
БЭКАПЫ
Зачем нужны бэкапы на мобильной платформе
Специалисты знают, насколько порой ненадежны мобильные приложения на 1С: в любой момент могут возникнуть ошибки, из-за которых базы пользователей просто разрушатся. Одновременно мы сталкиваемся с ненадежностью самих устройств: их можно разбить, потерять, их могут украсть, а пользователи хотят сохранить свои данные. И вплоть до версии 8.3.9 мы не имели платформенного механизма сохранения бэкапа.

Поскольку раньше у пользователей не было кнопки «сохранить копию», разработчикам приложения Boss пришлось самим делать бэкапы. Как мы это сделали?
Сами данные базы мы сохраняем в виде ХML.
Желательно предложить пользователю несколько вариантов хранения копий — прежде всего, это удобно клиентам, они могут выбрать наилучший для себя вариант: выгрузить в облако, отправить себе на почту, сохранить на устройстве.
Таким образом, разработчики дополнительно себя страхуют. Если что-то пошло не так, и вдруг сломался механизм создания копий на Гугл-Диске или Яндекс-Диске, всегда можно сказать пользователю, что в данный момент разработчик разбирается с ошибкой, а пока он может сохранить данные альтернативным способом. И пользователи остаются довольны, потому что они могут быть спокойны за свои данные.
Обязательно нужно сделать акцент на облачные сервисы, потому что если устройство потеряется или разобьется, а пользователь сохранял копию на этом же устройстве, то данные будут утеряны.
Также мы обязательно напоминаем пользователю о необходимости создания бэкапов.

Как сохранять копии, если меняется конфигурация?
Когда мы говорим о массовом решении, о приложении, которое постоянно меняется, развивается и дорабатывается, надо учитывать поведение клиентов. Пользователь может захотеть восстановить бэкап, сохраненный в старой версии приложении, где не было каких-то реквизитов. И тогда возникает задача: прочитать данные, затем дозаполнить данные по логике обновления со старой версии приложения. Как это сделать? Помимо данных, сохранить еще и саму структуру данных, чтобы потом знать, как их читать.
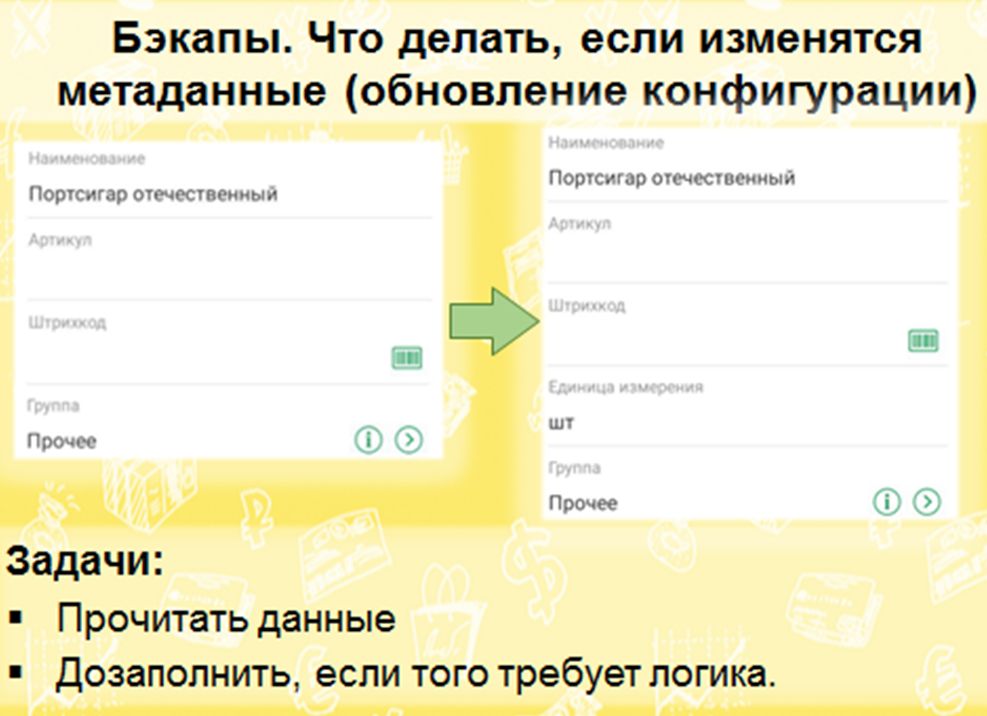
Есть несколько вариантов хранения этой структуры данных, в том числе ее можно хранить в самой конфигурации. То есть при выпуске каждой новой версии, сохранять структуру метаданных предыдущей версии в макет в конфигурации.
Не стоит забывать, что в мобильном приложении конфигурация не должна разрастаться просто так, мы должны дорожить местом в ней, должны делать ее наиболее компактной. Но приложение ведь развивается, и таких макетов будет много и со временем их будет становиться всё больше.
Поэтому в случае с мобильным приложением предпочтителен другой путь — сохранять структуру метаданных непосредственно в файле с данными. На выходе у нас получается вот такой файлик, где вначале мы храним какие-то вспомогательные данные – версию конфигурации, схему конфигурации, границы последовательностей, в уже после записываем сами данные пользователей в формате XML. Причем, в разделе файла "Вспомогательные данные" можно также хранить и другие важные данные, которые по каким-то причинам не получилось записать в XML.


Как читать бэкапы?
