

























* Есть желание повысить скорость работы медленных алгоритмов! Но…
* Нет времени думать о реализации многопоточности?
* о запуске и остановке потоков?
* о поддержании потоков в рабочем состоянии?
* о передаче данных в потоки и как получить ответ из потока?
* об организации последовательности?
Тогда ЭТО — то что надо!!!
Обновление для всех!
Еще больше возможностей, еще быстрее обработка, еще проще разработка — Универсальный менеджер потоков 2.0.
Полная версия, полностью открытый код и только за $m.
Данный материал переходит в разряд статьи
Очень кратко, о чем речь…
Фреймворк в виде одного общего модуля, позволяющего при получении объектов на обработку запускать их в несколько потоков. Особенности:
- Нет необходимости рассчитывать «порции» для обработки;
- Нет необходимости организовывать файловый обмен между потоками;
- Возможность запускать несколько менеджеров потоков одновременно, при этом потоки одного менеджера, могут запускать новые менеджеры со своими задачами и потоками (главное чтоб лицензий хватило :));
- Можно выстраивать граф зависимости объектов, что позволяет, например, избегать взаимоблокировок и/или организовать восстановление партий (на нашем предприятии удалось добиться 10х+ ускорения при 10 потоках в рабочее время – 200+ активных пользователей — Результаты работы механизма);
- Можно и нужно производить вмешательство в алгоритмы с помощью событий;
- Возможность описывать алгоритмы событий, как в модуле менеджера, так и в любом другом модуле БД (предпочтительно), а также во внешней обработке.
- Автоматический рестарт потока в случае ошибок;
- Контроль за количеством рестартов по каждому объекту;
- Возможность получать «ответы» от потоков;
- Возможность контролировать работу с помощью «Инструментов разработчика» или иных отчетов;
- Возможность срочного прерывания работы;
- И многое другое…
О том, как оно все работает описано ниже, при желании можно и свое написать 🙂
Буков очень много, но и картинок достаточно 🙂
Оглавление
Пример 1 (По складам — для восстановления партий не подходит)
Пример 2 (По складам — для восстановления партий подходит)
Пример 3 (По складам и номенклатуре — для восстановления партий не подходит)
Пример 4 (По складам и номенклатуре — для восстановления партий не подходит)
Пример 5 (По складам и номенклатуре — для восстановления партий подходит)
Пример 6 (Варианты на одном примере)
Обновление «Очереди для потоков»
Функция ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков()
Функция ИнициализироватьМенеджерПотоков()
Процедура «ОбработатьОбъект()»
Функция «ОбработатьСобытиеРазработчика()»
Месторасположение функции «ОбработатьСобытиеРазработчика()»
В общем модуле «МенеджераПотоков»
В произвольном модуле БД (рекомендуемый)
События функции «ОбработатьСобытиеРазработчика()»
Событие: «ПередЗапускомМенеджераПотоков»
Событие: «ПриЗапускеМенеджераПотоков»
Событие: «ПриПолученииМассиваРесурсов»
Событие: «ПриОбработкеИсключенийИзОчередиМенеджера»
Событие: «ПриОпределенииТипДанныхВПотоке»
Событие: «ПриОбработкеДействияПотока»
Событие: «ПриОбработкеОтветаПотока»
Событие: «ПриНевозможностиОбработатьОбъект»
Событие: «ПередЗавершениемМенеджераПотоков»
Событие: «ПослеЗавершенияМенеджераПотоков»
Событие: «ПриПолученииМестаХраненияФайловМониторинга»
Вариант передачи данных между событиями
Введение
В данной публикации будет максимально подробно «разжеван» способ реализации «Менеджера потоков», а так же предоставлены демо обработки с готовым открытым исходным кодом.
Описание и примеры с кодом, в данной статье, будут даны в общих чертах по принципу от общего к частному. На каких-то скринах будут отсутствовать параметры процедур и функций или строки кода, в связи с тем, что в данной конкретной теме это не является существенным.
Все повествование будет вестись на примере «Восстановления партий», т.к. эта задача была первоочередной, но в дальнейшем переродилась в «Универсальный механизм». «Универсальным» он назван по той причине, что общий модуль, где располагаются алгоритмы «Менеджера потоков» могут быть обособлены и не изменны на всем протяжении использования механизма, но при этом решать разные задачи (восстановление партий, расчет зарплаты, формирование пакетов документов, формирование отчетов и т.д.).
Весь код и в скринах, и в обработках написан на обычных формах, т.к. разработка велась на базе УПП. Описание предоставлено в рамках «Восстановления партий».
Но обо всем по порядку …
Результаты работы механизма
При распараллеливании на 10 потоков.
| Показатель | Ноябрь 2026 | Декабрь 2026 | Январь 2026 | Февраль 2026 |
|---|---|---|---|---|
| Документов в последовательности (шт.) | 22865 | 18298 | 14788 | 17189 |
| Документов для восстановления (шт.) | 14192 | 9252 | 8537 | 9921 |
| Однопоточное восстановление («холодный»/«прогретый») (мин.) | 293/265 | 215/196 | 172/162 | 219/203 |
| Параллельное восстановление («холодный»/«прогретый») (мин.) | 30/24 | 20/16 | 16/14 | 19/17 |
Здесь и далее под «холодный» и «прогреты» понимается запуск обработки сразу после восстановления БД («холодный») и запуск повторно («прогретый»).
Как проводились тесты:
- на копии продуктивной БД (УПП; 3 года; ~200 Гб; 1 организация);
- по 4 месяцам (ноябрь 2026, декабрь 2026, январь 2026, февраль 2026);
- копия БД восстанавливалась на момент перед первым восстановлением последовательности за период;
- по каждому месяцу было развёрнуто по 2 копии БД, в одной запускался типовое восстановление (без настроек обработки), в другой с использованием «Менеджера потоков»
Железо
Сервер 1С и Клиент
- Процессор: i7-3930K 3.2 ГГц;
- ОЗУ: 16Гб;
- ПЗУ: SSD KINGSTON SH103S3120G;
SQL Сервер
(продуктив: 1 продуктивная база; 15-18 баз разработчиков)
- Процессор: 2xXeon E5-2697v2 2.7 ГГц;
- ОЗУ: 128Гб;
- ПЗУ Система: RAID-1 2xSSD IBM System X 512Гб;
- ПЗУ База: SSD Intel P3700 800Гб (только приобрели – тестируем, обе тестируемые базы тут);
- ПЗУ Tempdb: RAID-10 4xSSD IBM System X 512Гб.
Программное обеспечение
Сервер 1С и Клиент
- Win 7 Prof SP1 64x
- 1С:Предприятие 8.3 (8.3.9.1850) 32x
SQL Сервер
- WinServer 2012 R2 Standard 64x
- SQL Server 2008 R2 (10.50.6000)
Предыстория
(кому не интересно могут смело идти дальше)
Мое основное рабочее место в крупной строительной организации. Часто бывает, что ближе к концу отчетному периоду начинают все интенсивнее приходить документы, включая те, что относятся к началу отчетного периода. И приходиться заново проводить восстановление партий и перезакрывать период. Все бы ни чего, но делать это в рабочее время не получается из-за блокировок. Приходится восстановление проводить по ночам, а период закрывать на следующий день и так по каждому месяцу до крайнего. В худшем случае может потребоваться 3 дня L.
Если месяц закрыт и все ошибки выверены, то на полное перезакрытие уходит около 5 часов, 3-4 из которых – это восстановление партий. В свою очередь восстановление партий — это всего лишь один этап при закрытии месяца, а всего их от 28 до 31 в зависимости от периода. При вопросе, что оптимизировать сомнений уже не осталось.
Я был знаком с механизмом фоновых заданий, но часто на практике его использовать не приходилось. Мне виделось решение проблемы именно тут, но как?
У нашей организации очень обширная география (от Сочи до Камчатки). В своем большинстве объекты обособленные. Склады и производство находятся в непосредственной близости друг к другу. Перемещения материалов между объектами происходят достаточно редко по сравнению поступлениями и списаниями на них. Тогда и появилась первая мысль «а нельзя ли восстанавливать последовательность в рамках объектов?».
Первая версия обработки в данном направлении была готова примерно через 2 недели (это был февраль 2026г.) и тогда показала неплохие результаты, партии восстанавливались примерно за 50 мин. Но у данной обработки были большие минусы:
- была не пригодна для общего использования (не у всех такая особенность учета складов и производства);
- достаточно много корректировок в типовом коде;
- достаточно сложна для понимания принципов работы при вычислении порции для потоков.
Как в жизни, если не получается или получается «не совсем удачно» — обратимся к мануалу :).
Хотелось большего выигрыша в скорости, что подвигло меня посмотреть, что по этому поводу пишут в интернете. Нашел интересные статьи:
- Ускорение восстановления последовательности документов в УПП. (Источник: http://www.forum.mista.ru/topic.php?id=541251&page=1); Это был первый источник, где можно было ознакомиться с мыслями сообщества по данному вопросу. Вы этой теме была найдена ссылка – след. пункт, на более глубокий теоретический подход к решению проблемы.
- Ускорение процесса восстановления последовательности в 1С 8 УПП с использованием параллельных вычислений (Источник: http://www.softpoint.ru/archive/article_id375.php); Достаточно подробно и в картинках – весьма познавательно.
- Параллельное восстановление партий (Источник: http://techlab.rarus.ru/news/articles/parallelnoe-vosstanovlenie-partiy/ ) Тут больше о достижении 1С-Рарус в решении данного вопроса, а также представлены результаты одного из заказчиков.
Это дало мне надежду, что можно найти еще более оптимальное решение. Но в связи с загрузкой на работе пришлось закинуть идею в дальний ящик, т.к. задачу решал на энтузиазме, а не по просьбе заказчика.
…
Снова вернуться к данной разработке меня подвигло появление свободного времени и любопытство. Еще раз ознакомившись с вышеописанными источниками решил поискать, о какой доработке типового УПП писал «1С-Рарус». Решил поискать «тормоза» типового решения. Кандидаты нашлись довольно быстро — это:
- Настройка в обработке «Восстановление партий» Меню – «Настройка» — «Настройка обработки» — «Ручная настройка» — «Количество документов в выборке». Данный параметр отвечает за количество итераций «Запрос в цикле». По умолчанию = 1, т.е. выполнение запроса на выборку 1 документа и так столько раз, сколько документов в обрабатываемом периоде последовательности.
- Процедура «СдвинутьПоследовательностьВперед()» в общем модуле «Заполнение документов» из которой вызывается функция «ОпределитьНеобходимостьСдвигаГраницы», что приводит нас, как и в первом случае к «Запросу в цикле».
- Не оптимально написанные запросы в общем модуле «УправлениеЗапасамиПартионныйУчет»:
- Процедура ЗаполнитьЗапросПартийНаСкладахУпр;
- Процедура ЗаполнитьЗапросПартийНаСкладахБух;
- Процедура ЗаполнитьЗапросПартийНаСкладахНал;
Последнее, скорее всего и есть тот самый «патч» :).
Все остальное было не столь существенно:
После изменения настроек и исправления запросов результат стал следующий:
| Показатель | Ноябрь 2026 | Декабрь 2026 | Январь 2026 | Февраль 2026 |
|---|---|---|---|---|
| Однопоточное восстановление («холодный»/«прогретый») (мин.) | 293/265 | 215/196 | 172/162 | 219/203 |
| Однопоточное восстановление + оптимизация («холодный»/«прогретый» ) (мин.) | 130/108 | 85/67 | 67/54 | 76/62 |
| Параллельное восстановление («холодный»/«прогретый») (мин.) | 30/24 | 20/16 | 16/14 | 19/17 |
Это уже позволяло в критической ситуации (1 сессия в БД с блокировкой доступа) провести восстановление квартала за 1 рабочий день.
Далее, было желание реализации фоновых заданий. Решил попробовать схему описанную «SoftPoint», т.к. она более детально и подробно описана, но при было желание избавиться от минусов прошлой разработки.
На удивление решение оказалось значительно проще прошлогодних алгоритмов, за исключением одного момента, а именно управления документами в очередях. Так же мне «не давала покоя» реализация по принципу «у каждого потока своя очередь». В итоге я приступил к новой разработке, результатами которой и решил поделиться со всеми. И так поехали…
Общая схема

Данная схема показано очень упрощенно, дабы не испугать не искушенного. Как видно на рисунке необходимо изменить однопоточное проведение в цикле, на проведение в несколько потоков.
В общем случае потребуется внести 3 корректировки в типовой код:
- Перед циклом запустить инициализацию менеджера потоков;
- В цикле переопределить процедуру выполнения;
- После цикла дождаться завершения работы менеджера.
Общие описание каждой из процедур основного кода:
- Функция ИнициализироватьМенеджерПотоков() — предназначена для инициализации работы в потоках и установки начальных параметров менеджера потоков;
- Процедура ОбработатьОбъект() — производит первичные расчеты по объекту и передает его при необходимости в менеджер потоков;
- Процедура ДождатьсяОстановкиМенеджераПотоков() — ожидает завершения работы всех фоновых заданий, а так же производит сохранение всех отчетов мониторинга.
Общие описание основных процедур фонового задания «Менеджер потоков»:
- Функция ОбновитьОчередьОбъектов() – очищает "Очередь для потоков" от объектов если они уже обработаны, при необходимости перезапускает потоки, также определяет какие потоки свободны;
- Процедура ЗапуститьОбъектыИзОчередиВПоток () — производит передачу объектов из «Очереди для потоков» в свободные потоки;
- Процедура ДобавитьОбъектВОчередь() — добавляет объект в "Очередь для потоков" если есть свободное место;
Запуск и остановка ФЗ
Контроль запуска и остановки фоновых заданий очень важен, т.к. напрямую на них влиять «не удобно». Для исключительных ситуаций, например, не правильно выставлены начальные настройки, предоставлена простая обработка — «Интерактивная остановка менеджеров потоков». Ну или просто можно вызвать процедуру «МенеджерПотоков. ОстановитьМенеджерПотоковИнтерактивно()»
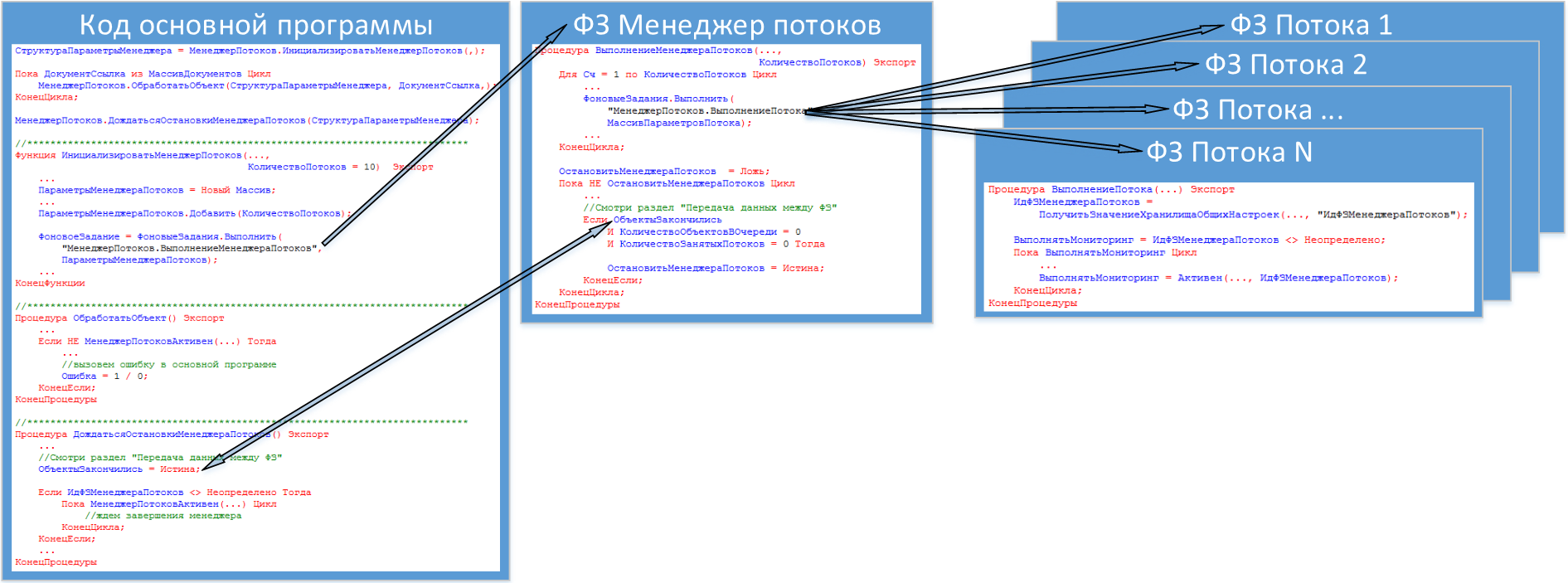
На данном рисунке видно, что все фоновые задания запускаются из процедуры «ИнициализироватьМенеджерПотоков». Сначала запускается менеджер потоков, а уже он запускает фоновые задания потоков. В каждом фоновом задании, включая «Менеджер потоков» запускается «бесконечный цикл». На каждой итерации цикла, потоки отслеживают активность «Менеджера потоков» и если он не активен, они завершают свою работу. В то же время, цикл основной программы, так же на каждой итерации проверяет активность «Менеджера потоков» и в случае его преждевременного завершения вызывает ошибку в основной программе.
