<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\




Достойные шаги в 1С по направлению использования нейросетей!
Дмитрий, никогда не было размышлений по поводу автоматического построения сети? Т.е. чтобы какой-то алгоритм (или даже специально построенная для этого отдельная сеть) сам рассчитывал количество нейронов, количество входов, количество выходов, тип сети и т.д.?
И еще вопрос… Почему при слишком большом количестве нейронов скрытого слоя сеть будет не «думать» а «зазубривать» возможные варианты? Ведь, по идее, наоборот — точность результата от этого будет выше, нет?
(1) Спасибо! Да есть саморганизующиеся сети (другой совсем тип) и то что Вы написали тоже есть по отношению к многослойным перцептронам. Причем тоже еще в 60х такие работы делались. Сам я тоже занимаюсь самоорагнизующимися сетями с собственной теорией только в другой области (изображения). Для 1Ски я специально такую простую сеть написал чтобы людей не пугать сразу, а чтобы потихоньку с малого начали использовать сети, разбираться. Кто-то дальше пойдет, кому то этого будет достаточно. Такая задумка.
По поводу «зазубривания» как бы не казалось противоположное, но это именно так. Об этом пишут исследователи и самому можно убедиться. Причем я в сове время натыкался на интересную книжку где автор приводит параллели с человеческим обучением (у нейросетей вообще очень много общего с реальным мозгом) и он пишет что типа когда человек чего то не понимает допустим в математике и ему лень разбираться он просто запоминает все возможные варианты т.е. зазубривает. Если дать много нейронов то отдельные сочетания входов просто поставят нужные веса чтобы выходы повторяли входы по отдельному нейрону на каждое сочетание и все. А вот добавить еще скрытых слоев — в это смыл может быть.
(2)
Это тоже в 1С?
Дмитрий, а есть размышления по использованию нейросетей в области конвертации данных? Например, предоставить УПП и ERP для переноса данных с первой конфигурации во вторую. И организовать сеть таким образом, чтобы перенести по максимуму все данные. Вообще, возможно ли такое организовать на сетях?
И еще… Как лучше организовать отдельный модуль по организации сети в 1С? Чтобы можно было внедрить такой «модуль» в любую конфигурацию, а потом вызывать его штатными средствами, например, в тех же отчетах. Организовать для этого какой-то определенный интерфейс, может привязать его к какому-нибудь уже существующему «стандарту» если таковы есть. Есть размышления?
Конечно, есть тот же ТерзорФлоу, почему бы его не использовать отдельной библиотекой. Но соглашусь с Вами, что лучше бы использовать средства 1С, т.к. это дает определенную прозрачность.
Хорошо подана информация. интересно читать было. в свое время сталкивался с этим. но дальше чтения не пошло. но думаю так что через несколько лет придется занимать вплотную этим..бизнес ростет.
(3) Да не, изображения то она не тянет нормально. Хотя у меня есть публикация just for fun что называется . Но пронозирование тянет в самый раз, поэтому я большие надежды на эту технологию возлагаю. Странно что в 1С это по дефолту нет. В САПе Хана есть например.
Насчет конвертации интересный и сложный вопрос. Если допустим использовать сеть для того чтобы искать похожие данные по смыслу (по месту использования, каким то свойствам) то да для этого они подойдут. Но тут думать надо.
Так обработка и есть такой модуль . Все процедуры с сетью в модуле обработки. Можно даже ее добавить в конфу и вызывать через объект обработки. Можно в модуль засунуть, да. Все равно обучение через какой то интерфейс надо проводить… А саму сеть решать( прогнозировать) можно просто метод вызывать или функцию как обертку сделать. Там много вариантов. Например я для понятности сделал хранение сетей ф файлах, а реально сейчас например храню в доп. реквизитах контрагентов на одном из решений.
(4) Спасибо! Тут как раз материал нацелен на то чтобы пощупать руками, поэкспериментировать
Бизнес не любит нейросети в учёте. Пока интерпретации чёткой не будет.
А в 1С есть типовые методы. Чем они лучше/хуже?
Чем нейросети лучше той же интерполяции? В обработке изображений это понятно, они давно себя зарекомендовали…
А на достаточно простых финансовых данных зачем эти навороты?
Но за реализацию однозначно ++++
(8)
Я думаю это для примера, с чего то надо начинать, с тем же прогнозированием справляется статистика, ну а дальше сложнее.