Берем ту схему данных, которую сохранили в файл, и на ее основании строим пакет XDTO для чтения файла. Создаем аналогичный объект в базе данных, заполняем его, выполняем обработки по дозаполнению при обновлении, и сохраняем уже готовый объект в базу данных.
Ниже на картинке можно посмотреть подсказку, как красиво записать модель XDTO данных конфигураций. В компании, выпустившей приложение Boss, экспериментировали с этим, находили несколько способов, но остановились именно на таком варианте записывания схемы метаданных. Когда открывается сам файл с данными, там виден обычный структурированный XML, читабельный, в котором перечислены все метаданные приложения.
// Запись схемы конфигурации
МодельXDTO = ФабрикаXDTO.ЭкспортМоделиXDTO("http://v8.1c.ru/8.1/data/enterprise/current-config");
ФабрикаXDTO.ЗаписатьXML(ФайлВыгрузки, МодельXDTO);
// Чтение схемы конфигурации
МодельXDTO = ФабрикаXDTO.ПрочитатьXML(ЧтениеXML, ФабрикаXDTO.Тип("http://v8.1c.ru/8.1/xdto","Model"));
ФабрикаВыгрузки = Новый ФабрикаXDTO(МодельXDTO);
Чтобы обезопасить пользователя, нужно обязательно переспрашивать его, а нужно ли ему восстановление бэкапа. Может, он просто экспериментировал и нажимал на все подряд кнопочки в приложении:) И сейчас текущие данные у него могут потеряться. Поэтому мы всегда при выполнении потенциально "опасных" действий уточняем, а действительно ли он этого хочет, и как это должно происходить. Пользователь должен отдавать себе отчет в своих действиях.
Механизм создания бэкапов обязательно должен быть, когда мы говорим об автономном решении, когда у пользователя все данные хранятся исключительно на мобильном устройстве: пользователь может свое устройство потерять, и тогда данные потеряются. И, казалось бы, если приложение работает не автономно, а связано с центральным сервером, то у пользователя не должно быть такой проблемы, ведь в случае утери устройства он подключится к серверу, получит все свои данные с сервера заново, и все будет ок.
Однако пользователи используют бэкапы не всегда так, как мы от них ожидаем:) Они очень часто используют их для того, чтобы просто «откатить» данные назад. Это правда очень странное поведение, но пользователям мобильных приложений лень разбираться, где они могли допустить ошибку при вводе данных, и они просто откатывают данные назад и заново заводят данные за текущий день. Проанализировав статистику работы с приложением Boss, мы осознали, что это нормальная практика и такое поведение пользователей встречается чаще, чем мы могли предположить.
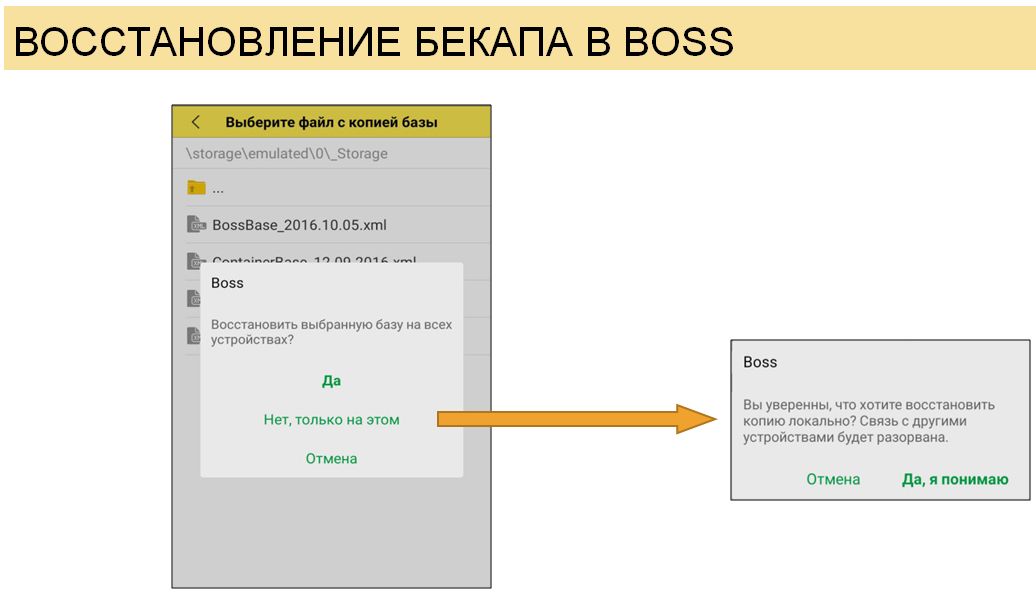
И если у вас используется синхронизация с другими устройствами, то вы должны это обработать. Здесь есть несколько путей решения:
- разорвать связь с сервером, уточняя, что данные на нем останутся такими, как были, а копия восстановится только на устройстве пользователя;
- лучше для пользователя — дать ему восстановить копию сразу на всех устройствах, предварительно прописав такие механизмы.

Тут есть еще один момент. До сих пор мы бэкапы сохраняли сами, контролировали весь процесс, прямо в коде отлавливали действия пользователя, когда он нажимал кнопку «сохранить копию». Все это можно потом обработать. В платформе 8.3.9 появилась возможность сохранять бэкапы именно средствами платформы. И пользователь делает это без нашего ведома. Если используется синхронизация с центральной базой, то нужно обязательно обработать такой сценарий. Мы должны как-то на своем сервере узнать, что пользователь восстановил ранее сохраненную копию и должны выдать ему какое-то решение. Мы не можем себе позволить, чтобы данные рассинхронизировались.
