<?php // Полная загрузка сервисных книжек, создан 2026-01-05 12:44:55
global $wpdb2;
global $failure;
global $file_hist;
///// echo '<H2><b>Старт загрузки</b></H2><br>';
$failure=FALSE;
//подключаемся к базе
$wpdb2 = include_once 'connection.php'; ; // подключаемся к MySQL
// если не удалось подключиться, и нужно оборвать PHP с сообщением об этой ошибке
if (!empty($wpdb2->error))
{
///// echo '<H2><b>Ошибка подключения к БД, завершение.</b></H2><br>';
$failure=TRUE;
wp_die( $wpdb2->error );
}
$m_size_file=0;
$m_mtime_file=0;
$m_comment='';
/////проверка существования файлов выгрузки из 1С
////файл выгрузки сервисных книжек
$file_hist = ABSPATH.'/_1c_alfa_exchange/AA_hist.csv';
if (!file_exists($file_hist))
{
///// echo '<H2><b>Файл обмена с сервисными книжками не существует.</b></H2><br>';
$m_comment='Файл обмена с сервисными книжками не существует';
$failure=TRUE;
}
/////инициируем таблицу лога
/////если не существует файла то возврат и ничего не делаем
if ($failure){
///включает защиту от SQL инъекций и данные можно передавать как есть, например: $_GET['foo']
///// echo '<H2><b>Попытка вставить запись в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>$m_comment));
wp_die();
///// echo '<H2><b>Возврат в начало.</b></H2><br>';
return $failure;
}
/////проверка лога загрузки, что бы не загружать тоже самое
$masiv_data_file=stat($file_hist); ////передаем в массив свойство файла
$m_size_file=$masiv_data_file[7]; ////получаем размер файла
$m_mtime_file=$masiv_data_file[9]; ////получаем дату модификации файла
////создаем запрос на получение последней удачной загрузки
////выбираем по штампу времени создания (редактирования) файла загрузки AA_hist.csv, $m_mtime_file
///// echo '<H2><b>Размер файла: '.$m_size_file.'</b></H2><br>';
///// echo '<H2><b>Штамп времени файла: '.$m_mtime_file.'</b></H2><br>';
///// echo '<H2><b>Формирование запроса на выборку из лога</b></H2><br>';
////препарируем запрос
$text_zaprosa=$wpdb2->prepare("SELECT * FROM `vin_logs` WHERE `last_mtime_upload` = %s", $m_mtime_file);
$results=$wpdb2->get_results($text_zaprosa);
if ($results)
{ foreach ( $results as $r)
{
////если штамп времени и размер файла совпадают, возврат
if (($r->last_mtime_upload==$m_mtime_file) && ($r->last_size_upload==$m_size_file))
{////echo '<H2><b>Возврат в начало, т.к. найдена запись в логе.</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>$m_mtime_file,'last_size_upload'=>$m_size_file,'comment'=>'Загрузка отменена, новых данных нет, т.к. найдена запись в логе.'));
wp_die();
return $failure;
}
}
}
////если данные новые, пишем в лог запись о начале загрузки
/////echo '<H2><b>Попытка вставить запись о начале загрузки в лог таблицу</b></H2><br>';
$insert_fail_zapros=$wpdb2->insert('vin_logs', array('time_stamp'=>time(),'last_mtime_upload'=>0, 'last_size_upload'=>$m_size_file, 'comment'=>'Начало загрузки'));
////очищаем таблицу
$clear_tbl_zap=$wpdb2->prepare("TRUNCATE TABLE %s", 'vin_history');
$clear_tbl_zap_repl=str_replace("'","`",$clear_tbl_zap);
$results=$wpdb2->query($clear_tbl_zap_repl);
///// echo '<H2><b>Очистка таблицы сервисных книжек</b></H2><br>';
if (empty($results))
{
///// echo '<H2><b>Ошибка очистки таблицы книжек, завершение.</b></H2><br>';
//// если очистка не удалась, возврат
$failure=TRUE;
wp_die();
return $failure;
}
////загружаем данные
$table='vin_history'; // Имя таблицы для импорта
//$file_hist Имя CSV файла, откуда берется информация // (путь от корня web-сервера)
$delim=';'; // Разделитель полей в CSV файле
$enclosed='"'; // Кавычки для содержимого полей
$escaped='\








Плюс.
Добротно написано, хорошие ссылки. Автор постарался. Плюс без разговоров!
Звезда в шоке — то, о чём звезда мечтала прочитать…
+
взакладки, спасибо
Люди! Я очень благодарен вам за лестные отзывы и плюсы.
Но больше мне хотелось бы получить замечания, предложения и поправки, особенно от тех, кто уже сталкивался с такими задачами. Тем более, что в этих 8 вариантах, я уверен, можно найти ошибки или улучшения, а значит и мои выводы в статье могут оказаться не верными.
Прошу конструктивной критики.