Статья очень интересная, однозначно +.
(7) А РАУЗ бизнес любит? Для нейросети не будет четкой интерпретации. Но есть ряд задач, для которых другие алгоритмы не работают (или дают результат существенно хуже).
(9) Статистика хорошо справляется только там, где есть аналитическая функция хорошо «ложащаяся» на набор данных. В случае набора данных для которого функции нет обученная нейросеть справится значительно лучше.
(8) Интерполяция?… Ну допустим у меня если я сегодня скидку сделаю в 2 раза больше то у меня выручка будет в 2 раза больше? А если в 3раза? Статистикой можно посмотреть допустим сколько товара продавалось при такой же скидке или при другой скидке и сделать линейную (или например квадратичную) экстраполяцию/интреполяцию. Но проблема в том что по статистике сложно вывести зависимость даже от одно фактора если ее мало. А интерпояция/экстраполяция это не порождает абстрактные знания о предмете, т.е. эти методы не добавляет информации — она остается такой же сжатой. Это как битовая картинка если ее увеличивать — появятся квадраты.
Допустим статистики много, но бизнес среда поменялась (что у нас происходит регулярно). Тогда накопленные продажи до 2014 года (2008, 1998 и т.д.) уже неприменимы к текущей ситуации. И план продаж строить на основе данных до кризиса нет смысла. А сеть во первых уловила зависимости, во вторых она к новым данным быстро приспособилась и выдает правильную картинку. В этом ее фишка.
(13) Так написано же зачем в (2)
(13) Да это не сложно. Посмотрите модуль обработки — там 300 строк вместе с сервисными процедурами. Любая печ форма под erp 2 больше в разы))
(16) не знаю чему вас там волосатые дяди научили в реальной жизни… Я же не предлагаю писать сверточные сети на 1С, тем более они не нужны для задач планирования и прогнозирования. У всего свое применение. Тут речь идет о применении этой технологии к решению конкретных экономических задач. Я мог написать и про CNN которыми я много лет занимаюсь,про генетические алгоритмы и про много что еще. Простой однослойный перцептрон на практике хорошо фильтрует сигнал — там не надо добавлять уровней адстракции если он и так справляется. Тоже самое и применительно к задачам 1Ски.
(12)
Вопрос какой функцией выполняем интерполяцию, при многих факторах анализа и сеть сложная будет.
А если обучающая выборка мелкая, то где гарантия, что сеть найдет правильное решение?
(17) Простой персептрон не нужен — есть линейная регрессия. Всё равно нужно приличную НС конструировать чтобы решать задачи на практике… ну и не пишется это на 1С конечно :). Не для того она 🙂
(19) про обработку сигнала это я для примера сказал, понятно что есть лучше методы. Кстати дисперсионные типа парной регрессии вычисляются дольше, ну не суть.
А почему это не пишется на 1С?Какие аргументы? И приличная это какая(какие слои, сколько нейронов) и почему именно такая?
(2)
Огромное спасибо! Ждём продолжения банкета)
Вот! То что нужно для моих задач с кучей ЮЛ, комиссией и себестоимостью.
(22) Ну, если это не шутка, то думаю для учета с/стоимости сети плохо подходят, по крайней мере гораздо хуже СЛАУ. Хотя… линейные нейроны чем не СЛАУ…
(23) Без подробностей. Цель — совсем не расчет затрат.
Первая статья на эту тему, где получил понятие, что это такое и как на практике работает))
Спасибо, интересно.
Показать
В данной процедуре есть бесполезное условие или автор ошибся и забыл поставить в условии возврат:
Выход всегда будет рассчитан так:
(26) Да, использовалось для другой конфигурации сети, потом переделал а убрать забыл. Сейчас смысла в этом куске нет.
(27) Т.е. выход всегда должен пройти через функцию активации, в данном примере через сигмойд??
(28) Да, в данной сетке все нейроны одинаковые в всех 3х слоях и всегда через активацию
(20)
Минимум 4-5 слоёв, иначе смысла особого нейросеть не имеет- будет почти линейный прогноз. Не менее 10-ка нейронов в каждом слое, ну и обучение на нормальном объёме данных.
Не говоря уже о том что если вы строите стат. модель желательно бы попробовать и векторные модели и деревья решений и нелинейную регрессию — вдруг даст лучший результат, ну и сеть обучать конечно не таким алгоритмом, да и не персептрон взять, и функцию активации другую… :).
Какая уж тут 1С…
(30) ух! А как Вы, не зная параметров задачи вот так вот сходу выдали параметры сети, а? И главное чем это обосновано? Почему 4-5, почему 10? Насчет обучения да — backpropagation тормозной алгоритм включая его улучшенные версии. А все остальное то — чем обусловлено?
«Но на мой взгляд тут нет ничего сложного, и принцип можно сформулирует так: если подобрать методом научного тыка такие параметры сети, чтобы она распознавала известные значения из выборки с той точностью, которая вас устраивает(а проверить это легко т.к. результат тоже известен), то можно считать что она обучена хорошо и неизвестные значения она также хорошо будет распознавать.» — я бы тут лучше параметры сети (количество слоев, количество нейронов в слое, соединения между нейронами) подбирал с помощью генетического алгоритма. А по поводу «о можно считать что она обучена хорошо и неизвестные значения она также хорошо будет распознавать» — это далеко не так — часто приходится обучать сеть с разными параметрами и даже с одинаковыми параметрами сети, но с разными случайными весовыми параметрами сети — разный результат будет. Приходится беггинг применять.
(19) А зачем «приличная НС»? — если задача стоит только в линейном разделении пространства двух классов объектов, и центры тяжести этих двух классов хорошо разделимы линейным классификатором, то почему и не обычный персептрон? — давайте еще AdaBost-инг сюда прикрутим? — тоже линейный (бинарный) классификатор. Не надо усложнять себе задачу, если она решается более простой моделью.
(30) Ну, на самом деле сеть и с одним скрытым слоем может аппроксимировать практически любую функцию (выпуклую). А с двумя скрытыми слоями — вообще любую (и не выпуклую). 4-5 слоев — это для глубокой сети, когда нужно выявить глубокие закономерности в данных + уменьшить количество связей в сети (сверточная сеть) и настраиваемых параметров.
(16)
Олег, научите всех нас! )) Как минимум — интересно! Как максимум — будет полезно!
Ну, или хотя бы ссылочку…
Обработку пока не скачивал, поэтому задам такие вопросы:
— есть ли в модели нейроны смещения?
— как задать гиперпараметры (я понял, что используется обратное распространение ошибки), управляющие градиентным спуском (скорость обучения и …(забыл как называется))?
— используется стохастический спуск (веса переопределяются сразу в момент уточнения или все сразу)?
— количество операций обучения в каких единицах? — это число «эпох» или число «сетов»;
— какое примерно быстродействие у обучения?
— есть ли возможность рассчитать ошибку? как она оценивается?
(33)
тогда НЕ НАДО ИСПОЛЬЗОВАТЬ НС! Модель подбирается под задачу. Если задача настолько простая что решается НС с несколькими нейронами, значит НС там не нужно — более того вредно.
(34)
Вы немного не понимаете… нужно разобраться в теории сначала.
Глубокие НС это совсем о другом.
Как и векторная модель и гауссовская… И что? :))))))) вообщем матчасть — немного надо углубиться
(36) bias можно просто в формуле задать
Скорость обучения тоже в коде отдельная переменная, на форму не выносил
Веса переопределяются в момент уточнения
Итерации — сеты, если я правильно понял вопрос
Ошибка в процессе обучения оценивается по среднеквадратическому отклонению
Скорость от 5 минут (15 нейронов 10000 итераций) до порядка 20. При текущей скорости обучения.
(35)
Либо платные видюхи по Classification/regression learner -ам на Mathworks либо курсы/конференции от экспоненты
Ну либо у ребят из Yandex Data Factory поучиться.
(40) Спасибо!!!
Занимательно! Просьба выложить пример файла сети и файл границы.
(39) Дмитрий, спасибо за ликбез. Даже я, человек, далёкий от нейронов и сетей, что-то понял. 🙂
Что касается «Я буду рад если кто то присоединится к этому проекту», то могу помочь создать готовое решение и продвинуть его. Есть целая отрасль, которая терпит большие убытки от неоперативного обновления ассортимента. Наверняка такая отрасль не одна, но эта — весьма платёжеспособна, плюс я уже вёл переговоры на эту тему, т.е. знаю людей, которые купят такое решение а, может быть, даже частично профинансируют его разработку.
(40) Олег, назвался груздем — полезай в кузов! Кооптирую тебя для участия в проекте.. в свободное от докладов на Инфостарте время. 🙂
(43) Это очень интересно! Я готов заняться подбором решения на конкретном проекте. Насчет массового решения не уверен, но тоже можно попробовать. Пишите в личку.
(38) Простите, не понял про векторную модель и гауссовскую модель….. Распределение по гауссу знаю, функцию такую знаю, что такое вектор знаю. А вот про модель векторную и модель гаусса…. просветите, пожалуйста. (я не ёрничаю, честно не понял).
(38) Глубокая нейросеть — это сеть где на каждом последующем слое (если это однонаправленная сеть) производится анализ специфичных для прикладной области признаков. Например, при анализе изображения — на первом слое — это точки (аналог ганглиозных клеток off/on). На втором — линии. На третьем углы. На четвертом — окружности. Ну а там и до лица человека дойдем. В обычной (второго поколения — MPL — сети) — там один скрытый слой, и этот слой пытается разгрести все изображение -> проблема с отсутствием анализа двумерности изображения, т.к. сеть полносвязная, то кол-во обучаемых параметров — просто огромно-> переобучение и кол-во примеров должно быть очень велико, ну и скорость обучения хромает и т.д. -> это все лечиться добавлением количеством слоев + новой парадигме обучения. Разве я не прав ?
(42) Ну вот из примера в статье
(43) Николай, конечно тиражная решение это хорошо… но и тут уже конкуренция приличная… У меня сейчас, к примеру, внедряются некто Nextail для управления товарным ассортиментом на основе машинного обучения. И у них есть конкурентное преимущество — они из Zara…
А для не тиражных с Yandex Data Factory нам конечно не тягаться 🙁
(48) Т.е. ты считаешь, что рынок плотно занят? Но ведь есть огромная ниша бесшовной интеграции «на платформе 1С». 😉
(45) Это стандартная функциональность Matlab-а при выборе модели для классификации или регрессии.
И то и то относится к машинному обучению, но при этом не НС. НС используют когда эти модели не дают нужного результата.
Что это такое — гуглится:
(49) Да… но «платформа 1С» по аналитическим возможностям уступает специализированным платформам. Т.е. если делать хорошо — это будут некоторые внешние компоненты… А они уже накладывают ограничения — данные сначала нужно затянуть в память а потом передать в ВК.
Таким образом «решение использует алгоритмы машинного обучения» — было бы крутым лэйблом и давало бы конкурентные преимущества, но позиционировать машинное обучение как основу наверное не стоит…
(46) Вы правы, и прекрасно понимаете что такое глубокая НС. Но коллега который думает что просто НС с кучей слоёв можно назвать глубокой ошибается.
(50) Ясно — SVM — метод опорных векторов. Меня смутило название — векторная модель. По поводу Гауссовой модели — это упрощенно матрица ко вариации + мат. ожидание -> просто вычисляем коэфф. корреляции с некоторыми ограничениями для нескольких сигналов.
Спасибо за статью!
Если не затруднит, объясните следующий момент:
почему ошибка перемножается на какой-то коэффициент вычисленный из значения выхода (А*(1-А))? что он означает?
(54) это принцип обратного распостранения ошибки от выходного слоя в обратном направлении, а смысл данного «коэффициента» в том, что коррекция происходит тем больше, чем больше вес у нейрона который включен в связь, т.е. чем больше вес тем больше «вклад» в ошибку — тем больше его надо откорректировать.
(53) Ну для меня это всё статистические модели :). Они конечно простые, но часто решают задачи лучше чем НС, не говоря о том что быстрее.
Если всё это дело лажает — уже приходится обучать НС, ну и как правило 1-2 слоя в этом случае проблему не решают.
(54) (55) Думаю, ответ не совсем точный.
А (1 — А), где А — значение выхода нейрона, это производная функции активации (в данном случае — сигмоида). То есть значение градиента (наклона) по этой координате (весу связи) в методе градиентного спуска. Еще проще — отношение изменения ошибки на выходе к изменению веса связи на входе. Это дает возможность узнать, на сколько в данном направлении нужно изменить вектор весов, чтобы идти в направлении минимума ошибки. Где-то еще должен быть коэффициент, отвечающий за величину шага (скорость обучения) и, возможно, еще один коэффициент (момент), отвечающий за учет величины предыдущего шага (инерцию), чтобы локальные минимумы проскакивать. Если этих коэффициентов и возможности их изменения нет, то обучение может очень часто не удаваться.
Можно еще почитать вот эту статью, где больше говорится об устройстве НС и ее обучении.
(57) Да все там точно, просто у меня сначала ошибка вычисляется, потом веса меняются в другом месте с коэффициентами
(58) Про
понял. Неточность (или, скорее, непонятый вопрос) я усмотрел именно в ответе. Вас спрашивали про А(1 — А), а вы отвечали про влияние веса.
(59) Так А-это выход нейрона на который надо распостранить ошибку, чем больше А тем больше ему ошибки достанется. Это чисто для расчета величны ошибки на каждый нейрон предыдущего слоя. Это не формула по которой выход нейрона расчитывается поэтому это не наклон сигмоиды. Наверно непривычно воспринимается потому что я в 2 действия это делаю.
(60) Прошу прощения за занудство:
А тогда (1 — А) зачем?
Проверочные вопросы: 1) а если функция активации будет другой (например, ReLU), формула изменится или нет? 2) как связаны обратное распространение ошибки и градиентный спуск?
Это я к тому, что, кажется, вы воспринимаете формулы, используемые в методе обратного распространения ошибки, как эмпирическое. Хотя они строгим образом выведены исходя из модели нейронной сети (которая действительно изначально эмпирическая). Опасность этого в том, что при таком понимании легко допустить ошибку: например, изменить модель, не изменив метод обучения.
И, наоборот, понимание зависимостей позволяет избегать трат времени на поиск «лучшего метода обучения» (в рамках градиентного спуска).
(56) Тут полностью с Вами согласен. SVM, AdaBost, корреляция — математические методы тем и лучше нейронных сетей, что позволяют ответить на вопрос почему данный сигнал (ошибочно или нет) относится методом к такому то классу, а не к другому. В нейронных сетях ответ на этот вопрос скрыт в самой нейросети, и достать его оттуда получается только для самых простых случаев — типа метода XOR, что само по себе настолько тривиально, что применение нейронной сети не оправдано. Поэтому я пытаюсь тоже сначала при решении применить математический метод от самого быстрого и простого — и потом уже по нарастающей.
(61) Хмм.. Может мы о разных вещах говорим… Ну и какая формула Вы считаете будет при ReLU?
(63) Думаю,
если на языке 1С.
(64) так это и есть сама функция активации, а та то формула это ошибка для 1го входа 1го нейрона. Т.е. мы уже посчитали выход (не важно какой функцией или вообще как), посчитали отклонение от желаемого значения (опять же неважно как оно получено) и нам надо посчитать на какую величину корректировать вес. Мы же об этой формуле говорим? Или есть какая то связь с функцией активации о которой я не знаю? А где про это написано конкретно — все перерыл не нашел. Вот что в википедии об этом — все как у меня:
(65) Функция активации ReLU
, а в (64) — ее производная. Они похожи из-за простоты ReLU, но там в скобках не А, а 1. Потому, что производная от Х равна 1.
Вот тоже из википедии
Обратите внимание, на формулу производной сигмоида и что там про производную говорится.
(66) да, теперь понял, точно это ж производная! Странно что у меня и так прокатывало с гиперболическим тангенсом например))
(67) А в том то и дело, что гиперболический тангенс — эта по сути та же функция, отличается только областью значений, производная ее той же формулой выражается:
(68) Да спасибо что поправили. Я думаю Ваш коммент будет полезен тем кто будет разбираться
…вот смотрю я на всё это, а потом понимаю, что наша реальность — не всякие там завиральные нейронные сети, а экстренное впиливание новых счетов-фактур в дебри нетиповых конфиг, да объяснение бухам в сотый раз, почему у них на 62 счёте третье субконто красненькое… А это так, из параллельной вселенной, астрономически далёкой от автоматизации учёта с помощью 1С.
(70) автоматизация УЧЕТА это базовый уровень, чё про это говорить. Но я Вас понимаю мне тоже некоторые вещи кажется космос, а потом глядишь все вокруг начали внедрять.
(71) Просто ничего, кроме этого базового уровня, никому нафиг не нужно. НС это «космос» не потому, что продукт не потянет или программисты тупые, а потому, что нужды нет и не будет, готовности к этому никакой. В первую очередь среди тех, кто платит деньги. Попробуйте объяснить — хоть среднему торгашу, хоть гендиру фабрики, нафига это — он не поймёт и денег платить не станет. Разве только действительно, «все вокруг начали» — мода дурная пойдёт, тогда что-то глядишь изменится. Но вряд ли.