ОБМЕНЫ
Когда мы говорим про частное решение на мобильной платформе, то у нас, как правило, есть заказчик, который, например, хочет использовать мобильную платформу для своих торговых агентов, и чтобы они обменивались данными с центральной базой. Здесь все просто: одна база данных, несколько устройств, вы поднимаете сервер, настраиваете связь с ним. Так что проблема обмена между устройствами решается легко.
Но если мы говорим о массовом приложении, где много баз данных, у каждой из которых очень много пользователей, ситуация усложняется. Пользователи скачали приложение с маркета, и они хотят синхронизироваться друг с другом. Например, муж скачал приложение для учета личных финансов, и теперь хочет, чтобы жена тоже подключилась, и они вместе работали в одном приложении. Пользователей много, приложение развивается, растет, и появляется необходимость в большом-пребольшом количестве баз данных. Как это все организовать? Пользователи же не будут персонально обращаться к разработчикам, чтобы те создали для них отдельную базу и включили возможность синхронизации. Они хотят нажать на кнопочку, и чтобы все сразу же заработало. В тот же момент.
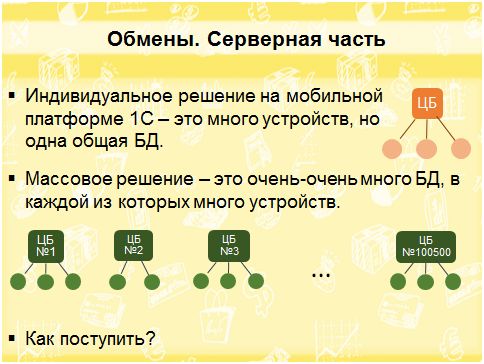
Как поступить? Тут на помощь приходит механизм разделения данных. Он позволяет организовать единую базу данных, где есть одна общая конфигурация, но при этом в рамках одной общей базы хранится неограниченно много баз пользователей.
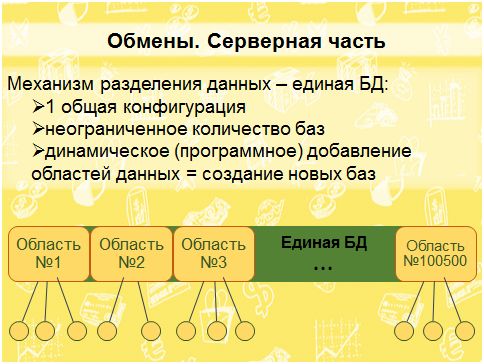
Самое приятное, что можно динамически, программно, без нашего участия добавлять пользователей. Реально пользователи просто нажимают на кнопочку «зарегистрироваться на сервере», и все само происходит: ему создается персональная база на сервере, и он может тут же начинать работать в ней.
Как это сделать? Первое и самое просто решение – написать свою серверную базу с этим механизмом. Когда наша компания начинала делать приложение Boss и обмены в нем, в первой версии мы так и сделали: написали серверную базу с механизмом разделения данных. Все работало, тем более что ничего сложного не было – разделителем баз является общий реквизит.
Но потом мы поняли, что изобретаем велосипед:) На самом деле есть уже готовое решение, причем в нем уже учтены моменты, о которых мы еще даже не думали. Это 1С:Фреш.

Здесь продуманна масштабируемость сервиса: что делать, когда будет очень много данных и баз, как расти с этим всем. Здесь есть момент о создании резервных копий областей данных: то есть мы не просто делаем бэкап одной общей базы данных, мы делаем копии конкретного пользователя. Причем, механизм там такой, что копии делаются только тогда, когда они реально нужны. Если пользователь не заходил неделю в базу, то мы не делаем ему копии, потому что там ничего не изменилось. Еще одна фишка Фреш – в сервисе реализован механизм для снижения нагрузки на сервер, а это очень важно, когда у вас много баз.
В целом Фреш для нас – что-то новое и интересное. Потихоньку мы пытаемся разобраться в нем, но в большинстве своем мы просто довольны его работой.

Передача данных. Как реализовать ее для обмена между устройствами
Платформа предоставляет два механизма – это SOAP и http сервисы. Тут есть нюансы, как обращаться к этим сервисам, когда задействован механизм разделения данных. В частности, нужно добавить параметры, которые указывают конкретный номер области, к которой вы обращаетесь, потому что по имени пользователя платформа не может определить, к какой базе обращаться. Кроме того, один и тот же пользователь может работать с несколькими базами в рамках единой базы (см. картинку).

Что касается сервисов, в приложении Boss реализован мгновенный обмен: один пользователь вводит данные, а другой их получает. Пользователи мобильных приложений привыкли ведь, что все происходит моментально, поэтому мы задумались, каким лучше сервисом пользоваться – SOAP или http. Ключевую роль сыграла скорость соединения. В http скорость соединения гораздо выше, а подключаясь по SOAP, мы получаем описание сервиса, которое тяжелое и долго грузится. У платформы есть способ хранить описание сервиса, но из-за параметров, которые мы добавляем динамически, мы не можем использовать WS-ссылки. Кроме того, обращение к http-сервисам удобнее и гибче, по нашему опыту.