Подредактируйте текст, а то все сливается. Выделите списки, отделите абзацы. Там в редакторе есть замечательная кнопка «Full screen».
6. Сделаю
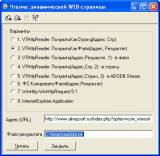
Хорошее исследование. Правда я отдаю предпочтение варианту 8 — в большинстве случаев парсинг составляет 90% кода в подобных обработках.
Если же данные нужно получать быстро, то InternetExplorer.Application конечно проигрывает…
(6) Пытался в статье вместо ссылки на скриншот вставить саму картинку в натуральную величину и не смог. Требует УРЛ картинки и ссылку на путь к файлу на моем компе не понимает.
Подскажите, пожалуйста, как это сделать?
(8) А Ваш код по варианту 8 отличается от моего?
8+ кстати InternetExplorer.Application можно несколько «ускорить» — обычно много времени тратится на загрузку — при этом 1С ждет пока загрузится страница (пустой цикл или слееп через вк)… я обычно кидаю на форму активикс, а 1С++ позволяет обрабатывать события активикс, а не тупо ждать загрузки. Такой метод позволяет почти «в фоне» загружать инфу
(10) сорри, сейчас код посмотреть не могу (дома 1С-ки нет). В понедельник гляну — если что — подправлю комментарий.
(12) Не забудьте
вопрос не в том, как прочитать вариантов7/8 — а почему предыдущие варианты не работают..???
Как оказалось, я рано обрадовался и поторопился с выводами по вариантам 7 и 8 .
При новых опытах нашлась страница , на которой эти варианты заткнулись: в варианте 7 страница урезалась до 330 символов, а вариант 8 выдал ошибку доступа к странице.
Возможно, это особая страница, которая имеет спец.защиту от автоматического «нечеловеческого» чтения роботами (где-то я видел упоминание о таких защитах).
А может руки кривые, и можно как-то улучшить код?
(14) Сам не понимаю почему варианты 1-5 не работают. Хотелось бы их использовать, читают они очень быстро. Может, удастся их усовершенствовать?
(15) ты пробовал эту ссылку открывать руками в ИЕ? у меня не открывается.
Кстати, добавь еще метод чтения через СоздатьОбъект(«MSXML2.XMLHTTP»)
ЗЫ Код не понравился 🙁
(16) Точно, ИЕ вылетает с ошибкой. А в Firefoxe у меня нормально грузится. Поэтому и вариант 8 с этой страницей не работает.
Вариант с СоздатьОбъект(«MSXML2.XMLHTTP») опробую и добавлю, если получится (С ХМЛ я еще не работал).
А какой код не понравился? Чем плох?
Ты же обещал свой код показать.Где он?
(17) Мой код есть например тут: — ничем не лучше твоего.
А код не понравился потому что … просто не понравился. Это сугубо ИМХО — можешь не обращать внимания.
Напрасно скромничаешь. Код хорош. Нашел для себя много полезного. Спасибо. Плюс
Меня извиняет, что это просто тестовая обработка 😳
По предложению (16) добавил вариант 9. MSXML2.XMLHTTP.
При этом выявилась еще одна пакость: при чтении некоторых страниц (например, вместо кириллицы в файле результата знаки вопроса. Хотя, вроде бы, все сделал, чтобы кириллица читалась правильно:
XMLHTTP.SetRequestHeader(«Connection», «close»);
XMLHTTP.SetRequestHeader(«Cache-Control», «no-cache»);
XMLHTTP.SetRequestHeader(«Accept-Language», «ru, en»);
XMLHTTP.SetRequestHeader(«Accept-Charset», «windows-1251;q=1, koi8-r;q=0.6, ISO-8859-5;q=0.4, ISO-8859-1;q=0.1»);
XMLHTTP.SetRequestHeader(«User-Agent», «Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)»);
При ручном сохранении этой страницы в htm или txt кириллица пишется в файл правильно.
Вопрос к гуру: как это поправить?
+ За отличный анализ
Добавил еще 5 вариантов в обработку, кое-что исправил. Добавил описания в статью. Наконец-то нашел то, что мне нужно — вариант 13. Microsoft.XMLHTTP+ MSScriptControl+ADODB.Stream. Он справился со всеми моими проблемами: показал вполне приемлемую скорость чтения и прочитал нормально ВСЕ предлагаемые ему динамические WEB — страницы, в том числе и каверзную страницу , причем нормально прочитал и кириллицу.
Кстати, занятное совпадение: вариант 13, сегодня пятница, 13-е ноября. Сколько плохих примет. А у меня такая удача. Вот и верь после этого в несчастливые числа и плохие приметы!
Отличный анализ, ссылки — есть над чем поразмыслить и что попробовать.
Особенно на фоне убивающих бесполезностью публикаций типа очередная загрузка-выгрузка аля-«клиент-банк».
Отлично! Приятно читать. Сам бы на такой отчет не решился !
+
Прикольная статья. Плюс.