Если даже, допустим, логисты не желают видеть воплощённое решение задачи коммивояжёра, а хотят, чтоб «операторы били ручками», а маркетологи орут, что у них отнимают хлеб — ну какая к чертям нейронная сеть, о чём вы?
(72) а к нам наоборот логисты обращались за оптимизацией делали несколько раз на разных алгоритмах, всякие оптимизации в wms тоже. Или например из экзотического — линейный и 2мерный раскрой на муравьином/ генетическом алгоритме для оконной фабрики. Ну и мат.методы в планировании и прогнозировании. Насколько я знаю много кто на 1Ске оптимизирует логистику. Да и вообще, например, сравните wms-ки например лет 10 назад и сейчас и их распостранение — они умнеют и распостраняются больше. Тоже могу сказать о бюджетировании, планированиии. Как это «продавать» я не знаю я не продажник, но факт есть.
Появилась реальная задачка, т.к. с данным вопросом еще не работал нужно разбираться.
Если можете помочь: , то велком=))
Что почитать из фундаментальных книг, чтобы понимать комментарии?
например «Нейронные сети, генетические алгоритмы и нечеткие системы» есть еще оч хорошая книга Тадеушевича помоему так и называется «Нейронные сети»
Приглашаю в проект:
Необходимо разработать движок для работы со смыслами.
Вот простая задача для понимания направления работы:
Система должна уметь составлять осмысленные предложения из набора слов, например:
— пустыня, озеро, река.
Можно добавлять любые слова, чтобы получилось предложение имеющее смысл.
Например: В пустыне нет озера и реки.
скачал вашу программу, открыть не могу
(78) А в чем проявляется проблема?
Вот скачал, а как это применять фиг его знает.. на входе цифровые значения… а где кроссовки… шнурки.. футболки… покупатель.
вот есть простая история продаж Покупатель — товар1, товар2… товар10 и период. Как «обучить» чтобы нейросеть «предсказала» что через 10 периодов покупатель купит товар5?
полезность статьи 0. Скачал обработку — а где брать имя файла сети и файл параметров, их структуру? вообщем одна обида злость и разочарование. Бери учебник и разбирайся….
Когда то давно, когда читал про нейросети — пытался написать нечто подобное — не осилил и бросил. Ваша статья заставила вернуться к этой теме.
Убить всех человеков! Слава роботам! (нейросетям) (бендер)
По «Выбрать количество нейронов скрытого слоя» вопрос — как определить что количество нейронов достаточно? анализ какой или просто интуитивно?
По построению — есть какие рекомендации что закладывать на обработку в 1 и 2-й слой? Тот же типовой пример по анализу продаж — что пойдет в первый слой и что во второй?
(83) Для 3-х слойного перцептрона есть рекомендация Число слоев скрытого = корень квадратный из ЧислоВходов*ЧислоВыходов , но это не жесткое правило и подбирать надо на конкретных данных. По поводу 1 или больше скрытых слоев, то это вопрос интересный. Если прогноз продаж представить некой зависимостью (функцией) и эта функция непрерывная в каком то диапазоне, то 3-х слойный (т.е. 1 скрытый) ее может апроксимировать. Но на практике мы не знаем зависимость и ее свойства и даже не знаем факторы которые влияют. Поэтому опять же теоретически 4-х слойным можно апроксимировать любую функцию. Как раз буквально на след. неделе я как раз собрался выложить пример готового отчета с 2мя скрытыми слоями.
(84) это будет здорово. Самое сложное и непонятное как раз понимание что закладывать в 1-й слой, а что во 2-й. Во всяком случае для меня и элементарная «мурзилка» позволит преодолеть этот барьер и попробовать реализовать реальную задачу
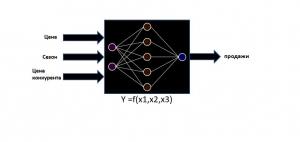
«..обучить сеть на то какою скидку дать покупателю чтобы он купил товара максимально исходя из его предыдущих покупок и некоторых специфических для отрасли параметров.». Для расчёта оптимальной скидки корректно на вход подавать?
н1 — сезон
н2 — цена
н3 — количество
(86) да, вполне. Если от жтого зависит то будет зависимость, если нет то не будет учитываться.