После того, как цикл основной программы был завершен, осуществляется установка переменной «ОбъектыЗакончились» в значение «Истина», затем запускается «бесконечный цикл» с ожиданием остановки «Менеджера потоков».
«Менеджер потоков» на каждой итерации своего «Бесконечного цикла» анализирует 3 параметра:
- ОбъектыЗакончились – значение переменной переданной из основной программы со значением «Истина» сообщает о том, что новых объектов в «Менеджер потоков» не поступит;
- КоличествоОбъектовВОчереди – говорит само за себя, количество объектов в «Очереди для потоков»;
- КоличествоЗанятыхПотоков – так же говорит само за себя;
Как только выполняется «условие выхода» из «Бесконечного цикла» — «Менеджер потоков» завершает свою работу.
Основная программа «увидев» не активность «Менеджера потоков» выходит из «бесконечного цикла».
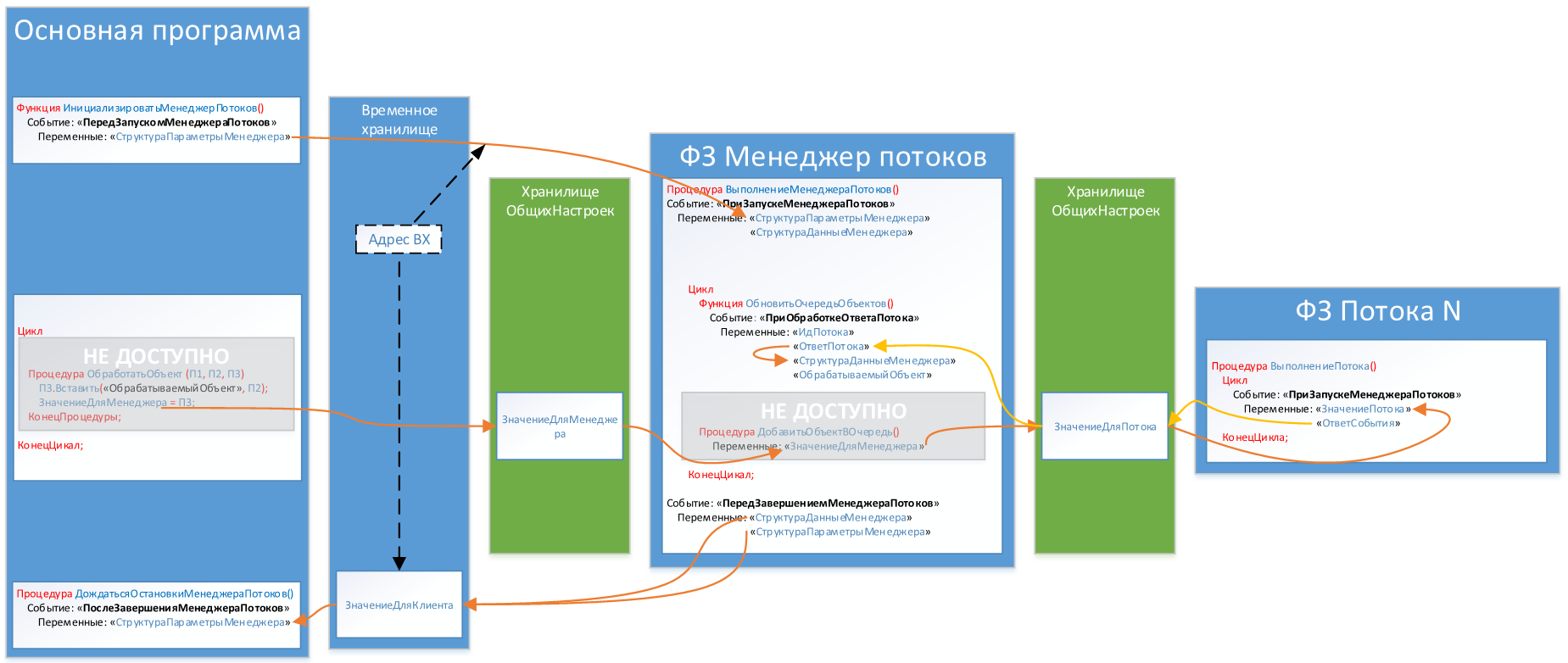
Передача данных между ФЗ
Это был один из самых важных вопросов в решении данной обработки, т.к. хотелось реализовать возможность доработки с минимальным вмешательством в типовой код и в структуру метаданных, без создания таблиц временного хранения данных.
«Хранилище общих настроек» подошло как нельзя кстати. Оно обладает как минимум 2ми плюсами:
- Хранит данные в разрезе пользователей ИБ;
- Хранит «Произвольный» тип данных.
Наблюдать «в живую», как происходит передача данным между фоновыми заданиями можно с помощью «Инструментов разработчика» — //infostart.ru/public/15126/ или http://devtool1c.ucoz.ru/ . Обработка «Редактор хранилищ настроек (ИР)» — Закладка «Общие».
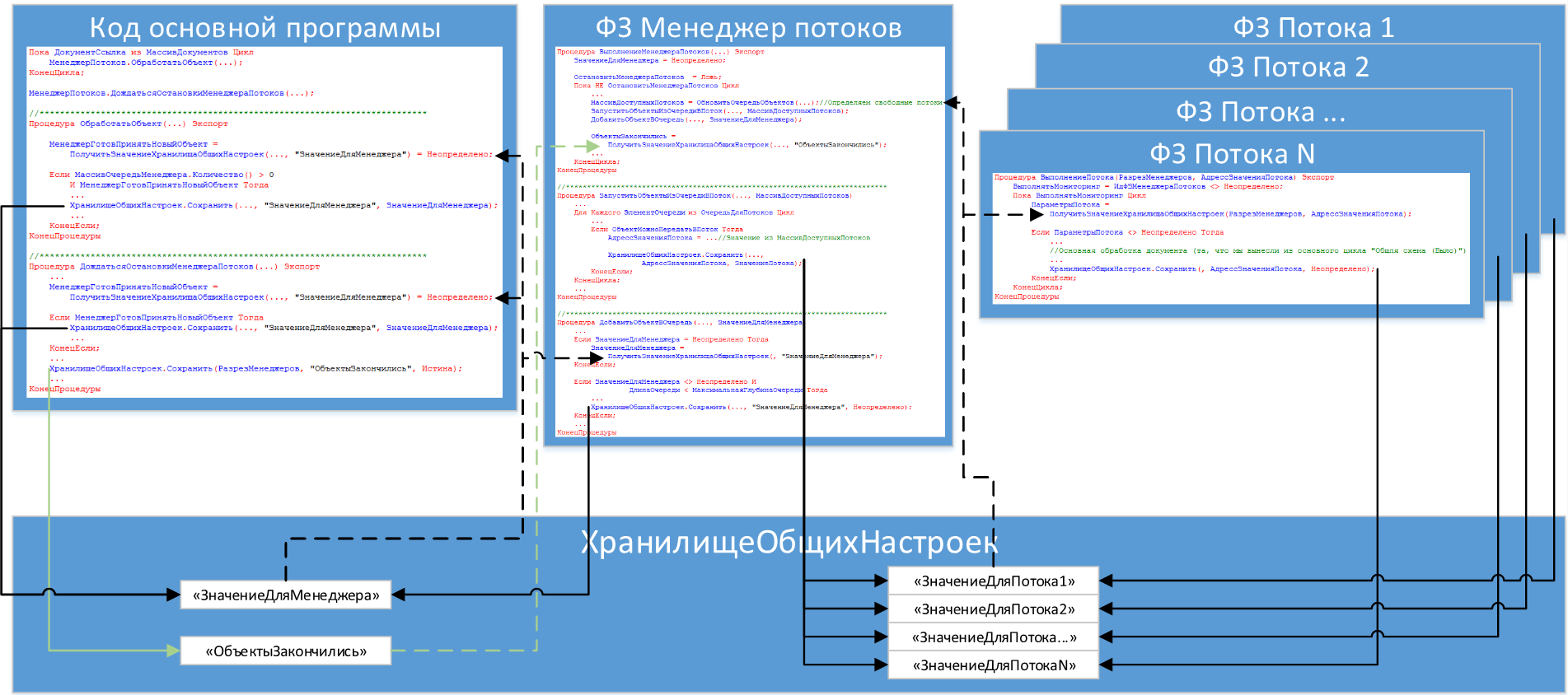
«Общение» происходит по принципу «семафоров». В одном коде алгоритм на каждой итерации цикла проверяет значение (чтение – пунктирная стрелка) из «ХранилищаОбщихНастроек» на равенство «Неопределено» и при необходимости записывает (запись – прямая стрелка) туда же необходимое значение, а в другом коде (фоновом задании), наоборот проверяет значение из «ХранилищаОбщихНастроек» на НЕ равенство «Неопределено» и при необходимости записывает «Неопределено». Чуть сложнее ситуация обстоит с «ЗначениеДляПотока», о чем будет рассказано дальше, но принцип точно такой же.
По такому же принципу реализована передача значения переменной «ДокументыЗакончились» (зеленые стрелки) рассмотренной в разделе «Запуск и остановка ФЗ».
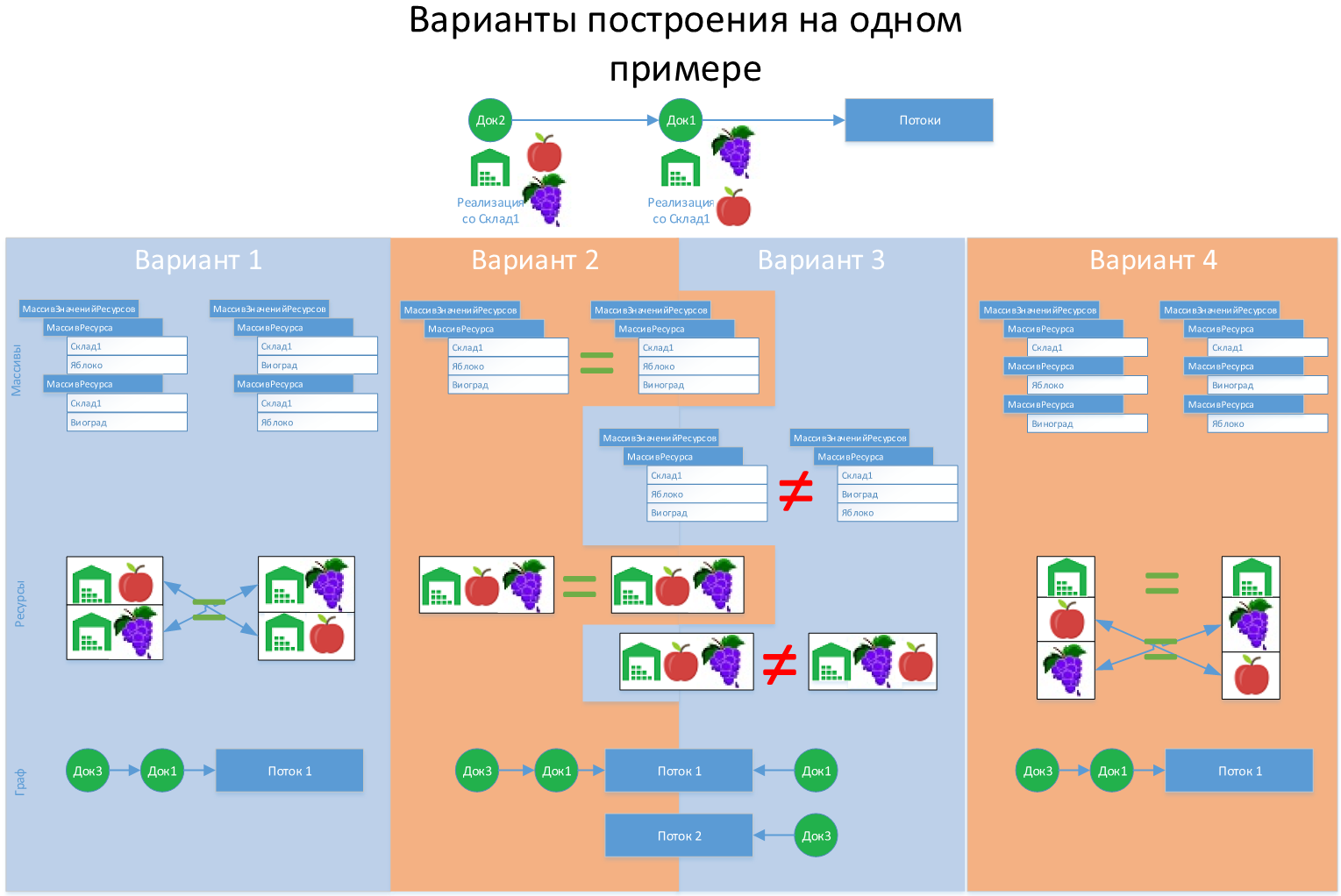
Расчет «Ресурса»
Ресурсом названа уникальная комбинация одного или нескольких значений объекта. Какая это будет комбинация(и), разработчик определяет сам. Объекты с одинаковым(и) ресурсами "строят" граф зависимости объектов, а так же производится объединение графов, если их больше одного. На представленном рисунке засчитываются ресурсы для двух графов, которые сразу объединяются в один:
- Склад и Номенклатура
- Заказ
(В нашей рабочей базе УПП строиться 3 графа для корректного расчета партий)
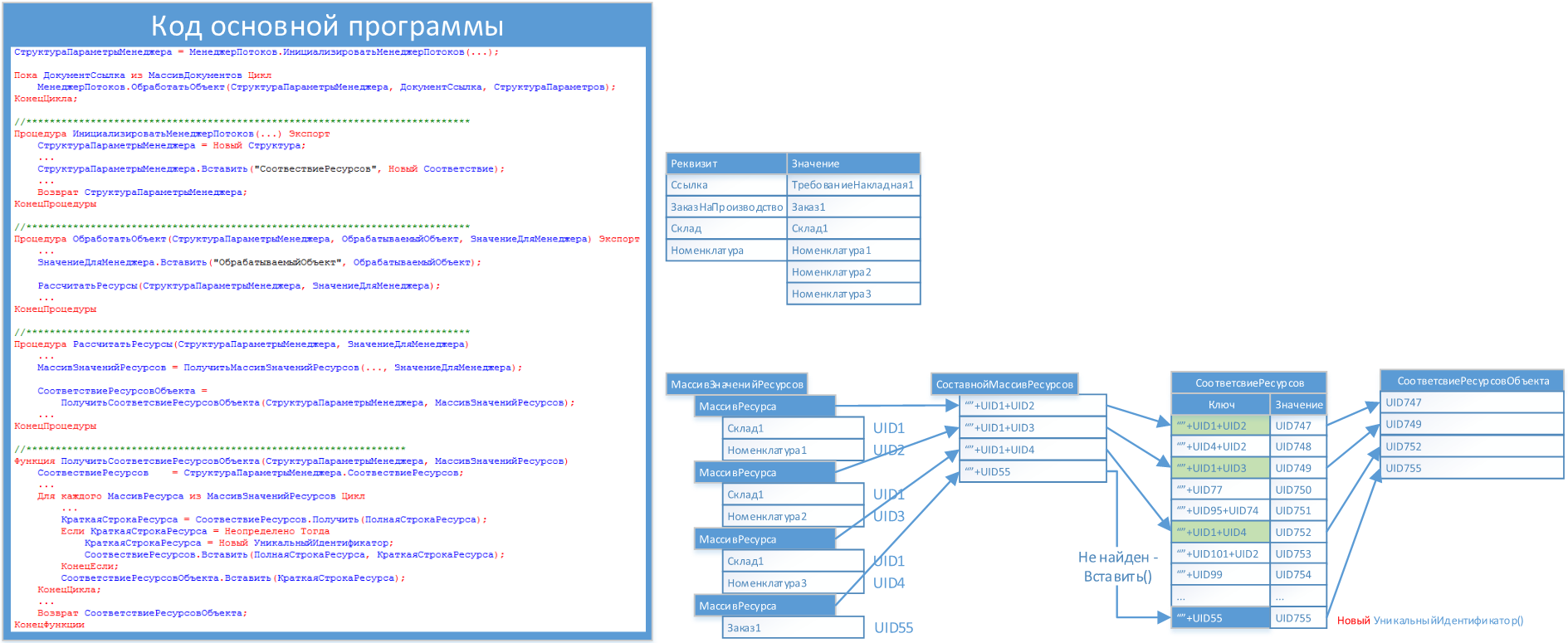
В процедуре «ИнициализацииМенеджераПотоков()» происходит создание «Общего», в рамках текущего выполнения, «Соответствия» всех ресурсов. В процессе обработки каждого документа создается «МассивЗначенийРесурсов», значениями которого является массив конкретного ресурса «МассивРесурса». По каждому «МассивРесурса» формируется составная строка из уникальных идентификаторов ссылок, которые, в свою очередь являются ключами в «СоответствияРесурсов» созданном при инициализации. Если ключ не найден, то в «СоответствиеРесурсов» заносится новое значение – Новый УникальныйИдентификатор().
Примеры формирования ресурсов:
Пример1:
Для восстановления партий не подойдет, т.к. по документу "Док6" — не корректно составлен ресурс, что влечет за собой, проведение "Док6" одновременно с "Док1". Ресурс "Док6" не совпадает ни с одним другим ресурсом других документов.
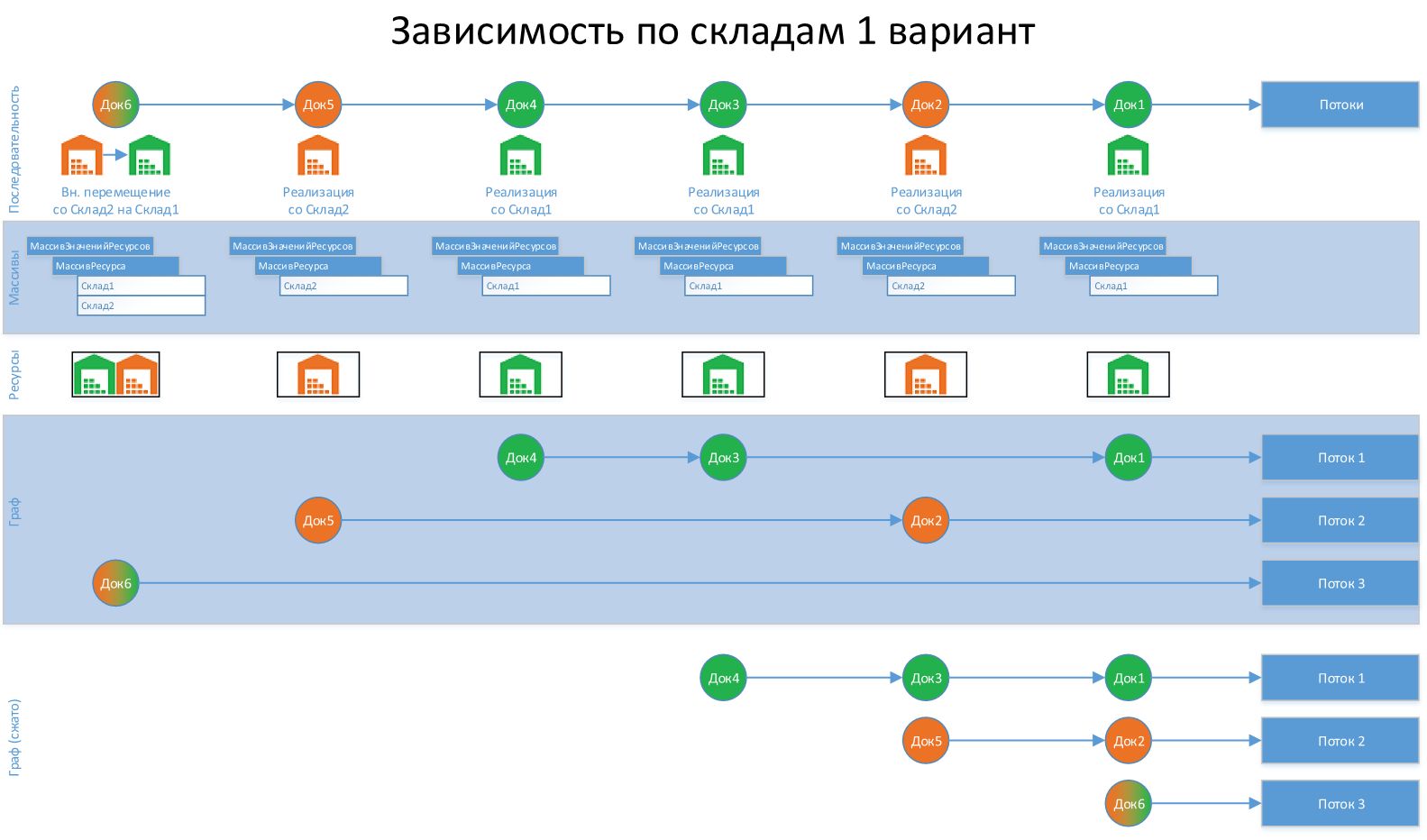
Пример 2
Для восстановления партий подойдет, т.к. ресурсы по документу "Док6" совпадают с ресурсом "Док4" и "Док5", следовательно "Док6" пойдет в обработку, толькот после того, как обработаются "Док4" и "Док5"

Пример 3
Для восстановления партий не подойдет, т.к. по всем документам получены разные ресурсы и документы идут в обработку независимо друг от друга
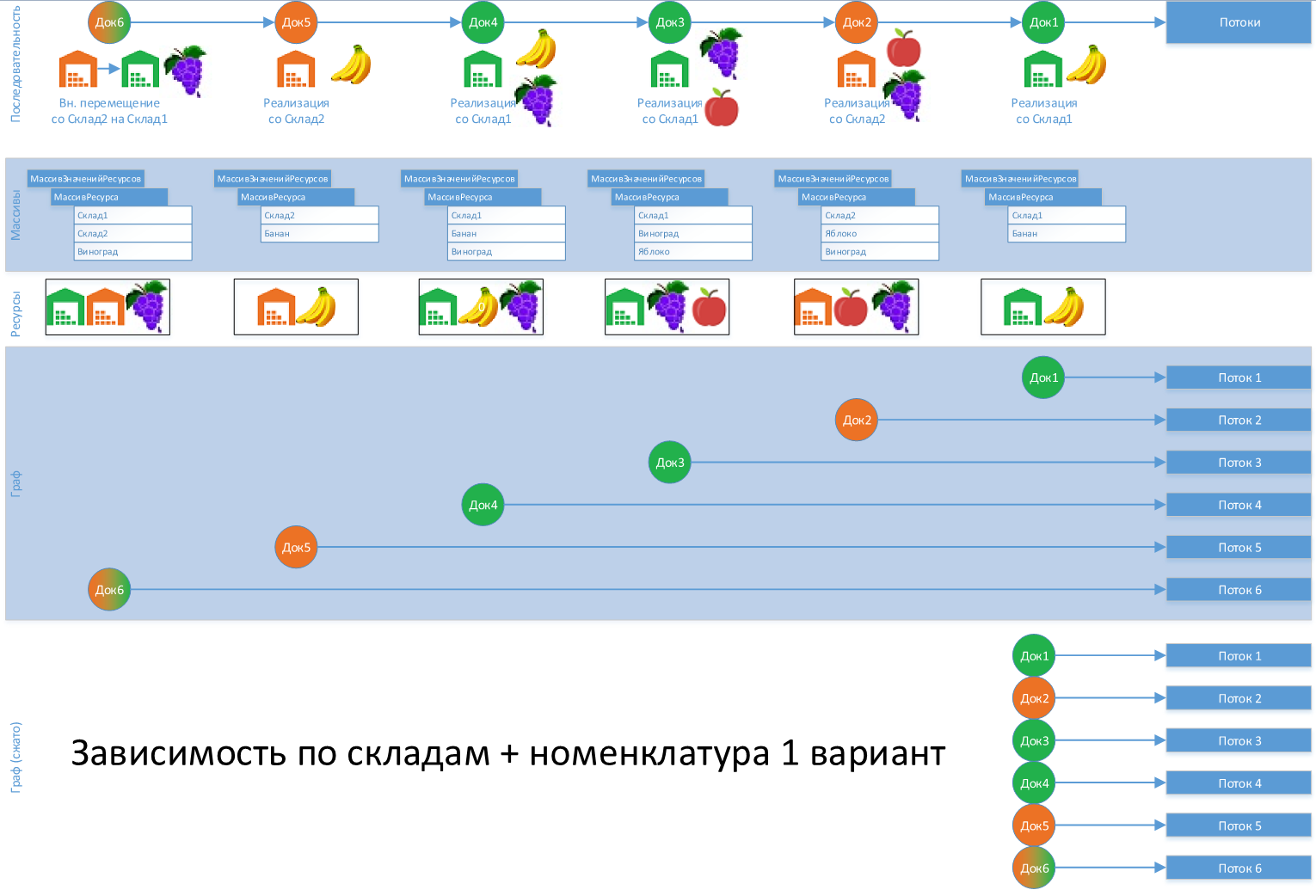
Пример 4
Для восстановления партий не подойдет, т.к. получены слишком "раздробленные" ресурсы — все документы, кроме "Док1" и "Док2", чем-то зависят от других документов.

Пример 5
Для восстановления партий подойдет, т.к. получены достаточные ресурсы, для того распараллелить и "обойти" блокировки.
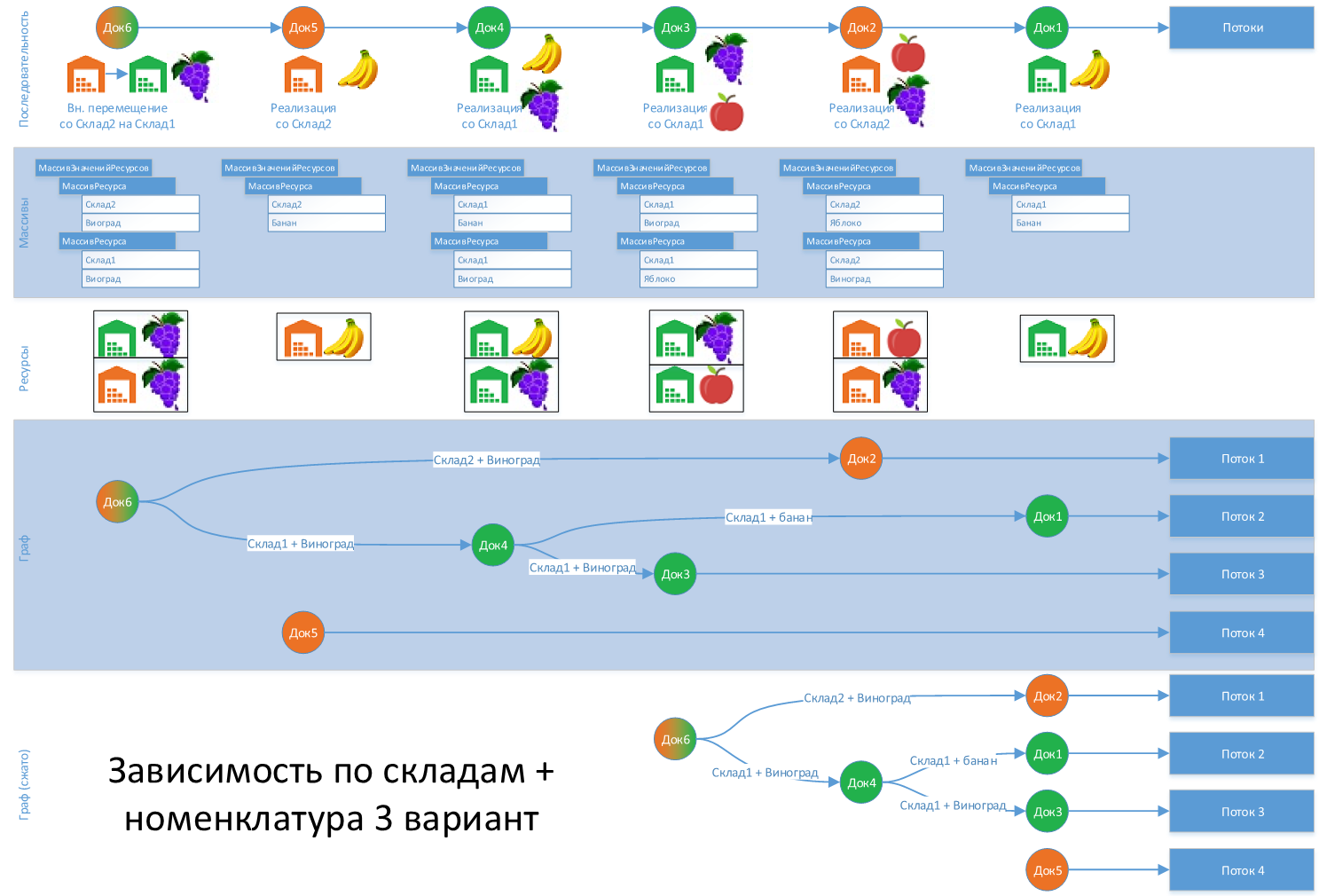
Пример 6
Краткий пример с двумя "почти" одинаковыми документами, но с разными результатами.
ВАЖНО!!! Последовательность значений в массиве "МассивРесурса" ИМЕЕТ значение.
Очереди
При реализации данной обработки пришлось создавать несколько очередей. Одна на стыке «Код основной программы» и «Менеджер потоков» — «ОчередьДляМенеджера», друга на стыке «Менеджер потоков» и «Фоновые задания» — «ОчередьДляПотоков».
Очередь для менеджера
Данная очередь вообще появилась под конец разработки, при анализе графиков наполнения «Очереди для потоков».
В последовательности присутствуют разные документы, как те по которым необходимо восстанавливать последовательность («Требование накладная», «Внутреннее перемещение», и т.д.), так и те по которым этого делать не надо («Поступление товаров и услуг»). Выяснилось, что возникали ситуация (длинная серия из документов, требующих восстановления последовательсти), когда «Очередь для потоков» была забита под завязку (она ограниченного размер, об этом чуть позже) и «Менеджер потоков» не мог принять новый документ от «основной программы». В этот момент «Основная программа» запускала «Бесконечный цикл» в ожидании, когда «Менеджер потоков» будет готов забрать документ. С другой стороны, были и обратные ситуации (длинная серия из документов НЕ требующих восстановления), в этот момент из основной программы не передавались документы в «Менеджер потоков» и данный этап мог быть достаточно длительным, чтобы полностью очистилась «Очередь для потоков» и опять возникал простой в ожидании появления документов для проведения.
Данная очередь и является своего рода буфером, наполняясь при первой ситуации и постепенно очищаясь при возникновении второй.

В процедуре «ИнициализацииМенеджераПотоков()» происходит создание бесконечного массива «МассивОчередьМенеджера». При выполнении обработки документов определяется необходимость восстановления партий по текущему документу. Если документ требует обработки, то он добавляется в очередь. Далее проверяется готов ли «Менеджер потоков» принять новый документ. Если «Готов», то из очереди передается первое значение в «Менеджер потоков» и затем оно удаляется из очереди. После того как цикл обработки документов «Основной программы» отработает, вызывается процедура «ДождатьсяОстановкиМенеджераПотоков». В самом начале которой идет обход «Очереди для менеджера» и постепенно до передаются документы в «Менеджер потоков» с ожиданием если «Менеджер потоков» в какой-то момент не готов принять документ.
Очередь для потоков
Данная очередь является основной для потоков, по большому счету — это граф. Данная очередь является ограниченной по размеру в отличии от «Очередь для менеджера». Связано это с ее постоянными обновлениями. В данном примере ее размер в 3 раза превышает количество потоков. Если ее сделать очень большой, это негативно скажется на общем результате, т.к. параллельности может и не добавит (смотри раздел «Запуск документов из очереди в поток»), а «расходы» на ее поддержание будут значительными.
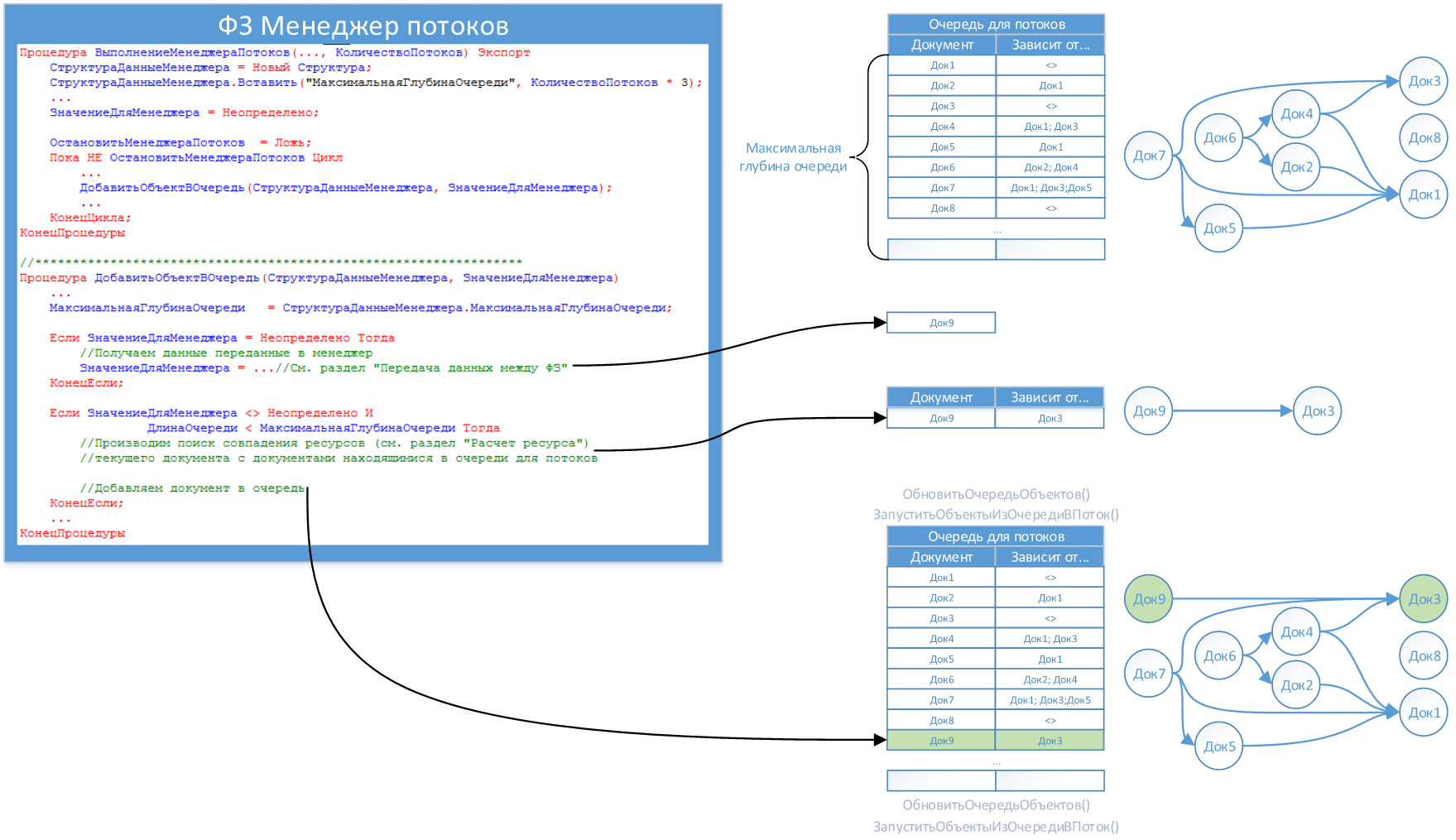
В самом начале запуска фонового задания «Менеджера потоков» определяется максимальная глубина очереди. Данное значение является предельным для добавления нового документа в очередь. В процессе работы «Менеджера потоков» вызывается процедура «ДобавитьОбъектВОчередь», которая проверяет появилось ли свободное место в очереди, рассчитывает зависимость документов на текущий момент и добавляет документ в очередь (граф).
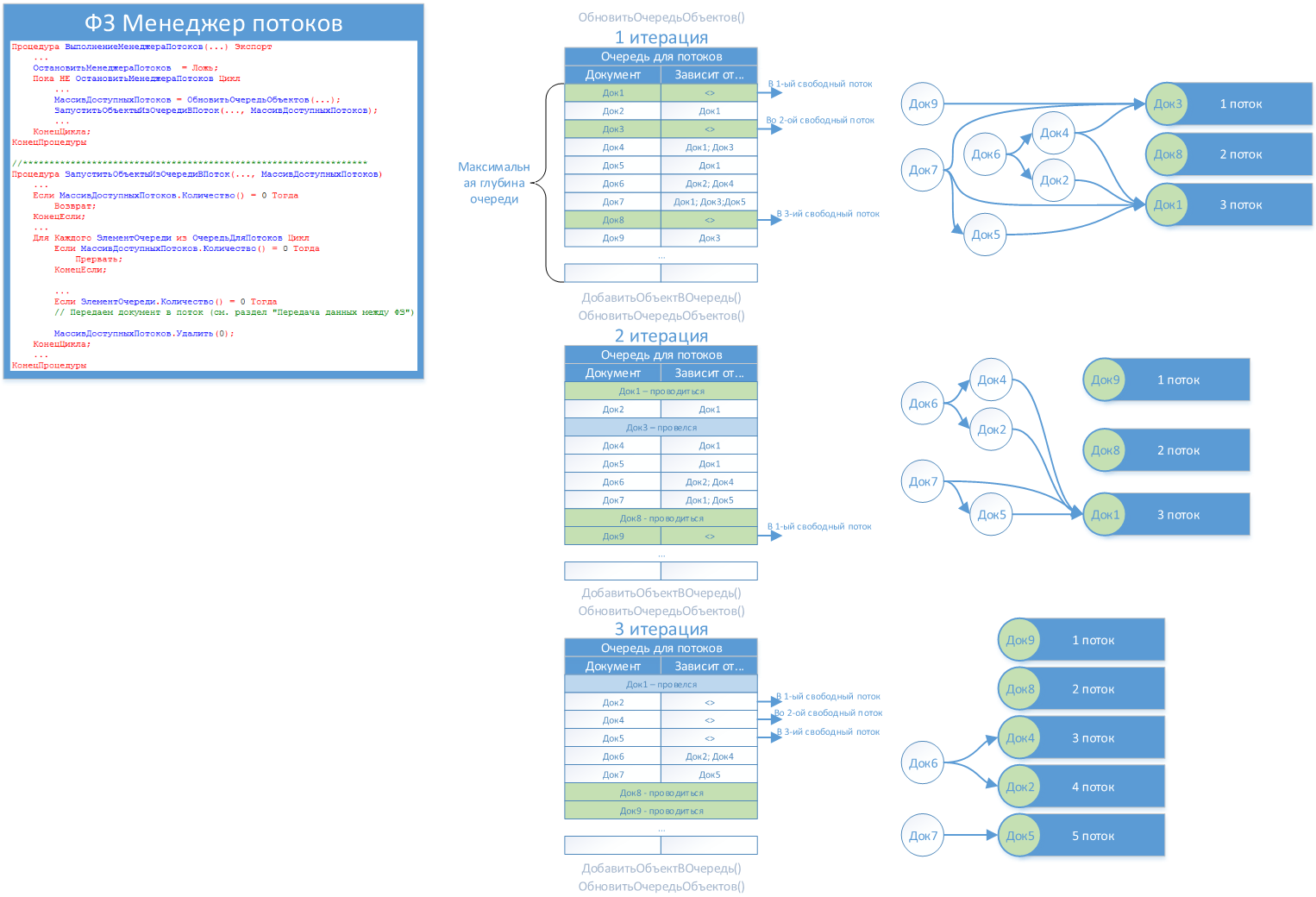
Обновление «Очереди для потоков»
В обязанности данной функции входит ряд проверок и действий, а именно:
- Определение свободных потоков;
- Перезапуск потоков в случае ошибок;
- Очистка «Очереди для потоков» от отработанных документов и от зависимости к этим документам;
- Получение «отчета» от фонового задания о том, как прошла обработка документа (был ли отказ) – см. раздел «Обработка ошибок».
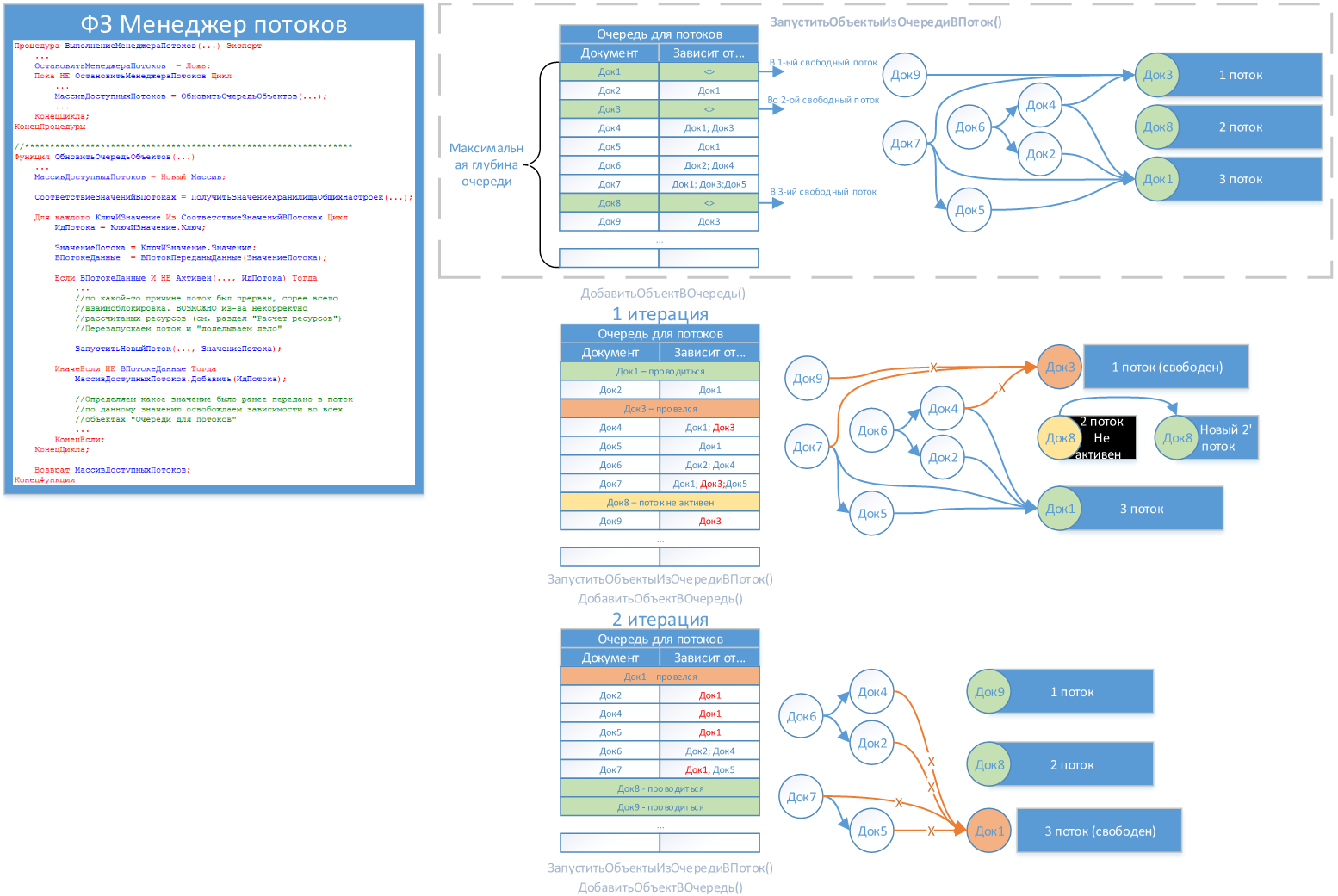
Запуск документов в поток
Суть данной процедуры достаточно проста. Она производит передачу независимых документов в свободные потоки.
На каждой итерации цикла проверяется если ли свободные потоки и «независимые» документы в графе. Каждый «независимый» документ направляется в отдельный поток. Если количество «независимых» документов превышает количество свободных потоков, то они ждут распределения в следующих итерациях.
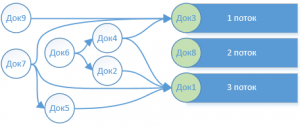
На первой итерации видно, что независимых документов в нашем графе – 3 шт. Каждый из них направляется в свой поток.
На второй итерации один из ранее проведенных документов (Док3) был проведен. От него уже освобождены (функцией ОбновитьОчередьОбъектов()) зависимые документы (Док4, Док7, Док9). Документ «Док9» стал «независимым» и он направляется в свободный поток.
На третьей итерации все повторяется, провелся «Док1». Освобождаются от зависимости четыре документа (Док2, Док4, Док5, Док7), три из которых становятся «Независимыми» и отправляются в потоки.
Обработка ошибок
Upd: Данный механизм претерпел значительные изменения — Универсальный менеджер потоков 2.0
При отработке фоновых заданий хорошо бы знать, какие документы отработали, а по каким прошел «Отказ».
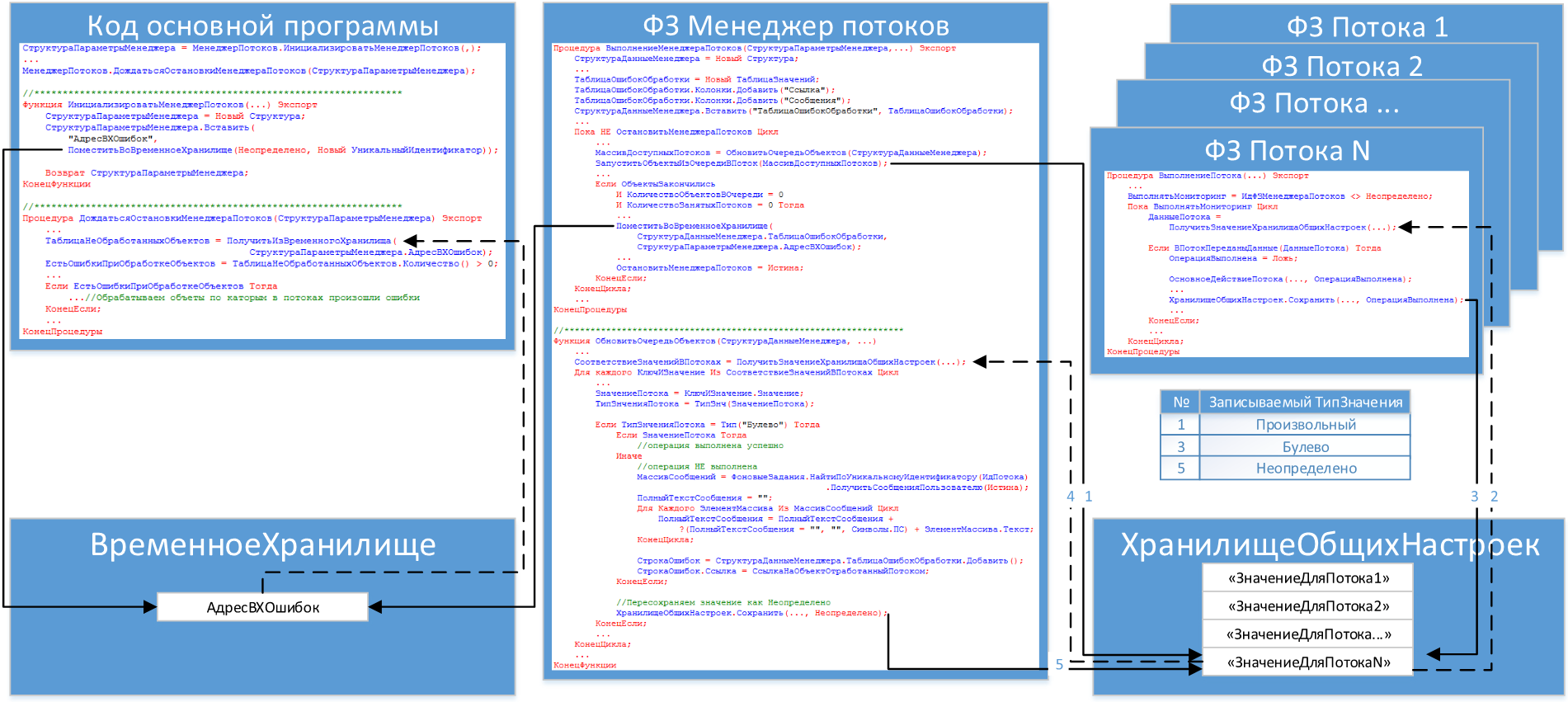
Все начинается с кода основной программы, где в функции «ИнициализироватьМенеджерПотоков()» получается адрес «АдресВХОшибок» временного хранилища, куда необходимо вернуть информацию по ошибкам. Данный адрес отправляется в «Менеджер потоков». В «Менеджере потоков» на каждой итерации цикла в «Очередь для потоков» по возможности добавляется информация (Структура). Поток, получив данную структуру обрабатывает документ и в это же значение «ЗначениеДляПотока» записывает результат выполнения (Булево). На одной из следующих итерация «Менеджер потоков» считывает значение «ЗначенияДляПотоков» в процедуре «ОбновитьОчередьОбъектов» и определяет тип и значение переменной. Если там:
- «Неопределено» — значит поток свободен;
- «Булево» — «Да» — обработка документа завершена успешно. Перезаписываем значение в «Неопределено». Поток свободен;
- «Булево» — «Нет» — обработка документа завершена с ошибкой. Перезаписываем значение в «Неопределено», сохраняем ссылку и сообщения пользователю в таблицу для дальнейшей передачи в код «основной программы». Поток свободен;
- «Струкутра» — поток еще занят.
После того, как в «Менеджере потоков» выполняется условие завершения работы. Список ошибок сохраняется во временном хранилище по адресу «АдресВХОшибок». На основании ошибочных документов определяется на какой момент времени сдвинуть границу последовательности.
Если ошибок нет – граница устанавливается на последний документ последовательности.
Если есть ошибки, рассчитывается минимальный момент времени среди ошибочных документов, в последовательностях (Упр. и Бух.) находиться предыдущие ему документы и для каждой последовательности устанавливается своя граница.
Функция ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков()
Данная функция получает структуру параметров необходимых при инициализации "МенеджераПотоков".