Сам использую WinHttpRequest для передачи информации на сайт из 7.7. Иногда случается, что сайт недоступен. В таком случае выполнение зависает. Причём применение метода SetTimeouts помогает мало. При установке таймаута в 1 секунду по его истечению вызывается исключение, отображающее соотв. ошибку, а вот дальше примерно 13 секунд объект WinHttpRequest не может уничтожиться (я использовал приравнивание его к нулю или к пустой строке, результат одинаков). Программа зависает и не реагирует ни на какие действия. С чем это может быть связано?
Кстати, а у XMLHTTP вообще невозможно установить таймаут — нет соотв. метода, так что там зависания ещё длительнее.
Спасибо за труд, полезная статья и обработка на примере какой можно учиться, набрел на статью случайно, выручила меня. ПЛЮС однозначно! 😉
Неплохая подборка способов работы с веб-страничками.
Однако поправлю.
AddIn.V7HttpReader прекрасно работает с любыми страницами и качает всю как надо. Проблема в самих страницах, которые не отдают заголовок «Content-length». Поэтому по умолчанию используется 1Кб. Со своими сайтами решаем проблему легко, просто добавляем отдачу заголовка, а вот с другими «нерадивыми» сайтами можно работать предложенными в Ваше работе способами.
P.S. Заголовок «Content-length» не отдают, как правило, динамические страницы работающие на языках вроде PHP, так как на момент отправки заголовков еще не известен размер передаваемой страницы. Решается проблема использованием буфера вывода страницы. Сначала выводим страницу в буфер, затем определяем размер данных, передаем заголовок и только потом выдаем полученные данные. Для PHP делается просто:
ob_start();
…. код страницы
….
// Определяем размер
$size=ob_get_length();
// Передаем заголовок
header(«Content-Length: $size»);
// Выводим данные из буфера
ob_end_flush();
// Передаем все браузеру
flush();
Спасибо большое. Очень полезный анализ.
(28) Похоже, Вы хорошо разбираетесь в этом вопросе. Поэтому просьба: не могли бы Вы привести здесь или выслать мне рабочий пример на 1С, позволяющий читать динамические страницы с использованием AddIn.V7HttpReader. Я думаю, многим он был бы очень полезен.
2mai, так Ваш пример и есть рабочий! Повторюсь, дело не в AddIn.V7HttpReader, а в отсутствии информации о размере полученной страницы. Прочтите еще раз внимательное мое сообщение. Я уже все подробно описал.
Вы молодец и примеры очень хорошие, я только уточнил почему себя так ведет AddIn.V7HttpReader . 🙂
Молодец, я намучался искать почему моё «Получить» из v7plus режет xml от яндекс мэп. Спасибо за материал.
«Мои опыты» — где нибудь в серьезном проекте твои опыты учавствуют? 🙂 Ставлю + за старания 🙂
Все эти опыты — как раз поиск решения для одного моего проекта. Правда серьезным его назвать я не рискну.
(34) Мои «3 строки кода» стабильно и быстро работают в механизмах интеграции нескольких крупных компаний через WS (в том числе и не 1С) на Soap и JSON
(35) 2vadmaster, эти «3 строки кода» я могу посмотреть?
(36) Тут у меня чел dimas103 сослался на вашу публикацию
3. dimas103 14.11.2013 16:57
И раз Опыт
И два Поиск в помощь
Вопросы были риторические, и ответа не требовали.
Обработка не содержит ничего интересного.
Вернее вопрос один сколько строчек кода?
Я ему попытался объяснить, что этот код работает и для HTTPS (просто 3 строчки кода как пример скачивания файлов) — видимо он не понял.
Я подумал, что эта разработка его, оказалось, что он просто на вашу публикацию сослался
Сначала использовал метод 7, но на некоторых сайтах получал проблему с кодировкой, но вариант 13 решил данную проблему работает чуть медленнее, но для меня это не критично.
«ADODB.Stream» использовал в обоих вариантах, так как информация приходит в utf-8
Дано гугл картинки по адресу
Справился только 7 метод
1-4 методы Компонента V7Plus : Попытка использования недопустимого протокола обмена
5-6 файлы нулевого размера
8 метод скачал 1/5 часть страницы (причем хвостик в конце)
9 — ошибка доступа
10 — просто завис, устал ждать
11-12 — нулевой размер
13 — x.Send(); msxml3.dll: Access is denied.
При этом при попытки скачать картинку (
только 13 метод смог скачать ей, остальные или нулевой размер или файл размером 10 байт с текстом «yOya.DExif» внутри
«ФС.КопироватьФайл(Адрес,ФайлКопии) отрабатывает моментально и без ошибок, но ФайлКопии даже не создается. Что и ожидалось. Уж слишком просто.»
возможно, отсутсвуют права на месторасположения файла-приемника
Огромное спасибо! Очень помог с п.13. Главный вопрос был с кодировкой — все русские буквы = «?????».
Корректная ссылка на источник: