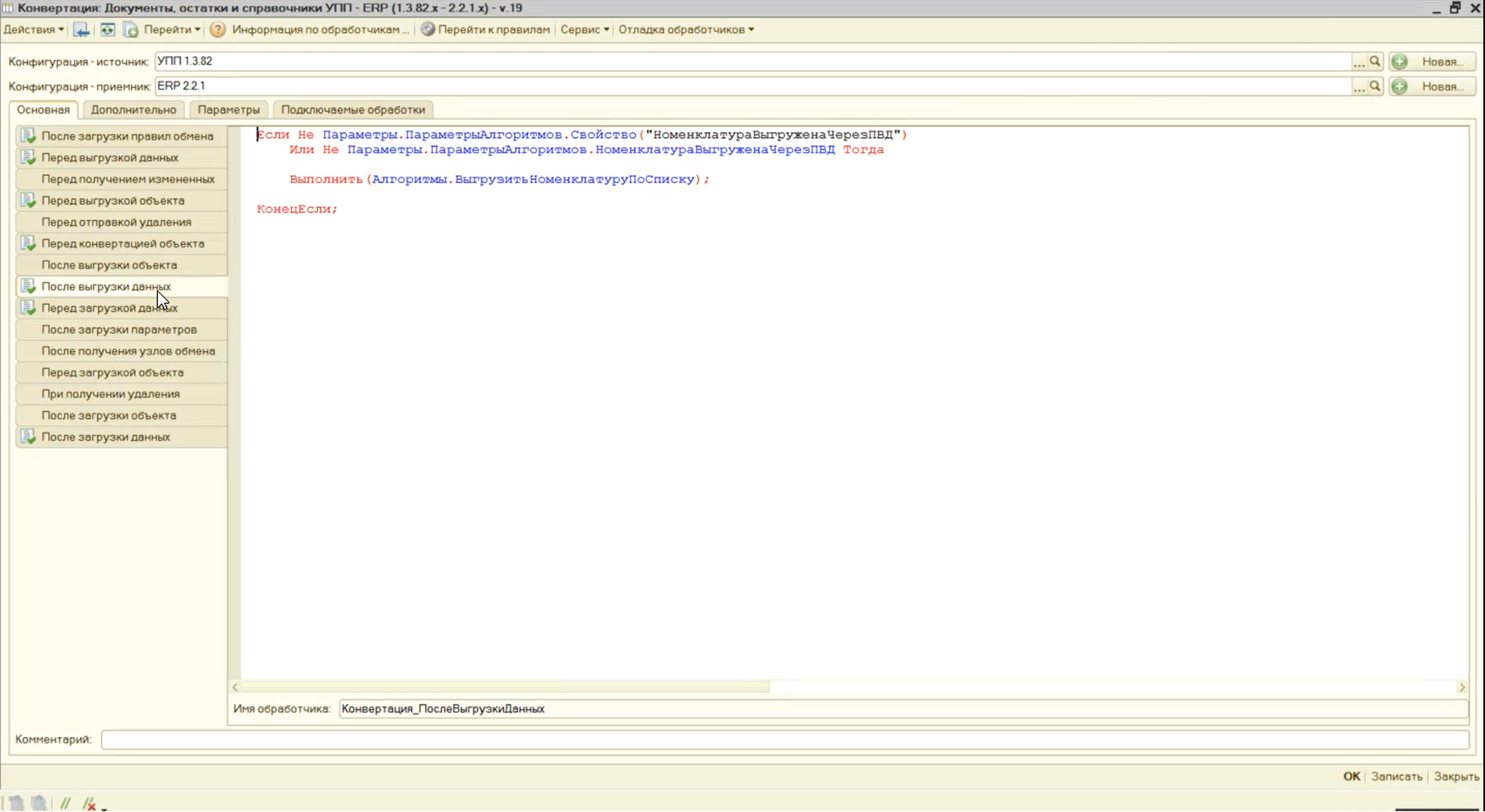
И уже в глобальном обработчике конвертации «После выгрузки данных» мы проверяем: если данные по номенклатуре с помощью правила выгрузки данных не выгружались, тогда мы запускаем тот же самый алгоритм «ВыгрузитьНоменклатуруПоСписку», где запрос выполняется один раз по свойствам и один раз к остаткам номенклатуры для определения ее группы финансового учета.
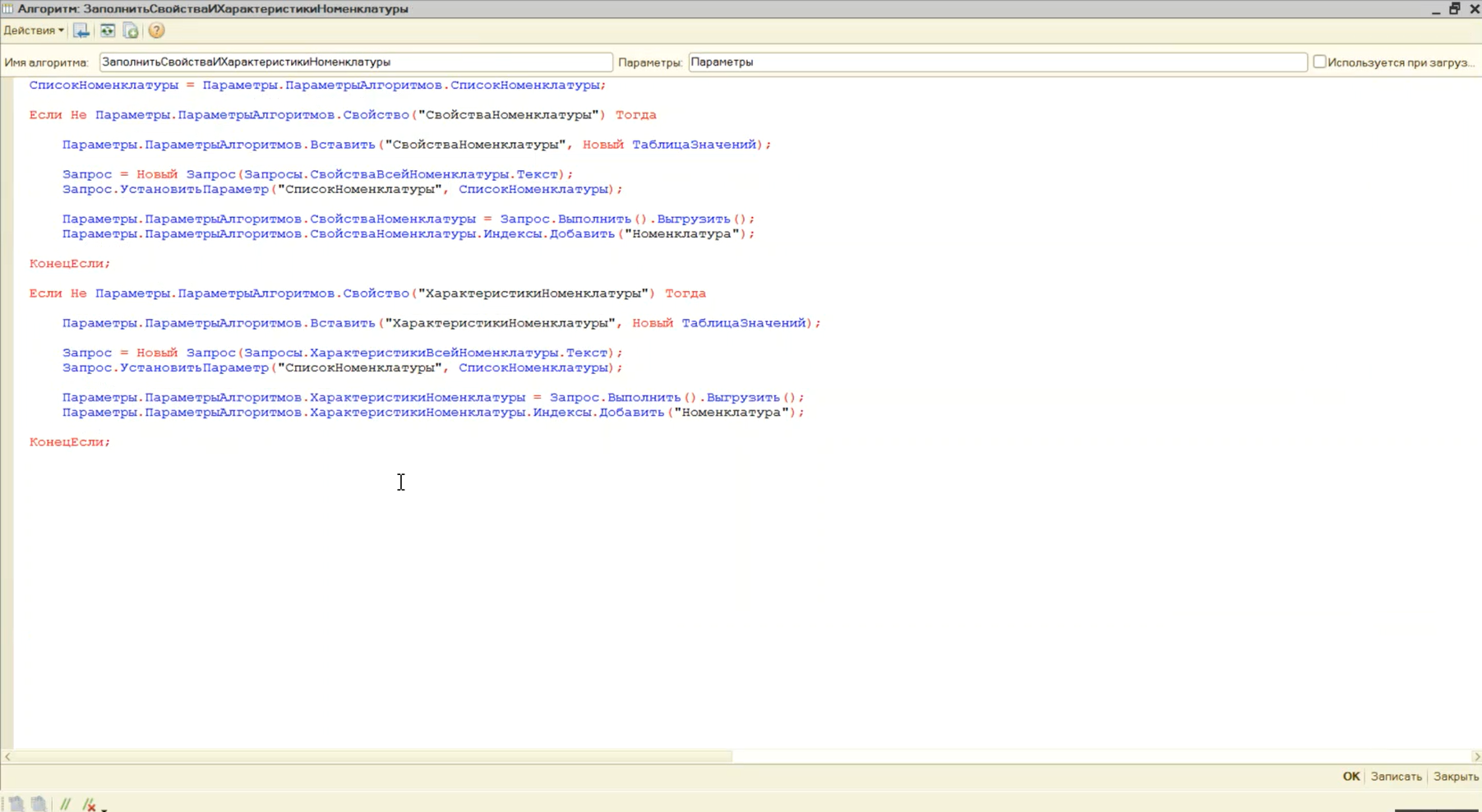
Мы с вами видели, что в алгоритме «ВыгрузитьНоменклатуруПоСписку» производится заполнение свойств и характеристик номенклатуры. Это две проиндексированные таблицы – таблица «СвойстваНоменклатуры» и таблица «ХарактеристикиНоменклатуры». А для чего я их вообще заполняю? Где они используются?
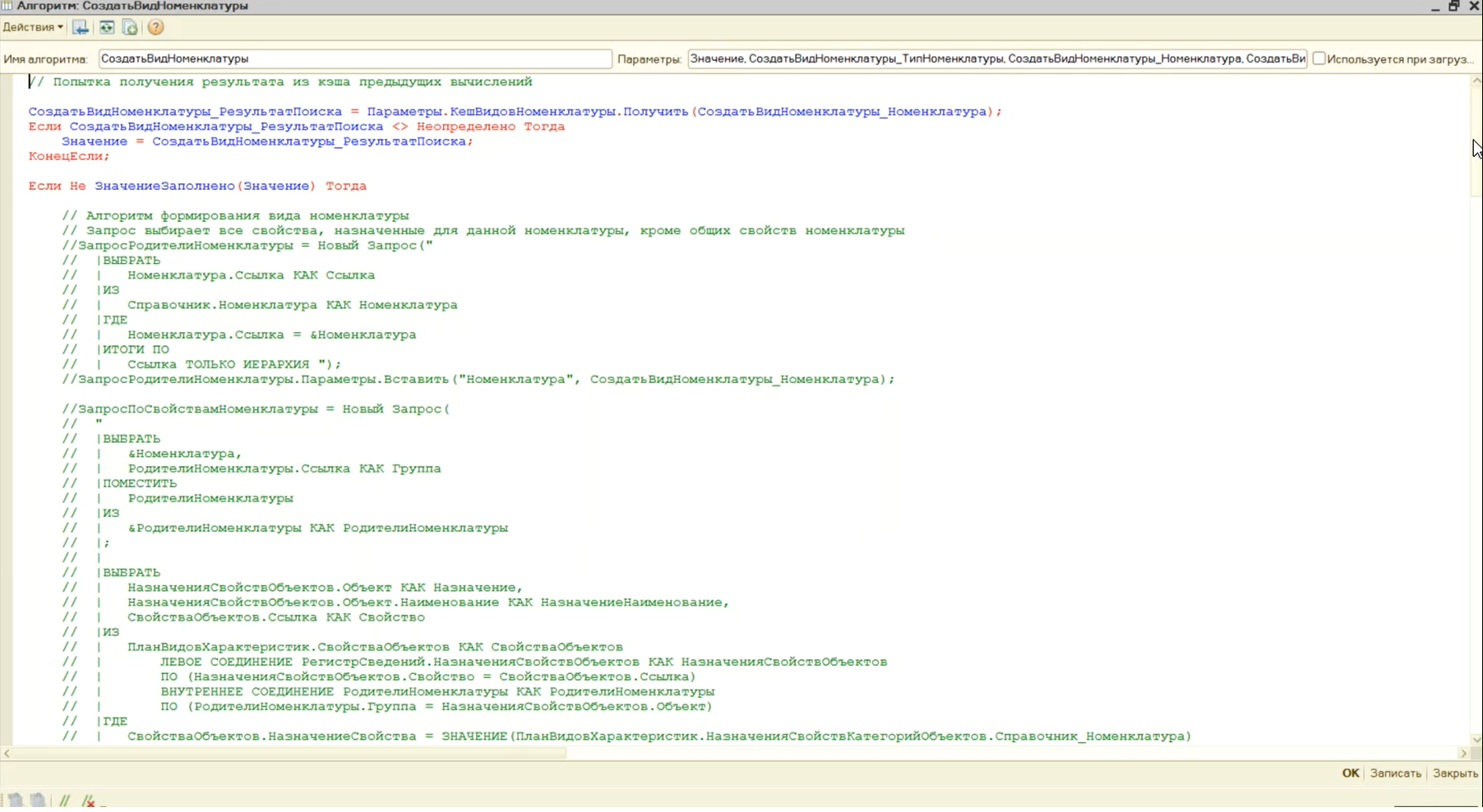
Они используются при переносе свойства «ВидНоменклатуры». Для этого в программе есть алгоритм «СоздатьВидНоменклатуры». То, что вы здесь видите сейчас – это типовой перенос с небольшими доработками. Весь закомментированный код – это запрос в цикле, который в типовом переносе будет выполняться для каждой позиции номенклатуры. А в нашем случае этот «запрос в цикле» вызываться не будет.
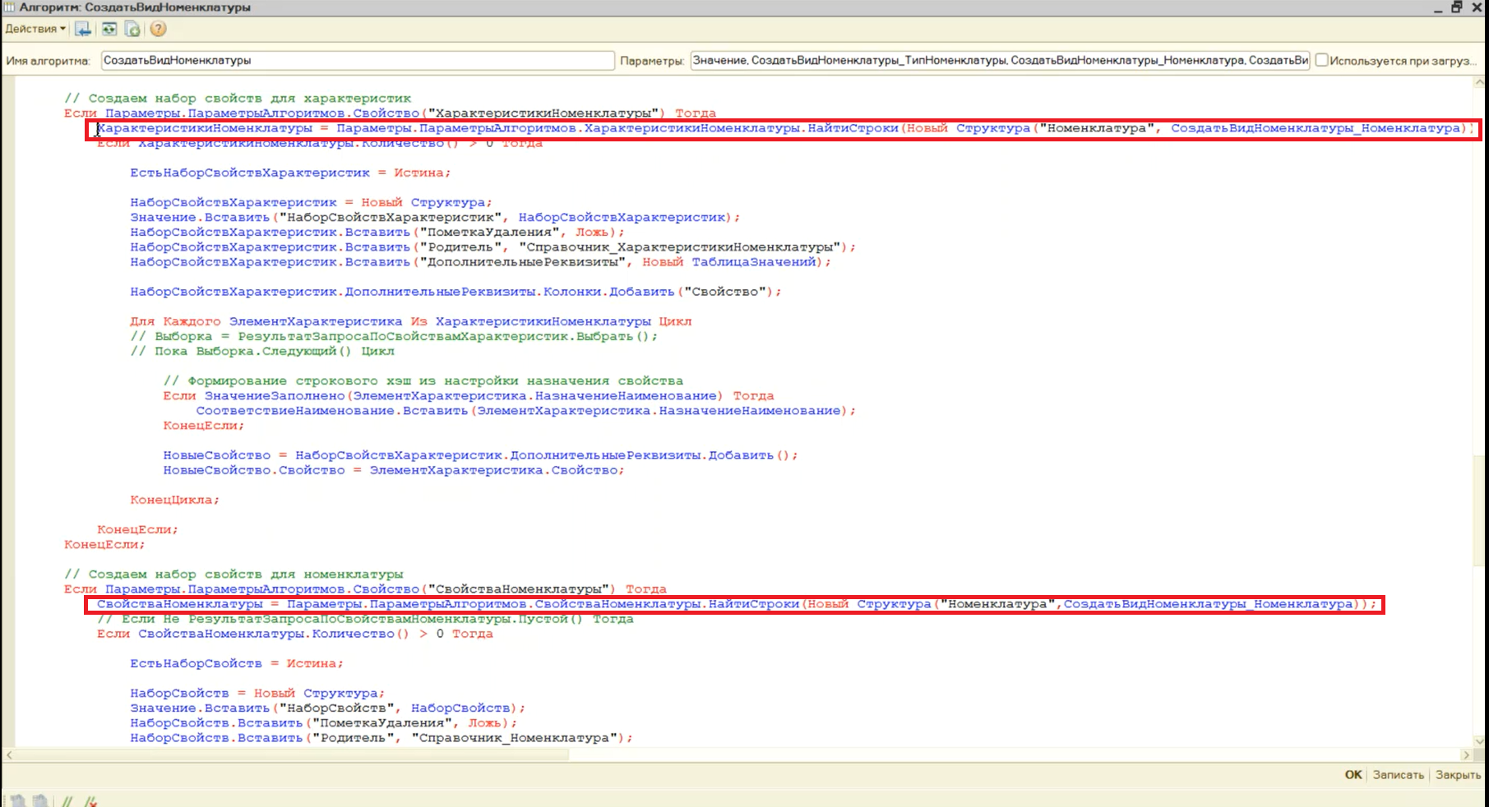