- Параметры функции:
- РазрезМенеджеров (Тип: Строка) – произвольный идентификатор текущего экземпляра менеджера потоков. Отвечает за разделение данных и ветвление алгоритмов описанных разработчиком (см. раздел «Функция ОбработатьСобытиеРазработчика») между несколькими одновременно запущенными Менеджерами потоков.
- Возвращаемое значение: – Тип: Структура
- РазрезМенеджеров (<РазрезМенеджеров>) — передаваемый параметр;
- КоличествоПотоков (Тип: Число) – отвечает за количество запущенных потоков для обработки информации (по умолчанию: 10);
- МодульОбработкиСобытийРазработчика (Тип: Неопределено / Строка / ДвоичныеДанные) – определяет, где располагаются алгоритмы разработчика (см. раздел «Функция ОбработатьСобытиеРазработчика»)
- Неопределено – в общем модуле «МенеджерПотоков»;
- Строка «ПутьДоМодуля.ИмяФункции» — в произвольном модуле БД;
- ДвоичныеДанные — в модуле объекта произвольной внешней обработки (по умолчанию: Неопределено). Двоичные данные сформированы на основании месторасположения текущей обработки (см. Демо обработки — перезапись элементов справочников);
- СтруктураПараметрыМенеджера (Тип: Структура) – Структура с параметрами для передачи их из основной программы в менеджер потоков. Если не определять, будет сформирована базовая структура параметров (по умолчанию: Неопределено);
- ВестиМониторингОчередиМенеджера (Тип: Булево) – Флаг отвечает за запись данных о наполнении менеджера потоков (по умолчанию: Ложь) (См. раздел «Отчеты»);
- ВестиМониторингПотоков (Тип: Булево) – Флаг отвечает за запись данных о работе потоков (по умолчанию: Ложь) (См. раздел «Отчеты»);
- ВестиМониторингПорядкаОбработки (Тип: Булево) – Флаг отвечает за запись данных о порядке обработки объектов (по умолчанию: Ложь)(См. раздел «Отчеты»);
- ПределКоличествоПопытокОбработатьОбъект (Тип: Число) — Количество попыток обработать объект. По достижению предела объект будет пропущен (по умолчанию: 5). Не доступно в демо-режиме;
- КоэффициентКратностиОчередиПотоковКПотокам (Тип: Число) — Коэффициент влияющий на размер "Очереди потоков" (по умолчанию: 3). Не доступно в демо-режиме.
Функция ИнициализироватьМенеджерПотоков()
Данная функция является основной, при настройке менеджера потоков, предназначена для инициализации работы в потоках и установки начальных параметров менеджера потоков.
Вызов данной функции осуществляется в начале работы. Примерная схема работы функции:


Процедура «ОбработатьОбъект()»
Upd: По мимо данной процедуры, появились НОВЫЕ — Универсальный менеджер потоков 2.0
Данная процедура является «подменной» первоначального однопоточного выполнения.

Параметры функции:
- «СтруктураПараметрыМенеджера» (Тип: Структура) – Структура полученная после вызова функции «ИнициализироватьМенеджерПотоков» — см. раздел «Функция ИнициализироватьМенеджерПотоков»;
- «ОбрабатываемыйОбъект» (Тип: Произвольный) – Ссылка на обрабатываемый объект
- «ЗначениеДляМенеджера» (Тип: Структура) – Произвольный набор параметров передаваемый в менеджер потоков.
«ОбрабатываемыйОбъект» автоматически включается в структуру «ЗначениеДляМенеджера».
Функция «ОбработатьСобытиеРазработчика()»
Upd: Данный раздел претерпел значительные изменения — Универсальный менеджер потоков 2.0
В принципе это единственная функция, куда разработчику необходимо вносить свой код. Вызов данной функции по умолчанию настроен из разных мест и позволяет в достаточной степени влиять на алгоритм.
Из какого места, какое событие вызывается показано на следующем рисунке.
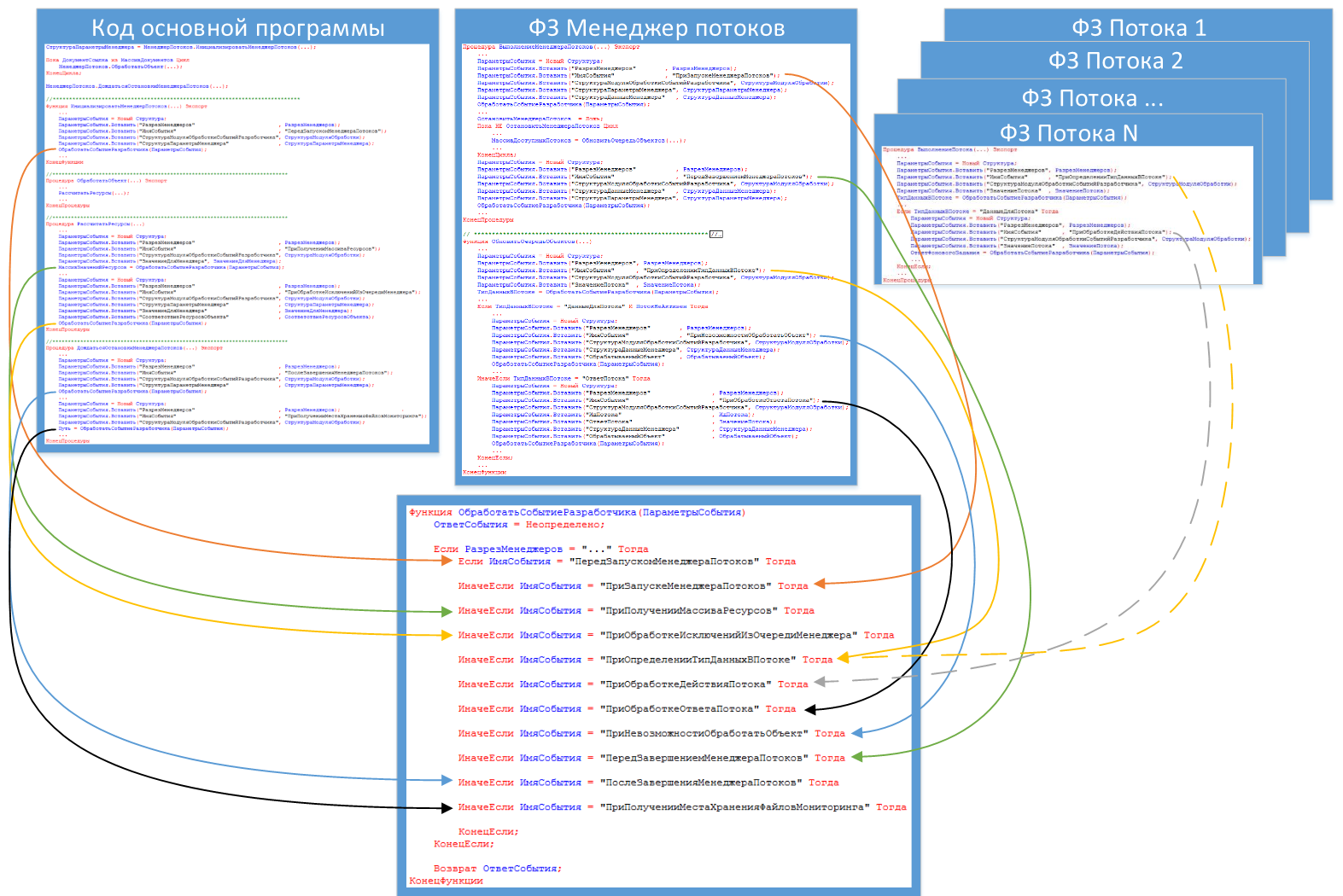
У данной функции всего 1 параметр и одно значение возврата:
- ПараметрыСобытия – Структура параметров необходимая событиям, у каждого события свой состав, но при этом 3 параметра обязательные:
- РазрезМенеджеров — текстовая переменная, (см. "РазрезМенеджеров").
- ИмяСобытия – текстовая переменная, по умолчанию может принимать одно из следующих значений:
- «ПередЗапускомМенеджераПотоков»;
- «ПриЗапускеМенеджераПотоков»;
- «ПриПолученииМассиваРесурсов» как функция;
- «ПриОбработкеИсключенийИзОчередиМенеджера»;
- «ПриОпределенииТипДанныхВПотоке» как функция;
- «ПриОбработкеДействияПотока» как функция;
- «ПриОбработкеОтветаПотока»;
- «ПриНевозможностиОбработатьОбъект»;
- «ПередЗавершениемМенеджераПотоков»;
- «ПослеЗавершенияМенеджераПотоков»;
- «ПриПолученииМестаХраненияФайловМониторинга» как функция.
- СтруктураМодуляОбработкиСобытийРазработчика – Структура хранящая информацию о том, где находятся алгоритмы разработчика
- События выступающие в роли функции могут вернуть определенные результаты в переменную «ОтветСобытия»:
- «ПриПолученииМассиваРесурсов» — типы: Массив (См. раздел «Расчет ресурса») / Неопределено (по умолчанию));
- «ПриОпределенииТипДанныхВПотоке» — Тип: Строка
- «ДанныеДляПотока»;
- «ОтветПотока»;
- «Неопределено» (по умолчанию);
- «ПриОбработкеДействияПотока» — Произвольный (по умолчанию — Неопределено);
- «ПриПолученииМестаХраненияФайловМониторинга» — Строка / Неопределено (по умолчанию).
Месторасположение функции «ОбработатьСобытиеРазработчика()»
Данная функция, состоит из 2х частей:
- Базовой (находится в общем модуле «МенеджерПотоков»);
- Вспомогательная (может находиться в произвольном модуле или во внешней обработке).
В общем модуле «МенеджераПотоков»
Тут все, как обычно, находим данную функцию и начинаем вставлять свои алгоритмы.
Плюсы:
- Весь алгоритм распараллеливания находиться в одном модуле (на самом деле сомнительный плюс J);
- Можно проследить ход выполнения отладчиком;
Минусы:
- При обновлении (если будут выпускаться новые редакции «Универсального менеджера потоков» — зависит заинтересованности сообщества и реализации новых идей), придется не просто заменить модуль, но еще и перенести свои алгоритмы.
В произвольном модуле БД (рекомендуемый)
В данном случае мы описываем экспортную функцию в произвольном модуле, который можем вызвать из отчета или обработки («Общий модуль» / «Модуль объекта» / …);
Изначально будет сделан вызов «базовой части» — функции «ОбработатьСобытиеРазработчика()» из общего модуля «МенеджерПотоков», а затем перенаправлен в необходимый произвольный модуль. Куда будут перенаправляется вызовы определятся при инициализации менеджера потоков.
Плюсы:
- Простой способ обновления (если будут обновления) «Универсального менеджера потоков»
- Модулей может быть неограниченное количество;
- Можно проследить ход выполнения отладчиком;
Минусы:
- Изменение метаданных;
Во внешней обработке
Данный способ подойдет для написания внешних обработок, т.к. позволяет описать алгоритм ТОЛЬКО в модуле обработки без корректировок БД.
ВНИМАНИЕ!!! По умолчанию создание обработки происходит в «безопасном режиме», что накладывает ряд ограничений.
- привилегированный режим отменяется, если он был установлен;
- попытки перехода в привилегированный режим игнорируются;
- запрещены операции с COM-объектами;
- запрещена загрузка и подключение внешних компонентов;
- запрещен доступ к файловой системе (кроме временных файлов);
- запрещен доступ к Интернету.
Изменение данного параметра устанавливается в
«Функция ПолучитьСтруктуруМодуляОбработчикаСобытийРазработчика(РазрезМенеджеров)»
Строка:
ОбъектМодуль = ВнешниеОбработки.Создать(ИмяТемпФайла, Ложь / Истина);
Истина – Безопасный режим;
Ложь – НЕ безопасный режим.
По причине того, что в демо обработке необходимо сохранять файл(ы) – "безопасный режим" необходимо отключить в модуле «МенеджерПотоков».
Плюсы:
- Простой способ обновления (если будут обновления) «Универсального менеджера потоков»
- Не требует изменение метаданных (если уже есть общий модуль «МенеджерПотоков»);
Минусы:
- Невозможно пройти отладчиком события разработчика 🙁
События функции «ОбработатьСобытиеРазработчика()»
Все параметры, передаваемые в данную функцию передаются через структуру «ПараметрыСобытия». Параметры по умолчанию:
- «РазрезМенеджеров» — см. раздел «функция ИнициализироватьМенеджерПотоков()»
- «ИмяСобытия» — строка и предопределенным именем события:
- «ПередЗапускомМенеджераПотоков»;
- «ПриЗапускеМенеджераПотоков»;
- «ПриПолученииМассиваРесурсов»;
- «ПриОбработкеИсключенийИзОчередиМенеджера»;
- «ПриОпределенииТипДанныхВПотоке»;
- «ПриОбработкеДействияПотока»;
- «ПриОбработкеОтветаПотока»;
- «ПриНевозможностиОбработатьОбъект»
- «ПередЗавершениемМенеджераПотоков»;
- «ПослеЗавершенияМенеджераПотоков»;
- «ПриПолученииМестаХраненияФайловМониторинга».
- «СтруктураМодуляОбработкиСобытийРазработчика» — служебная структура для определения вызова событий разработчика;
Событие: «ПередЗапускомМенеджераПотоков»
Место вызова: Код основной программы;
Принцип работы: Как процедура;
Доступные параметры:
- «СтруктураПараметрыМенеджера»
- Служебные параметры (РазрезМенеджеров, СтруктураМодуляОбработкиСобытийРазработчика, ВестиМониторингПотоков, ВестиМониторингПорядкаОбработки, АдресВХМониторингПотоков, АдресВХМониторингПорядкаОбработки)
- Дополнительные произвольные параметры переданные в функцию ИнициализироватьМенеджерПотоков() в параметр «СтруктураПараметрыМенеджера» (см. раздел «функция ИнициализироватьМенеджерПотоков()»)
Назначение: Позволяет передавать произвольные данные из основной программы в «Менеджер потоков»
Назначение в рамках восстановления партий: Определяет адрес во временном хранилище, куда вернуть таблицу значений с ошибками при восстановлении партий.
Событие: «ПриЗапускеМенеджераПотоков»
Место вызова: Фоновое задание «МенеджерПотоков»;
Принцип работы: Как процедура;
Доступные параметры:
- «СтруктураПараметрыМенеджера» — см. событие «ПередЗапускомМенеджераПотоков»;
- «СтруктураДанныеМенеджера»
- Служебные параметры (РазрезМенеджеров, СтруктураМодуляОбработкиСобытийРазработчика, СоотвествиеВедущийВедомые, СоотвествиеВедомыйВедущие, СоотвествиеОбъектРесурсы, СоотвествиеРесурсОбъекты, СоотвествиеПотокДанныеПотока, СоотвествиеОбъектПараметры, МаксимальнаяГлубинаОчереди)
Назначение: Позволяет выполнять произвольный алгоритм в самом начале запуска менеджера потоков, еще до запуска самих потоков.
Назначение в рамках восстановления партий: Создает временный объект (таблицу значений) для консолидации ошибок восстановления партий.
Событие: «ПриПолученииМассиваРесурсов»
Место вызова: Код основной программы;
Принцип работы: Как функция. Допустимые типы данных:
- Неопределено (по умолчанию);
- Массив – см. раздел «Расчет ресурса».
Доступные параметры:
- «ЗначениеДляМенеджера» — Структура для передачи в потоки (см. раздел Процедура «ОбработатьОбъект»);
Назначение: Описывает алгоритм получения массива «МассивЗначенийРесурсов» (см. раздел «Расчет ресурса»). Данное событие нужно, только если необходимо формировать зависимость обработки одних объектов от других
Назначение в рамках восстановления партий: Заполняет массив ресурсов для возможности распараллелить процесс восстановления партий.
Событие: «ПриОбработкеИсключенийИзОчередиМенеджера»
Место вызова: Код основной программы;
Принцип работы: Как функция. Допустимые типы данных:
- Неопределено (по умолчанию — включить в очередь);
- Булево (Истина — включить в очередь; Ложь — исключить из очереди).
Доступные параметры:
- «СтруктураПараметрыМенеджера» — см. событие «ПередЗапускомМенеджераПотоков»;
- «ЗначениеДляМенеджера» — Структура для передачи в потоки (см. раздел Процедура «ОбработатьОбъект»);
- «СоответствиеРесурсовОбъекта» — см. раздел «Расчет ресурса».
Назначение: Описывает алгоритм условий исключения объекта из очереди менеджера. По умолчанию все объекты добавляются в очередь менеджера.
Назначение в рамках восстановления партий: Исключает документы, не имеющие ресурсов, те по которым не надо восстанавливать последовательность.
Событие: «ПриОпределенииТипДанныхВПотоке»
Место вызова: Фоновое задание «МенеджерПотоков» / Фоновые задания потоков;
Принцип работы: Как функция. Допустимые типы данных:
- Неопределено (по умолчанию);
- Строка (Допустимые значения «ДанныеДляПотока» / «ОтветПотока» / «Неопределено»).