Итак, наша цель – реализовать обмен в режиме реального времени. То есть мы стараемся не делать так, чтобы пользователю пришлось зайти куда-то, нажать на какую-то кнопку, думать о том, насколько актуальные у него данные, должен ли он проводить актуализацию…У пользователей данные всегда должны быть актуальны. Они так привыкли, работая в мессенджерах – один данные отправил, другой их тут же получил. Все происходит моментально. То же самое касается приложений, касающихся бизнеса: один продавец оформил продажу, другой должен тут же увидеть актуальную ситуацию, никаких действий при этом не совершая.
Поэтому в приложении Boss используются для обменов фоновые задания. После каждой записи данных в базу, запускается фоновое задание, которое инициирует обмен. Первая часть – отправить данные на сервер. Затем другие устройства должны узнать, что есть новые данные. Для этого мы используем PUSH-уведомления. Эта схема уже работающая и она работает достаточно быстро.
Но мы захотели еще быстрее, поскольку работаем в режиме реального времени и данных у нас, как правило, немного. У нас маленькие XML, но при этом мы отправляем с первого устройства на сервер сообщение с этими данными, сервер отправляет PUSH на другое устройство, а то второе устройство после получения PUSH-а инициирует обмен со своей стороны, обращается к серверу и запрашивает данные, получает эти данные и затем отправляет ответ, что данные получены. Это долго, а ведь самих данных было совсем немного.
Мы задумались, как этот процесс можно ускорить.
Для этого мы разобрались, что содержит в себе PUSH, как его можно еще использовать. Оказалось, что PUSH содержит такие поля, как данные и текст. В документации iOS и Android указаны ограничения по размеру PUSH-сообщений, но нам этого показалось мало и мы захотели сами опытным путем во всем разобраться. И мы проверили, что для iOS сумма допустимых символов составляет 981 знак, а для Android – 3832 символа. В последнем случае ограничением вполне можно пользоваться, в такой объем можно впихнуть один или несколько объектов базы. И тогда разработчики компании изменили немного схему. Когда данных немного, мы отправляем их с одного устройства, получаем их на сервере, там упаковываем их в PUSH и прямо в нем же отправляем на другое устройство. Схема стала короче, а обмен стал происходить еще быстрее:)

Важный момент использования PUSH – не раздражаем пользователей.
Очень легко избавиться от такой ситуации: просто не отправлять пользователю много PUSH-сообщений:) Если он работает сейчас в приложении, отправлять много сообщений можно. Когда платформа работает, пользователь не видит PUSH, у него все происходит автоматически. А вот когда приложение закрыто, у клиента появляется много непрочитанных сообщений. Поэтому ни в коем случае нельзя отправлять следующие PUSH, пока не получен ответ от устройства, что приложение работает, активно и предыдущий PUSH уже обработан.
Еще один нюанс обмена – это работа через веб. Нам нужно использовать асинхронность максимально. Вы не можете работать как обычно – написали код – вызвали функцию – подождали, пока она выполнится – получили ответ – и все ок. Если вы работаете через веб, вы все равно столкнетесь с определенными ограничениями, например, с нестабильным интернетом, срабатываением таймаутов при выполнении длительных операций. Поэтому надо заранее продумывать архитектуру.

Посмотрим на примере регистрации устройства, что происходит в приложении, когда пользователь хочет зарегистрироваться. Он ведет учет какое-то время, он ввел достаточно много данных, но потом он хочет, чтобы продавец тоже работал с этой базой. Пользователь нажимает на кнопку «зарегистрироваться». Вначале все было очень просто: взяли его данные, записали на сервере, и, пожалуйста, можно работать и подключать пользователей. Но потом мы столкнулись с ситуацией, когда у некоторых пользователей базы данных на устройстве к моменту регистрации уже сильно разростались. И эта схема уже не работала, т.к. пока шла запись всей базы на сервере, срабатывал таймаут соединения или просто обрывался интернет. Поэтому мы заменили один синхронный вызов на множество коротких. Сейчас данные делятся, а не передаются все за один раз. Мы не ждем ни в коем случае, пока сервер будет обрабатывать и записывать данные. Отправили данные, получили ответ, что данные получены, закрыли соединение. Периодически надо опрашивать сервер, что там и как происходит, а тем временем на сервере работает фоновое задание, которое записывает полученные данные. Таким образом, получается много вызовов сервера, но у нас есть гарантия того, что все пройдет хорошо. И ни таймауты, ни нестабильность интернета не помешают произвести выгрузку всех данных на сервер.
ОБНОВЛЕНИЯ
Обмен между устройствами с разными версиями приложения
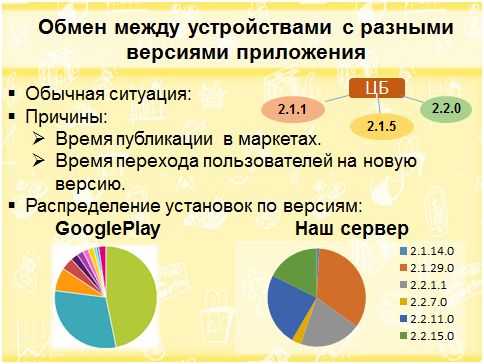
Поскольку мы говорим о массовом приложении, которое выпускается в маркеты, надо учитывать некоторые особенности процесса обновлений и обмена данными.
Если вы выпустили приложение для одного предприятия и решили его обновить, то обычно вы просто даете команду, чтобы все сотрудники дружно установили новое приложение. С пользователями, которые скачали приложение из маркета, так сделать нельзя. Вы вообще не можете им указывать, что им делать. К примеру, они работают в приложении и не хотят обновлять его ни сейчас, ни вообще никогда. У них не стоит автообновление, поэтому совершенно обычная ситуация, когда к центральной базе подключено несколько устройств, и все они с разными версиями. Еще одна причина такого явления – время публикации в маркетах: оно разное для iOS и Android. Мы часто внедряем ключевые штуки, например, исправляем критические ошибки, и не хотим ждать, пока iOS проверяет две недели новую версию, мы хотим хотя бы только для Android, но выпустить обновление прямо сейчас.
Мы не имеем права командовать пользователями. Если они хотят, то обновляются, а если нет – то ничего не делают. На картинке видно соотношение установок приложения Boss по версиям в GooglePlay, а также статистика с нашего сервера — реальное соотношение версий приложения, которые установлены на устройствах, обменивавшихся с сервером данными в течение последней недели. Вот такой набор, с которым надо работать. Это разные версии и разные метаданные. И нам надо организовать нормальный обмен при этом:)
Перед разработчиками стоят следующие задачи:
- Надо, чтобы все это работало. Пользователи не должны чувствовать дискомфорта от того, что они забыли обновиться. Они вообще не должны этого замечать. Обновились – стало лучше, ну и хорошо.
- Мы должны обеспечить сохранность данных. Например, у одного пользователя появился справочник и новый реквизит, а у другого еще нет. При этом если пользователь, у которого новых реквизитов нет, изменит у себя на устройстве что-то, то на других устройствах данные не должны пропасть.
- Надо обеспечить актуализацию данных, когда мы переходим на новую версию. Когда пользователь решит, что он готов обновиться, у него автоматически должны появиться все новые сведения, которых у него не было только потому, что у него была старая версия.

Как мы это сделали?
1. Мы используем на сервере 2 плана обмена. Первый – для обмена между устройствами, а второй – для обновлений. Например, мы отправили справочник пользователю, но у него нет единиц измерения, то есть неполные данные. Мы должны запомнить это. А когда он обновится, мы должны отправить ему все те сведения, которых у него не было. Для этого и нужен второй план обмена.
2. Для записи и чтения объектов мы используем тот же механизм, который используется для бэкапов, то есть сохраняем версию метаданных. В данном случае мы работаем с сервером, и мы можем позволить себе прямо в конфигурацию добавлять все, что угодно, поэтому просто в виде макетов добавляем в конфигурацию схемы метаданных по мере развития приложения.

Как мониторить массовые ошибки при обмене и на сервере
Во-первых, надо контролировать доступность самого сервера. С серверами такое бывает – они падают. Мы не выдумывали ничего особенного для мониторинга, а просто нашли бота в телеграмме, который кричит, если что-то не так. Он каждую минуту проверяет работоспособность сервера, и если вдруг сервер недоступен, начинает кричать, админы это видят и поднимают сервер.
Также мы собираем лог ошибок из журнала регистрации. Тоже ничего сверхъестественного – просто каждые три часа собираем лог ошибок, отправляем их на почту, периодически их просматриваем. Это помогает видеть частые проблемы и какие-то исключительные ситуации. Не сложно просматривать почту, отслеживать и быстро исправлять ошибки. Но это позволяет оперативно выявлять и решать проблемы, которые могут разрастаться с ростом баз данных.

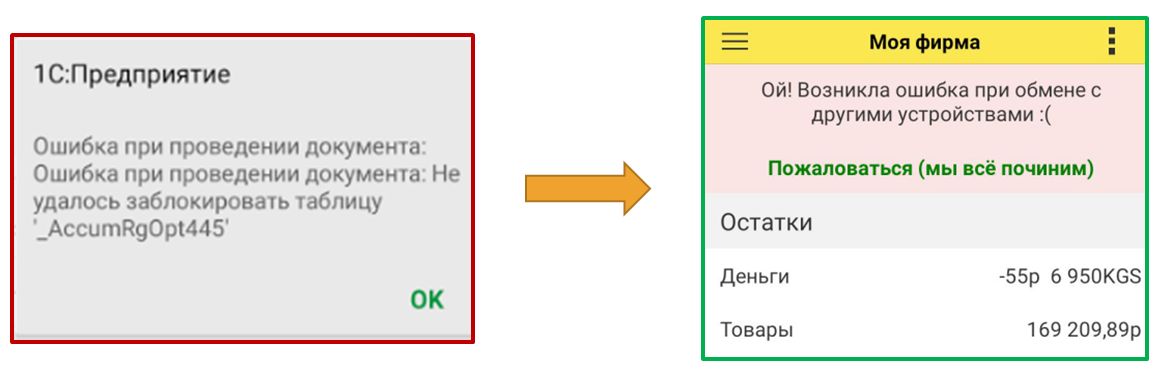
Еще важный момент – обязательно давать пользователю возможность "пожаловаться". Это улучшает наш статус в их глазах и спасает нас. Есть пользователи, как мы их называем, "истерички", которые при малейшей ошибке начинают отправлять нам на почту кучу сообщений, что ничего не работает, база не загружается, все страшно плохо. Но иногда они реально нас спасают, потому что находят порой такие баги, которые остальные еще чудом не обнаружили, серьезные баги.