Мы переопределили поведение алгоритма «СоздатьВидНоменклатуры», и используем поиск в уже созданных проиндексированных таблицах значений, где у нас хранятся найденные свойства и характеристики всей номенклатуры. При этом запрос мы выполнили один раз (в алгоритме «ЗаполнитьСвойстваИХарактеристикиНоменклатуры»), а для каждой позиции уже просто подставляем найденные характеристики и свойства.
Чуть позже я вам покажу замер производительности, выполненный на типовом коде, не содержащем этой оптимизации – вы увидите, что выполнение этого этапа занимало почти 40% всего времени. Зато теперь каждый из вас, кто встретится с этой задачей, сможет этот этап оптимизировать и значительно ускорить свой перенос. Тем более что базы «Управление производственным предприятием» чаще всего имеют большой размер, а так вы сможете сильно сократить время на переход.
Собственный кэш в глобальных параметрах
КЭШ В ПАРАМЕТРАХ
Событие перед выгрузкой объекта справочника Номенклатура:

Рассмотрим подробнее еще один прием оптимизации – это собственный кэш в параметрах. Вы, наверное, уже успели заметить, что я активно этим пользуюсь.
Например, здесь мы один раз в глобальном обработчике конвертации «Перед выгрузкой данных» заполняем глобальный параметр ТабАлкогольнаяПродукцияНоменклатуры той номенклатурой, которая является алкогольной продукцией.
А далее уже в событии «Перед выгрузкой» самой номенклатуры просто ищем, является ли она алкоголем. И если является, то заполняем эти свойства.
Глобальные обработчики
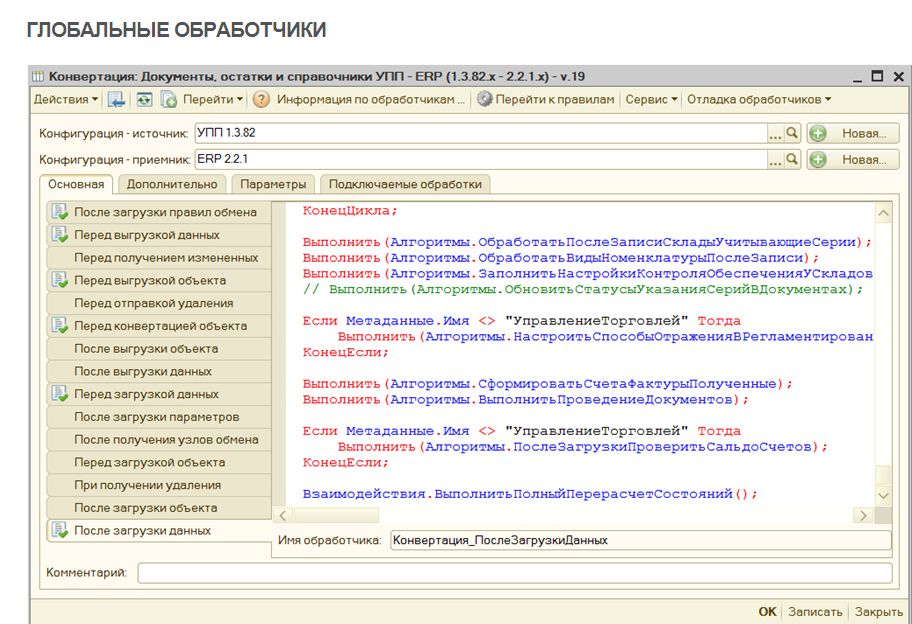
Грамотное использование глобальных обработчиков конвертации вообще очень важно. Например, здесь в глобальном обработчике «После загрузки данных» в программе-приемнике мы выполняем проведение загруженных документов. Это простое, но очень полезное действие, чтобы потом вручную после переноса их не перепроводить.
Сложности переносов данных. Классификация проблем
В своей работе я сталкивался с множеством сложных случаев переноса данных. Давайте рассмотрим, как я классифицирую такие случаи, а потом рассмотрим, какие для них есть способы решения.
- Во-первых, проблемы возникают из-за большого размера информационной базы. Когда нужно переносить сотни гигабайт, то, скорее всего, с этим могут возникнуть сложности – за один заход у вас ничего не получится.
- Во-вторых, в конфигурации могут быть некорректные пользовательские доработки, которые касаются непредоставления прав к объектам, ошибок чтения данных и пр. Или просто в базе могут быть некорректные данные – то, о чем мы уже говорили.
- В-третьих, вы можете столкнуться с недостаточной производительностью оборудования. Если у вас сама база открывается пять минут, и при этом она еще и имеет большой размер – проблемы при переносе у вас возникнут точно, и вам придется что-то делать с оборудованием.
Сложности переносов данных. Разделение на части большого объема данных для переноса
А теперь по порядку о том, какие способы исправления таких ситуаций я могу предложить, чтобы вы могли успешно решить свои задачи:
- Во-первых, вы можете выключать выгрузку свойств объектов «по ссылке» и выгружать эти объекты отдельным правилом выгрузки данных.
- Также популярной техникой является разделение всего переноса на этапы.
- Сначала мы выгружаем параметры учета;
- Далее – нормативно-справочную информацию (всю или частями). Иногда номенклатуру выгружают отдельно, как вы знаете;
- Потом переносим остатки на дату начала ведения учета;
- И далее – документы частями по полгода-год. Вот такие этапы мы можем рассмотреть.
- Есть еще одна методика. Она используется в типовом переходе с редакции ЗУП 2.5 на ЗУП 3.0. Если вы посмотрите код, то увидите, что она заключается в том, что каждая группа правил выгрузки данных выгружается по очереди в отдельный файл, а потом этот файл уже загружается в программу-приемник – также по очереди. Разумеется, если вы воспользуетесь такой техникой, вам придется особым образом свои правила оптимизировать, чтобы практически все правила конвертации, которые указаны «по ссылке», выгружали минимум данных. Так вы быстрее выполните свою задачу.

Рассмотрим кейс, где в справочнике «Номенклатура» было условно 100 миллионов позиций. Выполнить переход никак не получалось – один только запрос к остаткам номенклатуры выполнялся 30 минут. Что было исправлено?
- Изначально в правиле выгрузки номенклатуры стояла произвольная выборка. Я заменил ее стандартной выборкой. Благодаря этому в универсальной обработке обмена появляется возможность отбора, например, по группам номенклатуры.
- Также была отключена выгрузка свойств «по ссылке»
- И была проведена оптимизация выгрузки дополнительных свойств, которую мы рассмотрели ранее.
Сложности переносов данных. Некорректные пользовательские доработки
Следующий кейс – это программа Комплексная автоматизация. Ей было много лет, в ней много доработок, поэтому мне, чтобы решить проблему переноса данных, пришлось выполнить все способы оптимизации по очереди. Давайте рассмотрим, что я выполнял:
- Так как стояла задача перехода на типовую конфигурацию «Комплексная автоматизация 2.0», я, во-первых, обновил исходную программу до типовой.
- Потом обработал базу средствами СУБД – выполнил сжатие таблиц и пересчет статистик.
- Очистил ненужные для задачи перехода таблицы (такие, как «Версии объектов»).
- Ну и выполнил оптимизацию правил конвертации по выгрузке дополнительных свойств номенклатуры, про которую я говорил ранее.
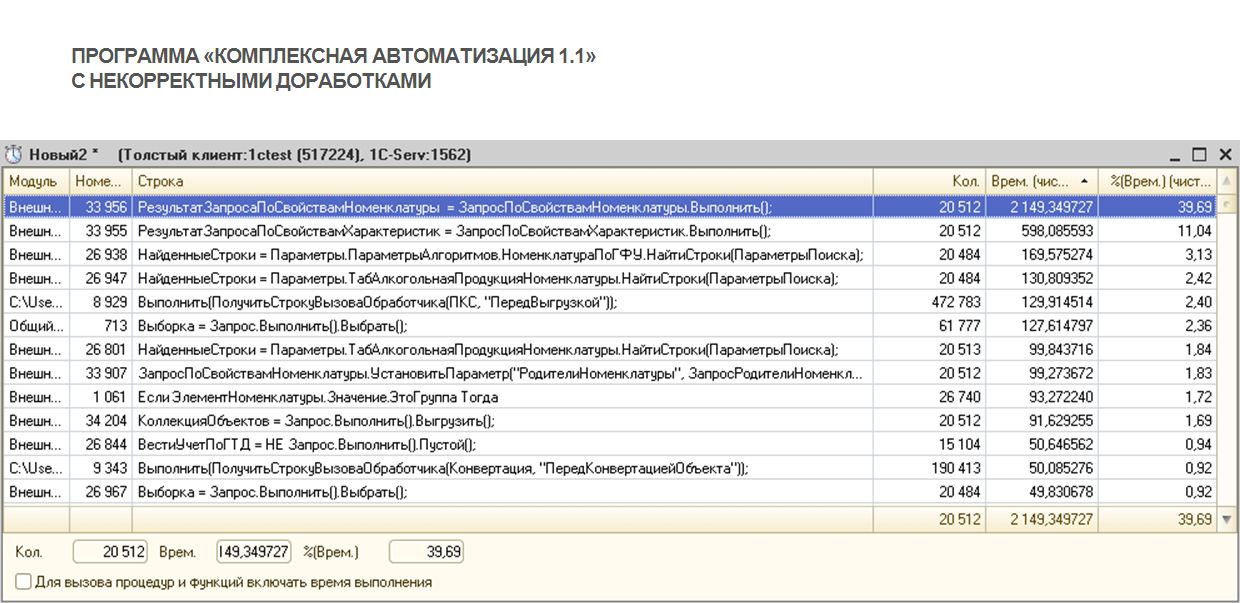
Обратите внимание, это – реальный замер производительности для двух часов (малой части всего перехода). На этом скриншоте вы видите, сколько времени реально занимает «запрос в цикле» к дополнительным свойствам номенклатуры (тот, который вы видели в примере ранее, где он был закомментирован в алгоритме «СоздатьВидНоменклатуры»). Кто откроет типовые правила конвертации этого перехода, увидит эти правила у себя.
Сравнение технологий обмена Конвертация 2.1 и EnterpriseData
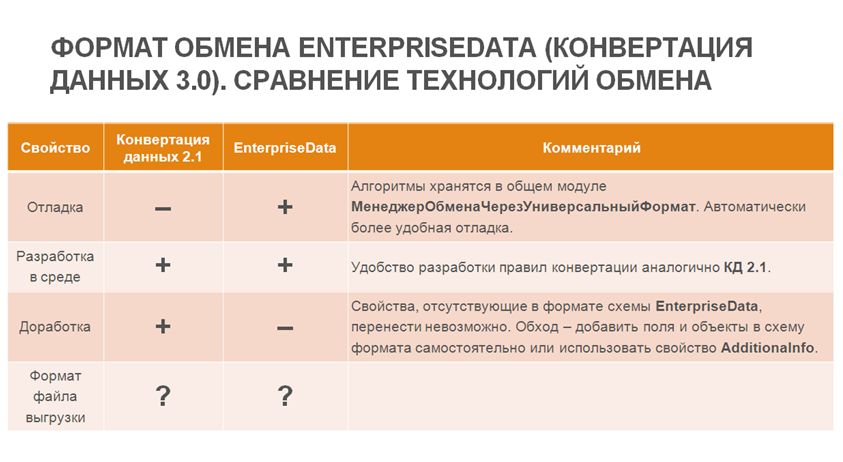
Давайте перейдем к сравнению технологий обмена «Конвертации данных» второй и третьей редакции. Третья редакция вышла уже в прошлом году, тогда на эту технологию перевели обмен «Бухгалтерии предприятия» и «Управление торговлей».
- Первый аспект – это удобство отладки.
- Как вы знаете, в «Конвертации данных» третьей редакции с использованием формата EnterpriseData все обработчики хранятся в общем модуле «МенеджерОбменаЧерезУниверсальныйФормат». Соответственно, вы автоматически получаете удобную отладку – любая ошибка тут же выведет вас к нужной строке.
- Как вы знаете, в старой редакции «Конвертации данных» 2.1 с этим были сложности.
- Что мы можем сказать про разработку новых правил конвертации? На мой взгляд, и «Конвертация данных» второй редакции, и «Конвертация данных» третьей редакции одинаково удобны в работе – создание правил конвертации производится почти по одним и тем же принципам. Ставим каждой из технологий плюс.
- Что насчет доработки правил конвертации?
- Если программа у нас не типовая, и нам нужно переносить какие-то свои дополнительные свойства – у новой технологии с этим сложности. Дело в том, что вы можете переносить только те свойства, которые есть в схеме данных. Поэтому вам либо придется эту схему данных редактировать в каждой из программ, участвующих в переносе, либо использовать AdditionalInfo – это дополнительное свойство строкового типа, в которое вы можете помещать свои переменные и при приеме информации их считывать.
- На мой взгляд, для обмена под нетиповые конфигурации значительно удобнее использовать «Конвертацию данных» старой редакции.