Доступные параметры:
- «ЗначениеПотока» — Структура, переданная в поток для обработки;
Назначение: Описывает алгоритм по которому определяется, что в «ЗначениеПотока» — храниться «ДанныеДляПотока» / «ОтветПотока» / «Неопределено».
Назначение в рамках восстановления партий: Если в «ЗначениеПотока» переменная «Булево» — значит это «ОтветПотока». Да – документ восстановлен. Нет – ошибка при восстановлении. Если «Структура», то по умолчанию – это «ДанныеДляПотока», а если Неопределено – «Неопределено» — поток Свободен.
Событие: «ПриОбработкеДействияПотока»
Место вызова: Фоновые задания потоков;
Принцип работы: Как функция. Допустимые типы данных:
- Неопределено (по умолчанию);
- Произвольный;
Доступные параметры:
- «ЗначениеПотока» — Структура, переданная в поток для обработки;
Назначение: Содержит основной алгоритм обработки объекта.
Назначение в рамках восстановления партий: Вызывает процедуру восстановления партий по переданному документу.
Событие: «ПриОбработкеОтветаПотока»
Место вызова: Фоновое задание «МенеджерПотоков»;
Принцип работы: Как процедура;
Доступные параметры:
- «ИдПотока» (Тип: Уникальный идентификатор) – УИД фонового задания, вернувшего ответ;
- «ОтветПотока» (Тип: Произвольный) – Данные возвращенные событием «ПриОбработкеДействияПотока»;
- «СтруктураДанныеМенеджера» — см. событие «ПриЗапускеМенеджераПотоков»;
- «ОбрабатываемыйОбъект» — ссылка на обрабатываемый объект (см. раздел «Процедура ОбработатьОбъект()»)
Назначение: Если требуется обрабатывать ответ от потока, то тут описывается что необходимо сделать.
Назначение в рамках восстановления партий: Если документ «провелся» — ничего не делаем J. Если же нет – тогда записываем информацию в таблицу значений описанную в событии «ПриЗапускеМенеджераПотоков».
Событие: «ПриНевозможностиОбработатьОбъект»
Место вызова: Фоновое задание «МенеджерПотоков»;
Принцип работы: Как процедура;
Доступные параметры:
- «СтруктураДанныеМенеджера» — см. событие «ПриЗапускеМенеджераПотоков»;
- «ОбрабатываемыйОбъект» — ссылка на обрабатываемый объект (см. раздел «Процедура ОбработатьОбъект()»)
Назначение: Событие вызывается после всех попыток («ПределКоличествоПопытокОбработатьОбъект») обработать объект, но до очистки информации о нем в «Менеджере потоков». Позволяет, например, записать объект в ошибки и вывести информацию после завершения работы «МенеджераПотоков»
Событие: «ПередЗавершениемМенеджераПотоков»
Место вызова: Фоновое задание «МенеджерПотоков»;
Принцип работы: Как процедура;
Доступные параметры:
- «СтруктураПараметрыМенеджера» — см. событие «ПередЗапускомМенеджераПотоков»;
- «СтруктураДанныеМенеджера» — см. событие «ПриЗапускеМенеджераПотоков».
Назначение: Позволяет выполнять произвольный алгоритм перед завершением менеджера потоков, но до очистки ХранилищеОбщихНастроек.
Назначение в рамках восстановления партий: Сохраняем заполненную таблицу значений, созданную в событии «ПриЗапускеМенеджераПотоков» во временном хранилище по адресу определенному в событии «ПередЗапускомМенеджераПотоков»
Событие: «ПослеЗавершенияМенеджераПотоков»
Место вызова: Код основной программы;
Принцип работы: Как процедура;
Доступные параметры:
- «СтруктураПараметрыМенеджера» — см. событие «ПередЗапускомМенеджераПотоков»;
Назначение: Произвольный алгоритм, после того как дождались остановки «Менеджера потоков»
Назначение в рамках восстановления партий: Получаем таблицу значений с ошибками обработки документов и сохраняем ее на диск в формате Excel. На основании данной таблицы определяем куда переместить границы последовательности.
Событие: «ПриПолученииМестаХраненияФайловМониторинга»
Место вызова: Код основной программы;
Принцип работы: Как функция. Допустимые типы данных:
- Строка – путь к папке куда будут сохранены отчеты мониторинга, если они были включены при инициализации менеджера потоков (см. раздел «Функция ИнициализироватьМенеджерПотоков()»);
Назначение: Определяет место сохранения файлов отчетов мониторинга, если он был включен при инициализации менеджера потоков.
Вариант передачи данных между событиями
Upd: Теперь используется новый механизм обмена — Универсальный менеджер потоков 2.0
Отчеты
Upd: Отчеты обновлены — Универсальный менеджер потоков 2.0
По умолчанию предоставлена возможность формировать 3 отчета:
- «Мониторинг порядок обработки» — фиксирует на какой итерации «Менеджера потоков» завершилась обработка объектов. Состав:
- «Ссылка» — Ссылка на обработанный объект;
- «НомерИтерации» — Номер итерации «Менеджера потоков» на которой завершилась обработка объекта.
- «Мониторинг потоков» — фиксирует на каждой итерации «Менеджера потоков» — количество объектов в «Очереди для потоков», количество занятых потоков и количество отработанных объектов. Состав:
- «ВремяВмс» — ТекущаяУниверсальнаяДатаВМиллисекундах();
- «НомерИттерации» — Номер итерации «Менеджера потоков» на которой снимаются значения;
- «ОбъектовВОчереди» — количество объектов в «Очереди для потоков»;
- «КоличествоЗанятыхПотоков» — количество потоков, занятых на текущей итерации;
- «КоличествоОбработанныхОбъектов» — количество объектов завершивших свою обработку на текущей итерации;
- «Мониторинг очереди менеджера» — фиксирует количество документов в «Очереди менеджера». Состав:
- «ВремяВмс» — ТекущаяУниверсальнаяДатаВМиллисекундах();
- «ОбъектовВОчередиМенеждера» — Общее количество документов в «Очереди менеджера»;
Их включение осуществляется в процедуре «ИнициализироватьМенеджерПотоков()» (См. Раздел «Функция ИнициализироватьМенеджерПотоков()»)
«Мониторинг порядок обработки» и «Мониторинг потоков» заполняются в фоновом задании «Менеджера потоков», а «Мониторинг очереди менеджера» в коде основной программы.
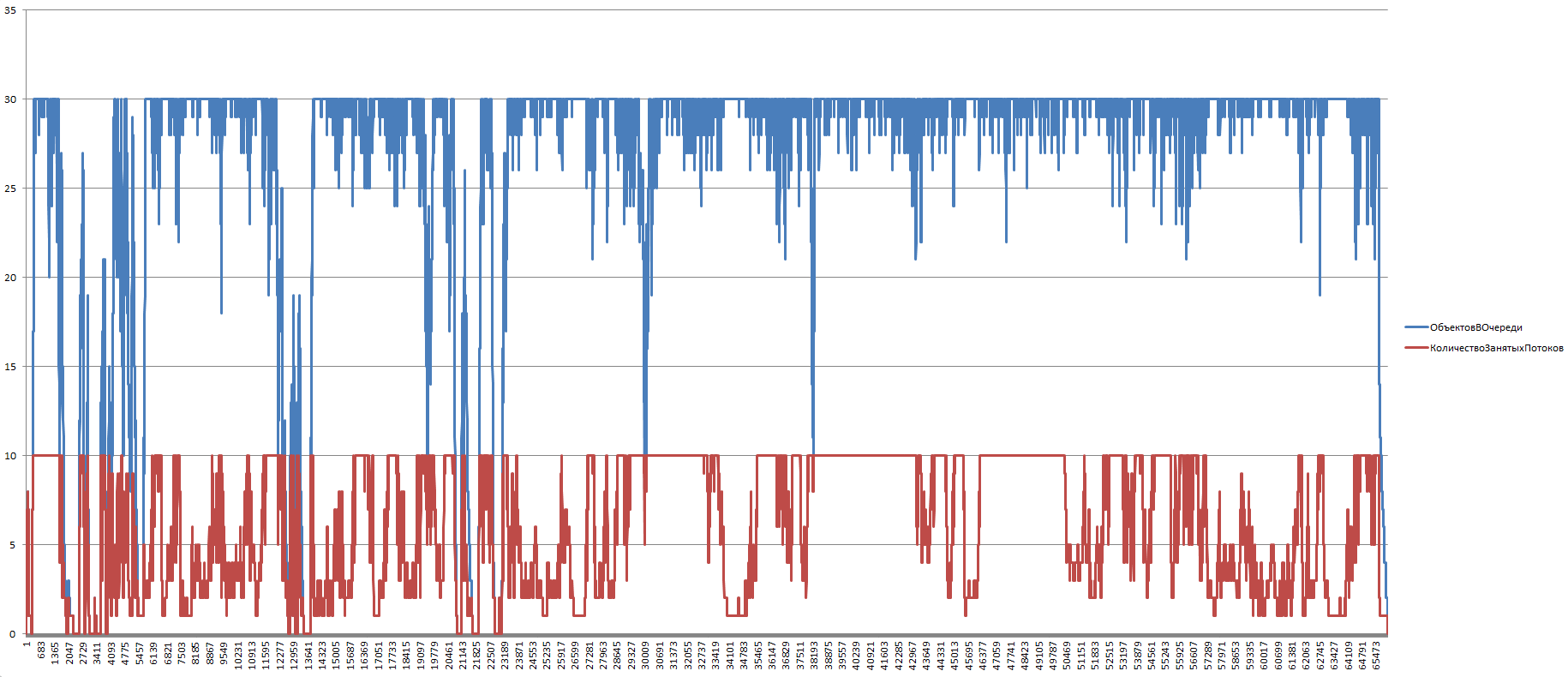
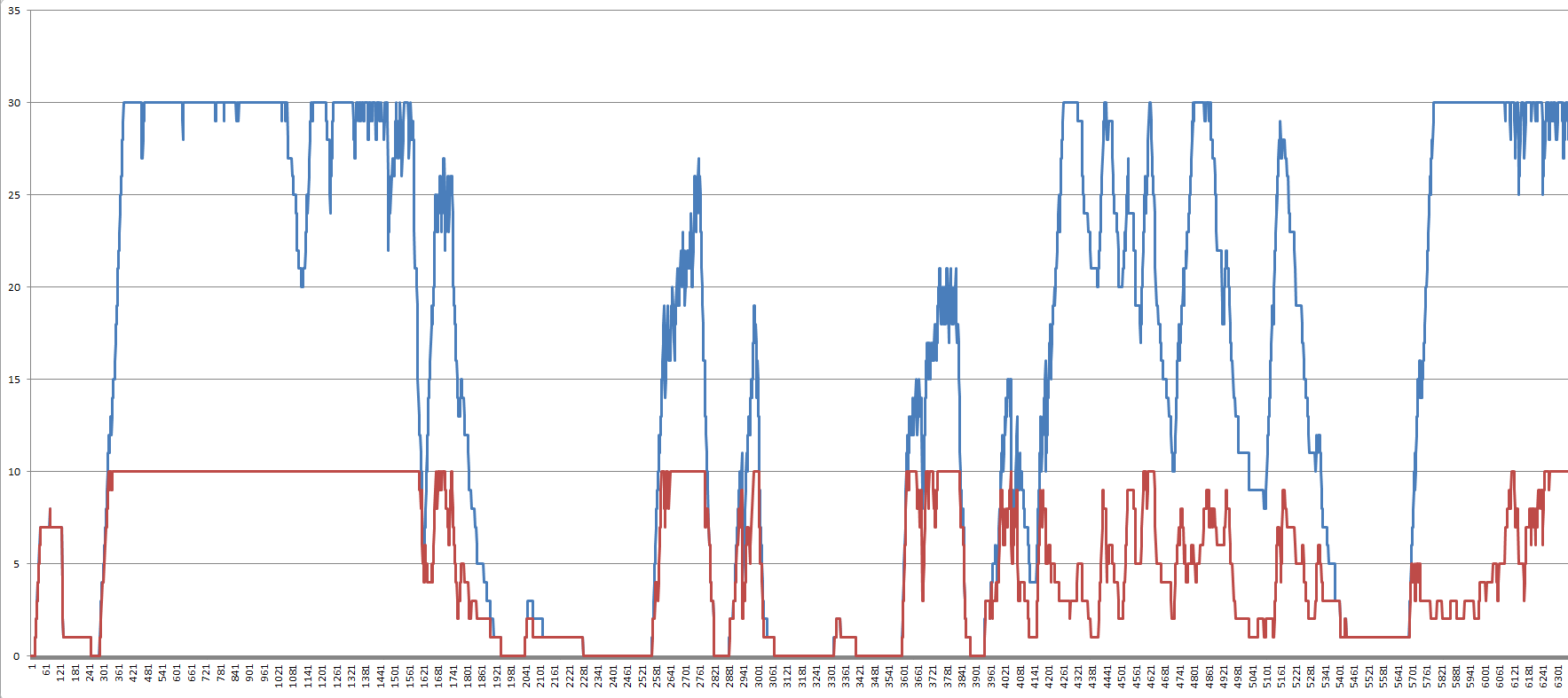
«Мониторинг потоков» и «Мониторинг очереди менеджера» — в большинстве своем больше информационные и позволяют построить графики. Графики из рассматриваемого примера «Восстановление партий»:
Ноябрь 2026 мониторинг потоков (полный)
Ноябрь 2026 мониторинг потоков (начало укрупненно)
Ноябрь 2026 Мониторинг очереди менеджера

графики по всем месяцам в архиве
На всех графиках «Мониторинг очереди менеджера» последней «прямолинейный» спуск — это обработка документов в процедуре «ДождатьсяОстановкиМенеджераПотоков()» уже после того как отработал основной цикл перебора документов в последовательности.
Количество отчетов можно расширить с помощью функции «ОбработатьСобытиеРазработчика()». При восстановлении партий формируется дополнительный отчет по необработанным документам с описанием ошибки. Так же на основании данного отчета определяется куда перенести границу последовательности после окончания работы восстановления партий.
Все отчеты сохраняются в файл на том компьютере, откуда вызван основной цикл обхода документов. Место сохранения описывается в функции «ОбработатьСобытиеРазработчика()», событие «ПриПолученииМестаХраненияФайловМониторинга».
Демо обработки
Каждая обработка позволяет вызывать любой способом месторасположение функции «ОбработатьСобытиеРазработчика()» (см. раздел «Месторасположение функции «ОбработатьСобытиеРазработчика()»»):
- В общем модуле «МенеджераПотоков»
- В произвольном модуле БД
- Во внешней обработке
Все инструкции, что необходимо сделать написаны в каждой обработке в модуле объекта.
В демо примерах представлены 2 вида обработок выполняющие одно действие:
1. Формирование расчетных листов по сотрудникам и сохранение их на ПК (только для УПП 1.3).
В каждой обработке есть 2 способа формирования расчетных листков («независимый» и с построением зависимости объектов), и три варианта обработки результата, что в конечном итоге дает 6 вариантов обработки:
- Независимое формирование (сохраняем на сервере потока);
- Независимое формирование (сохраняем на сервере менеджера);
- Независимое формирование (сохраняем на клиенте);
- Зависимость по 1-ой букве (сохраняем на сервере потока);
- Зависимость по 1-ой букве (сохраняем на сервере менеджера);
- Зависимость по 1-ой букве (сохраняем на клиенте);
«Независимое формирование» — Это формирование отчетов полностью параллельно, без всякой зависимости.
«Зависимость по 1-ой букве» — это формирование с построением зависимости (графа), где сотрудники, фамилии которых начинаются на одну и ту же букву выстраиваются в очередь, а если буквы не совпадают, то как при независимом формировании (зависимость ненесет ни какой практической цели — просто коказано как ее добиться).
3 варианта обработки результата, показывают, как происходит обмен данными между основной программой / Менеджером потоков / фоновыми заданиями.
Варианты обработки (от простого к сложному – по количеству кода):
- (сохраняем на сервере потока) – В данном варианте передача данных идет только от клиента, через "менеджер потоков" на потоки, где каждый поток сохраняет файл;
- (сохраняем на сервере менеджера) – тут посложнее, данный вариант повторяет первый, но файл не сохраняется в потоке, а ответ (табличный документ) передается обратно в менеджер потоков, где данные консолидируются и в конце перед завершением менеджера потоков файлы начинают сохраняться на сервер, где работал менеджер потоков.
- (сохраняем на клиенте) – ну и самый сложный вариант, повторяет второй, но опять файлы не сохраняются на диск, а передаются через временное хранилище на клиент, где и производят сохранение данных на диск.