Пользователя нельзя пугать. Ни страшными сообщениями, ничем другим. Им надо красиво все объяснять и предлагать пожаловаться. А мы обещаем все решить. Тогда и пользователи довольные, ведь они видят, что о них заботятся, и сразу верят, что им помогут:)
***************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2026 DEVELOPER. Больше статей можно прочитать здесь.
В 2026 году приглашаем всех принять участие в 7 региональных митапах, а также юбилейной INFOSTART EVENT 2026 в Москве.
Related Posts
 Получение логина и пароля техподдержки 1С из базы
Получение логина и пароля техподдержки 1С из базы Класс для вывода отчета в Excel
Класс для вывода отчета в Excel Счет-фактура для УПП
Счет-фактура для УПП Библиотека классов для создания внешней компоненты 1С на C#
Библиотека классов для создания внешней компоненты 1С на C#- Акт об оказании услуг (со скидками) — внешняя печатная форма для Управление торговлей 11.1.10.86
 Прайс-лист с артикулом в отдельной колонке
Прайс-лист с артикулом в отдельной колонке
Класс!
Т.е. судя по вступлению про бэкапы, Вы выложили этот материал только по тому, что он теперь не актуален? теперь есть платформенный механизм… В статье как я понял рассказывается, о том как сделать удобное приложение с точки зрения пользователя, но нет никакого примера кода, что очень прискорбно, потому как на бумаге можно и получше вашего на фантазировать, по моему куда более важно рассказать о том как это реализовать с помощью программных механизмов 1С. Как по мне, так это «пустая» статья без исходников.
Крутая статья.
«Что касается сервисов, в приложении Boss реализован мгновенный обмен: один пользователь вводит данные, а другой их получает.»
Скажите, а как у Вас в центральной (стационарной базе) организован план обмена? Что «сидит» в узле плана — пользователь или устройство? Иными словами, для рассылки пушей надо хранить идентификаторы устройств GCMsg. На конкретном устройстве может быть авторизован только один пользователь или любой? К примеру, месседжинг. Пользователь ГравБух написал в чат «Бухгалтерия». Все юзеры из чата «Бухгалтерия» должны получить это сообщение. Для этого надо отобрать ИД, которым отправить пуши. Чтобы их отобрать, надо знать кто из юзеров на каком устройстве авторизован.
Надеюсь, мой вопрос понятн, хотя несколько сумбурно написал…
А что у вас за фирма? Интересно работаете.
(2)это не совсем статья, это транскрипция доклада с прошлой конференции, все тонкости обсуждались там в кулуарах 🙂
(5) я знал, что без Вас тут не обошлось ))) к сожалению, тонкости как раз нигде и не описаны, а именно они — самое интересное)))
Например, «Поэтому в приложении Boss используются для обменов фоновые задания. После каждой записи данных в базу, запускается фоновое задание, которое инициирует обмен.»
Моблиьное приложение — по сути, аналог файловой базы. Значит не фоновЫЕ задания, а фоновоОЕ задание, так как в файловой базе одновременно может выполняться только ОДНО фоновое задание
(6) все намного и намного хитрее. Во-первых — используются разные фоновые задания, отсюда и фоновЫЕ, хотя и последовательно.
Но, помимо них еще есть обмен по событию, и регламент. Так что тут все достаточно сложно, на самом деле.
(7) На самом деле, кстати, пуши — не панацея. Потому что что такое пуш на самом деле? По сути, на устройстве крутится служба гугл, которая раз в каком-то промежуток времени шлет запрос гугл-сервер на предмет «я ИД такой-то, есть что для меня?». И это именно так, потому что иначе как? Если бы сервер гугла иницировал обмен, то он по факту должен знать связку «ИД гугла — мак-адрес телефона в конкретной сети конкретного оператора СОСС». Чтобы послать месседж конкретному устройству, на котором авторизован в своей гугл-учетке конкретный юзер. Конечно же, он такими данными не обладает.
Поэтому, банальное
завернутое в фоновое задание — тоже самое, что пуши.
Главное, чтобы 1С могла фоново работать, а для этого надо ей это разрешить в настройках устройства.
Тестировал, такой код ни разу не «сажает батарею».
Делал похожее решение, пришел к отказу от планов обмена так как xml слишком громоздкий и планы обменов просто взрывали мозг. Проверку новых данных делали простым http сервисом.
(3) в узле плана обмена «сидит» даже не устройство, а конкретная база на конкретном устройстве — на сервере соответственно храним ИдентификаторПодписчикаДоставляемыхУведомлений этой базы (см. метод ПолучитьИдентификаторПодписчикаУведомлений() ) и какой пользователь там работает, чтобы знать какие куда отправлять данные.
(8) ну не совсем то же самое, т.к. в таком случае нам нужно с какой-то периодичностью «дергать» наш сервер и спрашивать его «есть чё для меня», и когда накапливается несколько тысяч баз по несколько устройств в базе, то как-то сервер уже будет не очень-то рад такой популярности:) А чтобы обмен происходил именно быстро с точки зрения пользователя, дергать придется еще и очень часто.
А так мы без острой необходимости к серверу не обращаемся, и перекладываем ответственност на службу гугл и пуши. А дергаем сервер, грубо говоря, в двух случаях: когда что-то записали на этом устройстве (чтобы отправить новые данные на сервер) и когда получили пуш, что на сервере появилось что-то новое с другого устройства.