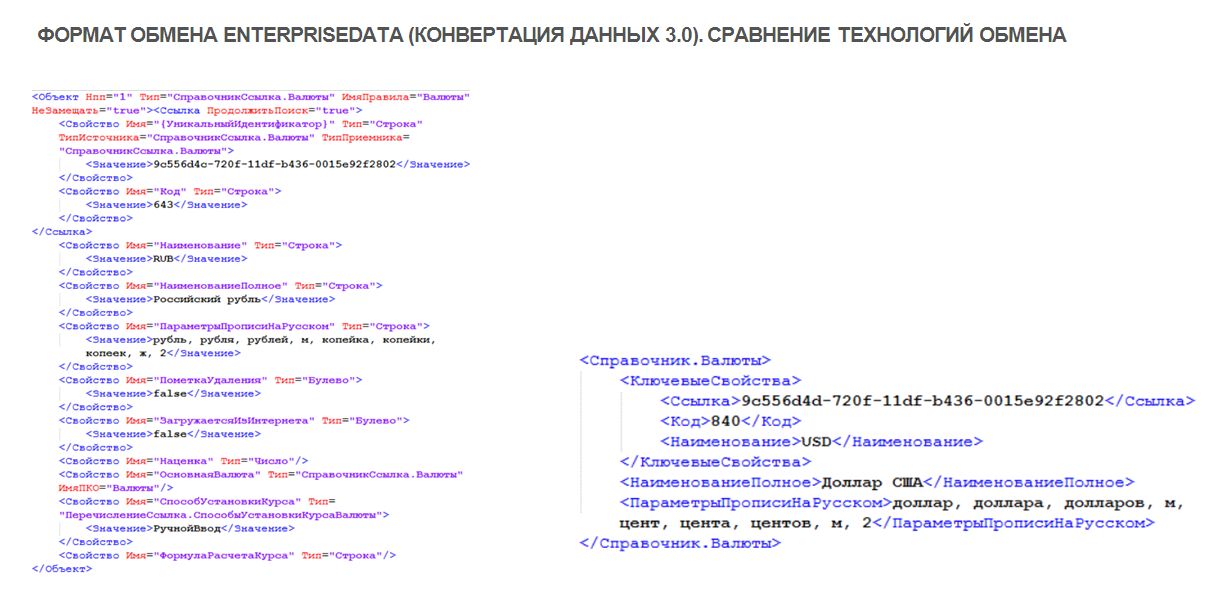
- Что насчет формата хранения данных у «Конвертации данных» второй редакции и «Конвертации данных» третьей редакции? Давайте посмотрим, как он выглядит. Слева выгрузка формата второй редакции, справа EnterpriseData. И в том и в другом случае выгружена одна валюта. Мы видим, что запись стала значительно компактнее, но в целом, это тот же самый файл xml со всеми своими минусами – когда вы будете загружать в него двоичные данные, вы столкнетесь с проблемами производительности.
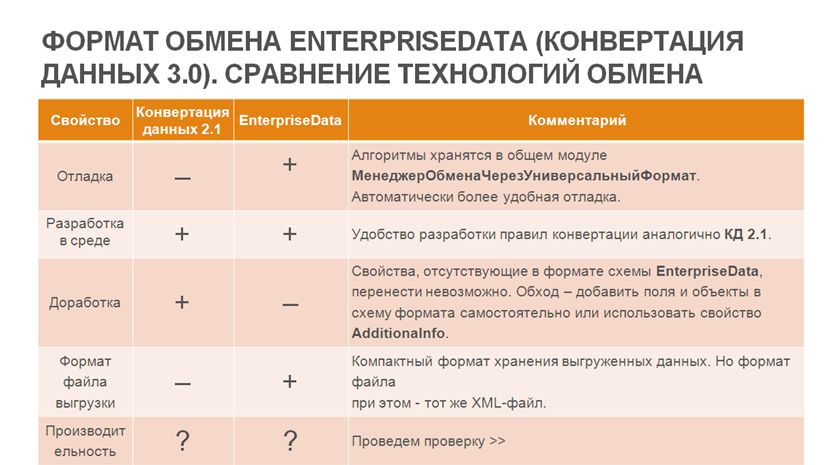
Однако за более сжатый формат мы можем поставить плюс для «Конвертации данных 3.0».

- Что насчет производительности? Давайте проведем проверку. Я создал две демонстрационные базы «Управление торговлей» разных релизов. Я понимаю, что это разные программы, но и технологии разные, поэтому для целей нашего сравнения можно их использовать. И попробовал обменяться данными с «Бухгалтерией предприятия» одного и того же релиза. Создал документы «Реализация», в каждом по 100 строк товаров. И запустил по три разных переноса (в первом – 10 объектов, во втором – 200 объектов, а в третьем – 1000 объектов). Вот такие замеры у меня получились.

Если мы будем считать, что время на перенос подчиняется линейному закону, то согласно предыдущему замеру получим примерно такие константы, где:
- Постоянная часть C – это время на установление соединения, на прием сообщений от «Бухгалтерии» (допустим, пустого сообщения)
- А время К – это количество секунд на обработку одного такого документа реализации.
В результате, в моем случае на моем оборудовании универсальный формат обмена работает на 15% быстрее.
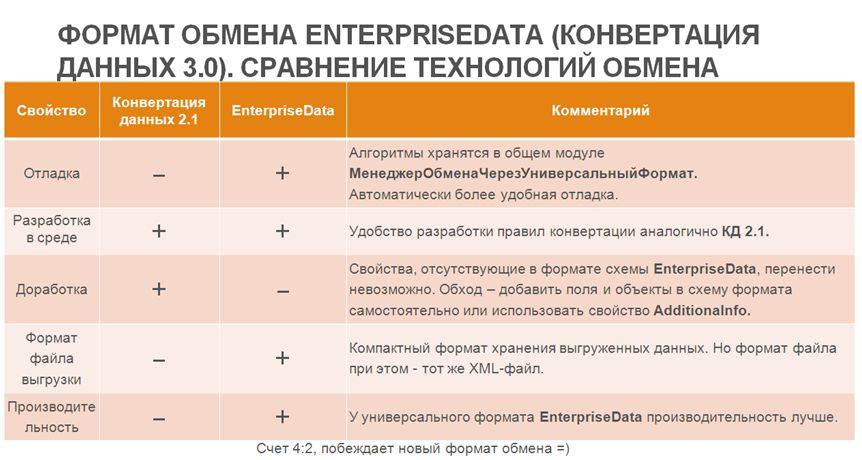
Это не очень много, но ставим ему плюс.