Итого для ознакомления предоставлено 18 примеров работы (3 варианта расположения * 2 способа формирования * 3 варианта обработки результата)
Таблица возможности запуска обработки (Только для УПП 1.3):
| Вызов событий | Демо | Для разработчика | Полная |
| В произвольном модуле | + | + | + |
| Во внешней (этой) обработке | + | -* | -/+** |
| В модуле менеджера потоков | -*** | -*** | + |
"+" — можно запустить
"—" — нельзя запустить
* — из-за безопасного режима;
** — по умолчанию безопасный режим включен, но его можно отключить;
*** — из-за закрытого кода.
2. Перезапись N-элементов произвольного справочника (любая БД)
В каждой обработке есть 2 способа перезаписи "независимы" и с зависимостью
"Независимая перезапись" — это перезапись полностью параллельно без всякой зависимости;
"Зависимость по четности кода" — выстраивает очередь по четным и нечетным кодам (инициализировать можно любое количество потоков, но одновременно будет занято 1-2 потока)
Вот результат простой перезаписи 500 ед. номенклатуры в УПП (колебания от 9 до 16 потоков между 7-8 сек связаны скорее всего с тем, что начало/конец замера происходили вначале/вконце секунды):
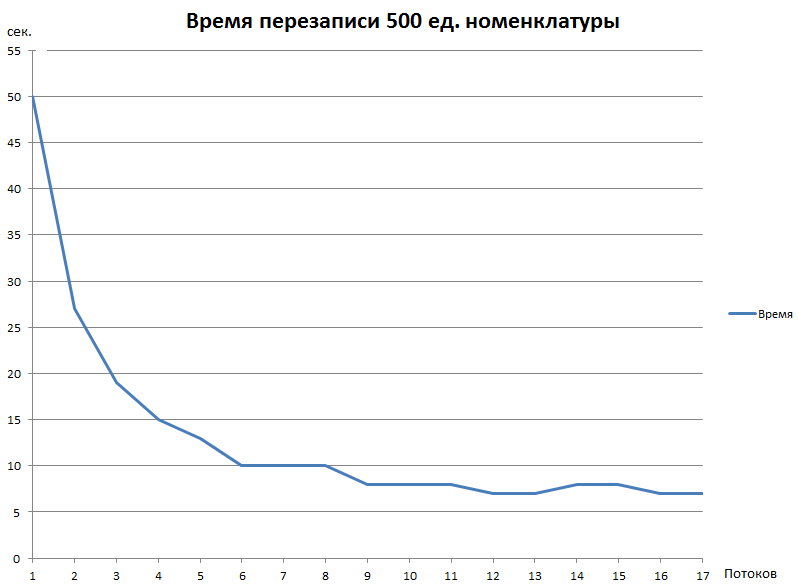
Таблица возможности запуска обработки:
| Вызов событий | Демо | Для разработчика | Полная |
| В произвольном модуле | + | + | + |
| Во внешней (этой) обработке | + | + | -/+* |
| В модуле менеджера потоков | +** | -*** | + |
"+" — можно запустить
"—" — нельзя запустить
* — по умолчанию безопасный режим включен, но его можно отключить;
** — код закрыт, но для данной обработки код уже встроен;
*** — из-за закрытого кода;
Менеджер потоков (Демо)
Upd: Полная версия, полностью открытый код и только за $m. — Универсальный менеджер потоков 2.0
Предоставил файл поставки конфигурации с общим модулем (закрыт от редактирования). Имеет ряд ограничений по сравнению с полной версией:
- Максимальное количество потоков = 3;
- Значения в общих настройках сохраняются с префиксом "Демо_";
- Обработка событий разработчика из внешних обработок в НЕ безопасном режиме;
- "Замедленно" получение Значений из хранилища общих настроек;
- Используется не оптимальный (ранний вариант) способ передачи данных между основной программой и "Менеджером потоков";
- Используется не оптимальный (ранний вариант) построение графа.
А так все работает. Как писал выше, для Вас модуль не представляет интереса, весь свой функционал надо выложить в функцию "ОбработатьСобытиеРазработчика()". Как? Смотрите Демо обработки.
Заключение
Upd: Продолжение — Универсальный менеджер потоков 2.0
Вот теперь, наверное, можно сказать, что я удовлетворил свое любопытство и с пользой потратил свободное время :).
Если сообщество будет заинтересовано в дальнейшем развитии данного механизма, то думаю это вполне можно реализовать. Как вариант дальнейшего развития вижу:
- Дополнительно реализовать для управляемых форм с переводом в асинхронный режим;
- Добавление новых событий;
- Формирование графа зависимости, как отчета, с весом каждого ребра;
- Программное формирование отчетов мониторинга на СКД без необходимости сохранять их в файл на клиенте;
- И прочие доработки…
Обновления
Обновление 2026 02 07:
Обновление 2026 07 13:
Новое в версии v1.0.1
- Изменен механизм Инициализации менеджера потоков;
- Изменен способ указания "МодульОбработкиСобытийРазработчика " если алгоритмы во внешней обработке. Ранее надо было передать путь к обработке, но в связи с адаптацией под УФ необходимо передать ДвоичныеДанные (пример в Демо обработке — "перезапись элементов справочников").
- Добавлена функция ПолучитьСтруктуруПараметровИнициализацииМенеджераПотоков;
- Добавлен механизм «попыток» обработать объект;
- Добавлена возможность управлять размером «Очереди потоков».
- Добавлено событие ПриНевозможностиОбработатьОбъект;
- Код адаптирован под управляемые формы (без модальности и синхронных вызовов);
- Демо обработка «Перезапись элементов справочников» получила управляемую форму;
- Демо обработка «Интерактивная остановка менеджеров потоков» получила управляемую форму;
- Исправлены ошибки.
Статья:
- Внесены исправления в тексте под новую версию;
- Исправлены ошибки;
Обновление 2026 06 09:
В статью добавлены Примеры формирования ресурсов
Related Posts
 Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается
Восстановление последовательности документов при закрытии месяца в Бухгалтерия 3.0 не завершается Заполнение табличных частей
Заполнение табличных частей Формирование сводных актов выполненных работ
Формирование сводных актов выполненных работ Ввод поступления в переработку на основании передачи сырья (между организациями)
Ввод поступления в переработку на основании передачи сырья (между организациями)- Конспект по установке сервера 1С на linux
 Получение имени компьютера и его IP локально и в терминале
Получение имени компьютера и его IP локально и в терминале
Верните картинки!
(1) Сейчас решим с модераторами
(1) Сейчас перезалью
(1) Готово!
(4) нет картинок
(5)
(6) имеется ввиду в самой публикации вместо картинок крестики
(7) А сейчас? Просто — у меня все ок. Если нет — еще раз перезалью
у меня так и так далее по всей странице
появились картинки
(9) Перезалил картинки и перебил ссылки. Теперь видно?
(10) Спасибо!
Не совсем понятны результаты до и после. Т.е. с использованием механизма и без него.
Сколько по времени занимало?
(13) Результаты из первой таблицы?
Колонки с месяцами — это месяцы за который восстанавливались партии.
Есть 2а показателя: «Однопоточное восстановление» и «Параллельное восстановление»
Первый показывает сколько времени занимало восстановление партий в типовом варианте (один поток): для восстановления партий за «Ноября 2016» при первом запуске было затрачено 293 мин. При повторном (сразу после первого) запуске — 265 мин.
При этом при использовании механизма распараллеливания тот же самый период «Ноябрь 2016» при первом запуске завершился за 30 мин, а при повторном за 24 мин.
Точно так же по остальным месяцам
Да, забыл дать пояснение, Это время при распараллеливании на 10 потоков
(13) Ответ ниже — дал без ссылки на ваше сообщение 🙂
(15) Почти линейно для 10 потоков… Не плохо…
(16) тут есть одно уточнение… По графикам ниже видно, что распараллеливание не напрямую на 10 потоков идет, а в зависимости от количеств «свободных» документов (если они в графе не зависят от других документов). Более того в обработке отключена процедура «СдвигПоследовательностиВперед» и «пропускаются» приходные документы. За счет этого и достигается ускорение близкое к х10. Если бы база была с 2 поступления на 2 склада по 1-номенклатуре и 10000 документов списания (с этих складов), то тут уже не получилось бы распараллелить больше чем на х2 :).
Вижу восстановление партий . Но в бух нет партий , а есть последовательности — с измерением Организация и СостояниеПроведения.
Ничего больше нет.
Аналогично в регистре бухгалтерии только Организация. валюта, подразделение — так что и модифицировать последовательность не удасться.
Бухи и так отдельно по организациям перепроводят.
Правильно ли понимаю — что в данном случае (типовые Бух и все что на них) — Ваша обработка никак не поможет ?
(18) На БУ не тестировал, затачивал под УПП. Но суть одна и та же. Типовые метаданные не меняются, добавляется новый общий модуль. Последовательность в УПП тоже только в разрезе «Организаций». Типовой код изменен не значительно, примерно как в «Общей схеме». Также в цикле перебираются документы подаются в «менеджер потоков» — он уже строит по документам зависимость на основании Ресурсов (см. раздел «Расчет ресурсов») — рассчитанных ВАМИ (см. раздел «Обработать события разработчика») и посылает их по потоки. Мое «Восстановление партий» можно рассматривать, как еще один вариант примеров, но у кого-то результат и на нем заработает :). Для БУ — не помню архитектуру, но по прикидкам основное распараллеливание будет по субконто 10/41/43 счетов.
(18) И да, имеется ввиду последовательность, в УПП они называются «ПартионныйУчет» и «ПартионныйУчетБУ»
(19)
Не понял. В бухии идут проводки зависящие от других проводок сделанных ранее по организации, с разными счетами и субконто. Не только ресурсы — но счета и субконто. Например — зачет авансов по документу если стоит — будут сформированы проводки по зачету авансов. Не представляю как все это можно распараллелить (в рамках одной организации)
(18) Еще дополню… При расчете «Ресурсов» вы определяете как будет выстраиваться зависимость документов. Можно сделать только по «Складу», тогда все документы у которых один и тот же склад будут выстраиваться в очередь. Можно по склад + номенклатура, тогда документы с одним складом могут проводиться параллельно если у них разный состав номенклатуры. Тут все уже будет зависеть от Вас и потребностей заказчика. Можно например реализовать (бред, но можно), не только по субконто 10/41/43 счетов, а по произвольному другому алгоритму зависимости, например, по году рождения ответственного за документ — если у ответственных за документ один и тот же год рождения, то эти документы проводятся друг за другом, а другие параллельно, но тут уже могут возникнуть блокировки и/или взаимоблокировки накладываемые архитектурными реализациями платформы. Так что распараллеливать надо то — что можно распараллелить.
(21) тут не надо путать теплое и мягкое. Последовательность партий восстанавливается своей обработкой, а последовательность взаиморасчетов своей — ни та ни другая документы не перепроводит. Они двигают свои регистры / счета. Вот в рамках этих обработок и происходит «вклинивание» и описание правил по распараллеливанию.
(23)
Вы можете хотя бы схематично/на пальцах описать как для типовой бухгалтерии 3.0 или 2.0 использовать фреймворк ?
(21) Попробую на пальцах объяснить на взаиморасчетах. Есть:
Док1 (Поступление) — Контрагент1, Договор1 5000
Док2 (Поступление) — Контрагент1, Договор2 4000
Док3 (Поступление) — Контрагент2, Договор3 3000
Док4 (Взаимозачет) — Контрагент1, Договор1 / Контрагент2, Договор3 5000 — перенос долго
Док5 (Платежка) Контрагент2, Договор3
Док6 (Платежка) Контрагент1, Договор2
что примерно приведет к тому что на рисунке. На каждой итерации будет проведено столько документов сколько показано, на первой 3, на второй 2, на третьей 1. В итоге 6 документов проведено за 3 шага, вместо 6 при стандартном подходе
Но для ресурсов Вы должны написать свой алгоритм в событии «ПриПолученииМассиваРесурсов».
(Пример взят из головы)
(24) Без проблем:
Создаете общий модуль «МенеджерПотоков» — туда переноситься весь код из модуля объекта — предоставляемой обработки. Затем по рекомендации, создаете еще один общий модуль Имя без разницы (укажите его при Инициализации) с экспортной функцией «ОбработатьСобытиеРазработчика» В этой функции на примере картинки из ( «ОбработатьСобытиеРазработчика()») описываете свой код. По обработке документа, расчету ресурсов, получению ответ ну в принципе и все
(24) Как писать код можно посмотреть в домообработках (скачать можно бесплатно). Например в «РЛ-Параллельно (события в произвольном модуле)»
(24) Ваш вариант (если не надо получать ответ от потоков) —
ИначеЕсли РазрезМенеджеров = «РЛ — Зависимость по 1-ой букве (сохраняем на сервере потока)» Тогда
…..
(25) Перепутал местами на скрине 2 и 3 документ
За что я только что заплатил 10 $m ?!
(30) еще 10000руб предстоит заплатить чтобы все увидеть 🙂
(31) действительно =)
(30) Есть вопросы? Готов ответить.
(30) Завтра, напишу ещё демообработки «по универсальнее» с функцией перезаписи N-элементов произвольного справочника. Предоставив пользователю возможность выбрать справочник, количество потоков и количество перезаписываемых элементов
(30) Добавил новые демообработки, как сообщал ранее.
Знакомы ли с этой разработкой? Если да, то что в ней не устроило?
(36) А если нет?
Действительно с этой разработкой не знаком, и не смогу сейчас привести примеры отличий. Если Вы с ней знакомы или есть знающий знакомый, можем пообщаться в чате и составить карту отличий (если Вы в этом заинтересованы).
Бегло я попытался поглядеть, что в цф-ке. Но готовых тестовых примеров не нашел, так что сложно оценить «что», «как» и «где» должен писать разработчик работающий с предоставленным Вами модулем.
Могу кратко описать, что может мой модуль:
* Модуль состоит только из одного общего модуля без регистров и перечислений (подглядел в цф-ке)
* Автоматическое построение зависимости объектов для обработки (что позволяет реализовать восстановление партий, о чем говориться в статье);
* отдельно выделенный, от модуля менеджера потоков, модуль(и) разработчика со своими алгоритмами (модуль менеджера может быть без изменений вообще);
* возможность описать код разработчика вне метаданных (в самой внешней обработке), что позволяет их (внешние обработки) писать без изменения конфигурации БД;
* возможность одновременного запуска нескольких менеджеров с разными алгоритмами (В разработке сейчас обсуждается расчет зарплаты, где есть ряд выполняемых операций, при этом есть четкая зависимость одних операций от других, но ряд операций при этом могут выполняться параллельно в одной из веток дерева(графа), а следом идущие операции (этой же ветки), только при завершении всех этих параллельных. При этом каждая операция будет стартовать свой менеджер потоков, который будет распараллеливать выполнение конкретно взятой операции, но это пока в обсуждении, но пока все укладывается в возможности модуля);
* перезапуск ФЗ, в случае вылета;
* ну и еще что-то по мелочи, все возможности описаны в статье 🙂
Что увидел в описании «TaskManagerFor1C» это ограничение по количеству выполнений одной операции, после чего она считается не выполненной. Такой функционал в моем модуле на сегодня отсутствует, но потребность в нем тоже есть и это уже заложено в следующих обновлениях, как и ряд других идей 🙂
Если есть конкретные вопросы задавайте
(37) Приведенное решение не мое.
Спасибо за краткое описание, собственно и хотелось по-быстрому, не вникая глубоко, понять отличия. Теперь вижу, что стоит изучить подробнее.
Если не сложно, ткните ссылкой в обсуждение.
Правильно ли я понимаю, что планируются готовые модули разработчика для типовых конфигураций, в частности, для ЗУП?
(38)
Если не сложно, ткните ссылкой в обсуждение.
Обсуждение внутренне, в рамках нашей организации, не для общего использования 🙂
(38)
Не совсем 🙂 Я выкладываю только модуль позволяющий производить распараллеливание. А разработчик/разработчики разрабатывают вторую часть которая опирается на модуль. По аналоги с 1С. Я предоставляю платформу (мой модуль), а разработчики пишут свое отраслевое решение (модули с обработчиками событий под конкретные задачи). Так что вопрос о разработке модулей для типовых конфигураций я отдаю на волю разработчикам 🙂
Разработчик (фриланс / франч) берет модуль для разработки (с закрытым кодом) добавляет свой модуль с обработкой событий и выставляет конечному клиенту(ам). Под каждую разработку отдельное приобретение, но на неограниченное количество поставок клиентам.
Или
Конечный пользователь приобретает модуль (с открытым кодом) и использует его как хочет на неограниченное количество проектов в рамках своей организации .
(38)
В ближайшее время выложу дополнительные картинки с разъяснением расчета ресурсов, при каких условиях как строится граф, а то пишут, что это достаточно сложная часть и демо примера — мало 🙂
(38) Добавил картинки (разъяснения) по формированию ресурсов
(42) Спасибо за отзыв!
Эпохальным он станет, если им начнут пользоваться — эпохально 🙂
Если бы вложили готовый модуль для встраивания в БП3 — цены бы Вам не было! Но и без этого — несомненный плюс!
(44) Готовый модуль чего? Восстановления партий? т.к. именно его тут нет :). Честно подумывал над этим, но я проводил оптимизацию под УПП 1.3, и под условия нашей организации. А в других организациях могут быть свои условия, потребности и доработки. Кроме того в моих алгоритмах использованы не все возможности распараллеливания, например, у нас нет характеристик, и их я не встраивал в алгоритмы событий, а у кого то они могут быть в данном случае мой алгоритм будет снижать возможность распараллелить проведение и так далее.
Хотя если будет заинтересованность, наверное выложу, как пример 🙂
(44) Более того… Разработку таких модулей (обработчиков событий) я предлагаю сообществу.
PS Да, да, знаю, что защита примитивна. Но хоть что-то 🙂 Если вы планируете делать разработку с поддержкой многопоточности на основе данного модуля и предлагать ее потенциальным покупателям, то уповаю на Ваше благоразумее в плане приобретения полной версии. Если Вы являетесь конечным покупателем, то для Вас одно приобретение для одной организации, на неограниченное количество проектов. Если фриланс/франчайзи :), то одно приобретение на один проект (обработку), но на неограниченое количество конечных пользователей.
Статья отличная, но орфографические ошибки просто убивают всякое желание продолжать чтение. Исправьте! Есть же Word в конце-концов!
(47) Большое спасибо за замечания. Основная часть стать была написана в Word (я бы не осилил написать столько, с таким «незначительным» количеством ошибок :)). БОльшая часть ошибок была допущена в результате правки и обновления разделов, их увы делал на «коленке».
Что нашел — поправил, надеюсь стало лучше.
а можно отдельную статью только кратко и с простыми примерами?)в раза 6 кратче )
оч тяжело читать и сразу все механизмы описывать наверно нет смысла, для меня лично, но труд как сказали эпохальный , выглядит слишком зло.
(49)
Если кратко, то что оставить? Если написать в 6 раз меньше, то надо выкинуть 5/6 статьи.
Для «простоты», что требуется от разработчика — скачайте демообработки, а именно «Запись справочников», а в нем Вас будет интересовать – модуль формы и модуль объекта, а именно Функция «ОбработатьСобытиеРазработчика». Под условием:
«Если РазрезМенеджеров = «Запись справочника — Независимая запись» Тогда»
Это САМЫЙ простой способ распараллелить 🙂
Под условием:
ИначеЕсли РазрезМенеджеров = «Запись справочника — Зависимость по четности кода» Тогда
Это САМЫЙ простой способ распараллелить при выстраивании зависимости объектов 🙂
Получилось в 6 раз короче??? В данном случае придется самому пытаться понять, как оно устроено — зато кратко. Будут вопросы — обращайтесь к данной статье.
Основные сложности и прочие события реализованы для получения ответов от потоков на клиент. А так же предоставляют возможность собирать информацию для отчетов в момент работы.
(50)
Как запустить ,примеры что можно запустить, например обмен какой-то или отчёт..
это тоже что и у вас или нет?
Я вот не помню видел вроде как можно запустить отчет в отдельном потоке и свернув его например делать дальше работу.
(51) Самый простой способ опробовать:
* Скачиваем «Универсальный «Менеджер потоков Демо»»;
* Скачиваем демообработки;
* Устанавливаем «Менеджер потоков» на любую конфигурацию
* Запускаем демо обработки, где от разных настроек обработок будут разные результаты. (Формирование расчетных листов оттестировано только на УПП 1.3, возможно будет работать в ЗУП, но под рукой не было — не проверил).
Это самый простой способ распараллелить, и не самый оптимальный. Его основные минусы:
* Необходимо обдумывать как разбить обрабатываемый массив на части (порции) (В предоставленной статье порция — это склад).
*
тут узкое место в том, что пока ПАЧКА фоновых заданий не отработает полностью новое не запуститься. Если в первую выборку попадет один гигантский склад и 9 маленьких, но при этом в общей выборке их предположи 11, то последний 11 склад будет ждать завершения всего блока, ходя 9 потоков по сути будут давно свободны.
* Не реализована обратная связь между потоками и клиентом, хотя допил не большой,
* И САМОЕ ГЛАВНОЕ, если в потоке произойдет ЛЮБАЯ ошибка, хоть ожидание захвата таблицы, он просто прекратит свою жизнь, и Вам ни как об этом не сообщит
В текущем «менеджере потоков» это все учтено. 🙂
Максимально близкое решение предоставили на (36), но отличия, бегло обнаруженные, я так же описал в (37)
(53) Благодарю за отзыв.
Интересно что переписали в Процедура ЗаполнитьЗапросПартийНаСкладахУпр и тд.
(55) За основу взял «http://xn—-1-bedvffifm4g.xn--p1ai/news/2016-07-05-not-optimal-query-sample/» (курсы -по -1с .рф)
А дальше по профайлеру и потребностям нашей организации.
(25) в строительстве больше разрезов при проведении документов — объект строительства, договор, заказ, склад, организация, номенклатура, документ-партия для материалов — все это «измерения» в терминах 1С для учета.
1) пробовали ли вы использовать для перепроведения последовательности документов стандартный механизм восстановления последовательности по измерениям?
2) главный фокус статьи — это разделение всех документов по разрезам учета (см. первый абзац) — добавив в учет дополнительные таблицы для хранения этой информации?
когда я столкнулся с проблемой перепроведения документов для пересчета определенного показателя, я реализовал и описал в статье подобный подход
(57)
— разрезов больше, но тех что не вызывают блокировок значительно меньше. Например в БУ, можете сколь угодно много добавлять разрезов, но «мельче» чем «Склад»+»Номенклатура» раздробить (распараллелить) не получиться.
(57)
Вы меня сейчас озадачили… Какой стандартный механизм позволяет восстанавливать последовательность по измерениям. Единственное измерение стандартного механизма — это «Организация», ну еще «УУ» и «БУ». Все, больше мне ни какие измерения для восстановления в стандартном механизме не доступны (мне не известны).
(57)
Если под разрезами вы понимаете «УУ» и «БУ», в принципе можно и так сказать, но в данной статье я его не использовал, каждый документ восстанавливался одновременно по двум учетам. Распараллеливание идет на уровне данных документа. Грубо, если у вас есть два склада не связанных между собой (и производства в том числе), то восстановление можно запустить в 2 потока.
(57)
— нет в БД ни какие новые объекты метаданных создавать не надо. Все рассчитывается и формируется «на лету» согласно заложенных Вами алгоритмов.
(57)
с Вашей статьей я знаком
(57)
Не обратил внимание к чему вы писали сообщение.
На самом деле, для выстраивания зависимости объектов, разрезов может быть произвольное количество не обязательно 2. Можно реально использовать все что вы перечислили, а можно все, но не разом, а в совокупности, например, построить две и более зависимостей: 1ая по «Объект строительства» + «Организация» + «Заказ»; 2ая по «Организация» + «Склад» + «Номенклатура» + «Документ-Партия» и 3я по «Объект строительства» + «Договор». Все это приведет к формированию 3х графов, которые в итоге сольются в 1 смешанный граф и далее обрабатываются по описанной выше схеме, текущий документ не будет передан в обработку, пока не будут обработаны ВСЕ ведущие документы с такими же наборами данных (ресурсов).
Надеюсь понятно описал. Опять же прошу ознакомиться с примерами особенно с
(58)
дополнительные измерения можно запрограммировать, чтобы ускорить общее перепроведение — вот статьи об этом:
суть такая — Измерения. Последовательности могут иметь подчиненные объекты, называемые измерениями, которые создаются на закладке Данные окна редактирования.
Если для последовательности не создано ни одного измерения, то при восстановлении данной последовательности будут перепроводиться все входящие документы. Если требуется, чтобы данная последовательность учитывала не все, а вполне определенные ситуации, то в последовательность включают измерение. В этом случае перепроводить нужно будет только те документы, которые изменяют состояние регистра с учетом свойств измерения.
Если изменяется состояние регистров, участвующих в последовательности, то неактуальными становятся более поздние документы с теми же значениями в реквизитах (перечислены в свойстве измерения Соответствие реквизитам документов), которые содержатся в реквизитах удаленных (добавленных) записей регистров (перечислены в свойстве измерения Соответствие реквизитам движений).
Например, последовательность учитывает изменение состояния регистров по документам Приходная накладная и Расходная накладная. Если требуется учитывать дополнительные критерии необходимости перепроведения указанных документов (например, нужно перепроводить документы по определенному значению номенклатуры), то в последовательность следует добавить измерение. В палитре свойств измерения указать его тип (СправочникСсылка.Номенклатура) и установить связь с реквизитами регистров.
(58)
про это — не понял вас
в целом, по вашей статье — у меня создалось поверхностное мнение, что вы распараллелили перепроведение по измерениям — да, это помогает ускорить стандартный механизм типового восстановления последовательности при закрытии месяца. такая идея уже заложена в механизм объекта конфигурации «Последовательность документов». Вы наверное сделали как-то по другому.
(58)
ясно. можно и «на лету» — значит задействуете ОЗУ — ресурсы памяти — такое же хранение данных только в других таблицах, и на обработку собственных запросов требуется такое же время и ресурсы ОЗУ… в итоге у вас насколько сложные (длинные) запросы получились? Я не убеждаю ни в чем, просто технические детали реализации вашего механизма уже интересны …
(37)
вопросов пока нет, просто тема интересная,
разрыхлил новые статьи на ИТС
Ускорение процесса восстановления последовательности взаиморасчетов в БП КОРП
да и вообще, что представлено на гитхабе — это опять-таки плагин на базе имеющихся фоновых заданий — и кто-то может сделает для конкретной задачи оптимальнее зная специфику учета.
(60) Что такое «измерение» объекта «последовательность» я знаю. И сколько переделок в коде вслед за этим необходимо сделать — тоже представляю. Я думал Вы говорите о типовой обработке восстановления последовательности и о возможности запустить восстановления по «скрытым» для меня измерениям.
(61) Вы не совсем поняли мой механизм. Все что вы добавляете в объекты метаданных — это только 1 (один) общий модуль. В целом этого достаточно, но я рекомендую, для своих обработчиков создавать по дополнитльному общему модулю.
Ни каких изменений других объектов производить не требуется.
У Вас вообще в БД может не быть объекта последовательность, а объекты мы можете обрабатывать в разных потоках. Рассматриваемый пример «восстановление последовательности» — это как один из множества вариантов использоватния механизма.
Вы же используя его можете восстановить последовательность расчетов с контрагентами, или рассчитать зарплаты или вообще произвести произвольную обработку данных в потоках, хоть заполнить таблицу значений расчетными суммами или записать перезаписать массу объектов. Но для этих целей больше подойдет . В нем данный механизм получил расширенные функции
(62) Опять же советую Вам ознакомиться со статьей не поверхностно, а детально, если она Вас заинтересовала, т.к. сейчас Вы не до конца осознаете что и как реализовано. Не поверите, но я вообще при реализации рассмотренного примера, не изменил ни одного типового запроса. А если в цифрах, то общий модуль менеджера потоков ~1000 строк кода, это то что не требует корректировок, а объем кода обрабатывающий события менеджера это примерно еще 500 строк и ВСЕ. Этого достаточно чтобы партии «типовой» (уже не совсем, т.к. чуток вмещаться надо для инициализации менеджера потоков, но и это можно вынести во внешнюю обработку) УПП отрабатывали в разы быстрее, чем типовой обработкой. Я сомневаюсь, что в 500 строчках кода можно наваять что-то
(62)
Да там есть запросы для получения «ресурсов», но я не скажу, что выборка из регистра с отбором по ссылке документа это сложный запрос, или определение присутствие и заполненность поля «Заказа» в передаваемом на обработку документе — это что-то сверх сложно и непостижимое :)).
В дальнейшем я предлагаю дискуссию перенести в чат обновления , т.к. там все последние доработки механизма.
(62)
Предлагаю скачать работающий механизм () и ознакомиться с работой рассмотренных примеров, там уже не восстановление партий. Думаю многие вопросы так же отпадут.
А так, конечно задавайте вопросы с удовольствием отвечу, только просьба все же ознакомиться с 2мя статьями, что бы не пришлось повторять то что написано выше 🙂
(63)
Так на данном ресурсе — много можно отнести к категории «плагин». Вопрос в том, что для реализации множества задач можно использовать 1 общий подход — это ведь значительно эффективнее чем каждый раз писать одно и то же или чуть чуть другое с нуля.
Что разработка на гитхабе, что моя разработка предлагают Вам такой инструмент, используя который Вы можете ускорить выполнение своих обработок в РАЗЫ!!! и для этого может потребоваться не так много сил и времени. В частности рассмотренного тут примера, разве плохо иметь возможность восстанавливать последовательность партий месяца в рабочее время за 20-30 мин, когда работают 200+ пользователей без «блокировок» транзакций???? Если нет, тогда чем плохи данные плагины? А типовой механизм такого не позволит даже если использовать предложенный Вами способ добавления измерений в объект «Последовательность».
(63)
Ознакомился с предоставленной статьей. Решение верное, но предложенная реализация имеет ряд ограничений:
1. Необходимость находить документы «корректировка долга» и «авансовый отчет» для определения границы обрабатываемого периода.
2. Множество запусков и остановок фоновых заданий (после обработки документов ФЗ перезапускается с новыми данными).
3. Не ясно как обрабатываются ошибки, если в переданном пакете документов один из них не провелся.
4. Нет возможности запускать в рабочее время, т.к. может быть ожидание захвата таблицы и после 20 сек, ФЗ просто прекратит свое существование 🙂
можно еще найти «ограничений» предложенного механизма если знать что там точно реализовали и как.
Я конечно не говорю, что предложенный мной механизм не имеет ограничений, но данные «подводные камни» в нем отработаны
(64) ок, понял вас
(66) ясно, интересный подход ))
код вашего модуля открыт?
(66)
надо знать конфу, которую обрабатываешь, поскольку Заказ может сидеть в реквизите «Сделка» , «ДокументОснование» или просто «Заказ» или использовать структуру подчиненности и по типу объекта проверять все реквизиты….
(70)
(70)
Само собой! Менеджер — универсален, а пакет обработчиков событий — индивидуален 🙂 В принципе разработчики могут менеджером пользоваться как платформой для разработки. Если конечно есть желание, то могут свое написать — основные идеи я изложил. Но как показывает практика — это долго, не с точки зрения разработки (я версию написал примерно за 2 недели, да и то я четко представлял что необходимо сделать), а с точки зрения тесотов 🙂
(72) Спасибо! Лестно — это слышать 🙂
Но если я «крут», то это вообще отвесные скалы 🙂
и многие другие …
(45) было бы отлично если бы выложили
(27) я скачал примеры. Не увидел там пример РЛ.
(75) РЛ, листы были в первой статье, во второй я их решил не выкладывать, т.к. они имеют все же определенную специфику, а не общее решение. Прикладываю обработку по РЛ, но под версию 2.0 ее придется чуток подправить «напильником»
Добрый день, куда делись прикрепленный файлы, в частности «Демо обработки»??
Добрый день! Спасибо за большой труд.
Можно ли решить с помощью менеджера такую задачу: При интерактивном проведении документов пользователями, отправлять документы в менеджер потоков, где они проводятся. После проведения получать информации о статусе (проведен или нет).
Как можно выполнить обработку документов в потоке при запуске с разных рабочих мест?
(78) Добрый день!
А зачем Вам при «интерактивном проведении» выполнять это в потоках?
Если у Вас грамотно настроена блокировка данных, документы и так буду проводиться параллельно, ведь проводить их будут разные пользователи.
«Менеджер потоков» позволяет выбрав объекты для обработки (не обязательно документы) в одном сеансе (одним запросом), обработать их несколько потоков, а не стандартным перебором с обработкой.
Хотим ускорить интерактивное проведение документов. Пример: пользователь нажал «Провести и закрыть» и документ через пару секунд закрылся. А на самом деле документ встал в очередь проведения и проведется через 10 минут.
(80) это называется допроведение документов. В данном случае это имеет смысл. Сначала вы складываете документы в очередь (Регистр сведений), затем запускаете обработку, которая считывает накопленную очередь и отправляет документы в менеджер потоков, где они уже будут обработаны в потоках. Так — да сделать можно. Про ответ, об успешном проведении, можно не заморачиваться, а просто в потоке удалять документ из очереди (регистра сведений).
Но опять есть один вопрос.
А в очереди, между вызовами, будут сотни документов?
Просто смысл делать многопоточное проведение, если с этим в состоянии справить и одна последовательная очередь. Вот если документов успевает нападать столько что в 1 поток их провести не получается (очередь копиться быстрее чем происходит проведение), вот тогда имеет смысл думать о менеджере потоков.
Спасибо за идеи. Действительно документов будет много, хочу воспользоваться возможностью менеджера потоков организовать проведение в несколько потоков.
Здравствуйте! Нам нужна помощь в разделении потоков в восстановлении последовательности в 1С УПП 1.3 (без производства)
сможете ли нам помочь в этом, как можно с вами связаться или куда отправить свои контакты?
(83) пишите в «личку», постараюсь помочь 🙂
В личку не могу написать, пишет «Сообщение не отправлено, отложенная группа»…
(85) Проверьте свои сообщения, я там должен был засветиться 🙂 Попробуйте мне ответить 🙂