(9) не очень понимаю, в чем связь плана обмена, xml и http-сервиса — это же 3 отдельных никак не связанных вещи, и уж точно не взаимозаменяемые 🙂
А в каком формате вы передаете данные вместо xml? json?
(2) насчет бекапов: платформенный механизм хоть и есть, но очень уж «далеко» спрятан для рядового пользователя, и особенно далеким он становится, когда после поломки базы платформа просто сообщает об ошибке и закрывается, т.е. «список приложений» в мобильном приложении 1С уже никак не достать; + он сохраняет копии на том же устройстве, и пользователю тогда нужно самостоятельно те копии доставать и переносить в облако, если он сильно обеспокоен сохранностью данных:)
Ну и когда используется синхронизация с сервером, та платформенная копия (аналог dt в настольной 1С) тоже не особо поможет, т.к. тут разве что разрывать связь с сервером и заново регистрировать восстановленную базу и подключать другие устройства.
А насчет примеров кода: в докладе ставилась цель хотя бы «на пальцах» успеть рассказать идеи и предоставить пищу для размышлений, изначально это не статья и точно не мануал:)
Но интересно, какая именно часть не до конца понятна/недостаточно подробно изложена и требует примеров кода?
(10) а когда пользователи авторизуются в программе на устройстве — связку «база на устройстве — пользователь» — обновляете, отправив данные с устройства на сервер? И связка наверняка в регистре сведений))) я также делал, собственно говоря. Насчёт нескольких тысяч мобильных пользователей — таких объёмов объёмов, честно говоря, никогда не видел. Скорее всего, при такой нагрузке сервер для обменов данными надо выносить в отдельную базу и синхронизировать с продакшном регламентном.
(12)
А в каком формате вы передаете данные вместо xml? json?
А я и не говоил об их связи, я имел ввиду что:
1.Отказался от планов обмена
2.Для обмена использовал свой очень сжатый формат
3.HTTP сервисы использовал для определения новых данных на сервере
(15) просто в вашей первой формулировке прослеживалась связь, значит не так прочитала)
(15)
Мне уже прям интересно — каким образов вы фиксируете удаленные объекты и регистры сведений. Жуть как интересно.
Что значит сжатый формат? Текст хорошо сжимается хранилищем значений. JSON поддерживается и на сервере и в мобильнике. Куда еще «сжатее»?
А старых? А удаленных? А измененных? А блокировки данных? А данные которые вдруг стали не доступны, или наоборот — доступны, когда по РЛС склад не доступен, а потом поменяли склад на другой в документе?
В ваших словах, как мне кажется, затаилось очень-очень узкоспециализированное решение. Которое уж никак не может претендовать на нечто «универсальное, что можно советовать всем». ИМХО
(17)
нормально их фиксируем по ObjectID, а как по вашему их фиксирует механизм РИБ?
(17)
Ну вы серьезно? Есть более сжатые форматы чем JSON. Мой формат похож на csv.
Кстати хранилищем значений сжимается в веб-сервисах, а они не приемлемо тормозят. А насчет HTTP сервисов недавно открыл вариант сжатия в хранилище и предачу по Base64, но я еще не тестировал его, думаю выйгрыш будет не большой.
(17)
RLS не требовался в реализованных решенях т.к. обмен Сервер — Терминал
(17)
Заметьте мы обсуждаем тут решение Сервер <-> Мобильная платформа.
Решение универсальное и план обмена может менять сам пользователь на лету. Так же их может существовать сколько угодно и для разных мобильных (переферийных) баз свой план.
Так же бинарные данные и картинки тоже переносятся.
(18)
А какой ID у регистра сведений? И это получается, что при каждом удалении/изменении регистра и т.д. — у вас вызываются обработчики которые фиксируют все это куда-то. Где потом 100% узкое место лдя блокировок, причем по всей системе в куче.
csv — это вообще не формат обмена данными, чтобы его использовать — систему надо покрывать кучей тестов, из серии, а что если разделитель попадется в наименовании. А также следить за порядком данных в нем, и вообще — csv, это уже давно частный случай JSON. Это раз, два — в csv вы выигрываете только в том, что не именуете теги, но так этогда просто массив данных того же json, но система уже сама может контролировать запрещенные символы и кучу всего другого. Два — хранилище — это арзиватор, архиватор отлично сжимает тексты, которые повторяются очень часто, а значит сжав JSON и CSV вы получите мизерный прирост, который вообще не стоит затраченных усилий. Три — json парситься платформой, а csv — мы мучаете сами, т.е. напрягаете не платформенные механизмы для парсинга, а прикладные, что всегда плохо.
Та и в целом — JSON это хороший тон.
А еще хранилище можно записать в текст и передать просто в теле запроса текстом, а можно вернуть бинарные данные.
РЛС не требовался — это понятно, но как это связано с сервером терминалом?
А я где то говорил про стационарную 1С?
Решение универсальное и план обмена может менять сам пользователь на лету. Так же их может существовать сколько угодно и для разных мобильных (переферийных) баз свой план.
Так же бинарные данные и картинки тоже переносятся.
Меня не покидает чувство, что вы просто не захотели разбираться досконально в планах обмена и прочих механизмах, потому что то о чем вы говорите — вообще никак не связано с тем, как это все делается.
P.S. Я согласен, что бывают старые проекты, которым уже 3 года, или больше, и там иногда требовалось отказаться от планов и прочей ахинеи в мобильной 1С, но это не из-за того, что по другому — круто, а из-за того, что раньше по другому просто не работало в принципе.