Соответственно, новая технология «Конвертация данных 3.0» у нас побеждает со счетом 4:2. Будем ей пользоваться – фирма 1С работает над развитием.
Чего не хватает технологии Конвертация данных 3.0?
Давайте я коротко опишу те недостатки, которые до сих пор есть в технологии Конвертация данных 3.0:
- В первую очередь, это – производительность. Все-таки, при переносе больших информационных баз эти проблемы все равно возникают и некоторые пользователи скажут, что прямые запросы в СУБД позволят выполнить переход значительно быстрее.
- Также это – отсутствие многопоточности.
- Гарантия доставки сообщений. Если вы целые сутки выполняете выгрузку данных, и она прервется, вам придется все начинать с нуля.
- Отсутствие встроенной проверки. Да, у вас при обмене от «Бухгалтерии» приходит информация о том, что такой-то номер сообщения на той стороне принят. Но нет сверки данных. Вы не знаете, какие документы не провелись, какие некорректно загрузились. Да, у вас есть список конфликтов и ошибок, но этого недостаточно. Сверки с исходной базой у вас нет.
Пользователям недостаточно тех возможностей, которые есть в текущей технологии. Поэтому многие компании разрабатывают свои шины обмена, и одним из таких продуктов является 2is:Интеграция, которая большинство описанных здесь проблем решает. Кроме того, она сейчас имеет и поддержку нового формата обмена EnterpriseData.
Заключение. Выводы
На мой взгляд, «Конвертация данных» второй редакции – это до сих пор актуальный инструмент с огромными возможностями, который имеет большое количество способов оптимизации проведения и переноса и позволяет выполнить огромное количество различных задач при его хорошем знании. Мы будем продолжать его использовать наряду с новой технологией от фирмы 1С – EnterpriseData.
Бонусы
Специально для конференции я выложил две небольших упрощающих инструмента для проведения и переноса.
- Первый – это сверка документов после переноса через COM-соединение с поиском по любым реквизитам. Он универсальный, вы можете в нем сравнить свойства справочника «Контрагент» со свойствами справочника «Партнер».
- Второй инструмент – это доработка обработки «Универсальный обмен в формате XML», позволяющая выгружать информацию по этапам, по группам правил выгрузки, с такой же поэтапной загрузкой.
***************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 DEVELOPER. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Вроде в ИТС так и написано — КД 3.0 не заменяет КД 2.0 — это разные направления технологии обмена данными
Сейчас все типовые обмены работают через EnterpriseData ? Или где-то еще используется КД 2.1 ?
полезный обзор
(2) Где-то КД2 доступна как альтернатив и поддерживается, где-то все еще только КД2 — если память не изменяет, то УТ/РТ так работают.
Вот такой бы материал по EnterpriseData 🙂
После прочтения осталась каша в голове относительно методов оптимизации, событий, алгоритмов, кэша. Для начинающих знакомится с КД написано сложновато, т.к. остается ощущение недосказанности. За статью спасибо.
Главная проблема EnterpriseData не отмечена.
Один и тот же объект в РАЗНЫЕ конфигурации должен (пусть и не всегда) переноситься ПО-РАЗНОМУ.
А это в EnterpriseData невозможно в принципе.
Как пример, рассмотрите Виды номенклатуры: в БП 3 и КА 2 это совершенно разный «физический смысл».
Т.е. в самой идеологии ошибка: все что лежит в промежуточном файле, в стандарте EnterpriseData, должно быть одинаковым для всех. Алгоритмы выгрузки и загрузки у каждой конфигурации свои, а промежуточный результат — одинаковый. В этом была идея. В этом главное преимущество, которое на самом деле является главным недостатком.
Поймите главное: в момент выгрузки нужно знать ДЛЯ КОГО выгружаем и делать это по-разному, но не из-за различий в структуре информационных баз вовсе, а из-за различий в логике и методиках учета.
На чем основано это утверждение?
(5) По EnterpriseData есть статья «1С: Конвертация данных 3. Инструкции и примеры. EnterpriseData (универсальный формат обмена)».
Если автор статьи (ТС) посчитает нужным, добавит ссылку в статью или комментарии 😉
Порядок подготовки данных к обмену практически не зависит от способа переноса.
Нужно бы год указать — 2015-й, а то не все прочитают статью до конца 😉
(2) Используем только её. Большего не надо.
универсальный обмен, универсальный формат обмена, универсальная выгрузка-загрузка, универсальная обработка — зарапортуешься.
не пора ли уже использовать возможности русского языка и развести таки эти понятия (эту кашу)?