Сейчас же — все работает отлично. Поэтому не нужно выдумывать велосипеды 🙂
(19)
Фиксируются в отдельный регистр под каждый объект, так же как и в РИБ
(19)
все спец символы контролируются тегами для HTML, в данном решении парсить данные не нужно так как они уже структурированы по колонкам, теги тоже не нужны
(19)
Я это и имел ввиду когда написал BASE64 🙂 Вопрос по выйгрышу остается открытым
(19)
В момент формирования пакета данных для терминала фильтрация происходит по нужным правилам
(19)
В обычных решениях 1С я везде использовать РИБ. Но в данном случае были взвешены во внимание скорость, ограничения РИБ и гибкость нужная клиентам и было принято решение сделать свой механизм.
(19)
У меня тоже все работает отлично, разница в том что я контролирую весь процесс полностью.
(19)
В мире ИТ всегда выдумываются велосипеды, благодаря этому мы имеем C++, Java. а сейчас Kotlin для мобильной разработки и кучу всяких JS-фреймворков и я считаю это прекрасно.
(20)
Почему вы используете термин РИБ? Он тут вообще не применим, в принципе, и опять я повторюсь — вы не разобрались в механизмах. Вам никто не мешает регистрировать планами, а потом делать выборки из планов.
Если честно — я понимаю о чем вы пишите, я сам так когда делал, пока не научился делать это правильно.
Вы смотрели бесплатный курс по мобильной платформе?
(21)
Если честно — я понимаю о чем вы пишите, я сам ак когда делал, пока не научился делать это правильно.
Ок, механизм распреленных баз данных используя планы обмена. Да я в курсе что можно самостоятельно регистрировать изменения в план, меня все же не устраивает этот механизм от платформы, мне нужен полный контроль.
Нет бесплатный курс не смотрел.
(22) есть планы обмена, их задача регистрировать изменения данных, с возможностью дальнейшего переноса данных куда угодно и в каком угодно виде.
Есть РИБ — риб, это частный случай использования планов обмена, который подразумевает одно ключевое упрощение — у вас все базы входящие в риб должны быть идентичны, так как риб переносит вместе с данными и конфигурацию.
Мобильная платформа вообще не поддерживает риб и это логично.
Отсюда вопрос — зачем писать свой велосипед обмена данными, если есть стандартный.
Советую посмотреть курс, тогда большая часть вопросов отпадет сама собой.
(23)
Отсюда вопрос — зачем писать свой велосипед обмена данными, если есть стандартный.
Не вижу в этом ничего логичного. Зачем писать я ответил выше.
(23)
Посмотрел бесплатный курс… я конечно понимаю, что это своего рода реклама для полного курса, но все же просмотрев готовое решение и сам курс я сделал вывод, что как и 99% вводных курсов по всем технологиям, он имеет мало общего с реальностью.
Я никому не рекомендую читать этот вводный курс, а про полный и не знаю что сказать, спасибо вам и удачи.
(24) Как это не видите, т.е. вы считаете, что при написании заказов для торговых агентов — база мобильной должна полностью соответствовать стационарной 1С? Та еще и обновляться при каждом обновлении стационарной? Я вас правильно понял?
(25) При чем тут платный, в бесплатном курсе хорошо разобраны планы обмена, причем в платном — про них ни слова нету. Но раз вы даже из этой информации ничего не смогли вынести (где рассказано про планы, про то, почему именно они, как работать с ними, как преобразовывать данные и т.д.), то да, наверное я зря стараюсь, когда пытаюсь чтобы было по меньше велосипедов в мире 1С.
Ну ок, пусть будет так. Тогда и вам удачи 🙂
(26) Ссылку на курс дайте плиз. И на платный , и на бесплатный
(27) там смотрите раздел по мобильным, там три курса.
http:// /courses/
(13) А не подскажете, какая функция делает выгрузку базы средствами платформы?
Полистал хелп, прочитал список изменений в 8.3.9?
О какой программной выгрузке базы идет речь?
Нашел только выгрузку журнала регистрации и выгрузку конфы в файлы xml, но это ведь не то?
Надо ведь на выходе получить dt?
(30) речь не о программной выгрузке, а о том, что пользователь теперь может самостоятельно делать бекап, до 8.3.9 этого не было. Правда спрятали эту функцию так далеко, что пользователи ее и не находят, что в нашем случае и хорошо:) А пройти пользователю нужно вот такой путь — список приложений — меню этой базы — Изменить — Администрирование — Резервное копирование. На выходе если заглянуть в папку с бекапом — там 1CD файл с кучей служебных, вот только просто открыть такой файл на настольной платформе не получится.
Программно создать такой бекап нельзя, как и узнать, что пользователь его развернул. Поэтому чтобы перестраховаться в случае, если используете синхронизацию, нужно добавить свою какую-то проверку: например, записывать дату последней синхронизации на мобильном и на сервере для каждого устройства, и сверять эти даты.
Когда уже будет БСП для мобильной платформы?..
Добрый день Снежана,
Каким образом вы посылаете PUSH на клиентские андроид / iOS терминалы?
Какой сервис вы используете? Google или 1С или другой?
Сразу говорю что я не ваш конкурент так как работаю в другой стране и создаю узкоспециализированные решения. Заранее спасибо за ответ.
С Уважением, Василий.